
基于视触数据融合的多模态细分类系统
2022-02-13 11:53郭睿华宋俊鹏王文旭杨琨
科学技术与工程 2022年36期
郭睿华, 宋俊鹏, 王文旭, 杨琨
(太原理工大学信息与计算机学院, 晋中030600)
随着全自动化时代的到来,机械臂已被应用到越来越多的场景,如航天、深潜、工业以及残障辅助等诸多领域[1-4]。在这些场景中,机械臂帮人们节省了大量的人力资源成本。但同时,人们对机械臂的要求也日益提高。
众多研究者基于机械臂的物体分拣开展研究。视觉技术结合机械臂的发展已经趋向于成熟,并在物体分类领域中已经有了非常不错的表现,将机器视觉技术应用于分拣领域可减少人工分拣工作量、降低分拣差错率,极大地提升工业生产效率,实现分拣作业的自动化和智能化[5]。Cheng等[6]针对传统的图像分类方法在工业环境中照明不均匀且存在遮挡的条件下表现不佳的问题设计了随机裁剪集成神经网络(resource constrained edge-neural networks, RCE-NN),该网络对于具有重叠部分的图像,将集成学习与随机裁剪相结合,最终在十类包括颜色相同但轮廓不同、以及不同颜色、形状和纹理的物体组成的数据集下进行了测试,分类准确率达到98.14%;Harel等[7]为实现机械臂在采摘过程中对甜椒成熟度进行分类,使用随机森林算法处理相机从多视点采集的甜椒的RGB-D图像,并在不同成熟度的红辣椒和黄辣椒上进行测试,分类准确率达到95%;Kaymak等[8]为使用四自由度树莓派机械手加相机完成对工作平台上的物体的分类,使用不同的局部特征匹配算法进行组合,最终使用尺度不变特征转换(scale invariant feature transform, SIFT)+SIFT的组合匹配算法对20个物体进行了测试,分类准确率达到了97%。Liong等[9]为了实现对特定类型小牛皮上的蜱咬缺陷进行识别,提出了一种执行皮革缺陷分类的自动机制,该机制通过手工制作边缘检测器和人工神经网络通过多个分类器(即决策树、支持向量机、最近邻分类器和集合分类器)对皮革上的缺陷进行识别,最终在2 500块400×400的皮革样片中获得了84%的分类准确率。但单一视觉的机械臂系统仍然存在着缺陷,这种系统过度的依赖于工作环境的光线强度,以及对于一些外观相近但实则分属不同的物体缺乏感知能力。
Fishel等[10]使用BioTac传感器对117种不同的材料进行分类,在具有精确控制接触力和牵引力的测试台设置中,针对牵引力,粗糙度和细度3个特征使用贝叶斯分类,准确率为达到了95.4%;Xu等[11]使用安装在Shadow Hand上的BioTac基于贝叶斯探索框架执行多个探索运动,针对10种不同的材料可以达到99%的分类精度;Omarali等[12]为了实现远程操作材料触觉分类,使用基于光纤的触觉和接近传感器的远程控制机器人操纵器来扫描远程环境中物体的表面,并采用随机森林、卷积神经和多模态卷积神经网络等机器学习技术进行材料分类,最后在5种不同材料上进行了测试,分类精度达到了90%;Zhang等[13]为了用安装触觉传感器的机械手实现对目标的准确分类,提出了一种新的模型,即将卷积神经网络和残差网络相结合,并优化了模型的卷积核、超参数和损失函数通过K均值聚类方法进一步提高目标分类的准确性,最终将分类效果最佳的目标的准确率提高到80.098%,将分类结果较好的3个类的准确率提高到92.72%。仅凭触觉实现对物体的分类面临着诸如传感器成本高,特征提取不全面等问题,从而存在着一定的局限性。
由此可见,实现一个具有优良性能的机械臂分拣系统显然不是一个轻松的工作。复杂的工作环境,各种各样的物品对于这项工作都是巨大的挑战。单一感官的机械臂分拣系统总是存在着各种各样的局限性,并不能胜任复杂的分类环境。因此研究者开展了多传感信息融合的相关研究。Watkins-Valls等[14]研究了机械臂在光线不足且物体存在部分遮挡的环境下的机械臂分类任务,通过构建三维卷积神经网络融合视觉与触觉信息对10个具有不同几何形状的物体进行分类,分类准确率达到95%比单一视觉的分类准确率提高了25%。Wang等[15]为了使机械臂能够识别3D物体的形状,提出了一种3D感知的新模型,该模型综合物体的视觉触觉信息,在对14种不同物体的测试中,物体形状3D复现的匹配准确率达到了91%。但这些研究都比较侧重于对物体形状的识别,触觉信息则作为视觉分析的辅助数据,当环境中出现外观相似但材质不同的物体时分类工作则会面临巨大的挑战。
为此,提出一种基于视觉-触觉数据融合的机械臂细分类系统。系统通过OpenCV进行目标定位并通过快速搜索随机树(rapid-exploration random tree,RRT)路径规划算法实现对物体的抓取进而获取触觉信息,利用双输入的卷积神经网络将两类不同种类的数据分别提取特征,最后在连接层进行融合,完成综合物体视觉触觉信息的分类任务。
1 系统构成
搭建系统开展算法验证。系统采用Kinova公司生产的JACO系列机械臂完成运动及抓取功能,同时依靠深度相机及压敏传感器实现目标的定位及触觉感知。系统结构如图1所示。
JACO2-j2n6s200机械臂具有6个自由度,本体重量4.4 kg,负载能力为2.6 kg,最大臂展为984 mm,平均功耗为25 W。机械臂末端抓手为2指,抓手总重量为556 g,每个抓手都安装一个执行器,其抓取力为25 N,抓手打开或关闭的行程时间为1.2 s。

图1 系统结构图Fig.1 System structure diagram
视觉模块相机使用的是Intel RealSense Depth Camera D435i深度相机,相机被固定于机械臂的侧上方用于获取目标的距离信息以及获取用于模型预测的输入图像;物体定位模块使用OpenCV现对物体的目标检测和目标定位;运动规划模块分为两部分,一部分完成机械臂主体的运动规划,另一部分完成机械臂抓手的运动规划,采用机器人操作系统 (robot operating system, ROS)运动规划库结合目标检测的位置信息控制机械臂到达目标位置并进行抓取。
触觉模块将RP-C10-LT压敏传感器粘贴于机械臂手指用于获取抓取物体时的压力数据,RP-C电阻式压敏传感器具有静态/动态压力感应特性,响应速度快,耐久性寿命长等优点,随着压力增大,电阻呈现变小的趋势。整个实验系统场景设置如图2所示。

图2 实验场景示意图Fig.2 Overview of the experimental scene
2 机械臂目标定位与数据采集
2.1 目标定位
机械臂在运动时,需要依据视觉信息进行目标的定位,将相机坐标系下的物体转换到机械臂自身的坐标系下就显得尤为重要,相机与机械臂的结合有两种形式,一种为相机安装于机械臂上,一种为相机在机械臂外,为了获得更好的全局视野,采用相机固定在机械臂的外部(上方)的方式,如图3所示。

B为基底;E为末端执行器;P为标定靶;C为相机图3 相机标定示意图Fig.3 Schematic diagram of camera calibration

(1)

(2)

(3)
RARX=RXRD
(4)
RAtX+tA=RXtD+tX
(5)

(6)
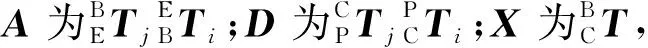
获取物体图像后,使用Canny边缘检测算子将相机捕获到的图像进行边缘处理,并寻找到物体在像素坐标系下的中心点,如图4所示。
根据式(6),像素坐标系与相机坐标系的转换关系可以得到物体在相机坐标系下的位置CQ。
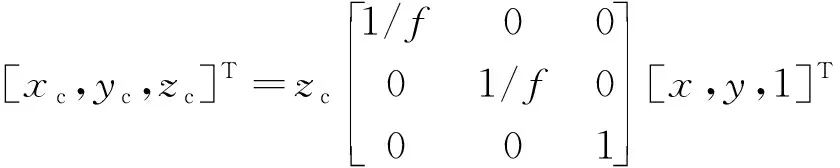
(7)
式(6)中:(x,y)为中心点的像素坐标;CQ(xc,yc,zc)为相机坐标系下的坐标;zc为深度值;f为相机的焦距。
由此获得物体中心在机械臂坐标系下的坐标BQ为
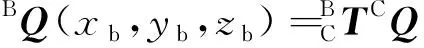
(8)

B为基底;E为末端执行器;P为标定靶;C为相机图4 提取图像的轮廓与中心点Fig.4 Extract the contour and center point of the image
2.2 机械臂运动规划
抓取物体时为增加抓取的稳定性,统一按照图5所示从物体上方进行抓取。
过程中使用增加了概率导向的RRT算法进行路径规划使机械臂运动到抓取点。相比于传统的RRT算法,增加了概率导向的RRT算法在路径寻找过程中的收敛速度更快。算法的伪代码如下。其中,M为机械臂工作的空间边界(包含障碍物位置信息),Ei为从qnear到qnew的连接边。

图5 机械臂抓取物体Fig.5 Robotic arm grabs objects

RRT-P(M, qinit, qgoal)1 T = {Ø};i=0;2 while (i 算法输入为工作空间M,机械臂起始状态qinit、机械臂目标状态qgoal。首先初始化路径T,Ø为空集;i为循环变量;N为算法终止门限值。采用ChooseTarget函数从起始状态开始依据概率P选择下一组机械臂关节状态qrand是朝向目标状态还是随机;运用Near函数从路径中选取最接近qrand的一点qnear;在Steer函数中,依据StepSize,向qrand进行移动得到新的一组关节状态qnew;使用Edge函数建立qnear到qnew的连接边Eedges;通过CollisionFree函数检测是否与环境发生碰撞,如果不发生碰撞则通过addNode和addEdge两个函数把qnew和Eedges加入路径集合T中。最后,通过AreaDectect函数检测qnew是否到达了qgoal的附近,误差区间半径为ε,如果返回TRUE则返回整条路径。采用ROS中的Rviz软件进行运动规划过程中各关节角度与角速度变化。 将压敏传感器集成于机械臂手爪上采集对不同物体抓取过程中的力的变化,采样频率为10 Hz。机械臂到达抓取点后开始记录压力数值,为使数据具有范围统一性,对物体进行恒速抓握,抓住物体后保持一秒间隔,然后松开。一次抓取中木质球,橡胶球,海绵球的典型压力曲线如图6所示。 为使图像更加平滑使用3次样条插值算法对压力曲线进行平滑处理,在每两个采样点中插入10个点。平滑后的曲线如图7所示。 图6 不同物品的抓取压力曲线Fig.6 Grasping pressure curves of different objects 图7 经平滑处理的压力曲线Fig.7 Smoothed rasping pressure curves 针对视觉数据与压力图像数据的特点设计了具有双输入的卷积神经网络模型,先对两类数据分别进行特征提取,然后通过全连接层进行连接进行同步学习,视觉触觉融合神经网络模型如图8所示。 视觉图像处理共包含4层卷积层与4层池化层,并在卷积层与池化层中间加入标准归一化层。卷积层的主要作用为提取输入视觉图像数据的特征信息,池化层采用最大池化主要作用为降低上层输入数据的数据规模以便于在最后用全连接层进行处理。 (1)输入层。输入图像为经过处理的224×224×3 的RGB图像。 (2)视觉模型第1层。用16个大小为3×3的卷积核对RGB图像进行same卷积,卷积后的特征矩阵大小为224×224×16,卷积完成后进行标准归一化处理并使用ReLU函数激活,然后进行2×2的最大池化,步长为2。池化后的特征矩阵大小为112×112×16。 Conv2d为二维卷积;ReLU为激活函数; MaxPooling为最大值池化; Flatten为展平; Fc为全连接; Output为输出图8 视觉触觉融合神经网络模型Fig.8 Visual and haptic fusion neural network model (3)第2层。用16个大小为3×3的卷积核对第1层传入的112×112×16的特征矩阵进行same卷积,卷积后的特征矩阵大小为112×112×16,卷积完成后进行标准归一化处理并使用ReLU函数激活,然后进行2×2的最大池化,步长为2。池化后的特征矩阵大小为56×56×16。 (4)第3层。用32个大小为3×3的卷积核对第2层传入的56×56×16的特征矩阵进行same卷积,卷积后的特征矩阵大小为56×56×32,卷积完成后进行标准归一化处理并使用ReLU函数激活,然后进行2×2的最大池化,步长为2。池化后的特征矩阵大小为28×28×32。 (5)第4层。用32个大小为3×3的卷积核对第3层传入的28×28×32的特征矩阵进行same卷积,卷积后的特征矩阵大小为28×28×32,卷积完成后进行标准归一化处理并使用ReLU函数激活,然后进行2×2的最大池化,步长为2。池化后的特征矩阵大小为14×14×32。 将卷积完成的14×14×32视觉特征矩阵展平为大小为1×6 272的特征向量。 触觉图像处理共有4层卷积层与4层池化层,并在卷积层与池化层中间加入标准归一化层。卷积层的主要作用为提取触觉图像输入数据的特征信息,池化层采用最大池化主要作用为降低上层输入数据的数据规模以便于在最后用全连接层进行处理。 (1)输入层:输入图像为经过处理的64×64的灰度图像。 (2)视觉模型第1层。用8个大小为3×3的卷积核对灰度图像进行same卷积,卷积后的特征矩阵大小为64×64×8,卷积完成后进行标准归一化处理并使用ReLU函数激活,然后进行2×2的最大池化,步长为2。池化后的特征矩阵大小为32×32×16。 (3)第2层。用8个大小为3×3的卷积核对第1层传入的32×32×16的特征矩阵进行same卷积,卷积后的特征矩阵大小为32×32×16,卷积完成后进行标准归一化处理并使用ReLU函数激活,然后进行2×2的最大池化,步长为2。池化后的特征矩阵大小为16×16×16。 (4)第3层。用16个大小为3×3的卷积核对第2层传入的16×16×16的特征矩阵进行same卷积,卷积后的特征矩阵大小为16×16×16,卷积完成后进行标准归一化处理并使用ReLU函数激活,然后进行2×2的最大池化,步长为2。池化后的特征矩阵大小为8×8×16。 (5)视觉模型第4层。用16个大小为3×3的卷积核对第3层传入的8×8×16的特征矩阵进行same卷积,卷积后的特征矩阵大小为8×8×16,卷积完成后进行标准归一化处理并使用ReLU函数激活,然后进行2×2的最大池化,步长为2。池化后的特征矩阵大小为4×4×16。 将卷积完成的大小为4×4×16的触觉特征矩阵展平为大小为1×256的特征向量。 将分别提取到的特征向量进行拼接组成大小为(6 272+256=6 528)的视觉触觉特征向量输入第一层全连接层,全连接层第1层由1 000个神经元组成,使用ReLU进行激活,全连接层第2层由50个神经元组成,ReLU函数进行激活,输出层有21个神经元组成代表要区分的21种物体,使用Softmax函数进行激活。 实验所用待分类物体包含不同形状(球形、正方体、长方体、圆柱、半球、半圆柱和圆台)与不同材质(木质,橡胶,海绵)的21种实心物体(木球、橡胶球、海绵球、木质正方体块、橡胶正方体块、海绵正方体块、木质长方体块、橡胶长方体块、海绵长方体块、木质半球、橡胶半球、海绵半球、木质半圆柱、橡胶半圆柱、海绵半圆柱、木质圆台、橡胶圆台和海绵圆台)各3个(不同颜色尺寸),共计实验物品63个,其中44个用于采集数据,剩余21个用于最后实际测试。对44个实验物体以不同角度(正上方、正面、正侧面、正斜侧面和侧斜侧面)、不同亮暗程度(采用夜间打光的方式,设置3个等级,调节光源为100%、50%和20%)及不同遮挡(无遮挡以及30%遮挡)进行拍照,将图片的分辨率处理为224×224,由此组建成由3960张图片组成原始数据集,再对原始图片进行翻转、伸缩变换,最终组建成由7 920张图片组成的视觉数据集。 使机械臂从不同角度进行抓取,抓取过程中为匀速抓取并匀速释放,每个物体抓取20次,最终构建成由880个压力图像组成的原始数据集。 由于视觉图像数据与触觉数据并无强关联性,因此采用在同材质物体中随机组合视觉数据与触觉数据,即对于同材质物体的图像随机选择两个同材质物体的压力图像构成视觉触觉数据对,最终形成由15 840个数据对组成的视觉触觉数据集。 为了验证本文模型在实际环境中的有效性,对模型进行了训练以及调整优化,所用电脑的配置信息如表1所示。 数据集按照1∶1∶6的比例分别划分为测试集,验证集以及训练集。其中通过训练集与验证集训练获得模型的参数并对模型的超参数进行调整,测试集用来评估模型的真实有效性。经过100轮训练后,最终获得模型的训练集准确率达到97.8%,测试集的准确率达到98.5%。训练曲线如图9所示。 为验证模型在此分类任务中的优势,设置了两个单一视觉卷积神经网络AlexNet与VGG16进行了对比实验,用相同的数据集各自进行了100轮的训练。实验结果表明,两种方法对于不同物品的检测准确率仅为62.8%和74.5%。例如,两类网络分别有47.5%和39.6%的概率把木质玩具球识别成为橡胶弹力球。可见单一视觉在具有较多相似物体的分类场景中并不适用。 表1 模型训练设备参数Table 1 The parameters of the model training equipment 图9 神经网络模型训练曲线Fig.9 Neural network model training curve 针对基于视触数据融合的多模态细分类系统进行研究,得出如下结论。 (1)搭建了用于机械臂细分类的硬件模块,包括机械臂的配置、深度相机标定以及传感器的部署;基于OpenCV与ROS系统进行了目标的定位以及路径规划。 (2)提出了一种有效的视觉触觉卷积神经网络模型,使用较少层数的卷积层完成了数据的融合分类。并通过实验验证了在具有较多具有相似外观不同材质物体的工作环境下,分类准确率达到98.5%,相较于传统的单视觉模型准确率有较大提升。 实验仍然存在可以改进的地方,今后可以对传感器的使用部署进行优化,并进一步提升算法效能,使系统具有更好的普适性。2.3 触觉数据采集


3 融合模型
3.1 视觉图像处理

3.2 触觉图像处理
3.3 连接层
4 算法验证
4.1 数据准备
4.2 算法对比


5 结论
猜你喜欢
计算机应用(2022年9期)2022-09-25
软件导刊(2022年3期)2022-03-25
北京航空航天大学学报(2021年9期)2021-11-02
海外星云(2021年6期)2021-10-14
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
计算机技术与发展(2019年1期)2019-01-21
特别健康(2018年3期)2018-07-04
智能计算机与应用(2018年2期)2018-05-23
北京航空航天大学学报(2018年1期)2018-04-20
