
基于BR算法和遗传算法优化生物柴油生产
2021-12-31 03:25文振中
广州化学 2021年6期
马 驰, 文振中*
(上海理工大学 能源与动力工程学院,上海 200093)
化石燃料的枯竭,对环境的关注以及化石燃料价格的急剧上涨,驱使科学家们寻找替代燃料。作为燃料,生物柴油比常规汽油柴油具有更大的优势。最受关注的优势是环境方面的优势,例如其生物降解性,无毒,硫排放量少,排放较少的空气污染物和除氮氧化物以外的温室气体。除此之外,生物柴油更好的润滑性(减少发动机磨损)并且燃烧时具有更高的氧含量(鼓励完全燃烧)。近年来有关生物柴油的研究取得了诸多进展,尤其是关于生物柴油的制备工艺以及生产成本的研究受到了广泛关注。
鹿清华等[1]对我国生物柴油的可获性及成本进行了分析,提出了利用废弃油脂以及木本油脂作为生产生物柴油主要原料的建议,并对微藻生物柴油的发展和生产提出了展望。李琪等[2]总结了生物柴油的原料类型及生产工艺,并对生物柴油发展前景进行了展望。熊犍等[3]综述了降低生物柴油生产成本的5种方法,分别为:选择含油率高、再生周期短、适应贫瘠土地及不同气候条件的新型植物原料;研究新型固体催化剂;引入超临界法等新工艺;使用比较简便的方法将甘油转化为高附加值产品;以及适度生产规模等。可以看出,虽然国内很多学者对生物柴油的成本及影响因素进行了研究,但基本都停留在总结与综述的层面,并且缺少大量可靠数据的支撑。此前,本人曾提出过运用BP神经网络L-M算法来预测生物柴油成本,取得了不错的预测效果[4]。但预测精度仍有待提高,对网络方法进行改进优化并将不同预测方法进行比对显得尤为重要。
本文采用之前研究中所获取的数据,首先采用BP神经网络BR算法对生物柴油成本进行了预测,与之前研究相比,预测精度有所提高。接着采用遗传算法优化BP神经网络的训练过程,同样实现了不错的预测效果。本文的研究进一步验证了原料成本,工厂产能和甘油置信度对生物柴油生产成本的重要影响,并有效验证了神经网络在处理实际问题中的强大解决能力。
1 数据与评价参数
1.1 数据来源
本文的数据来源于先前研究中所获取的数据[5-25],数据的引用均为真实有效数据,仅对单位进行了统一换算。数据共有59组,主要的数据参数包括:原料价格、工厂产能、甘油置信度和单位成本价格。整理好的数据参数如表1所示。

表1 数据集
1.2 评价参数
采用均方误差mse(mean square error)和相关系数R2作为预测结果的评价指标。均方误差和相关系数的表达式分别如式(1)、(2)所示。

式中,ti为数据实际值,ai为预测值,t¯为实际数据平均值,N为数据样本数。相关系数R2大小决定了变量之间的相关程度,相关系数R2越接近1,表明神经网络的拟合性越好,否则相反。均方误差mse越接近0,表明网络的拟合性越好,否则相反。
2 结果与讨论
2.1 神经网络结构建立与参数设置
BP神经网络通过不断修正网络中的权值和阈值来实现网络的最佳输出[26-28]。一个完整的神经网络结构包括输入层,输出层,隐含层。本例中共有3个输入参数,1个输出参数,因此输入和输出层中的节点个数分别为3和1。隐含层节点个数选取采用经验公式hiddennum=2×inputnum+1其中hiddennum为隐含层节点个数,inputnum为输入层节点个数,因此确定最佳的隐含层节点数为7。确定好的BP神经网络拓扑结构为3―7―1。
将数据划分为训练集和测试集两组,训练和测试集的比例分别为0.85和0.15。采用mapminmax函数对数据进行前处理,将数据参数归一化到[-1,1]区间内,这一步的目的是为了使数据分布更加集中,从而得出更好的预测效果与回归效果。在数据的训练过程中,使用trainbr函数作为网络的训练函数,与trainlm函数相比,trainbr函数减去了训练数据当中的验证集,从而使更多数据进入训练集,往往能实现更好的训练效果。网络参数设置中,将训练集中的训练和测试参数分别设置为0.8和0.2。迭代次数设置为100次,学习率设置为0.1,目标精度设置为0.000 01。
将预测数据代入训练好的神经网络进行预测,连续运行10次预测的相关系数与均方误差见表2。使用BR算法相关系数范围为0.836 5~0.984,均方误差范围为0.003 6~0.031 1;选用第4次训练数据进行预测效果分析,BR算法的预测效果和预测误差如图1、图2所示。由图2计算可知,采用BR算法进行预测的预测结果平均相对误差为4.47%,而之前采用L-M算法进行预测结果的平均相对误差为5.85%,使用BP算法的预测精度有所提高,预测误差降低,预测效果更好。

表2 BR算法预测结果参数表

图1 BR算法预测效果

图2 BR算法预测误差
2.2 遗传算法的原理与实现
2.2.1 遗传算法原理
遗传算法通过模拟自然界中遗传和进化机制,实现输出路径最优化。将遗传算法优化与BP神经网络结合起来可以优化网络结构中的权值和阈值[29-31]。传统的反向传播网络采用梯度下降法逐步调整权值和阈值,而遗传算法将每个个体看作一组染色体,通过一系列筛选、交叉、变异操作得到一组理想的个体,个体中包含了寻优后神经网络结构中的权值、阈值;使用遗传算法训练后的网络预测效果往往优于传统反向传播算法。遗传算法的实现过程主要可分为如下几步:
2.2.2 染色体编码
常见的染色体编码方法有二进制法、实数法等,本文采用实数编码法对数据个体进行编码。由BR算法构建的网络结构可知,输入、隐含和输出层节点数分别为3、7、1。通过实数编码法计算,共有3×7+7×1=28个权值,7+1=8个阈值,所以遗传算法个体编码长度为28+8=36,使用实数编码法将每个个体编码成一个长度为36的实数串。
2.2.3适应度函数
个体最终的选择直接取决于适应度函数的设定,个体被选择的概率很大程度上取决于个体本身适应度的好坏,适应度越好说明该方法在生物柴油的成本预测中的预测效果越优。适应度好的个体往往被优先选择进入下一步,而适应度差的个体被逐步淘汰。为了得出更好的预测效果,将适应度函数设置为测试结果的预测值与期望值之差的绝对值之和,适应度函数F计算公式如式(3)所示。

式中,n为网络输出节点数;ti为BP神经网络第i个节点的期望值;ai为第i个节点的预测值;k为系数。可以看出,最终的适应度值F越小,个体所包含的权值和阈值更理想,网络运行效果越好。
2.2.4 选择、交叉和变异操作
设置好遗传算法的适应度函数后,需要通过选择、交叉和变异找到最优适应值的对应个体。其中选择操作中采用轮盘赌法进行选择,即基于适应度比例的选择策略,每个个体i的选择概率Pi为

式中,Fi为个体i的适应度值,由于适应度值越小越好,所以先对适应度值进行求倒;k为系数;N为种群个体数目。交叉操作选取两个不同个体进行染色体的交换组合,通过交叉操作,新的个体得以产生,若交叉后的个体适应度值优于交叉前个体的适应度值,该个体得到保留并进入变异操作,否则被淘汰。变异操作选取单个个体进行染色体结构变异,变异后的个体同样需要进行筛选。通过以上选择、交叉和变异过程,最终适应度最好的个体得以保留,使用该个体所对应的网络参数对测试集数据进行预测。
2.3 预测结果与比较
2.3.1 遗传算法预测结果
将群体规模M设置为10,遗传代数G设置为10代、交叉概率Pc和变异概率Pm分别设置为0.3和0.1。使用优化后的网络对50组训练数据完成训练后,用剩余的9组数据进行效果测试。运行后的预测结果如图3所示,预测误差如图4所示。从图4可以看出,采用遗传算法进行预测的结果误差更为平滑,预测的分布更加均匀,显示出遗传算法优化后的BP神经网络在实际预测中更加可靠。

图3 遗传算法预测效果
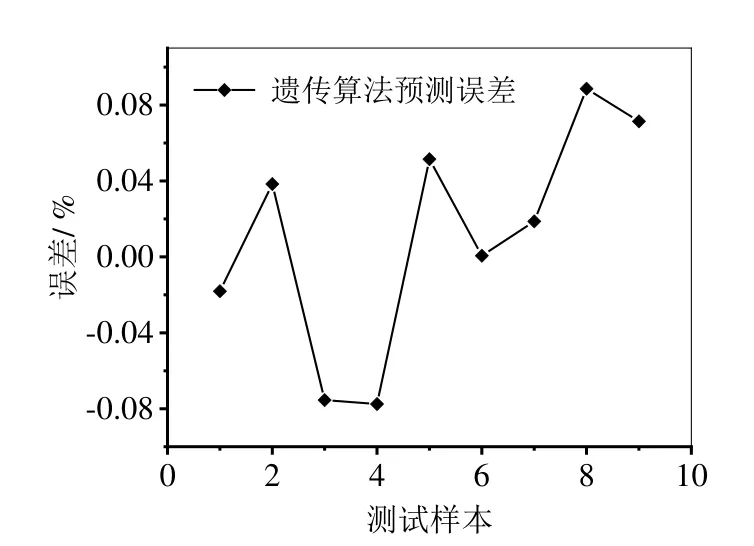
图4 遗传算法预测误差
2.3.2 3种算法结果比较
将使用L-M、BR和遗传算法三种不同预测方法的结果列于表3。与L-M算法相比,两种算法均有更优的预测效果。相比于L-M算法,使用BR算法的均方误差更接近0,相关系数更接近1,预测的平均相对误差由5.85%下降到4.47%,预测的效果得到了全面提升。与L-M和BR算法相比,遗传算法的相关系数有所下降,但均方误差在三种方法中最小,使用遗传算法预测的平均相对误差为4.89%,小于L-M算法而大于BR算法;与另外两种算法相比,遗传算法最大的优势是预测的输出更加平滑稳定,单个数据点的最大预测误差明显下降,在实际预测中具有更好的综合应用效果。综上,使用BR算法能够全面优化BP神经网络的预测效果,使用遗传算法优化在实际应用预测中效果最为理想。

表3 不同算法预测结果
3 结论
生物柴油生产成本是生物柴油发展中关注的重要问题,研究不同影响因素对最终生产成本的共同作用效果具有重要的实际意义。人工神经网络具有出色的复杂非线性问题处理和建模能力,在数据处理与预测当中得到了越来越广泛的应用。针对多变量对生物柴油成本的作用影响,本文在基于先前研究的基础上,分别引进了BR算法和遗传算法对原有的神经网络进行了改进。研究结果表明使用BR算法和遗传算法优化后的预测精度均得到提升,预测的平均相对误差均有所下降。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
中国石油石化(2021年8期)2021-03-30
郑州大学学报(工学版)(2018年2期)2018-04-13
石油地球物理勘探(2017年2期)2017-11-23
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
中国塑料(2016年11期)2016-04-16
智能系统学报(2015年4期)2015-12-27
智能建筑电气技术(2015年5期)2015-12-10
河南科技(2014年8期)2014-02-27
