
动态视觉传感器的目标检测算法对比分析
2021-12-28 10:47邱忠宇赵文龙潘洪涛史冉东
空天防御 2021年4期
邱忠宇,赵文龙,高 文,潘洪涛,史冉东
(上海机电工程研究所,上海 201109)
0 前 言
近年来,机器视觉在安防、军事、医疗、工业农业生产等诸多领域大放异彩,但面对复杂环境,图像传感器仍无法平衡高精度与低计算消耗的关系。1991年,《Scientific American》杂志上刊登了一张由模仿眼睛神经结构的新型硅视网膜获得的猫的图像[1],这是首次从生物学和工程学角度研究立体视觉问题并产生成果,也标志着视觉仿生神经形态领域的揭幕。事件相机作为一种异步传感器,改变了传统获取视觉信息的方式,从原来的根据时钟周期采样获取视觉信息,变为依靠动态场景中光线变化获取视觉信息,这与视网膜系统的信号传输有着极大相似之处。
动态视觉传感器最早源于瑞士的Jörg Kramer 教授设计的第一款异步动态视觉传感器(dynamic vision sensor,DVS),其成像规格为48×48,每个像素点会根据光照强度变化,输出ON/OFF 事件[2-3]。2004年,瑞士的Lichtsteiner 等[4]在动态视觉传感器中加入反馈机制,加快了模型反应速度,提高了传感器的动态范围。2006年到2008年,Lichtsteiner 等[5]将前端光感受器与开关电容差分电路相结合,使得响应延迟值进一步降低,动态范围也有所提升。2009年,奥地利的Posch团队[6]设计了一款基于事件的红外视觉传感器。2014年,瑞士Berner 等[7]设计了动态有源像素视觉传感器(dynamic and active pixel vision sensor,DAVIS),实现异步事件和同步帧级图像的同时输出。
事件相机以其微秒级的时间分辨率、低延迟、高动态范围和低功耗的特性,在高速、高动态范围等挑战性场景中有着极高的应用潜力。本文通过对基于事件的特征检测算法和基于事件的卷积神经网络算法这两种目标检测算法进行对比分析,验证基于事件的卷积神经网络算法在多目标、高速场景检测的优越性。
为验证检测算法,根据MNIST-DVS 数据集和POKER-DVS 数据集进行目标检测,具体流程如图1所示。基于事件的特征检测算法采用第一章的积分模型和LS(leaky surface)模型进行事件相机数据的预处理,并通过改进方向梯度直方图(histogram of oriented gradient,HOG)算法进行特征提取,改进支持向量机(support vector machine,SVM)分类器进行特征分类,进而实现目标的检测与分类。基于事件的卷积神经网络算法采用第一章的LS 模型,将其放在神经网络模型的第一层进行事件处理,然后进行神经网络的模型训练,最终实现基于事件的卷积神经网络的目标检测。
1 动态视觉传感器事件处理
动态视觉传感器作为一种异步传感器,改变了传统获取视觉信息的方式。动态视觉传感器与传统图像传感器的区别在于,动态视觉传感器没有“帧”的概念,主要利用动态场景的光照强度变化进行采样,输出由微秒级的事件组成,类似于点云,不受传输速度的限制,图2 为传统图像传感器与动态视觉传感器的对比。
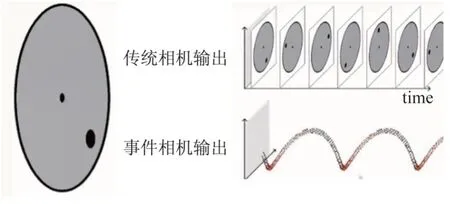
图2 传统图像传感器与动态视觉传感器的输出对比Fig.2 Output comparison between traditional imaging sensor and dynamic vision sensor
动态视觉传感器的输出样例如表1 所示,共有4个变量,分别为时间t、像素点横坐标x、纵坐标y、极性p。时间t单位为微秒级分辨率,较为精确地表示出像素点的光照强度变化时间;坐标(x,y)构成一个二维空间,表示像素点的位置;极性p∈{-1,1}表示某一个像素点的光照强度是否发生变化。如果p无变化则动态视觉传感器没有事件输出;如果像素点的光照强度变亮超过某个阈值,则极性为1;如果像素点的光照强度变暗超过某个阈值,则极性为-1。有效提取事件信息是一个重要的研究内容,本文参照已有方法选取两种模型进行对比。

表1 动态视觉传感器输出样例Tab.1 Output sample of dynamic vision sensor
1.1 LS模型
CanniciM 等[8]设计一种LS 模型,将动态视觉传感器产生的稀疏事件整合到一个表面,用于卷积神经网络的事件预处理,便于后续卷积层、池化层的内部数据处理和修改信息的向下传递。
参照尖峰神经网络具有保持过去事件记忆的功能,其主要通过一个能够累积事件的体系结构将动态视觉传感器产生的稀疏事件整合到LS模型上。时刻t产生的事件对应像素坐标(xe,ye)和时间戳tts,每个像素位置(x,y)产生一定的增量Δincr。此外,表面所有像素的衰减量取决于上一次接收到的事件和先前接收到的事件之间的时间间隔,因此,t时刻的表面像素(x,y)对应值具体可以表示为
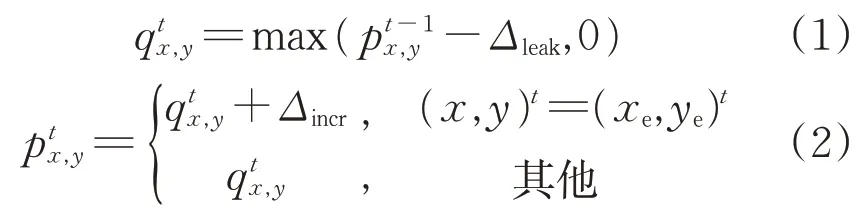
式中:表示LS 模型上的像素坐标(x,y)的值;Δleak=λ·(tts-tt-1s)。λ和Δincr对整个模型有很大影响:Δincr决定每个事件中包含多少信息,而λ定义了其中的衰减率,可通过调整λ和Δincr决定每个像素点值的累积,最大值化操作可防止像素值变为负值。
1.2 积分模型
解决稀疏事件还有另外一种方式——积分模型[9],主要是将每个像素点的事件转化为一系列的连续函数,然后通过积分实现图像重构。
根据输出事件e={tts,x,y,p},基于事件相机的积分模型可表示为
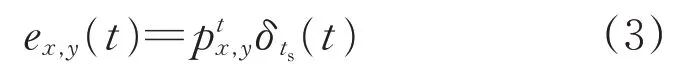
式中:ex,y(t)表示随时间变化的连续函数;δts(t)是一个脉冲函数,事件序列被转换成连续时间信号,由一系列脉冲组成;表示时间戳为tts的位置(x,y)的事件输出极性。这样,图像中每一个像素点都有对应的一个ex,y(t)来表示。
接着定义增量E为时间段[f,t]之间的事件的积分累加,可表达为

通过得到的增量E,将其与原始值进行整合,像素点(x,y)对应值可表达为
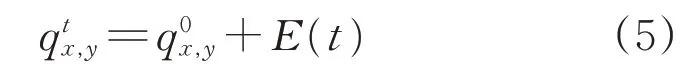
2 基于事件的特征检测算法
基于事件的特征检测算法采用改进HOG 算法[10]和改进多分类SVM 算法[11-12]。首先采用LS 模型或积分模型将事件形成到某一平面,再通过改进HOG算法和改进多分类SVM 算法进行特征提取和目标检测。HOG特征提取算法,在进行梯度计算之前通过高斯滤波实现图像的平滑操作,对梯度方向位于相邻区间的中心之间的方向和位置进行双线性插值,可降低图像的局部细节特征,提高图像的整体细节性,原理如图3所示。点M、N、P像素值的计算公式为
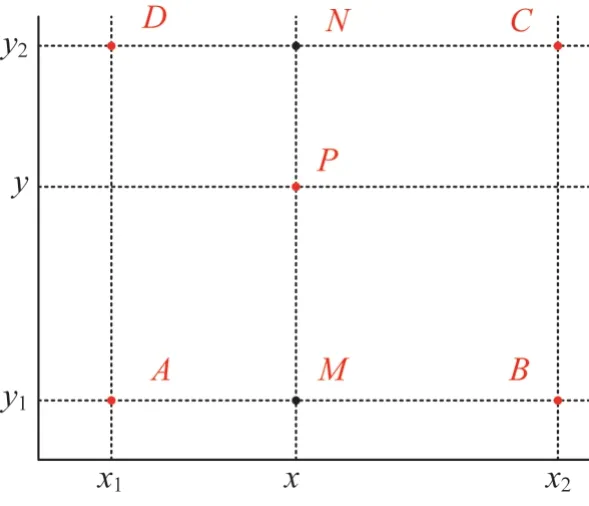
图3 双线性插值原理Fig.3 Schematic diagram of bilinear interpolation
并将A、B、C、D的坐标(0,0)、(0,1)、(1,0)和(1,1)代入,化简可得矩阵表达形式为
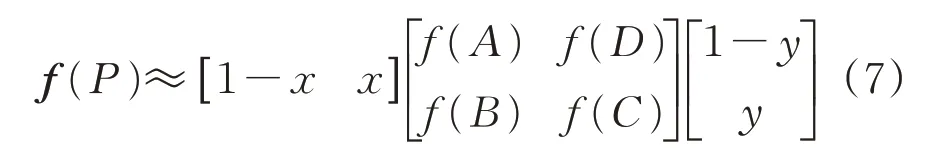
式中:f(A)、f(B)、f(C)、f(D)、f(M)、f(N)、f(P)分别为像素点A、B、C、D、M、N、P的像素值。
SVM分类器只是一个二分类模型,要将多分类复杂问题转换为二分类的简单问题,可通过采用多个SVM 分类器来实现多分类目的。由于目标检测中提取出来的特征向量中背景类别通常占绝大部分,因此本文对二叉树的分类方法进行了改进。首先将背景与其他类别通过SVM 分类器进行分类,以有效地分离背景特征类别与目标特征类别,最大限度地提高目标检测的精度。改进多分类SVM 算法如图4所示,步骤为:
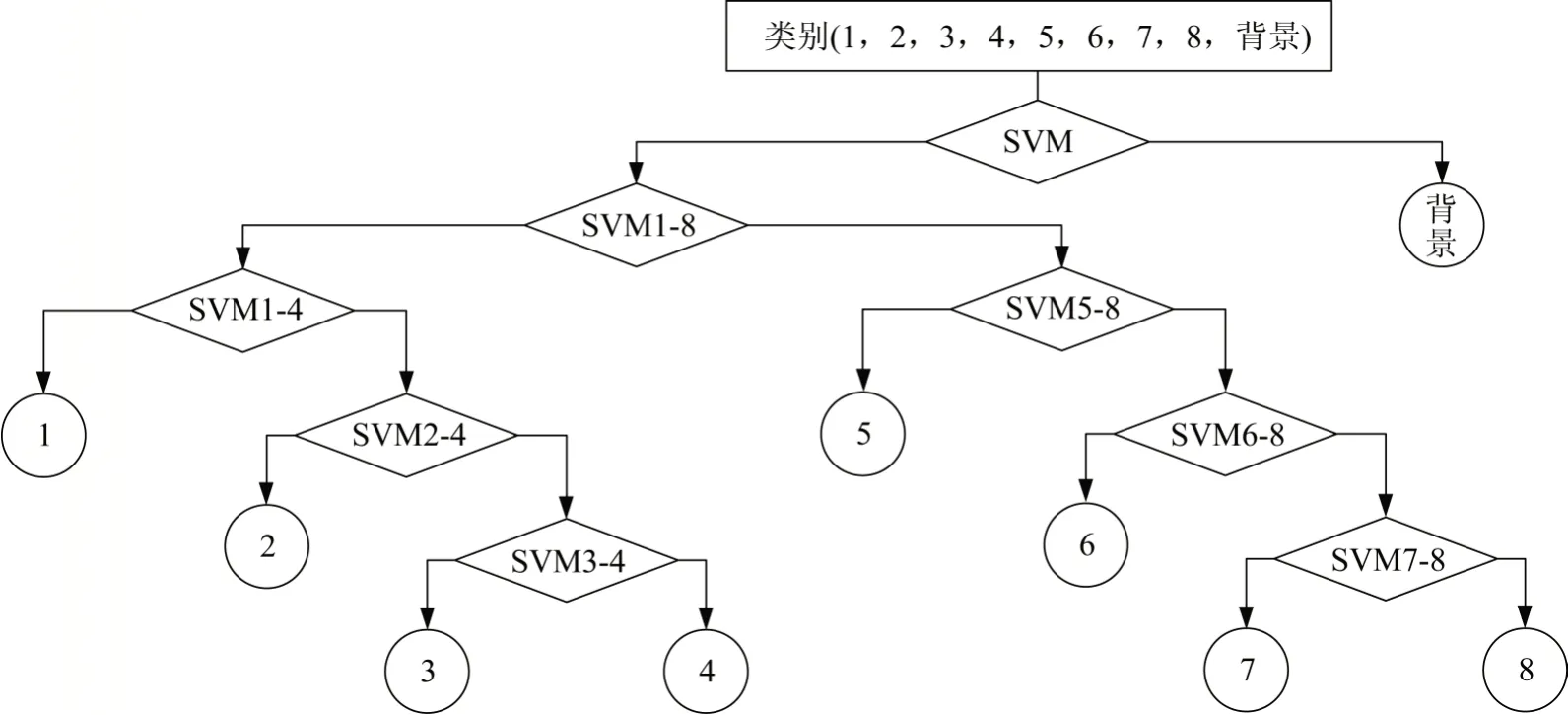
图4 改进多分类SVM算法Fig.4 Improved multi-classification SVM algorithm
1)将训练样本数据集输入SVM 模型中,得到一个初步分类背景特征与目标特征的SVM模型S。
2)通过模型S将目标特征和背景特征分为两大类。
3)根据目标特征类别数量N判定是否需要进行二分类。如果N≤6,可直接进行逐个分类;否则,则需要先进行二分类,再次将目标特征分成两大类,以减少错误累积。
4)输出各个特征类别,实现目标检测。
3 基于事件的卷积神经网络算法
本文采用已有的基于事件的深度学习目标检测算法——Event-YOLO[8]进行验证,基于事件的卷积神经网络,对卷积层和池化层进行重新表达,通过重新计算更新事件的像素区域的特征,并以此实现最终的目标预测。在此设计中,特征图只会在新事件传入时才进行更新,此外,Event-YOLO 引入了衰减机制,随着时间推移,某些像素点的增量在各个隐藏层也会不断衰减,这也导致了计算出来的特征信息会随着视觉信息在输入端的消失而逐渐衰减消失。
Event-YOLO算法的网络架构主要参照了YOLO检测网络[13],加入了LS 模型,并改进了卷积层、池化层、全连接层。基于事件的卷积层(e-conv)的主要功能是:通过事件更新来确定此刻的特征图相比于上一时刻特征图在哪个区域发生变化,便于重新计算已经发生变化的特征图和重用未变化的特征图。基于事件的最大池化层的设计核心在于:在最大池化层的每个接收域中,最大值的位置可能会随着时间保持不变,利用此性质可避免每次重新计算最大值的位置。全连接层可用1×1的基于事件的卷积层来代替,将之前层提取的特征映射成一组向量。损失函数与YOLO网络损失函数相同。
Event-YOLO 网络结构如图5 所示,网络采用事件流作为输入,通过LS 模型将事件集成到一个表面上,并采用基于事件的卷积层、基于事件的最大池化层对事件进行特征提取,最后形成可用于目标检测和分类的网络结构。所采用的事件数据集像素大小均为128×128或256×256,因此本文将输入表层划分成4×4 个区域,这样无论数据集尺寸为何种形式,都无需对网络进行大的修改。此外,本网络结构设置每个区域需要预测两个回归框,即B=2,由于类别根据数据集的不同有所差异,在MNIST-DVS 数据集中,共有10个数字,类别数目C=10。
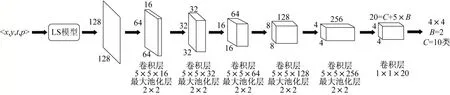
图5 Event-YOLO网络结构Fig.5 Event-YOLO network structure
4 仿真结果及分析
4.1 检测数据集
目前传统图像的目标检测数据集数不胜数,但DVS尚处于起步阶段,公开的基于事件的数据集资源稀缺。目前最流行的数据集有:MINST-DVS、POKER-DVS[14]、CIFAR10-DVS[15],这些数据集大多来源于传统的数据集。受限于数据集,本文采用MINST-DVS、POKER-DVS两种数据集进行检测。
MNIST-DVS数据集是由塞维利亚微电子研究所制作,来源于传统图像MNIST数据集。MNIST-DVS数据集通过平滑插值算法,将原始尺寸的手写数字图像放大4、8、16倍,最终通过动态视觉传感器录制300 00组事件数据集,其中0~9每个数字各有3 000组。
POKER-DVS 数据集是一个小的神经拟态记录的数据集,通过在DVS前快速浏览定制扑克牌而制作形成,此数据集包含了黑桃、红桃、方块、梅花4 类目标,每组数据像素大小为31×31。POKER-DVS 数据集数据样本过少,为便于应用到目标检测算法中,本文进行处理,每个时长控制在1.5 ms 左右,并结合扑克牌中的边界框,最终形成了292个数据样本。
为验证已有算法的准确性,本文设计了单目标、多目标、快速运动场景进行试验验证。在单目标检测中,采用MNIST-DVS 数据集进行验证;多目标和快速运动场景采用POKER-DVS数据集。
4.2 MNIST-DVS数据集检测结果分析
单目标检测采用MNIST-DVS 数据集进行验证,在基于事件的特征检测算法中,采用不同的事件处理模型对MNIST-DVS 数据集进行检测,检测结果如表2 所示。由表2 可知,数字6 和数字9 在不同的角度有着极大的相似性,且两者的检测精度较低,其主要原因在于错误的分类。此外根据数据还可以发现,积分模型和LS 模型这两种模型对事件的处理结果精度大致相当。
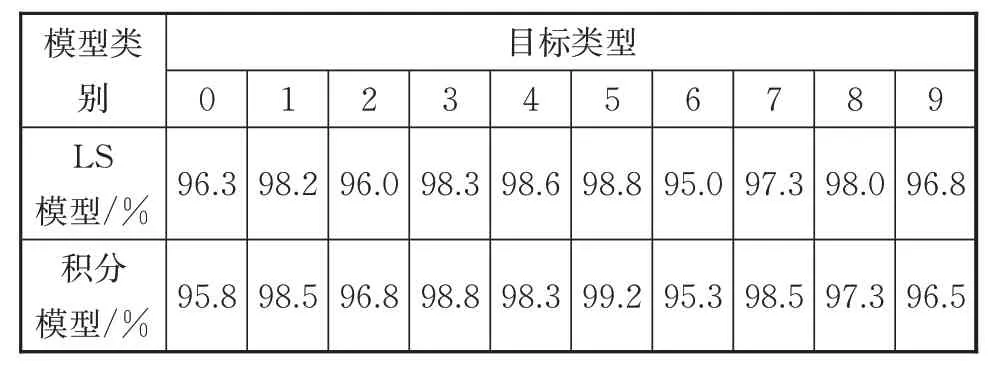
表2 基于事件的特征检测结果Tab.2 Result of event-based feature detection
MINST-DVS 数据集下,基于事件的特征检测算法准确率为97.3%,基于事件的卷积神经网络算法准确率为98.2%(事件处理后3 种不同尺寸数字图片的检测结果如图6 所示)。两种算法检测准确率都比较高,均在97%以上,其原因在于该数据集背景较为简单,事件处理模型可以快速地将事件背景剔除,形成只有数据的表层,这种检测较为简单且准确率会很高。

图6 MINST-DVS数据Fig.6 MINST-DVS dataset
4.3 POKER-DVS数据集检测结果分析
在快速场景目标检测中,基于事件的特征检测算法结果较差,准确率为52.6%,检测效果较差的原因不在此文中进行分析。面对多目标检测,简单的基于事件的检测网络结构不足以实现复杂的目标检测,因此本实验加深网络层次,加深了Event-YOLO网络,增加基于事件的卷积层的层数,并将其网络结构命名为Event-YOLO-D。POKER-DVS 数据集检测结果如图7所示。

图7 POKER-DVS数据Fig.7 POKER-DVS dataset
根据数据集检测结果,如表3所示,对于单目标检测,不同的检测网络目标检测准确率均高达98%以上,精度较高,符合验证性能;对于多目标和快速运动场景,受限于数据集较小,且目标在DVS 中闪动极为快速,检测准确率相对不高,但增加网络层数对检测的准确度有明显提升,基于DVS的目标检测效果已经远远高于同类别的传统图像检测效果。
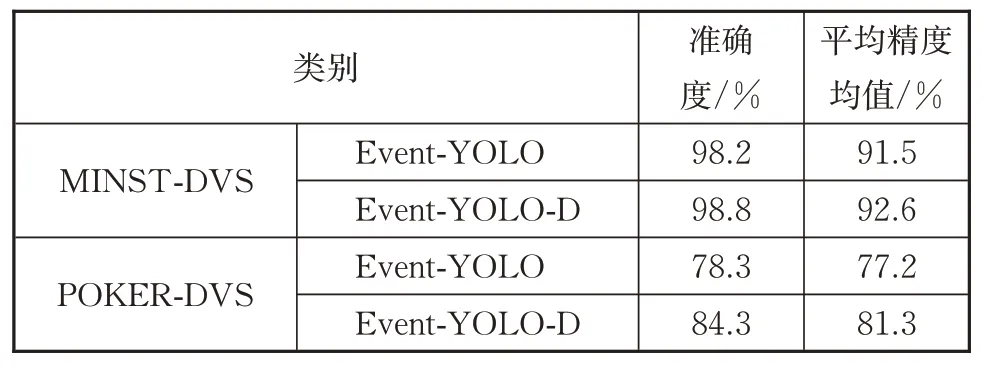
表3 不同数据集的检测结果Tab.3 Detection results of different dataset
5 结束语
本文针对动态视觉传感器输出事件特性的分析,提出两种处理事件模型并通过算法检测仿真进行比较,仿真结果表明,相同条件下两种处理事件模型的检测准确度无较大差异。此外,本文根据基于事件的特征检测算法和卷积神经网络算法,分别对MNISTDVS和POKER-DVS数据集进行单目标、多目标和快速场景检测,基于事件的卷积神经网络算法检测效果更佳,网络层数越多,检测精度越高,验证了基于事件的卷积神经网络算法在多目标、高速场景检测的优越性。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
小学科学(2022年8期)2022-09-07
计算机仿真(2022年7期)2022-08-22
消费电子(2022年5期)2022-08-15
计算技术与自动化(2022年1期)2022-04-15
舰船科学技术(2021年12期)2021-03-29
上海师范大学学报·自然科学版(2019年5期)2019-12-13
时代英语·高一(2019年1期)2019-03-13
现代电子技术(2018年18期)2018-09-12
软件导刊(2018年4期)2018-05-15
