
基于图注意力网络的舆情演变预测研究
2022-02-10 06:47彭思琪周安民周雨婷刘德辉
四川大学学报(自然科学版) 2022年1期
彭思琪, 周安民, 廖 珊, 周雨婷, 刘德辉, 文 雅
(四川大学网络空间安全学院, 成都 610064)
1 引 言
舆情是社会公众对各类事件所持有的社会态度的一种综合反映. 传统的社会舆情存在于大众的思想观念和日常的街头巷尾的议论之中. 随着移动互联网井喷式发展,网络成为群众表达社情民意和交流情感的重要渠道,社会舆情开始转向网络化[1]. 网络舆情是社会舆情在互联网空间的映射,是社会舆情的直接反映. 由于网络媒体具有进入门槛低、信息规模超大、信息发布与传播迅速、参与群体庞大和实时交互性强等综合性特点,这使得网络舆情的产生、扩散、爆发和引导更加复杂. 因此,对网络舆情事件进行有效的监测和预警具有重要的意义和价值.
尽管目前国内外已经有很多成熟的舆情监控系统,如中国舆情网帕拉斯(PALAS)、Goonie、Nielsen等,用来帮助企业和政府促进长远发展、构建和谐环境. 但是这些大多是对网站、博客和论坛等进行监测,进而对舆情热点、舆情趋势等进行分析. 面对纷繁复杂的网络舆情,特别是在舆情变化迅速,信息量巨大的社交网络环境中,要想实现对网络舆情的监控和管理,预防舆情危机的突发,这些是远远不够的. 一个关键的解决方案就是对网络舆情事件下一阶段的演变进行预测[2].
如果能在网络舆情发展的初期,及时对其趋势进行科学有效的预测,将会对舆情预警工作起到实质性的帮助. 目前国内外学者在舆情趋势预测方面已有较多研究,但是,现有的相关研究工作大多是基于热度指标的预测,如点击量、评论量和转发量等. 这些指标在一定程度上确实能通过大众对事件的关注程度反映出舆情事件的趋势,但难以反映大众在舆情发展过程中的态度变化. 态度变化,也即情感变化,是指大众对本次舆情事件的观点和情感的具体变化. 尽早了解情感变化的意义主要表现在:对政府而言,可以掌握社会舆论的动向,发现社会中存在的问题与矛盾,及时对负面舆情进行引导;对企业而言,可以根据用户对企业负面舆情所持有的态度,及时制定相应的公关策略,也可以获取用户的消费兴趣. 因此,为了达到真正的预警效果,可以通过预测事件的情感发展趋势来把握大众的态度变化,进而反映舆情事件的趋势.
情感倾向性预测一直是研究的热点问题,通过预测情感倾向性可以直观把握事件整体,如用户对产品的评价[3]. 然而,该类研究具有一定的局限性. 由于大众对舆情事件的情感态度在大多数情况下都表现出同种倾向性,很少会随着事件的发展呈现出不同的情感倾向性,将情感倾向性作为事件情感趋势演变预测的对象的研究意义不大. 尽管如此,情感倾向性的强弱程度在事件发展的不同阶段还是在不断变化的.
基于以上分析,本文提出基于图注意力网络(GAT)的舆情事件情感趋势演变预测方法,通过情感值来对舆情事件的情感演变趋势进行预测. 具体而言,我们根据社交平台上针对某个舆情事件的评论文本计算出事件每个时间段的情感得分,以此反映大众对该舆情事件的情感态度变化. 进而通过情感得分进行数值预测,预测出事件在下一时间段的情感演变趋势. 由于除评论文本信息外,事件的已知外部信息较少,利用图结构将评论文本分阶段表示为情感词交互图,忽略评论中无关词的信息,获取时序文本数据中动态的空间相关性. 不仅能更充分、有效地关注文本的情感语义信息,更为无任何可用信息的预测阶段提供了较为丰富的情感预测依据. 此外,图注意力网络将注意力机制引入到基于空间域的图神经网络. 在情感趋势演变预测中,图注意力网络运用注意力机制来对邻居节点做聚合操作,实现对不同邻居节点权重的自适应分配,避免引入过多的学习参数,从而大大提高了预测模型的表达能力[4]. 同时,针对网络舆情事件周期往往较短,导致无较长的情感值时间序列用于预测的情况,本文将门控循环单元(GRU)与图注意力网络相结合,用于捕获时序关系,对短期事件进行动态预测. 实验表明本文方法能较为准确地预测事件在下一时间段的情感值,为网络舆情事件的预警提供帮助.
2 相关工作
目前,针对舆情事件演变预测的研究,主要是基于热度指标的. 聂黎生[5]将微博的点击数量作为舆情趋势变化的直接反映,提出基于核主成分分析与粒子群随机森林算法实现舆情演变预测. Yu等[6]对微博舆情事件的点击量、回复量和转载量加权求和,得到舆情事件的趋势值,利用马尔可夫模型预测高校舆情趋势. Li等[7]采用术语频率与语义权重定义新的流行度量化方法来捕获话题的人气,从语义上解决噪声和歧义问题. 但是通过热度指标并不能反映出大众对某件网络舆情事件过去、现在和未来的态度变化.
而对舆情事件情感的预测,大多局限于情感的倾向性预测,未对情感值进行精确预测. 连淑娟等[8]将中文自动构词算法构建的的文本倾向性分类方法词库和基于信息瓶颈的特征提取方法相结合,有效提高了网络舆情倾向性的预测精确度. 王亚民等[9]先计算各微博的情绪值,按照其数值大小,统计正、中、负三个情绪等级下的样本数量比例,并使用文档频度权重测度方法合成公众对政策的最终舆情支持度,再利用马尔可夫模型预测民众对公共政策的态度舆情倾向.
由于大众对舆情事件的情感态度在大多数情况下都表现出同种倾向性,但情感的强弱程度是在不断变化的. 因此,通过情感值能更有效地反映舆情事件发展趋势. 王努努等[10]直接使用Rost CM文本挖掘软件对微博正文数据进行情感值计算,形成情感时间序列,进而基于ARIMA和BP神经网络组合模型对其情感变化趋势进行综合分析和预测. 马晓宁等[11]通过对评论的句式分析,利用短语模式计算单句及复句的情感值,构建情感值时间序列,建立基于相关向量机的网络舆情情感趋势演变预测模型.
Li等[12]使用图到序列模型生成新闻评论,该模型将输入新闻建模为主题交互图. 通过将文章组织成图结构,可以更好地理解文章的内部结构和主题之间的联系. 为了研究图动态演化的实际场景,Pareja等[13]通过循环神经网络演化图卷积网络参数来捕捉图序列的动态性,用于解决链接预测,边分类和节点分类等任务.
3 基于图注意力网络的舆情事件情感趋势演变预测模型本文提出的舆情事件情感趋势演变预测模型架构如图1所示. 该模型主要包含数据预处理、情感量化、构造图和建立预测模型四个部分. 首先,我们从社交媒体平台爬取某一舆情事件在舆情演化阶段的全部评论文本数据,对文本数据进行预处理以及数据划分等工作;其次,对每个时间步长内的评论文本进行情感量化,得到各时间步长内的情感词及每个情感词对应的情感得分,进而计算得到各时间段的情感值,建立情感值的时间序列;然后利用情感词和评论文本的语义相似度为事件发展的每个时间段都构造一个对应的图;最后,我们使用门控循环单元和图注意力网络构建预测模型.

图1 预测模型架构Fig.1 Architecture of the prediction model
3.1 数据收集与处理
由于社交平台上的评论形式多样,既可以是文字形式、图片形式,又可以是表情符号等形式,并且也会存在许多重复、无效的信息[14]. 为了提高情感预测的准确性和可靠性,本文需要从社交平台上选取合适的、能够反应出事件情感的数据. 进一步地,我们还需要对数据进行文本预处理,过滤掉与舆情事件无关的评论,同时把评论中的词形还原,利于后续情感量化工作的展开.
考虑到图片的处理工作较为复杂,要想快速从图片中提取到大量的有效信息也有一定难度,本文仅利用了评论中的文本信息来完成情感预测任务. 通过对收集的文本数据进行整理,我们发现数据中存在来自不同用户的相同评论文本内容,分析可能是用户进行转发操作或者是网络上的“水军”刷帖造成的. 因此需要对数据进行去重处理,避免相同文本信息过多,对文本的情感分析造成干扰. 同时,本文将主要精力集中在对文本内容的情感分析上,不考虑表情符号、标点符号、特殊字符和超链接等.
本文收集的数据是来自Twitter上关于弗洛伊德事件的英文评论文本. 众所周知,在英文当中,一些词会在不同的情况中有不同的形态,如:名词有单复数,动词有时态和语态,形容词有比较级. 而在本文提出的方法中,这些形态差异是没有意义的甚至有干扰作用,因此需要将不同形态的词转换为其原型,即词形还原. 我们使用的是Python中的自然语言处理工具包NLTK作为词形还原的工具.
面对庞大的数据量,本文将评论文本数据按时间划分成42个时间段,从每个时间段中随机选取适量、均等的评论文本,以缩短运行时间,提高预测效率.
3.2 情感量化
SnowNLP作为一个较成熟的英文情感量化工具,可以快速判断一句话的情感倾向. 此外,SnowNLP的语料主要是电商平台上商品的评论数据,对商品的评论数据进行情感分析的准确率较高. 然而,本文是针对舆情事件的评论数据进行情感分析. 众所周知,相比于本文目标语料——Twitter评论而言,商品评论数据集的情感倾向更明显,情感特征更突出. 因而,若使用SnowNLP,将会因为领域偏差,造成模型预测性能的不确定干扰,不能真实客观地反应本文所提方法的性能和有效性. 另一方面,若使用SnowNLP,需要构建大量人工标注的对应事件的语料库用来替换电商评论语料,人工成本太高. 因此,SnowNLP在本文中的适应性不高,不能适用于本文所讨论的舆情事件情感演变的范畴. 其次,本文使用的是情感交互图结构,选取情感词作为图中的顶点,因此需要对句中每个情感词在不同语义环境下进行分析. 然而,SnowNLP只能给某条评论句进行打分,无法获得某一情感词的具体得分.
另一方面,知网(HowNet)是董振东先生、董强先生父子毕三十年之功标注的大型语言知识库,知网发布的情感词典主要分为中文和英文两个部分,共包含如下数据:中文正面评价词语3730个、中文负面评价词语3116个、中文正面情感词语836个、中文负面情感词语1254个;英文正面评价词语3594个、英文负面评价词语3563个、英文正面情感词语769个、英文负面情感词语1011个. HowNet中的英文情感词典包含积极词、消极词和程度词,可以满足对各个情感词单独进行分析的需求,并且该词典不限于单一领域,适用于各种舆情事件的情感分析.
综上所述,我们结合HowNet设计了一套英文情感量化规则,该规则的跨领域普适性较强,并且不再局限于句子级的情感分析,还可以对处于不同语义环境的的情感词进行更细粒度的情感量化分析.
本文从HowNet词典中选取英文正面评价词语和英文正面情感词语合并去重作为本文的积极情感词典,选取英文负面评价词语和英文负面情感词语合并去重作为本文的消极情感词典. 此外,程度副词往往会对文本的情感强弱程度有很大的影响[15]. 为了精确计算文本的情感值,我们对HowNet中提供的英文程度级别词语按照语气的强弱分为以下6类:极其、非常、很、较、稍微、略微. 需要注意的是,文本中若存在否定词,其情感倾向将会发生逆转,因此我们还加入了否定词词典. 表1列出了各类词典的代表词以及情感权值的设置.
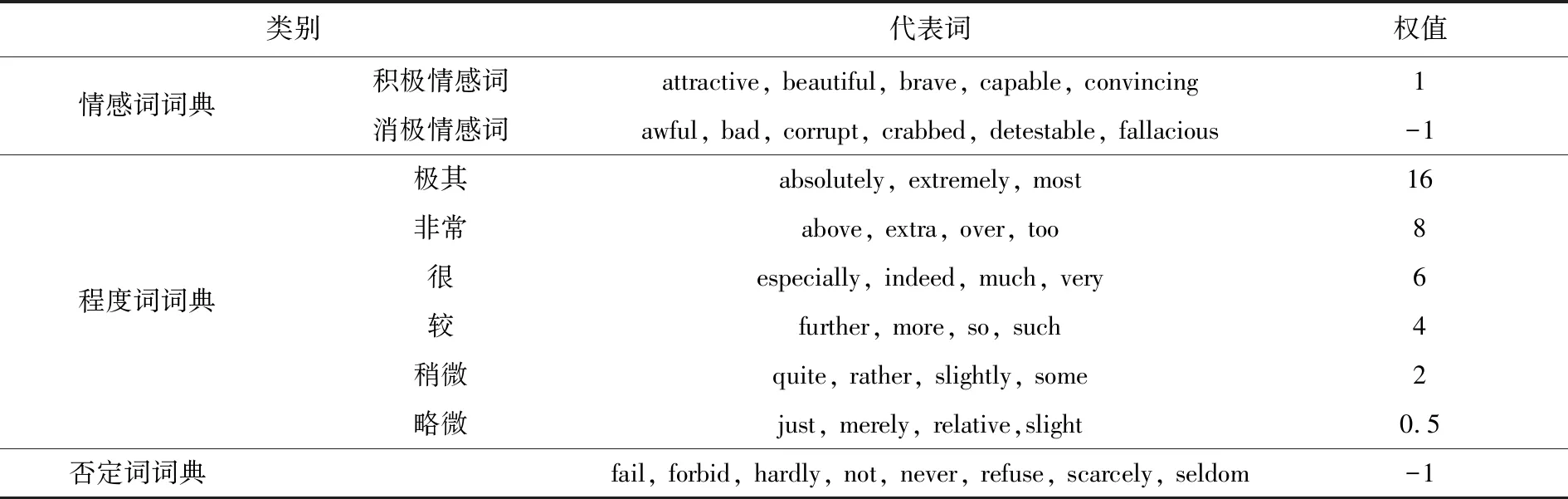
表1 各类词典及情感权值Tab.1 Dictionaries and emotional weights
表1中各类情感词典的权值设定是依据HowNet词典而来的. 在HowNet词典中,已将英文程度级别词语按照语气的强弱分为6类:极其、非常、很、较、稍微、略微,赋予的权值范围为11到64. 而本文的目标语料来自于Twitter,目标事件是弗洛伊德枪击案. 该事件的整个发展过程情感倾向波动幅度较小,各顶点情感词差异性不明显,情感词的语气强弱无太大差异[16]. 因此,为了避免最终计算出的情感得分不利于对评论文本开展进一步的情感量化分析,本文将词语的权值缩小到一个较小且便于分析的范围,其中不同程度级别词语之间的权值比例也是大致依据HowNet词典中的比例来设定的. 该权值范围的选取经过了前期的预实验与分析,但由于该部分预实验的实验结果庞杂,不利于论文的科学性展示,故未将该部分的结果呈现到论文中. 接下来,我们对权值范围的选取做简单描述.
首先,将积极情感词、消极情感词和否定词的权值分别设为1、-1和-1. 再根据HowNet词典中对程度词的分类,将“稍微”这一级别的程度词的权值设为一个较小的值2. 通过分析HowNet词典,我们发现“稍微”、“较”、“很”、“非常”之间的权值间隔不大,因此按照语气强度由低到高,分别将权值依次加2,最终即可得到“非常”的权值为8. “极其”为最高级别的程度词,在HowNet词典中,“极其”的权值是“非常”的2倍,因此赋值为16. 与HowNet词典中不同的是,我们认为“略微”这一级别对应的程度词起到削弱情感词语气强度的作用,因此将权值设为0.5.
确定情感词典之后,基于情感词典对每个评论文本进行逐词匹配,查找文本中所有的积极情感词和消极情感词. 在英文文本中,程度副词既有可能出现在情感词前,也有可能出现在情感词后,因此需要以每个情感词为基准,分别向前、向后依次寻找程度副词,直到查找到下一个情感词为止. 所有查找到的程度词的权重相加即为该词的程度权值. 还需要往情感词前查找否定词,同样的,当查找到下一个情感词就停止搜索,统计出该情感词前面出现的否定词数量. 若否定词的数量为奇数,则该词的否定权值为-1;若为偶数,则该词的否定权值为1. 每个情感词的情感打分规则具体如式(1)所示.
S=(-1)nVeW
(1)
其中,S为情感词的情感得分;n为否定词个数;Ve代表情感词性,值为1表示积极情感词,值为-1表示消极情感词;W是程度权值.
进一步地,将同一时间段内不同评论文本中出现的相同情感词的情感得分相加即可得到该情感词在本时间段的情感得分. 处在不同时间段的同一情感词的得分是不相同的,会根据语义环境的变化而动态改变,更符合情感分析原则. 最后,每个时间段的情感值为该时间段内所有情感词的情感得分之和.
3.3 图结构
对给定时间段内的全部评论文本,在获取到情感词后,我们将该时间段内的评论文本与对应的情感词关联起来构建情感交互图,如图2所示.
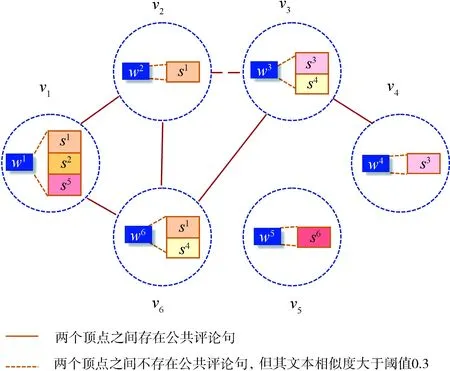
图2 情感交互图Fig.2 Emotional interaction diagram
交互图中的顶点是在该时间步长内出现的情感词,若评论文本中存在情感词w,则将该条评论s归属到对应的顶点v. 一个顶点可以包含多条评论,一条评论也可以分配给多个顶点. 该映射关系也间接反映出两个情感词关联的公共评论文本越多,所表达的情感越接近.
在本文中,我们提出一种基于文本结构和文本内容联合的方法,用于构造顶点之间的边. 顶点vi和顶点vj所关联的评论文本的TF-IDF文本相似度为Tij. 如果所关联的评论文本存在公共评论,公共评论的数量为N,则在这两个顶点之间添加一条边eij,其权值wij为
(2)
其中,a、b分别为Tij转化为最简分数后的分子和分母. 文本相似度的阈值α设为0.3,若两个顶点之间不存在公共评论,但其文本相似度Tij大于或等于α,则同样在vi和vj之间添加一条边eij,其权值为
wij=Tij
(3)
3.4 建立预测模型
现有的基于图神经网络的预测模型,大多是以图神经网络作为特征提取器,得到节点的嵌入向量,再利用循环神经网络进行序列学习[17-20]. 这些方法需要节点在整个时间跨度的信息,在某些极端情况下,不同时间步长的节点集可能完全不同,因此不太适用于节点集频繁变化的场景. Pareja等[13]提出使用循环神经网络将动态性注入到图卷积网络的参数中,形成一个演化序列,该方法可以有效应对这一挑战.
本文在此基础上将注意力机制引入到基于空间域的图神经网络,不仅可以捕获图的动态性,还实现对不同邻居权重的自适应分配[21,22]. 图注意力网络用注意力机制对邻居节点特征加权求和,邻居节点特征的权重完全取决于节点特征,独立于图结构. 图中的每个节点可以根据邻居节点的特征,为其分配不同的权重. 此外,注意力机制以共享的方式应用于图中的所有边,因此它不依赖于对全局图结构的预先访问,也不依赖于对所有节点特征的预先访问.
预测模型由图注意力网络和门控循环单元组合而成,以图注意力网络为基础,引入门控循环单元来更新网络参数. 图结构中的节点特征沿着图注意力网络进行层层卷积,得到该时间段的节点嵌入矩阵,同时,权重矩阵利用门控循环单元随着时间的推移演化. 权重参数矩阵在第l层的动态演化过程如下.
(4)
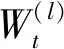
(5)
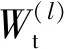
模型输入第t个时间段到第t+x个时间段的图结构,再使用多层感知机MLP,即可通过x个图结构信息预测下一时间段即第t+x+1时间段的可能出现的情感词及对应得分,将所有得分相加作为该时间段预测得到的情感值. 预测的情感词均来自事先构建好的情感词典.
4 实验及评估
4.1 数据集
本文以弗洛伊德事件为研究对象进行情感趋势演变预测. 在收集数据集时,我们发现该舆情事件的讨论时间跨度主要集中在2020年5月26到2020年6月8日,这14天内. 其中,2020年5月26日为弗洛伊德事件发生的起始时间,在此之前Twitter上没有该事件的相关讨论;而在2020年6月8日后,只能找到极其少量的相关话题,表明此时针对该事件的舆论已经基本结束,不需要再进行演变分析. 因此,为了确保舆情事件预测的准确性和可靠性,我们从Twitter上爬取了弗洛伊德事件整个生命周期即14天内的全部相关评论文本,并将数据进行划分. 数据划分方案为:每8个小时为一个时间步长,一天分为3个时间段,那么14天可以划分为42个时间段. 从每个时间段随机选取500条评论文本数据作为图结构的数据输入,避免数据量过大导致模型训练和预测消耗大量时间,无法做到快速预测.
4.2 实验指标
回归预测算法的评价指标包括平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)和R2(R-Square)决定系数等,计算公式如下.
(6)
(7)
(8)
(9)
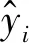
平均绝对误差、均方误差和均方根误差的值越小,表明模型的拟合效果越好,但是这些评价指标也具有一定的局限性. 同一个模型,在不同的实际应用中,数据的量纲不同,导致这些评价指标无法直接进行比较,不具有可读性. 因此本文主要使用R2决定系数对预测模型进行评价.
R2是多元回归中的回归平方和占总平方和的比例,它是度量多元回归方程中拟合程度的一个统计量. 其值越接近1,表明回归平方和占总平方和的比例越大,回归线与各观测点越接近,回归的拟合程度就越好. 通俗理解,R2值为1表示在理想状况下,该模型对所有的观测值预测准确,没有偏差;R2值大于0小于1是常见状况,表明该模型的拟合水平比均值模型好,越接近1代表模型预测越准确;R2值等于或小于0时,该模型没有实际价值.
4.3 实验环境及参数设置
本实验在GPU型号为NVIDIA GeForce RTX 3080,显存为10 G的服务器中完成,所用的编程语言为python 3.6,深度学习框架为pytorch 1.8.1.
每次利用6个时间段的图结构信息对下一时间段的情感值进行预测. 按照7∶3的比例将42个时间段的数据集以时间维度划分训练集和测试集,训练集中应该减去前6个时间段的数据,因此训练集为23个,测试集为13个. 情感词典中积极情感词语和消极情感词语共4735个,对应着图结构中的节点. 每个节点的特征数为5,用随机向量进行初始化. 采用RMSprop优化器对参数进行更新,参数的学习率设置为0.00001. 为防止过度拟合,将dropout比率设置为0.5.
4.4 实验结果与分析
据我们所知,现有的基于社交网络平台的评论文本对舆情事件开展回归预测的研究较少,目前尚未找到相对成熟的可以进行对比的研究工作或算法. 针对弗洛伊德事件数据集,我们将本文提出的基于图注意力网络的预测模型和Pareja等[13]提出的基于图卷积网络的预测模型在情感趋势演变预测上的性能进行对比,如表2所示.
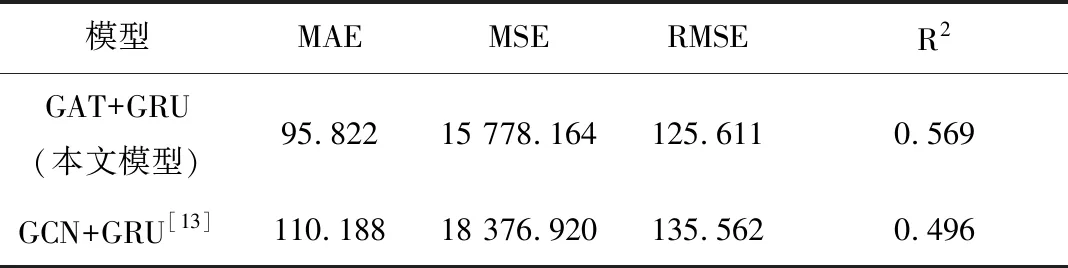
表2 模型预测性能对比Tab.2 Comparison of model prediction performance
由表2可知,在同一数据集,相同的情感量化方式下,基于图注意力网络的回归预测模型的MAE、MSE和RMSE值都小于基于图卷积网络的预测模型,说明本文提出模型预测出的情感值与真实情感值之间的误差更小. 同时,本文模型的R2决定系数也更接近于1,代表其预测性能更高,预测结果更准确.
本文的创新点在于,充分利用评论文本的语义关系、结构特性,将文本转化为图结构,再通过当前广受关注和应用的图卷积网络提取特征,并进行预测建模. 同时,为进一步优化该模型的性能,引入了注意力机制,在捕获图动态性的同时,实现了对不同邻居权重的自适应分配. 实验结果表明,引入注意力机制后模型的性能得以提升. 因此,本文提出的方法不仅在情感趋势演变预测方面取得了较好的效果,这也是图神经网络应用于演变预测领域的一个有效改进方案.
图3为每个时间段预测的情感值与真实的情感值绘制而成的折线图,从图中我们可以看出,本文提出的模型在对弗洛伊德事件的情感趋势演变预测上取得了较好的效果.
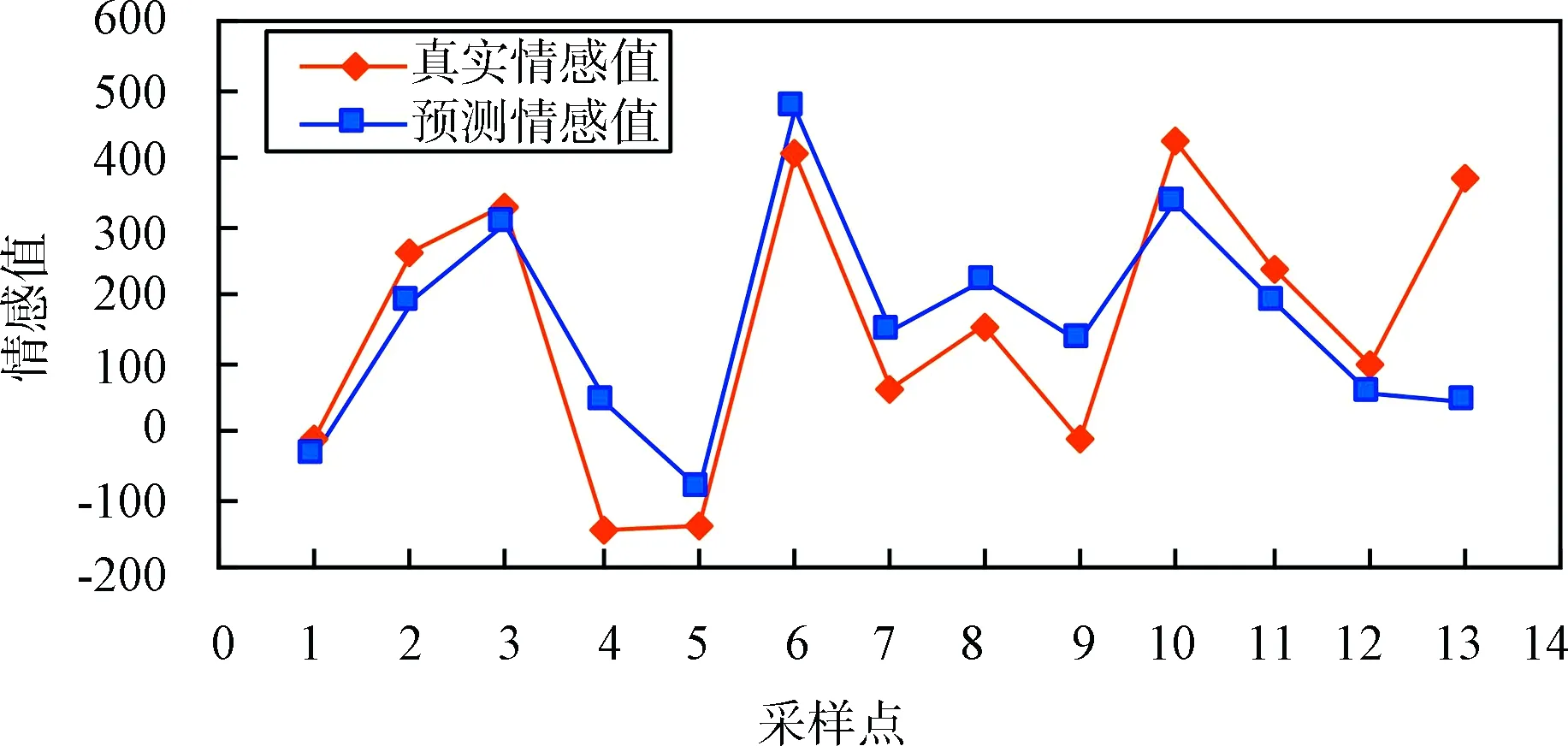
图3 预测情感值与真实情感值对比图Fig.3 Comparison of predicted and real sentiment values
5 结 论
本文提出一种基于评论文本的舆情事件情感趋势演变预测方法. 根据社交平台上针对某个舆情事件的评论文本计算出事件在每个时间段的情感得分,以此反映大众对该舆情事件的情感态度变化. 该方法将评论文本的情感值作为演变预测的对象,利用情感词和舆情事件中评论文本的语义相似度为事件发展的每个时间段都构造一个对应的图结构,再结合门控循环单元与图注意力网络构建预测模型对情感时间序列预测. 实验结果表明本方法能较为准确地对短期事件进行动态预测,为网络舆情事件的预警提供帮助. 证明了本方法在情感趋势演变预测方面的有效性. 后续工作将致力于进一步优化演变预测方法,使该方法能在网络舆情事件的预警中发挥更积极的作用.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
养生阅刊(2021年6期)2021-06-28
领导决策信息(2017年13期)2017-06-21
领导决策信息(2017年9期)2017-05-04
意林(2017年8期)2017-05-02
消费电子(2016年12期)2017-01-19
新东方英语(2016年11期)2016-11-11
科技视界(2016年1期)2016-03-30
物联网技术(2015年7期)2015-07-21
滇池(2014年5期)2014-05-29
