
自动驾驶仿真测试场景库构建研究
2021-12-29 03:55:00曾德松高琛谭北海余荣
现代计算机 2021年31期
曾德松,高琛,谭北海,余荣
(1.广东工业大学,广州 510006;2.广州蔚驰科技有限公司,广州 511455)
0 引言
现今,自动驾驶是一个热点话题。近10年来,国内外各大汽车制造厂商、众多研究机构、新型创业公司和各大高校都在智能汽车和自动驾驶领域进行了巨大的投入与研究,力求尽快的将智能汽车投入实际应用。然而,Tesla公司和Uber公司的自动驾驶汽车在近年来发生的事故使得大家认识到自动驾驶汽车在真正商业化应用前,都需要经过大量的测试验证才能进行生产使用[1]。传统的测试方法就是利用装有自动驾驶技术的汽车在真实道路上进行测试,这种方式体现出来的缺点就是时间长、成本高、不充分,另外真实道路测试受到很多限制,一些极端边界测试由于安全性考虑是无法实现的。从美国国家公路交通安全管理局(NHTSA)的研究数据来看[2],一辆汽车大约人为驾驶43.6万英里(70万公里)才会遇到一起事故,而且大约人为驾驶1亿英里(1.6亿公里)导致1人死亡。这样来看事故场合测试不仅很难得到而且安全性存在较大问题。单纯依靠真实道路测试的方法显现了巨大的局限性,限制了自动驾驶技术的测试开发。
基于真实道路测试的局限性,仿真技术在自动驾驶领域的应用受到广泛研究者研究探索,通过研究也发现国内外自动驾驶汽车的研究方向重点在于自动驾驶仿真测试开发[3]。目前自动驾驶测试开发流程一般是先仿真测试再到真实道路测试,仿真测试占有较大比重。所以自动驾驶仿真场景库是自动驾驶测试验证不可或缺的角色。目前对于仿真测试开发以及仿真场景库搭建主要聚焦在国内外一些大型公司,如美国Waymo和中国百度,此外车企、研究高校也逐渐在仿真测试场景库方面进行大量的研究开发。
在一个自动驾驶场景中人-车-路-环境之间是可以从空间、时间维度来描述的,是一个复杂动态关系的模型,这种关系模型形成的无限场景是自动驾驶仿真测试开发的基础[4]。为了解决传统道路测试的一系列局限性,本文基于大量国内外的研究和相关研究文献分析,在第1节中针对场景作为自动驾驶仿真测试场景库的主体进行一系列的分析,梳理了场景的定义、场景的元素、场景的数据来源;在第2节中总结了常见场景数据处理,主要包括数据预处理、场景特征提取、场景聚类分析;在第3节中归纳了自动驾驶仿真测试场景库体系的搭建、分布式架构、基于场景库的V字开发模型;在第4节中以前面的为基础提出了基于场景库开发的应用;在第5节中对目前自动驾驶仿真测试场景库的研究提出了一些未来的研究展望。
1 自动驾驶仿真测试场景
1.1 场景定义
对于自动驾驶领域来说场景就是为了测试验证自动驾驶技术的环境,通常与软件的系统开发相结合,运用于测试开发的各个方面,因此在构建自动驾驶仿真场景库之前理解场景显得至关重要[5]。在仿真测试软件系统方面可以用于系统使用的描述、使用要求、使用环境,以及构建性能更加突出的软件系统[6]。
但是,在自动驾驶仿真测试领域中,至今也没有研究者给出过绝对唯一的场景定义。Ulbrich等[7]定义“场景是按照时间序列进行的事件发展”,所有的场景都在一个初始化时间序列的环境中开始。Go等[8]定义“场景由参与者、参与者的背景信息和对其环境的假设、参与者的目的、行动或事件的顺序”,总的来说,任何领域的场景要素都是一样的,但是场景的使用却大不相同。Menzel等[9]根据自动驾驶仿真测试在不同阶段所需场景的不同,提出了三个大的场景分类,有功能场景、逻辑场景、具体场景。朱冰等[10]在相关研究综述的分析上提出场景的本质在于自动驾驶汽车在每个行驶时间中与每个相关的环境成员的动态组合。
上述研究观点中对于场景定义在核心点上观念是相同的:场景定义中应该包含自动驾驶测试车辆的驾驶任务、其他交通参与者和车辆所处的环境。并且,这三者之间会形成一定的动态交互行为。因此,场景的定义可以这样描述:场景是一段时间内测试车辆和周围行驶环境中的各组成元素动态互动联系的描述。具有无限丰富、极其复杂、难以预测、不可穷尽等特点。
1.2 场景元素
确定自动驾驶场景中的元素是任何基于场景技术开发的基石。然而,对于场景中元素的类型与内容,不同研究者之间仍存在争议。Geyer等[11]提出场景元素有预定好的驾驶任务、静态场景元素和动态场景元素。Sauerbier等[12]提出场景元素应包括测试车辆、交通环境元素、驾驶任务信息和特定驾驶行为。Groh等[13]将场景元素分为三类:静态元素,指静止时间足够长到动作几乎察觉不到的物体,比如车道线、静态交通标志等;动态元素,指在一定时间内有一定行为动作的物体,比如行人、骑自行车的人等;环境元素,指所处环境中的一些微观元素,比如天气、照明、风速等。
每一个自动驾驶仿真测试场景中测试车辆在行驶的过程中会影响周围的场景元素,反过来周围场景元素也会对测试车辆产生影响,尤其是测试车辆与周围的交通流。更加深入理解来说测试车辆的本身属性也对场景的构成产生巨大影响。本文通过整合并分析上述研究,梳理了如图1所示的场景元素组成。

图1 场景元素
其中场景元素主要有两大类:车辆基本信息和环境元素。其中,车辆基本信息包括三类:测试车辆的静态属性、动态属性和驾驶任务,环境要素包括四类:气象、静态环境、动态环境和交通参与者。
1.3 场景数据来源
了解场景定义以及场景元素后就需要收集大量的场景数据,建立场景库。目前国内外已经有很多研究机构搭建收集数据,以此来搭建仿真测试场景库。德国KITTI、美国NHTSA、中国腾讯TAD Sim、百度Apollo等都在为自动驾驶测试开发领域开发了大量的场景数据收集系统,给后续仿真场景的搭建提供强有力的数据支撑[14]。整个自动驾驶仿真场景所需的数据来源主要有真实数据、仿真数据[15],如图2所示。

图2 场景数据来源
1.3.1 真实数据
真实数据源主要包括自然驾驶数据、事故数据、封闭场地测试数据、开放道路测试数据。其中自然驾驶数据与事故数据是最常见的真实数据来源,一般研究都基于这两者。
自然驾驶数据来源一般是通过先进的数据采集设备[16],比如在传统汽车上安装摄像头、导航仪、雷达等多个传感器,然后像平时生活开车一样驾驶汽车进行采集数据。比较常见的自然驾驶数据采集环境通常有城市交通道路、高速公路等。国内外对于自然数据的采集体系可以说是相当庞大,美国NHTSA和密歇根州交通部赞助密歇根大学交通研究所开发的IVBSS项目自主搭建了高效的数据采集系统,并利用此系统在几百人驾驶14个月的情况下采集了超过33万公里数据[17]。中国汽车技术研究中心有限公司从2015年开始在北京、天津、上海等城市开展自然数据采集项目,到目前为止已经有超过32万公里的数据,设计城市中心、乡村道路、高速路等常见区域[18]。
事故数据来源一般从每个国家的道路交通事故数据中进行人为的分析筛选。虽然事故数据比较缺乏,但目前许多国家和研究机构都开发收集了比较可靠的交通事故数据,如中国的中汽技术研究中心建立的CIDAS事故数据库、德国的GIDAS深度事故数据库、美国国家公路交通安全管理局的GES数据库。
1.3.2 仿真数据
仿真数据源主要包括驾驶模拟器数据、仿真软件仿真数据。
驾驶模拟器数据主要来源于驾驶模拟器,驾驶模拟器可以在仿真软件中由真实人员驾驶来进行采集数据,相比于真实道路驾驶而言驾驶模拟器既可以保证安全性又可以体现真实性。熊坚等[19]研究说明目前着力开发小型驾驶模拟器可以缓解中国交通面临的许多问题,模拟器主要由驾驶系统、控制系统、视觉系统和语音系统组成。Rong等[20]介绍了一种用于自动驾驶的高保真驾驶模拟器-LGSVL,提供端到端的全栈模拟,可以随时连接到Autoware和Apollo。
仿真软件仿真数据主要来源于仿真软件,通过人为的设定驾驶任务或行驶路线,让测试车辆在虚拟仿真场景下进行行驶,以此来产生仿真数据[21]。仿真环境中的场地可以通过导入地图或地图建模生成,其核心构成主要包括交通流建模,周围静态环境建模[22]。交通流建模大多采用开源交通流仿真软件,如VISSIM、SUMO等,另外元胞自动机的方式也比较常见[23]。
2 场景数据处理
利用各个来源的场景数据进行仿真场景库构建之前必须进行场景数据处理,而场景数据处理的核心是提取能够体现目标场景的特征元素。这个过程需要经过一系列操作。
德国PEGASUS项目在欧洲汽车工业领域的带动下拥有17个合作伙伴,一直努力于如何实现自动驾驶汽车在保证质量的前提下快速实现商用,在其研究自动驾驶仿真技术的过程中就提出了场景数据的处理流程[24]:原始场景数据采集生成、场景数据格式单位检查、额外备注信息的生成、场景相互之间关联程度的分析、场景发生概率分析、场景数字化聚类分析,由逻辑场景经仿真软件生成测试场景。百度Apollo自动驾驶部门提出了一种集中在场景聚类分析方面的方法,主要包含目标场景数据清洗、分析场景元素组成、数字化聚类操作[25]。基于国内外对自动驾驶场景数据处理的研究与综述,本文总结了常见场景数据处理,主要有数据预处理、场景特征提取、场景聚类分析。
2.1 数据预处理
从数据来源来看不同方式获取的传感器数据可能存在格式、单位等差异。而且原始数据没有经过预处理会出现很多无效、错位数据。因此,传感器数据清洗成为构建场景库的前提。
一开始对采集到原始场景数据在利用之前必须进行数据的清洗,不然会影响后续的使用效率。数据清洗主要针对数据冗余、数据缺失、数据异常等进行相关的数据修复操作[26]。目前数据清洗技术已经得到了不错的发展,不仅仅是通过人工手段,更加高效的是算法加人工辅助的方式。不过任何数据清洗方式都必须按照在满足数据清洗质量的前提下尽量降低数据清洗代价[27]。可以用C ost(x)来衡量单个数据元组的清洗代价,C ost(s)表示整个数据集的清洗代价,定义为:

式中x是分组后的单个数据元组;φ(x)是x与所有数据元组总和的比值;t i是数据要素;是修复后的数据要素;s是所有数据元组总和;D是t A到的距离。
2.2 场景特征提取
经过清洗后的数据必须经过场景特征提取才能实现场景解构,以场景特征为要素进行场景聚类是目前比较契合的思路。其中苏江平等[28]根据特征变量的统计分布,选择更加突出场景组成的要素,有道路类型、车辆速度、行人状态、行人速度、时间。胡林等[29]根据测试车辆与两轮车的测试为场景,选择光照、道路类型、测试车辆行驶速度、两轮车行驶速度等特征要素。目前对于场景特征元素的确定一般都是根据目标测试场景的需求来进行主观的分析,没有客观的依据。徐向阳等[30]基于事故场景选择对事故严重影响程度的因素采取多元Logistics回归模型进行分析,多元Logistics回归模型可以定义如公式(3)。

式中Y为事故场景的严重影响程度,其中Y的取值为i=1,2,3,…,A-1;x是影响事故程度的变量,其中N是变量x的数量;α是回归模型的截距;β是回归模型的系数;每一种结果均与Y=A进行对比。
在初步主观分析选取自动驾驶仿真测试特征要素后采用SPSS数据分析软件进行模型分析。
2.3 场景聚类分析
场景特征提取后由于各个特征要素之间的单位存在较大的差异,会导致聚类分析效率低下,所以在聚类分析前要进行场景特征变量进行数字化处理[31]。根据场景特征变量在场景中的表现形式可以进行静态定义处理和动态定义处理,其中静态定义处理其实就是指可以用常数表示状态,比如天气中的晴天和雨天就可以用0和1表示;动态定义处理就是指元素状态会随时变化,不能单纯用常数来表示,比如测试车辆速度和目标速度可以采用极差标准化的方式进行处理[32],这样处理后的动态变量取值就在0~1范围内,标准化后的变量用z xy表示,如公式(4)。

式中i为数据样本的个数;y为一个数据样本中特征变量的个数。
比如危险场景进行特征提取并且特征变量预处理后可以形成如表1所示。

表1 事故场景特征变量的定义
在对相关场景特征进行数字化处理后就可以进行聚类分析。聚类分析是一种比较常见的数据挖掘算法,核心是利用数字公式将相似性高的对象或者元素划分为一类,相似度低的相互分开[33]。常用的聚类算法主要包括K均值聚类、层次聚类、密度聚类、基于深度学习的聚类等[34]。其中层次聚类算法大致的聚类分析过程如图3所示[35]。

图3 层次聚类流程
3 自动驾驶仿真场景库
随着目前新能源领域的快速发展,自动驾驶技术也成为研究的热门。自动驾驶技术要想得到不断的完善必须经过充的测试,必须从一开始道路测试到现在的场景测试转化,国内有许多企业已经在这方面有了一定的突破成果,比如中国汽车工程研究股份有限公司搭建的“中国典型场景库V2.0”、百度的“Apollo场景库”、腾讯的“TAD Sim场景库”等。
3.1 场景库体系搭建
在第1节中阐述了自动驾驶场景的相关概念,其实自动驾驶场景库是由满足某种测试需求的一系列自动驾驶测试场景构成的数据库,是自动驾驶汽车研发与测试过程中的基础数据库,是加快自动驾驶安全测试开发的重要数据库,搭建场景库主要通过虚拟仿真环境及工具链进行复现[36]。整个搭建过程由数据层到场景层。搭建流程如图4所示。其实直接通过仿真软件的场景编辑器进行人工编辑场景各个元素也可以搭建仿真场景,但是只靠仿真软件的方式搭建的场景其真实性、逼真性表现低下。

图4 仿真场景库搭建流程
(1)数据层主要是通过真实的开放或者封闭场地、仿真软件、经验库中采集仿真场景构建所需的数据并对采集到的数据进行一系列的预处理操作,比如冗余删除、缺失删除、数据修复等,最后进行数据格式和参数的统一化后导入场景层。
(2)场景层主要是将数据层导入的数据进行场景特征提取、场景特征数字化操作以形成有用的场景集,然后通过场景聚类处理形成不同的逻辑场景,最后由逻辑场景通过仿真软件构成不同的仿真场景形成场景库。
3.2 分布式架构
从数据-场景-场景库整个开发流程来看,系统需要具备数据处理、数据渲染、场景生成等能力,这些功能实现的背后反映了场景库设计应该具有优秀存储技术与计算技术的支撑。单一的节点不能满足大数据量以及高性能的要求,必须将场景库设计成一个多节点共同分担任务的系统架构。互联网技术中的分布式技术就能完美实现这个架构需求,它追求的理念是降低单个服务器的压力,保证高可靠、低时延。场景库各个模块可以采用分布式微服务进行设计开发,一般可以使用SpringCloud+SpringBoot框架或Dubbo+Zoo⁃Keeper框架。每个模块中的存储、计算任务可以使用主流大数据开发最具代表的几款框架:Ha⁃doop、Spark、Storm、Samza。整体搭建架构如下图5所示。郭建朋[37]采用微服务框架实现了具有数据检验提交、数据标注、数据统计分析三个模块的自动驾驶场景库数据系统,模块中的存储采用FastDFS分布式存储系统,计算任务采用Spark框架。崔志斌[38]利用Docker+Spark技术在云端搭建高性能云数据平台,实现了本地与边缘云端之间的低时延数据数据传输。
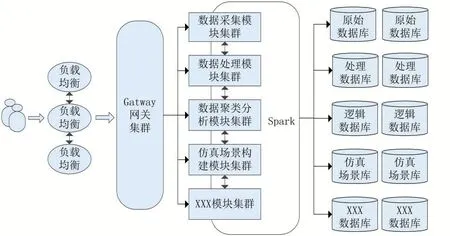
图5 分布式整体搭建架构
3.3 基于场景库的V字开发模型
随着自动驾驶水平的提高,测试场景变得无限丰富,极其复杂,难以捉摸,取之不尽。在道路测试中覆盖所有情况已不可能。因此基于场景库的开发模型变得越加重要。针对自动驾驶的仿真测试同样必须满足汽车的V字开发流程,如图6所示是基于场景库的V字开发模型。它主要包括虚拟测试和实车测试。虚拟测试有模型在环测试(MIL)、驾驶员在环测试(DIL)、硬件在环测试(HIL)、车辆在环测试(VIL),实车测试有封闭道路测试和开放道路测试[39]。

图6 基于场景库的V字开发模型
(1)MIL。模型在环测试是一种虚拟仿真方法,测试系统包括工作台、测试软件和虚拟仿真模型。虚拟仿真模型与被测软件的数据交互通过系统实现,涉及道路交通模型、车辆动力学模型、传感器模型和控制算法[40]。可以通过一系列测试用例在开发环境中运行来验证模型与设计功能之间的一致性,主要用于初级阶段模型与算法的开发。MIL测试逻辑如图7所示[41]。

图7 MIL测试逻辑
(2)DIL。驾驶员在环测试指驾驶员通过外接驾驶器通过人机交互界面进行驾驶虚拟车辆,以此实现驾驶员操作车辆与虚拟场景中其他车辆的互动。Dosovitskiy等[42]介绍了一种用于自动驾驶研究的驾驶模拟器-CARLA,可以支持自动驾驶系统的开发、验证,并使用在三种自动驾驶方法性能研究上。Manawadu等[43]开发了一个简易的驾驶模拟器,可以连接任意接口,创建由驾驶员在现实驾驶中遇到的场景和事件组成的虚拟环境,并实现完全自动驾驶。张珊等[44]利用驾驶员在环在仿真软件CarMaker上仿真开发的一个危险碰撞场景中进行测试,以此来验证在危险驾驶情况下ADAS的反应能力。
(3)HIL。硬件在环测试是一种半物理的测试方式,在于测试计算机的软硬件综合性能。HIL测试适用于比较复杂的工况,在为危险场景测试中可以体现其高效、可重复的优点。Končar等[45]介绍了一个完整的汽车视频记录器HIL设备解决方案,是一种模块化和可扩展化的设备。这种设备可以显著减少自动驾驶所需的算法开发时间。Di等[46]开发了一个基于HIL用于ADAS功能验证的车辆测试台,该测试台通常用于测试汽车上的发动机模块、制动系统模块、变速器控制模块。
(4)VIL。车辆在环测试是指现实世界中真实测试车辆融合到虚拟环境中进行的整车验证测试,VIL可以反映与现实世界相同水平的车辆动力学,节省构建外部环境进行系统验证的成本,并可以避免测试过程中可能发生的碰撞风险[47]。赵祥模等[48]开发了一个由多个子系统组成的VIL自动驾驶快速测试平台,可以使汽车行驶状况达到真实道路行驶状态。Tettamanti等[49]介绍了一种新的车辆在环测试环境方法,能够模拟自动测试车辆周围的真实交通,实现安全的车辆测试。
从传统的汽车到现在的自动驾驶车辆,随着自动驾驶技术和网络连接功能的增加,车辆测试也在不断的丰富,目前MIL、SIL、HIL、DIL和VIL等在环测试已经成为自动驾驶测试开发不可或缺的组成部分[50]。从模型图可以看出自动驾驶仿真场景数据库嵌入到自动驾驶汽车测试开发的所有阶段。其中场景提取主要通过搜索接口实现,场景生成主要通过3.1节所述搭建方法实现。由于场景丰富、计算速度快、测试效率高、资源消耗低、可重复性好、易于嵌入到汽车开发的各个环节,汽车企业和研究机构正逐步向场景化方向发展。
4 基于场景库开发的应用
对于以上针对自动驾驶仿真测试所述的场景库开发框架不仅可以充分体现真实驾驶场景映射到虚拟场景、虚拟场景反映真实现状,而且分布式微服务架构支撑着整个框架,显著提升开发效率,具有广泛的应用和可挖掘的价值。例如可用于开发搭建自然行驶、变道超车、危险碰撞等仿真场景。苏江平等[51]利用11辆汽车在中国五个城市进行数据采集,对其中的车与行人的危险冲突场景进行场景特征提取,然后采用系统聚类法进行聚类分析得到了四类车-行人的逻辑危险冲突场景。Xia等[52]提出一种基于场景复杂度的自动驾驶测试场景生成方法,利用层次分析法提取出衡量测试场景复杂度的指标,然后再聚类将离散的测试用例组合成连续的逻辑场景。Zhang等[53]基于中国事故深度研究(CIDAS)数据库选取一起公路交通事故,通过分析事故原因确定了事故影响因素,然后通过虚拟仿真软件CarMaker构建了包含实际道路环境、主车、其他交通参与者等的交通事故场景。研究目前现有的相关自动驾驶仿真测试场景开发成果可以发现搭建思路基本符合本文研究所述的自动驾驶仿真测试场景库开发框架。基于以上1、2、3节所述内容下面以典型机动车-机动车危险碰撞场景搭建来说明本文所述场景库开发框架的应用。
(1)总体模块设计。从场景库开发框架出发可以分为场景数据预处理模块、场景特征提取模块、场景聚类分析模块、场景仿真构建模块。这些模块之间采用分布式微服务架构进行搭建,大体如图8所示。功能页面展示中通过微服务架构中的远程服务调用各个模块,每个模块采用容器化集群技术,模块与模块之间也具有调用关系,每个模块对相关数据进行提取完成模块功能,最后存储功能结果。这样可以减少各模块之间的耦合度,同时加快各个模块的运行效率。

图8 总体模块设计
(2)场景数据预处理模块。这个模块对机动车-机动车危险碰撞场景数据中的结构化数据与非结构化数据进行异常值修正、缺失值补充。一般可以手动或者编写清洗逻辑代码对有异常的数据进行取均值、取默认值、舍去,要保证清洗代价尽可能低[54]。
(3)场景特征提取模块。这个模块根据机动车-机动车危险碰撞影响因素进行分析确定场景特征,然后对场景数据集进行特征提取。比如可以选取机动车-机动车危险碰撞场景时的光照、天气、路段、交通控制方式、碰撞类型、机动车1速度、机动车2速度为影响因素确定场景特征元素,提取后如表2所示。

表2 机动车-机动车碰撞场景特征元素统计
(4)场景聚类分析模块。这个模块对各种聚类算法优劣势比较选择适合对场景特征提取后场景集聚类分析的算法,首先对(3)得到的特征元素表示按照表1中的数字化定义进行数字化转换操作形成数据集,如表3所示。

表3 机动车-机动车碰撞场景特征元素数字化处理
之后算法分析将数字化处理过数据集表示为一个矩阵,如公式(5)所示。

然后进行样本间距离计算,具体方式是在聚类分析的过程中根据欧式公式来计算样本间的距离,通过计算将距离近的类进行聚合,如公式(6)所示。

式中y是样本中的变量总数;X(i,x)、X(j,x)表示第i、j个样本中的第x个变量。
最后通过类间距离计算后确定最终类数以及聚类分析结果[55]。这个聚类结果可以确定每一类机动车-机动车危险碰撞逻辑场景的场景特征表示以及各个参数分布。如表4所示。
(5)场景仿真构建模块。这个模块根据表4中得到的逻辑场景选择仿真软件进行静态场景元素和动态场景元素的仿真搭建,最终形成机动车-机动车碰撞的仿真场景库。

表4 聚类分析成逻辑场景
5 研究展望
伴随着自动驾驶技术研究的不断深入发展,自动驾驶测试难度也随之提升,开发仿真测试场景是一个非常可靠、有价值的方向,目前国内有很多的研究学者针对仿真测试进行了大量的研究,市面上有很多公司逐步开发自己的自动驾驶仿真测试场景库并有了一定的成果,但是相比于国外来说还是比较落后,还无法跟上自动驾驶技术发展的快速步伐。未来,自动驾驶仿真测试场景库开发方向仍具有巨大的研究开发空间,这里提出如下几个可深入思考与探索的研究方面。
(1)国产仿真技术研究。仿真是仿真测试场景库开发搭建中的一个重要环节,其技术的高低可以展现仿真的逼真度、丰富度。但是目前场景仿真技术因难度大、成本高处于停滞不前的状态,并且中国还是汽车生产与消费的佼佼者,没有自主研发的技术或软件必然成为仿真场景开发的一大阻力,国外仿真软件不能体现中国道路场景的特色。未来可以加大国产仿真技术的研究,开发中国特色的仿真软件。
(2)丰富边界场景研究。目前正常驾驶仿真场景已经开发成熟,基本可以满足自动驾驶技术的测试需求,然而边界场景却极度缺乏,主要在于边界场景构建困难。边界场景的丰富度就可以体现一个仿真场景库的功能边界。现今广大研究者还未将重心转移到边界场景的研究上,未来可以以边界场景研究为核心出发点,衍生开发更多边界场景。
(3)加速场景库场景生成与提取研究。从数据到场景库无非是实现场景库场景的生成以及自动驾驶测试时的场景提取使用,由于场景生成过程的难度和场景库场景数据庞大导致这两个操作都需要经历长时间的等待,为了测试效率未来可以在加速方面进行进一步的研究,可以考虑引用分布式加速引擎开发以及分布式计算平台等。
6 结语
(1)目前自动驾驶汽车正在不断地出现在大众视野中,随着而来的自动驾驶技术测试也变得更加困难,每一辆自动驾驶汽车在上路之前都必须经过充分的测试,由于临界事故测试等场景的缺乏,道路测试已经不能满足测试的需求。道路测试所占比重逐渐被仿真场景测试所取代,研究仿真场景开发、搭建场景库已成为自动驾驶测试开发必不可少的重要环节。
(2)本文在调研分析大量自动驾驶仿真测试场景库研究成果的基础上,首先针对场景作为自动驾驶仿真测试场景库的主体进行一系列的分析,梳理了场景的定义、场景的元素、场景的数据来源;其次,总结了常见场景数据处理,主要包括数据预处理、场景特征提取、场景聚类分析;再次,归纳了自动驾驶仿真测试场景库体系的搭建、分布式架构、基于场景库的V字开发模型;最后,在此基础上提出了基于场景库开发的应用。本文所述内容可以给自动驾驶仿真测试场景库开发研究提供一定的参考与认知。
(3)自动驾驶仿真测试场景库的研究现在正处于不断探索与开发的阶段,场景库丰富度、多样性、有效性等都需要研究开发者共同努力,未来可以往仿真场景自动生成、加速生成、共建场景库等方向继续研究前行,推动自动驾驶技术的发展。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:30
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01 06:27:42
幽默大师(2020年11期)2020-11-26 06:12:12
学生天地(2020年5期)2020-08-25 09:09:08
摄影之友(影像视觉)(2019年3期)2019-03-30 01:37:20
摄影之友(影像视觉)(2019年2期)2019-03-05 08:27:26
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:20
电子测试(2018年10期)2018-06-26 05:53:36
汽车博览(2016年9期)2016-10-18 13:05:41
文理导航·教育研究与实践(2015年12期)2015-12-04 00:49:23
