
基于关联规则的作战数据质量校验方法研究
2022-02-17 12:11:24姚鹏飞
电子设计工程 2022年3期
姚鹏飞
(92493 部队,辽宁 葫芦岛 125000)
作战数据是维系作战指挥信息系统的“血液”,作战数据质量的高低直接影响系统的发挥效率[1]。作战数据根据属性划分,主要包括作战基础数据、动态数据和指挥决策数据,近年来,随着作战相关任务量的持续增加和信息化手段的不断提升,基于这3种数据类型上设计的各类作战数据信息系统也日益增多,这些数据对于首长机关指挥决策、部队遂行各类军事任务、信息化装备效能发挥起着重要的支撑作用[2],数据的正确性、一致性、完整性、可靠性要求越来越高。目前,各类信息系统数据的数据质量检查主要依靠人工判查和内置的数据检验规则来完成,能够实现对系统中单个数据项完整性、正确性的约束检查,但对于存在关联关系的数据项之间的一致性约束检查还不够完善。
针对现有作战数据信息系统有关联关系数据项所存在的问题特点,在梳理分析影响数据质量因素和现有方法不足的基础上,通过引入关联规则挖掘方法,使用FP-tree 挖掘数据库中的2-频繁数据项,获取数据项之间的有效关联关系,以此来检测人工填报数据可能出现的错误。通过与信息系统中现有的审核规则相结合,可以弥补人工判查存在的不足,有效提高了数据质量。
1 数据质量
1.1 数据质量维度
数据作为信息系统产生的产品,像产品一样进行管理,需要质量保证[3]。通常,数据质量问题可分为4 类,即单数据源模式层问题、单数据源实例层问题、多数据源模式层问题以及多数据源实例层问题[4]。在基于人工录入的信息系统中,数据质量的主要问题可以归结为单数据源实例层问题,典型的表现形式是拼写错误、相似重复记录和互相矛盾的字段。数据质量维度通常采用4 个指标进行衡量,即数据一致性、数据正确性、数据完整性和数据可靠性[5-6]。
数据一致性:主要是指数据或数据项之间的逻辑关系是否正确,是否存在前后矛盾。
数据正确性:准确性是对数据内容正确性的测量标准,如数据的取值是否有意义,是否在合理范围内。
数据完整性:完整性是对数据的存在性、有效性、结构、内容和其他基本特征的测量标准,如填充率、有效性、范围、最大值和最小值等。
数据可靠性:数据内容是否能够正确反映客观事实。
1.2 目前常用检查方法
在作战数据信息系统中,目前常用的数据质量检查主要包括人工检查法、基于规则库的检查方法两种。人工检查方法主要是通过人工逐项分析比对数据项,或通过生成各类数据报表、数据图展示等数据可视化方式,查找数据填报过程中存在的明显错误。基于规则库的检查方法主要是通过基于SQL 语言,制定一系列数据校验规则,筛选错误项。人工检查方式在数据量较大时效率低下,不满足数据实时性处理要求,基于规则库的检查方法可以快速完成数据质量检查,但主要针对的是单个数据项的完整性检查,对于数据项之间的关联关系检查力度不够。
2 关联规则挖掘
2.1 基本概念
关联规则是数据挖掘领域广泛使用的方法之一,关联规则挖掘通常指的是从大量的数据集中挖掘到有价值的、可描述数据项之间关联关系的数据挖掘方法,对于存在关联关系的两个或多个数据项,可通过其中一项属性的值预测另一项或多个项属性的值[7-11]。关联规则挖掘主要包含两步,第一步设定最小支持度,找出关系数据库中所有大于等于最小支持度的数据项集,第二步是设定最小置信度,利用频繁项集生成关联规则,根据最小置信度进行关联规则选取,最后得到强关联规则[12-13]。
将数据库中不可再分割的数据单元称为项,用符号i表示,把i的集合记为I,称为项集,即I={i1,i2,i3,…,in},设T为事物数据库,T={t1,t2,t3,…,tn},每个事物ti(i=1,2,3,4,5,…,n) 包含的项集都是I的子集,记为ti⊆I,一个关联规则可表示为X→Y的蕴涵式,X⊂I,Y⊂I,并且X∩Y=Φ[14]。关联规则的支持度support和置信度confidence是度量关联规则的两个重要特征量。关联规则X→Y的支持度是指事物数据库中同时包含X和Y的交易数和所有交易数之比,记为support(X→Y)=support(X∪Y)=P(XY),置信度是指交易包含X和Y的交易数与包含X的交易数之比,记为confidence=满足最小支持度阈值和最小置信度阈值的规则称为强规则[15-16]。
2.2 常用算法
关联规则挖掘主要是挖掘数据内部繁项集,获取数据之间关联关系,在关联规则挖掘领域,常用的数据关联规则算法主要包括Apriori 算法、FP-Tree 算法等。Apriori 算法为数据关联规则挖掘经典算法,由R.Agrawal 等人在1993 年提出,其基本思想是通过对事物数据库的多次扫描来完成数据项集支持度的计算,发现频繁项集从而生成关联规则,采取一个层次顺序搜索的循环方法来实现频繁项集的挖掘[17]。第一次扫描数据库,得到频繁1-项集的集合L1,第K(K>1)次扫描首先利用第K-1 次扫描的结果LK-1来产生候选集K-项集的集合CK,然后在扫描的过程中确定CK的支持度。最后,在每次扫描结束时计算频繁K-项集的集合LK,算法在候选集K-项集CK为空时结束。存在的主要问题是需要多次对数据进行扫描,I/O 开销很大,运行效率较低[18-19]。FP-Tree算法是对传统Apriori 算法的改进,可以满足不同数据量的使用需求,采取将提供频繁项集的数据库数据压缩成一棵频繁模式树,但仍保留其中项集关联信息的分治策略,只需要对数据库进行两次扫描,算法运行效率较高,是当前应用最为广泛的关联关系挖掘算法。
3 基于关联规则挖掘的错误数据检测过程
考虑到目前作战数据的量级、规模以及数据处理速度的要求,文中采用FP-Tree 算法实现对作战数据信息系统中关联数据项的挖掘,FP-Tree 算法是通过引入数据结构来临时存储数据,主要包括原始数据、FP-tree和节点链表,以此来减少I/O 开销,以表1 所示的关系型数据库为例,完成FP-Tree 构建。
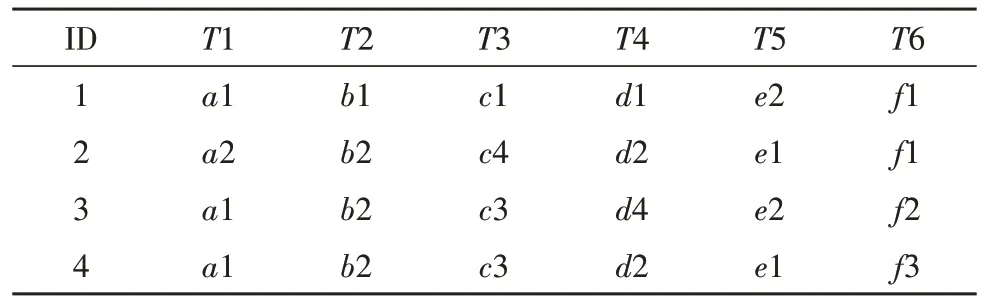
表1 数据库示例
3.1 建立项头表
通过扫描数据库建立项头表,删除支持度小于10%的数据,并对数据进行排序,项头表建立过程如图1 所示。
3.2 建立FP-tree
根据项头表和排序后的数据库数据进行FP-tree的建立。第一步是为FP-tree 建立根节点,记为null,第二步是将排序后的数据依次插入FP-tree的树结构中。若添加的节点已经在FP-tree 中出现,则更新该节点的支持度数值,对于新节点,项头表对应的节点会通过节点链表引入新节点,直至所有数据插入完成,从而完成树的建立。树的建立过程如图1所示。
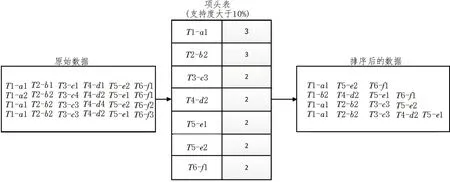
图1 项头表建立过程
3.3 挖掘FP-tree频繁项集
建立FP-tree和项头表后,从项头表底部依次向上挖掘,构造条件模式基,把挖掘的节点作为叶子节点所对应的FP-tree 子树,将子树中每个节点的的计数设置为叶子节点的计数,并删除计数低于支持度的节点,通过递归算法完成挖掘过程。
对于两数据项之间的关联关系,找到只包含两数据项的集合,即2-频繁项,对图2 所示的FP-tree进行挖掘,以T6-f1 节点为例,挖掘到的部分2-频繁项集为{T2-b2:1,T6-f1:1},{T4-d2:1,T6-f1:1},{T5-e1:1,T6-f1:1}。同样以T6-f1 节点为例,挖掘到的部分关联关系如表2 所示。
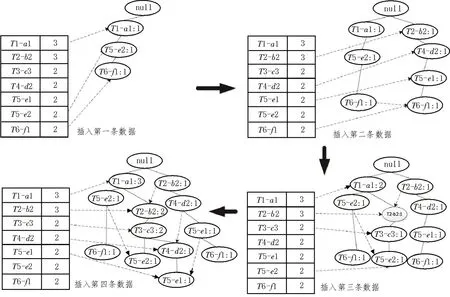
图2 FP-tree建立过程
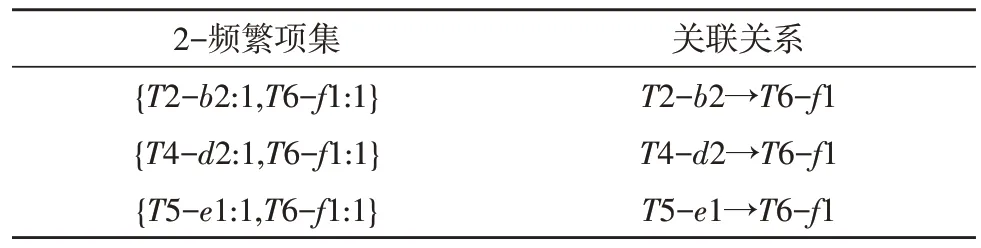
表2 挖掘到的2-频繁项集
3.4 数据错误检测
在作战数据信息系统中,数据经过各单位初审以及系统自带的校验工具审核后,数据的错误并非是大概率发生的,且一些数据项之间存在着本质关联。通过FP-tree 构建及关联规则挖掘后,若存在关联关系的数据项相应指标之间置信度低于设定阈值,可视为数据填报错误。
例如关键岗位人员信息表中,职务级别和军衔之间的关联程度较高,若计算后置信度低于阈值,可视为填报错误。
4 实例验证
4.1 数据准备
以某单位关键岗位人员信息表为例,共涉及552条数据记录,5 个数据指标,相应字段的编码、范围、含义如表3 所示。

表3 关键岗位人员信息表各字段含义及编码含义
4.2 有效关联规则挖掘
基于关联规则实现错误检测的算法步骤:
1)读入数据,筛选存在一定关联关系的数据项,并将其转换为二维数组类型;
2)通过FP-tree 算法,产生2-频繁项集合;
3)对于每一个频繁项集,构造所有可能的关联规则,然后计算每一个关联规则置信度,输出置信度小于阈值的有效关联规则;
4)对生成的有效关联规则进行人工判别,剔除明显错误的关联规则;
5)根据关联规则,筛选出可能填报错误的数据项。
4.3 实验结果
表4 中包含的规则如下:
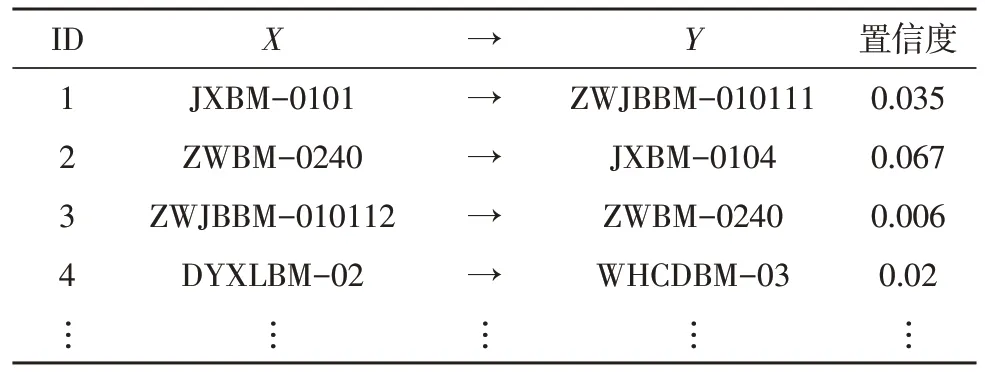
表4 有效关联(阈值=0.07)
规则1:存在军衔为大校、职务级别为正团职的人员,对生成的4 条数据记录进行检查,得到结果:1)两名军衔为大校的人员,职务级别误填为正团职,属于填报错误;2)另外两名军衔为大校的人员,职务级别填为正团职,经过核实,这两名人员兼有技术职务,属于正确填报。
规则2:存在职务为处长但军衔为少校的人员,对生成的两条数据记录进行检查,得到结果:两名处长军衔填报错误,属错误填报。
规则3:存在职务级别为副团、职务为处长的人员,对生成的一条数据记录进行检查,得到结果:一名职务级别为副团职人员的职务信息误填为处长,属错误填报。
规则4:存在第一学历为博士研究生但文化程度为硕士研究生的人员,对生成的两条数据记录进行检查,得到结果:两名第一学历为博士研究生的人员,文化程度误填为硕士研究生。
5 结论
通过选取存在关联关系的数据项,设置置信度小于阈值的筛选条件,可生成能够有效检测错误的关联规则,从而能够筛选出可能出错的数据项。但是针对生成的关联规则,还需要结合实际情况进行筛选,而不能直接进行应用。后续的工作中还需要考虑不同阈值下的关联规则生成情况和实验验证结果,使其阈值取值更为合理,从而使该方法具备更强的通用性和可操作性。综合理论分析和实验结果可知,该方法在设定的阈值条件下可以筛选出可能填报错误的数据项,一定程度上能够提高数据审核效率,弥补现阶段人工逐项核对和基于规则库进行数据审查方法所存在的不足,可作为作战数据信息系统质量审查的一个补充方法。
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
甘肃科技(2020年19期)2020-03-11 09:42:42
计算机与生活(2019年11期)2019-11-12 05:41:02
科技与创新(2019年14期)2019-08-12 12:55:20
计算机应用(2018年5期)2018-07-25 07:41:26
轴承(2015年2期)2015-07-25 03:51:04
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
计算机工程与设计(2011年7期)2011-09-07 10:16:42
电讯技术(2011年11期)2011-04-02 14:00:37
