
改进卷积神经网络的苹果叶分类方法
2022-01-21 04:24王文涛柳鸣赵志伟王嘉鑫
中南民族大学学报(自然科学版) 2022年1期
王文涛,柳鸣,赵志伟,王嘉鑫
(中南民族大学 计算机科学学院,武汉 430074)
植物病害对作物产量产生严重负面影响.现有植物病害分类和识别的主要方法是人参与病叶分类和识别,存在分类所需时间长、病叶分类准确率低的问题.而模式识别是从植物叶片图像中自动分割疾病,这为现有方法提供了新思路.
识别植物是否患病及病类为多分类问题.2012年,WANG等[1]利用k-means算法对图像进行分割,手动提取特征后,将BP神经网络分别用作识别葡萄疾病和小麦疾病的分类器.同年TINA等[2]采用层叠泛化结构将3种基于支持向量机的分类器的分类决策结合起来从低级分类器产生的中间类别中提取中间特征,训练高级支持向量机,纠正颜色、纹理和形状支持向量机产生的错误,提高识别性能.2017年,KUMAR等[3]分别基于空间特征和小波特征对神经网络进行训练和性能计算,用小波特征进行训练时提高了模型准确率.同年,OUPPAPHAN等[4]依据HE等[5]的理论,改进了基于残差模块的卷积模型,改进了基本模型的分类准确率和时间开销.2018年CHOUHAN[6]等基于细菌觅食优化径向基函数神经网络方法,给径向基函数神经网络分配最佳权重,来进一步提高网络的速度和准确性.使用区域生长算法通过对具有共同属性的种子点进行搜索和分组来提高网络分 类 效 果.2020年,AVERSANO等[7]分 别 使 用VGG19[8]、Xception[9]和ResNet(Residual Networks)[10]模型加以迁移学习的方法来提升模型的精度.虽然这些方法都在一定程度上解决了植物病态分类准确率不高的问题,但在分类模型中存在的标签模糊的问题仍未被改进.
本文改进了一个神经网络训练模型DenseNet[11](Densely Connected Convolutional Networks)来进行苹果病叶的多分类任务,为了减轻训练时的过拟合,训练时在数据层面使用GridMask[12]删除输入图像中的一组不连续的像素值,同时保留输入图像的部分信息.使用广义平均池化(Generalized Mean Pooling,GeM)[13]增大输入特征的对比度,加强模型对细节特征的提取、标签平滑LS(LabelSmoothing)[14]作为损失函数来提升模型的泛化能力.
1 相关工作及方法
1.1 主要流程
主要对传统神经网络分类过程增加数据增强同时改进模型池化及损失函数(图1).

图1 主要方法流程图Fig.1 Main method flow chart
1.2 数据增强
单纯使用已有的病叶分类算法训练出来的模型泛化能力不强,只能识别原始图像与病叶特征差异很大的图像,而那些较小差异很难被检测出来,在不更改模型的情况下提高准确性和泛化能力,使用数据增强的方法突出某些感兴趣的信息,同时抑制一些不需要的信息,提高图像的使用价值.
现有最常用的数据增强方法为信息删除,但容易造成目标保留和删除之间的不平衡[15].GridMask[12]方法是以结构化的方式来删除区域,删除区域是一组空间均匀分布的正方形区域.在这种结构中,通过控制被删除区域的密度和大小,使删除区域和被删除区域在统计分布上更平衡.如图2所示,GridMask输入一幅图像x∈RH×W×C,M∈{0,1}H×W为待除去像素点的二进制掩膜(M=1则保留像素,否则移除),x͂=x×M.(r,d,δx,δy)表示一个M块,每个遮挡都是通过如图2中单元平铺组成.r是每个单元中较短灰度边缘的比率.d是每个单元的长度,δx,δy是图像的第一个完整单元和边界之间的距离.
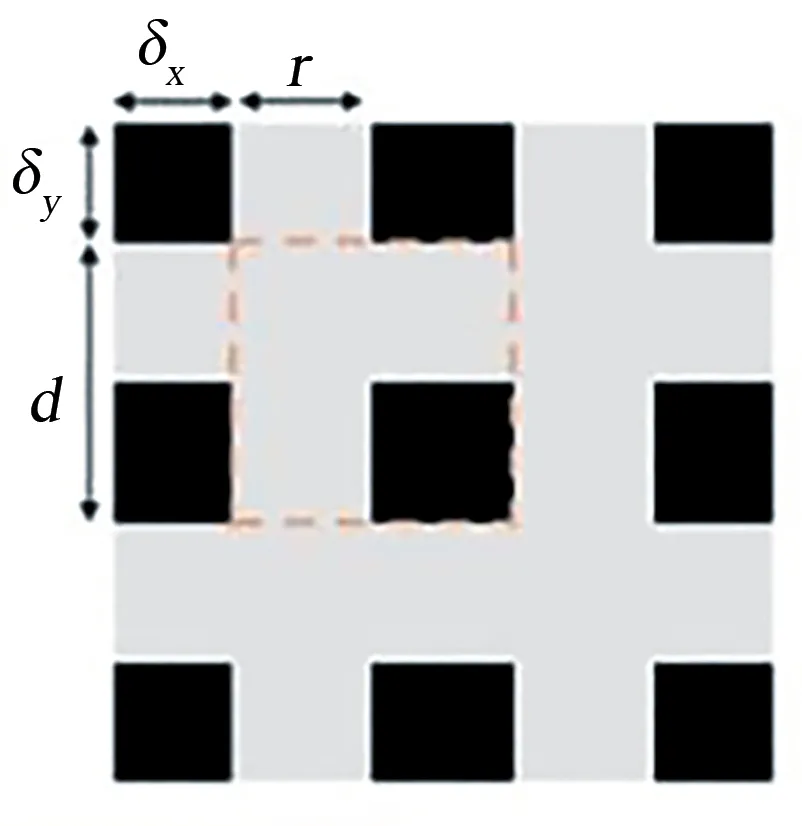
图2 基于GridMask的掩膜单元Fig.2 Mask unit based on GridMask
一个GridMask对应4个参数,分别是x、y、r和d,通过这4个参数确定一组特定的mask.实际应用的过程中,还对该Mask进行了旋转.
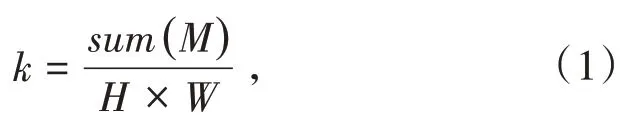
如公式(1)所描述k为图像信息的保留比例,其中H和W分别是原图的高和宽,M是保留下来的像素数,保留比例k计算公式如公式(1),该参数k和上述的4个参数无直接关系,但间接定义了r,如公式(2):
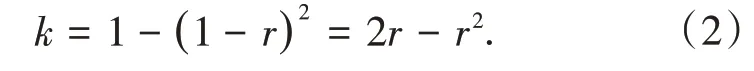
每个单元内d的长度不影响k的大小,但是它决定了裁剪块的大小.当r是定值时,一个裁剪块的长度l=r×d训练时保持比例k不变.通过改变d的值增加随机性扩大图像训练时的特征.如公式(3):
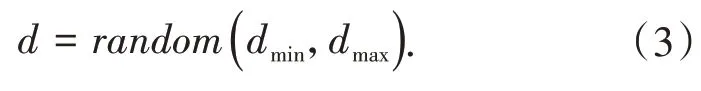
再次使用random函数在给定r和d基础上,改变单元和边界之间距离δx,δy,如公式(4)所示:
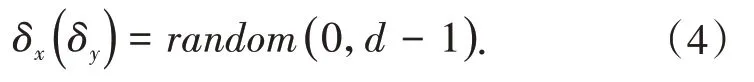
1.3 神经网络模型
基于共享权重结构和平移不变性的特点,深度神经网络(DNN),尤其是卷积神经网络(CNN),被广泛用于图像分类任务,并且自2012年以来在图像分类领域取得了不错效果[16].DenseNet[11]密集连接网络作为残差网络ResNet[10]的逻辑扩展,ResNet[10]残差连接以相加的方式把每层与前一两层进行连接,逻辑上可以表示为:
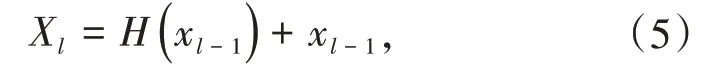
而密集连接网络将每一层的特征图连接在通道维度上,逻辑上可以表示为:
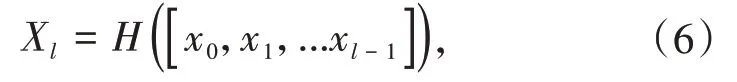
Xl为第l层的输出,[x0,x1,…xl-1]为前l-1层的所有特征图的拼接.H()是包含Batch Normalization(BN)、ReLU和卷积组合的一个非线性函数.由于能获得前面所有层的特征信息,使得特征信息和梯度被更好地保留和重用,用更深的模型来训练数据集,增加网络识别特征的能力,其中DenseNet[11]前向传播如图3所示.
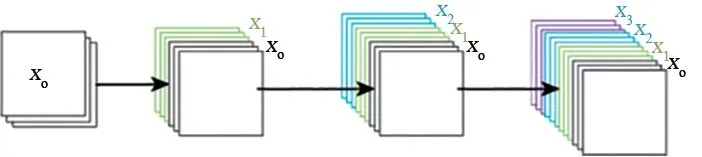
图3 DenseNet前向传播图Fig.3 DenseNet forward propagation
Dense Block(密集连接块)和过渡层(transition)共同组成DenseNet[11]网络结构,由于需要接受每层的特征图,在深层网络里如果不限制特征图数量,导致拼接后的特征图数量较大.为了便于融合各特征通道,在每3×3卷积之前,引入1×1卷积作为瓶颈层(图4),以减少输入特征图的数量,压缩模型参数,从而提高计算时间开销.
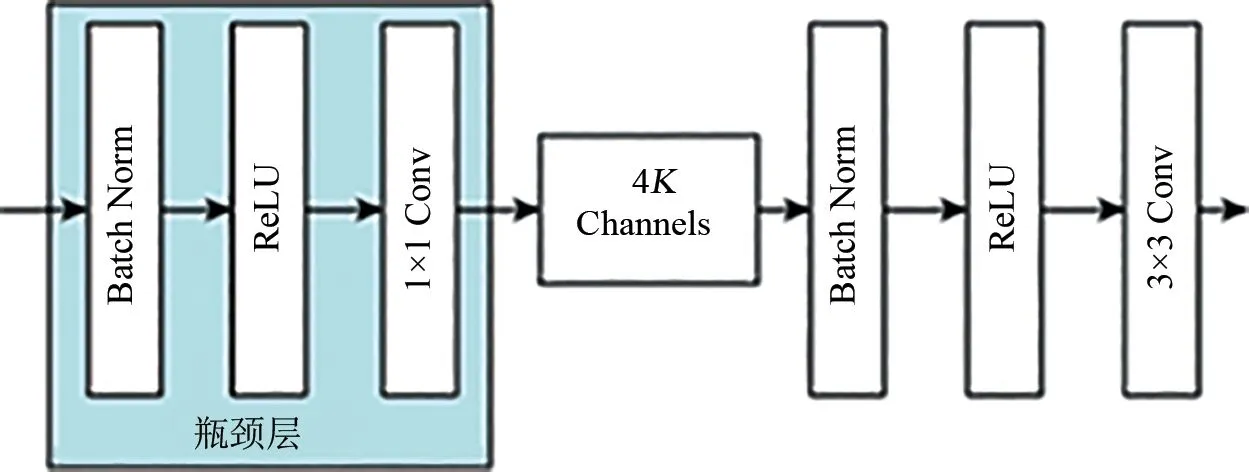
图4 Dense layer结构Fig.4 The structure of Dense layer
对于过渡层,如果上一层的dense block输出m个特征映射,过渡层生成θm个特征映射,其中0≤θm≤1称为压缩因子,当θm=1时,特征映射保持不变;当θm<1时,过渡层能够压缩模型.
在 大 规 模ILSVRC 2012(ImageNet)[17]数 据 集上,DenseNet[11]的 精 度 与ResNet[10]相 似,但 是DenseNet[11]使用的参数数量不到ResNet[10]的一半,而且DenseNet[11]中FLOP的数量则大约一半.不仅如此,本文在DenseNet[11]的基础上,在最后一层池化,使用了一个带指数参数p的广义平均池化[13],改进了池化策略来提升模型分类时鲁棒性.它具有可学习的参数,可以是一个全局参数,也可以是每个输出维度一个参数.最大池化(maxpooling)和平均池化(meanpooling)为参数p分别为∞和1的特殊情况.实验表明,由于卷积层比全连接层提取的特征效果更好,一般从CNN中提取出的特征形如W、H、K,W、H分别是图像经过卷积后的宽高,K是通道数.等式右边的每一个f则代表每个通道中各个小块对应的特征值,也写作Xk.最大池化是从某通道的所有特征中提取其中最大值作为该图的整体特征,而平均池化将所有小块的均值作为整体特征,f(g)和f(m)是最大池化和平均池化后的全局特征.其结果由公式(7)~(9)给出:
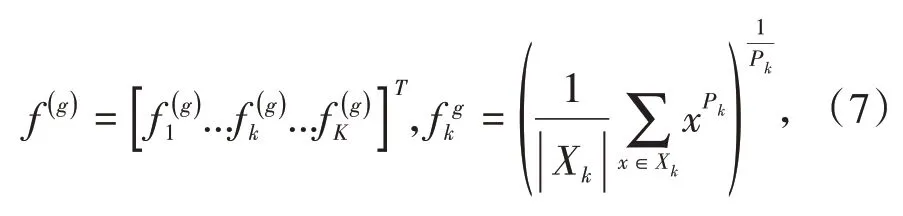
对于最大池化:
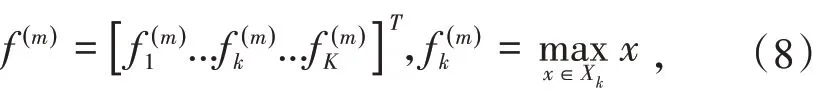
对于平均池化:

其中x是卷积三维张量中第k个特征图的所有元素.图像分类需要更多的特征信息,最大池化仅计算每个特征图的最大值,平均池化平均计算每个特征图的所有响应值,这两种方法都削弱了具有区分度的特征值.GeM[13]将整张图每个像素的pk次方求和再开pk次方,当pk>1时会增大输入特征的对比度,专注于输入特征图突出的部分.从后文的实验显示,最大池化分类效果一般比平均池化模型分类准确率要好,最大池化、平均池化和广义平均池化区别在于聚合过程每个特征图pk的取值,当pk从1到∞的过程中,也就是平均池化到最大池化变化过程中,可能会出现一个局部最优解或者全局最优解,广义平均池化[13]相当于整合了最大池化和全局池化信息,达到提升模型分类精度目的.论文中使用的广义平均池化结构与各分类模型全局最大池化结构相同.
1.4 损失函数
在图像分类任务中,交叉熵(Cross Entropy)是最常见的损失函数,交叉熵损失(即对数损失)衡量的是输出为0到1之间的概率值的分类模型的性能.随着预测概率与实际标签的偏离,交叉熵损失会增加.因此,当实际观察标签为1时预测0.01的概率将很不理想,并导致高损失值.若还存在训练数据包含不正确标签,这将最终导致模型学习数据集中的噪声和不正确的特征,这样会使得出现过拟合和过度自信结果.交叉熵使用的one-hot编码产生的真实标签概率值(0和1)不能保证模型的泛化能力.本文使用标签平滑(label smoothing[14])损失函数来解决此类问题,更能反映原始训练图像与贴错标签图像真实差距,预测结果不会过于极端,提高了模型鲁棒性.
在传统的softmax函数层中对每个输入样本x模型分配给第k(k∈{1…K})类概率为:
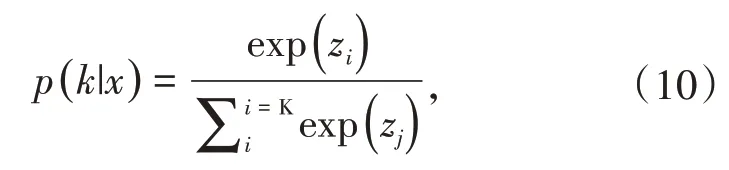
其中zj是第i个节点的输出值,最终真实标签q(y()这类标签经过one-hot编码)及其交叉熵损失函数为:
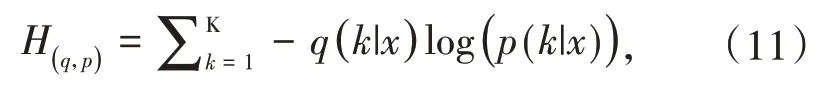
这时,为了解决标签错误导致模型的过度自信,对标签进行平滑处理,平滑后的标签概率qLS(k|x)为:
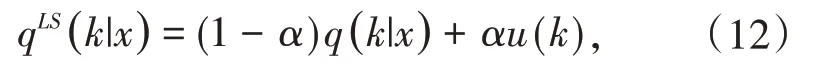
其中u(k)=服从均匀分布,K为类别数,此时平滑后的交叉熵损失函数为:
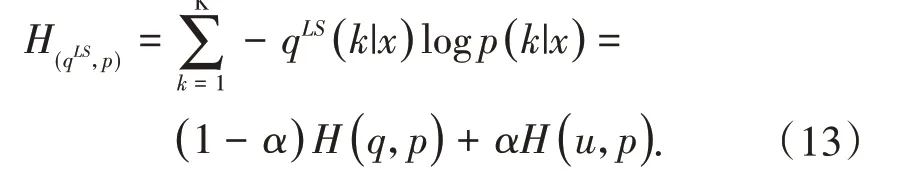
标签平滑[14]会促使网络倒数第二层的激活值更接近真实类别的类中心.本文使用此方法来解决病叶标签贴错问题,达到了更好的分类效果.
2 模型训练和实验结果分析
为了验证本文方法的有效性,实验在Plant Pathology 2020-FGVC7[18]数据集上进行,该数据集是由Zach Guillian团队在纽约日内瓦康奈尔农业科技公司(Cornell Agriculture)一个未浇水的苹果园中,从商业栽培品种中捕捉到的2019年生长季节多个苹果叶面疾病症状高质量、真实的RGB图像.如图5、6、7、8为数据集4个类别的原始图像.健康苹果叶(healthy)示例如图5.健康的叶子是完全绿色的,没有任何棕色或者黄色的斑点或疤痕,健康的叶子不会结痂斑或生锈斑.

图5 健康苹果叶示例Fig.5 Example of healthy apple leaves
结痂斑苹果叶(scab)示例如图6.带有“疮痂”叶子在整个叶子上有很大的棕色痕迹和污渍.结痂被定义为“由真菌或细菌引起的各种苹果叶疾病,在果实、叶子或根上产生硬壳状斑点”,棕色斑点是这些细菌或真菌感染的标志.

图6 结痂斑苹果叶示例Fig.6 Example of scabbed apple leaves
锈斑苹果(rust)叶示例如图7.带有“铁锈”的叶子在图片中有几个棕黄色的斑点.锈病易发生在谷物和其他水果叶上,其特征是受影响的叶片和叶鞘上的锈色孢子脓包,这是由几种锈菌引起,黄色斑点是一种叫做“锈菌”的特殊真菌感染的迹象.

图7 生锈斑苹果叶示例Fig.7 Example of rusty apple leaves
多种疾病苹果叶示例如图8.叶子表现出几种疾病的症状,包括棕色斑点和黄色斑点,这些苹果叶有不止一种上述疾病.

图8 多种疾病苹果叶示例Fig.8 Example of apple leaves with multi disease
2.1 模型训练
原始输入训练数据共1820张苹果叶图片,健康、结痂斑、锈斑、多疾病4类苹果叶样本比例为6∶1∶6∶6,由于卷积神经网络CNN分类准确度依赖原始数据.在数据平衡方面,本文使用旋转、水平或垂直翻转的方式(图9)对多种疾病苹果叶(multidisease)进行图像处理后混合至原始训练中,达到扩充多种疾病苹果叶(multi-disease),使训练数据4类样本比例达到1∶1∶1∶1.

图9 经翻转后的多种疾病苹果叶Fig.9 Multi disease apple leaves after flipping
不同的病叶对应不同的病叶特征,在输入模型前需要对图片数据进行预处理,本文首先对不同光照下的叶子图片数据进行光照处理,由于病叶的数量分布不均匀,基于原数据采用数据增强方法使模型能应对更多图像,从而提升模型泛化能力,防止模型过拟合.
在数据增强阶段,为了在不更改模型的情况提高模型的泛化能力,实验使用GridMask[12]方法,部分结果如图10所示.

图10 GridMask增强后的训练集示例Fig.10 Examples of training set enhanced by GridMask
在实验中遇到同一种病态苹果叶图被不同类的标签所标注(图11),图11(a)、图11(b)根据病理都属于多种疾病苹果叶,而图11(b)被错分为生锈斑苹果叶.训练和验证集划分按照8∶2比例划分,实验结果以总体分类精度(over all,OA)、Kappa系数(K)和召回率(recall)来评估.总体分类精度是指被正确分类的类别像元数与总的类别个数的比值.对于Kappa系数,总体样本数为n,Po是每类正确样本数除以样本总和,即整体样本精度,a和b分别为真实和预测样本数量,recall直接由sklearn中的混淆矩阵给出,其中Kappa系数和召回率(recall)计算公式如下:

图11 被不同标签标注的同一苹果叶Fig.11 The same apple leaf marked by different labels
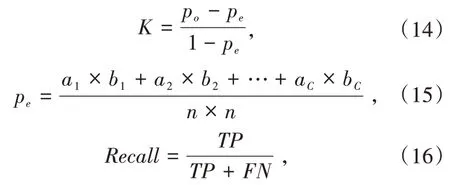
TP是指各类样本中预测为正样本,实际也为正样本的数量,FN是指各类样本中预测为负样本,实际也为正样本的数量.
2.2 实验结果分析
对于图11存在的错标问题,本文改进的模型将图11(b)错标的病叶分类为正确的标签,对于标签模糊问题起到了较好分类的作用.结果如图12.
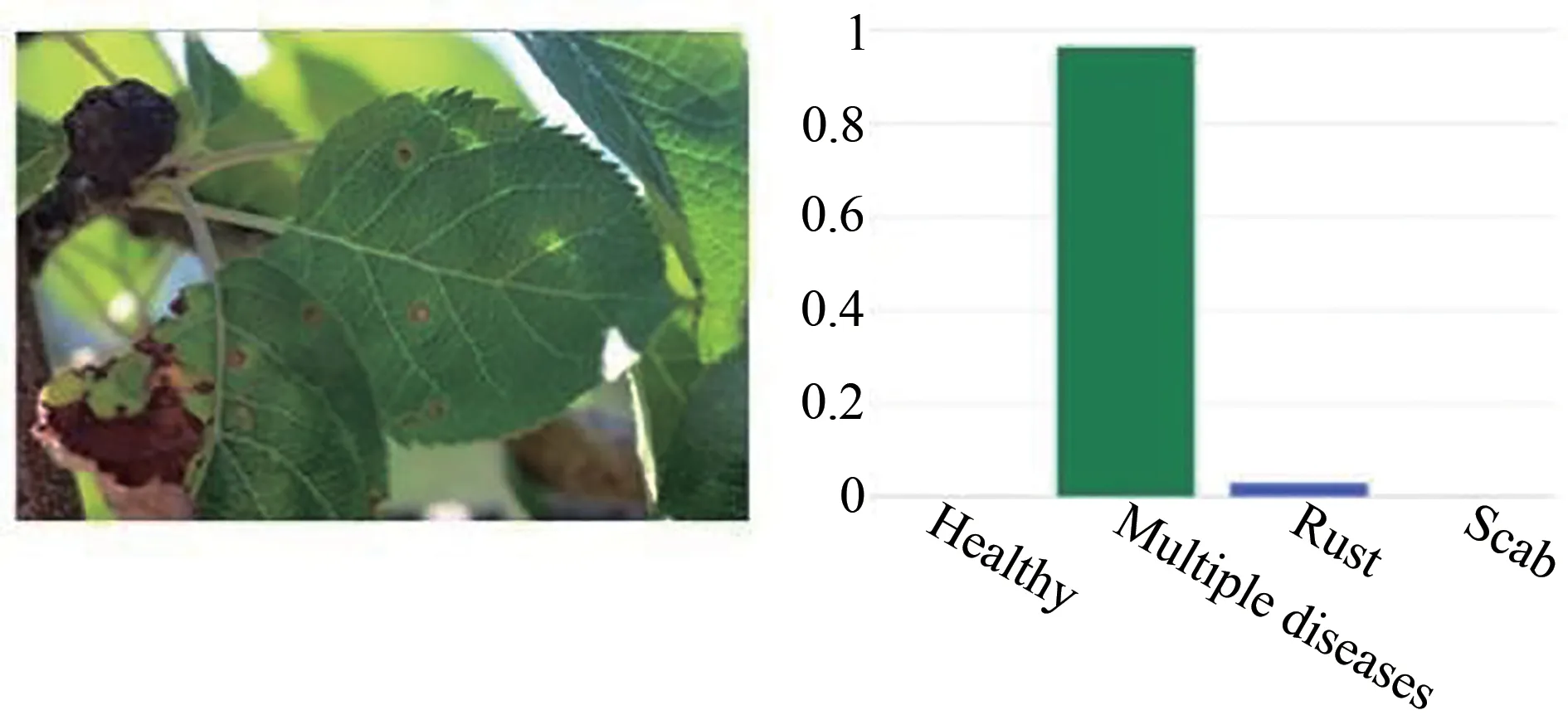
图12 对不同标签标注样本的分类结果Fig.12 Classification results of samples marked with different labels
为了增强实验效果和验证模型的有效性,增加了一个与原数据集特性相近plant village数据集做对比实验,选取了该数据集苹果类别中健康苹果树叶(healthy),雪松锈病叶(Cedar_apple_rust),黑腐病叶(Black_rot)以及黑星病叶(Apple_scab)共1600张图片按照1∶1∶1∶1作单独训练实验和模型迁移学习训练.训练plant village之前已删除重复图像和标签模糊的图像,作为原始模型迁移到Plant Pathology 2020-FGVC7[18]进行训练.
表1是各个模型分布在两个数据集上单独训练的结果,图13是选取了3个训练模型验证集损失值变化,从结果上来看本文所使用的神经网络(DenseNet_121)模型和深度可分离卷积Mobilenet模型的分类率性能相差不大或者更加优异,从表后两列来看本文改进神经网络所使用的数据增强方法GridMask[12]、广义平均池化(GeM)[13]、损失函数labelsmoothing[14]在抑制过拟合、提高模型的鲁棒性方面起到了很好的作用.
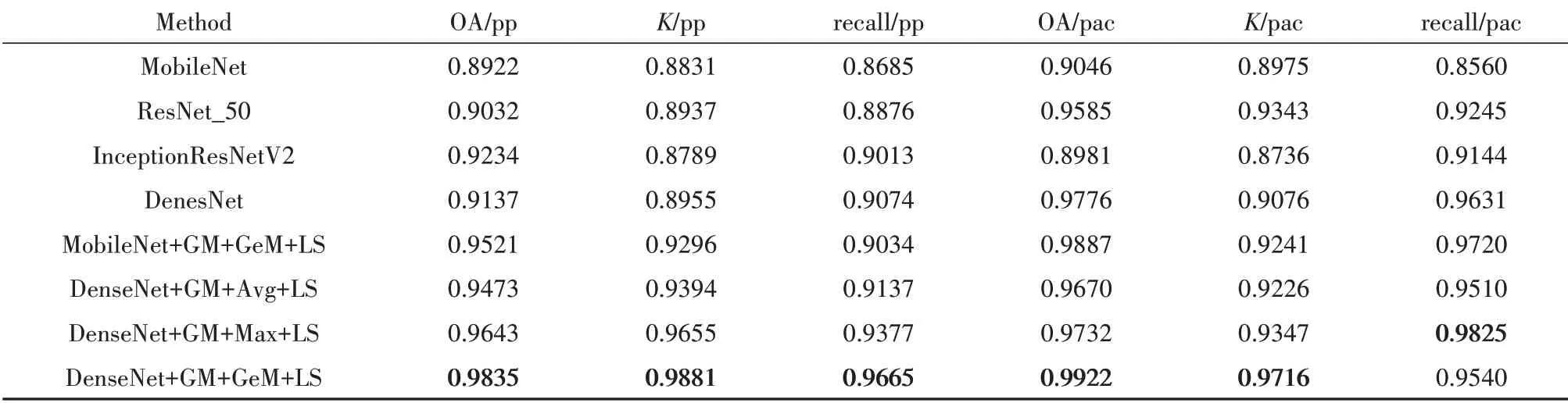
表1 各个模型在不同数据集上单独训练总体分类结果Tab.1 Each model independently trains the overall classification accuracy on different data sets
图13中选取的模型分别为DenesNet、MobileNet+GM+GeM+LS和本文模型,用来反映损失值变化情况,未经改进的原始DenseNet模型的loss最小值和变化平稳程度略差于本文改进模型,可见本文改进的模型对提升模型鲁棒性有一定的作用.
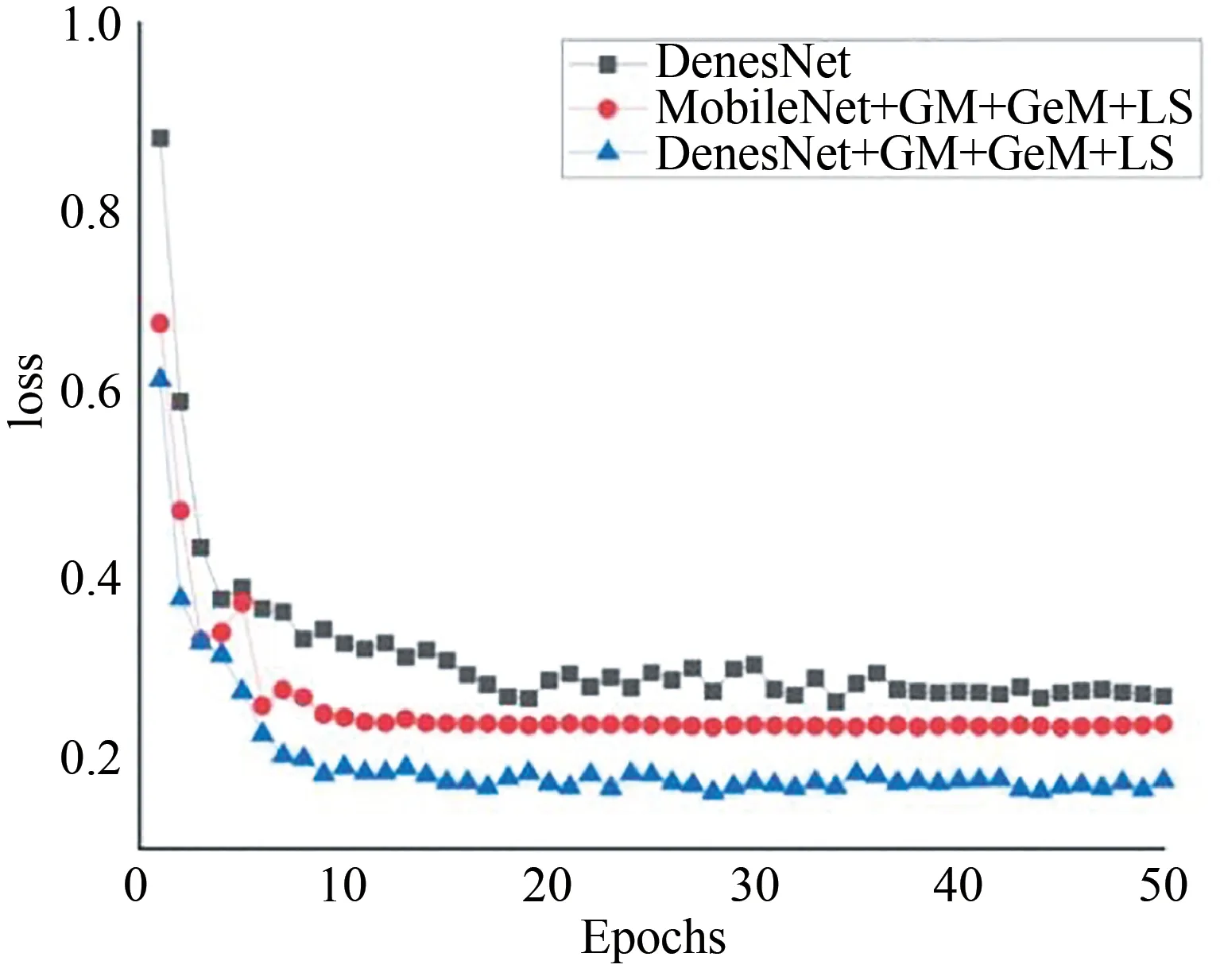
图13 不同分类模型loss值变化情况Fig.13 Changes of loss values of different classification models
不仅如此,本文在数据混合时所采用的迁移学习(TL)方法,将plant village数据集上训练好模型迁移到Plant Pathology 2020-FGVC7[18]数据集上进行训练,结果如表2、3.
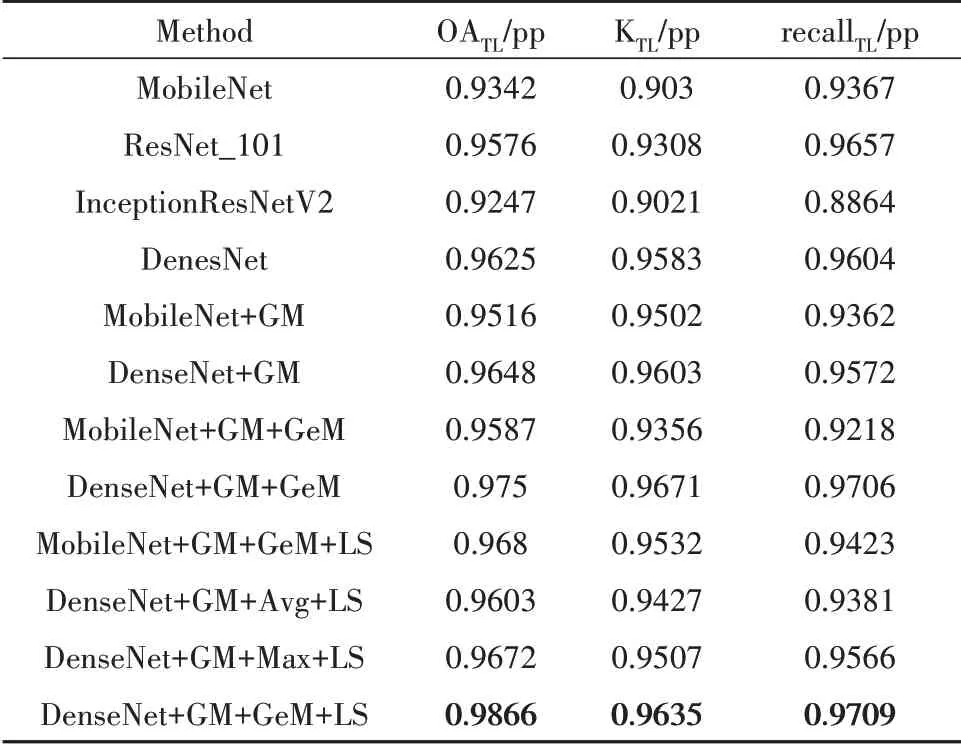
表2 各模型迁移训练PlantPathology2020总体分类结果Tab.2 The classification accuracy transfer method trains on PlantPathology2020
为了达到更好的分类准确率的效果,本文两次模型训练时都使用了GridMask[12]+GeM[13]+LabelSmoothing[14]方法,所取得的分类结果比在Plant Pathology 2020-FGVC7[18]单独 训练的结果有所提升,对每一个EPOCH在分类时间开销上结果如表4,其中,相较于普通卷积网络时间复杂度Time~O(M2∙K2∙X∙Y),DenseNet[11]时 间 复 杂 度 为Time~O(DenseNet[11]将每一层时间复杂度进行累加(M2表示特征图的面积大小、K2表示卷积核的面积大小、X表示当前层的输入通道个数、Y表示当前的输出通道个数,N为卷积层个数),结合迁移学习的DenseNet[11]具有更少的时间开销.
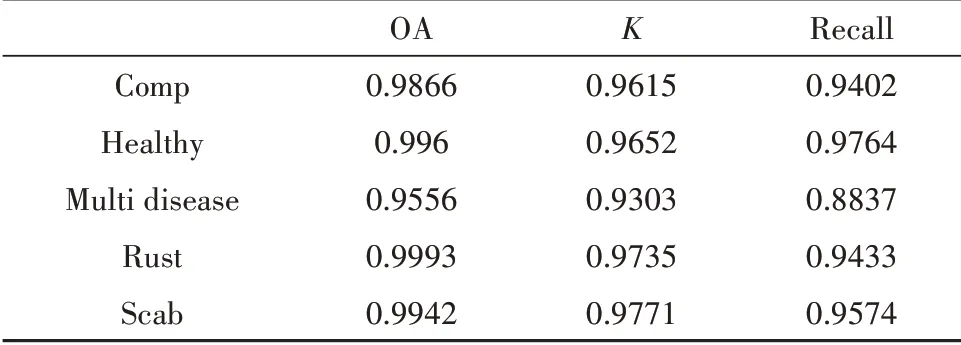
表3 本文方法病叶分类结果Tab.3 accuracy of diseased leaves by method of this paper

表4 本文方法训练每个Epoch的平均时间(秒)Tab.4 Average time(s)for training each Epoch by these methods
表格中模型参数计算使用的神经网络框架为TensorFlow2.3.0版,测试实验所使用的硬件为i7-8700(CPU).
为了检测模型的泛化能力,本文在多种疾病的苹果叶上使用CycleGan模型[19]将锈斑病苹果叶风格迁移到正常叶子生成新的具有锈斑病苹果叶风格测试集,如图14所示.对于所有生成的100张测试图片,本文所用改进的模型分类准确率为0.87、召回率为0.89,由于标签模糊的影响,这个结果符合预期.

图14 风格迁移后测试分类器效果图Fig.14 Test classifier renderings after style transfer
实验中设置的各个参数说明:在各个模型里设置的神经网络优化器为随机梯度下降(Stochastic Gradient Descent,SGD),LearningRate设置为0.00016,BatchSize为16,本文训练50轮并保存验证集上准确率最高的模型.GridMask[12]参数ratio(r)参考的原文中的0.6,GeM[13]和LabelSmoothing[14]的各项参数都为原文的默认参数,GeM[13]的p选取的默认值3,La⁃belSmoothing[14]中参数α=0.02.
3 结语
针对判断苹果树叶是否为病叶的问题,本文在数据层面使用数据增强的方法减轻训练时的过拟合,在模型层面改进池化策略,并通过改进损失函数来提升模型的泛化能力.在数据集Plant Patholo⁃gy 2020-FGVC7[18]和plant village数据集上分别对4个模型进行训练与测试均取得了较好的分类结果.最后将plant village数据集预训练好的模型迁移到Plant Pathology 2020-FGVC7[18]数据集上进行训练和测试,结果表明提升了分类器的准确率.未来将改进和优化更优良的算法和模型.
猜你喜欢
计算机应用(2022年9期)2022-09-25
农业工程学报(2022年12期)2022-09-09
软件导刊(2022年3期)2022-03-25
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
智能计算机与应用(2018年2期)2018-05-23
海峡姐妹(2018年3期)2018-05-09
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
