
基于注意力机制多尺度网络的自然场景情绪识别
2022-02-10 06:47晋儒龙卿粼波文虹茜
四川大学学报(自然科学版) 2022年1期
晋儒龙, 卿粼波, 文虹茜
(四川大学电子信息学院, 成都 610065)
1 引 言
情绪识别是计算机视觉的一项基本任务,它是情感计算的一部分,旨在识别出某个体的感受与状态,例如高兴、悲伤、厌恶和惊喜等.情绪识别技术用途广泛,目前已经在人机交互[1]、安防[2]和医疗健康[3]等领域有所应用,然而自然场景中的情绪识别存在识别难度大等问题仍具挑战性.得益于深度学习近几年的快速发展,基于卷积神经网络(Convolutional Neural Network, CNN)的方法已经成为各种先进模型的基础.
情绪表达的途径多种多样,语音、文本、生理电信号以及图像[4-7]是情绪识别的常见方式.在自然环境中,语音和文本数据难以采集,生理电信号的采集会对研究对象的情绪产生干预,因此基于视觉信息仍是主要的情绪识别方法.关于面部情绪识别,无论是传统的手工提取特征,还是深度学习方法,多数都是关注面部特征,因其能够提供最明显直观的情感状态.普遍使用的方法是面部动作编码系统(Facial Action Coding System, FACS)[8],核心思想是将面部定义为多个运动单元(Action Unit),然后根据不同运动单元的组合编码为6种基本表情(快乐、悲伤、恐惧、惊讶、愤怒和嫉妒).由于深度CNN网络的快速发展,运动单元从手工设计转变为自动识别,例如Jain等[9]提出使用CNN进行特征提取和情绪分类.但是人脸在自然场景中存在光照不均匀、遮挡和拍摄角度等问题,导致难以准确识别其情绪状态.
关于姿态情绪识别,Nicolaou等[10]提出一种面部结合肩部运动信息的情绪识别方法,Schindler等[11]使用身体姿态在约束条件下识别6种基本情绪.Dael等[12]发现身体的动作和姿态不仅能反映情绪强度,还能得到具体的情绪类别.然而,同一种姿态或行为在不同语境中表达的可能是不同的情绪状态.例如,在家中看电脑和在办公室看电脑是同一种行为,综合考虑其姿势,衣着以及环境会得到情绪状态不同的结论.
最后是基于场景的情绪识别,Mou等[13]通过融合人脸,身体以及场景信息进行群体的情绪识别,但基于场景信息的个体情绪识别很少被研究.为了更好地研究基于场景的情绪识别Kosti等[14]提出了EMOTIC (EMOTions In Context database)数据集,并且基于该数据集设计了一个双通道的基准网络结构,分别用于提取人物特征和场景特征.在此基础上,Zhang等[15]利用Region Proposal Network (RPN)网络提取场景元素作为节点构建情感图进行情绪识别.Bendjoudi等[16]在双通道的基准网络上提出多任务损失函数改进模型的训练过程.虽然上述方法都利用了场景信息,但是自然场景中的情绪线索有大小远近之分,简单地对场景信息提取特征,并不能有效利用场景中的情感线索.
为了改善上述问题,本文提出了一种基于注意力机制的多尺度情绪识别网络模型.此网络由人物分支与场景分支组成.针对人物个体在自然场景中存在的不确定性问题,人物分支设计一种身体注意力机制用来预判个体情绪的置信度,并且作用于人物的特征,从而抑制相应的不确定性.针对场景情绪线索探索不充分的问题,场景分支设计了全局-局部的网络结构.对于全局信息,利用空间注意力机制获取场景中的全局信息.对于局部信息,利用空间金字塔能够捕获不同粒度信息的能力,将场景中多种尺度的情感线索进行融合增强,从而获得更加丰富的场景特征表示.最后早期融合双分支的特征向量,得到最终的情绪分类结果.本文的主要贡献如下:(1) 提出一种基于注意力机制与多尺度的网络,充分捕获人物与场景各自的情感线索,最后融合二者之间的关系,推理出人物在自然场景中的情绪类别;(2) 在EMOTIC数据集进行广泛的实验,实验结果证明了提出模型的有效性.
2 模型结构
现有方法在探索人物与场景线索时,只是简单地提取特征,然后进行融合并进行情绪分类,并未关注人物在场景中的不确定性,以及场景信息的复杂性.针对以上问题,设计一种基于注意力机制的多尺度网络情绪识别模型,系统框架如图1所示.对于人物个体,提取特征的同时使用注意力机制学习当前人物情绪的置信度;对于场景,使用特征金字塔提取不同尺度的特征图,其中高阶语义信息使用空间注意力机制学习场景中的主要信息,最后融合双分支网络获得情绪分类的结果.
2.1 人物分支
在图像中,人物个体能够直观地描述情绪状态,因此建立基于人体的CNN网络结构.为避免过拟合以及增强模型泛化性能,使用Image-Net数据集下预训练的ResNet-50模型进行微调.根据Bounding Box裁剪出人物区域,作为网络的输入IB∈,通过ResNet-50得到的特征向量记作XB∈,其中d表示情绪类别数.其前向传播如式(1)所示
XB=F(IB;WB)
(1)
其中,WB表示网络权重.考虑到图像中人物的遮挡以及人物在图像中是否占主导地位的因素,加入注意力机制预判当前人物对情绪识别的置信度.该注意力机制有两点值得注意:(1) 位置不同于传统的注意力机制.不是位于特征图之后,而是直接置于特征提取之前,这样可以有效地预判当前人物的情绪置信度;(2)结构不同于Squeeze-and-Excitation[17]模型.首先使用全局平均池化得到11的卷积核,再通过两个卷积层得到权重λ,最后与XB点乘,得到基于人物CNN的分类结果如式(2)所示.
fB=λ⊗XB
(2)
其中,⊗表示按位置相乘.部分判决结果如图2a所示.

图1基于注意力机制的多尺度网络情绪识别框架Fig.1 The framework of attention mechanism and multi-scale network based emotion recognition
2.2 场景分支
文献[13-15, 18]的研究已表明场景信息能够很好地辅助情绪识别,因此搭建基于场景的CNN网络结构.为了防止与人物特征重复提取,对场景中主要人物增加掩模,如式(3)所示,对于场景图像IC∈有
(3)
其中,bboxIB表示主要人物所在区域.使用特征金字塔(Feature Pyramid Networks, FPN)[19]处理场景细节信息.FPN常用于多尺度目标检测,它能够在增加少量计算量的前提下融合低分辨率语义信息较强的特征图和高分辨率语义信息较弱但空间信息丰富的特征图,在下采样过程中有效地增强局部细节特征.FPN分为自底向上和自上而下两个过程,在自底向上的过程中,采用预训练的ResNet-18模型作为特征提取网络,ResNet拥有4个残差块,为避免内存占用以及过拟合问题,使用最后3个残差块的输出构建FPN,记作C={C3,C4,C5},分别对应IC的{8,16,32}下采样倍数;在自顶向下的过程中,采用两倍最近邻插值对{C3,C4,C5}上采样,然后与其下一层的特征图进行对应位置的相加,得到对应的特征金字塔P={P3,P4,P5},C与P拥有相同的尺寸.由于P共享同一个分类器,所以在分类前通过11卷积修正所有特征图的通道为256维,分类器由两个卷积层和全局平均池化构成,输出分类结果为

(4)
由于只关注场景中对情绪识别有帮助的部分,因此引入空间注意力机制,对此使用Attention Branch Network[20],与FPN自底向上过程共享网络权重,该网络能够有效地识别定位图像中主要的区域,其输出记作fC2.场景分支的分类结果由fC1和fC2构成.
2.3 模型融合
为融合人物分支和场景分支的特征向量,使用早期融合在通道维数连接
f=concatnate[fB,fC1,fC2]
(5)
然后通过一个全连接层对特征向量f∈进行分类,再通过Softmax归一化到[0, 1]区间.
3 实验与分析
3.1 实验数据
本文基于EMOTIC数据集[14]进行实验,该数据集图片来源于MSCOCO、Ade20K和网络下载等3部分.共包含23 571张图片,标注了34 320个人物.标注信息包含26类情绪,每个人物至少拥有一种情绪标签.其中70%用于训练,10%用于验证,20%用于测试.
3.2 实验设置
本文在Ubuntu16.04系统使用Pytorch框架进行实验,GPU为NVIDIA GeForce GTX2080,内存为11 GB,模型参数的优化使用Adam优化器,初始学习率为1e-4并按照余弦方式下降,训练轮数为70次,批次为32,使用MultiLabelSoftMarginLoss函数进行误差反向传播.IB和IC缩放为224224,使用水平翻转,改变对比度、亮度和饱和度进行数据增强.
3.3 实验分析
沿用文献[14]使用的mAP(mean Average Precision)作为评价指标以便客观评价模型性能.实验对比了EMOTIC数据集的基准方法[18],Bendjoudi等[16]提出的方法以及Zhang等[15]提出的方法.实验结果如表1所示,从表1可以发现自然场景中的复杂情绪识别任务挑战较大.文献[16]在基准模型[18]的基础上对损失函数进行改进,获得了一定的性能提升.先进模型[15]利用目标检测算法进一步提取场景线索,其性能的提升也说明有效利用场景线索可以辅助情绪识别.
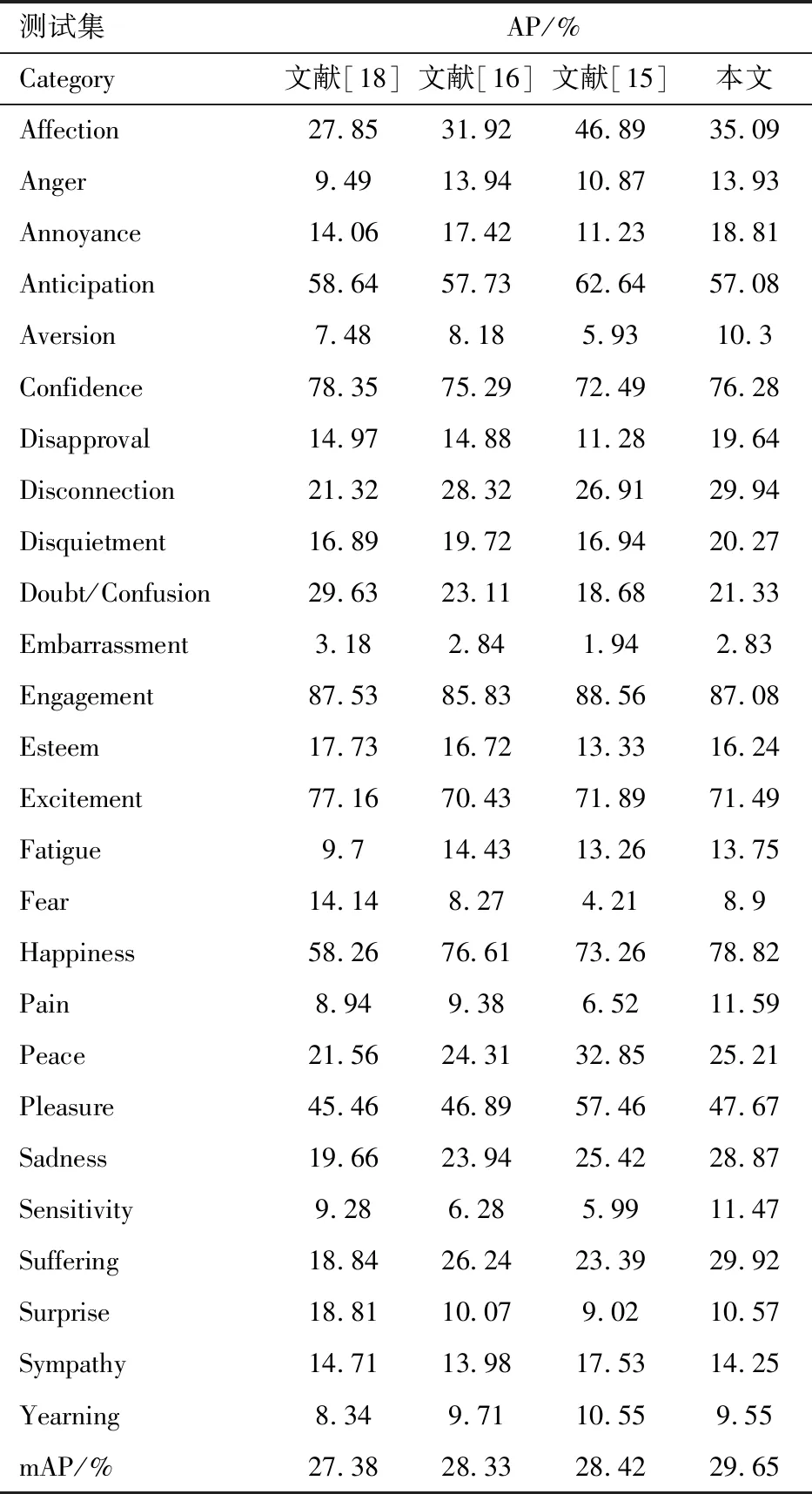
表1 EMOTIC测试集下的AP和mAPTab.1 Quantitative evaluation of EMOTIC in comparison on average precision and mean average precision
本文模型利用多尺度信息以及空间注意力机制探索不同粒度的场景信息,相比单阶段方法[16,18]分别提升了2.27%和1.32%.相比于先进模型[15]使用双阶段的训练策略(先单独检测自然场景的线索,然后依赖图神经网络构建情感计算图),我们的模型可以实现端到端的训练以及计算量的减少,并且mAP提升了1.23%,表明了本文提出模型的优越性.
值得注意的是,在数据较少的类别Annoyance(2%),Aversion(1%),Disapproval(2%),Pain(1%),Sadness(2%),AP值均优于其他方法,其中Disapproval提升最多为4.67%.说明当数据较少时,本文模型仍能有效学习到自然场景中的情绪线索.在数据较多的类别Confidence(23%),Engagement(50%),Happiness(26%),相比其他方法,提升幅度有限.主要是因为场景分支未使用较深层数的骨干网络,这使得我们的模型能够在数据少的类别实现明显的性能提升.但随着网络的加深,容易导致模型过拟合,进而降低泛化性能.详细类别分布见文献[14].整体来说,所提出模型在多数类别的AP均获得了提升,mAP也达到了最优结果.
为了更准确地衡量本文模型的有效性,设计消融实验对比分析身体注意力机制(w/BA),空间注意力机制(w/CA)以及特征金字塔(w/FPN)等3个组件的性能,实验结果如表2所示.可见三者组合使用可以获得最优的性能,三者单独使用也优于其他方法.其中BA用于预判人物在场景中的情绪置信度,同时抑制人物个体的不确定性,性能相比先进方法提升了0.67%.CA用来捕获全局场景信息,提升最多为1.85%,用来提取局部场景信息的FPN也获得了可比的性能提升.消融实验结果表明该模型使用的3个模块能够充分利用人物信息和场景中的全局-局部信息,从而有效提高情绪识别效果.

表2 基于注意力机制的多尺度网络消融实验Tab.2 Ablation studies for proposed method
除了实验数据分析,我们也对部分测试集进行可视化分析,如图2所示.一方面是人物分支的情绪权重λ,如图2(a)所示,当人物在图片中清晰可见时,其权重较大;当人物受到分辨率,拍摄角度等影响,通过人物本身难以识别其情绪状态,对应的情绪权重也相应减少并弱化人物对情绪识别的影响.另一方面是场景分支的空间注意力分布,如图2 (c)和(d)所示,对人物增加掩模后,场景分支将注意力从人物本身转移到关注场景本身,这样可以有效地避免人物分支与场景分支学习到重复的特征.表3的实验结果也表明对人物增加掩模后(w/ masking)性能有所提升.

图2 情绪识别结果可视化(a) 原始图像;(b) 人物情绪标签,其中绿框为真值,蓝框为预测值;(c)(d) 分别为原始图像和IC训练得到的空间注意力分布Fig.2 Visualization of emotion recognition results(a) Original image; (b) multi-label,which ground truth in green box and prediction in blue box; (c) and (d) results of without hiding the body and with hiding the body during training respectively

表3 人物增加掩模性能对比Tab.3 Quantitative evaluation of with/without masking.
4 结 论
本文研究了基于人物与场景线索的自然场景情绪识别问题,提出了基于注意力机制的多尺度情绪识别网络结构,在完全缺乏人脸信息的真实场景中,实现了对26类复杂情绪的基本识别.网络结构由人物分支与场景分支组成,针对人物分支设计的身体注意力机制能够有效预判当前人物对情绪识别的置信度,针对场景分支,融合空间注意力机制和特征金字塔可以进一步探索场景中的全局-局部情绪线索.在EMOTIC数据集上进行多个实验以评估该方法的识别性能.与相关方法比较,实验结果验证了该模型的有效性.虽然本文方法在识别精度上有较好的结果,但仍然有进一步的提升空间,主要原因是在对人物分支以及数据集不平衡的研究有限,在后续研究中,会考虑融合行为识别和改进训练策略等方式,提升算法识别的精度.
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
小雪花·成长指南(2022年1期)2022-04-09
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机系统应用(2021年10期)2022-01-06
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
第二课堂(课外活动版)(2016年2期)2016-10-21
疯狂英语·口语版(2013年1期)2013-01-31
阅读(中年级)(2009年11期)2009-04-14
中学英语之友·高一版(2008年10期)2008-12-11
