
利用关系抽取技术联合识别文本中的方面-极性对
2022-02-10 06:47卜令梅卢永美于中华
四川大学学报(自然科学版) 2022年1期
卜令梅, 陈 黎, 卢永美, 于中华
(四川大学计算机学院, 成都 610065)
1 引 言
情感分析的目的是识别人们在文本中表达的态度.随着互联网的快速发展,从网络上海量的评论信息中获取用户的情感倾向[1,2],有很大的商业价值和研究价值.早期的情感分析研究主要聚焦于文档级和句子级,通常假设一段文本只针对一个方面(aspect),并对给定的文本整体判断其情感极性.事实上,一段文本中经常包含多个不同方面,每个方面的情感倾向可能不相同,因此,情感分析的研究热点逐渐由粗粒度转向细粒度,其中方面级情感分析(Aspect-Based Sentiment Analysis,ABSA)是细粒度情感分析的一项重要研究任务.
早期的ABSA被视作方面抽取[3-6]和极性分类[7-11]两个独立的子任务,并采用流水线的方法将两个子任务结合起来获取方面-情感极性对,但是存在错误传播问题.此外,在进行方面抽取时,无法利用极性信息,影响抽取效果.为了克服上述缺点,最新的解决方案是使用单词级(token)序列标注和基于跨度(span,是句子的一个片段,由起始词和结尾词标记.)的联合分类方法.文献[12-14]分别针对方面抽取和极性分类使用不同的标注体系,利用序列标注模型进行ABSA任务,这种方法可以捕捉方面和情感之间的相互作用,然而此方法对那些由多个单词构成的方面,要为每个单词分别进行极性标注,所以面临情感不一致问题.如图1所示的实例中,针对包含两个单词的方面garlic knots,极性分类器可能会将garlic标注为积极(positive),而knots标注为消极(negative),从而导致整个garlic knots的情感极性有歧义.基于span的方法[15-17]通过预测整个方面的极性避免了情感不一致问题.然而在针对候选span使用的{ TPOS, TNEG, TNEU, O }标签体系中,TPOS、TNEG和TNEU分别表示候选跨度是具有积极、消极和中性的方面,而O表示候选span不是一个有效的方面,这使得标签体系存在异质问题,导致模型难以为两个相关但不同的子任务捕捉相应的信息.此外,虽然上述方法捕捉了一个句子中各个方面之间的相互作用,但它们忽略了不同方面极性对之间的相互关联,这种关联对一个句子中所有方面的极性判断至关重要.

图1 方面级情感分析实例Fig.1 An example of ABSA
为了捕捉一个句子中所有方面极性对之间的相关性,本文受关系抽取技术[18-20]的启发,将ABSA任务视为一元关系抽取,其中方面看成实体,其对应的极性作为关系,利用关系抽取技术生成方面-情感极性对,提出利用关系抽取技术联合识别文本中方面-情感极性对(Employing Relation Extraction to Aspect-Polarity Pairs Generation,REAPP)的模型.本文在3个公开的基准数据集进行了一系列实验.结果表明,本文的模型提高了方面级情感分析任务的性能,同时也验证了利用方面极性对之间的关联能够提高ABSA任务的性能.
本文的贡献主要有两方面:(1) 将ABSA任务归结为一元关系抽取问题,捕捉文本中不同方面极性对之间的相互作用,克服了现有方法中存在的情感不一致和标签异质问题;(2) 在3个数据集上进行了实验,验证了本文模型的性能.
2 相关工作
早期的ABSA先进行方面抽取再为给定的方面进行情感极性分类,这种分离模型的做法应用受限,目前联合两个子任务已经成为研究热点.2013年,Mitchell等[12]首先尝试使用条件随机场(Conditional Random Fields,CRF)为联合标签进行序列标注,同时与流水线方法进行了对比,但实验表明联合标签并没有比流水线方法效果更佳.2015年,Zhang等[13]在Mitchell等[12]的基础上,进一步引入神经网络模型,然而也没能验证端到端方法比流水线方法更具优越性.此后,Li等[14]意识到之前的做法面对由多个单词构成的方面时,由于为每个单词预测的情感极性可能不一致而导致该方面的情感歧义问题,于是在为当前单词进行标注时利用了之前单词的嵌入信息进行缓解,然而这种方法并不能完全避免情感不一致问题.所以在2019年,研究者开始将方面看成一个span,用基于span的方法避免上述情感不一致问题.Hu等[15]提出使用两个基于span的分类器识别span的起始位置和结束位置,然后针对整个span进行极性分类.但该工作对span起始位置和结束位置的识别是独立进行的,只能通过启发式算法为二者进行配对.Lin等[17]为了避免丢失正确的方面,改进了Hu等[15]的启发式算法,首先通过匹配预测结果中最接近的起始和结束位置获取候选span,然后通过拓展策略确定正确span,虽然进行了更有效的开始和结束位置配对,但仍旧独立进行起始位置和结束位置的识别工作,没有从根本上解决二者的配对问题.Zhou等[16]枚举候选span并调用多分类器从{TPOS, TNEG, TNEU, O}中确定候选span的类别,显然该集合包含的异质分类标签会影响分类性能.
3 任务与模型
为了解决现有的ABSA研究存在的问题,本文提出将ABSA任务视为一元关系抽取的过程,将方面视为实体,使用span的方式进行表示,其对应的极性视为关系,方面-情感极性对则表示为(方面起始位置,方面结束位置,情感极性)三元组.
3.1 任务定义
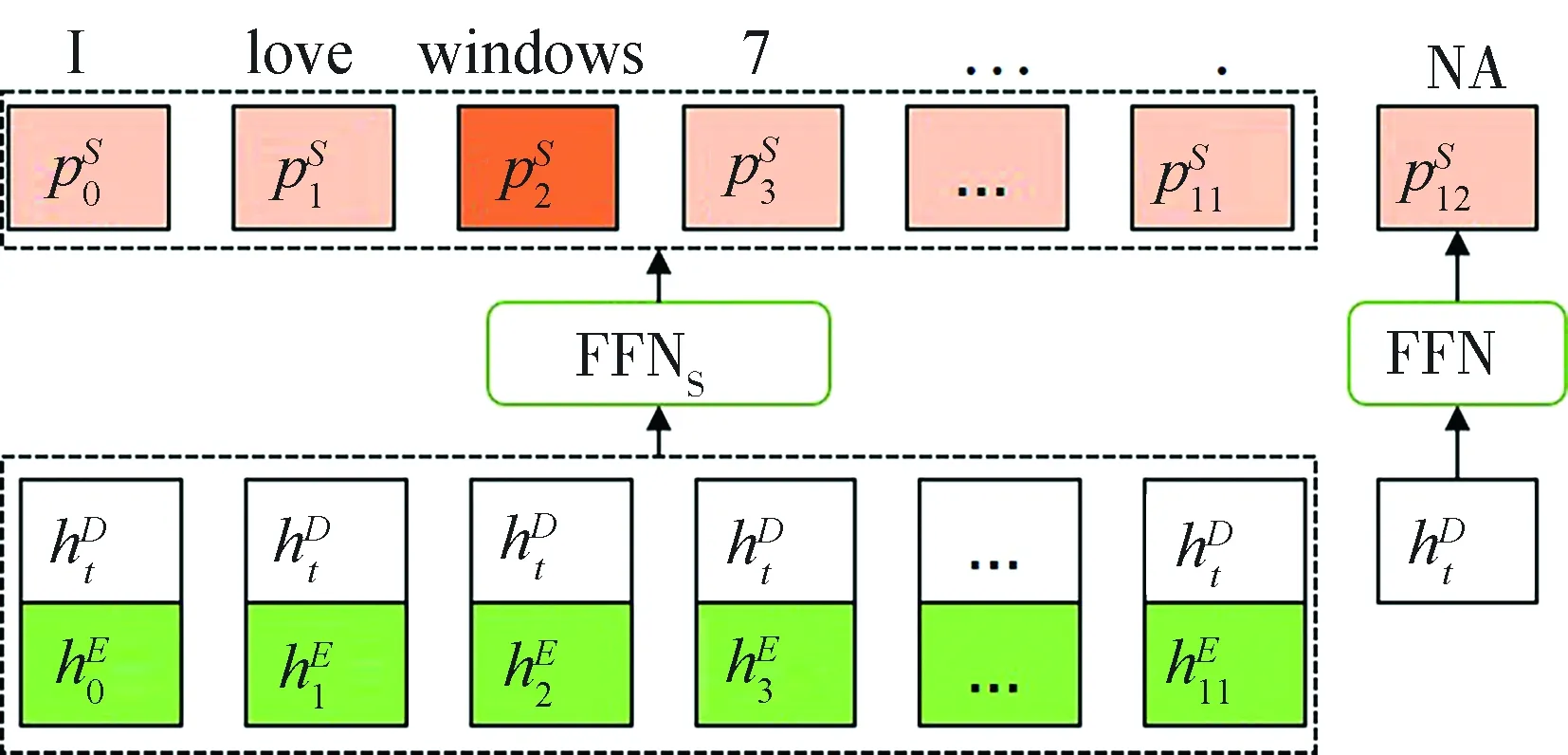
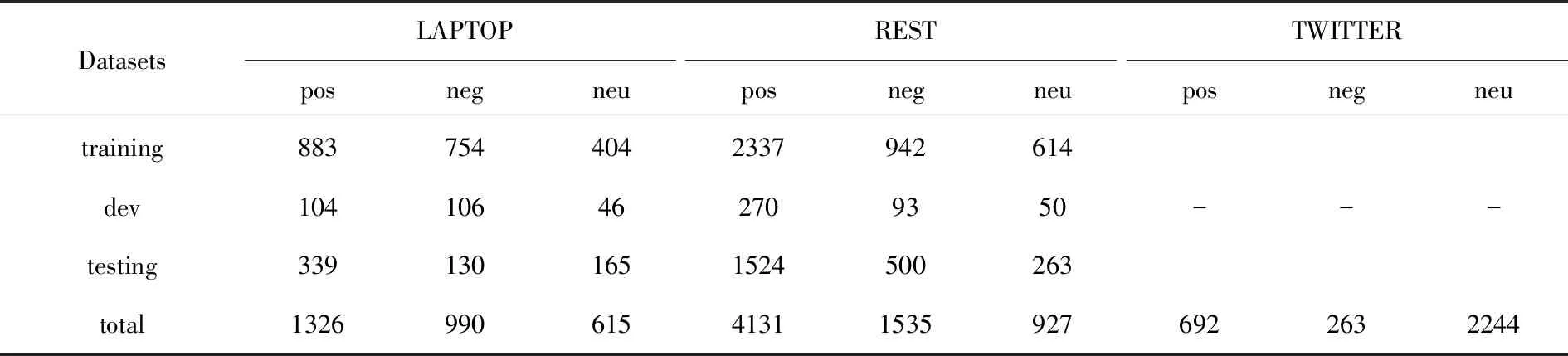
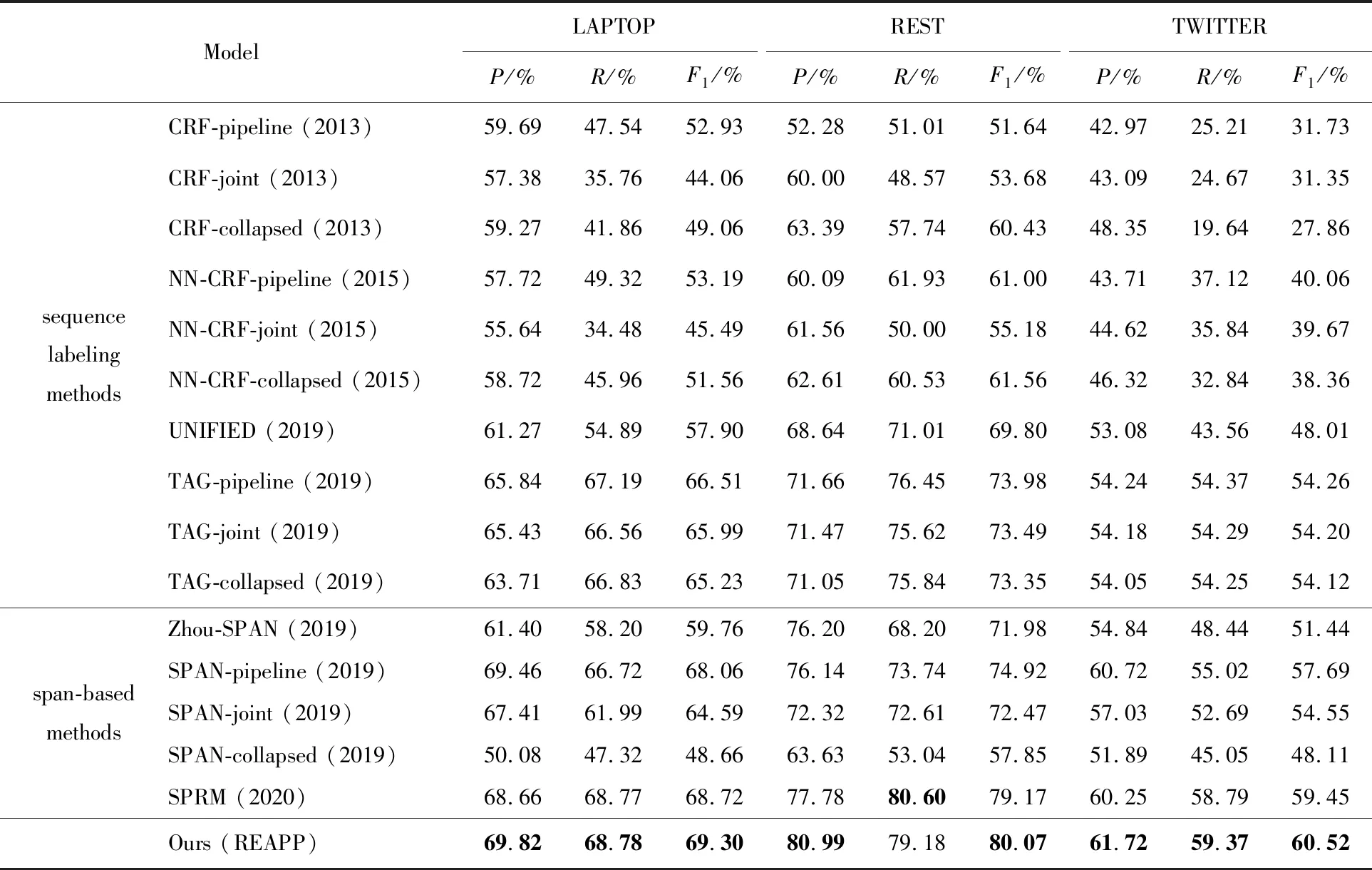
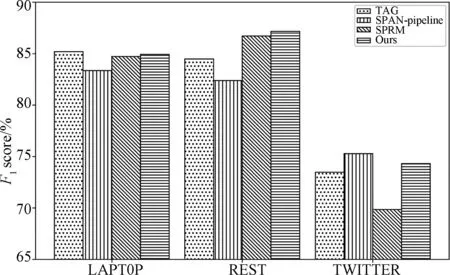
给定一个句子S={w1,w2,…,wn},每个句子由n个单词组成,本文的任务是根据输入的句子自动识别S中所有的评价对象以及情感极性,即输出集合Y={ 表1 REAPP的输入输出例子Tab.1 An example for input and output of REAPP 本文提出的REAPP模型由三层组成,如图 2所示.第一层为嵌入层,负责利用词嵌入初始化句子中的所有单词;第二层为编码层,根据词嵌入进行句子分析,捕捉句子中所有单词之间的相互作用,生成单词的上下文表达;最后一层是解码层,注意力机制为解码层提供上下文表达,解码层在每个时序步中生成三元组. 图2 REAPP模型结构图Fig.2 The architecture of REAPP model (1) (2) 其中,Wu为待学习的参数;et为当前时刻通过注意力计算得到的上下文向量,计算如式(3)~(6)所示. (3) βt,i=vPtanh(mt+nt,i) (4) (5) (6) 其中,WP,bP,WQ和vP均为待学习的参数.在得到解码器t时刻的状态后,模型开始解码,解码过程主要包含3个步骤:t%3=1时开始解码新的三元组,生成评价对象的起始位置;t%3=2时生成评价对象的结束位置;t%3=0时预测情感极性,一个完整的三元组总是需要经历这3个时刻,具体进行哪个操作由t对3取余的结果确定,模型会循环执行这一系列操作,直到生成表示结束的三元组. 生成起始位置时(t%3=1),需考虑生成NA三元组的可能,且在ABSA任务中每个方面只需要生成一次,所以本文引入向量Ms∈Rn来屏蔽已经拷贝过的方面,计算起始位置概率分布的过程如图 3和式(7)~(10)所示. 图3 方面起始位置识别Fig.3 Start position identification of an aspect (7) (8) (9) ps=softmax([Ms⊗qs;qNA]) (10) 其中,Ws,bs,WNA和bNA均为待学习的参数. 生成结束位置时(t%3=2),其起始位置已经明确,本文引入另一个向量Me∈Rn确保结束位置在起始位置之后,其他操作与t%3=1类似,计算结束位置概率分布的过程如图4和式(11)~(13)所示. 图4 方面结束位置识别Fig.4 End position identification of an aspect (11) (12) pe=softmax([Ms⊗qe⊗Me;qNA]) (13) 其中,We,be均为待学习的参数. 图5 方面极性分类Fig.5 Polarity classification of an aspect (14) (15) pr=softmax([qr;qSNA]) (16) 其中,Wr,br,WSNA和bSNA均为待学习的参数. (17) 本文在3个ABSA任务公开的数据集LAPTOP、REST和TWITTER[12]上验证了REAPP模型的有效性.为了便于比较,本文采用与Zhou等[16]相同的数据划分,其中TWITTER使用十折交叉验证,实验数据统计如表2所示.本文使用的评价指标包括精确率、召回率、F1得分和准确率.此外,只有当预测的方面与黄金标注完全一致才认为是正确的方面. 表2 实验数据统计Tab.2 Statistics of the datasets 本文使用glove.840B.300d初始化词嵌入(nlp.stanford.edu/projects/glove/),而解码器使用的词嵌入是随机初始化的,此外,本文使用Stanford CoreNLP toolkit对句子中的单词进行POS标注(stanfordnlp.github.io/CoreNLP/),POS嵌入的维度是50.本文使用50个大小为3的滤波器,字符级编码维度为50.输入句子的上下文编码是通过两个堆叠的Bi-LSTM学习的,正向和反向的维度都是150维,解码端的LSTM维度设置为300.本文的学习率设置为0.001,batch大小为32,dropout设置为0.5,使用Adam优化器. 本文对比的模型包括以下较先进的方法: (1) CRF-pipelined,joint,collapsed(2013)[12]:一种基于情感词典和手工构建特征的CRF序列标记方法; (2) NN-CRF-pipelined,joint,collapsed(2015)[13]:一种顶层使用CRF序列标注捕捉标签相关性的浅层网络模型; (3) UNIFIED(2019)[14]:一种使用联合标签的基于Bi-LSTM进行序列标注的方法; (4) TAG-pipelined,joint,collapsed(2019)[15]:一种以BERT为编码器,基于CRF进行序列标注的模型; (5) Zhou-SPAN(2019)[16]:集中基于span的联合方法,使用span制导的注意力机制获取每个span的情感信息; (6) Hu-SPAN-pipelined,joint,collapsed(2019)[15]:一种以BERT为编码器的基于span的方法,提出将起始位置和结束位置配对的启发式算法; (7) SPRM(2020)[17]:对Hu-SPAN-joint[15]的改进,为每个子任务设计私有编码器以及联合编码器,以捕获两个任务之间的关联信息. 在3个基准数据集上,方面-情感极性对抽取的实验结果如表3所示,从表3可看出,无论是与序列标注的方法相比,还是与基于span的方法相比,本文模型都表现最佳.SPAN-pipeline (2019)的F1值比TAG-pipeline (2019)在3个数据集上分别提升了1.55%、0.94%和3.43%,可以看出基于span的方法比序列标注方法更有优势,因为其针对整个span进行情感分类,有效避免了序列标注方法给多个单词构成的方面所带来的情感歧义问题.而本文方法除了针对整个span进行极性分类,还使用序列模型捕捉文本中不同方面-情感极性对之间的相互作用,提出的REAPP模型比效果最好的序列标注模型TAG-pipeline (2019)在3个数据集上的F1值分别提高了2.79%、6.09%和6.26%,而和基于span的模型SPRM (2020)相比,虽然在REST数据集上,本文的召回率较低,但精确率比SPRM高出了3.21%,在3个数据集上的F1值分别超出0.58%、0.90%和1.07%. 表3 方面-极性对抽取实验结果Tab.3 Comparison of different methods’ results on three datasets 为了分析模型在方面抽取的性能,本文计算了REAPP在3个数据集上方面抽取的F1得分,和序列标注以及基于span的方法进行对比,如图6. 图6 方面抽取对比结果Fig.6 The results of aspect extraction 从图6的实验结果可以看出,本文的模型在LAPTOP、REST和TWITTER数据集上的F1值分别为84.93%、87.16%和74.31%,比SPRM(2020)的F1值提高了0.21%、0.45%、4.46%,这证明本文模型对方面的识别是有效的.此外还可以发现,SPRM虽然在LAPTOP和REST上表现较好,但是在TWITTER上表现较SPAN-pipeline模型和本文的模型差很多,这说明SPRM和SPAN-pipeline二者采用的启发式规则不能自适应所有的数据集,而本文的模型可以适应句子长度的变化,在识别评价对象时受其影响较小. 对于REAPP模型在情感极性分类上的性能,本文针对所有被正确识别出的方面,计算情感极性分类的准确率(Acc),在3个数据集上和效果最好的情感分类器进行对比,结果如图 7所示. 图7 情感极性分类对比结果Fig.7 The results of polarity classification 由实验结果可知,本文的模型在LAPTOP、REST和TWITTER数据集上的准确率分别是81.52%、90.82%和79.12%,是目前在3个数据集上极性分类效果最好的模型. 本文提出了REAPP模型,与当前序列标注方法和基于span的模型不同,利用了句子中方面-情感极性对之间的关系,捕捉方面抽取和极性分类两个子任务之间的相互作用.此外极性预测针对整个方面,从而避免了现有单词级序列标注方法存在的情感极性不一致问题和基于span方法中标签体系的异质问题.在3个数据集上的实验表明,本文模型优于现有的最好方法. 目前本文在进行情感极性预测时,计算注意力的方式和位置识别相同,接下来,本文考虑在预测情感极性时,使用方面制导的注意力机制以更好的捕捉特定方面的情感信息.此外,通过表3还可以看出,不论是REAPP模型还是其他两类模型,召回率相对精确率都较低,这说明预测的方面数量较少,后续本文会尝试解决这个问题.
3.2 提出的模型

3.3 嵌入层
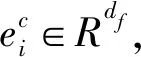
3.4 编码层

3.5 解码层
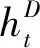

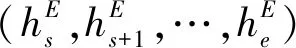


4 实验与结果
4.1 实验数据
4.2 实验设置
4.3 基线模型
4.4 结果分析
4.5 方面抽取结果分析
4.6 极性分类结果分析

5 结 论
猜你喜欢
模式识别与人工智能(2022年9期)2022-10-17
计算机应用与软件(2022年5期)2022-07-07
中学生报·教育教学研究(2022年1期)2022-04-18
计算机研究与发展(2022年1期)2022-01-19
计算机应用与软件(2021年4期)2021-04-15
河北科技大学学报(2020年4期)2020-09-10
时代英语·高一(2019年5期)2019-09-03
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
数理化学习·高一二版(2009年2期)2009-03-30
