
基于FSCD-CNN的深度图像快速帧内预测模式选择算法
2022-01-19 12:43:08崔鹏涛刘敬怀
应用科学学报 2021年3期
崔鹏涛, 张 倩, 刘敬怀, 周 超, 王 斌, 司 文
1.上海师范大学信息与机电工程学院,上海200234
2.上海商学院商务信息学院,上海201400
近年来,随着多媒体技术的不断发展,3D 视频逐渐受到了人们的青睐。3D 视频在给观众带来极佳的视觉盛宴的同时也带来数据量过大、存储要求高、传输难度大等问题。为了更好地满足大众的需求,立体视频编码联合工作组在HEVC 的基础上提出了新一代高效立体视频编码标准,即3D-HEVC[1]。3D-HEVC 采用了多视点视频加深度图的编码格式,可以同时对多个视点的纹理图以及相应的深度图进行编码,从而提高了3D 视频的编码性能。在帧内编码中,3D-HEVC 不仅保留了原有HEVC 的四叉树的编码结构和35 种帧内预测模式,而且针对深度图的帧内预测增加了深度建模模式(depth modeling mode, DMM),从而更有效地提高了编码性能。但由于3D-HEVC 使用的四叉树结构即要对所有编码单元(coding uint, CU)进行递归计算,又要计算多个预测模式的最小率失真代价以确定最优的编码模式及CU 深度,因此大大提升了编码的复杂度。
为了提高深度图编码效率,减少DMM 模式的编码时间,文献[2] 利用梯度滤波器探索深度图特征,检测DMM 最佳位置,从而提出了一种基于梯度的空间探索算法。文献[3] 通过角点特征来判别深度图的边缘信息,以此对CU 进行划分,无需探索DMM 编码模式的过程。文献[4] 提出了一种基于平滑度的DMM 模式快速决策算法,根据当前块的平滑度来判断是否提前终止DMM 模式的探索,避免对DMM 模式进行不必要的评估。文献[5] 提出了一种基于灰度共生矩阵(gray-level co-occurrence matrix, GLCM)的优化编码算法,使用GLCM 检测同类区域,将编码单元划分为不同类型,从而跳过一些模式的探索,减少DMM 模式的编码时间。文献[6] 基于纹理特征和空间特征,提出一种基于K-Means 的DMM 模式快速决策算法,从而降低DMM 模式的复杂度。文献[7] 提出了一种基于角点特征的DMM 模式快速算法,根据特征角点来评估边缘的朝向,从而加快DMM 模式的探索。文献[8] 提出了一种基于方差的快速模式选择算法,根据方差来评估DMM 模式的代价值,降低计算复杂度。文献[9]通过计算PU 的梯度值,提出了基于梯度信息的帧内模式快速算法,利用PU 的梯度信息,省去部分帧内DMM 模式的探索,降低计算复杂度。这些方法虽然降低了编码时间,但是却增加了3D-HEVC 编码和解码的复杂性。
由于3D-HEVC 采用了四叉树形式的CU 划分结构,在编码过程中耗费了大量的时间。文献[10] 通过为不同大小的CU 设置相应的恰可察觉失真(just noticeable difference, JND)值来判断CU 是否需要进一步划分为更小的CU,从而降低CU 划分过程中的计算复杂度。文献[11] 把CU 分为前景、不均匀背景以及均匀背景,对于均匀的背景可以提前终止CU 划分。同时,随着机器学习和人工智能技术的不断发展,很多机器学习的方法都将用在视频编码中,文献[12] 使用大数据聚类,提取用于3D-HEVC 编码中纹理图CU 深度的决策模型,对CU递归划分进行预测。文献[13] 使用数据挖掘,建立决策树,来判定当前深度图CU 是否需要再划分。文献[14] 使用机器学习方法,根据HEVC 纹理图CU 的复杂度,构建了基于SVM 的复杂度分类模型,来确定CU 的最优深度,从而跳过部分CU 的计算。但是传统的机器学习方法还存在弊端,需要手工选取和提取特征来选择性能最佳的特征进行学习,这大大提高了复杂度。同时这些方法的可移植性较差,只适用于特定的系统或者模型环境。而近年来,深度学习的出现和快速发展克服了这些弊端。
深度学习是自端到端的学习过程,它具有很强大的分类处理能力,同时适应性强。在HEVC 编码中,文献[15] 将深度学习用于HEVC 纹理图CU 的划分中,引入了卷积神经网络(convolutional neural network, CNN)和长短期记忆网络(long short-term memory,LSTM)来预测纹理图CU 的划分,从而跳过了部分计算,降低了HEVC 编码复杂度。文献[16] 在HEVC 的CU 划分中加入了CNN 网络以确定纹理图CU 的最优候选模式,减少了LCU 中CU 候选模式的最大数目,降低了计算复杂度。文献[17] 在HEVC 编码中引入了CNN 网络,将LCU 分为简单CU 和复杂CU,然后预测纹理图LCU 的最佳划分范围,跳过了不必要的CU 计算,降低了计算复杂度。文献[18] 也在HEVC 的编码中,采用一种多输入的CNN 网络架构来预测纹理图CU 的划分。文献[19] 通过残差、宏块划分和位分配等特性,提出了一种使用LSTM 来预测CU 划分的方法,降低了编码复杂度。以上文献说明深度学习在视频纹理图编码上有着巨大潜力。
这些现有的深度学习技术主要集中在如何提高纹理图编码性能,以使视频的编码效率得到最大限度的提高,而没有充分考虑3D 视频序列深度图的特点和编码复杂度,于是本文在深度图LCU 的快速划分算法中引入了拥有强大特征提取能力的卷积神经网络,构建相应的Cu 深度快速选择卷积神经网络(fast selecting Cu’s depth-convolutional neural network,FSCD-CNN),从而降低了帧内编码的复杂度并减少了编码时间。
1 基于FSCD-CNN 的深度图像快速帧内预测模式选择算法
1.1 算法设计思想
在3D-HEVC 中,深度图和纹理图的主要编码过程基本一致,但在纹理图编码框架的基础上加入了一些新的编码模式来提高性能。本文从视频序列“Newspaper”中取出的纹理图和深度图如图1 所示,可以看到:相比于纹理图,深度图有大量的平缓区域以及少量的不均匀区域,且深度图中LCU 最优划分深度大多为0。

图1 “Newspaper”视点2 深度图Figure 1 Depth map of “Newspaper” viewpoint 2
经“Newspaper”等视频序列的深度图测试分析发现,平均94.53% 的LCU 是以64×64或32×32 的尺寸进行编码的,只有5.45% 的LCU 以16×16 或8×8 的尺寸进行编码,如表1 所示。
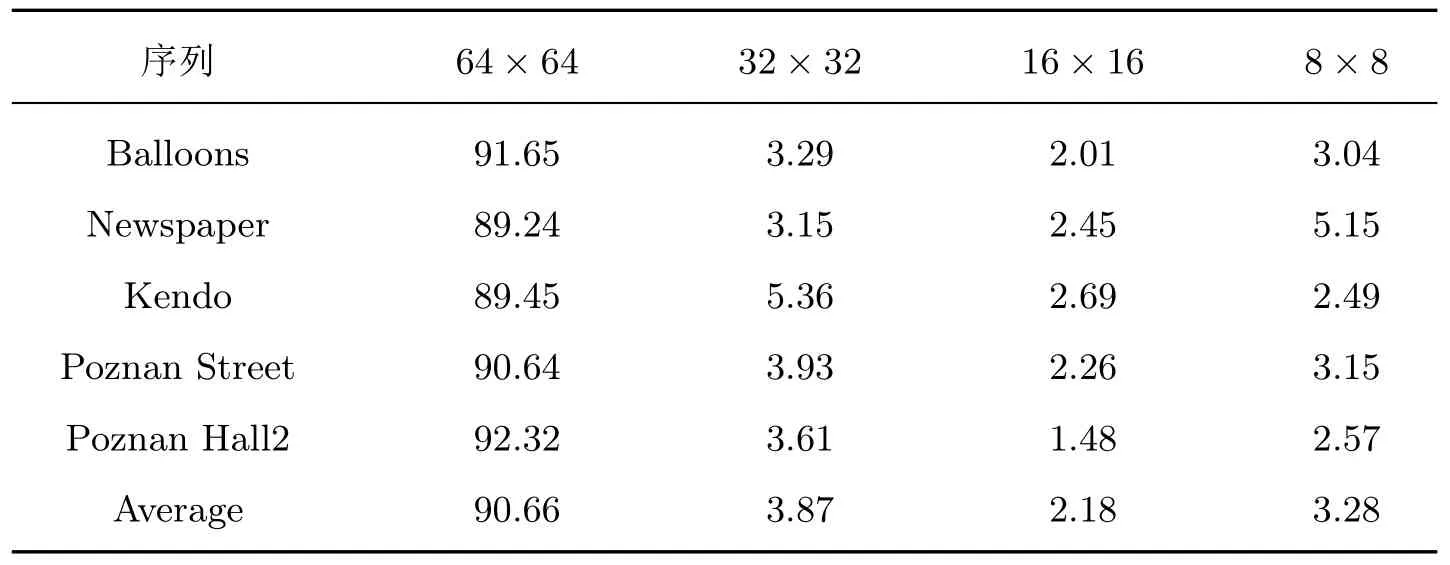
表1 各视频序列的LCU 尺寸划分占比Table 1 LCU size partition proportion of different video sequence %
因此,当CU 达到最优深度的时候,如果通过算法检测并终止CU 的继续划分,则可以提高编码性能。卷积神经网络在预测、分类等方面有着非常优良的性能,它克服了传统机器学习中人工提取特征的弊端,实现了端对端的学习。将卷积神经网络与编码器相结合,应用于HEVC 的纹理图编码以及3D-HEVC 的运动估计,以达到提升编码效率的目的。基于上述思想,本文将卷积神经网络应用于3D-HEVC 的深度图LCU 递归划分中,搭建了适用于深度图划分的FSCD-CNN 框架,借助于卷积神经网络优秀的特征提取性能,将3D-HEVC 编码与深度学习相结合,提出了一种基于FSCD-CNN 的深度图像快速帧内预测模式选择算法,对深度图LCU 的最优划分深度进行预测,得到最优深度值depth_pre,从而提前终止CU 划分,跳过了预测范围外的RD-cost 计算。实验结果表明:本文所提方法在减少编码复杂度的同时,编码质量几乎保持不变。
1.2 FSCD-CNN 模型搭建与训练
1.2.1 训练数据的获取
本文训练数据来自3D-HEVC 标准视频序列(包括“Balloons”“Kendo”“Poznan Street”),算法不需要进行人工提取特征,而是直接构建具有代表性和概括性的训练数据集就可以获得优良的分类预测模型。将每个深度序列前6 帧的LCU 作为深度图LCU 的训练集,由于编码采用的是双视点合成,取出的LCU 约10 728 个,如表2 所示。
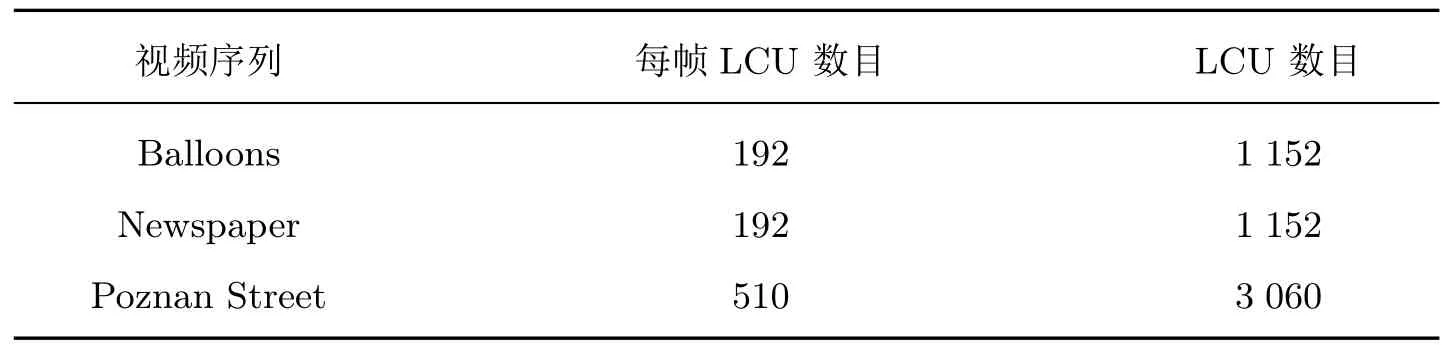
表2 训练样本Table 2 Training samples 个
对于取出的LCU 数据集,根据其编码后的最优深度结果贴上标签D,D的取值为{D1,D2,D3,D4},分别对应4 层CU 划分深度。
1.2.2 FSCD-CNN 模型
本文搭建的适合深度图LCU 分类的深度框架如图2 所示,模型通过对深度图LCU 的分类进行学习,加快了视频编码的速度。
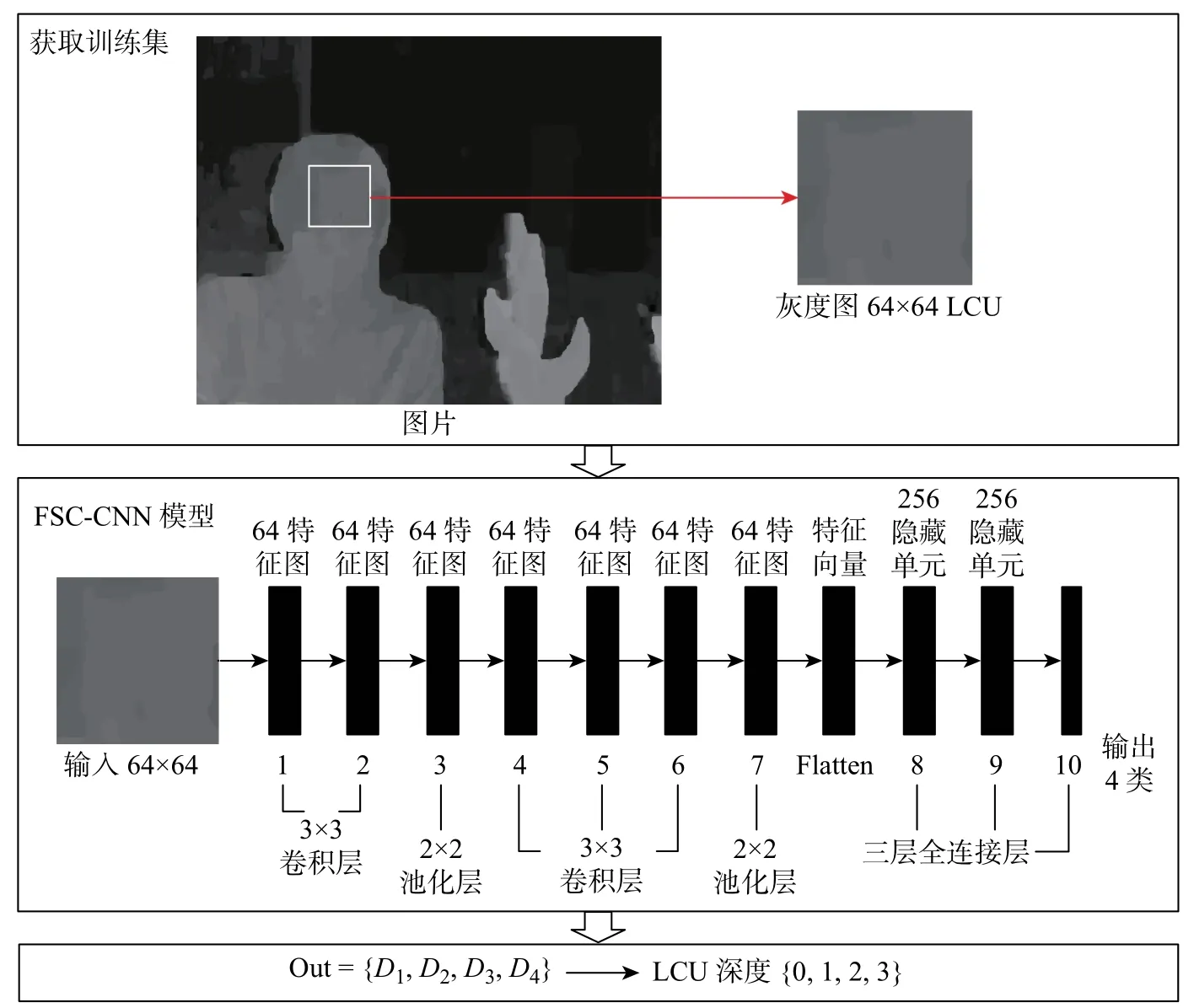
图2 FSCD-CNN 模型Figure 2 FSCD-CNN model
整个深度学习框架是由10 层组成,其中包括5 个卷积层、2 个池化层以及3 个全连接层。FSCD-CNN 的第1 层具有64 个特征图的卷积层,输入是从视频序列获得的大量64×64像素的图像及与之相应的深度标签。第1 层的卷积核大小是3×3,其特征图的尺寸是62×62。然后进行批规范化(batch normalization, BN)以更好地提高训练速度,同时防止过拟合,使模型性能更加优良。对比训练集上的实验发现,在第1 层卷积层后面使用BN 能得到更好的模型精度,获得了更好的分类结果。第2 层卷积层具有64 个60×60 的特征图,其卷积核大小也是3×3。第3 层是2×2 的池化层,具有64 个30×30 的特征图。然后是卷积核为3×3的连续3 层卷积层,它们分别具有64 个28×28 的特征图、64 个26×26 的特征图以及64 个24×24 的特征图。连续的3 层卷积层获得了更大的感受野,可以更好地总结卷积层信息,让决策函数性能得以提升。第7 层是2×2 的池化层,具有64 个12×12 的特征图。第8 层和第9 层都是具有256 个神经元的全连接层,同时为了防止过拟合,将随机丢弃50% 的特征。第10 层是具有4 个单元的层,它是整个模型的输出层,用以输出分类结果。输出层使用softmax激活函数,对输入的数据进行分类判定,给出每个深度图的最优预测分类结果。
模型采用的损失函数是交叉熵损失函数,公式为
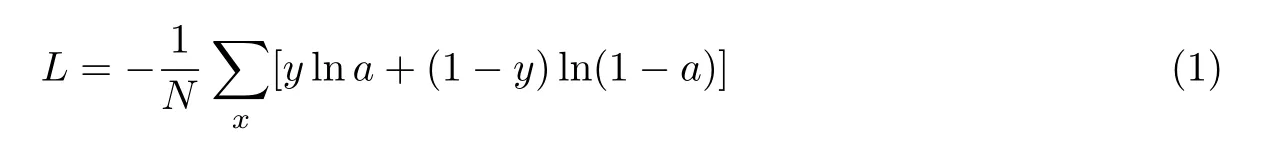
式中:a为实际输出,y为期望输出,L为损失值,N为数据总数,x为训练输入。
3D-HEVC 使用了四叉树结构对CU 进行递归计算,并且对多个预测模式计算最小率失真代价,由此带来了大量复杂度。本文提出基于FSCD-CNN 的深度图像快速帧内预测模式选择算法,预测CU 划分深度,提前终止CU 递归划分。本文所提出的深度决策算法流程图如
1.3 基于FSCD-CNN 的深度图像快速帧内预测模式选择算法
图3 所示。该算法主要分为以下3 个模块:首先是读取模块,从视频序列中获取深度图LCU,并将其传给CNN 网络,用于识别预测;其次是预测模块,使用已训练的CNN 网络对输入的深度图LCU 进行预测,将其分为4 类,分别是深度D1、D2、D3、D4,同时把初步的分类预测结果输入到模式决策模块;最后由模式决策模块对这个数据进行判定再处理,进而得到CU的最佳决策深度,如果当前深度图LCU 预测的深度是0,则遍历35 种帧内模式,将最大可能模式(most possible modes, MPM)加入到候选模式,同时跳过DMM 模式,停止CU 递归划分,确定最佳预测模式与CU 深度。如果预测的深度不为0,则继续帧内模式遍历、DMM 探索以及CU 的递归划分,直到当前CU 深度等于预测CU 深度为止。实验结果表明,本文提出的算法相对于3D-HEVC 的测试序列,其LCU 深度预测平均节省了42.58% 的时间,对编码性能影响很少,可以实现编码效率的大幅提升。
2 算法实现
在3D-HEVC 帧内预测中,有37 种预测模式,分别是PLANAR 模式、DC 模式、33 种角度模式以及2 种DMM 模式,如表3 所示。

表3 帧内预测模式Table 3 Intra-frame prediction modes
DMM 模式是3D-HEVC 在HEVC 基础上设计的。加入DMM 模式是为了更准确地描绘深度图CU 的边缘情况。对于这些FSCD-CNN 预测最优深度为0 的深度图LCU,直接跳过DMM 搜索,节省了编码时间。对于那些预测深度小于3 的LCU,提前终止该CU 的划分。
基于FSCD-CNN 的深度图像快速帧内预测模式选择算法的流程如图3 所示。
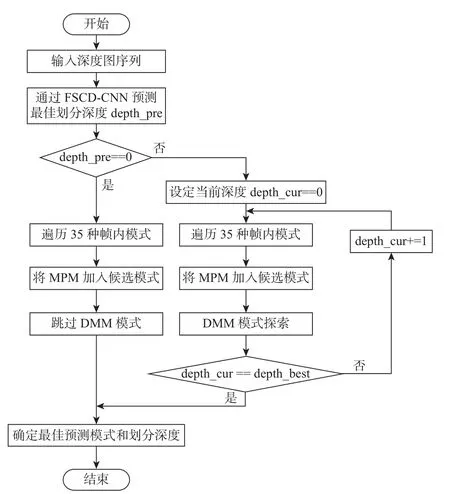
图3 基于FSCD-CNN 的深度图像快速帧内预测模式选择算法Figure 3 Fast intra prediction mode selection algorithm for depth images based on FSCD-CNN
具体的算法步骤如下:
步骤1输入深度图序列;
步骤2使用FSCD-CNN 模型对输入的深度图LCU 进行最佳深度预测;
步骤3如果模型预测的最优分类结果是深度0,那么就遍历35 种帧内模式,同时把MPM 放进候选列表,跳过DMM 模式搜索,然后进入步骤5,否则进入步骤4;
步骤4遍历35 种帧内模式,同时把MPM 放进候选列表以进行DMM 模式搜索;
步骤5决定LCU 最佳划分深度,从候选列表选择最佳模式;
步骤6对下一个LCU 进行判定,直至全部判定完。
3 实验结果和分析
为了评估所提算法的性能,对该算法和3D-HEVC 的视频编码平台HTM-13.0 进行了对比实验。测试序列是官方的5 个视频序列,分别是“Balloon”“Kendo”“Newspaper”“Poznan Hall2”“Poznan street”。这些视频采用的是双视点编码,视频序列信息如表4 所示。本文的4 组量化参数分别设置为(25,34)、(30,39)、(35,42)、(40,45),相应的实验配置如表5 所示。实验所采用的硬件设备为2.8GHZ 的CPU,16G 的内存以及GTX1060 显卡。

表4 序列信息Table 4 Sequence information

表5 编码配置Table 5 Encoding configuration
使用相同峰值信噪比下的码率差异(Bjontegaard delta bitrate, BDBR)和相同码率下的峰值信噪比差异(Bjontegaard delta peak signal-to-noise rate, BDPSNR)来评估视频编码性能,则节省的时间比率为

式中:T0为HTM13 原始编码运行时间,T1为所提出算法运行时间。
对合成视点的BDBR、BDPSNR 和节省的时间T进行评估的实验结果如表6 所示,可以看出,所提算法与原编码器相比平均节省了42.6% 的编码时间,同时性能损失可以忽略不计。
如图4 所示,“Newspaper”和“Kendo”视频序列在HTM13 原始编码平台下以及所提出的算法下的RD 曲线几乎一致,因此编码性能的损失几乎可以忽略不计,而本文所提出的算法分别减少了41.6% 和47.6% 的时间复杂度。为了进一步对所提算法进行评估,将本算法与文献[20] 及文献[21] 的算法进行比较。文献[20-21] 都针对深度图CU 四叉树划分中复杂度过高问题给出了优化方法和解决方案,文献[20] 是对LCU 的最优划分深度进行预测,文献[21]是对当前CU 是否划分进行判定,旨在CU 划分部分进行优化以降低编码复杂度。
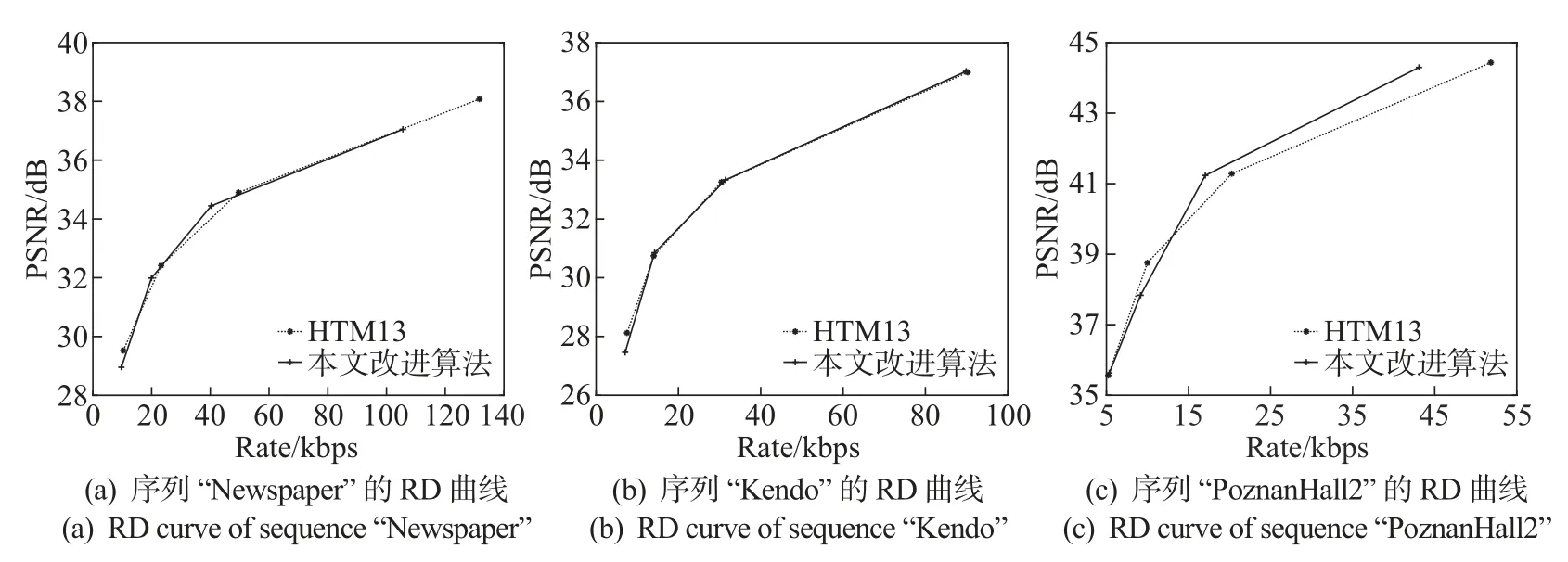
图4 视频序列RD 曲线Figure 4 RD curves of video sequence
由表6 可以发现,文献[20] 在序列“Newspaper”以及序列“Kendo”上分别节省23.5%和23.1% 的编码时间,所有序列平均节省了25.2% 编码时间;文献[21] 所提算法在序列“Newspaper”和“Kendo”上分别节省了21.1% 和22.7% 的编码时间。而本文算法在上述序列上分别节省了41.6% 和47.6% 的编码时间,所有序列平均节省了42.6% 的编码时间。

表6 实验结果对比Table 6 Comparison of experimental results
实验结果表明,相比于文献[20-21] 所提的算法,本文算法进一步节省了近15% 的编码时间,而编码性能却几乎一致。由此可见,本文提出的基于FSCD-CNN 的深度图像快速帧内预测模式选择算法可以有效提高3D-HEVC 深度图编码性能。
4 结 语
本文提出了一种基于FSCD-CNN 的深度图像快速帧内预测模式选择算法,用以减少3D-HEVC 的帧内编码时间。深入研究了深度图的平滑程度与CU 深度划分之间的关系,探讨了基于深度学习的CU 提前终止划分的问题,进而提出了FSCD-CNN 框架,并借助CNN出色的特征提取及分类能力对LCU 的最优划分深度进行预测。实验结果表明,相比于原始HTM13.0 编码平台,本文算法几乎没有性能的损失,且能减少42.6% 的编码时间。与文献[20-21] 中的算法相比,本文算法节省时间更多。在未来的研究中将进一步优化和提升网络结构。
(编辑:管玉娟)
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
计算机应用(2019年3期)2019-07-31 12:14:01
电子制作(2019年11期)2019-07-04 00:34:38
中国惯性技术学报(2019年6期)2019-03-04 09:50:10
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中央民族大学学报(自然科学版)(2017年2期)2017-06-11 07:14:54
软件导刊(2016年9期)2016-11-07 22:22:57
科技视界(2016年2期)2016-03-30 11:17:03
火控雷达技术(2016年3期)2016-02-06 02:30:28
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01 02:54:43
