
基于用户会话的TF-Ranking推荐方法
2022-01-19 12:43:20孙静宇
应用科学学报 2021年3期
贾 丹, 孙静宇
1.太原理工大学信息与计算机学院,山西太原030024
2.太原理工大学软件学院,山西太原030024
近年来,作为新型智能工具,推荐系统已经被广泛地应用在视频推荐、广告推送、网上购物等诸多领域中。其作用表现在两方面:1)推荐系统可以快速地为用户提供有效信息;2)通过有效推荐促进消费,在用户和商家之间建立稳定牢固的关系。推荐系统的本质是对用户意图的预测。在一定的时间内,用户意图受到各种因素的影响会发生改变,如兴趣演变、及时需求和全球主流时尚[1]。传统的推荐方法只关注了用户最后一次的反馈行为,忽略了用户会话中的历史行为。但用户的历史行为是用户兴趣的具体体现,对预测用户兴趣偏好具有重大意义。文献[2] 提出了推荐系统的概念。2006年10月,Netflix 举办了一场算法比赛,其目标是提高原有算法——Cinematch 算法的推荐准确率。比赛获胜团队采用了融合矩阵分解的玻尔兹曼机算法,将推荐算法的正确率提高了10%,大大推动了推荐系统的发展[3]。2012年之后,随着深度学习技术的日趋完善,深度神经网络也被广泛应用到了推荐系统领域中。2015年,文献[4] 提出了基于用户会话的推荐系统模型。该模型利用循环神经网络学习用户的序列化数据信息。2016年,文献[5] 加入了Dropout 网络对数据进行降噪处理。同年,文献[6]基于深度神经网络技术,实现了从大规模可选内容中找到最有可能的推荐结果。这些模型充分利用循环神经网络和长短期神经网络的特点,学习具有序列化特征的商品用户数据,从而大大提升了推荐系统的性能和用户体验。但是,这些模型均基于分类或回归原理,忽略了推荐系统的本质:为网络用户提供最佳的商品排名清单。2018年,谷歌研发团队针对此问题提出了TF-Ranking 模型,该模型处理速度快,质量高,是一个优秀的排名模型[7]。本文基于用户会话,提出了一种融合XGBoost 和门控循环单元网络的改进TF-Ranking 推荐方法,并在Trivago RecSys Challenge 2019 数据集上进行了实验。
1 相关技术
1.1 GRU 门控单元网络
循环神经网络可以处理时间序列化数据。但是传统的循环神经网络存在一个明显的缺点,即短期记忆会对预测结果产生较大的影响,并且随着序列数据长度的增加,这种影响也在不断增强。为解决长短期依赖的问题,文献[8] 于1997年提出了长短期记忆(long short-term memory, LSTM)网络,LSTM 的核心是1 个神经元状态(cell state)和3 个不同作用的控制门(gates)机制。3 个门控制单元分别是输入门(input gate)、输出门(output gate)和遗忘门(forget gate)。3 个门用来调节信息流,通过学习一条完整序列中最重要的信息来减弱短期记忆的影响。但LSTM 结构复杂且矩阵参数较多,因此增加了训练的难度[9-11]。
其工作原理主要包含3 个步骤。首先需要通过t −1 时刻隐藏层状态和t时刻的输入得到2 个门控单元,如式(1) 和(2) 所示。
2014年,文献[12] 提出了门控循环单元(gate recurrent unit, GRU),GRU 网络简化了LSTM 网络,并且得到了与LSTM 几乎相同的实验结果。如图1 所示,为代替LSTM 中的3个控制门,GRU 设置了更新门(update gate)和重置门(reset gate)。更新门用来决定哪些信息要被丢弃,哪些新的数据需要被保留;重置门用来决定网络需要丢弃多少历史信息。GRU将所有要传递的信息存储于隐藏层状态里。
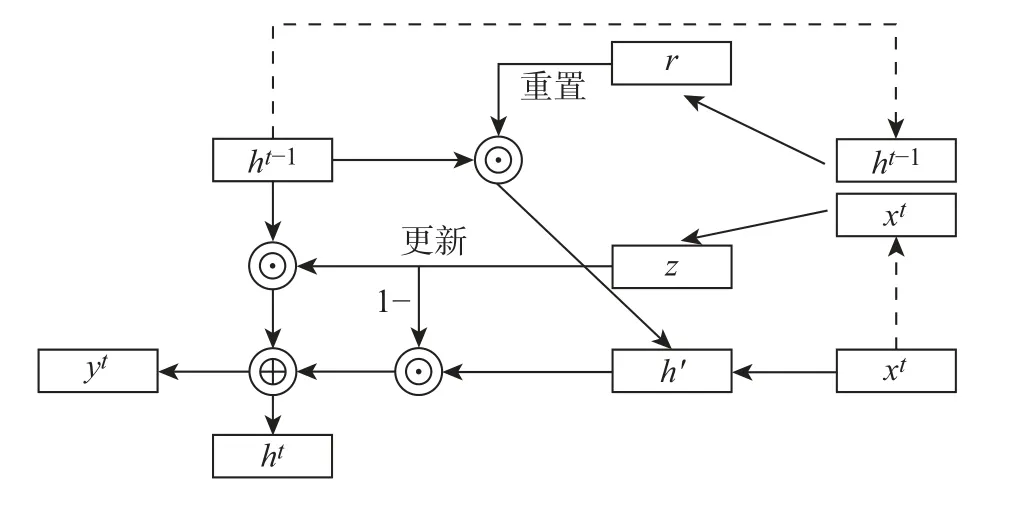
图1 门控循环单元Figure 1 Gated recurrent unit

式中:r是重置门,z是更新门,σ是sigmoid 激活函数。然后对重置门和t −1 时刻隐藏层状态ht−1进行点积运算,将得到的结果和t时刻的输入拼接成向量并通过tanh 函数缩放到−1到1 之间,有
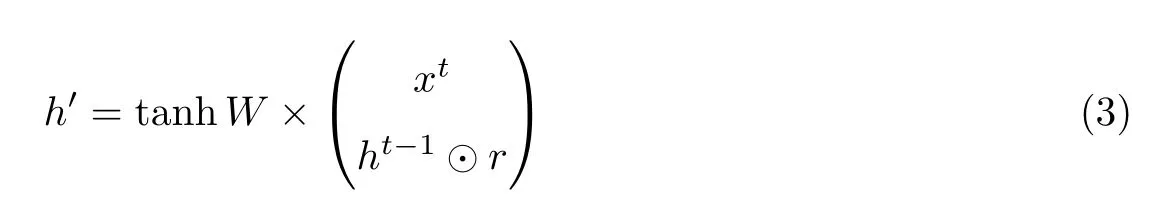
最后的关键步骤是决定t时刻隐藏层的状态,即
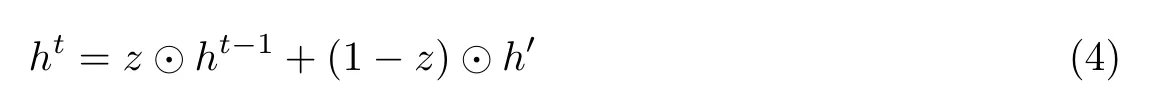
式中:z ⊙h(t−1)表示t −1 时刻要遗忘的数据,(1−z)⊙h′表示需要选择性记住的数据。结构更简单的GRU 大大降低了神经网络对硬件计算能力的要求,从而也减少了时间成本。
1.2 提升树模型和XGBoost
梯度提升树与监督学习有关,监督学习一般涉及两个问题:分类和回归。分类问题强调的是历史数据“是不是”以及“是什么”的问题;而回归问题则强调如何根据历史数据形成可预测的趋势。
梯度消失是训练神经网络中经常遇到的问题,为了避免梯度消失带来的权重无法更新的问题,可以使用提升树模型来学习参数。
本文之所以引入XGBoost 对特征进行描述是因为该技术具有以下3 个优势:
1)因为XGBoost 具有执行单调约束的特点,所以输入和目标变量可以严格地沿一个方向变化。XGBoost 可以控制输入变量和目标变量之间的关系,使其仅为非递减或非递增,保证其变化速率恒定可测。
2)XGBoost 使用了最佳优先树生长策略。树中的节点按顺序展开,从而减少了大部分损失。
3)将Dropout 网络应用到提升树中。传统深度学习技术的Dropout 网络用来随机丢弃一些神经元的连接,将Dropout 网络应用到提升树中,可以代替收缩的正则项。
XGBoost 是改进的提升树模型,它所定义的目标函数不仅包含训练损失,还有一个正则项。训练损失函数决定模型在数据上如何学习参数,常用的损失函数有均方差和logistic 函数。正则项的作用是控制模型的复杂度,使得数据分布更加均匀、有效和整齐[13]。XGBoost中每一棵树的节点代表数据的一个特征描述,每一条分支用来表达该特征是否被满足。从根节点到叶子节点的这条路径就是对每一个项目的部分特征描述[14-15]。在树集成模型中包含k个函数,最终一个项目的评分预测就是这k个函数的累加和,公式为
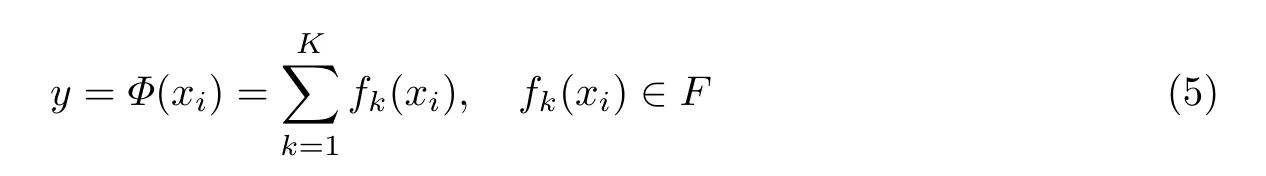
式中
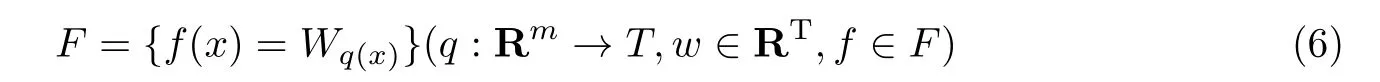
式中:Wq(x)表示叶子节点x的最终得分。最终的目标函数为
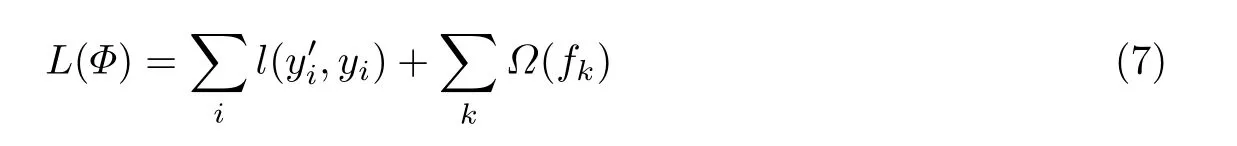
式中:k棵树的正则项
1.3 排名函数
传统排序问题的本质是分类和回归问题,其目标是尽可能准确地预测一个商品的标签或者一个商品的评分[16]。但是,在推荐系统中,用户并不关心商品是否为一支笔或者该笔的评分是否为4 颗星。因此,推荐系统主要研究的不再是评分和贴标签问题,而是排名问题。排名问题更多关注的是相关项目的相对顺序,而不是项目的绝对得分。所以将组合不同的排序模型进行数据训练,通过神经网络不断调节权重参数,从而得到最优排名。这种方法叫做Learning to Rank 方法,简称LTR。
排序学习有3 个重要步骤:1)收集和标注训练数据;2)通过训练数据得到排序模型;3)将学习到的排序模型应用到新查询中。图2 是排序学习系统框架示意图。LTR 模型有3 种训练数据的方法:1)针对每一个查询,模型都给出了一个相关度系数,且每个相关度系数彼此独立;2)模型会随机组合结果列表中的两个文档,并计算这个两文档相对于查询的相关度;3)模型会根据所有查询结果形成一个关于相关度的排序列表。与3 种训练数据方法相对应的3 种LTR 算法是Pointwise 方法、Pairwise 方法和Listwise 方法。
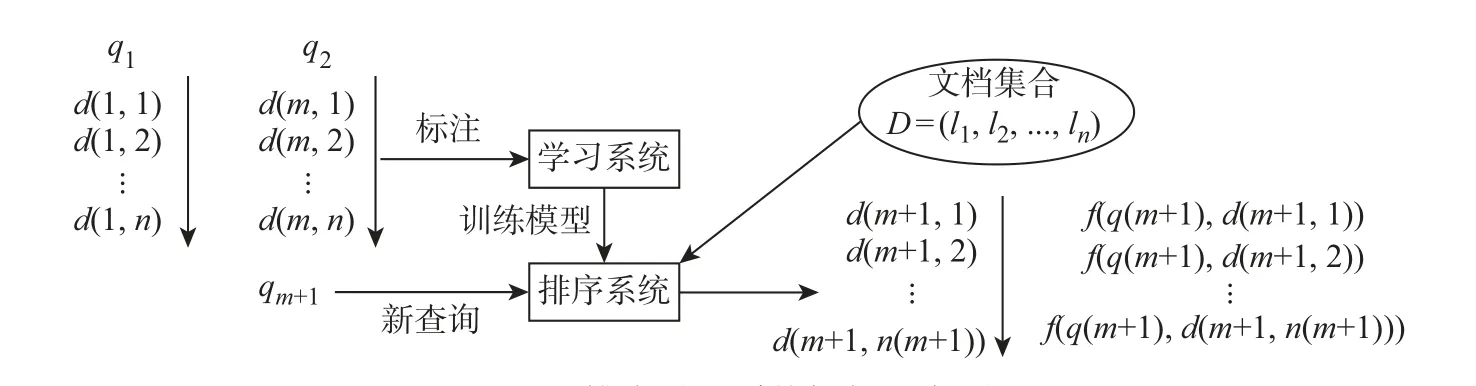
图2 排序学习系统框架示意图Figure 2 LTR system diagramm
Pointwise 方法关注的是某一个时刻查询结果中单个文档对于查询的相关程度,最后通过结果列表中的得分简单地进行排序。查询列表结果中每一个文档的得分是彼此独立的。Pairwise 方法考虑了两个文档相对于目标查询的相关程度。使用Pairwise 方法得到1 组有序对以及这两个文档相对于查询文档的相关度,其目标是尽量减少逆序的数量。
Listwise 方法对整个查询结果集合进行排序,因此输入数据量大,训练的复杂度也大。而本文使用Pairwise 方法,如图3 所示。模型的输入是两个相对于查询目标的相关文档,这两个相关文档相对于目标文档的相似度分别为(d1,p1)和(d2,p2),于是可以根据p1和p2来判断两个文档相对于查询目标的相关度,相关度高的会被放在列表清单中的前端。该方法的优势在于,通过对两个文档相关系数进行标记来比较这两个文档相对于查询目标的相关度,选择出相似度高的文档,尽可能地减少查询结果逆排序的情况,从而达到为用户提供一个尽可能满足其意愿的排名列表。
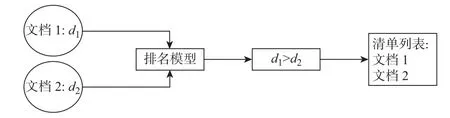
图3 Pairwise 方法Figure 3 Pairwise method
2 核心模型及模型改进
2.1 基于用户会话的GRU 推荐
一般的推荐平台只关注到了用户最后一次的点击事件,却忽略了用户的历史行为。因此,使用GRU 学习用户会话数据,更好地利用历史数据建立长期的User-Item 模型,并预测下一时刻可能的用户点击事件。
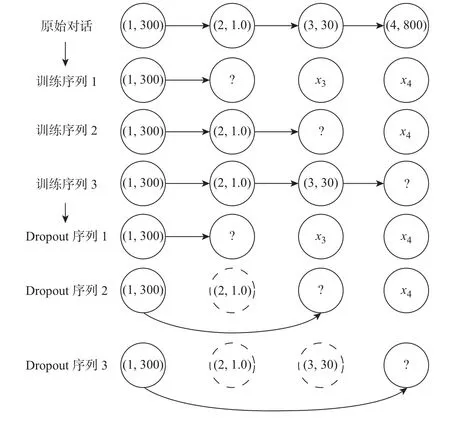
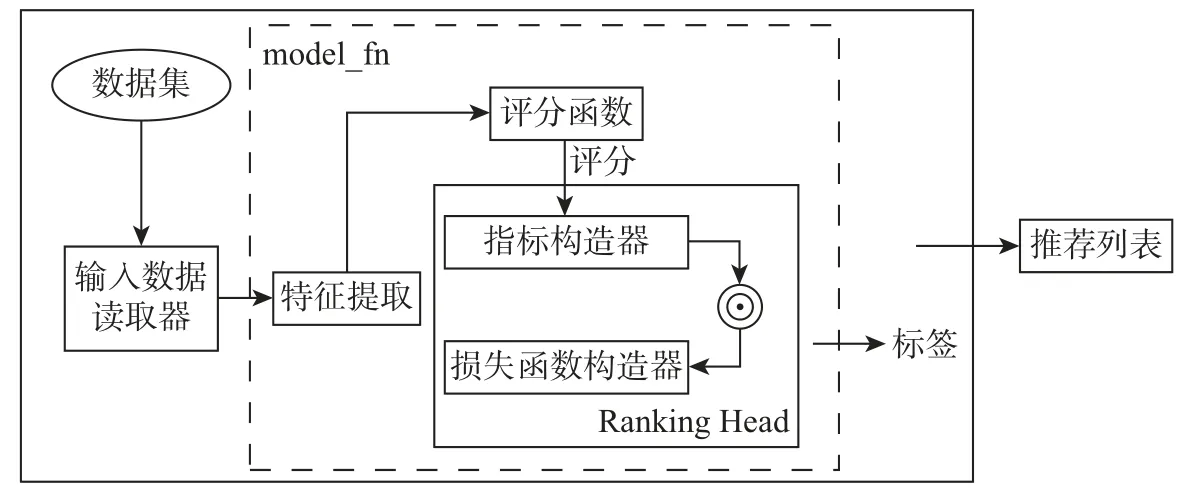
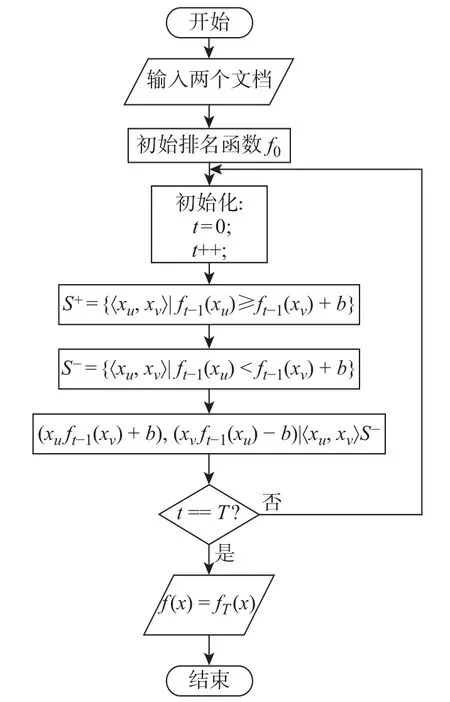
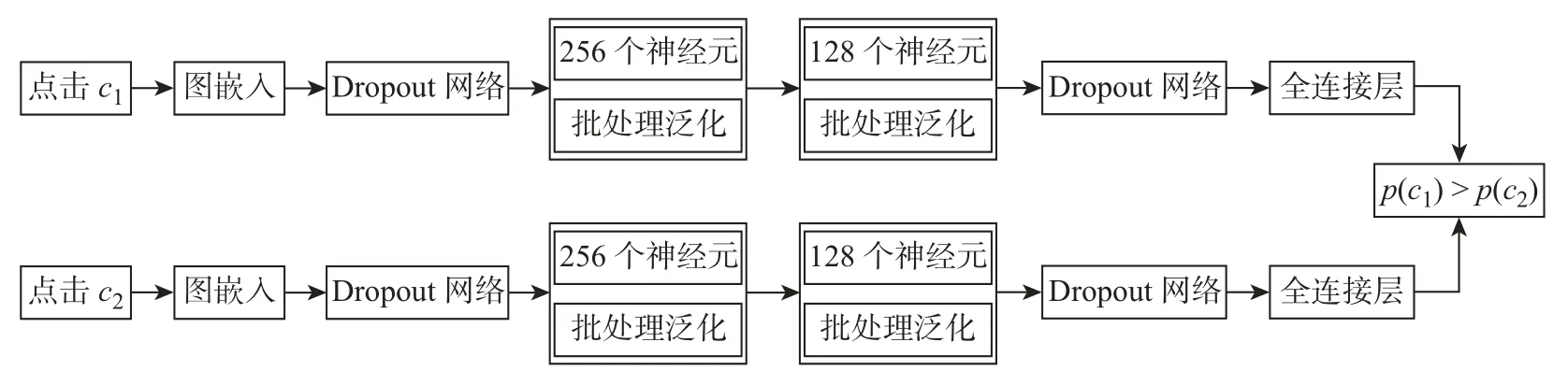
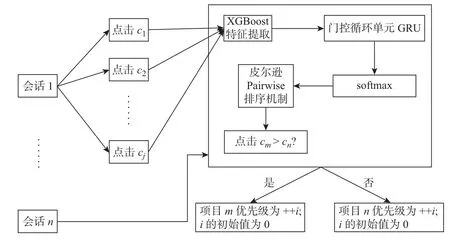
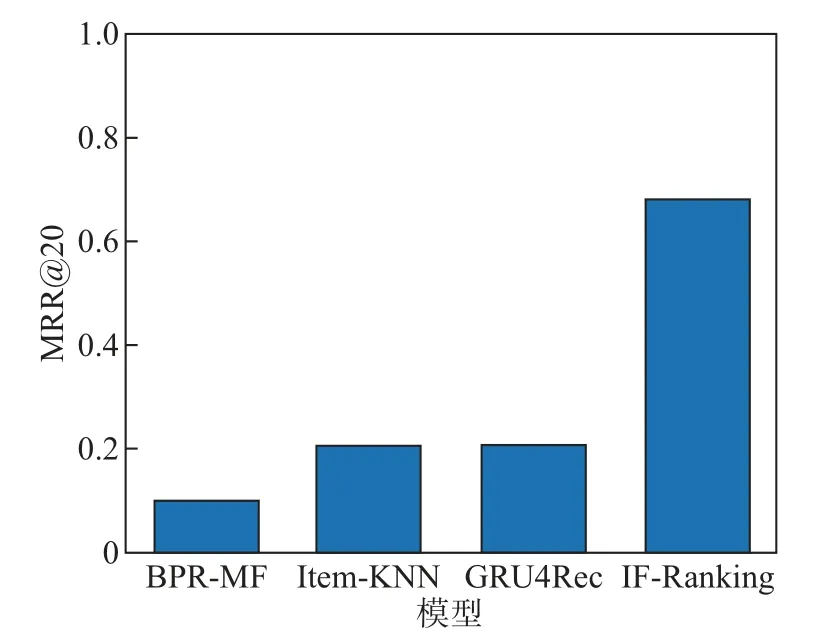
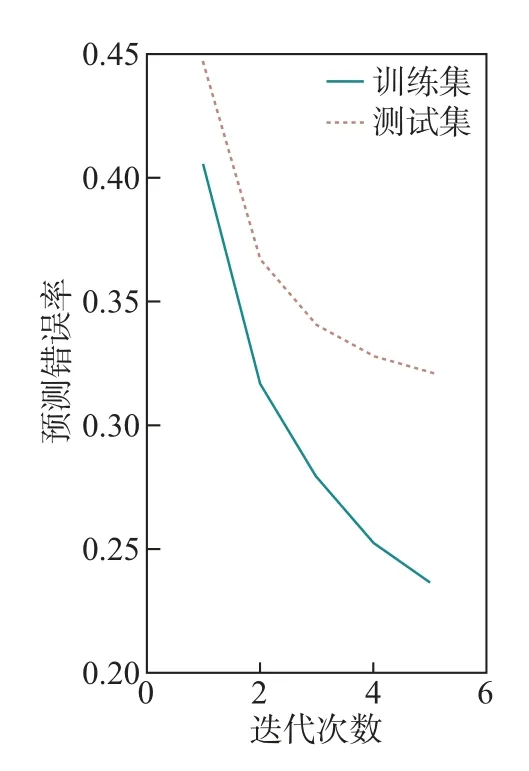
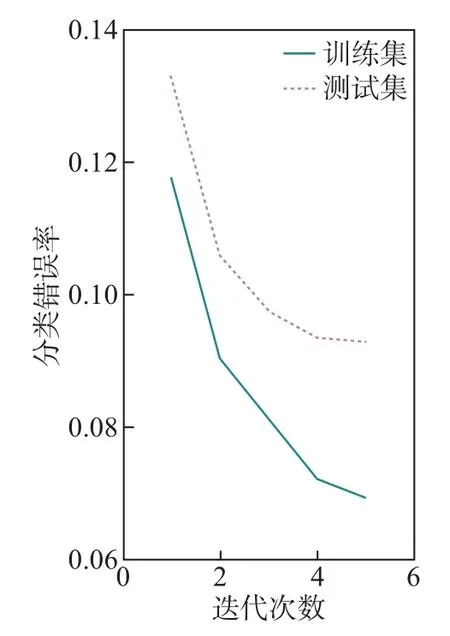
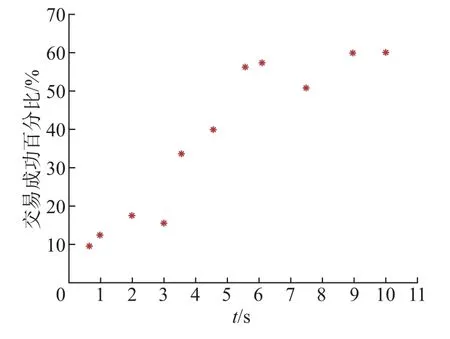
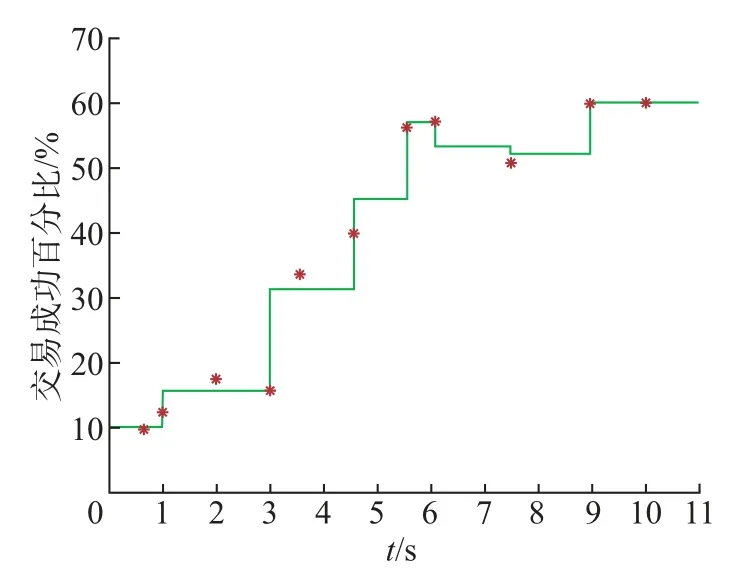
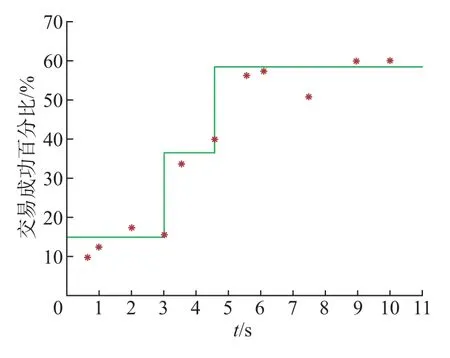
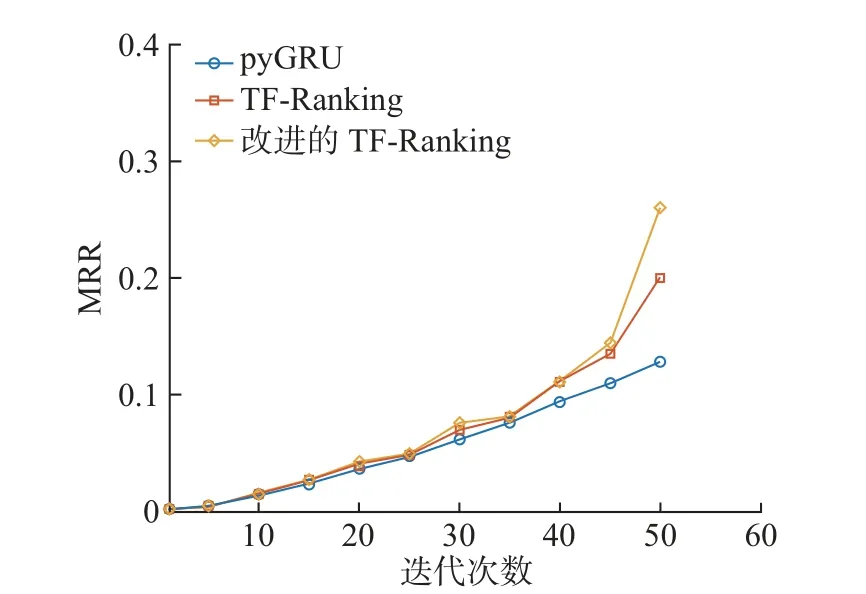
在一个点击会话中包含n个Items,即[x1,x2,··· ,xn],构建一个模型M只能接收一个会话S中的前j(1 ≤j 图4 GRU 网络处理单个序列Figure 4 Training procedure for a single sequence in our GRU 通常用户会话的长度是变化的,一些用户在找到心仪项目之前可能已经点击了很多项目,而另一些用户可能很快就找到了目标项目。本文引入Dropout 网络进行数据管理。如果输入的训练序列是[x1,x2,··· ,xn],则会产生一组序列及与之相对应的标签([x1],V(x2)),([x1,x2],V(x3)),···, ([x1,x2,··· ,xn−1],V(xn))。通过一个嵌入的Dropout 网络随机删除会话中的点击,并对数据进行正则化处理,使输入数据分布更加均匀,以此减少噪声数据。 本文对Dropout 进行了优化,如图5 所示,所提到的方法不会随机删除点击,而是选择与前一点击事件间隔时间较短的点击即会话中停留时间(dwell time)最短的点击进行删除;同时还设置一个时间戳,当计算出来的dwell time 小于该时间戳时,这个点击会被删除。因为当用户对一个项目产生兴趣时,就会在本链接或网页上浏览更多的信息,故停留在该项目上的时间就较长;反之,如果用户匆匆关闭该页面或跳转到另一个链接上,则在本项目上的停留时间就较短,所以该点击就被视作不被感兴趣的项目或者是被误点击的项目。会话S中的每一个点击事件xi是一个二元组,记作xi=(i,di),其中i是点击事件xi的唯一标识,di表示用户在会话S中的xi项目上的停留时间,di的计算式为 图5 用改进后的Dropout 网络处理数据Figure 5 Preprocessing with improved Dropout network 式中:ti+1为点击事件xi+1发生的时间,t为点击事件xi发生的时间。 TF-Ranking 的核心组件是一个model_fn 函数,该函数会接收特征和标签作为输入,并根据不同的模式(TRAIN、EVAL、PREDICT) 返回损失、预测、度量指标和训练操作。使 2018年,谷歌提供了一个开源库,叫作TF-Ranking,是一个基于Tensorflow 并且在深度学习场景中可以实现LTR 方法的框架。TF-Ranking 可以实现并优化Pairwise 和Listwise 排名损失、多项目得分、排名指标等。用TF-Ranking 构建model_fn 函数是基于评分函数和排名头[19]进行组合的。图6 给出了一个TF-Ranking 模型,其使用方法很简单,包含4 个核心步骤:定义评分函数、定义测量指标(metric)、定义损失函数(loss function)、构建排名统计量(ranking estimator)。 图6 TF-Ranking 模型Figure 6 TF-Ranking model Scoring Function 评分函数具有同时支持单个项目评分函数和多项评分函数的功能。单项评分函数通过函数f(x) = [h(x1),h(x2),··· ,h(xn)] 来建模,其中输入数据h(xn) 代表单个示例的特征,计算出f(x) 作为输出。一般情况下通过一组参数使f(x) 参数化,记作f(.,θ)。TF-Ranking 使用Ranking Head 为一个排名逻辑具体化指标和损失。核心算法如图7所示。 图7 算法流程图Figure 7 Algorithm flow diagram 本文使用具有以下结构的正向神经网络:两个分别具有256 和128 个神经元的隐藏层,每个神经元后跟一个批处理规范化层[20],如图8 所示。同时将批处理规范化应用于输入数据中。一个学习速率等于0.5 的Dropout 层会应用到最后一个隐藏层中。而输出层也是一个密集层,这个输出层包含大量的神经元,其数量等于需要评价得分的项目Item。 图8 本文模型Figure 8 Proposed model 最终改进后的模型如图9 所示,该模型不仅使用XGBoost 进行特征提取,还引入了具有位移不变性的皮尔逊相关系数描述项目之间的相似性。经过改进Dropout 网络后的会话点击依次进入网络,然后利用XGBoost 对其进行特征提取,并且利用GRU 学习数据,最终得知两个文档相对于目标查询的相关度强弱。 图9 GRU 的排名模型Figure 9 Ranking model based on GRU 本文使用了Trivago 网站提供的公开数据集,并且在Trivago RecSys Challenge 2019 数据集上测试了本文提出的模型。该数据集包含了700 000 位匿名用户和81 770 个不同项目的近1 600 万条的会话日志,Trivago RecSys Challenge 2019 数据集提供了4 个数据文件,每条日志会话都包含4 个公有字段user_id,session_id,timestamp 和step,分别如表1~3所示。 表1 数据集介绍Table 1 Information about data set 评价指标选择召回率和平均倒数排名(mean reciprocal rank, MRR)。 表2 数据文件Table 2 Data files 表3 相关属性Table 3 Relevant properties 1)针对不同模型平均倒数的排名情况。图10 是Trivago RecSys Challenge 2019 数据集在不同模型上前20 的平均倒数排名情况,可以看出本文所提模型在性能上得到了很大提高。 图10 模型比较Figure 10 Comparison of different models BPR-MF 算法是结合矩阵分解的贝叶斯个性化排名算法。该算法容易出现冷启动和矩阵高度稀疏的现象;Item-KNN 是基于项目商品的推荐算法,该算法将项目的隐形因子扩展到top-N问题上,在一定程度上解决了稀疏数据集的问题,较之BPR-MF 算法在MRR评价指标上有明显提高;GRU4Rec 算法的推荐性能与Item-KNN 算法相比并没有显著提升;TF-Ranking 算法解决了传统推荐算法过度关注单一项目分类和评分的问题,因此在MRR 指标上的表现明显优于其他3 种算法。 2)使用Dropout 网络对模型正确率的影响。如表4 所示,选取dwell time 短的点击进行删除较之随机删除点击的Dropout 网络的召回率提高了1.32%。同时也在普通神经网络上对较小型的数据集进行实验,实验结果表明,改进后的Dropout 网络正则化效果明显,如图11和12 所示,测试集的预测错误率和分类错误率明显降低。 表4 不同Dropout 网络对比Table 4 Comparison of different Dropout networks 图11 改进后的Dropout 网络预测错误率Figure 11 Error rate on improved Dropout network 图12 改进后的Dropout 网络分类错误率Figure 12 Misclassification rate on improved Dropout network 3)利用XGBoost 提高数据使用效率。图13 是原始数据的分布情况,从图中可以看到,数据分布较分散,不利于数据处理。XGBoost 的关键技术就在于同时使用正则化和训练损失来处理原始数据。如图14 是单独使用正则化处理数据的结果,虽然数据处理准确率较高,但是尚存在过拟合化的问题。如图15 是单独使用训练损失后的数据分布情况,可以看到数据失真率较高。如图16 是使用了XGBoost 后的数据分布情况,其中,横坐标为用户停留时间,纵坐标为用户成功交易的百分比,即此时购买商品的人数占总人数的百分比。从图16 中可以观察到,数据分布得更加均匀有效。 图13 原始数据Figure 13 Original data 图14 使用正则化处理数据Figure 14 Data process with regularization 图15 数据分布Figure 15 Data distribution 图16 使用训练损失处理数据Figure 16 Data process with training loss 4)TF-Ranking 模型在推荐领域中的优异表现。图17 是pyGRU 模型,TF-Ranking 模型和改进的TF-Ranking 模型在不同迭代次数下MRR 的变化情况,从图中可以发现,TFRanking 的数据收敛速度更快,性能更优。 图17 不同模型MRR 对比Figure 17 MRR compare on different models 5)设备的种类和预测准确率的相关性。使用相同设备的用户会话被聚集在一起。被关联设备的会话占比和对应的MRR 如表5 所示。 表5 与设备相关的推荐Table 5 Relevant to device recommendation 实验结果表明,在移动设备上的推荐性能表现良好。因此提出假设如下:由于移动设备的导航性能受到限制,而且进行比较的灵活性较小,因此用户主要关注页面中前几项。 6)用户的交互行为对模型预测准确率的影响。从表6 中可以得到,如果在成交之前恰好只发生了一次(编号1-1),则MRR 很高。相反,如果成交前发生了多次点击(编号1-2),则性能会下降。值得注意的是,当只发生一次点击事件时(编号0-1),性能反而会降低。当没有发生过用户交互时,模型依旧能够以较高的正确率(编号0-0)为用户提供个性化推荐。 表6 交互评估Table 6 Interaction evaluation 本文使用GRU 网络学习用户会话日志中的点击事件,通过TF-Ranking 形成了相关度较高的列表,从而进行个性化的预测和推荐。引入改进的Dropout 网络和树提升模型正则化数据,使数据分布更加均匀同时避免过拟合化。基于Tensorflow 框架,使用TF-Ranking 排名函数得到一个相关性较强的正序排名酒店推荐清单。 本文使用的Pairwise 方法比传统分类和回归方法更加贴近推荐系统的本质,该方法的特点是:被比较的查询结果只有两个,且都将不再被编码。但真实的查询结果往往多于两个文档,因此今后会进一步研究使用Listwise 方法来提供更加准确的相关排名列表。另外,本文使用的所有数据均来自线下的数据集,下一步可以研究如何直接对线上数据进行学习,从而预测用户的下一个点击事件,使在线算法更能满足推荐系统的即时性需要。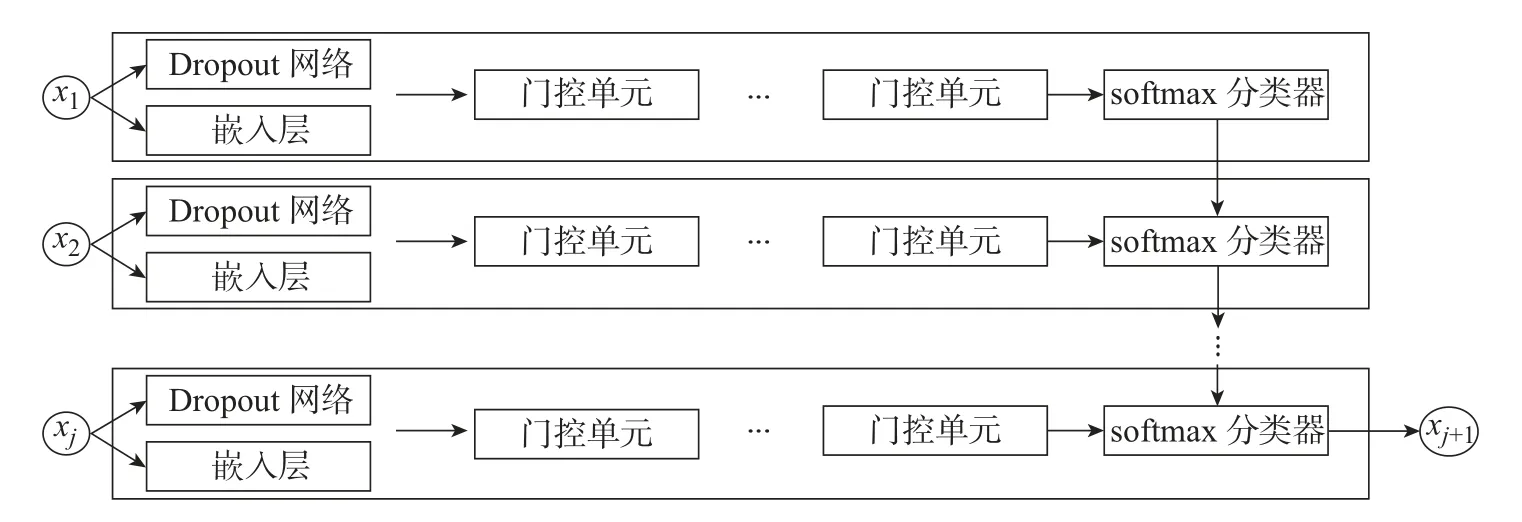
2.2 改进后的Dropout 网络

2.3 TF-Ranking 模型
3 实验结果及分析

3.1 实验数据集


3.2 实验结果分析




4 结 语
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
电子制作(2019年19期)2019-11-23 08:42:00
数学年刊A辑(中文版)(2019年1期)2019-01-31 02:35:44
数学杂志(2018年5期)2018-09-19 08:13:48
信息安全研究(2016年4期)2016-12-01 06:06:54
重型机械(2016年1期)2016-03-01 03:42:04
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
数学年刊A辑(中文版)(2014年5期)2014-11-01 05:43:38
