
基于弱监督学习的玉米苗期植株图像实例分割方法
2022-02-06 00:53赵亚楠邓寒冰赵露露张羽丰
农业工程学报 2022年19期
赵亚楠,邓寒冰,2,刘 婷,赵露露,赵 凯,杨 景,张羽丰
基于弱监督学习的玉米苗期植株图像实例分割方法
赵亚楠1,邓寒冰1,2※,刘 婷1,赵露露1,赵 凯1,杨 景1,张羽丰1
(1. 沈阳农业大学信息与电气工程学院,沈阳 110866;2. 辽宁省农业信息化工程技术研究中心,沈阳 110866)
基于有监督深度学习的图像分割任务通常利用像素级标签来保证模型的训练和测试精度,但受植株复杂形态影响,保证像素级标签精度的同时,时间成本也显著提高。为降低深度模型训练成本,同时保证模型能够有较高的图像分割精度,该研究提出一种基于边界框掩膜的深度卷积神经网络(Bounding-box Mask Deep Convolutional Neural Network,BM-DCNN),在有监督深度学习模型中融入伪标签生成模块,利用伪标签代替真值标签进行网络训练。试验结果表明,伪标签与真值标签的平均交并比为81.83%,平均余弦相似度为86.14%,高于Grabcut类方法生成伪标签精度(与真值标签的平均交并比为40.49%,平均余弦相似度为61.84%);对于玉米苗期图像(顶视图)计算了三种人工标注方式的时间成本,边界框标签为2.5 min/张,涂鸦标签为15.8 min/张,像素级标签为32.4 min/张;利用伪标签样本进行训练后,BM-DCNN模型的两种主干网络当IoU值大于0.7时(AP70),BM-DCNN模型对应的实例分割精度已经高于有监督模型。BM-DCNN模型的两种主干网络对应的平均准确率分别为67.57%和75.37%,接近相同条件下的有监督实例分割结果(分别为67.95%和78.52%),最高可达到有监督分割结果的99.44%。试验证明BM-DCNN模型可以使用低成本的弱标签实现高精度的玉米苗期植株图像实例分割,为基于图像的玉米出苗率统计以及苗期冠层覆盖度计算提供低成本解决方案及技术支持。
实例分割;深度学习;弱监督学习;玉米;植物表型
0 引 言
在深度学习技术普及之前,实现图像目标检测和图像分割等任务主要依赖于人工设计的局部特征,利用图像特征的抽象信息概括全局信息,进而区分图像中的不同区域和不同对象。但如何描述局部特征需要极强的专业领域知识,在验证局部特征有效性上也需要耗费大量人力,而且人工描述的特征也往往依赖于图像场景,不具有普适性。近些年,随着深度学习技术的发展,借助深层卷积神经网络可以从图像中学习具有不同层次的特征表述,通过特征融合以实现更加精准的视觉任务。目前,主流的计算机视觉技术任务可以分为图像分类、目标检测、图像分割等,其中图像分割领域的实例分割是最具挑战性的任务之一。要实现图像实例分割,不仅需要对图像中的对象进行精确定位,还要对每个实例进行像素级别的分类,因而同时具备了目标检测和语义分割的功能。从技术发展的趋势以及应用效果看,基于深层卷积神经网络的图像实例分割方法已经成为该领域的首选技术[1-3]。深度学习技术对图像复杂特征的描述和融合能力得到了植物表型研究领域的关注,由于其能自动完成对图像中植物复杂形态的精准描述,已经有很多成熟的植物表型平台、模型和技术方法是在深度学习模型基础上演变而来[4-7]。
但深度学习技术的应用需要大量的可训练数据,这样才能充分发挥深层卷积神经网络强大的特征提取和图像分析能力。由于图像实例分割的训练样本需要使用像素级的掩膜信息,这也直接提高了人工标注成本,特别是面对植物表型领域的图像样本,其图像的多样性、植株形体的复杂性、海量的样本数都导致无法高质量、高效率的实现训练样本的人工标注。Amy等[8]对样本标注方式进行了比较,对平均包含2.8个对象的图像进行像素级标注大概需要4 min,而对于单一植物性状特征的像素级标注时间成本要增加2~3倍。因此,为了降低样本的人工标注成本,有研究人员提出了基于弱监督学习的实例分割方法。基于弱监督学习的实例分割是在弱标签的监督下,对图像中感兴趣目标进行分类、定位和分割,这减少了实例分割模型对像素级信息的过度依赖,在粗粒度的范围下实现图像特征提取和解析。目前,考虑到模型稳定性以及实现成本,基于弱监督学习的实例分割模型较多采用两段式结构,其实现流程为:1)在弱标签基础上自动生成实例分割所需的像素级伪标签;2)在伪标签的监督下训练一个有监督实例分割网络。这种方式是在有监督深度学习模型的基础上,根据伪标签的特性和质量,完善并实现全监督实例分割网络,进而减少弱监督训练标签对实例分割的限制。弱标签的标注方式和特征表达对于生成伪标签的质量以及图像分割的精度影响比较大。目前,弱监督学习的实例分割方法从标签类型上区分主要包括:基于边界框的弱监督图像分割方法[9-11]、基于涂鸦信息的弱监督图像分割方法[12-13]、基于图像类别标签的弱监督图像分割方法[14-16]等。这些方法的共同特点是标注的对象信息不如像素级信息精确,但相比起无监督学习方法又给出了更有效的特征区域和特征信息。从时间成本上看,最容易获得的弱标签是类别标签,用类别标记图像大约需要20 s,但它只描述了某些类别的对象,并且没有给出它们在图像中的位置信息,对于分离同一类的不同对象也没有帮助。边界框注释每幅图像大约需要38.1 s[17],虽然增加了标注的时间成本,但边界框提供有关单个对象及其位置的信息,这比构建像素级掩膜更有吸引力。许多研究人员已经开展了基于边界框的图像语义分割[18]和图像实例分割[19-21]方法研究,将边界框注释作为搜索空间,通过对象掩膜生成器可以在其中找到类不可知的对象掩膜。这些掩膜生成器中,有的使用概率图模型(如条件随机场[22]和GrabCut[23])、有的使用图像的底层特征作为二元约束项进行多尺度组合分组(Multiscale Combinatorial Grouping,MCG)[24],有的利用图像RGB颜色空间[25],还有利用图像中的边缘特征。Rajch等[26]提出从边界框获取像素级标签的DeepCut方法,该方法通过迭代密集条件随机场和卷积神经网络模型来扩展Grabcut方法,可以实现给定边界框的神经网络分类器训练,将分类问题看作稠密连接的条件随机场下的能量最小化问题,并不断迭代实现实例分割。Khoreva等[27]使用边界框标签训练弱监督实例分割模型,该方法使用类似Grabcut算法,从已有边界框标签中获得训练标签,将训练标签放入全监督模型中训练实现实例分割。Hsu等[28]假设给出的所有边界框都是紧密贴合的,采用多任务学习解决紧密边界框内前景与背景不明确问题,该方法在每个边界框内遍历扫描生成正负框,并将多任务学习集成到弱监督实例分割网络中,通过对边界框内前景、背景的判断以及掩码的对应推导出最终的实例掩码。Tian等[29]提出每个像素点预测在坐标轴上的位置投影损失函数,利用边界框内相同颜色可能属于同类物体的先验计算像素点之间的相似性损失函数,通过这一策略能够有效解决监督标注信息缺失的问题。Boxsup算法[30]、Box-driven算法[31]从边界框标注信息中获取到像素级分割,进行语义分割模型的训练。上述方法在解决非农业场景图像分割问题时给出了一些有效的方案,但对于大田环境下的苗期玉米图像实例分割问题,由于玉米种植密度较高,图像中存在植株间交叉、植株与阴影形态相似等问题,这都会导致利用弱标签来生成的伪标签与真值(Ground truth)相差过大,严重影响伪标签的质量,降低了模型的实例分割精度。
为了解决这一问题,本文提出一种基于弱监督深度学习的苗期玉米植株图像实例分割方法,利用边界框信息在图像上产生弱标签,同时将图像的RGB颜色模型转换为HSV颜色模型,并配合使用全连接条件随机场消除图像中植株影子以及图像噪声对伪标签精度的影响,将伪标签代替真值标签对优化后的YOLACT模型[32]进行训练,最终得到可以用于玉米苗期植株实例分割的模型。
1 材料与方法
1.1 试验材料和数据采集
试验选取的玉米品种是“先玉335”。该品种幼苗时期长势较强,幼苗叶鞘紫色,叶片、叶缘绿色,株型紧凑,叶片上举,全株叶片数20片左右,具有抗玉米瘤黑粉病、灰斑病、纹枯病和玉米螟,高抗茎腐病,中抗弯孢菌叶斑病等,其优越的抗病性可以让玉米在整个生长周期保持植株健康。
试验主要采集玉米苗期植株的顶视图像,为了保证数据采集效率和图像质量,试验选用大疆的“精灵4-RTK”无人机,起飞质量1.39 kg,续航时间约为30 min,最大水平飞行速度为50 km/h,相机分辨率为5 472×3 078像素,所有参数能够满足本试验的要求。在利用无人机进行原始图像采集时,为了保证玉米苗期植株形态的稳定,拍摄时的风力应小于3级且天气晴朗,采集时间为9:00-11:00,航飞高度控制为6 m。飞行采用自动起飞规划的航线,整个航线覆盖玉米植株生长的全部试验田。
经过初步人工筛查,共为试验挑选出1 000张玉米苗期群体顶视图像。其中800张图像(80%)作为训练样本集,100张图像(10%)作为训练过程中阶段性检验模型的验证样本集,100张图像(10%)作为模型最终的测试样本集。
1.2 真值标签和弱标签获取
本文提出基于弱监督深度学习的图像实例分割方法,训练样本的标签是非像素级的弱标签(Weak labels),利用弱标签来产生像素级的伪标签(Pseudo labels),进而完成模型训练。因此,为了验证伪标签的精度以及模型的分割效果,本试验需要准备两种类型的标签:一是像素级别的真值标签(Ground truth labels),另一种是弱监督标签。其中真值标签用在测评伪标签质量以及最终的模型分割精度,而弱监督标签用来产生伪标签并训练模型。
由于在图像上标注真值标签和弱监督标签都需要人工参与,所以本文选用开源的Labelme标注工具,对原始玉米苗期植株的顶视图像进行两次标注(如图1所示)。试验选用边界框(Bounding box)作为弱监督标签的基本形状,边界框区域内的像素被标记为前景(即玉米植株区域),边界框外部的像素被标记为背景。其中图1b是有监督学习对应的像素级真值标签,图1c是本研究使用的边界框标签。从图1中的对比可以看出,利用边界框作为标签区域会附带很多背景像素,但是由于标注方式简单,人工标注的时间成本远远低于像素级别的标注方式。此外,为了保证深度学习模型训练样本多样性,试验对现有的样本集进行图像增强,对800张训练样本进行90°旋转、180°旋转、镜像、亮度增强操作,将训练集扩增到3 200张。

a. 原始图像a. Original imageb. 像素级真值标签b. Pixel-wise ground truth labelsc. 边界框标签c. Bounding-box labels
1.3 模型框架及硬件平台
本文以边界框作为实例分割样本的标签形态,提出一种基于边界框掩膜的深度卷积神经网络(Bounding-box Mask Deep Convolutional Neural Networks,BM-DCNN)模型,利用弱标签提供的前景信息实现网络参数的训练。整个过程如图2所示,包括以下3个主要步骤:1)图像中玉米植株的弱标签获取,即使用标注工具(本试验使用Labelme)对图像中的玉米植株进行边界框标注;2)利用弱标签生成像素级伪标签,首先通过颜色空间转换优化图割方法生成的伪标签,利用HSV颜色模型的各分量阈值减少图割结果中的背景像素,再使用全连接条件随机场消除图像中植株影子以及植株附近噪声对伪标签精度的影响,最终得到伪标签;3)利用伪标签训练实例分割网络,将伪标签代替真值信息监督模型训练过程并对模型进行测试和评价。
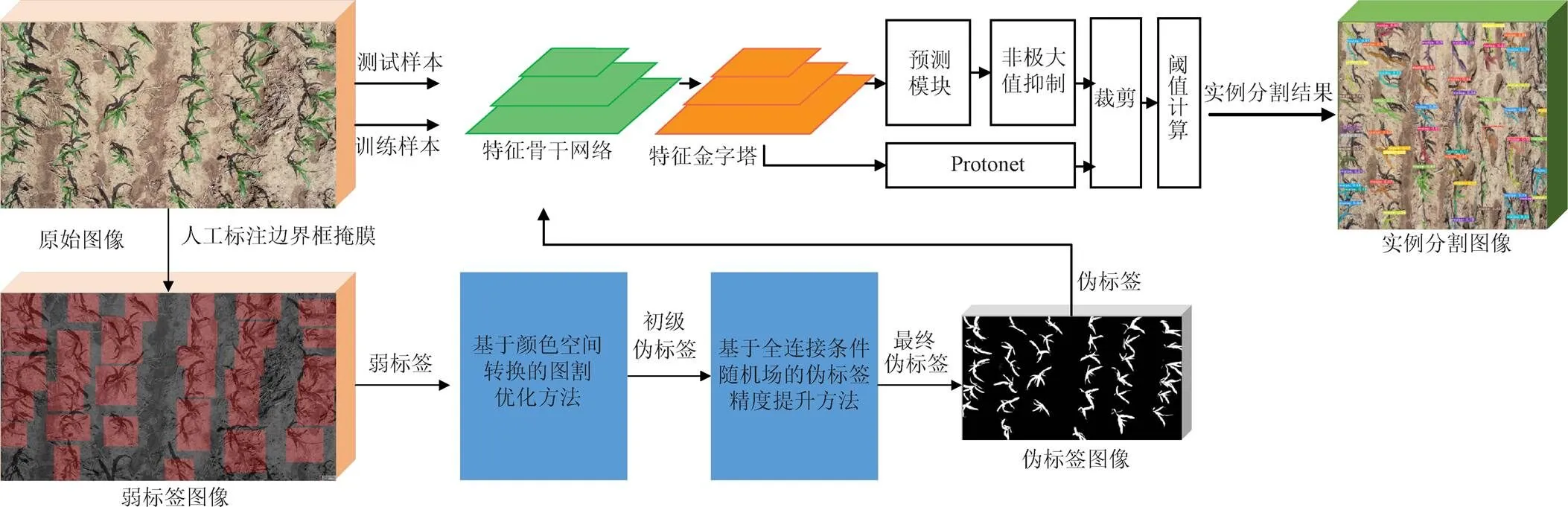
图2 边界框掩膜深度卷积神经网络
在试验的模型训练过程中,需要对不同标签形式的样本进行训练和测试对比,为保证训练、测试过程的公平性,本试验将模型对应的训练任务放到同一硬件平台上完成。试验平台采用Dell Precision 7920,内存为64 GB,中央处理器主频为2.1 GHz,中央处理器核心数为16,图形处理器(Graphic Processing Pnit,GPU)为NVIDA 2080Ti,图形处理器显存为11 GB,图形处理器核心数为4 352。
2 边界框掩膜深度卷积神经网络(BM-DCNN)
2.1 基于颜色空间转换的图割方法优化
图像采集过程由于受太阳光的直射干扰,玉米植株会在附近区域产生较大面积的阴影,因此在进行边界框标注时,这些阴影与植株本身被同时标注为前景信息,该部分植株阴影会对伪标签的准确度产生巨大影响,特别是在算法本身需要使用图像的纹理和边界等信息对前景分割时(比如Grabcut),由于植株阴影与植株本身边缘信息高度相似,因此阴影部分的像素也经常被误认为是植株区域,将阴影与真正的植株区域进行合并处理,这会导致伪标签与真值之间的误差过大,利用这样的伪标签来训练模型,收敛后的模型输出精度普遍较低。
由此可见,本试验中边界框区域的植株阴影是影响伪标签精确度的重要因素,去除植株阴影是提高伪标签精度的必要步骤。考虑到玉米植株与其阴影在RGB颜色直方图中存在较多重叠区间,而相比于RGB颜色空间模型,HSV颜色空间模型更加符合人类对颜色的描述和解释,试验首先将图像从RGB颜色空间转换成HSV颜色空间。将RGB图像进行通道分离,分离后分别对、、三通道,按照式(1)进行归一化处理,分别获得、和。
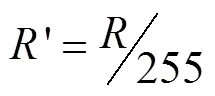
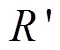
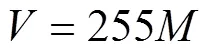

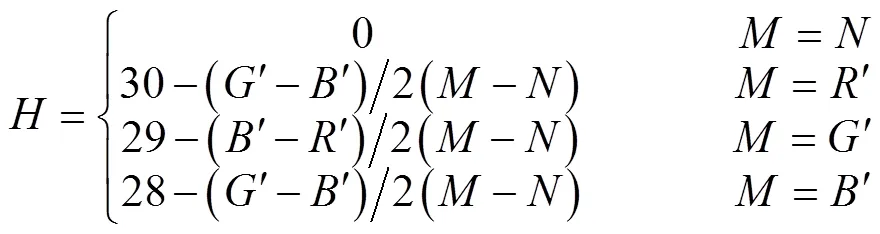
式中的、、分别代表RGB图像在HSV颜色空间模型中转换之后的数值。通过HSV的各分量直方图(图3)可以看出,植株与阴影对应的像素之间存在明显的波谷区域,以、、各通道的波谷区域作为区分植株和阴影的阈值选取区间,经过抽样和筛选最终确定通道的取值范围是[35,77],通道的取值范围是[43,200],的阈值范围是[46,255]。
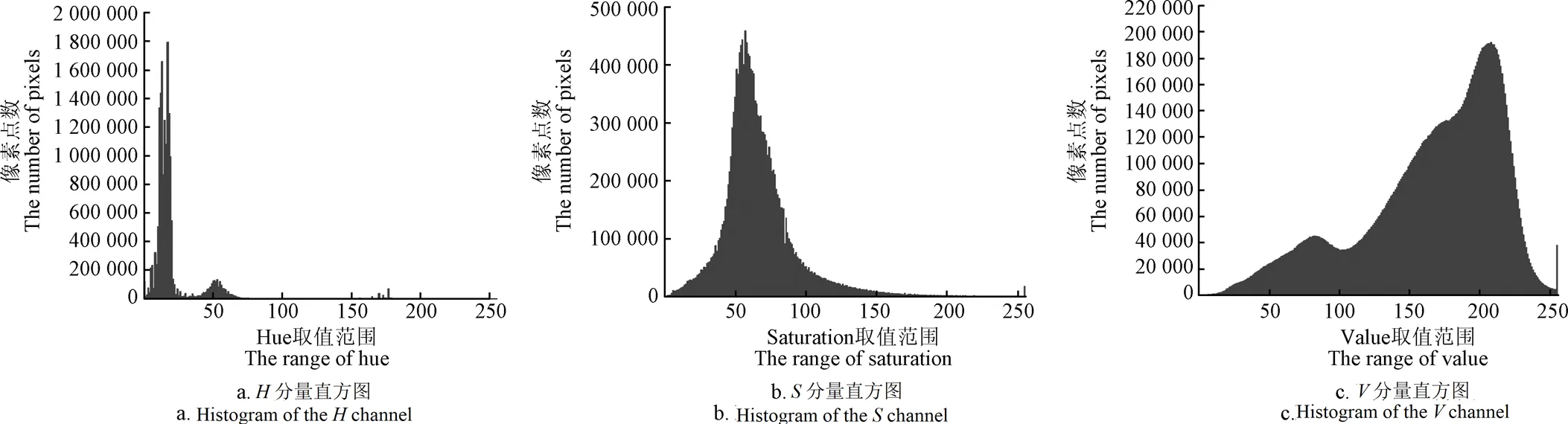
图3 玉米植株图像H、S、V分量直方图(统计值)
利用HSV三个通道的阈值范围,在图像的所有边界框区域中去除玉米植株阴影部分,可以获得边界框区域内的初级伪标签(Primary Pseudo Label),如图4c所示。
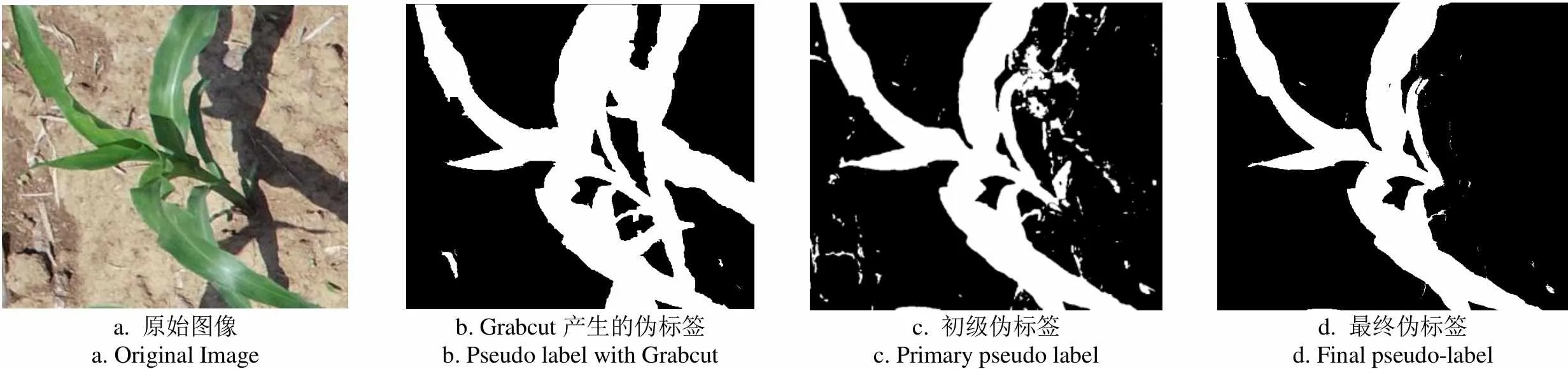
a. 原始图像a. Original Imageb. Grabcut产生的伪标签b. Pseudo label with Grabcutc. 初级伪标签c. Primary pseudo labeld. 最终伪标签d. Final pseudo-label
2.2 基于全连接条件随机场的伪标签精度提升方法
由于初级伪标签中存在大量无效像素区域(如图4c所示),其与真值标签之间仍存在较大精度差距,利用初级伪标签进行训练时,无效像素会影响模型收敛过程。通过观察,无效像素区域通常在图像中是孤立的,而植株区域的像素都是连通的,因此可以从全局像素间的位置和距离来判断像素类别。因此,为获得精度更高的伪标签图像,本文选用全连接条件随机场(Dense Condition Random Field,DenseCRF)对初级伪标签进行二次优化。
全连接条件随机场是目前图像分割中常使用的一种图像后处理方式,它是条件随机场(Condition Random Field,CRF)的改进模式,可以结合原图像中所有像素之间的关系对已有分类结果进行处理,优化已有分类中粗糙和不确定的标签,修正细碎的错分区域,得到更精细的图像前景边界。为了更加精准地生成边界框标注内的玉米植株像素信息,本文利用DenseCRF对初级伪标签进行像素级二次优化。其中DenseCRF的能量函数由一元势函数和二元势函数构成,如式(5)所示:
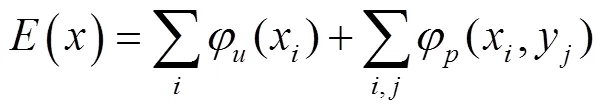
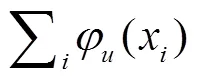
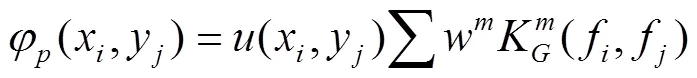
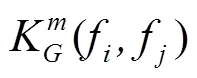
利用DenseCRF对初级伪标签进行优化并获得伪标签,单个边界框弱标签的图像结果如图4d所示。图5给出了无人机拍摄的玉米植株图像上生成初级伪标签和伪标签图像的效果图,从图中可以看出,DenseCRF消除了初始标签图中植株附近的大量的噪声点,降低了伪标签与真值图像的精度差。

a. 原始图像a. Original imageb.初级伪标签b. Primary pseudo-labelc. 最终伪标签c. Final pseudo-label
2.3 伪标签精度评价指标
由于BM-DCNN是利用弱监督标签来产生像素级伪标签,进而代替像素级真值标签完成模型训练,为了验证伪标签的精度,本研究选取两种评价指标,分别是平均交并比,平均余弦相似度。平均交并比(Mean Intersection over Union,mIoU)如式(7)所示:
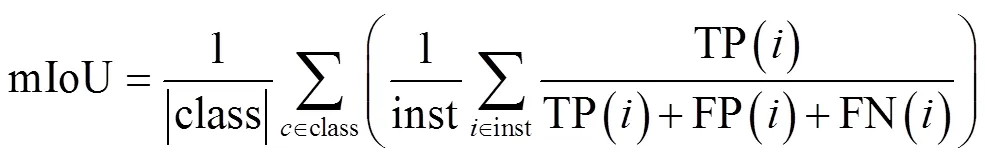
式中inst表示图像中全部实例集合,TP()表示第个实例的真正例,FP()表示第个实例的假正例,FN()表示第个实例的假负例,class表示图像集中的类别集合,因为本研究中只针对玉米植株进行处理,因此|class|=1。
此外,本研究还利用余弦相似度来验证伪标签精度,通过比较空间向量中两个向量夹角的余弦值来衡量个体之间的差异。当余弦值越接近于1,代表两个个体之间的夹角越小,两个向量之间越相似。假设向量和是多维向量,那么向量和向量之间夹角的余弦值计算公式如下:
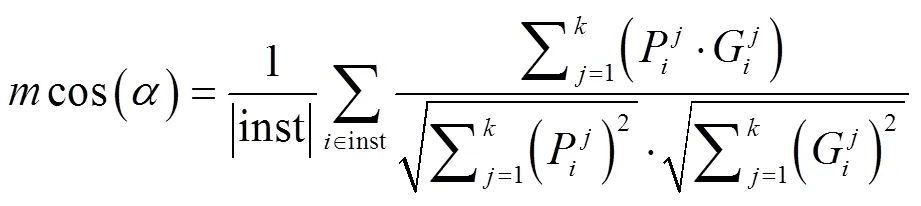
除本文方法外,选取常用的3种伪标签生成方式,利用上述评价标准对不同方法产生的伪标签与真值标签对比,结果如表1所示,对于大田环境下苗期玉米植株数据集,伪标签与真值标签的平均交并比为81.83%,平均余弦相似度为86.14%,明显优于初级伪标签与真值标签的平均交并比(mIoU=75.33%)和平均余弦相似度(cos()=74.77%),线标注产生的伪标签与真值标签的平均交并比(mIoU=70.50%)和平均余弦相似度(cos()=79.69%)以及Grabcut产生的伪标签与真值标签的平均交并比(mIoU=40.49%)和平均余弦相似度(cos()=61.84%)。
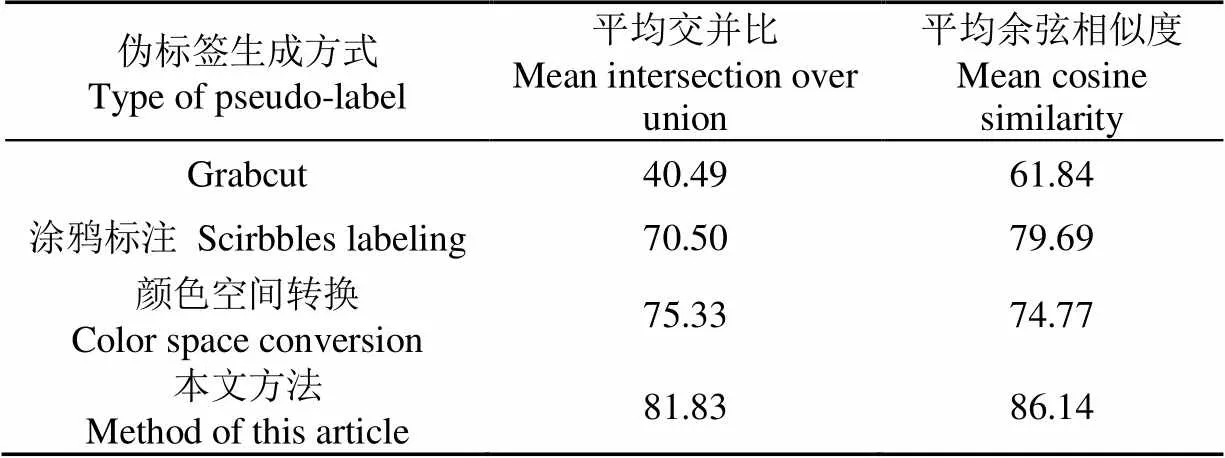
表1 伪标签与真值标签对比结果
图6分别给出了真值标签(图6b)、Grabcut伪标签(图6c)、涂鸦标注伪标签(图6d)和本文方法得到的伪标签(图6f),其中图6f已经去掉了初级伪标签(图6e)中大部分的噪声像素以及Grabcut伪标签和涂鸦标注伪标签中的错误标注区域。
2.4 实例分割网络选择和优化
为了满足实例分割精度和分割实时性要求,本研究选择YOLACT(You Only Look At Coefficients)实例分割模型作为BM-DCNN的基础模型。YOLACT是基于目标检测模型开发的实例分割模型,模型结构见图7,在目标检测基础上增加了掩膜分支,将实例分割过程划分成两个并行分支:一是掩膜分割,通过全卷积网络[33](Fully Convolutional Networks,FCN)生成与输入图像大小一致的原型掩膜(Prototype masks),该分支不依赖于特定实例,单个实例是在检测结果上通过剪裁得到的;二是目标检测,针对图像锚点(Anchor)预测掩膜系数,来获取图像中实例的坐标位置,最后通过非极大值抑制(Non-Maximum Suppression,NMS)筛选,将模型的两个分支利用线性组合来获得最后的预测结果。

a. 原始图像a. Original imageb. 真值标签b. Ground truth labelsc. Grabcut伪标签c. Grabcut pseudo-label d. 涂鸦标注伪标签d. Graffiti labeling pseudo-labele.初级伪标签e. Primary pseudo-labelf. 优化后的伪标签f. Optimized pseudo-label
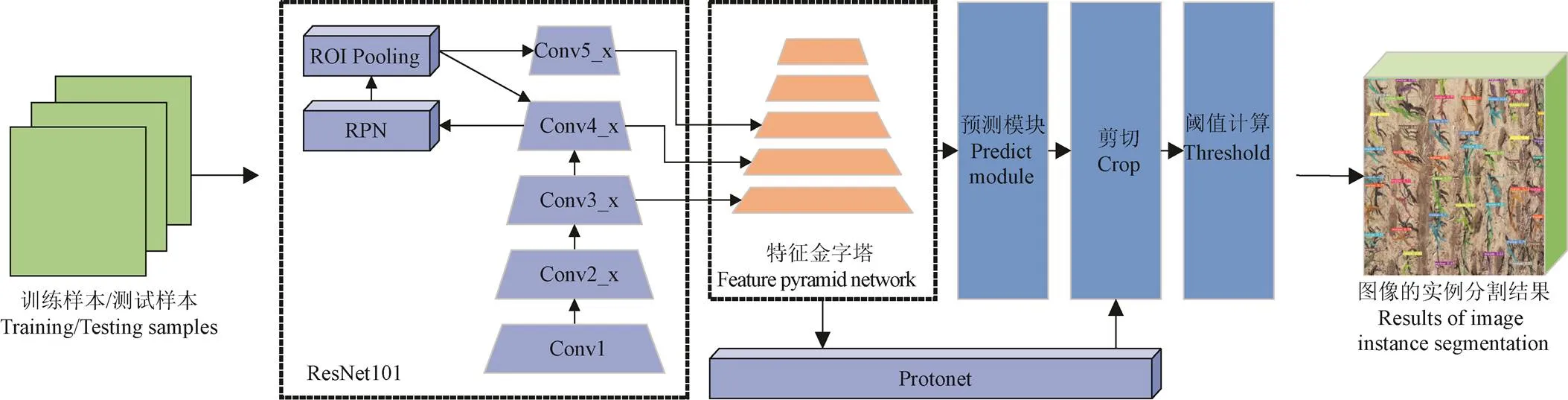
注:ROI Pooling是指感兴趣区域池化,RPN表示区域生成网络,Conv表示卷积核。
文献[27]中使用ResNet101作为整个模型的特征提取网络,但本试验使用的数据集规模要远小于公共数据集(如ImageNet、COCO),因此该模型的固有参数数量和层数都容易在小规模数据集上出现过拟合或梯度爆炸问题,因此在试验中,对YOLACT框架进行改造,分别用ResNet50-FPN和Darknet53作为基础网络,替代ResNet101进行特征提取。此外,试验中使用动量(Momentum)优化器来训练和优化网络,具体如式(9)所示:
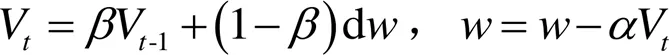
式中V是指数加权平均计算出的速度,是Momentum动量,d是原始梯度,是未训练的网络参数,是学习率。由于模型学习速度与学习率有关,将训练的初始学习率设为0.01。此外,在大量的深度学习实验中发现初始动量为0.9时模型鲁棒性较强,因此将初始动量设置为0.9。由于NVIDA 2080Ti图形处理器GPU显存上限为11GB,考虑训练样本分辨率较高,所以将训练批次尺寸(batch size)设置为8,在训练过程中,每轮训练步数为3 000,训练轮数上限数为100,每完成一次全样本迭代后对模型进行阶段验证,同时降低学习率,使得模型逐步趋向收敛。经过模型微调,动量始终保持在0.9,学习率稳定在0.000 1,在上述参数的约束下YOLACT模型能够快速收敛。
因为样本数量有限,即使采用数据增强也无法满足网络中多层参数的充分训练,为了让网络模型能够更好地实现特征提取,本研究选择在预训练好的模型上进行微调(fine-tuning)的方式来训练BM-DCNN的基础模型,即基于迁移学习(Transfer learning)[34]方法来解决此问题,利用迁移学习可以让模型从不同领域学习到的特征应用于特定领域。本研究中将在COCO数据集上训练的特征提取网络参数迁移到BM-DCNN的主干网络中,以提升模型对多种玉米植株图像的特征敏感度,最终实现玉米植株图像实例分割。
3 结果与分析
由于YOLACT模型中的ResNet101作为模型的特征提取网络的参数较多,对于本试验中的数据集规模容易出现训练不充分的情况,因此试验更换了特征提取网络,以适应本试验的数据集特点。图8给出了模型在训练过程中损失函数的变化情况,可以看出在使用预训练参数对基础模型赋值之后,无论使用ResNet50-FPN还是Darknet53作为基础网络,BM-DCNN模型的在训练过程中损失值随着训练轮数的增加,都呈现出明显的下降趋势。通过对比,ResNet50-FPN和Darknet53两种模型的模型深度适中,训练时间成本可控,训练过程中的损失函数值收敛趋势明显,因此选择这两种网络作为模型的特征提取网络。
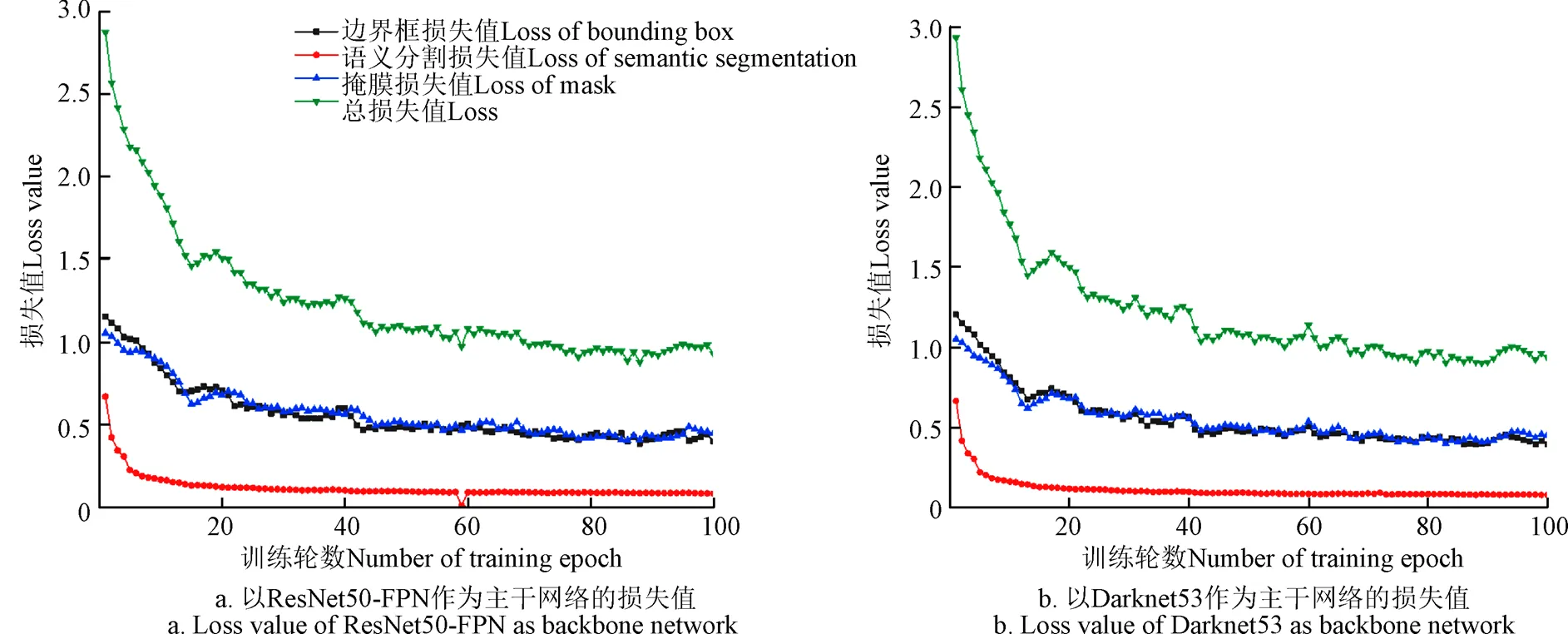
图8 基于迁移学习的BM-DCNN模型在训练中的损失值
基于这两种模型提取的特征信息,试验对比了有监督模型与弱监督模型在测试集上的分割精度(如表2所示)。掩膜对应图像中玉米植株实例分割掩模的平均精确度。其中AP50、AP55、AP60和AP70分别代表分割结果与真值之间的交并比值大于等于0.5、0.55、0.6和0.7时的平均精度。
由表2可知,用Grabcut伪标签和涂鸦标注伪标签代替真值标签训练时,在ResNet50-FPN和Darknet53两种训练条件下,掩膜的平均精度在AP50、AP55、AP60和AP70远低于BM-DCNN,这表明本文方法生成的伪标签代替真值标签进行实例分割模型训练的表现远好于Grabcut伪标签与线标注伪标签。ResNet50-FPN和Darknet53在有监督训练条件下,掩膜的平均精度差小于1个百分点,其中ResNet50-FPN每项对应的分割精度更高。而在BM-DCNN模型训练条件下,两个模型的掩膜精度,ResNet50-FPN除了在AP50和AP55上略高于Darknet53之外,在AP60和AP70上都低于Darknet53。这表明BM-DCNN模型在使用Darknet53作为特征提取网络时,在高IoU条件下计算平均精度时表现得更好。
此外,通过对比模型在有监督和弱监督条件下的分割精度,发现BM-DCNN模型与有监督模型非常接近,主干网络分别为ResNet50-FPN和Darknet53时,BM-DCNN的掩膜AP50值分别达到有监督实例分割的91.01%和87.50%。当IoU值大于0.7时(AP70),BM-DCNN模型对应的实例分割精度甚至高于有监督模型。其原因是在人工标注过程中,错误像素类别的比例与玉米植株形态复杂程度成正比,而弱标签产生方式只与图像颜色、纹理等基本特征有关,因此错误像素产生的比例因植株形态变化而有较大差异,因此在IoU值大于0.7时,两种特征提取网络对应的平均像素精度都高于有监督模型。
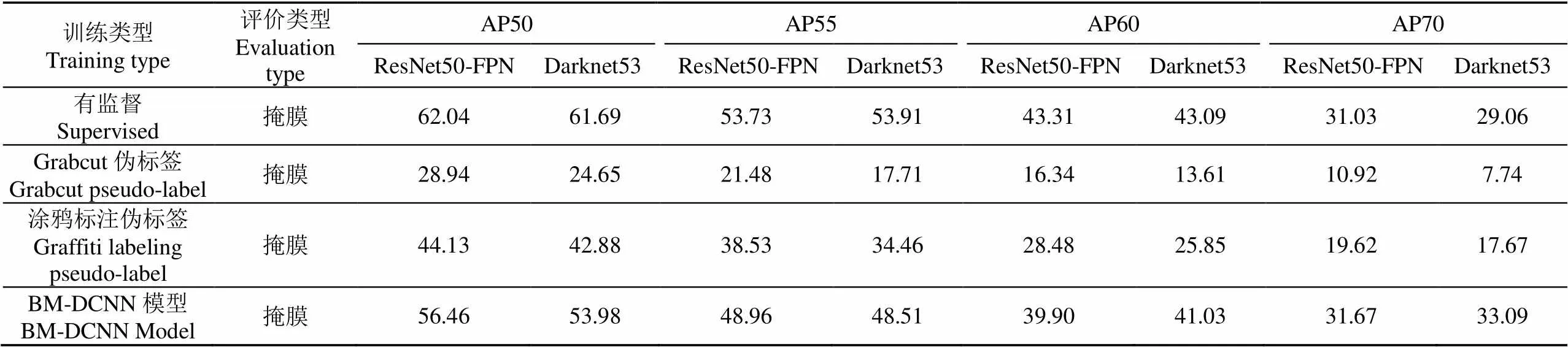
表2 不同标注方式实例分割检测结果表
注:AP50表示交并比大于0.5时模型的平均像素准确率(AP55,AP60和AP70同理)。
Note: AP50 is the average pixel accuracy of models when the intersection of union ratio is greater than 0.5. (AP55, AP60 and AP70 are the same)
图9给出了BM-DCNN模型与有监督实例分割模型在测试集上的效果对比,从图中可以看出,两种模型在对无人机拍摄的玉米苗期图像上进行玉米植株实例分割的效果非常接近,对于单株或者重叠较少的植株都能够准确区分,而且对于阴影部分也能统一归为背景,而不会误分割成玉米植株。

图9 有监督模型与弱监督模型的实例分割效果对比
此外,本试验还计算了有监督实例分割模型和BM-DCNN模型的在测试集中平均准确率(Mean accuracy),如表3所示,在使用ResNet50-FPN作为特征提取网络时,有监督实例分割模型和BM-DCNN实例分割的平均准确率分别为67.95%和67.57%,BM-DCNN实例分割的平均准确率可以达到有监督实例分割的99.44%。在使用Darknet53作为特征提取网络时,有监督实例分割模型和BM-DCNN实例分割的平均准确率分别为78.52%和75.37%,BM-DCNN实例分割的平均准确率可以达到有监督实例分割的95.99%。这表明BM-DCNN实例分割的结果与有监督实例分割结果十分接近。
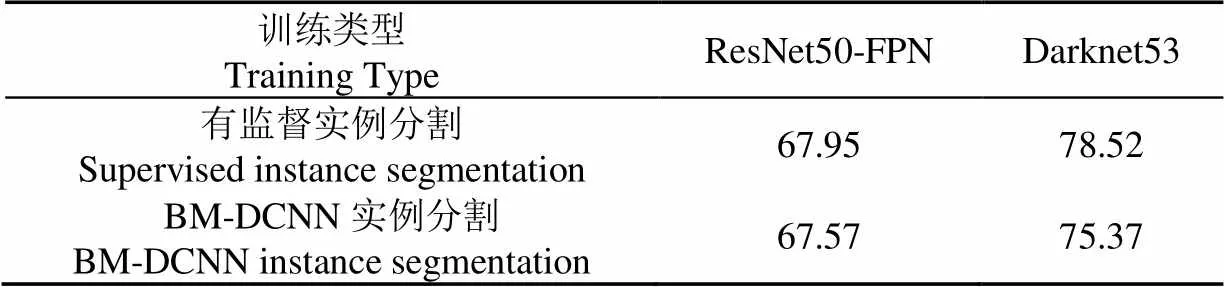
表3 实例分割平均准确率结果表
为进一步验证本文算法的实例分割效果,又利用真值标签和本文伪标签分别对MASK R-CNN、Deep Snake、SOLOv2进行训练,用训练好的模型验证苗期玉米的实例分割效果。从表4可以看出,对无人机尺度下大田环境玉米图片进行人工标注,平均每张图片的像素级标注成本是32.4 min/张,涂鸦标注成本是15.8 min/张,边界框标注成本是2.5 min/张,获得真值标签的人工标注成本是本文伪标签的13倍,获得涂鸦标注伪标签的时间成本是本文伪标签的6倍。
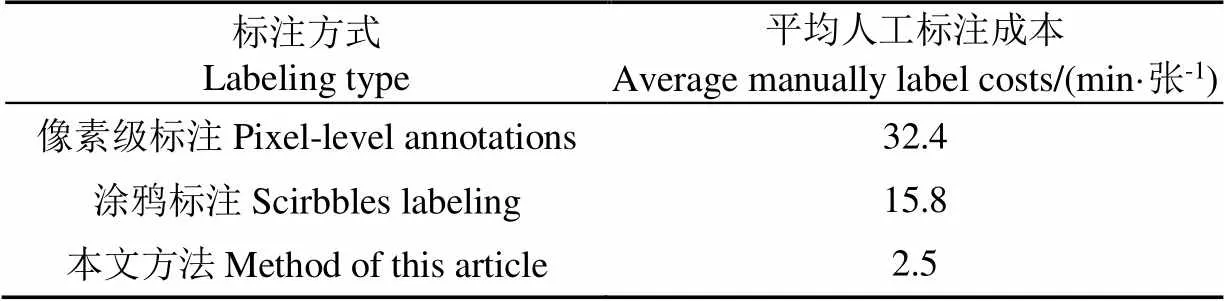
表4 不同标注方式人工成本
从表5可以看出,不同实例分割模型使用真值标签和本文伪标签实例分割检测速度差在1帧/s左右,实例分割结果平均准确率差在3个百分点左右,使用本文伪标签进行弱监督实例分割精度可以达到全监督实例分割精度的96%以上,这表明使用本文伪标签来代替真值标签对大田环境下苗期玉米图像进行实例分割是可行的,且本文方法生成的伪标签可以极大减少人工标注成本。
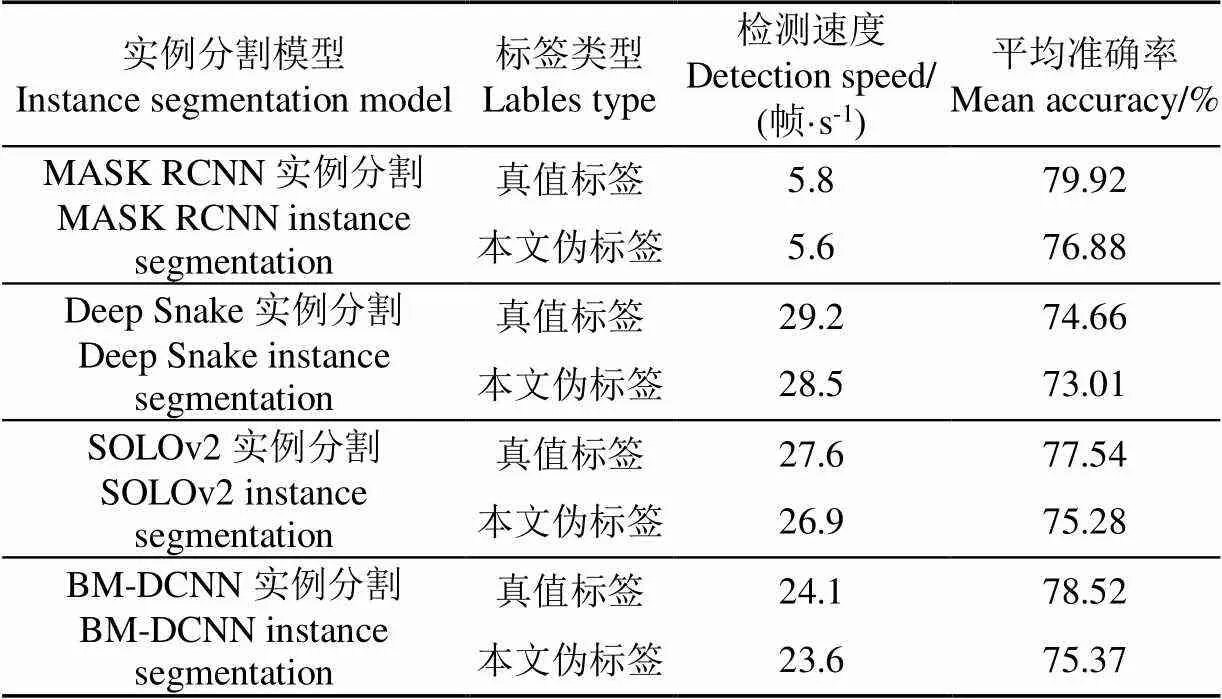
表5 不同实例分割模型分割数据对比表
4 结 论
本研究以大田玉米苗期植株为研究对象,提出一种基于弱监督学习的玉米苗期植株图像实例分割模型BM-DCNN,利用边界框形式的弱标签产生像素级伪标签作为训练样本,在YOLACT网络框架下分别使用ResNet5-FPN和Darknet53替代原基础网络并根据任务类型和数据规模调整了网络,最终得到以下结论:
1)针对苗期玉米植株图像像素级标签的时间成本问题,本文基于边界框(Bounding box)提出了一种弱标签生成方法,在边界框范围内生成像素级伪标签,通过改变颜色空间并使用全连接条件随机场提高伪标签的精度,降低了图像中影子与噪声对标签的影响,经验证伪标签人工标注成本为2.5 min/张,真值标签人工标注成本为32.4 min/张,极大程度减少人工标注成本,伪标签与真值标签的平均交并比可以达到81.83%,平均余弦相似度可以达到86.14%,考虑到真值标签在植株细节处理方面存在认为误差,这个精度下的伪标签可以用于网络训练。
2)以伪标签代替像素级真值标签进行网络训练,同时分别选择ResNet50-FPN和Darknet53作为BM-DCNN模型的特征提取网络当特征提取网络。试验中发现两种网络对于模型实现高精度的弱监督实例分割都提供了较好的特征支持。当主干网络为ResNet50-FPN时,BM-DCNN的掩膜的AP50值达到有监督实例分割的91.01%,当主干网络为Darknet53时,BM-DCNN的掩膜的AP50值达到有监督实例分割的87.50%。
3)在计算AP70值时,BM-DCNN的掩膜精度超过了有监督模型,这表明在对平均交并比做更严格的限制时,弱监督学习在分割精度上要优于有监督模型,是由于植物性状结构复杂而导致的人工标注不精细导致的,BM-DCNN的伪标签产生过程会克服该问题,提升像素级标签在植株边缘的分割精度。
4)对比有监督实例分割模型和BM-DCNN在测试集上的平均准确率,使用ResNet50-FPN作为特征提取网络时,BM-DCNN实例分割的平均准确率可以达到有监督实例分割的99.44%。使用Darknet53作为特征提取网络时,BM-DCNN实例分割的平均准确率可以达到有监督实例分割的95.99%。这表明BM-DCNN实例分割的结果与有监督实例分割结果十分接近。
5)不同实例分割模型分别使用真值标签和本文伪标签训练,实例分割检测速度差在1帧/s左右,测试集的实例分割结果平均准确率差在3个百分点左右。
由此可见,针对玉米苗期植株图像(顶视图)的实例分割任务,BM-DCNN的实例分割效果几乎可以达到同等条件下有监督实例分割模型的分割效果。由此可见,在无人机大面积作业场景下,利用图像的边界框标签来代替像素级真值标签来完成深度学习模型的训练是具备可行性的,这大幅度降低了样本人工标注的时间成本,为快速实现玉米苗期植株数量统计和冠层覆盖度计算等应用场景提供理论方法支撑。
[1] 苏丽,孙雨鑫,苑守正. 基于深度学习的实例分割研究综述[J]. 智能系统学报,2022,17(1):16-31.
Su Li, Sun Yuxin, Yuan Shouzheng. A survey of instance segmentation research based on deep learning[J]. CAAI Transactions on Intelligent Systems, 2022, 17(1): 16-31. (in Chinese with English abstract)
[2] 邓颖,吴华瑞,朱华吉. 基于实例分割的柑橘花朵识别及花量统计[J]. 农业工程学报,2020,36(7):200-207.
Deng Ying, Wu Huarui, Zhu Huaji. Recognition and counting of citrus flowers based on instance segmentation[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2020, 36(7): 200-207. (in Chinese with English abstract)
[3] 宋杰,肖亮,练智超,等. 基于深度学习的数字病理图像分割综述与展望[J]. 软件学报,2021,32(5):1427-1460.
Song Jie, Xiao Liang, Lian Zhichao, et al. Overview and prospect of deep learning for image segmentation in digital pathology[J]. Journal of Software, 2021, 32(5): 1427-1460. (in Chinese with English abstract)
[4] 岑海燕,朱月明,孙大伟,等. 深度学习在植物表型研究中的应用现状与展望[J]. 农业工程学报,2020,36(9):1-16.
Cen Haiyan, Zhu Yueming, Sun Dawei, et al. Current status and future perspective of the application of deep learning in plant phenotype research[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2020, 36(9): 1-16. (in Chinese with English abstract)
[5] 王春颖,泮玮婷,李祥,等. 基于ST-LSTM的植物生长发育预测模型[J]. 农业机械学报,2022,53(6):250-258.
Wang Chunying, Pan Weiting, Li Xiang, et al. Plant growth and development prediction model based on ST-LSTM[J]. Transactions of the Chinese Society for Agricultural Machinery, 2022, 53(6): 250-258. (in Chinese with English abstract)
[6] 邓寒冰,许童羽,周云成,等基于深度掩码的玉米植株图像分割模型[J]. 农业工程学报,2021,37(18):109-120.
Deng Hanbing, Xu Tongyu, Zhou Yuncheng, et al. Segmentation model for maize plant images based on depth mask[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(18): 109-120. (in Chinese with English abstract)
[7] Hati A J, Singh R R. Artificial intelligence in smart farms: Plant phenotyping for species recognition and health condition identification using deep learning[J]. Artificial Intelligence, 2021, 2(2): 274-289.
[8] Amy B, Olga R, Vittorio F, et al. What’s the point: Semantic segmentation with point supervision[C]// European Conference on Computer Vision, Amsterdam: IEEE, 2016.
[9] Remez T, Huang J, Brown M. Learning to segment via cut-and-paste[C]// IEEE International Conference on Computer Vision, Venice: IEEE, 2017.
[10] Li Qizhu, Arnab A, Torr P. Weakly-and semisupervised panoptic segmentation[C]// European Conference on Computer Vision, Munich: IEEE, 2018.
[11] Jaedong H, Seohyun K, Jeany S, et al. Weakly supervised instance segmentation by deep community learning[C]// IEEE Winter Conference on Applications of Computer Vision, Waikoloa: IEEE, 2021.
[12] Lin D, Dai J, Jia J, et al. ScribbleSup: Scribble-Supervised convolutional networks for semantic segmentation[C]// IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas: IEEE, 2016.
[13] Özgün Ç, Abdulkadir A, Lienkamp S, et al. 3D U-Net: learning dense volumetric segmentation from sparse annotation[C]// International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens: MICCAI, 2016.
[14] Jiwoon A, Sunghyun C, Suha K. Weakly supervised learning of instance segmentation with inter-pixel relations[C]// IEEE Conference on Computer Vision and Pattern Recognition, Long Beach: IEEE, 2019.
[15] Jiwoon A, Suha K. Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation[C]// IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City: IEEE, 2018.
[16] Jungbeom L, Eunji K, Sungmin L, et al. Ficklenet: Weakly and semi-supervised semantic image segmentation using stochastic inference[C]// IEEE Conference on Computer Vision and Pattern Recognition, Long Beach: IEEE, 2019.
[17] Miriam B, Amaia S Jordi T, et al. Budget-aware semi-supervised semantic and instance segmentation[C]// IEEE Conference on Computer Vision and Pattern Recognition, Long Beach: IEEE, 2019.
[18] Viveka K, Siddhartha C, Amit A, et al. Box2seg: Attention weighted loss and discriminative feature learning for weakly supervised segmentation[C]// European Conference on Computer Vision, Edinburgh: IEEE, 2020.
[19] Aditya A, Jawahar C, Pawan K. Weakly supervised instance segmentation by learning annotation consistent instances[C]// European Conference on Computer Vision, Edinburgh: IEEE, 2020.
[20] Liao S, Sun Y, Gao C, et al. Weakly supervised instance segmentation using hybrid networks[C]// International Conference on Acoustics, Speech and Signal Processing, Brighton: IEEE, 2019.
[21] Sun Y, Liao S, Gao C, et al. Weakly supervised instance segmentation based on two-stage transfer learning[J]. IEEE Access, 2020, 8: 24135-24144.
[22] Lafferty J, Mccallum A , Pereira F. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[C]//International Conference on Machine Learning, Berkshires: IMLS, 2001.
[23] Carsten R, Vladimir K, Andrew B. GrabCut: Interactive foreground extraction using iterated graph cuts[J]. Proceedings of Siggraph, 2004, 23(3): 309-314.
[24] Pont-Tuset J, Arbelaez P, Barron J, et al. Multiscale combinatorial grouping for image segmentation and object proposal generation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(1): 128-140.
[25] Papandreou G, Chen L C, Murphy K, et al. Weakly- and semi-supervised learning of a DCNN for semantic image segmentation[C]// IEEE International Conference on Computer Vision, Santiago: IEEE, 2015.
[26] Rajchl M, Lee M, Oktay O, et al. DeepCut: Object segmentation from bounding box annotations using convolutional neural networks[J]. IEEE Transactions on Medical Imaging, 2016, 36(2): 674-683.
[27] Khoreva A, Benenson R, Hosang J, et al. Simple does it: Weakly supervised instance and semantic segmentation[C]// IEEE Conference on Computer Vision and Pattern Recognition, Hawaii: IEEE, 2017.
[28] Hsu C, Hsu K, Tsai C, et al. Weakly supervised instance segmentation using the bounding box tightness prior[C]// Conference and Workshop on Neural Information Processing Systems, Vancouver: NIPS, 2019.
[29] Tian Z, Shen C, Wang X, et al. BoxInst: High-performance instance segmentation with box annotations[C]//IEEE Conference on Computer Vision and Pattern Recognition, Montreal: IEEE, 2021.
[30] Dai J, He K, Sun J. Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation[C]// IEEE International Conference on Computer Vision, Santiago: IEEE, 2015.
[31] Song C, Huang Y, Ouyang W, et al. Box-driven class-wise region masking and filling rate guided loss for weakly supervised semantic segmentation[C]// IEEE Conference on Computer Vision and Pattern Recognition, Long Beach: IEEE, 2019.
[32] Bolya D, Zhou C, Xiao F, et al. YOLACT:Real-time instance segmentation[C]// IEEE International Conference on Computer Vision, Seoul: IEEE, 2019.
[33] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas: IEEE, 2016.
[34] Pan S, Yang Q. A survey on transfer learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345-1359.
Instance segmentation method of seedling maize plant images based on weak supervised learning
Zhao Yanan1, Deng Hanbing1,2※, Liu Ting1, Zhao Lulu1, Zhao Kai1, Yang Jing1, Zhang Yufeng1
(1.110866;2.110866)
Deep learning has gradually been one of the most important technologies in the field of agriculture in recent years. However, the problems of labeling quality and cost of training samples for supervised deep learning have become the bottleneck of restricting the development of technology. In order to reduce the cost of deep model training and ensure that the model can have high image segmentation accuracy, in this study, a model named Bounding-box Mask Deep Convolutional Neural Network (BM-DCNN) was proposed to realize automatic training and segmentation for maize plant. First of all, using DJI’s Genie 4-RTK drone to collect top images of maize seedlings. The flight uses an automatic take-off planned route, and the entire route covers the entire test field. Second of all, using the open source labeling tool called Labelme to label top images of maize seedlings. The top images of the original maize seedling plants need to be labeled twice. In this study, we used bounding boxes as the basic shapes for weakly supervised labels, and pixels within the bounding boxes area were marked as foreground(i.e. the possible effective pixels of a maize plant). Pixels outside the bounding boxes were marked as background. Finally, the information of bounding boxes was used to generate primary pseudo-labels on the images, and the RGB color model of the images was converted to the HSV(Hue-Saturation-Value) color model, and the full connection condition random field(DenceCRF) was used to eliminate the influence of plant shadow and the image noise on the pseudo-labels accuracy in the images. The pseudo-labels were trained on the optimized YoLact model instead of the ground truth labels. The optimized model can be used for the instance segmentation of the plants at the maize seedling stage. We designed an experiment for verification and testing of BM-DCNN. By comparing the similarity between pseudo-labels mask and ground truth, it found that the mean intersection over union (mIoU) was 81.83% and mean cosine similarity (mcos(ɑ)) was 86.14%, which was higher than the accuracy of pseudo-labels generated by Grabcut(the mIoU was 40.49% and mean cosine similarity was 61.84%). For the maize seedling image (top view), the time cost of three manual annotation methods was calculated, with bounding box labels of 2.5 min/sheet, scirbbles labels of 15.8 min/sheet, and pixel-level labels of 32.4 min/sheet. Considering that the ground truth labels had an error in the handing of maize plant details, the pseudo-labels at the accuracy can be used for deep convolutional neural network training. By comparing the accuracy of instance segmentation between BM-DCNN and fully supervised instance segmentation model, when the IoU value of the BM-DCNN was greater than 0.7(AP70), the instance segmentation accuracy corresponding to the BM-DCNN model was higher than that of the supervised model. The average accuracy of the two backbone networks of the BM-DCNN model were 67.57% and 75.37%, respectively, which were close to the supervised instance segmentation results under the same conditions (67.95% and 78.52%, respectively), and the higher average accuracy can reach 99.44% of the supervised segmentation results. Therefore, For the instance segmentation task of the maize seedling plants images(top view), the instance segmentation effect of BM-DCNN can almost achieve the segmentation effect of the supervised instance segmentation model under the same conditions. It can be seen that in the large-area operation scenario of the UAV, it was feasible to use the bounding box labels of the images to replace the ground truth labels to complete the training of deep learning model, which greatly reduced the time cost of manual labeling of the samples, and provided theoretical support for the rapid realization of the application scenarios, such as the number of plants at the seedling stage of maize and the calculation of canopy coverage.
instance segmentation; deep learning; weak supervised learning; maize; plant phenotype
10.11975/j.issn.1002-6819.2022.19.016
S823.92; TP391.41
A
1002-6819(2022)-19-0143-10
赵亚楠,邓寒冰,刘婷,等. 基于弱监督学习的玉米苗期植株图像实例分割方法[J]. 农业工程学报,2022,38(19):143-152.doi:10.11975/j.issn.1002-6819.2022.19.016 http://www.tcsae.org
Zhao Yanan, Deng Hanbing, Liu Ting, et al. Instance segmentation method of seedling maize plant images based on weak supervised learning[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2022, 38(19): 143-152. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2022.19.016 http://www.tcsae.org
2022-06-28
2022-09-28
国家自然科学基金项目(31601218,31901399);辽宁省教育厅科学研究经费项目(LSNQN202022,LSNJC202004);辽宁省创新能力提升联合基金项目(2021-NLTS-11-03)
赵亚楠,研究方向为机器学习与模式识别。Email:zynzhaoyanan@163.com
邓寒冰,博士,副教授,研究方向为机器学习与模式识别、计算机视觉、作物表型信息获取与分析。Email:denghanbing@syau.edu.cn
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21
小学科学(学生版)(2021年4期)2021-07-23
现代装饰(2020年4期)2020-05-20
证券法律评论(2018年0期)2018-08-31
电子制作(2017年1期)2017-05-17
智能系统学报(2015年5期)2015-12-03
浙江大学学报(工学版)(2015年2期)2015-05-30
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
外语学刊(2009年3期)2009-06-04
