
采用改进YOLOv5的蕉穗识别及其底部果轴定位
2022-02-04 12:14段洁利王昭锐邹湘军袁浩天黄广生
农业工程学报 2022年19期
段洁利,王昭锐,邹湘军,袁浩天,黄广生,杨 洲,3
采用改进YOLOv5的蕉穗识别及其底部果轴定位
段洁利1,2,王昭锐1,邹湘军1,袁浩天1,黄广生1,杨 洲1,2,3※
(1. 华南农业大学工程学院,广州 510642;2. 岭南现代农业科学与技术广东省实验室,广州 510600;3. 嘉应学院广东省山区特色农业资源保护与精准利用重点实验室,梅州 514015)
为提高香蕉采摘机器人的作业效率和质量,实现机器人末端承接机构的精确定位,该研究提出一种基于YOLOv5算法的蕉穗识别,并对蕉穗底部果轴进行定位的方法。将CA(Coordinate Attention)注意力机制融合到主干网络中,同时将C3(Concentrated-Comprehensive Convolution Block)特征提取模块与CA注意力机制模块融合构成C3CA模块,以此增强蕉穗特征信息的提取。用 EIoU(Efficient Intersection over Union)损失对原损失函数CIoU(Complete Intersection over Union)进行替换,加快模型收敛并降低损失值。通过改进预测目标框回归公式获取试验所需定位点,并对该点的相机坐标系进行转换求解出三维坐标。采用D435i深度相机对蕉穗底部果轴进行定位试验。识别试验表明,与YOLOv5、Faster R-CNN等模型相比,改进YOLOv5模型的平均精度值(mean Average Precision, mAP)分别提升了0.17和21.26个百分点;定位试验表明,采用改进YOLOv5模型对蕉穗底部果轴定位误差均值和误差比均值分别为0.063 m和2.992%,与YOLOv5和Faster R-CNN模型相比,定位误差均值和误差比均值分别降低了0.022 m和1.173个百分点,0.105 m和5.054个百分点。试验实时可视化结果表明,改进模型能对果园环境下蕉穗进行快速识别和定位,保证作业质量,为后续水果采摘机器人的研究奠定了基础。
图像识别;机器人;香蕉采摘;果轴定位;注意力机制;损失函数
0 引 言
中国是香蕉生产和消费大国,但是香蕉采摘效率低,损伤较大,是一项高耗劳动力的活动[1]。传统的香蕉采收通常需要两个青壮年手工操作,劳动强度大,并随着人口老龄化和劳动力高成本化,势必会降低采收效率[2]。为了提高香蕉的采收效率、减少损伤和应对劳动力短缺等问题,本研究对蕉穗进行识别定位,为其应用于采摘机器人的托接系统做前期研究。近年来,国内外对于机器人的研究逐渐从工业领域拓展到了农业领域[3],与此同时基于图像处理和机器学习的目标检测方法也更广泛地应用于农业作业。卢军等[4]针对果实遮挡,在变化光照条件下提出了基于彩色信息和目标轮廓整合的柑橘遮挡检测方法。顾苏杭等[5]考虑到光照等因素,提出一种基于显著性轮廓的苹果目标识别方法应用于苹果采摘机器人,该方法能通过图像分割以及图像后处理完整地提取苹果轮廓,对苹果目标识别率达到98%。Yamamoto等[6]针对传统果实识别需要对其特征设置特定阈值带来的泛化性低的问题,提出了基于传统RGB数码相机结合机器学习的方法对番茄图像特征生成的分类模型进行图像分割,达到理想的分割效果。
上述传统机器学习方法检测复杂背景图像中的水果目标会受到背景信息影响[7],而且需要手工提取特征,难以获得较好的检测结果。采用深度学习方法只需要提供带标签的数据集,而不需要人为设计特征就能够从数据集中提取目标的特征[8]。由于卷积神经网络内嵌多个隐含层,通过学习得到更加高级的数据特征表示,在解决目标检测等问题有很大的优势[9]。常用的目标检测网络有Fast R-CNN(Fast Region with CNN)系列[10-12]、SSD(Single Shot multibox Detector)[13-16]和YOLO(You Only Look Once)系列[17-20]。YOLO网络相较于其他两者的模型更精简,运行速度最快,实时性更好[21],因此在农业目标检测上的应用也越来越普遍。吕石磊等[22]提出一种基于改进YOLOv3-LITE轻量级网络模型,实现了自然环境下柑橘果实的快速精确识别。赵德安等[23]通过YOLOv3卷积神经网络遍历整个图像,回归目标类别和位置,在保证检测效率与准确率的前提下实现了端到端的目标检测。同样是基于改进YOLOv3模型,Tian等[24]提出应用于光照波动、复杂背景、重叠和枝叶遮挡等条件下的果园不同生长阶段的苹果检测。该方法加入了密集连接网络(DenseNet),有效地提升了网络性能并实现重叠和遮挡条件下的苹果检测。同样为了克服上述问题,Liu等[25]基于YOLOv3提出了一种改进的番茄检测模型YOLO-Tomato,用圆形包围盒更准确地匹配番茄果实,提升了模型的检测性能。
目前国内外对于球形水果的目标检测趋于成熟,但以香蕉为对象的目标检测成果尚少。Fu等[26]首先对自然环境下的香蕉目标检测提出了一种基于颜色和纹理特征的自然环境下香蕉检测方法;后续作者基于YOLOv4提出YOLO-banana目标检测网络[27-29],实现果园环境下对香蕉果实多类别快速检测。Wu[30-32]等对香蕉机器人进行研究,提出了基于YOLO系列算法的香蕉多目标特征识别,并针对香蕉果轴断蕾点进行视觉定位,经试验达到作业要求。
该研究在上述相关研究的基础上提出一种能够搭载于香蕉采收机器人承接机构上的基于改进YOLOv5的果园环境下蕉穗目标识别定位的视觉系统,通过该系统对蕉穗进行识别和对蕉穗底部果轴进行定位,并对识别精度和定位精度进行验证。
1 材料与数据
1.1 图像获取
该研究所使用的蕉穗果实图像于2021年3月17日和2022年2月10日分别在广东省农科院香蕉园和广东省潮州市饶平县内香蕉种植地区进行拍摄,拍摄当天天气晴。图像采集设备为高像素智能手机,拍摄过程摄像头与香蕉果实距离为500~1 500 mm,图像分辨率为3 024×4 000像素,共采集果园环境下的蕉穗图片500张,按照4∶1的比例构造训练集和测试集,即训练集图片400张,测试集图片100张。
1.2 图像预处理
用图像标注软件LabelImg对采集的500张蕉穗图片进行标注,生成YOLO模型对应的xml文件,文件包含蕉穗在图像中的坐标位置、图像大小以及标签名banana。然后把蕉穗图片和标注好的文件分成训练集和测试集分别放在images和labels文件夹,组成本研究需要使用的蕉穗数据集。
2 蕉穗目标检测
2.1 改进YOLOv5网络
YOLOv5的网络结构主要由骨干网络(Backbone)、颈部网络(Neck)以及预测网络(Prediction)组成。根据模型由小到大,YOLOv5网络分成YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x。考虑到果园环境下蕉穗识别任务的实时性和效率,该研究选择较轻量级的YOLOv5s进行改进。如图1所示,本文从以下三方面进行改进:
1)在Backbone 网络的C3模块(Concentrated- Comprehensive Convolution Block)之后添加CA(Coordinate Attention)注意力机制,构成C3CA模块,4个C3CA模块可以将网络中有用的特征信息进行重用,强化对蕉穗特征的提取。
2)在最后一个C3CA模块后面添加CA模块,加强对位置信息和通道信息的提取,有助于提升目标定位效果。
3)用EIoU(Efficient Intersection over Union)损失对原损失函数CIoU(Complete Intersection over Union)进行替换,通过分别计算目标框宽高的差异值,改善样本分布不均的问题,加快模型收敛并降低模型损失。
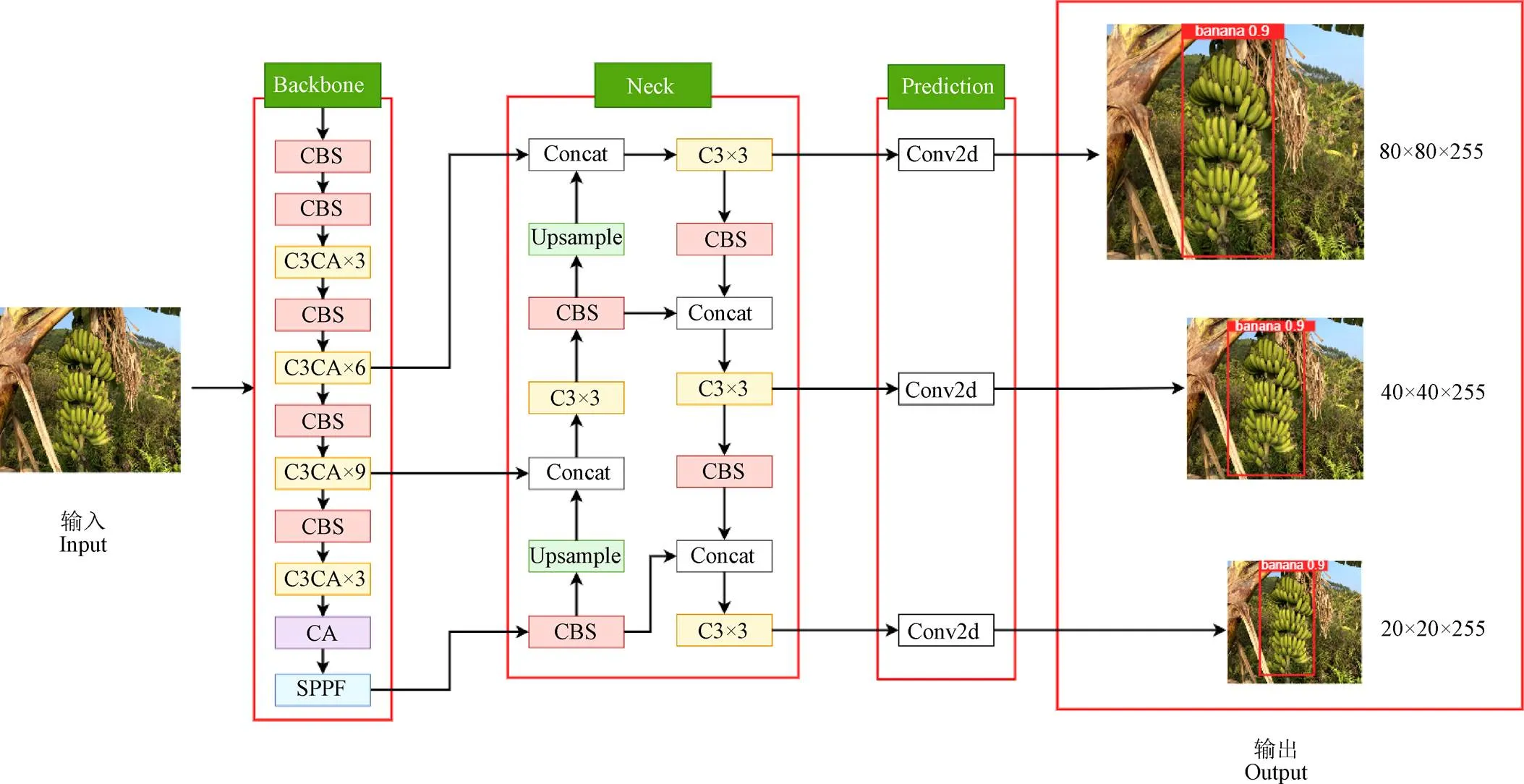
注:CBS为卷积单元;C3CA、C3模块后面的数字表示模块个数;SPPF为池化操作;Concat表示特征拼接;Upsample为特征上采样;Conv2d表示二维卷积;输出80×80×255、40×40×255和20×20×255表示网络输出特征图的长、宽和深度。
2.1.1 CA注意力模块
由于果园环境下生长的蕉穗背景复杂、形态多样,这会对算法最终的识别效果造成一定影响,因此该研究在YOLOv5算法网络中添加注意力机制,通过突出蕉穗的重要特征从而提升识别效果。最早用于计算机视觉的通道注意力机制对于提升网络性能具有显著效果,但通常会忽略非常重要的位置信息[33]。因此本研究采用将位置信息结合通道注意力的轻量级移动网络CA注意力模块强化蕉穗特征信息并弱化背景信息。CA注意力模块的实现分为全局信息嵌入和坐标注意力生成两个部分。
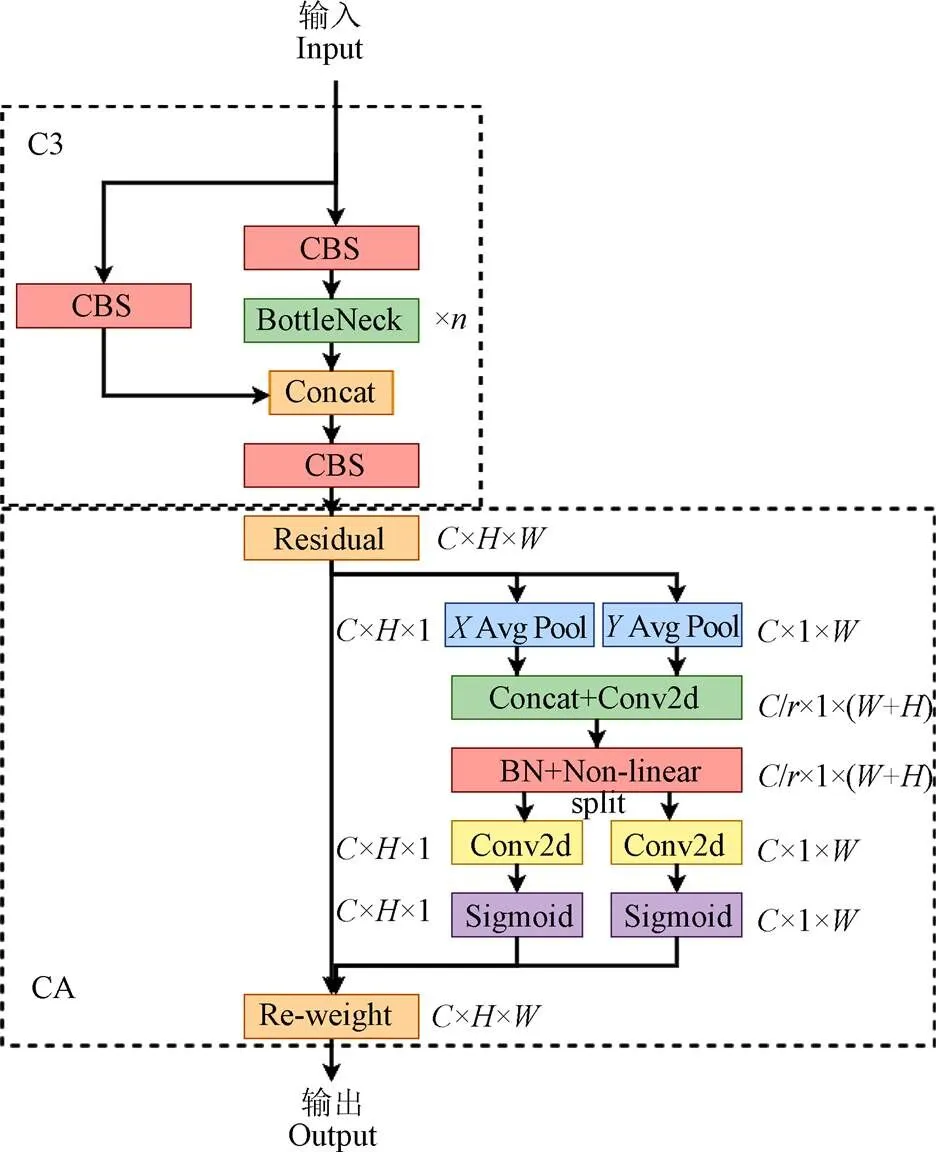
注:C、H、W分别表示特征通道的深度、高度和宽度;r为缩减比;n表示对应模块个数;:X Avg Pool、Y Avg Pool分别表示横向全局池化和纵向全局池化。
式(1)为通道注意力机制中用于全局信息嵌入的全局池化操作,给定输入特征张量=[1,2,3,…,x]∈R×H×W,全局池化操作与第通道(∈)相关的输出Z为




上述两种变换分别沿着两个空间方向聚合特征,输出结果使注意力模块捕捉一个空间方向并保存另一空间方向的准确位置信息,这使得网络对于目标的定位更为精准。
为充分利用上述方法获取到的全局信息并利用其表达的特征进行注意力生成,将式(2)、(3)结果进行拼接操作,再使用卷积变换形成中间特征图
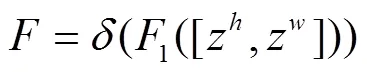

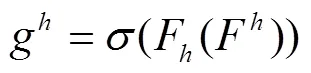

式中为sigmoid激活函数。最后将g及g展开作为注意力权值,注意力机制的模块输出=[1,2,3,…,y]为

2.1.2 损失函数
原始YOLOv5模型采用CIoU(Complete Intersection over Union)损失在一定程度上可以加快预测框回归速度,但仍存在相对比例惩罚项对于线性比例的预测框宽高比和真实框的宽高比不起作用的问题,而且预测框宽高无法保持同增减。为了解决这些问题,采用EIoU(Efficient Intersection over Union)[34]作为改进模型的损失函数,分别通过计算边界框宽高的差异比消除CIoU纵横比描述所存在的模糊性,EIoU损失值EIoU为

式中IoU、dis和asp分别表示交并比损失、距离损失和相位损失;表示中心点之间的欧式距离;和b表示预测框和真实框的中心点;表示预测框和真实框最小包围矩形的对角线长度;w和h表示预测框的宽高;w和h表示真实框的宽高;d、d表示预测框和真实框最小包围矩形的宽度和高度。
2.2 试验参数和评价指标
该研究蕉穗检测网络采用Pytorch框架搭建,处理器为11th Gen Intel(R) Core(TM) i7-11800H@2.30GHz,16G内存,显卡为GeForce RTX 3060 Laptop GPU。批量大小(batch size)设置为4,训练步数(Epoch)设为300,图像通过归一化处理为分辨率640×640,学习率(Learning rate)为0.01,优化器采用随机梯度下降(Stochastic gradient descent, SGD)。试验结果的评价指标采用准确率(Precision)、召回率(Recall)、平均精度值(mean Average Precision, mAP)和模型大小,设定IoU(Intersection over Union)≥0.5为对蕉穗的正确检测。
3 蕉穗底部果轴定位
3.1 相机参数
试验使用Intel RealSense D435i立体视觉深度相机,深度图分辨率为1 280×720像素,彩色图分辨率为848×480像素,深度探测范围0.2~10.0 m,采用USB供电。采用RealSense相机自带软件Intel Real Sense Viewer获取相机内参,如表1所示。

表1 RealSense D435i相机内参数
3.2 定位点求解
在YOLOv5目标检测网络中通过回归公式预测边界框的中心点b、b以及宽高b、b如下
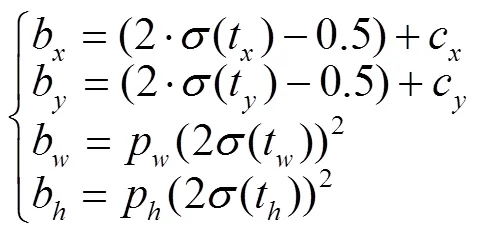
式中t,t是对目标中心坐标预测的偏移参数;t,t是对目标宽高预测的缩放因子;(c,c)为对应网格左上角的坐标,p、p为锚框模板映射在特征层上的宽和高。b、b、b、b可以通过xywh2xyxy( )函数唯一确定预测框左上和右下两对坐标值(1,1)和(2,2)。最后通过几何关系求出定位点(1,1)如下
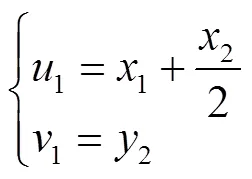
通过该式即求得目标检测框底部的中心点,由于该点与蕉穗底部果轴基本重合,因此也就得到蕉穗底部果轴在像素坐标系下的定位点(1,1),如图3所示。
3.3 定位原理
如图4所示,本研究要确定定位点在世界坐标系中的位置必须先求得该点到相机坐标系{x,y,z}转换关系,再求得相机坐标系到图像坐标系{,}以及图像坐标系到像素坐标系{,}的转换关系。坐标系{,}平行于坐标系{x,y,z}中x,y构成的平面,坐标系{,}的原点位于图像左上角。定位点通过刚体变换矩阵转换到相机坐标系下的点P。依据投影光线的相似三角形原理推导出坐标系{x,y,z}与坐标系{,}之间的转换关系如下:

注:图像所处像素坐标系为{};c和c为网格左上角对应方向的长度;p和p为锚框的宽和高;(b,b)为预测边界框的中心点;b和b为预测边界框的宽高;(1,1)和(2,2)分别为预测框两对坐标值;(1,1)为本研究的定位点。
Note: The pixel coordinate system of the image is{};candcare the coordinate at the upper left corner of the corresponding grid;pandpare the width and height of the anchor frame; (b,b) is the center point of the prediction bounding box;bandbare the width and height of the predicted bounding box; (1,1) and (2,2) are prediction box two pairs of coordinate values respectively; (1,1) is the anchor point of this study.
图3 目标边界框和定位点回归
Fig.3 Regression of target boundary box and anchor point

注:{xc, yc, zc}为相机坐标系,原点为Oc;{x,y}为图像坐标系,原点为Oi;{u,v}为像素坐标系,原点为Op;点Pc为相机坐标系下的定位点;点P为投影光线OcPc与图像坐标系平面的交点;f为焦距,mm。
又因为图像坐标系与像素坐标系存在平移关系,所以两者间又有如下转换



即为相机坐标系和像素坐标系的转换公式。其中

如图5所示,蕉穗深度图像由左右两个红外相机各对同一蕉穗获取P1、P2两幅红外图像,然后通过三角测量的原理获得深度图像Pd后与彩色图像Pc进行配准。设定彩色图素坐标系{u,v},深度图素坐标系{u,v},对两者进行配准后每一帧彩色图像中检测到的每一个像素点(u,v)都能对应一个深度图像素点(u,v)。最后根据公式(14)和pyrealsense2库中的get_distance( )函数可以得到定位点在相机坐标系下的三维坐标(x,y,z)。
注:P1、P2为左右红外相机分别获取的红外图像;Pd、Pc分别为深度图和彩色图;{u,v}为彩色图素坐标系;{u,v}为深度图素坐标系。
Note: P1and P2are infrared images obtained by left and right infrared cameras respectively; Pdand Pcare depth map and color map respectively; {u,v} is the color pixel coordinate system; {u,v} is the depth map pixel coordinate system.
图5 相机配准示意图
Fig.5 Camera registration diagram
3.4 试验设计和评价指标
定位试验通过使用模型训练结果对蕉穗进行目标检测,将目标检测框底部的中心点作为定位点并求解该点的三维坐标。由于将试验得到的相机到果轴的距离距离值z代入式(14)将可得果轴的其它两个坐标数值x和y,因此误差源在于所测量的z值。影响定位试验误差的因素很多,主要为环境噪声引起的图像定位点误差、随机误差和测量工具误差等。为了验证该研究识别定位的可靠性,对距离值z进行精度评价。为验证相机定位的精度,采用激光测距仪作为辅助设备。
如图6所示,为了模拟果园环境下对蕉穗的实时定位,该试验将激光测距仪安装到深度相机上端。经测量得激光测距仪与深度相机的高度差远小于定位点距离,因此忽略此高度差。将该装置连接至笔记本电脑,用Python开发的程序驱动深度相机获取距离测量值z,同时使用激光测距仪获取距离测量值z并对应保存。为了评价定位精度,采用误差均值E和误差比均值E作为评价指标,E反映了估计值和真实值之间的绝对误差,E反映了估计值和真实值的相对误差。计算公式如下:

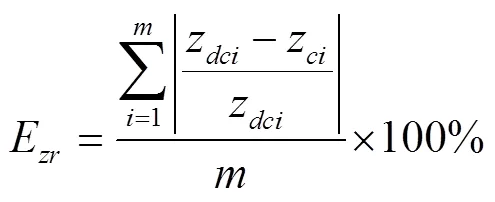
式中为同一幅图像成功识别并定位的蕉穗株数。

注:zci为深度相机测量值,m;zdci为激光测距仪测量值,m。
4 结果与分析
4.1 模型训练结果
为了丰富数据集,提升网络模型的鲁棒性和泛化性能,防止数据集数量不足造成过拟合,模型训练时对蕉穗图像进行数据增强,包括平移(Translate)、缩放(Scale)、左右翻转(Flip left-right)、混叠(Mixup)和改变HSV值,将蕉穗训练集扩充到844张。在保证训练批量、步数、优化器、和学习率等初始参数和设备一致的前提下,对YOLOv5、Faster R-CNN模型和改进YOLOv5模型进行训练。表2是模型训练结果,与原始YOLOv5模型相比,改进模型的准确率提升2.8个百分点,召回率达到100%,平均精度值提升0.17个百分点;与Faster R-CNN模型相比,改进模型的准确率提升52.96个百分点,召回率提升17.91个百分点,平均精度值提升21.26个百分点;改进YOLOv5模型与原始YOLOv5模型大小相比减小了1.06 MB。从训练结果可以看出改进模型在融合了CA注意力机制和C3CA特征提取模块之后具有最高的平均精度值,而且模型占用内存最小,能够很好提升模型对果园环境下蕉穗的特征提取能力,能够在保证平均精度值的前提下改善识别效果。
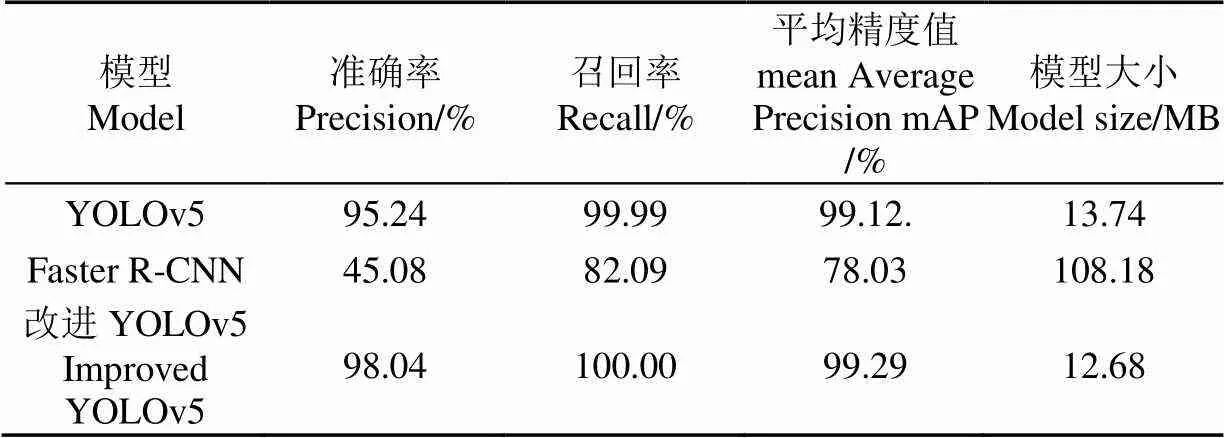
表2 模型的训练结果
4.2 模型消融试验结果
改进的YOLOv5模型在YOLOv5模型的基础上融合了CA注意力模块、C3CA特征提取模块和EIoU损失函数。为了能够更加直观地分析改进的YOLOv5模型相较于原始模型的提升,分别进行了5组试验并对比试验的平均精度值mAP,试验结果如表3所示。
试验1为原始YOLOv5模型,在不添加CA、 C3CA和EIoU的条件下平均精度值为99.12%;与原始YOLOv5模型相比,试验2和试验3分别只添加了CA模块和C3CA模块,平均精度值分别提高了0.03个百分点和0.02个百分点;试验4为同时添加CA和C3CA模块的改进YOLOv5模型,平均精度值提高了0.14个百分点;试验5为本研究的改进模型,平均精度值为99.29%,提高了0.17个百分点。
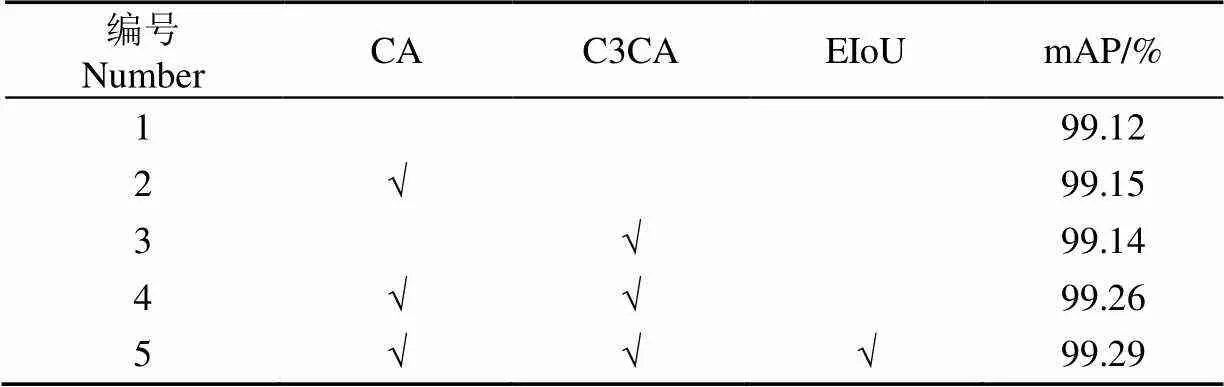
表3 模型消融试验结果
注:“√”表示采用该方法。
Note: “√” indicates that this method is used.
图7为对原始YOLOv5模型(试验1)与改进YOLOv5模型(试验5)进行训练后的定位损失函数和目标损失函数,可以看出训练经过300步数后趋于稳定,模型收敛,并且改进模型与原始模型相比损失值更低,训练效果得到提升。

图7 训练损失函数
4.3 定位试验结果
为了提升作业效率,确定最佳的定位范围,该研究首先在广东省肇庆市农科所蕉园进行了预试验,将试验的测量值范围限制在1.0~2.5 m。
正式试验在广东省东莞市水果蔬菜研究所进行。模拟果园环境下对蕉穗底部果轴的实时定位进行了随机试验,采用YOLOv5模型、Faster R-CNN模型和改进YOLOv5模型对距离为1.0~2.5 m范围的单株和双株蕉穗进行识别与直线距离定位,每个模型进行10次定位试验。如图8所示为YOLOv5模型、Faster R-CNN模型和改进YOLOv5模型的部分试验的可视化图像,三种模型在定位范围内都识别到了视野内的蕉穗,并都获取到了测量值。从置信度来看,改进YOLOv5模型达到了90%,置信度得到了保证。记录深度相机测量值z和激光测距仪测量值z,计算误差均值E和误差比均值E并计算平均值,结果如表4所示。

注:FPS为相机帧率;检测框上的信息“banana”为类别名香蕉,后面的数字为置信度;检测框底部数值表示定位点在相机坐标系下的三维坐标(xc,yc,zc)。

表4 蕉穗底部果轴定位试验结果
注:z、z分别为深度相机测量值和激光测距仪测量值,m;E、E分别为为误差均值和误差比均值,%。
Note:zandzare the depth camera measurement and the laser rangefinder measurement respectively, m;EandEare the mean of error and the mean of error ratio respectively, %.
根据表4试验结果可得:所得到的误差均值E分别为0.085、0.168和0.063 m;误差比均值E分别为4.165%、8.046%和2.992%。与Faster R-CNN模型相比,改进YOLOv5模型的误差均值E和误差比均值E分别降低了0.105 m和5.054个百分点;与原始YOLOv5模型相比,改进YOLOv5模型的误差均值E和误差比均值E分别降低了0.022 m和1.173个百分点;除此之外,试验中测量得出误差大于0.2 m的情况则为定位错误。原始YOLOv5模型在试验编号3、4出现定位错误;Faster R-CNN模型在试验编号1、4、8出现定位错误;改进YOLOv5模型仅有试验编号6出现了定位错误,错误率相比之下有所降低。综上所述,改进YOLOv5模型对蕉穗底部果轴定位能够达到试验目的,效果相比原始YOLOv5模型和Faster R-CNN模型都得到提升。
5 结 论
为了实现果园环境蕉穗的快速识别定位,该研究在YOLOv5模型的基础上添加了CA注意力模块和C3CA特征提取模块,提升网络对蕉穗特征信息的提取;并用EIoU损失函数替换原先的CIoU损失函数;在目标检测阶段回归了蕉穗底部果轴定位点,通过深度相机获取定位点在相机坐标系下的三维坐标。
1)与YOLOv5模型相比,改进YOLOv5模型对蕉穗的识别准确率提升了2.8个百分点,平均精度值提升了0.17个百分点;模型大小减小了1.06 MB。改进模型在模型大小和平均精度值方面都得到提升,减少了训练时的内存损耗,更利于模型的迁移应用,加强室外实时识别的效果。
2)在定位试验中,改进YOLOv5模型的误差均值E和误差比均值E分别为0.063 m和2.992%。较YOLOv5模型降低了0.022 m和1.173个百分点;较Faster R-CNN模型降低了0.105 m和5.054个百分点。改进模型的定位试验误差最低,进一步减小了对蕉穗底部果轴的定位误差。
采用改进YOLOv5模型能较好的在果园环境下进行迁移应用和快速识别定位,能够满足果园环境下香蕉采摘机器人承接机构对蕉穗底部果轴的定位要求。
[1] 段洁利,陆华忠,王慰祖,等. 水果采收机械的现状与发展[J]. 广东农业科学,2012,39(16):189-192.
Duan Jieli, Lu Huazhong, Wang Weizu, et al. Present situation and developent of the fruit harvesting machinery[J]. Guangdong Agricultural Sciences, 2012, 39(16): 189-192. (in Chinese with English abstract).
[2] Duan Jieli, Wang Zhaorui, Ye Lei, et al. Research progress and developent trend of motion planning of fruit picking robot arm[J]. Journal of Intellient Agricultural Mechanization, 2021, 2(2): 7-17.
段洁利,王昭锐,叶磊,等. 水果采摘机械臂运动规划研究进展与发展趋势[J]. 智能化农业装备学报,2021,2(2):7-17. (in English with Chinese abstract)
[3] Liu Y, Ma X, Shu L, et al. From industry 4.0 to agriculture 4.0: Current status, enabling technologies, and research challenges[J]. IEEE Transactions on Industrial Informatics, 2020, 17(6): 4322-4334.
[4] 卢军,桑农. 变化光照下树上柑橘目标检测与遮挡轮廓恢复技术[J]. 农业机械学报,2014,45(4):76-81.
Lu Jun, Sang Nong. Detection of circus fruits within tree canopy and recovery for occusion contour in variable illumination[J]. Transactions of the Chinese Society of Agricultural Machinery, 2014, 45(4): 76-81. (in Chinese with English abstract)
[5] 顾苏杭,马正华,吕继东. 基于显著性轮廓的苹果目标识别方法[J]. 计算机应用研究,2017,34(8):2551-2556.
Gu Suhang, Ma Zhenghua, Lü Jidong. Recognition method of apple target based on sinificant contour[J]. Application Research of Computers, 2017, 34(8): 2551-2556. (in Chinese with English abstract)
[6] Yamamoto K, Guo W, Yoshioka Y, et al. On plant detection of intact tomato fruits using image analysis and machine learning methods[J]. Sensors, 2014, 14(7): 12191-12206.
[7] Kang D, Benipal Sukhpreet S, Gopal Dharshan L, et al. Hybrid pixel-level concrete crack segmentation and quantification across complex backgrounds using deep learning[J]. Automation in Construction, 2020, 118: 103291.
[8] 胡根生,吴继甜,鲍文霞,等. 基于改进YOLOv5网络的复杂背景图像中茶尺蠖检测[J]. 农业工程学报,2021,37(21):191-198.
Hu Gensheng, Wu Jitian, Bao Wenxia, et al. Detection ofin complex background images using improved YOLOv5[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(21): 191-198. (in Chinese with English abstract)
[9] LeCun Yann, Bengio Yoshua, Hinton Geoffrey. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
[10] Girshick R. Fast R-CNN[C]//Santiago: Proceedings of the IEEE International Conference on Computer Vision, 2015: 1440-1448.
[11] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. Advances in Neural Information Processing Systems, 2015, 28: 91-99.
[12] Li J, Liang X, Shen S, et al. Scale-aware Fast r-cnn for pedestrian etection[J]. IEEE Transactions on Multimedia, 2017, 20(4): 985-996.
[13] Liu W, Anguelov D, Erhan D, et al. SSD: Single shot multibox detector[C]//Cham: European Conference on Computer Vision. Springer. 2016: 21-37.
[14] Womg A, Shafiee Mohammad J, Li F, et al. Tiny SSD: A tiny single-shot detection deep convolutional neural network for real-time embedded object detection[C]//Toronto: 2018 15th Conference on Computer and Robot Vision (CRV), 2018: 95-101.
[15] Wang X, Hua X, Xiao F, et al. Multi-object detection in traffic scenes based on improved SSD[J]. Electronics, 2018, 7(11): 302.
[16] Zhai S, Shang D, Wang S, et al. DF-SSD: An improved SSD object detection algorithm based on DenseNet and feature fusion[J]. IEEE Access, 2020, 8: 24344-24357.
[17] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Las Vegas: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779-788.
[18] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]//Honolulu: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2017: 6517-6525.
[19] Redmon J, Farhadi A YOLOv3: An incremental improvement[EB/OL]. (2018-04-08) [2022-08-12] https://arxiv.org/abs/1804.02767.
[20] Alexey B, Wang C, Liao H. YOLOv4: Optimal speed and accuracy of object detection[EB/OL]. (2020-04-23) [2022-08-12] https://arxiv.org/abs/2004.10934.
[21] Fang W, Wang L, Ren P. Tinier-YOLO: A real-time object detection method for constrained environments[J]. IEEE Access, 2019, 8: 1935-1944.
[22] 吕石磊,卢思华,李震,等. 基于改进YOLOv3-LITE轻量级神经网络的柑橘识别方法[J]. 农业工程学报,2019,35(17):205-214.
Lü Shilei, Lu Sihua, Li Zhen, et al. Orange recognition method using improved YOLOv3-LITE lightweight neural network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(17): 205-214. (in Chinese with English abstract)
[23] 赵德安,吴任迪,刘晓洋,等. 基于YOLO深度卷积神经网络的复杂背景下机器人采摘苹果定位[J]. 农业工程学报,2019,35(3):164-173.
Zhao De'an, Wu Rendi, Liu Xiaoyang, et al. Apple positioning based on YOLO deep convolutional neural network for picking robot in complex background[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(3): 164-173. (in Chinese with English abstract)
[24] Tian Y, Yang G, Wang Z, et al. Apple detection during different growth stages in orchards using the improved YOLO-V3 model[J]. Computers and Electronics in Agriculture, 2019, 157: 417-426.
[25] Liu G, Nouaze J C, Touko Mbouembe P L, et al. YOLO-Tomato: A robust algorithm for tomato detection based on YOLOv3[J]. Sensors, 2020, 20(7): 2145.
[26] Fu L, Duan J, Zou X, et al. Banana detection based on color and texture features in the natural environment[J]. Computers and Electronics in Agriculture, 2019, 167: 105057.
[27] Fu L, Duan J, Zou X, et al. Fast and accurate detection of banana fruits in complex background orchards[J]. IEEE Access, 2020, 8: 196835-196846.
[28] Fu L, Yang Z, Wu F, et al. YOLO-Banana: A lightweight neural network for rapid detection of banana bunches and stalks in the natural environment[J]. Agronomy, 2022, 12(2), 391.
[29] Fu L, Wu F, Zou X, et al. Fast detection of banana bunches and stalks in the natural environment based on deep learning[J]. Computers and Electronics in Agriculture, 2022, 194: 106800.
[30] Wu F, Duan J, Chen S, et al. Multi-target recognition of bananas and automatic positioning for the inflorescence axis cutting point[J/OL]. Frontiers in Plant Science, (2021-11-02)[2022-08-12] https://doi.org/10.3389/fpls.2021.705021.
[31] 吴烽云,叶雅欣,陈思宇,等. 复杂环境下香蕉多目标特征快速识别研究[J]. 华南农业大学学报,2022,43(2):96-104.
Wu Fengyun, Ye Yaxin, Chen Siyu, et al. Research on fast recognition of banana multi-target features by visual robot in complex environment[J]. Journal of South China Agricultural University, 2022, 43(2): 96-104. (in Chinese with English abstract)
[32] Wu F, Duan J, Ai P, et al. Rachis detection and three-dimensional localization of cut off point for vision-based banana robot[J]. Computers and Electronics in Agriculture, 2022, 198: 107079.
[33] Hou Q, Zhou D, Feng J. Coordinate attention for efficient mobile network design[EB/OL]. (2021-03-04) [2022-08-12] https://arxiv.org/abs/2103.02907.
[34] Zhang Y, Ren W, Zhang Z, et al. Focal and efficient IOU loss for accurate bounding box regression[EB/OL]. (2022-07-16) [2022-08-12] https://arxiv.org/abs/2101.08158.
Recognition of bananas to locate bottom fruit axis using improved YOLOv5
Duan Jieli1,2, Wang Zhaorui1, Zou Xiangjun1, Yuan Haotian1, Huang Guangsheng1, Yang Zhou1,2,3※
(1.,,510642,; 2.,510600,; 3.,,514015,)
Banana has been one of the major fruits in the production and consumption in China. But, the banana harvesting is a high labor consuming activity with the low efficiency and large fruit damage. This study aims to improve the operation efficiency and quality of the banana in the picking robot. An accurate and rapid recognition was also proposed to locate the fruit axis at the bottom of banana using the YOLOv5 algorithm. Specifically, a coordinate attention (CA) mechanism was fused into the backbone network. The Concentrated-Comprehensive Convolution Block (C3) feature extraction module was fused with the CA attention mechanism module to form the C3CA module, in order to enhance the extraction of the banana feature information. The original Complete Intersection over Union (CIoU) of loss function was replaced with the Efficient Intersection over Union (EIoU). As such, the convergence of the model was speeded up to reduce the loss value. After that, the anchor point was determined for the test to improve the regression formula of prediction target box. The camera coordinate system of the point was transformed to deal with the three-dimensional coordinates. D435i depth camera was then used to locate the fruit axis at the bottom of banana. The original YOLOv5, Faster R-CNN, and improved YOLOv5 model were trained to verify the model. The accuracy of the improved model increased by 2.8 percentage points, the recall rate reached 100%, and the average accuracy value increased by 0.17 percentage points, compared with the original. There were the 52.96 percentage points higher precision, 17.91 percentage points higher recall, and 21.26 percentage points higher average precision value, compared with the Faster R-CNN model. The size of the improved model was reduced by 1.06MB, compared with the original. The field test was conducted on July 1, 2022 in Dongguan Fruit and Vegetable Research Institute, Guangdong Province, China. A test was realized for the random real-time location of the fruit axis at the bottom of banana in the field environment. The original YOLOv5, Faster R-CNN, and improved YOLOv5 model were used to recognize and localize the single and double plants in the range of 1.0-2.5 m. Each model was tested for 10 times. The estimated and real values were recorded to calculate the mean error, the mean error ratio, and the mean value. The original YOLOv5, Faster R-CNN, and improved YOLOv5 model all performed better to identify the banana in the field of view within the localization range and the estimated values. Among them, the mean errors were 0.085, 0.168, and 0.063 m, respectively, while the mean error ratios were 4.165%, 8.046%, and 2.992%, respectively. The mean values of error and error ratio in the improved model were reduced by 0.105 m, and 5.054 percentage points, respectively, during the original training, compared with the Faster R-CNN model. By contrast, the error and error ratio of the improved YOLOv5 model were reduced by 0.022 m and 1.173 percentage points, respectively, compared with the original. In addition, the measurement error greater than 0.2 m in the test was a locating error. Only test 6 showed the locating errors with the low error rate in the improved YOLOv5 model. The locating errors were found in tests 3 and 4 of the original, while the Faster R-CNN model showed the localization errors in the tests of 1, 4 and 8. Together with the ideal localization, the lower error and higher dimensional accuracy, the improved YOLOv5 model was conducive to the migration application and rapid recognition of bananas in the complex environments. In this case, the vision module of banana picking robot can meet the requirements for the axial locating of the undertaking mechanism at the bottom of banana fruit in the field environment.
image recognition;robots; banana picking; fruit axis location; attention mechanism; loss function
10.11975/j.issn.1002-6819.2022.19.014
S225.93
A
1002-6819(2022)-19-0122-09
段洁利,王昭锐,邹湘军,等. 采用改进YOLOv5的蕉穗识别及其底部果轴定位[J]. 农业工程学报,2022,38(19):122-130.doi:10.11975/j.issn.1002-6819.2022.19.014 http://www.tcsae.org
Duan Jieli, Wang Zhaorui, Zou Xiangjun, et al. Recognition of bananas to locate bottom fruit axis using improved YOLOv5[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2022, 38(19): 122-130. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2022.19.014 http://www.tcsae.org
2022-08-12
2022-09-29
岭南现代农业实验室科研项目(NT2021009);国家重点研发计划项目(2020YFD1000104);财政部和农业农村部:现代农业产业技术体系建设专项资金(CARS-31-10);广东省现代农业产业技术体系创新团队建设专项资金(2022KJ109)
段洁利,博士,博士生导师,研究方向为智能农业装备。Email:duanjieli@scau.edu.cn
杨洲,博士,博士生导师,研究方向为水果生产机械化与信息化。Email:yangzhou@scau.edu.cn
猜你喜欢
中学生数理化·七年级数学人教版(2022年6期)2022-06-05
导航定位学报(2022年2期)2022-04-11
保健医苑(2021年9期)2021-09-08
导航定位与授时(2020年5期)2020-09-23
铁道通信信号(2020年9期)2020-02-06
中国外汇(2019年20期)2019-11-25
煤炭工程(2019年6期)2019-06-22
中国铁道科学(2019年1期)2019-02-19
中国设备工程(2018年14期)2018-08-09
中学生数理化·七年级数学人教版(2018年4期)2018-06-28
