
基于人工智能算法的成绩等级预测研究
2021-12-29 03:55崔园
现代计算机 2021年31期
崔园
(成都医学院大健康与智能工程学院医学信息工程教研室,成都 610500)
0 引言
在课程教学中引入前沿的计算机网络技术,对传统的课堂教学方式进行改革,将学生在课堂上被动地接受知识转变为学生能够积极主动地进行个性化、高效率的学习,在课程教学改革中如何提高教学效果,如何有效改善课程教学现状是当前一个重要的研究方向。
目前关于网络教学平台的相关研究表明,学习效果与访问次数、在线学习时间和线上讨论次数是有相关性的[1];含有微课视频服务的教学平台,为学生进行课后线上学习提供了新途径,也对提高教学效果有较大的帮助[2];另外,也有研究表明根据学生的学习行为数据,运用分类算法可较准确的预测学生学习态度[3]。我们结合已有的研究结果,并对现有的课程网络教学平台进行研究,总结出如下问题并提出想法:①部分网络教学平台中所产生的统计数据不全面,以至不能有效地充分地分析统计数据,因此,选择一款统计数据较为全面的网络教学平台尤为重要。②网络教学平台普遍缺少对学生学习效果提供智能评价功能,如果我们利用人工智能算法对学生在网络教学平台学习过程中所产生的海量数据进行数据分析,评估课终考试成绩等级,那么教师对学习效果不佳的学生就可以进行督促与指导,也能为教师提供教学改革的决策依据。针对上述问题,本文研究了运用人工智能算法对网络教学平台统计数据进行分析及成绩等级预测。
1 网络教学平台主要功能
在本研究中,我们选择基于超星网络教学平台统计的学习行为数据作为研究对象,该平台是基于任务驱动教学模式的课程平台,是基于资源共享式和师生互动式的网络平台,可作为传统课堂教学的网络辅助教学平台。超星网络在课程内容上按照教学大纲设计了知识结构,加入了充足的有趣味性的教学案例,同时教学平台将重难点做成微课,并拓展了知识点的讲解,方便学生自主学习。
超星网络教学平台的主要功能包括:用户管理、角色权限、学生信息管理、任务管理、作业管理、教学资料管理、教学管理等。在本研究中我们建立了教学数据分析库,它是学生通过网络教学平台参与并完成任务模块、在线学习、观看微课视频、在线测验及作业等任务之后产生的。运用综合学习效果评价算法对学生在教学平台的学习参与和学习效果方面给予评价,运用人工智能的分类算法对学生学习参与数据进行课终考试成绩等级预测分析。一方面,教师对于任务点完成情况不好及作业、测验结果不理想的学生给予督导教学,另一方面,教师在教学中可以及时调整授课内容及教学方法,评价报表为教师教学方法改革及学生调整自我学习方式提供了辅助决策支持[3]。
2 综合学习效果评价算法
在本研究中,我们对学生参与学习程度、作业完成情况等任务点执行情况做出综合学习效果评价,从教学数据分析库中发现潜在的规律或关联数据,运用人工智能中的分类算法对学生学习参与数据进行课终考试成绩等级预测分析,进而对在网络教学平台上学习时间不够、自主学习的效果不太理想的学生进行督导。
在进行学生综合学习效果评价中我们建立了良好的评价模型,结合了学生参与平台互动教学的情况,我们将综合学习效果评价设计为:在线学习时间、微课学习时间、平台作业完成情况、在线章节测验情况、阶段性考试情况5个维度,以下将对综合学习效果评价算法进行说明,公式如下:

式(1)中:N=5,S i为学生在网络教学平台某一项教学环节上的参与程度或成绩,具体计算公式如下:

公式(2)及公式(3)为学生学习过程任务的参与程度,是学生本人在该教学环节上的参与情况与教师发布的任务点总数的比值,公式(4)、公式(5)及公式(6)可以反映学生学习效果,该比值对于不同层次、不同专业的学习对象都能较为客观真实地反映学生完成教师发布任务的情况,学生要想得到较高的S分数必须认真参与每一项任务,因而该教学平台是任务驱动的教学模式。
3 分类算法
3.1 人工智能分类算法介绍
分类分析是通过分析具有类别的样本的特点,得到决定样本属于各种类别的规则或方法。分类算法的主要作用是对已标记好类别的训练数据训练得出规则,从而对新样本进行分类,预测一个归属的类别。常用的分类算法包括:随机森林分类法、逻辑回归分类算法、基于支持向量机(SVM)和XGboost分类法等。对学生各项Si进行分类需要经过数据预处理、特征提取、分类算法选择及最终的学习效果评价。
3.2 特征的提取
由教学平台收集的数据是教学数据与学生学习行为原始数据,在经过数据预处理后,从数据中找出学生学习行为特征显得尤为重要,特征是否突出将影响分类器训练结果。本实验中,将学生各项Si做为特征数据进行分析。
3.3 分类算法的选择与实现
不同训练集选择不同的分类算法,本文通过运用了Python中提供的随机森林算法、逻辑回归算法、SVM向量机以及XGboost算法进行五折交叉验证,对不同分类器准确率进行比较,找出正确率相对较高的分类法。下面分别简述四种分类算法及代码:
(1)随机森林是一种基于树的集成分类器。采用概率熵计算方法,自动减少特征个数。在Python中的代码如下:
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score,train_test_split
pl_random_forest=Pipeline(steps=[('random_forest',RandomForestClassifier())])
scores=cross_val_score(pl_random_forest,teaching_data,label_df,cv=5,scoring='accuracy')
print('Accuracy for RandomForest:',scores.mean())
print('五次分类结果准确率是',scores)
(2)逻辑回归分类器,逻辑回归是一种线性分类器,其工作方式与线性回归相同。代码如下:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
pl_log_reg=Pipeline(steps=[('scaler',StandardScaler()),('log_reg',LogisticRegression(multi_class='multino⁃mial',solver='saga',max_iter=10))])
scores=cross_val_score(pl_log_reg,teaching_data,la⁃bel_df,cv=5,scoring='accuracy')
print('Accuracy for Logistic Regression:',scores.mean())
print('五次分类结果准确率是',scores)
(3)SVM线性支持向量机分类器。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
pl_svm=Pipeline(steps=[('scaler',StandardScaler()),('pl_svm',LinearSVC())])
scores= cross_val_score(pl_svm,teaching_data,la⁃bel_df,cv=5,s coring='accuracy')
print('Accuracy for Linear SVM:',scores.mean())
print('五次分类结果准确率是',scores)
(4)XGBoost是一个基于提升树的集成分类器。与“随机森林”一样,它也会自动减少特征集。
import xgboost as xgb
pl_xgb=Pipeline(steps=[('xgboost',xgb.XGBClassifier(objective='multi:softmax'))])
scores=cross_val_score(pl_xgb,teaching_data,label_df,cv=5,scoring='accuracy')
print('Accuracy for XGBoost Classifier:',scores.mean())
print('五次分类结果准确率是',scores)
4 实验及结果分析
本文选用Python做为建模工具,运用Py⁃thon提供的多种分类算法进行实验,实验数据来源于我校2019级各专业的《计算机应用基础》公共课程的教学数据,共计11个教学班约510个学生学习数据记录。实验采用五折交叉验证方式,每次训练集合的学生数为400,测试集合数为110。实验所用的数据集中每条记录包括学生学习参与程度、测验成绩以及课终考试成绩。训练集分类器将学生各项参与程度及测验成绩设为输入,将学生课终考试成绩设为分类器输出标签,共分为三类,80分以上的标记为“excellent”,60分至80分之间的标记为“good”,60分以下标记为“bad”。
4.1 分类结果
在应用不同分类器进行分类之前,首先通过代码查看数据表中已标记好的列“label”的分布情况,代码如下:
import pandas as pd
teaching_data=pd.read_csv('stu_data.csv',index_col=False)
teaching_data.head()
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(12,5))
sns.countplot(x=teaching_data.label,color='mediumsea⁃green')
plt.title('Credit level distribution',fontsize=16)
plt.ylabel('Class Counts',fontsize=16)
plt.xlabel('Class Label',fontsize=16)
plt.xticks(rotation='vertical');
label_df=teaching_data['label']
teaching_data.drop('label',axis=1,inplace=True)
teaching_data.head()
从条形图图1中可以清楚地看出目标变量“label”被分为“excellent”、“good”及“bad”三类,被分到每一类的大致数据量,类分布没有偏态,样本数据已被分类器分离开了。
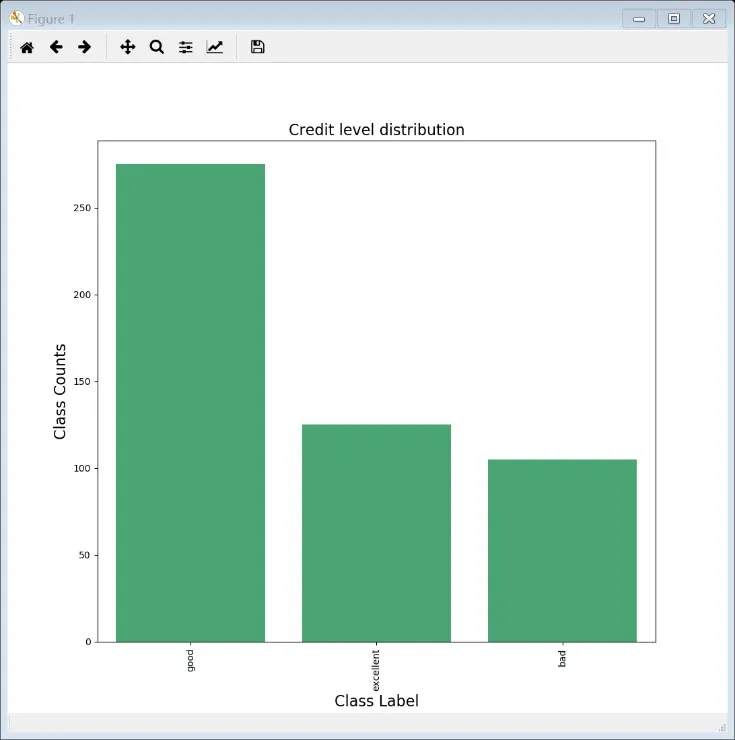
图1 类分布柱形图
在表1中,我们应用了Python中4种常用的分类器进行5组交叉验证,进而比较每种分类算法对每组数据进行分类的准确率,实验结果表明,XGboost分类算法准确率相对最高,平均值达到了0.9284。

表1 四种分类器准确率比较
本文对超星网络教学平台学生行为统计数据进行XGboost分类算法分析,实现了对课终考试成绩等级预测的能力,在实际教学过程中,教师可根据学生在学习过程中各项学习参与度及学习效果,预测课终考试成绩等级,对于学习不积极、参与度不高及学习效果不佳的学生进行监督与指导,学生也能够根据预测成绩及时改善学习方法,提高学习积极性,最终提高学习效果。
5 结语
本文研究了运用人工智能分类算法进行成绩等级的预测,较好地实现了对学生学习过程进行监督与指导。运用XGboost算法能较好地根据学生学习参与度预估学生知识掌握水平和成绩等级,这使得该教学平台更加智能化,为学生能够实现自主学习进行了指导,教师也能够依据预测结果对学生学习过程进行监督,改善了网络教学平台的教学效果。
猜你喜欢
计算机时代(2022年9期)2022-11-03
现代电子技术(2022年15期)2022-07-28
中国教育信息化·高教职教(2022年4期)2022-05-13
民族文汇(2022年14期)2022-05-10
电子产品世界(2022年4期)2022-04-21
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
课程教育研究(2021年10期)2021-04-13
健康体检与管理(2021年10期)2021-01-03
