
基于改进的MMR算法的新闻文本抽取式摘要方法
2022-01-19 12:43:10李传艺贾欣欣葛季栋
应用科学学报 2021年3期
程 琨, 李传艺, 贾欣欣, 葛季栋, 骆 斌
南京大学软件学院,江苏南京210093
自动文本摘要技术能够从海量文本中快速提取有效信息,从而提升信息获取效率。但是在面向新闻领域的应用中,由于不同新闻文本之间长度差异较大,自动文本摘要技术表现出了以下缺点:1)对于长文本,摘要中的重复内容较多,冗余问题较为严重,并且对于特定专业领域的文本优化较差;2)对于短文本,在摘要过程中由于考虑的因素较少,所以摘要质量较低。
为此,结合已有的监督方法和非监督方法,本文分别提出了两个抽取式摘要模型。第1个模型对传统的基于最大边缘相关(maximal marginal relevance, MMR)摘要算法进行了改进,融入了句子位置、标题相似度等多个权重。第2 个模型是结合支持向量机(support vector machine, SVM)和MMR 构建SVM-MMR 的摘要模型,该模型加入了监督学习方法,将新闻摘要视为二分类问题,即新闻文本中的每个句子只存在两种情况:“摘要”与“不摘要”。选取词语、结构和语义3 个方面的特征,将新闻文本中的句子向量化,并通过SVM 进行分类,最后在SVM 分类结果的基础上引入MMR 算法对句子进行二次选择,从而降低摘要的冗余,提高摘要的质量。
基于MMR 摘要算法用来解决文档的排序问题,其核心思想在于平衡文档的相关性和冗余性,使得选出的文档足够准确,从而能够很好地完成文本摘要任务。因此本文所提出的两种算法都是通过改进MMR 算法实现的。
抽取式摘要是一种常用的自动文本摘要技术,包括4 类无监督方法,分别是基于图模型的方法、基于潜在语义的方法、基于线性规划的方法和基于向量空间的方法。基于图模型的方法认为在一篇文本中,如果某句和文中所有句子都有较强的关联,那么这个句子就是该文本的中心句。TextRank 模型[1]及其改进方法[2-3]常用来衡量句子的关联性;基于潜在语义的方法通过挖掘文本的词句隐藏信息来生成摘要[4-5];基于线性规划的方法将抽取式摘要看作在一定约束条件下的最优化问题,并基于整数线性规划(integer linear programming, ILP)[6-7]进行句子摘要和去冗余处理;基于向量空间的方法首先将句子向量化,然后通过计算余弦相似度来衡量每个句子的重要程度[7]。
基于监督学习的抽取式摘要方法先将文本中的句子映射为特征向量,再用决策树[8]、隐马尔科夫[9]、条件随机场[10]等机器学习分类算法来训练模型,进而对文本中的句子进行分类。分类的结果为“1” 或“0”,分别代表该句子能否作为文本最终摘要。文献[11] 提出用SVM作为分类器进行抽取式摘要。文献[12] 以语音摘要为研究对象,利用改进的SVM 模型进行抽取式摘要。文献[13] 通过构造多维度特征对摘要中的句子进行向量化,然后使用SVM 模型对会议记录进行抽取式摘要。文献[14] 利用神经网络模型来拟合ROUGE 分数,最后利用MMR 算法进行摘要。近年来也出现了许多基于深度学习的模型[15-16],这一类模型不需要很多人工抽取的特征,更强调如何设计模型使其能自动地从输入文本中学习特征。
1 基于MMR 的改进模型
在实现该模型时,首先需要综合考虑影响新闻摘要的各个因素,计算新闻文本句子的初始权重。然后,通过改进的MMR 算法对句子的初始权重进行迭代,得到这些句子的最终权重。最后,按最终权重的大小对句子进行排序选出一定比例的句子,进而按照句子在原文中的顺序输出所抽取出的句子得到摘要集。
1.1 影响新闻摘要的因素
根据已有的抽取式文本摘要相关研究成果、对人工标注文本摘要过程的分析以及对新闻文本特点的归纳,本文总结出了以下4 个影响新闻摘要的因素。
1.1.1 句子的位置权重
句子的位置与新闻文本的主题存在相关关系,一般来说,文本的第1 段或最后1 段通常是对整个报道的总结,具有高度的概括性。根据文献[17] 所述,设新闻文本的第1 段由u个句子组成,最后1 段由v个句子组成,文本中句子总数为n,则可设置句子Si的位置权重Lweight(Si) 为
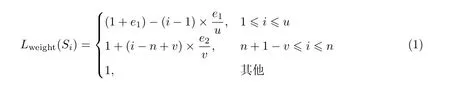
式(1) 保证了在第1 段话中距离第1 句越远的句子,其权重越小;而在最后1 段话中,距离最后1 句越近的句子,其权重越大。式中,e1和e2分别用来控制第1 段和最后1 段所有句子的相对初始权重,一般在0 到1 之间。具体值可以根据待处理新闻文本的特征进行设置。如果新闻中第1 段的概括性更强,则将e1设为比e2更大的数,例如e1为0.5,e2为0.1。
1.1.2 线索词与转折词
线索词和转折词通常引出具有总结性或强调性的句子。包含线索词和转折词的句子往往比不包含该类词的句子更能表达新闻主旨。设ClueWords 代表线索词和转折词,Cweight(Si)表示句子Si的线索词和转折词权重,则该权重的计算公式为

1.1.3 标题相似度
标题往往是新闻内容的高度凝练,因此与标题相似度高的句子应具有更高的权重。本文使用预训练BERT 模型对句子和标题进行向量化,然后将两个向量的余弦相似度作为句子和标题的相似度。设句子Si和标题T的句向量分别为(x1,··· ,xn) 和(y1,··· ,yn),则句子Si的标题相似度权重Sweight(Si) 的计算公式为

1.1.4 关键词权重
含有文本关键词的句子通常比其他句子具有更多的文本有效信息。本文通过TF-IDF 算法来抽取新闻文本和新闻标题中10 个关键词作为关键词表,使用Keywords 表示关键词集合。如果句子中含有关键词,则关键词权重值Kweight(Si) 赋值为1,即

1.2 初始权重计算
得到上述影响新闻摘要的4 个权重值后,需要设计加权算法以计算最终的初始权重。首先由Lweight、Cweight、Kweight加权得到中间权重wmid,即
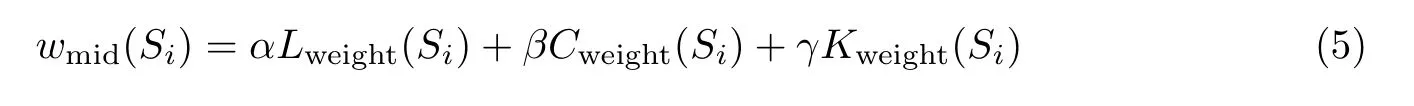
式中:α,β,γ为加权系数,且α+β+γ= 1。在具体应用场景下,加权系数可以根据文本不同级别权重值的取值范围及其重要程度进行设置。
再将中间权重wmid与标题相似度权重Sweight加权,得到句子Si的初始权重w(Si)
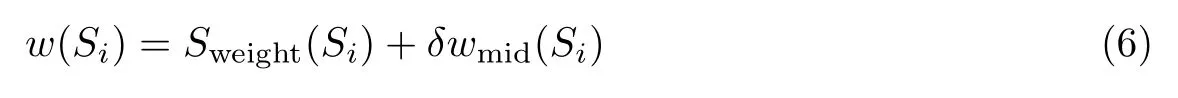
式中,为了保证Sweight和wmid在同一数量级,而且为了能够动态调整wmid的权重,引入了调节因子δ。
1.3 改进MMR 算法
初始MMR 算法是用来根据查询对文档集合进行排序的,本文对MMR 算法进行了改进,使其适用于面向新闻文本的抽取式摘要。
抽取式摘要的目的是对句子进行合理的排序,然后根据顺序选出一定比例的摘要集。根据这个目的,本文设计的面向摘要的MMR 算法如下:

式中:D是通过MMR 算法得到的阶段性候选集,λ为控制摘要概括性与冗余性的一个系数。
该算法的公式共分为两部分,w(Si) 计算的是新闻本文中所有句子的初始权重,similarity(Si,D) 计算的是新闻文本中句子与已入选候选集句子之间的相似度,其中−(1−λ)是负值。如果当前句子与摘要集句子之间的相似度过大,那么该算法会对当前句子的权重进行惩罚,以尽可能地减少摘要集的冗余。
使用该算法对初始权重进行迭代的流程图如图1 所示。
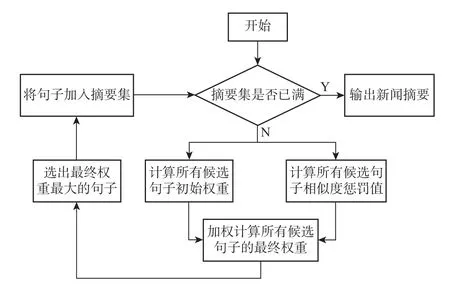
图1 MMR算法流程图Figure 1 Algorithm flow chart of MMR
2 基于SVM-MMR 的融合模型
在实现该模型时,首先需要构造句子特征,将新闻文本中的句子转化为句向量,然后训练并使用SVM 预测每个句子成为摘要的概率值,按概率值大小排序纳入摘要集。对处于摘要比例边缘的句子利用改进的MMR 算法进行二次选择,得到最终的摘要集。
2.1 特征工程
在进行句子特征构造时,本文首先综合选取了3 类特征,分别为词语特征、结构特征和语义特征。其中词语特征14 个,结构特征6 个,语义特征5 个,共计25 个。
然后需要从这一系列特征中选取最优的特征用于模型的训练。在选取特征的时候考虑两方面的因素,一是特征的方差值不能过小,否则说明样本在这个特征上区别不大;二是特征和目标的相关性越高越好。
本文采用过滤式选择来选取特征,包括以下两种方法。
1)基于方差的特征过滤方法
计算各特征方差值,过滤掉方差小于5 的特征。
2)基于卡方验证的特征过滤方法
设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值A与期望E的差距,构建统计量的计算公式为

统计量x2的值即描述了自变量与因变量之间的相关程度,其值越大,相关程度也越大,相互独立性越弱。
经过特征过滤后得到的最终特征如表1 所示。
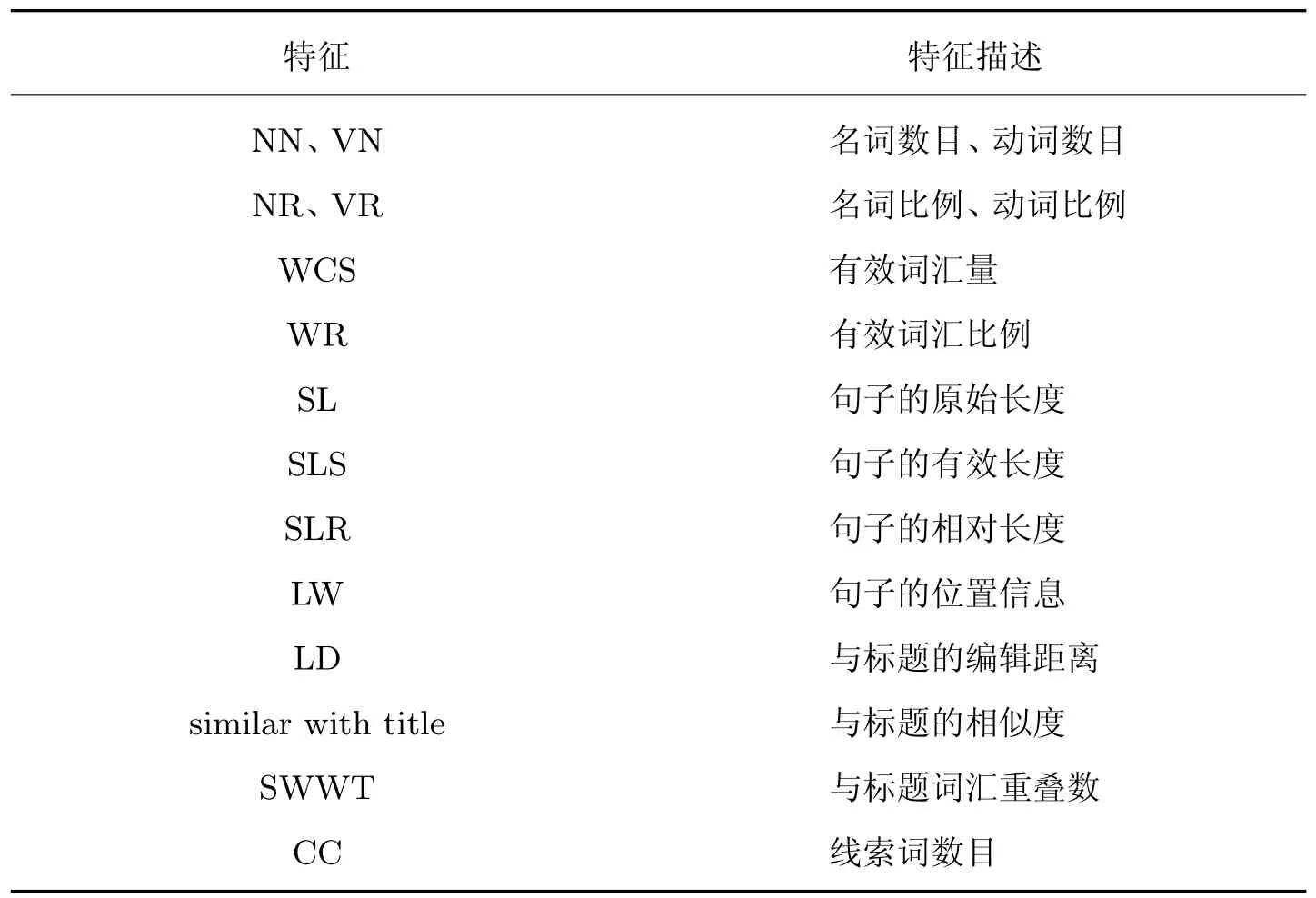
表1 输入SVM的句子特征列表Table 1 List of sentence features used in SVM
2.2 SVM-MMR 融合算法
根据特征过滤得到的16 个特征可将新闻文本中的所有句子转化为16 维向量。对特征向量使用SVM 算法训练并进行概率估计,输出句子入选摘要集中的概率,并根据概率值对新闻文本的句子进行降序排列。
在SVM 算法训练过程中,采用StandardScaler() 函数对特征进行归一化处理,采用SMOTE() 函数对样本进行过采样,使得正负样本均衡,并使用GridSearchCV() 函数对参数进行网格搜索,通过交叉验证确定最佳效果参数。
这些句子分为两类。第1 类为Ss,该类句子概率值排名很靠前,可以直接入选摘要集。第2 类为Sc,该类句子排名在摘要比例附近,有时其概率值的差异并不大,需要纳入候选集中进行二次选择。本文采用改进的MMR 算法对第2 类句子进行处理。通过SVM 模型计算得到的概率值pi仍然具有有效信息,本文将概率值pi与MMR 算法相结合,求出每个句子的得分为

式中:Sm表示摘要集,Si是摘要候选集Sc中的句子,sim(Si,T) 是指句子Si与新闻文本标题T的相似度,sim(Si,Sm) 是指句子Si与当前摘要集的相似度。
为了使新闻摘要的冗余度较低,定义MMR 得分为
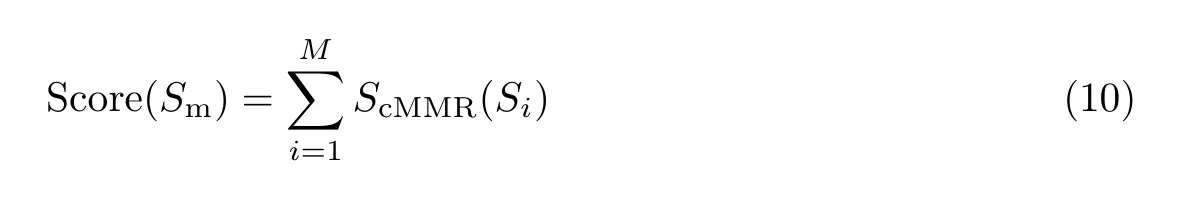
MMR 得分越高,说明最终摘要的冗余度越低、质量越高。所以根据MMR 得分来选出最优摘要句,公式为

式中:Sf为最终的摘要集;Ss为被直接选作摘要的句子;S′c为从摘要候选集Sc中进行二次选择选出的摘要句;S′c有多种组合。选出其中MMR 得分最高的组合与Ss共同构成最终的摘要。
3 实 验
3.1 语料库构建
本文采用的数据集是从“第一财经”新闻网站的汽车新闻模块[18]爬取的新闻报道,共计4 000 篇,保留了每篇报道的新闻标题。其中3 200 篇用于监督学习的模型训练,共有63 360个句子;800 篇为测试集,用于模型效果对比。
对上面得到的数据集,需要进行基本的处理,以构建语料库,主要步骤如下:
步骤1对网页标记以及一些特殊字符进行处理,删除新闻中的图集与视频,提取出数据中的文本信息并进行去重处理。
步骤2对网页标记以及一些特殊字符进行处理,删除新闻中的图集与视频,以句号、感叹号和问号为分割标志对这4 000 篇新闻报道进行分句和人工标注,从每篇报道中抽取约20% 的句子,形成最终的摘要。
经过统计,本实验数据集的基本信息如表2 所示。

表2 数据集基本信息Table 2 Basic information of data set
3.2 实验设置
对于构建的语料,需要进行一系列预处理方可输入模型中使用,主要预处理步骤如下。
步骤1中文分词
本文通过正则表达式去除文本中特殊字符、数字符号以及英文字母等,再采用jieba 精确模式对文本进行分词。
步骤2去停用词
本文使用一本比较通用的停用词词典,去除新闻文本中的停用词。
步骤3词性标注
名词以及动词往往能够表达比较关键的信息,本文使用THULAC 工具进行词性标注,以方便特征的抽取。
在实验时,如无特殊说明,那么所有模型的摘要比例均为20%,该最优摘要比例可根据对比试验得出。在MMR 模型中,将e1设为0.5,e2设为0.1,α,β,γ的值分别设定为0.2, 0.4,0.4,并且使用滚雪球的方法确定δ的取值为0.18,λ值设为0.9。在SVM-MMR 模型中,本文对SVM 的最优参数进行网格搜索,并采用5 折交叉验证的方式来减少结果的偶然性,最终使用的各项参数如表3 所示。在综合考虑MMR 和SVM 结果时,λ1取值为0.5,λ2取值为0.9。

表3 SVM参数设置Table 3 Parameters of SVM
3.3 评估标准
本文采用两方面的评价指标。一方面的评价指标为平均准确率P、平均召回率R以及由P和R得到的平均F值,其定义分别如下:
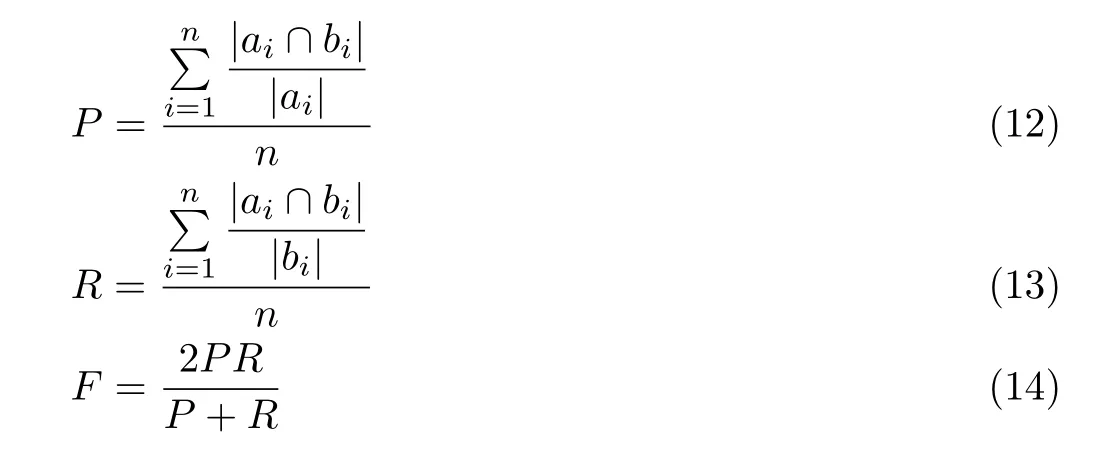
式中:n为新闻文本的总数,ai表示通过抽取式摘要算法得到的第i个新闻文本的摘要句子集,ai表示人工摘要得到的第i个新闻文本的摘要句子集。
另一方面的评价指标从新闻摘要的实际目的出发,定义了新闻标题词汇覆盖率TitleCover和文章词汇覆盖率ContentCover,公式分别如下:

式中:wsummary表示人工摘要以及通过各个抽取式摘要算法得到的摘要的词汇集,wtitle表示新闻文本标题的词汇集,wcontent表示新闻文本内容的词汇集。
3.4 对比实验
3.4.1 基线模型的对比试验
在本实验中,所用的评价指标为平均准确率P与平均召回率R。对比模型共有4 个,分别为传统的MMR 模型、文献[19] 中的TextRank 摘要模型以及2 个基于SVM 的摘要模型。
1) 传统MMR 模型:该模型对于初始权重的定义较为单一,仅仅考虑了句子相似度,且基于词汇重合度的句子相似度计算方法对于文本的语义不能充分地挖掘。
2) TextRank 模型:本文复现了文献[19] 中改进的TextRank 模型,该模型首先使用Doc2Vec 模型对文本中的句子向量化,然后利用改进的K-means 算法对文本进行聚类,将句子的位置关系以及与标题的相似度等因素融入到TextRank 算法的初始权重中进行迭代,最后将每个簇类中最终权重最大的句子组合起来形成摘要集。但是,该模型句子与句子间聚类效果并不明显,可见聚类算法对于冗余的消除效果有限。
3) SVM-1 模型:该模型的特征工程采用文献[13] 中的方法,其主要特征包括Unigram、Bigram 等基于词频的特征,还包括句子长度等结构性特征。存在的主要问题有特征多数基于统计方面的特征、缺少高级特征、在文本内容方面的挖掘不足等。
4) SVM-2 模型:该模型采用本文的特征工程,使用SVM 进行概率输出,但是放弃后续利用MMR 算法进行二次排序的流程。相比于TextRank、MMR 等无监督模型,SVM 模型选取的特征更为全面,而且机器学习模型可以对不同特征进行合理加权得到最终的结果,使得结果更为可靠。但其效果不如本文,因为本文的SVM-MMR 模型通过MMR 算法对SVM 模型的结果进行了进一步的处理,降低了摘要的冗余性,使得最终的摘要质量更高。
在该实验中关于“汽车后市场”的新闻和摘要抽取结果如表4 所示。本新闻共29 句话,使用1,2,···,29 将每一句话按照顺序进行编号,新闻完整内容参见链接https://www.yicai.com/news/100547881.html。从该抽取结果中可以看出,本文所提出的MMR 方法相比传统的MMR方法,少了与新闻文本主旨关系不大的第19, 21 句,但多出了能够较好概括文本内容的第28句,验证了本文MMR 方法所选取的权重在语义挖掘上的显著进步。另外,TextRank 方法中第20, 21 句出现了语义冗余,而本文MMR 方法抽取出的5 句摘要句中未出现该情况。
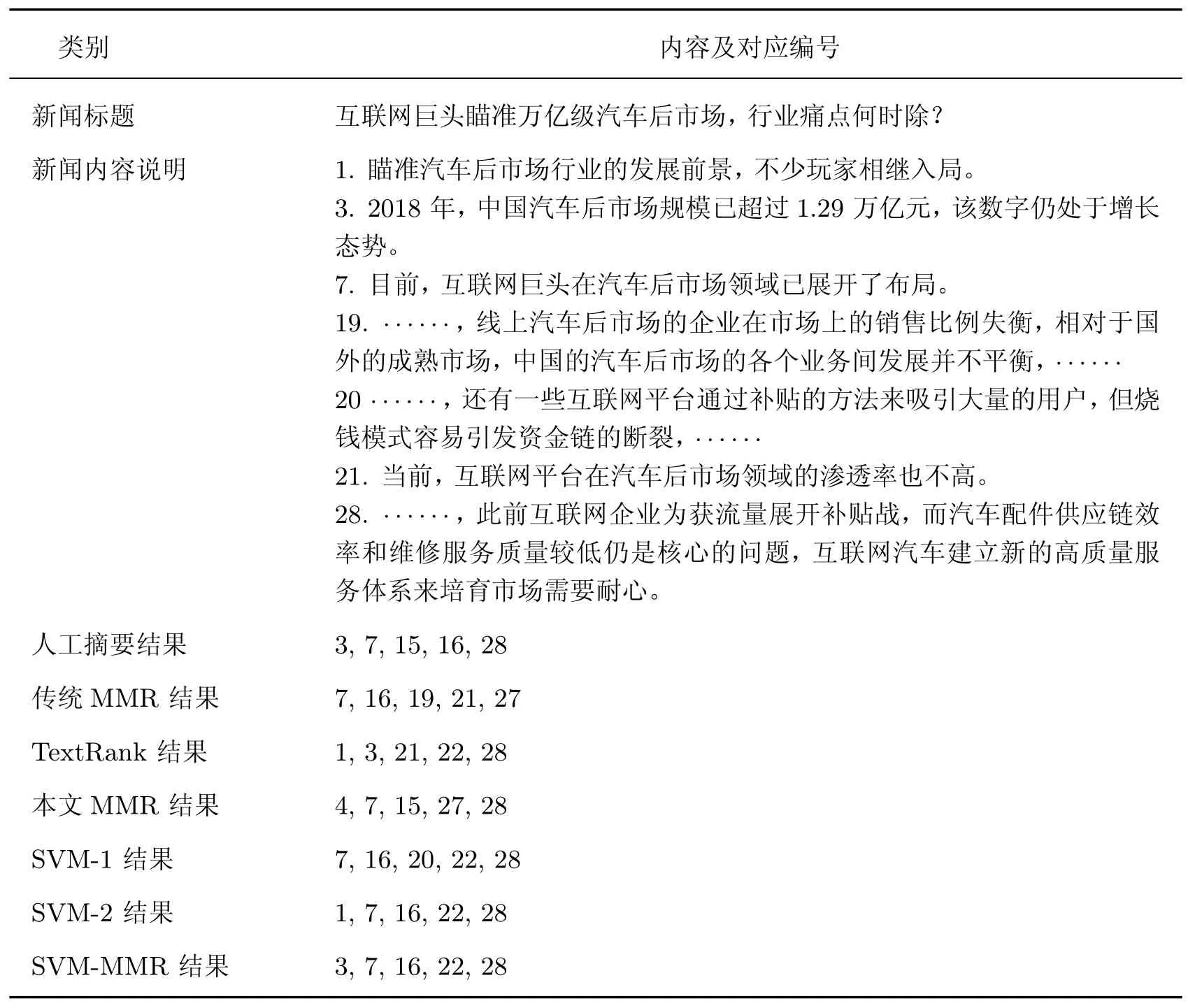
表4 新闻摘要举例Table 4 Example of news summary
此外,本文所提出的SVM-MMR 方法相比SVM-1 方法,能够多抽取出与主题密切相关的第3 句,说明SVM-MMR 方法在特征工程方面的显著成效。与SVM-2 方法相比时,SVMMMR 方法在进行二次选择时去除了SVM-2 方法中由第1 句、第7 句摘要句带来的冗余度,证明了SVM-MMR 方法具有较好的冗余处理能力。
该实验结果的统计数据如图2 所示,这些统计数据证实了上述分析。在传统MMR、TextRank 以及本文改进MMR 这3 种无监督模型中,本文改进MMR 模型效果最好,其统计值相比于传统MMR 算法有14.8% 的提升,相比于TextRank 算法也有4.6% 的提升。SVM-2的统计值相比于SVM-1 有5% 的提升,验证了本文在特征工程方面的有效性。不管是平均准确率P,还是平均召回率R,本文提出SVM-MMR 模型表现均达到最佳,相比于传统MMR模型,准确率提升了20.4%,验证了本文改进的MMR 算法对于冗余处理的有效性。

图2 基线模型对比实验结果Figure 2 Baseline model comparison results
3.4.2 摘要速度的对比实验
下文研究基于本文MMR 模型的新闻摘要方法和基于SVM-MMR 模型的新闻摘要方法进行摘要的速度差别。
首先探究两种摘要方法得到的摘要结果所占比例对摘要速度的影响。对于每一种方法分别进行5 次实验,统计每次实验耗时,最终取5 次实验耗时的平均值作为结果。每一次实验均随机选取200 个新闻文本。使用上述两种方法批量生成摘要,并以运行时间作为指标进行对比。
图3 对比了两种不同方法设定不同的摘要比例且处理相同的新闻文本时所消耗的时间。可以看出,随着设定的摘要比例数值的上升,两种摘要方法的运行时间均逐渐增加。对于MMR 算法,摘要的句子数越多,算法迭代次数越多,运行时间就越多。此外在平均耗时方面,基于MMR 模型的新闻摘要方法约为基于SVM-MMR 模型的新闻摘要方法的1/3,主要原因是MMR 模型为无监督算法,不需要对新闻文本进行特征抽取。这也说明MMR 模型更加适用于长文本的摘要任务,而且在批量处理摘要任务时的效率更具优势。SVM-MMR 模型为监督算法,首先需要抽取新闻文本的特征,将句子向量化之后再利用SVM 模型对句子进行分类,耗时较长,因此比较适用于短文本的摘要任务。

图3 摘要比例对摘要速度的影响Figure 3 Impact of abstract ratio on abstract speed
其次探究在相同的摘要比例下原文本长度对摘要速度的影响。将测试集中的新闻文本按照包含的句子数量进行分类,分别使用基于MMR 模型的新闻摘要方法和基于SVM-MMR模型的新闻摘要方法批量生成摘要,使用每篇新闻的平均摘要时间作为统计指标。
图4 展示了当摘要比例设定为20%时新闻文本长度与摘要平均耗时的变化情况。其中,本文所提MMR 摘要模型的摘要时间变化不大,对文本的长度不够敏感,而SVM-MMR 模型的摘要时间明显增大,对文本的长度较为敏感。这说明本文的MMR 摘要模型更适用于长文本或对摘要效率要求较高的场景,而SVM-MMR 模型更适用于短文本或对摘要质量要求较高的场景。

图4 文本长度对摘要速度的影响Figure 4 Effect of text length on abstract speed
3.4.3 文本覆盖率的对比试验
在本实验中,所用的文本覆盖率指标为TitleCover 和ContentCover。
实验结果如图5 所示,可以看出人工摘要的TitleCover 与ContentCover 分别为69.7%和52.4%。
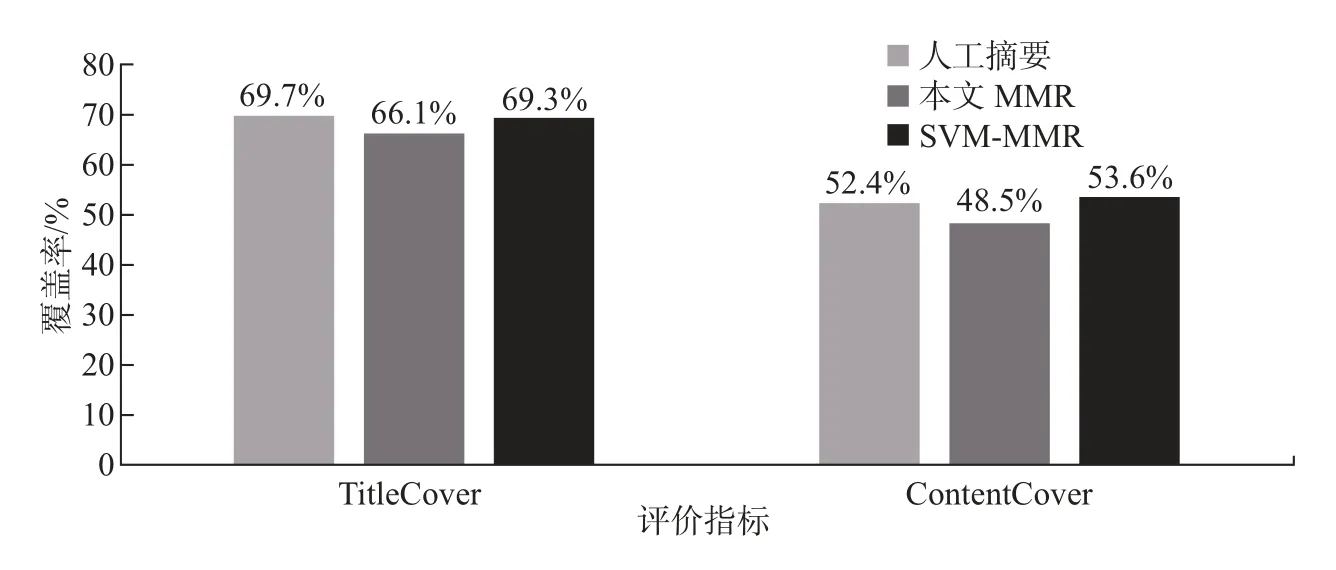
图5 摘要对新闻文本的覆盖率Figure 5 Abstract coverage of news text
通过对比可得,本文MMR 模型在两项指标上分别比人工摘要低约4% 和5%。SVMMMR 模型的TitleCover 只比人工摘要低0.4%,而ContentCover 却略高于人工摘要。这是因为在利用SVM-MMR 模型对句子进行摘要的过程中,比较偏向于选择信息更为丰富、长度更长的句子,所以ContentCover 的值也就更高。例如,同样是表4 “汽车后市场”一例中,SVM-MMR 相比人工摘要,更多地选择了语义更丰富的句子,而非仅仅长度较短的句子。本文所提出的MMR 模型和SVM-MMR 模型抽取出的摘要句能较好地帮助人们理解文本内容的含义。该实验也说明了通过MMR 模型与SVM-MMR 模型抽取出来的摘要对新闻文本的内容具有一个较好的覆盖率,而且SVM-MMR 模型的效果要优于MMR 模型的效果。
3.5 结果分析
首先,本文提出的基于MMR 和基于SVM-MMR 的摘要模型,相比传统MMR 模型来说,正确率分别提升了14.8% 和20.4%,体现了本文两种摘要方法的强大优势。
其次,由上述对比试验可以看出,基于MMR 模型的摘要效果远优于传统MMR 模型的摘要效果,而且其摘要效率约为SVM-MMR 模型的3 倍,对新闻文本的长度不太敏感。但基于MMR 的模型对影响摘要的因素考虑得不够全面,其摘要质量不及SVM-MMR 模型,因此该模型适用于对摘要效率要求较高的场景,比如面向长文本的摘要任务以及对时间有要求的批量摘要任务等。
对于基于SVM-MMR 的摘要模型来说,其优点是在判断一个句子是否属于摘要句时考虑的因素较为全面,而且不需要考虑特征的权重。此外,SVM-MMR 模型通过MMR 算法进一步对摘要进行“二次筛选”,提高了摘要质量。但是该模型在摘要过程中,首先需对新闻文本中的句子进行特征选择,这导致了该模型的摘要效率较低,耗时约为MMR 模型的3 倍,且对文本长度较为敏感,因此基于SVM-MMR 的摘要模型适用于对摘要质量要求较高的场景,比如面向短文本的摘要任务等。
如果对摘要质量或运行效率没有特殊的要求,那么在大规模批量处理新闻摘要的任务中,如果是短文本则可以调用SVM-MMR 模型进行摘要,如果是长文本则可以调用MMR 模型进行摘要。综合使用两个模型,可以在摘要质量与运行效率之间取得一个平衡。
4 结 语
本文根据新闻文本的特点,提出了两种新闻摘要方法,分别为基于MMR 的摘要模型以及基于SVM-MMR 的摘要模型。前者结合数据集的特点,将标题相似度、句子位置、关键词以及线索词信息融入到句子的初始权重之中,然后通过MMR 迭代完成新闻摘要任务。后者选取词语、结构、语义3 个方面的特征,将新闻文本中的句子映射到向量空间,通过SVM 对句子进行概率预测,并利用MMR 算法去除摘要集中的冗余。
然而,本文所提出的摘要方法存在对特征选取依赖较大的问题,在基于SVM-MMR 模型的摘要方法中,模型效果的好坏十分依赖于特征的选取。神经网络可以自动学习数据的特征,若将抽取式摘要视为序列标注任务,循环神经网络则能很好地解决这一任务,因此利用循环神经网络进行抽取式摘要是未来的一个研究方向。
(编辑:管玉娟)
