
基于两阶段数据增强和双向深度残差TCN的用户负荷曲线分类方法
2022-02-17 07:10张杰刘洋李文峰王磊许立雄
电力建设 2022年2期
张杰,刘洋,2,李文峰,王磊,许立雄
(1. 四川大学电气工程学院,成都市 610065; 2. 智能电网四川省重点实验室(四川大学),成都市 610065; 3. 国网河南省电力公司, 郑州市 450052)
0 引 言
随着互联网和能源系统深度融合,能源互联网加速形成,针对电力用户的个性化售电服务逐渐丰富,迫切需要对电力用户进行精细化建模[1]。研究用电曲线外在规律与内在机理、分析用户用电行为与用电心理成为当前电力系统研究的热点[2]。负荷曲线分类作为用户用电行为感知的重点和基础,对于负荷预测[3]、需求侧响应[4]、异常用电检测[5]具有支撑作用,对于提升电网服务质量、改善用户用能体验具有重要意义。
伴随智能化用电信息采集系统的高度完善,用户用电数据快速增长,用电行为多元化和差异化特征加深,用户采集数据潜藏的缺失、空值、分布不均衡等问题愈发凸显,严重影响用户负荷的精细化建模。研究行之有效的数据增强方法以及更加高效准确的负荷聚类分类算法具有重要意义。
在算法层面,以支持向量机(support vector machine,SVM)、反向传播神经网络(back propagation neural network,BPNN)为代表的机器学习算法在负荷曲线分类上性能表现较好[6-7]。文献[6]在Spark平台将BPNN并行化,实现对海量负荷数据的高效分类;文献[7]通过稀疏自编码神经网络来学习负荷曲线特征,训练SVM实现负荷曲线的有监督分类。随着深度学习的发展,以长短期记忆(long short-term memory,LSTM)神经网络为代表的循环神经网络(recurrent neural network,RNN)引入序列建模,可充分挖掘负荷数据的时序特征,建立更加精细化的用户负荷模型。文献[8]提出一种基于注意力机制的LSTM短期负荷预测模型,通过注意力机制突出关键时序特征,进一步提高了预测精度。然而,LSTM在面对较长输入序列时,存在训练时间长、收敛速度慢等问题。将卷积神经网络应用于序列建模,改造得到的时间卷积网络(temporal convolutional network,TCN)具有卷积类神经网络通用并行处理数据的优势,可有效避免上述问题[9],且记忆范围可调,训练过程复杂度低,在文本分类、视频分割和识别等多个领域表现优于LSTM[10-11]。
在数据层面,数据缺失和类别不平衡是制约分类模型效能的重要因素。用户用电行为随机性、波动性不断增强,多点、多尺度数据片段缺失现象层出不穷,传统补全方法愈发难以适应复杂多变的数据缺失场景[12-14]。尤其在高比例数据缺失场景下,数据资源丢弃已成为常态,缺失数据重构研究面临难题。文献[12]采用数理统计方法填充用户缺失负荷数据,在低缺失率下达到较高补全精度;文献[13]利用生成式模型学习数据之间的复杂关联性实现缺失数据重构,但需要大量完整样本序列训练;文献[14]基于压缩感知理论利用负荷矩阵的低秩性修补缺失数据,由于其充分考虑负荷数据时空关联性,在较高比例数据缺失时仍有较好的补全精度。类别不平衡是模式识别领域的重要难题之一,表现为分类任务中少数类样本被多数类淹没,导致分类模型效能严重退化,已在电力负荷数据研究中受到重视[15-16]。文献[15]提出一种基于聚类结果的人工少数类过采样(synthetic minority oversampling technique,SMOTE)方法以改善训练样本中类别不平衡现象;文献[16]使用基于边界的数据合成算法对负荷数据样本进行平衡处理。但上述SMOTE及其改进方法只利用局部先验信息,生成数据跟真实负荷存在较大差距。
针对以上问题,本文提出一种基于两阶段数据增强的双向深度残差TCN负荷曲线分类方法。主要工作为:1)将用户负荷数据转换成多维张量结构,建立以张量核范数为约束的低秩张量补全(low rank tensor completion,LRTC)模型,并使用交替方向乘子法(alternating direction method of multipliers,ADMM)优化求解;2)构建稳定性更强的生成对抗网络(generation adversarial network based on Wasserstein distance,WGAN)模型,学习少数类样本的真实分布规律,通过样本生成实现类别平衡;3)基于权重规范化(weight normalization,WN)机制、ELU(exponential linear units)激活函数、随机失活(Dropout)机制、残差连接的多层次模型优化技术,采用双向时序建模强化模型微观波动特征提取能力,构建双向深度残差TCN模型对用户负荷曲线实施分类。
1 两阶段用户负荷数据增强方法
1.1 负荷缺失数据补全算法
由于用户负荷数据本身具有时序性(随时间上下波动)、周期性(以日、周、月为单位的周期重复)、空间相关性(同一类型的用户表现出相似的用电规律)等特性[17],在多维张量数据结构上定义的张量核范数与之具有强相关性,且规律性越强,张量核范数越小。因此,可充分利用多维度数据特征之间的相关性,实现缺失数据的高精度补全。基于LRTC的补全模型如式(1)所示:
(1)
式中:X和M分别为待补全负荷张量和原负荷张量;Ω表示未缺失元素的集合;PΩ(·)表示采样操作符,当张量元素属于Ω时保持不变,否则将元素值置为0;=·=TNN表示张量核范数。
引入辅助变量Z=X,可构造增广拉格朗日函数:
L(X,Z,Q)=‖Z‖TNN+lΩ(X)+
(2)
式中:Q为拉格朗日乘子;β为平衡参数;指示函数lΩ(·)只有在元素属于Ω并且该元素值和M对应位置的元素值相等才为0,其他情况都为无穷大;〈·〉表示张量内积; ‖·‖F表示张量F范数。根据交替方向乘子法框架[18],X、Z、Q可被交替优化求解:
(3)
(4)
Qk+1=Qk+β(Xk+1-Zk+1)
(5)
式中:k为迭代次数;Y为实际数据集组成的观察张量;X:Y=PΩ(X)通过等式约束使得X满足未缺失元素值和实际观察值一致。
通过不断求解待补全负荷张量X、辅助张量Z以及拉格朗日乘子Q,最后当X不再变化时,这时可认为X张量核范数已达到最小,最终恢复出缺失位置的负荷数据。
1.2 负荷样本类别平衡算法
负荷类别不平衡是指用户用电行为差异化、个性化所引起的负荷形态特征多样化,但各种典型用电模式中样本数目差异较大,导致分类器具有偏向性,其决策边界对于多数类样本过于宽松,对于少数类样本过于严格,因而在多数类上精确率偏低,在少数类上召回率偏低。
生成对抗网络(generation adversarial network,GAN)的主要思想在于生成器(generator)和判别器(discriminator)的对抗博弈[19]。生成器从随机噪声中采样,试图在隐变量空间和真实样本空间建立映射关系,最终输出维度同真实样本一致的生成样本;判别器负责判断输入是否来自于真实样本X或者生成样本,输出为介于0和1之间的概率值。在相互对抗学习中,生成器生成的样本质量逐渐提升,判别器难以鉴定真伪,最终达到纳什均衡。GAN的原理如图1所示。
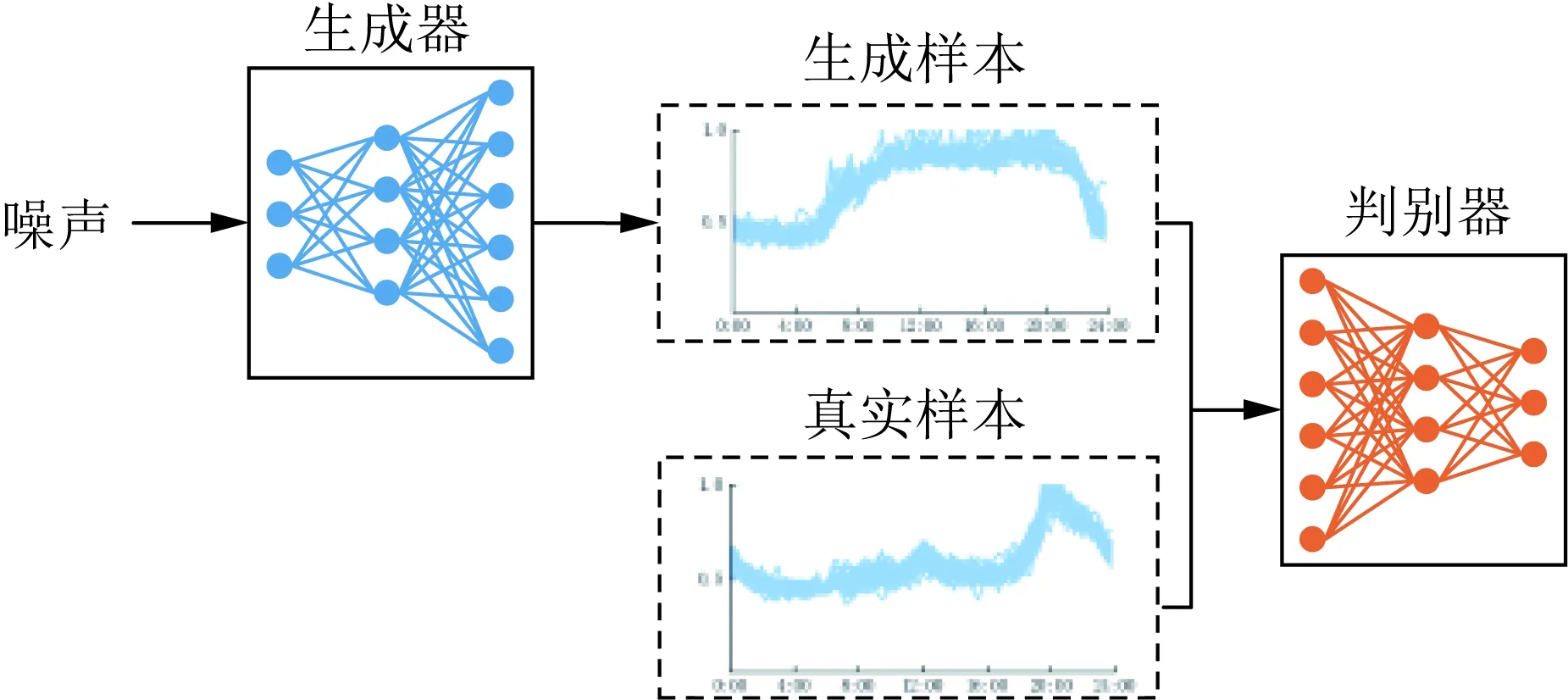
图1 GAN原理Fig.1 Schematic diagram of GAN
通过引入Wasserstein距离代替JS散度(Jensen-Shannon divergence),避免传统GAN训练过程中的模式坍塌、梯度消失等问题[20]。加入梯度惩罚项的判别器损失函数如式(6)所示:

(6)
式中:E(·)为数学期望;D(x)表示判别器判定为真的概率;-λEx~Py(·)为梯度惩罚项;λ表示正则化因子;Py指介于真实分布Pr和生成分布Pg之间的惩罚分布;‖·‖P为P范数;∇xD(x)表示对x求导。
通过文献调研以及多次实验,确定WGAN网络结构为:生成器使用4层全连接层,隐藏层神经元个数为128、256、128,激活函数为线性整流函数(rectified linear unit,ReLU),输出层大小与真实日负荷采样数一致,为96;判别器使用4层全连接层,隐藏层神经元个数选取为256、128、64,激活函数选取为ReLU,输出层神经元个数为1,不使用激活函数。
2 用户负荷曲线分类方法
传统时间卷积网络随着模型深度增加存在梯度消失、模型不稳定、收敛速度慢等问题;并且输入时间序列特征维度过长时,单向TCN存在记忆能力衰退的现象。因此,本文面向大规模用户负荷曲线分类,提出一种改进的双向深度残差TCN模型。引入WN方法将权重解耦为长度和方向的组合,有效加速模型收敛;使用带负值输出的ELU激活函数替换原有的ReLU激活函数,可减少偏移效应,降低计算量,避免梯度消失;使用残差连接层,可提高模型深度,稳定模型训练过程;在模型中添加Dropout技术,可有效避免模型过拟合;采用双向时序建模避免记忆衰退,可提取更多负荷微观波动特征。
2.1 典型时间卷积网络
时间卷积网络主要由因果卷积和空洞卷积两部分组成[9]。因果卷积只利用输入时刻之前的序列参与运算,而不涉及未来的数据信息,保证时序建模的因果性。空洞卷积允许卷积输入存在间隔采样,且层级越高空洞因子越大,因此卷积感受野随着层数呈指数级增长,以适应高维情况下的序列输入。典型的时间卷积网络如图2所示。
对于一维输入序列x和卷积核f,经过空洞卷积后的第i时刻隐藏层输出为:
(7)
式中:K为卷积核大小;d为空洞系数;f(j)为卷积核中的第j个元素;xi-d·j为对应卷积相乘的输入序列元素。

图2 时间卷积网络模型Fig.2 Temporal convolutional network
2.2 改进的时间卷积网络
本文使用WN方法[9]、ELU激活函数[21]、Dropout方法[22]以及残差连接[23]优化传统的TCN,得到如图3所示的深度残差TCN层(deep residual TCN, DR-TCN)。

图3 深度残差TCN层Fig.3 Deep residual blocks of TCN
2.2.1 WN方法
WN方法将神经元权重W重新解耦为长度m和方向V的乘积,以此加快收敛速度,稳定模型训练过程,如式(8)所示:
(8)
2.2.2 ELU激活函数
ELU表达式如式(9)所示。当输入大于0时,其线性输出可以有效缓解梯度消失;当输入小于0时,其指数负值输出使得输出均值尽可能接近于0,减少偏移效应,提高收敛速度。
(9)
式中:α为可调参数,控制ELU在负值部分的饱和程度。
2.2.3 残差连接
残差连接使得输入数据x跳过中间环节,与经过非线性变换后的特征F(x)相加求和,形成短路连接,如式(10)所示:
H=x+F(x)
(10)
这种结构既可以跨层传送信息,避免特征提取过程中的信息丢失,又可在模型深度增加的时候,抑制梯度消失,增强模型稳定性。
在时间序列问题的研究中,双向时序建模相较单向建模在特征捕获上更为精确[24]。对负荷序列进行正反时序双向建模能够综合提取曲线的上升下降细微变化趋势,更有利于提升负荷分类的精度。因此,本文采用Bi-DR-TCN对负荷序列进行正向和反向特征提取,网络整体结构如图4所示。

图4 Bi-DR-TCN模型Fig.4 Bi-DR-TCN model
2.3 用户负荷曲线分类流程
基于以上内容,用户用电负荷曲线分类流程如图5所示。
1)缺失补全:对全体用户负荷数据构建三维观察张量,使用LRTC恢复缺失数据点,将补全后的日负荷数据作归一化处理。
2)类别平衡:将数据集分层抽样划分成训练集(训练模型)、验证集(寻找最优超参数)、测试集(测试模型效果)。使用WGAN学习训练集中判定为少数类的样本,并随机生成样本得到类别平衡的增强数据集。
3)负荷分类:将增强训练集输入到Bi-DR-TCN进行学习和训练,在验证集上测试各组超参数的效果,寻找卷积核大小、空洞因子、卷积层层数等最优超参数组合,并使用最优组合分类器在测试集上对负荷曲线进行分类,并对结果进行分析。
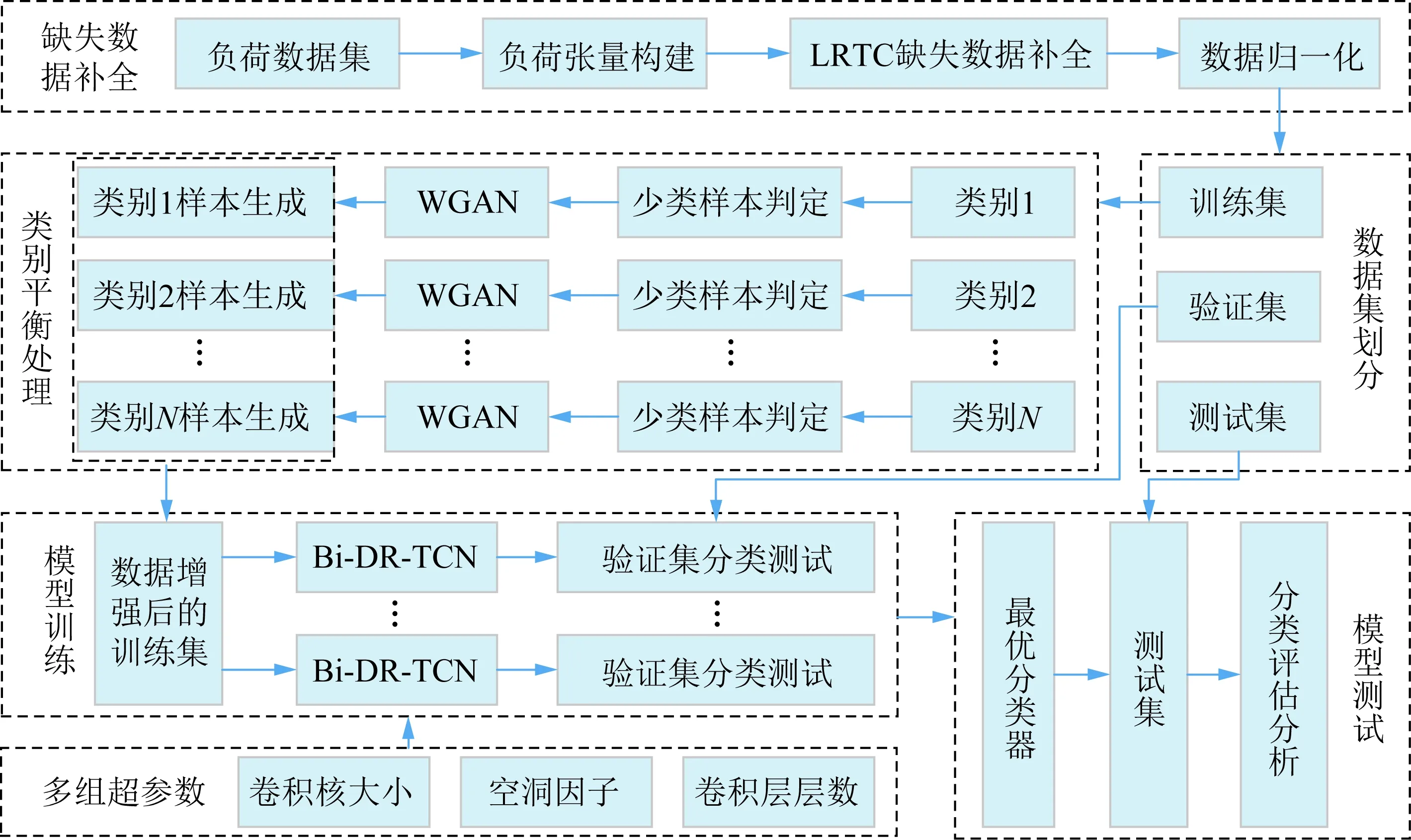
图5 负荷分类流程Fig.5 Load classification framework
3 算例分析
本文算例使用的计算机配置为Intel I5 2.2 GHz 处理器,16 GB内存,64位Windows10操作系统,在基于tensorflow 2.2,Python3.6的keras框架下搭建神经网络,缺失数据补全优化程序则在更擅长数值优化的matlab2015上实现。
算例数据使用UCR标准时序数据集[25]和UCI机器学习数据集[26]。UCR包含多个领域的时间序列基准数据集,是时序数据分类领域的标准数据集之一,本文选取与电力领域相关的IPD(Italy power demand)和PC(power consumption)数据集,论证所提负荷曲线分类方法Bi-DR-TCN的有效性,其基本信息如表1所示。

表1 UCR数据集参数Table 1 Parameters of UCR data set
实际用户用电数据来源于UCI负荷数据集ED(ElectricityLoadDiagrams20112014),选取从2014年9月16日到2014年11月14日共计60天的时间序列负荷作为数据集,其中用户数为321,每日采样点数为96,日负荷标签类别为5类,由多种典型聚类方法多数投票得到[16]。
3.1 IPD和PC分类实验
为验证本文所提Bi-DR-TCN分类模型的有效性,对比传统TCN、LSTM以及门控循环单元(gate recurrent unit,GRU)三种深度学习模型的分类精度与收敛效率,实验结果如表2所示。
如表2所示,与传统的TCN、LSTM、GRU网络相比,本文所提Bi-DR-TCN分类模型在IPD数据集上分类准确率分别提高0.58个百分点、2.71个百分点、1.35个百分点,迭代次数分别减少188、73、142次;在PC数据集上分类准确率分别提高1.11个百分点、2.78个百分点、5.56个百分点,迭代次数分别减少8、155、63次;平均分类正确率分别提高0.84个百分点、2.74个百分点、3.46个百分点,平均迭代次数降低了98、68、56次,说明本文所提方法在对时序数据分类时有更优的分类辨识能力和更少的迭代次数。
图6是Bi-DR-TCN和TCN在训练过程中的平均误差收敛情况。相比TCN,本文所提方法在第一个训练周期的损失函数误差降低61%,而且在相同迭代次数下拥有更低的训练误差,说明双向序列建模在一次迭代过程中能获取到更丰富的细节特征,从而加速模型收敛。

图6 训练迭代对比Fig.6 Comparison of training iterations
3.2 ED分类实验
通过在实测负荷数据集进行分类实验,验证所提用户用电负荷曲线分类框架的实用性,以及缺失数据补全算法LRTC和生成式模型WGAN的有效性。
3.2.1 缺失数据补全
上述UCR得到的负荷数据集不存在数据缺失。因此,为了模拟现实中负荷数据缺失现象,这里将负荷数据随机缺失40%,实际中数据丢失一般不会超过该数值。
不同的张量构建方法往往对补全性能有很大的影响。经过多次实验,本文构建的三维张量各个维度分别为:用户数、天数以及一天采样的数目。最大迭代次数设为1 000,β设置为1。由于三维数据补全效果无法直观展示,这里固定用户维度,选取补全张量的某个横切面来说明LRTC的有效性。某用户的缺失补全热力图如图7所示,其中图7(a)、(b)和(c)分别为原图、缺失图(图中深蓝色为缺失)和补全图。
由图7(a)和图7(c)可知,原图和补全图整体上高度一致,说明LRTC能捕捉到用户用电整体趋势。分析图7(c),该用户在早上7点工作日用电水平较高(图中深红色部分)而周末用电水平较低(图中青色部分),在下午时段工作日用电水平较低(图中黄色部分)而周末用电水平较高(图中红色部分),表现出2种用电模式。而且随着天数增加,用电量总体呈现下降趋势(图中红色区域变淡)。以上规律在原图、补全图均有体现,说明LRTC可充分利用负荷数据之间的时空关联性实现缺失数据的高精度补全,进而提高后续负荷分类的效果。

图7 缺失补全对比Fig.7 Comparison between missing and completion
3.2.2 类别平衡处理
在将负荷数据集进行缺失补全以及归一化之后,按照1∶1∶8的比例将负荷数据集划分为训练集、验证集、测试集。其中训练集5个类别的样本数量分别为927、375、71、80、206。当WGAN达到纳什均衡时,此时使用生成器从高斯噪声中随机抽样生成样本。为避免生成样本太多淹没真实样本,只对类别2、类别3、类别4、类别5扩充样本数量至类别1规模的一半。通过对比生成样本与原始样本的差异来判断WGAN样本生成的效果。以类3为例,生成样本和原始样本的展示如图8所示,图中黑色、橙色曲线分别为生成样本、原始样本均值中心。
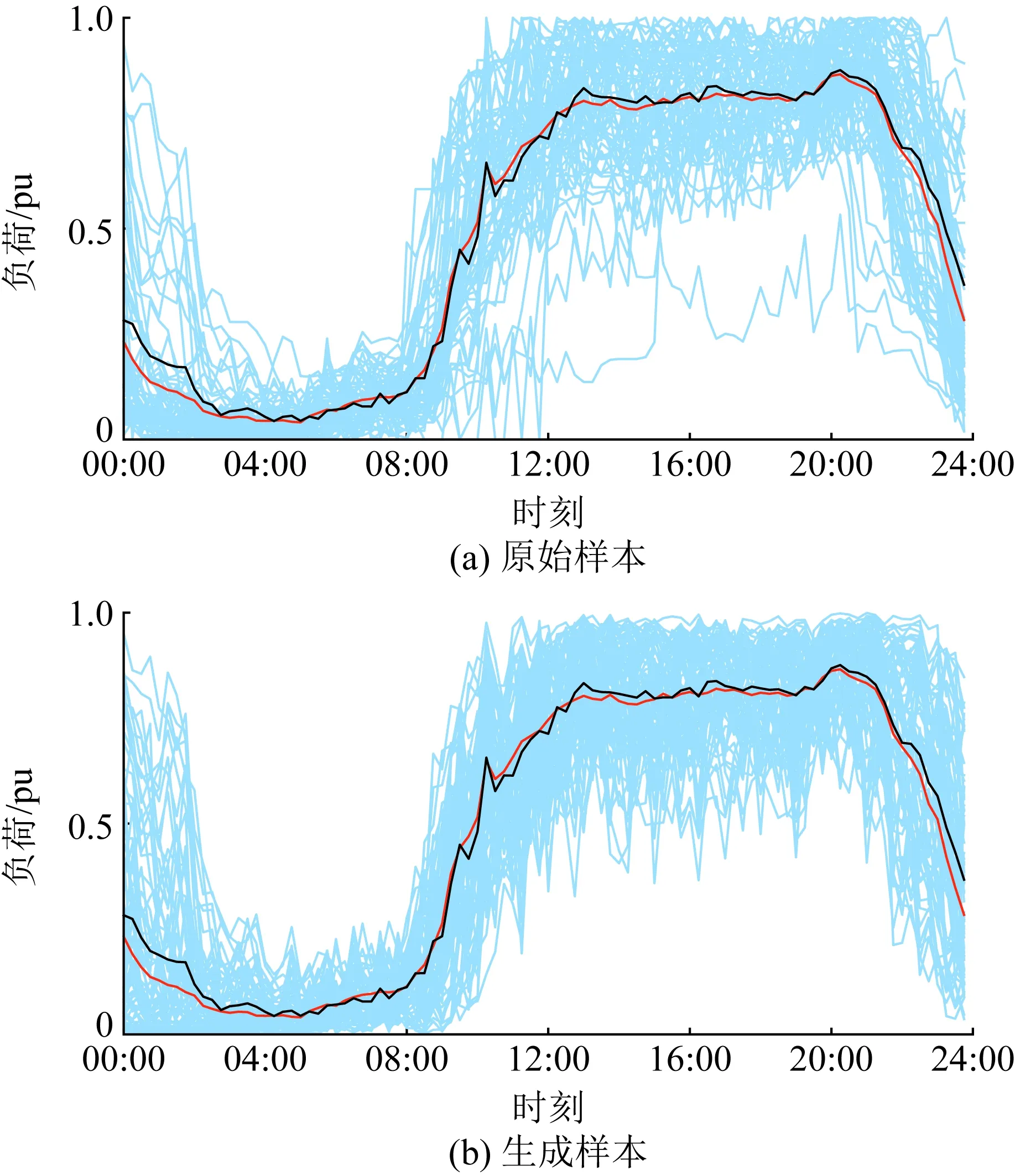
图8 生成样本与原始样本对比Fig.8 Comparison between synthetic and real samples
由图8可知,生成样本和原始样本的分布基本一致,但生成样本之间以及生成样本与原始样本存在一定的差异,说明WGAN能通过神经网络之间的对抗博弈建立起从隐空间高斯分布到原始数据真实分布的映射,生成符合原始样本数据分布特性的高质量样本。同时,相比原始样本,生成的样本在不同时刻存在一定的细微波动,避免了生成数据的同质化,能有效增强数据样本多样性,提高分类器的泛化能力。
3.2.3 负荷分类实验
将上述生成样本加入到训练集中平衡类别,使用增强训练集对Bi-DR-TCN进行训练,并在验证集上测试得到的最优超参数组合如下:Bi-DR-TCN卷积层层数为4,卷积核大小为12,卷积核个数为16,空洞因子设为1、2、4、8,Dropout为0.05,批大小为64,时间步为96,特征数为1,损失函数为交叉熵,优化器为Adam。负荷分类结果如图9所示。

图9 负荷分类结果Fig.9 Load classification results
由负荷均值曲线说明本文方法能有效辨识不同用电特性的负荷。类别1从早上10点到晚上8点用电水平较高,属于工作日负荷;类别2在晚上8点左右存在用电高峰,持续时间较短;类别3从凌晨4点开始到晚上8点用电水平不断攀升,晚上8点以后迅速下降,属于单调型;类别4与类别1相似,但其用电高峰期较短;类别5用电量比较平稳,维持在某一水平上下,属于平稳型。有效区分以上5种用户用电模式,可以促进用户参与需求响应,减少用电峰谷差,提升经济效益。
3.2.4 数据增强有效性
为验证数据增强对于负荷分类结果的影响,对比有无缺失数据补全,有无类别平衡等4种情况的分类效果,各个类别的分类精度如表3所示。
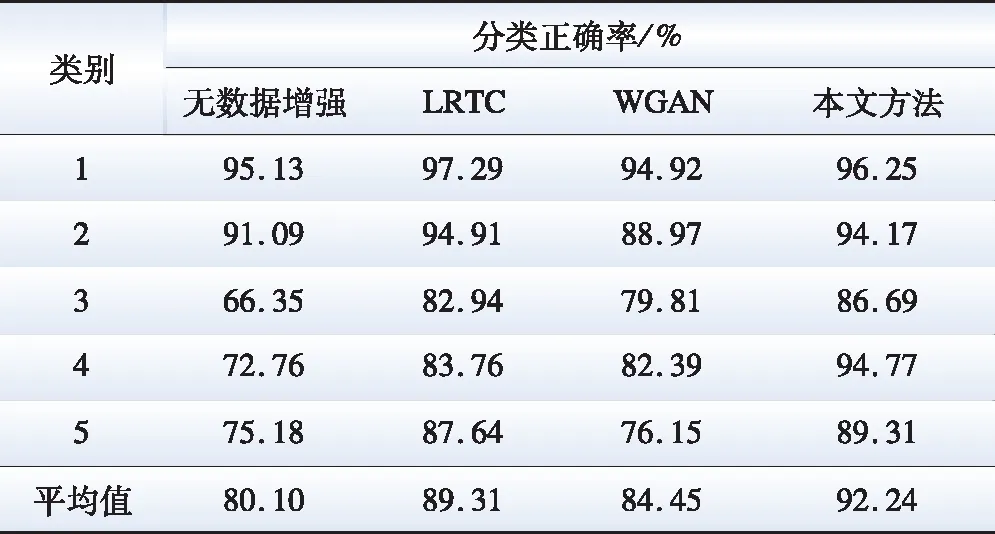
表3 不同数据增强方法效果对比Table 3 Comparison of different data enhancement methods
对比表3,相比无数据增强,采用LRTC进行缺失数据补全后,各个类别分类精度分别提高12.4%、11%、16.5%、3.82%、2.16%,平均精度提升9.21%,说明缺失数据补全模块能整体提高后续负荷的辨识精度。相比无数据增强,采用WGAN进行类别平衡后,分类精度较差的类别5、类别4、类别3分别提升0.97%、9.63%、13.46%,类别2、类别1分类精度有所下降,整体分类精度提高4.35%,说明采用WGAN进行类别平衡能改善分类器的偏向性,大幅提升少数类的分类精度,虽然存在多数类分类精度轻微下降的现象,但对整体的分类辨识能力仍有增益作用。对比无处理、只进行缺失补全、只进行类别平衡,两阶段数据增强拥有最高的分类精度,说明缺失数据补全与类别平衡相结合对提升负荷曲线分类模型辨识效果有积极的作用。此外,本文方法在各个类别都拥有较高的分类精度,说明本文所提负荷曲线分类框架具有一定的实用性。
4 结 论
本文针对电力用户负荷中存在的数据缺失、类别不平衡问题以及分类模型性能缺陷,提出一种基于两阶段数据增强和Bi-DR-TCN的用户负荷曲线分类方法,首先采用LRTC处理缺失数据,其次利用WGAN平衡数据集,最后训练Bi-DR-TCN实现用户负荷曲线的高效精准分类。
算例表明,LRTC能有效应用于配网侧采集得到的用户负荷数据,实现缺失数据高精度补全;经过对抗学习训练后的WGAN,能够生成近似满足样本真实分布的高质量样本,实现负荷样本类别平衡;与LSTM、GRU相比,所提Bi-DR-TCN分类模型具有更快的收敛速度和更高的分类精度,能实现对负荷曲线的精准分类。
后续研究将致力于在Hadoop、Spark等大数据计算平台上分布式并行化所提方法,提升算法对于海量数据的处理效率。
猜你喜欢
西南师范大学学报(自然科学版)(2022年1期)2022-03-02
陶瓷学报(2021年4期)2021-10-14
华南师范大学学报(自然科学版)(2021年3期)2021-07-03
中学生数理化·中考版(2020年12期)2021-01-18
五邑大学学报(自然科学版)(2020年4期)2020-12-09
少儿画王(3-6岁)(2020年4期)2020-09-13
杭州电子科技大学学报(自然科学版)(2020年1期)2020-04-09
活力(2019年15期)2019-09-25
小学生必读(中年级版)(2018年10期)2019-01-04
消费导刊(2018年8期)2018-05-25
