
基于AIA和PNN的路基健康监测
2022-02-17 12:11:30成兴保程永强张博
电子设计工程 2022年3期
成兴保,程永强,张博
(太原理工大学信息与计算机学院,山西晋中 030600)
我国高速公路建设工作的稳定推进,通车里程数逐年递增,截止到2018 年底,中国高速公路总里程已达14 万千米,位居全球第一,投资总额超过10 万亿元。高速公路给人们的出行带来了极大的便利,但每年高速公路由于路基的塌陷,路面的破损等原因也给人们的生命安全和交通出行带来了极大的威胁,给国家造成了巨大的财产损失。因此,加强道路路基健康监测和预警有很重要的工程实用意义,对于我国建设智能化高速交通系统也有重要意义[1]。
公路路基的病害具有很强的隐蔽性,及时检测到这些病害并且采取合适的应对措施可以延长公路的使用寿命[2],目前对于公路路基病害的识别主要是基于探地雷达(GPR)检测技术、光纤传感技术、超声波检测技术、频谱分析技术、图像检测技术等5 种技术采集信号和数据[3-4],然后结合不同的数据处理方法,例如尺度不变特征变换算法、级联卷积神经网络、SVM(支持向量机)和浅层神经网络等,对数据进行处理得到病害的位置及原因[5-6]。
上述算法在一些方面实现了对公路路基损害的识别与定位,但依旧存在一些问题:1)无损检测的技术对于专业性要求较高,且易受周围环境因素的影响;2)识别算法稳定性和准确性还需要继续提高;3)现有办法还需要根据技术人员和专家的经验来辅助分析异常数据对应路基损害的原因[7-8]。因此,开发一种实效性强、准确度高的路基病害自动识别系统对于路基健康运行有重要的意义。
随着机器学习的发展,人工免疫和神经网络等仿生学算法在目标识别和故障检测领域中逐渐受到重视[9]。人工免疫算法(AIA)是受免疫系统启发设计的算法,相比需要时间连续性或者大量正常和异常特征信号的异常检测方法,人体免疫系统仅仅依赖对正常状态的经验积累,减少了对异常特征信号的收集,就可以实现正常和异常数据的分类[10-11]。概率神经网络(PNN)是建立贝叶斯分类和Parzen 窗法上的一种并行算法,常收敛于最优解,具有较高的稳定性、诊断准确率和效率[12]。
文中首先基于嵌入式传感技术采集公路的五项静态数据,该技术成本更低,操作简单,实效性更强,然后利用AIA-PNN的组合模型对路基健康监测系统采集到的实时压力、沉降、应变、温度、湿度等信号进行分析处理,得到该数据对应公路路基病害的检测结果,并与BP 神经网络(BPNN)和最小二乘支持向量机(LS-SVM)的准确率进行对比,以期提高现有路基检测的效率和准确性。
1 路基健康监测系统
路基健康监测系统由多通道传感采集节点、数据处理中心、后台检测中心3 部分组成,实物机箱如图1 所示。

图1 系统机箱实物图
传感采集节点包含压力传感器、应变传感器、单点沉降计和温湿度传感器这4 类传感采集装置,其主要功能是在接收采集指令以后,将采集到的实时路基数据通过RS485 总线传递给数据处理中心;数据处理中心采用Cortex-M3 内核的STM32F103 系列芯片作为控制核心,围绕该芯片设计最小系统所需的外围电路,其主要功能是将传感采集中心采集到的原始数据用ARM 处理器进行简单转换处理后存储在SD 卡中,方便查询历史数据,并通过终端LCD显示屏,直观显示实时数据,同时把数据通过有线或者无线的方法发送到后台监测中心,进行进一步分析处理;后台监测中心可实现进行数据的远程接收,应用相关处理数据的算法和软件对数据进行解析处理,并自动备份在数据库和云端,如果检测到异常值,发出预警信号,并向终端发出相关指令,实现路基的安全监测。路基健康监测系统结构框架如图2 所示。

图2 路基健康监测系统结构框架
路基健康监测系统可采集到5 种不同的路基静态数据,分别为压力信号、沉降信号、应变信号、温度信号、湿度信号,文中主要针对性地研究了沉降信号和应变信号。这两种数据有以下特点:数据自身只有大小和量纲,无正常或者异常的数据标签;数据采集以外部指令来执行,并无固定采集周期;由于野外太阳能供电的不稳定,数据传输有时会出现漏报。
2 基于人工免疫算法的异常检测
2.1 人工免疫系统
免疫系统的核心功能之一是区别“自己”与“非己”物质,免疫系统的这个核心机制常被应用在异常检测方面,异常泛指对偏离各类系统自身规定的正常状态的现象和行为,包含故障和错误情况监测、异样诊断、异常变化等[13]。利用仿生学的概念,目前检测异常的算法有克隆选择算法、阴性选择算法,树突状细胞算法等,由于美国计算机安全专家Forrest 等提出的阴性选择算法的核心思想是利用有限的“自己”样本集合生成“非己”样本集合,通过反向思维来检测数据异常与否,有效解决了故障样本匮乏难以实现故障检测的问题[14],为此,文中选择阴性选择算法作为该二分类问题的判断标准,免疫应答机制的实现过程有如下步骤:
1)学习和抗体库的形成。首先给系统定义部分“自己”信息,构成学习样本的数据集,然后利用阴性选择算法产生一个检测器集,使检测器集与学习样本数据集中的数据都不匹配,尽量多覆盖“非己”空间的检测器集即生成的抗体库。抗体库的建立流程如图3所示。

图3 抗体库的建立流程
2)异常数据的识别。将路基健康监测系统采集到的采集数据作为输入信息,与抗体库中的抗体进行匹配计算,如果被测数据与抗体库中任意一个抗体匹配,则表明该样本为“非己”数据,发出警报信号,并将该数据单独提取出来;反之,则为“自己”数据,存入正常数据的数据库。异常数据的检测流程如图4所示。

图4 异常数据的检测流程
3)故障类型的诊断。将“非己”信息输入抗体库进行聚类学习,并对故障类型进行人工标注,建立故障信息库,上一步检测到的异常数据通过概率神经网络算法,判断其属于故障库中的哪种故障,并相应的给出推荐解决方案。诊断过程与结果的操作流程如图5所示。

图5 诊断过程与结果的操作流程
2.2 基于人工免疫的数据检测算法
通过对采集数据的分析处理,获得数据变化规律,结合人工免疫系统的应答机制,实现对相应位置路基健康的监测和预警。
文中首先收集大量路基健康运行时的正常数据样本,然后对数据进行归一化处理,处理方法如式(1)所示,表1为部分正常数据归一化前后的样本数据。
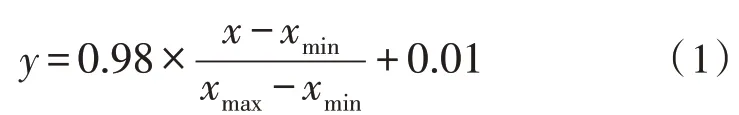
其中,y为归一化以后的数据,x为原始数据大小,xmax为原始数据中的最大值,xmin为原始数据中的最小值。
表1 可知,原始数据每个样本有5 个特征,分别对应沉降、温度、湿度、应变(ΔL/L×106)和压强,这样会形成一个五维空间,而阴性选择算法随着维度的增加,计算量明显增大,计算时间明显加长,因此,需要选取两个贡献率最大的主要成分,由经验得知,路基健康情况与沉降和应变关系最密切。
文中使用的数据分析软件为MATLABR2018b,计算机的主要配置为AMD(R)Core(4C+6G)A10-7300CPU@1.90 GHz,RAM4G,64 位Windows10操作系统。通过随机生成的范围在[0,1]之间的二维数据与正常数据的匹配程度来生成抗体库,匹配程度按照欧氏距离来计算,可以在平面坐标系中将“自己”数据和抗体库的值与半径结合起来表示为一个个平面圆,取“自己”数据和抗体库的半径均为0.01,分别画出抗体库内抗体数量n=100、200、300、400的抗体分布状态,如图6 所示,其中,整个平面坐标系代表系统空间,灰色平面圆代表“自己”数据,黑色平面圆代表抗体,余下部分为未被覆盖区域。
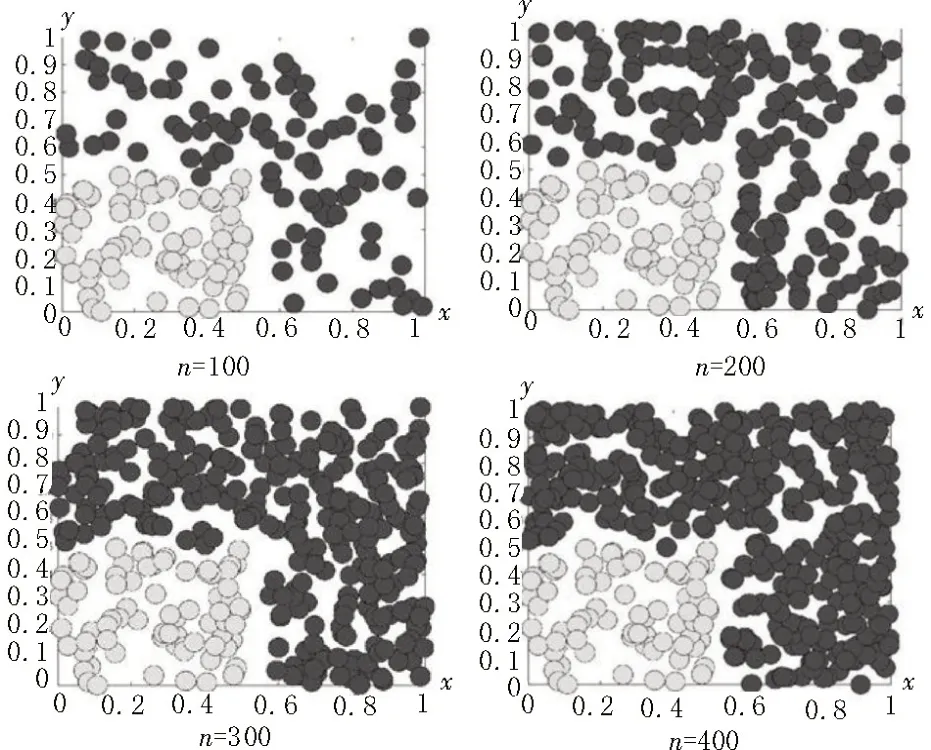
图6 抗体数量n在不同值时“自己”和抗体库的分布状态
由图6 可知,抗体库数量越多,未被覆盖的区域面积越小,但是抗体库如果过多,会造成重叠现象,并且计算时间会成倍增加,因此选取合适的抗体数量阈值,既可以保证在足够多覆盖率的前提下,也可以减少运算次数。文中选取的“自己”数据样本量为80 个,抗体库的样本量为300 个,符合上述条件。
匹配计算即抗原-抗体亲和力的计算,一般计算亲和力的公式为:

式中,tk是抗原和抗体k的结合强度,通常免疫算法中计算结合强度tk的数学工具有海明距离、Euclidean 距离、Manhattan 距离等,对于有限维线性空间可以引入各种各样的向量范数,向量范数的种类可无穷多,但是这些范数之间有重要的关系。因此结合实际,文中引入向量的p-范数,定义如下:

式中,‖α‖p是酉空间cn的向量范数,称为向量α的p-范数。
由于抗体库是二维向量,因此选取p=2 时的向量范数来表示抗体抗原之间的距离,将待测数据与抗体库进行匹配计算,落在“自己”区域内的样本为正常数据,落在抗体中的样本为异常数据,落在未覆盖区域内的样本为未被监测数据,单独输出,进行人工复检(覆盖率足够的情况下,这类数据可忽略不计)。
图7 为部分检测样本的分布情况,圆圈为“自己”数据,加号为抗体分布,星号为检测样本中的异常数据,乘号为检测样本中的正常数据,黑三角形号为未检测到的数据,检测了250组数据,只有一组未检测到,其余249组均正确,漏检率约为0.4%。

图7 部分检测样本的分布情况
检测到的正常数据输入正常数据统计库,异常数据输入异常数据统计库,不断的将测量数据加入数据库,并将不断更新抗体库,增加检测样本的正确性且降低漏检率,类似生物体中的抗体的记忆功能,对于同类型故障的应答时间更短,可以对故障信息更快速、更准确地作出判断,提高现有判断水平,在工程应用中的实用意义更高。
3 基于概率神经网络的路基故障诊断
3.1 构建神经网络
概率神经网络(Probabilistic Neural Networks,PNN)是一种结构简单、应用广泛的神经网络,由输入层、模式层、求和层和输出层共4 层组成,在模式分类中有广泛应用。收集历史故障数据和相对应的故障类型,采用无监督学习的聚类方式,形成故障数据库,用于建立概率神经网络[15]。
根据实际路基损坏常见情况,定义5 种路基损坏模式:滑坡与坡面损坏、崩塌与碎落、路基的不均匀沉降、路基水毁、路基裂缝,加上正常状态,共6 种分类模式,如表2 所示。

表2 路基损坏分类模式
收集路基正常和5 种故障模式下的传感器数据,得到沉降、温度、湿度、应变、压力的数据,形成一个5 维向量x=[x1,x2,x3,x4,x5]。每种分类模式的样本收集30 份,共计180 种训练样本,每种分类模式的前20 个序号的数据作为训练样本,后10 个序号的数据作为测试样本。
用于路基健康诊断的概率神经网络模型包含120 份输入样本,每个样本为5 维向量,分类模式为6种,建立的概率神经网络模型如图8 所示。

图8 概率神经网络模型
图8 中概率神经网络的输入层包含5 个神经突触,与输入特征向量的维数保持完全相同,模式层包含120 个神经突触,每个节点对应一种训练样本,求和层包含6 个神经突触,对应文中分好的6 种情况,在Matlab 中经过训练以后,输出对应的类别序号。
可以直接使用Matlab 中的newpnn 函数创建网络模型,并用tic/toc 命令记录创建模型所需的时间,newpnn 函数中唯一可调参数为平滑因子spread,在PNN 网络诊断时,诊断准确率主要与spread和训练样本的数量有关,样本数量与准确率之间的关系为正相关,spread 与准确率的关系为负相关,因此,样本数量越多、spread 越小、准确率越高[13]。文中选用的样本数目为120 个,spread=1。
3.2 测试数据
故障诊断流程如图9 所示,包含样本输入、样本归一化、创建神经网络模型、测试以及输出测试结果共5 步。

图9 故障诊断流程
将60组测试数据输入已经训练好的神经网络中,并且针对不同的故障类别,给出不同的处理意见,Type1 对应现场调查,生态防护措施、反压坡脚、抗滑桩等;Type2 对应、提醒来往车辆、爆破清理、锚点固定、钢丝网固定、岩石固定等;Type3 对应限制路上车速、现场调查形成原因、必要时重新夯实路基;Type4 对应检查原因、恢复植被、整治河流、关注汛期;Type5 对应表面修补法、注浆修补法、填充修补法等;Type6 对应注意日常维护和保养[16];其中部分测试结果在MATLAB 中输出如图10 所示。

图10 部分测试结果
所用训练网络时间为0.142 430 s,其中59组正确,一组错误,概率神经网络所作诊断的准确率高达98.3%,并且对于不同的故障类型,给出对应的诊断意见,可以对监测人员起到辅助决策的作用。
4 实验结果
为了对比分析AIA-PNN组合模型在处理实验数据分类上的性能,文中引入神经网络中的BP 神经网络和最小二乘支持向量机,对18组不同故障路基静态数据的测试样本分别使用BP 神经网络、最小二乘法支持向量机和文中设计的AIA-PNN 分析,测试结果如表3 所示。由表3 可知AIA-PNN的组合处理方法在处理实验数据的分类识别上,其准确率要高于常规的BP 神经网络及最小二乘法支持向量机,为数据的分类识别提供了新的分析方法和检测工具。且BPNN 方法、LS-SVM 方法、AIA-PNN 方法的成功率分别为72.2%、83.3%、94.4%。
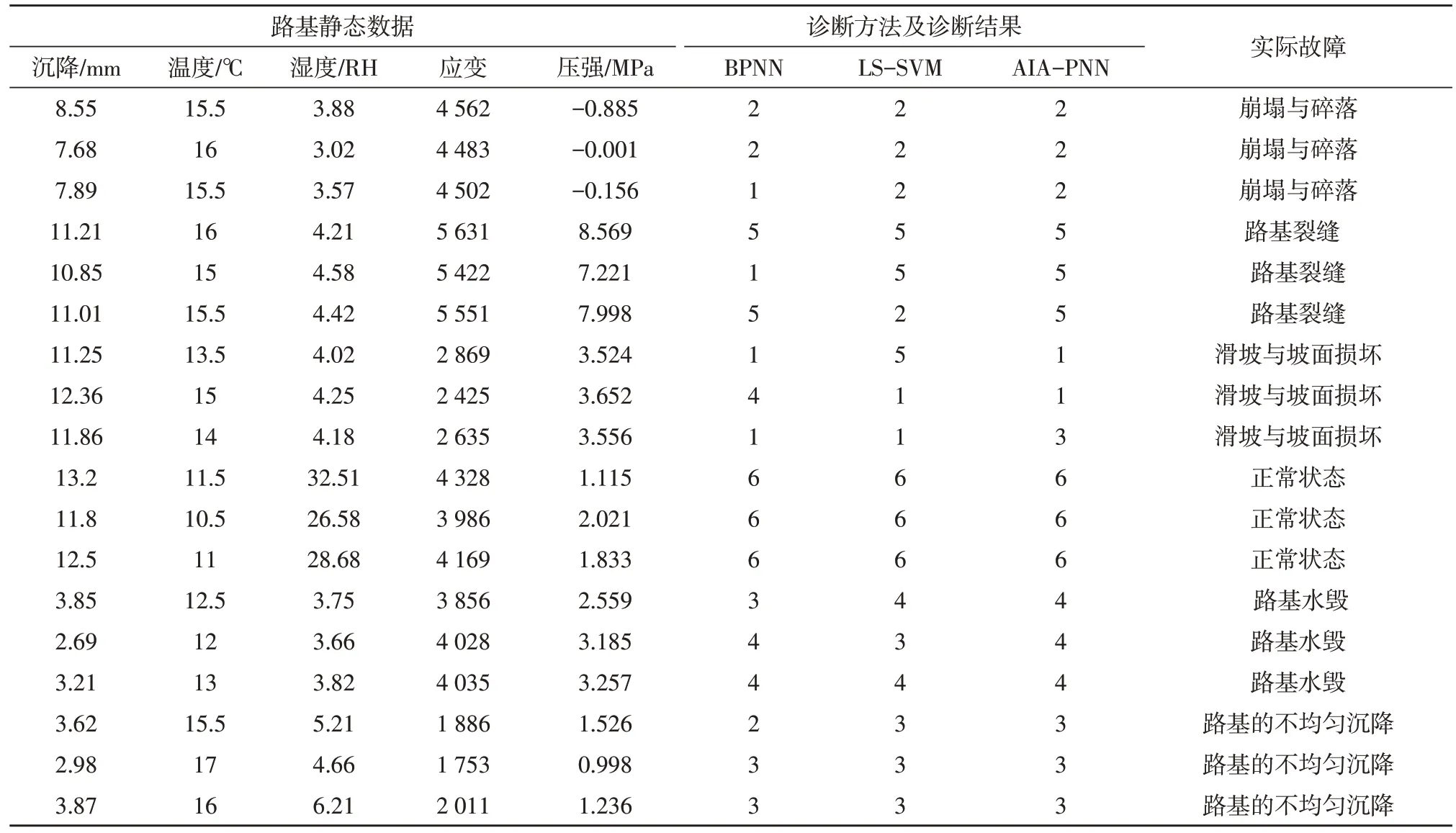
表3 路基静态数据测试样本算法测试结果
5 结论
文中通过人工免疫算法和概率神经网络算法对路基监测数据进行处理,将无标签的数据对应分类,基本可以实现预期目标,将异常数据和正常数据区分开,并且对异常数据可以做到细致具体的分类,对比BP 神经网络和最小二乘支持向量机有更高的准确率,对于每次分类和实际一致的数据,可以作为输入样本重新更新两个算法所需的数据库,基本可以实现数据的自我学习,扩展性比较好,对于不易获得异常数据的工程有很好的借鉴意义,再结合工程实际,给出处理建议,有很强的工程实用意义。
由于人工免疫算法、概率神经网络算法和概率神经网络都属于仿生智能算法,所以可以保证其收敛性,并且这两个算法对于异常值都比较敏感,但是其有效性是否具有统计学意义,还需要在大量不同路段上做进一步研究。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
建材发展导向(2022年3期)2022-04-19 12:51:50
建材发展导向(2021年6期)2021-06-09 05:57:06
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
电子制作(2019年19期)2019-11-23 08:42:00
中国公路(2017年14期)2017-09-26 11:51:51
中华建设(2017年1期)2017-06-07 02:56:14
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
重型机械(2016年1期)2016-03-01 03:42:04
新高考·高二数学(2015年11期)2015-12-23 18:17:44
