
基于强化学习的多模态场景人体危险行为识别方法
2022-01-19 09:10张晓龙王庆伟李尚滨
应用科学学报 2021年4期
张晓龙,王庆伟,李尚滨
1.东北林业大学体育部,黑龙江哈尔滨150040
2.哈尔滨华德学院体育教研部,黑龙江哈尔滨150025
3.哈尔滨工程大学体育部,黑龙江哈尔滨150001
社会公共安全突发事件的增加,成为当前关注的热点话题[1]。为了提高反恐行动、甄别危险信息等工作的效率,研究对人体危险行为进行精准而快速的识别方法是十分紧迫的。人体行为识别属于计算机视觉领域里比较热门的研究方向,伴随着数码相机与视频摄像头应用成本的不断降低,以及智能手机的大量使用,拍摄并获得视频图像数据已不存在难度[2]。
研究视频与图像内容属于计算机视觉领域与多媒体领域的核心问题。在视频与图像里,人体行为属于高精度研究视频图像内容的核心[3]。因此,识别视频与图像里的人体行为属于计算机视觉问题中十分有价值的课题,它的分析结果可以应用于智能视频监控、人机交互等领域。已有的相关研究成果如下:文献[4]提出了SPLDA降维和XGBoost分类器的行为识别方法,利用SPLDA算法在原有样本协方差矩阵不变的情况下获取最重要的主分量,将降维后的样本数据集通过XGBoost分类器进行最终的行为识别。文献[5]提出基于视频分段的空时双通道卷积神经网络的行为识别,先将视频分成多个等长不重叠的分段,再将这两种图像分别输入空域和时域卷积神经网络进行特征提取,最后集成双通道的预测特征得到视频行为识别结果。文献[6]提出基于复合特征及深度学习的人群行为识别方法,通过前景提取方法来提取人群静态信息,利用人群运动的变化获取人群动态信息,借助卷积神经网络(convolutional neural network,CNN)模型学习这两种不同的人群行为特征。深度学习技术的不断优化推动了强化学习的发展[7],因此本文提出一种基于强化学习的多模态场景人体危险行为识别方法,实现多模态场景人体危险行为的高精度识别。
1 基于强化学习的多模态场景人体危险行为识别方法
1.1 多模态场景人体危险行为提取
基于强化学习的特征提取算法将Q-Learning学习用于多模态场景人体行为特征提取时,设置的多模态场景人体行为特征子集属于空集,行为列表里包含加入与去除两种模式,依次描述加入一种人体行为特征与去除一种人体行为特征[8]。融合Wrapper特征提取方法,将高斯贝叶斯分类器目前状况(特征子集)的分类精度设成即时收益[9],此时可完成多模态场景下人体危险行为的特征提取。详细方法流程如图1所示。
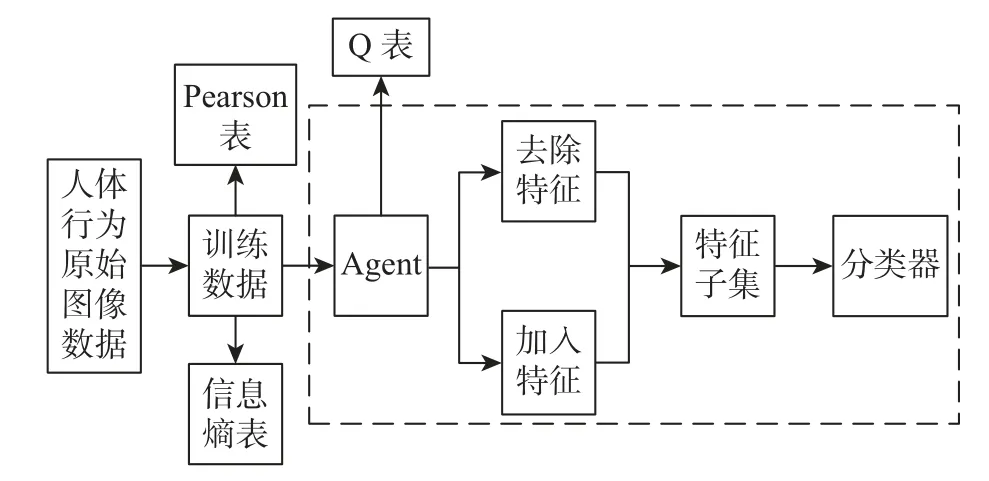
图1 多模态场景人体危险行为的特征提取Figure 1 Feature extraction of human dangerous behavior in multimodal scenes
基于强化学习的提取多模态场景人体危险行的步骤如下:
步骤1将多模态场景人体行为图像数据进行归一化与离散化预处理,获取训练数据[6]。
步骤2计算各个人体行为特征的信息熵与信息熵均值,把人体行为特征信息熵大于信息熵均值的特征标记在信息熵表中[10-11]。
步骤3生成各个人体行为特征Pearson相关系数和Pearson相关系数的均值[12],把大于Pearson相关系数均值的人体行为特征标记在Pearson表里。
步骤4把人体行为特征训练数据与Pearson表、信息熵表导入Agent,再由Agent按照加入与去除特征的人体行为所存在的差异收益进行判断[13]。
步骤5Agent训练学习停止后可以获取Q表,分析Q表后根据R环形成序列(R-loops forming sequences,RLFS)算法提取人体行为特征子集[14]。
按照步骤1~5设计RLFS算法流程,设定多模态场景人体危险行为数据集

式中:Y表示人体危险行为数据集函数;(Yji)M×E表示M个多模态场景人体行为和E个样本特征,那么多模态场景人体行为样本的种类参量为

式中:D表示多模态场景人体行为样本数量,dj表示多模态场景下每个感官j的危险样本。设多模态场景人体行为样本数据集为(D1,D2,···,DM)T,那么多模态场景人体危险行为特征集可用(g1,g2,···,gE)表示,其中g∈M。
将现有多模态场景人体危险行为特征集输入强化学习算法,直到输出最佳人体危险行为特征子集结束为止,具体步骤如下:
步骤1初始化人体危险行为特征子集H=∅,将备选特征集合T设为

步骤2计算各个特征的信息熵和信息熵均值,把大于信息熵均值的人体行为特征标进记在Pearson表里。
步骤3计算各个特征间Pearson相关系数和Pearson相关系数的及其均值[15],把大于均值的人体行为特征标进记在Pearson表里。
步骤4若H=∅,任意加入一个人体行为特征W,W∈T。
步骤5在T中任意选取一个人体行为特征W,计算特征子集分类精度并设成SW。获取目前人体危险行为特征子集H中特征间相关系数最大的特征,任意选取特征库中的特征V,计算人体行为特征子集H/{V}的分类精度并设成SV,将SW与SV中值最大的人体危险行为设成决策,那么
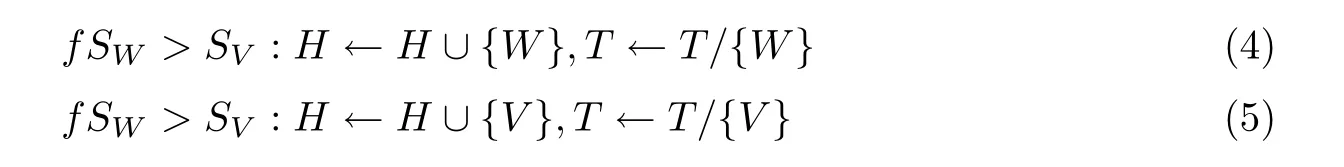
式中:f为行为变换系数。基于上述危险行为决策结果,计算Q值,刷新Q表。
步骤6分辨是否符合结束条件,如果符合便结束,在Q表中输出Q值的最高值所对应的人体危险行为特征子集;如果不符合那么跳转至步骤4。经过以上6个步骤就可以提取到多模态场景人体危险行为特征。
1.2 搭建人体危险行为模糊识别模型
围绕1.1节获取的多模态场景危险行为特征,用模糊模式识别方法以最高隶属准则先提取人体危险行为特征,再构建人体危险行为识别模型[16]。
本文以图像中人体危险行为作为识别对象,在识别危险行为前需要提取人体外形轮廓。将图像中水平方向设为X轴,垂直方向设为Y轴,则人体外形轮廓坐标如图2所示。

图2 人体外形轮廓坐标Figure 2 Coordinate of human body contour
将人体的中心点坐标设为(xb,yb),则外形轮廓上的某个点(xo,yo)的坐标位置可以根据该点到中心点的距离进行计算[17],从而确定人体的基本轮廓,便于判断人体姿态。具体计算公式为

式中:K(o)为人体形态变量。轮廓线上点(xo,yo)的曲率计算函数为

式中:ω(o)为轮廓的切向角度

根据轮廓线上点的切线角度,设定人体危险行为论域O中的模糊子集为B1、B2、B3、B4,建立一种多感官的危险行为模型库。
设定多模态场景人体危险行为模型Bj相应的第i个感官行为特征是Bji。设定各类感官危险行为数据,计算对应的行为特征。为了获取Bji的分布属性,删除冗余特征,具体的计算公式为
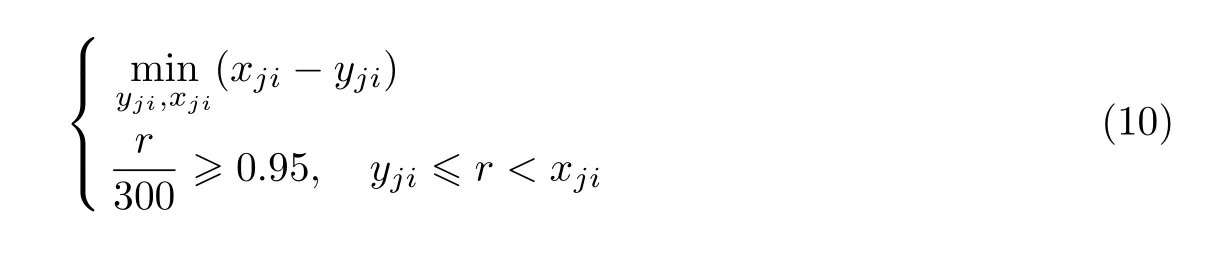
式中:r表示Bji的样本数目,xji、yji表示人体行为特征分布范围。按照Bji的分布属性,设定B1、B2、B3、B4的隶属度函数属于钟形函数[18-20]。针对各个感官标准危险行为模型,必须设定各个感官行为特征的权值ϖji,同时符合ϖji≥0且的条件。
以方差变量统一危险行为、差异行为的特征量并实施归一化处理,获取高精度差异行为[21-23]。可靠表达固定危险行为的行为特征,同时按照不同感官作用程度设置权值。
把多模态场景人体危险行为特征集合G={B1,B2,B2,B4}设成需要识别的目标,依次计算识别目标G,对比标准危险行为模型Bj的隶属度,于是有

选取Bj(G)中的最高值

因为模糊子集B1、B2、B3、B4仅属于论域O里的子集,所以为了增强识别结果的精度,按照实际人体危险行为感官值与多模态场景参考值进行检验,设置隶属度阈值θ。如果Bj(G)大于阈值θ,那么多模态场景中人体存在第j类感官形式危险行为;如果Bj(G)小于阈值θ,那么多模态场景中人体不存在危险行为[15]。
1.3 本文识别方法
本文利用强化学习算法提取多模态场景下人体危险行为,搭建行为模糊识别模型,实现人体危险行为的识别步骤如下:
步骤1设定多模态场景中人体危险行为数据集,并确定样本数据的行为种类参量。
步骤2初始化行为特征子集,在集合中抽取人体行为特征。
步骤3计算特征子集的分类精度,设置最大危险行为决策,形成强化学习Q-Learning算法,提取行为特征。
步骤4设定图像中危险行为人的轮廓目标,计算轮廓切向角度,建立多感官行为模型库。
步骤5设定感官行为特征权值,以方差变量统一危险行为、差异行为的特征。
步骤6将特征集合G设成需要识别的目标,对比标准危险行为模型的隶属度,确定人体危险行为。
基于强化学习的多模态场景人体危险行为识别具体流程如图3所示。
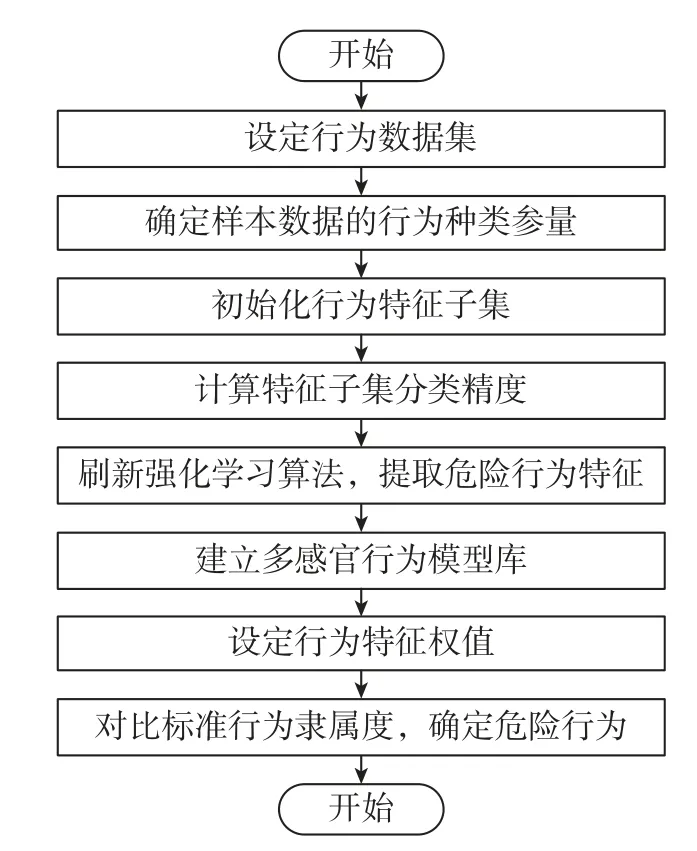
图3 基于强化学习的多模态场景人体危险行为识别Figure 3 Human dangerous behavior recognition in multimodal scenes based on reinforcement learning
2 实验分析与结果
2.1 实验环境和数据集
本实验使用UCF Dataset人体行为识别数据集,其中包括握手、指向、拥抱、推、踢和拳打等人体行为,共计320段视频、101个类别。排除40组异常样本数据后,从数据集中选取80组数据作为训练样本,数据大小为2 GB;将剩余的200组数据作为测试样本,数据大小为4.2 GB。
实验主机参数为Windows 8(64位)Vagrant 1.8.5,Intel®CoreTMi7 CPU M460@3.20 GHz处理器,8 GB内存,512 GB硬盘,在MATLAB R2017b搭建的环境下进行仿真实验。将本文研究的基于强化学习的多模态场景人体危险行为识别方法作为实验组,将基于SPLDA降维和XGBoost分类器的行为识别方法[4]、基于视频分段的空时双通道卷积神经网络的行为识别方法[5]、基于复合特征及深度学习的人群行为识别算法[6]作为对照组,对比4种方法识别人体危险行为的有效性。
2.2 实验指标
选择危险行为判定依据、危险行为识别准确率、危险行为识别延迟时间作为实验指标。
2.2.1 危险行为判定依据
抽取数据集中两个不同场景的握手动作和推搡动作的4幅图像,分别用4种方法进行识别判断。以不受环境影响且能准确判断区分两个动作作为准确判定的依据。
2.2.2 危险行为识别准确率
在200组测试样本数据中,共有危险行为数据96组,安全行为数据104组。识别准确率越高,说明识别效果越好。危险行为识别准确率P的计算公式为

式中:W为识别到的危险行为数量,Q为识别样本总数。
2.2.3 危险行为识别延迟时间
利用本文方法、文献[4-6]方法分别识别60组数据,在MATLAB平台计算每种方法的识别延迟时间。识别延迟时间越短,说明识别效率越高。
2.3 实验结果
根据3个实验指标来验证本文方法。
2.3.1 危险行为判定依据比较
在上述实验环境下,对不同场景下安全行为握手与危险行为推搡进行识别判断,实验结果如图4所示。

图4 不同方法的危险行为判定结果Figure 4 Dangerous behavior judgment results by different methods
由图4中的识别结果可知:文献[4]方法将场景2中的推搡行为错误地识别为握手;文献[5]方法将场景1中的推搡行为错误地识别为拥抱;文献[6]方法将场景1中的握手错误地识别为推搡,将场景2最后的握手推搡错误地识别为拥抱;本文方法则不受场景变换的影响,正确地识别了4个动作。
2.3.2 危险行为识别准确率比较
为进一步验证本文方法对危险行为识别的有效性,对比对照组方法的识别准确率,实验结果如图5所示。
由图5中不同方法的危险行为识别准确率可知:在识别过程中,本文方法的识别准确率在70%以上,最高识别率可达97%;而对照组3种方法的最高识别率则不超过80%。因为本文引用了强化学习方法,所以提高了危险行为的准确率。

图5 不同方法的危险行为识别准确率Figure 5 Recognition accuracy for dangerous behaviors by different methods
2.3.3 危险行为识别延迟时间比较
对危险行为的识别还需考虑识别延迟的问题,因为快速准确地识别危险行为能在一定程度上避免一些事故的发生。在上述实验环境下,得出了识别延迟实验结果如图6所示。

图6 不同方法的识别延迟时间Figure 6 Identif ication delay time of different methods
由上述实验结果可知:4种方法的识别延迟时间均随着数据量的增加而增长,对照组3种方法的识别延迟时间波动幅度较大,稳定性较差;而本文方法的延迟时间保持在相对稳定的状态,识别延迟时间介于130~260 ms之间。
3 结语
人们在平时生活里常常存在有意识、无意识的大量手势等行为,在沟通过程中也会常常通过手势等特征表达自己的思想。此外,在特殊的环境下也可以通过人体行为判断是否存在危险。为此,本文提出一种基于强化学习的多模态人体危险行为识别方法,并与3种行为识别方法进行实验对比,设定危险行为判定依据、危险行为识别准确率、危险行为识别延迟时间这3个实验指标。结果表明:本文方法对多模态人体危险行为的识别性能较好,准确率较高,且识别延迟时间低于300 ms。然而,本文只考虑了多模态场景中人体目标较少的情况,在后续研究中将对此进行改进,进一步扩大识别目标范围,并解决人群中存在的遮挡问题。
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
煤气与热力(2021年3期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
湖南邮电职业技术学院学报(2020年3期)2020-10-13
阜阳师范大学学报(自然科学版)(2020年3期)2020-08-13
南京大学学报(数学半年刊)(2020年1期)2020-03-19
交通运输系统工程与信息(2020年1期)2020-02-28
中国交通信息化(2018年5期)2018-08-21
