
电力项目规划评审微服务平台架构优化设计
2022-02-26 00:02:32李海滨周洁刘丽张晋梅宋斌宋堃
微型电脑应用 2022年2期
李海滨, 周洁, 刘丽, 张晋梅, 宋斌, 宋堃
(国网冀北电力有限公司 经济技术研究院, 北京 100038)
0 引言
随着网络技术在服务领域的广泛应用。各种微服务平台应运而生,评审微服务平台的出现,构成了电力项目规划评审新模式,同时对微服务平台评审工作提出了新的要求[1-3]。针对评审过程中对项目规划管理与控制结构为切入点,对微服务平台架构中存在的评审模式、管理结构进行系统性架构层优化,强化评审数据交互结构与数据库规范资源配置,提升流程交互机制、规范评审管理模式与架构功能,统一评审过程中对部门数据间的关联、授权及操作[4-5]。使电力项目规划评审微平台架构能够融入到实际应用场景。
在传统的电力项目规划评审架构模型中,主要将电力项目的规划评审流程划分为项目设计、项目进展、项目审批与项目改进4个环节,根据环节的进展性与关联性将其称为DPAI评审架构模式[6],它是由英文单词Design、 Progress、 Approval、 Improvement的首字母组成。
通过对传统电力项目规划评审的DPAI评审架构模式分析不难发现,传统的DPAI评审架构模式可归属于一种分散式管理架构,在各种变量的管理上存在一定的独立性,导致架构功能关联性一致,内部变量关联性却缺乏逻辑性,无法形成整条完整逻辑链,同时在评审数据的审批上,需要依赖架构以外的数据库支持,才能完成对相关规定数据的获取。在此过程中增加了数据库权限问题,降低了架构服务的完整性与一体性[7-8]。在逻辑变量上,传统架构是以一个问题循环为一个周期,多个具有相关性的问题被分为多个独立的问题周期来提供变量方案。在处理问题的效率上是有利的,但不利于评审问题的发现与解决。
1 微服务平台结构的逻辑链转换计算
基于上述对传统电力项目规划评审机构模型的分析,首先对逻辑链问题进行优化。根据逻辑链是由多个规划评审数据量之间关联量所构成的特点,结合上述提到了审批数据库问题,设计中采用挖掘算法对评审相关数据进行关联,同时在架构中建立决策树,实现对内建数据口的支持[9]。为了保证设计决策树下的每个关联子集键值规划的归一,采用决策树ID3算法来完成架构节点子集的挖掘归一计算。通过决策树ID3算法,对架构中审批数据子集的属性进行最大化增益,通过对内建数据文件内容变量的检索,获得多个决策树分支,由此构建起完整的数据关联树[10]。
决策树ID3算法假设项目规划评审过程中存在r个关联数据变量d1,d2,…,dr>,且满足同一个评审条件属性D,r个变量反馈关联信息k1,k2,…,kr>可根据评审条件属性D完成对整个评审计算流程的K定义,K内部所关联的数据库信息主要来源于Ky,其上述变量都在评审条件属性D上存在一个对应的条件关联键值dy,如果评审条件属性设为D,对应架构上的数据节点集合为K,且满足与决策树上的对应子集分支相统一。令架构上的静态子集对应数据库Ky中数据类型为Px的构成总量为Px,y。式(1)代表关联D所构成的决策树的子集分支熵:
(1)
式中,第y个静态子集对应的逻辑变量加权值为kx,y,…,kn,y/k,通过静态子集分支内部数据量除以K内的数据总量获得,同时可得到评审条件属性D此维度下的阈值等于d。FD同静态子集逻辑呈现出逆态形式。式(2)是对架构内建数据库Ky记性逻辑链转换的描述:
(2)
式中,Ky内数据类型隶属于Px的可能性可通过概率函数的形式描述为Qx,y=Kx,y/Ky。式(3)代表符合评审条件属性D具有相同关联性的分支对应信息总量:
HD=Xk1,x,k2,x,…,kn,y-FD
(3)
式中,决策树通过增强符合审批条件属性D的键值完成对逻辑链的转换,即决策树总键值HD的定义。
2 电力项目规划微服务架构内建数据库策略定义
数据库作为评审内容数据审定对比资源的来源,其内部规范、标准相关数据的总量与服务权限决定着平台架构完整度。针对微服务平台的轻量化结构特征,设计优化中对内建数据库进行了规范策略的定义,定义描述如下。
数据库采用MySQL进行搭建,且对数据库内部数据及变量采用统一存储管理。
对数据库内部数据进行命名格式管理,即相关评审数据表开头一律为“s_”,规范、法律一律用“fg_”开头,其余为数据用“j”开头。图像、阈值、存储调度、时间日志等数据借用时间+文件变量属性开头。若数据文件涉及到多个关联类型文件,采用文件+关联控制文件的形式进行存储。单个数据能够同时关联的文件的字符数量定义值为45个字符,大于45的字符数对应的文件采用压缩字典的方式进行数据记录。
数据库文件必须采用全权限键值结构,且数据库的键值能够自动生成整数键值。
数据库内部数据注册表内字段结构必须有定义和注释,便于数据后期变更维护操作。
数据库内部数据冗余值需设定为动态值,便于根据数据库链接检索速度,随时调整冗余值,避免数据库空间资源的浪费。
搭建好的数据内部资源一旦定义完毕,不得随意修正更改、删除、替换,若必须修正,需数据库高级权限用户审批后,方可修正更新。
为了提升数据库在评审服务中的检索效率,设计架构优化中采用超级索引方式,来提升数据库资源查询的效率,同时最大程度地降低资源更新带来的数据交互延迟。
2.1 电力项目规划架构策略注册表定义
电力项目规划微服务架构数据库策略内部设计架构定义注册表信息如表1所示。
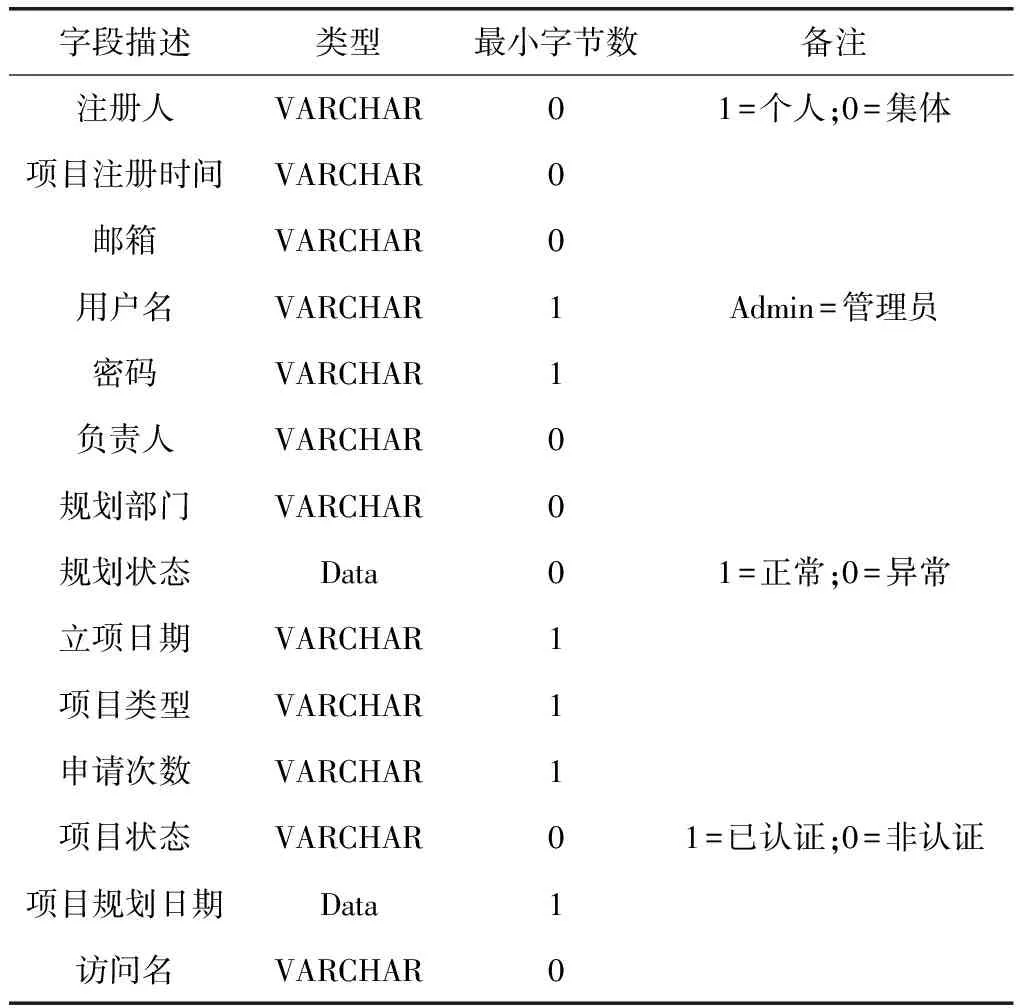
表1 电力项目架构数据信息表
2.2 评审架构数据信息注册表定义
根据上述项目规划策略注册表定义,将评审架构中的评审策略量进行关联逻辑的注册,通过对注册变量的配置定义,使评审流程以静态策略的形式固定下来,保证评审架构的稳定。具体评审架构数据信息注册量定义如表2所示。
2.3 服务架构的注册
根据表2注册表设计定义量,对优化机构对应服务进行设定,服务架构注册执行语言逻辑代码如图1所示。
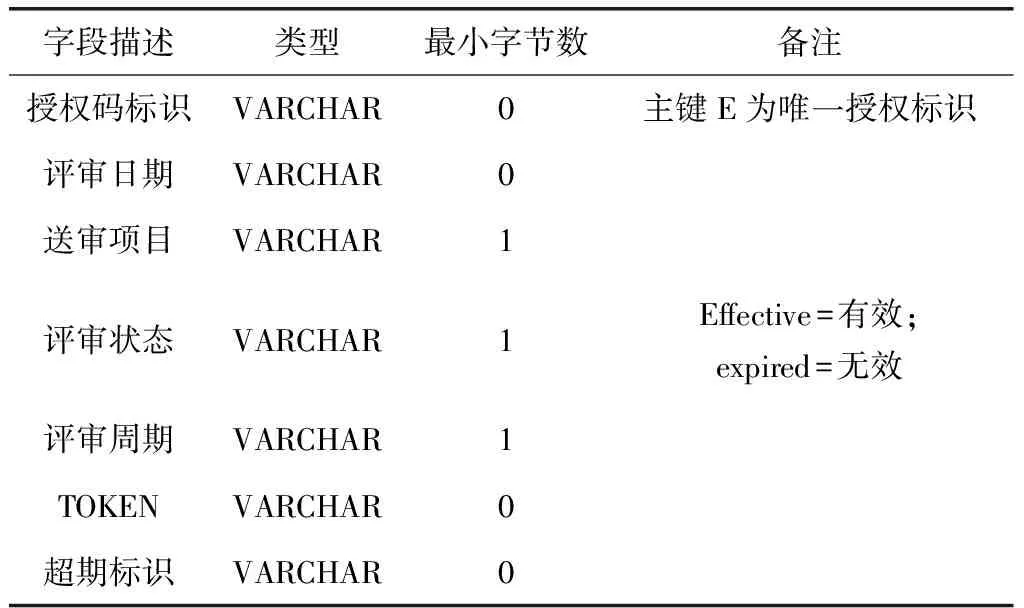
表2 评审架构数据信息表
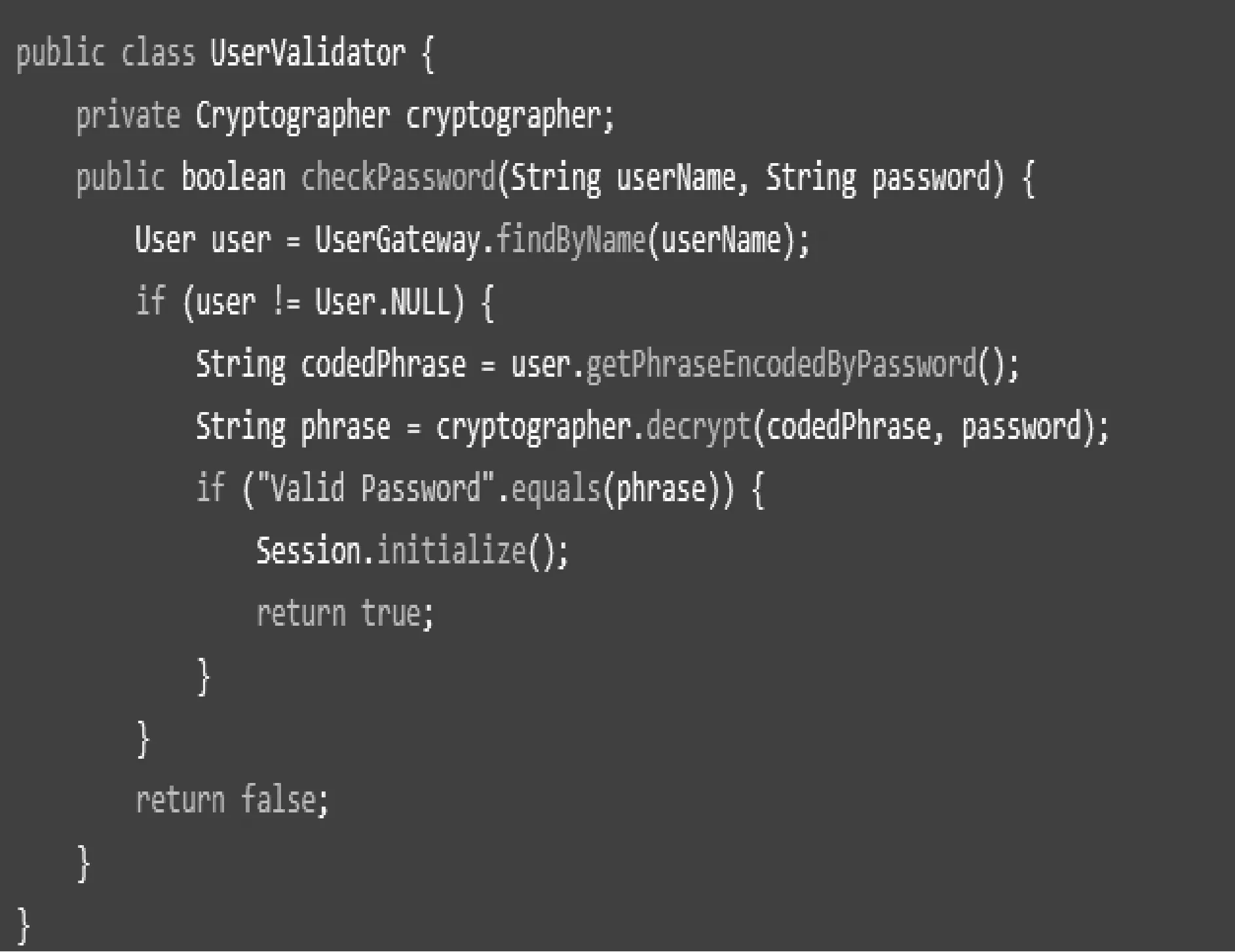
图1 服务架构注册执行语言逻辑代码
3 评审服务优化架构设计
完成上述优化设计后,对项目规划评审服务架构进行针对性优化设计。为了保留传统平台架构分散式管理的灵活性,设计采用MAster-Node的分布式架构,通过定义一个微服务节点来对多个评审节点进行管理,总体架构如图2所示。
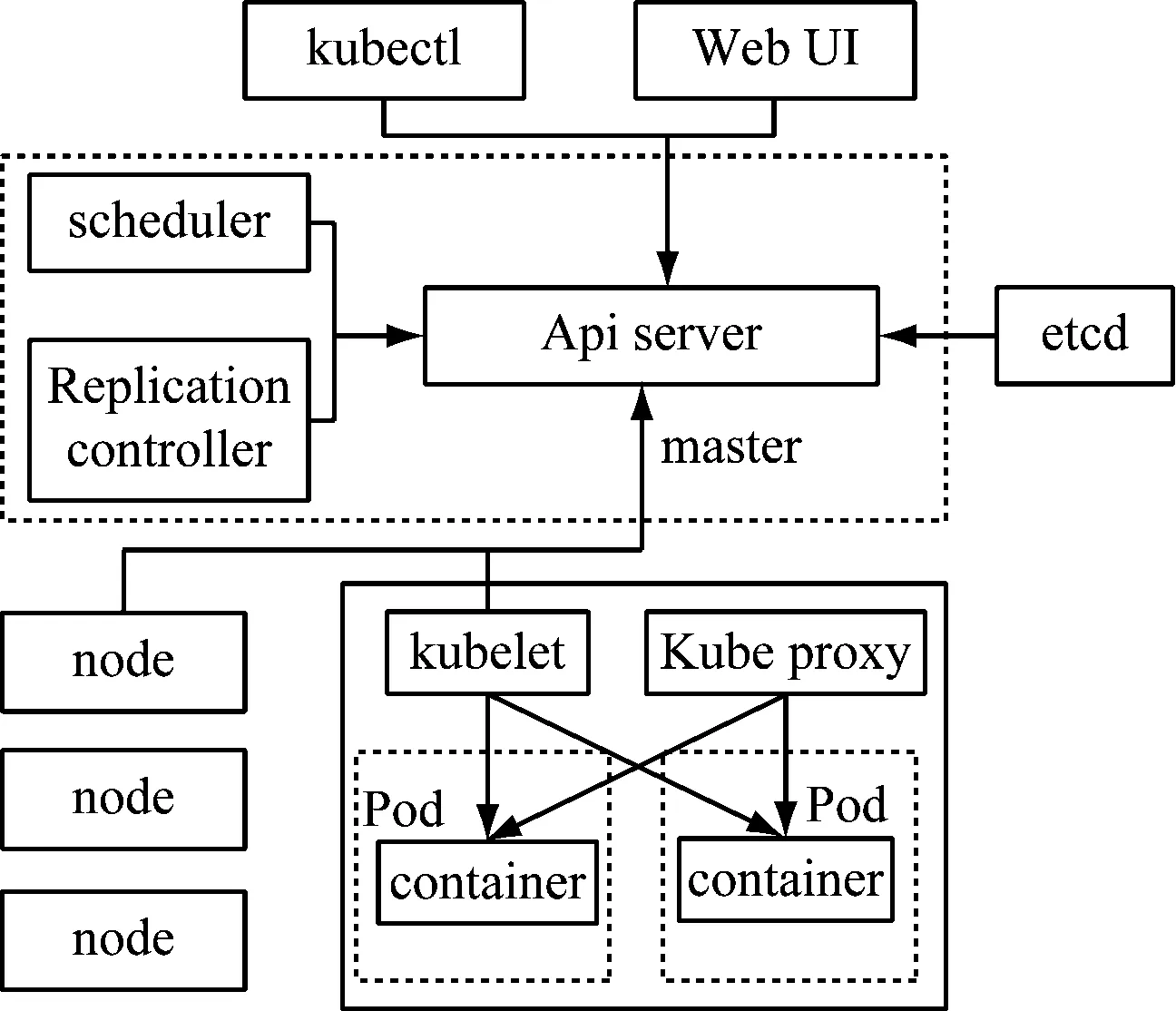
图2 评审服务优化架构总体结构
优化设计中,将微服务平台的主评审节点设置为K8 s主节点,通过主节点来完成对评审过程中子节点的分配管理,同时对数据的接入及Node节点的分布进行管理。在主节点的对外接口上,优化设计针对架构特征,采用API Sever为主接口设计,配合Controller Manage管理策略,对结构中的所有服务进行权限管理;考虑到架构底层资源的动态配置是决定评审服务架构合理性的关键,因此优化中采用Scheduie作为架构底层动态资源配置架构,同时为保证评审环节数据的永久性存储,设计了Etcd架构的存储配置量。
作为优化架构中的子节点,主要对评审服务过程中的Pod架构层进行服务层支持,在架构服务集群层面上将子节点服务转化为主节点服务操作,其中包括对Docker检索组件、评审进程Kubelet与授权服务进程KUber-Proxy的调动。Node子节点在启动前都会对单次服务所需的资源进行预配置,定时向架构主节点反馈自身相关资源信息与运行状态数据,并根据主节点动态实时做出相应资源与参量的调整。
4 实测数据选取
设计架构的实际数据测试需要采用架构测试工具,为了保证架构测试的稳定性,实验测试采用HP公司发布的LoadRunner 13.0 测试工具来完成。根据设计架构在评审服务中主要针对规划项目的评审数据流与数据库实际标准指数的处理,因此可通过一个任务测试接口来完成并发数据流的测试。
首先,抽取实际评审数据处理包的基础信息数据流导入优化后的电力项目规划微服务平台架构,抽取实际数据样本4500组,将抽取的实际数据样本设计为双节点并发的数据流模板,模板执行服务标签设定为“ps001”-“ps450”,共有450个节点测试流,每个并发节点测试流分别对应10个评审任务数据流,保存任务并导出。
4.1 实测数据脚本开发
实测数据脚本开发:通过LoadRunner 脚本编译工具,在IE核心浏览器的配合下,对评审工作流并发数据样本发起测试。实测步骤如下:
步骤1将实测样本导入优化架构;
步骤2通过测试工具用户名登录测试工具;
步骤3进入测试流程设置菜单;
步骤4设置菜单新建测试项目;
步骤5选择测试模板;
步骤6点击保存任务;
步骤7开始测试。
4.2 架构测试流的增长响应测试
实测数据样本评审任务测试模板执行服务标签设定为“xs001”-“xs450”共发送150个工作测试流,分析不同方法下响应耗时,得到结果如图3所示。
分析图3可知,不同方法的评审测试流增长状态不同。时间为50 s时,区块链方法发送的工作测试流为70,流程驱动方法发送的工作测试流为55,本文方法发送的工作测试流为100。时间为80 s时,区块链方法发送的工作测试流为105,流程驱动方法发送的工作测试流为85,本文方法发送的工作测试流为140。在相同时间内,本文方法能够发送更多的工作测试流,说明本文方法的评审测试流增长速度明显较快。
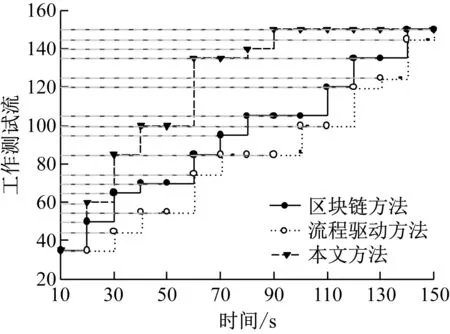
图3 不同方法评审测试流增长状态
评审微服务平台架构整体报告如表3所示。

表3 评审微服务平台架构整体性能报告
按照评审平台架构性能达标标准≥94.67%的要求,将报告1内的数据导入架构性能计算式(4):
(4)
式(4)中,设x=4 500,y=450,n=3,r=0.3;通过计算可得到优化后的架构评审任务并发逻辑达标率达到了98.67%,超过了电力项目规划平台架构设计技术标准94.67%,证明优化后的架构逻辑性更加合理,完全符合实际应用要求。同时通过溢出指标参数可以发现,架构在特定数据流的并发策略上还存在变数,后期可根据实际应用场景与用户群体的不同进行相应的修正。通过宁夏电力公司对该架构的使用反馈证明,设计架构已能够满足实际评审场景的应用要求,为不同用户群体,提供一站式评审服务。
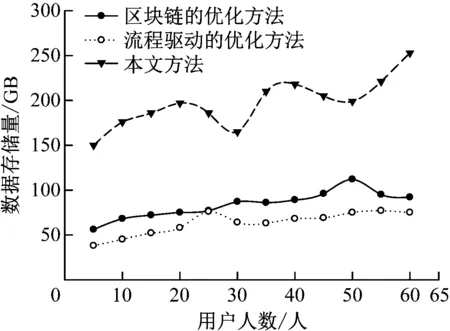
图4 不同方法优化后数据存储量
分析图4可知,不同的方法优化后数据存储量不同。当用户人数为5人时,区块链方法优化后数据存储量为56 GB,流程驱动方法优化后数据存储量38 GB, 本文方法优化后数据存储量150 GB。当用户人数为30人时,区块链方法优化后数据存储量为87 GB,流程驱动方法优化后数据存储量64 GB,本文方法优化后数据存储量165 GB。本文方法的数据存储量始终高于传统方法,这是因为本文方法分析了评审微服务平台底层数据量,并根据分析结果优化电力项目规划评审微服务平台架构,挖掘电力项目规划评审内容,提升数据存储量。
5 总结
区别于传统评审模式,微服务平台架构依托数字化办公与大数据计算技术,通过数据云端分析、交互、反馈,完成对评审流程的送报、审批、评审反馈流程的操作。因此,架构逻辑的合理性,直接决定评审服务的体验质量。为此,结合对传统平台架构模型的分析,进行了电力项目规划评审微服务平台架构优化设计。最后经实测数据表明,优化后的架构在操作流程切换、评审功能交互等操作逻辑上更加合理,提升了电力项目评审效率,简化了电流项目规划评审流程,对项目进程起到了推动作用。
猜你喜欢
信息安全与通信保密(2023年8期)2023-10-12 11:19:30
成都信息工程大学学报(2022年4期)2022-11-18 07:31:10
加油站服务指南(2022年6期)2022-07-28 06:07:08
汽车工程(2021年12期)2021-03-08 02:34:30
湖北农机化(2020年4期)2020-07-24 09:07:38
通信电源技术(2018年3期)2018-06-26 06:33:54
电信科学(2017年6期)2017-07-01 15:45:17
财经(2017年2期)2017-03-10 14:35:35
财经(2016年15期)2016-06-03 07:38:02
财经(2016年3期)2016-03-07 07:44:46
