
基于面部特征的疲劳驾驶检测方法研究
2021-12-24 01:43汪洪涛谢牡丹
武汉理工大学学报(交通科学与工程版) 2021年5期
汪洪涛 谢牡丹 潘 昊*
(武汉理工大学网络信息中心1) 武汉 430070) (武汉理工大学计算机与人工智能学院2) 武汉 430070)
0 引 言
疲劳驾驶是造成交通事故的重要原因之一.在中国,每年有30%以上的公路交通事故与疲劳驾驶有关[1].目前,疲劳驾驶的检测方法主要有基于心电图、脑电图等生理特征的疲劳检测方法;基于车道偏移、转向盘角度、车速等车辆行为特征的疲劳检测方法;以及基于驾驶员眼睛、嘴巴等面部特征的疲劳检测方法[2].
其中基于面部特征的疲劳检测方法具有非接触、低成本等优点逐渐成为研究热点.近年来,采用卷积神经网络的面部检测算法已经逐步成为了主流[3].Zhang等[4]提出了一种简单而有效的特征聚集网络(FANet)框架,用以构建一种新型的单极面部检测系统,框架的核心思想是利用一个卷积神经网络固有的多尺度特性聚合高级语义特征映射的不同尺度的上下文线索.Triantafyllidou等[5]提出了一种基于面部检测的轻量级深度卷积神经网络.然而,由于面部表情存在表情夸张、姿态变化、面部遮挡等客观不可控的因素,仅依靠单一的结构模型进行检测很难产生良好的泛化能力,使得模型在实际应用中的鲁棒性较差.为了克服这一不足,近年来出现了一系列改进的深度学习方法,其中级联CNN采用级联结构可以在训练大量样本的过程中捕捉到面部区域中各种复杂多变的情况[6].
文中提出了一种基于面部特征和多指标融合的方法,生成对抗网络的弱光增加网络[7],对驾驶员图像进行预处理,通过多任务级联卷积神经网络检测视频数据集中的面部,定位关键点,再将整张面部图像送入到FSR-Net(fatigue super-resolution network)多任务疲劳状态识别网络,同时检测眼部和嘴部状态,通过PERCLOS等多个指标进行疲劳驾驶判断.
1 基于生成对抗网络的弱光增强
疲劳驾驶检测主要是根据面部特征信息来进行判断,由于车辆在低光照或夜间行驶时,采集到的视频图像对比度低、能见度差、ISO噪声高,这大大影响了测试的精度.为了解决这些问题,研究人员提出了大量的算法,从基于直方图或基于认知的算法[8-9]到基于机器学习或深度学习的算法[10-11].本文提出一种基于生成对抗网络的弱光增强算法对驾驶员弱光图像进行增强.
1.1 EnhenceGAN网络结构设计
为了突破成对训练数据集以及真实图像监督标签的限制,设计了EnhenceGAN网络结构,提出了一个针对图像全局和局部的双鉴别器进行微光增强的机制,以及一种自正则化感知损失的方法来约束微光输入图像与其增强后的图像之间的特征距离,并结合对抗性损失进行训练,见图1.
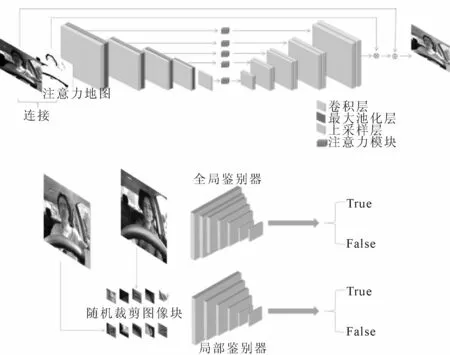
图1 EnhenceGAN整体架构
由图1可知:EnhenceGAN网络包含一个注意力引导的U-Net[12]生成器和一个双鉴别器,U-Net生成器是一个带有残差的编解码网络,由8个卷积块实现,每个卷积块由两个3×3的卷积层组成,并加入attention模块.双鉴别器是对全局和局部信息进行定向.对于全局鉴别器,通过引入相对论鉴别器函数,并用Leat square GAN(LSGAN) 损失代替相对论鉴别器中的sigmoid函数,生成全局鉴别器D和生成器G的损失函数,为
Exf~Pfake[DRa((xf,xr)2]
(1)
Er~Preat[DRa(xr,xf)2]
(2)
对于局部鉴别器,每次从输出和真实图像中随机裁剪5个图像块,采用LSGAN作为对抗性损失,为
Ex~Pfake-patches[(Dxf-1)2]
(3)
(4)
利用感知损失方法限制低光输入和增强正常光输出之间的VGG-feature距离,构建感知损失与对抗损失进对抗的损失函数LSFP,为
(5)
式中:IL为输入低光图像;G(IL)为生成器的增强输出;φi,j为在ImageNet上预训练VGG-16模型中提取的特征映射;i为第i个最大池化层;j为第i个最大化池化层后的第j个卷积层;Wi,j,Hi,j为提取的特征图的维数.式中强调了其自正则化的作用,即在增强前后图像内容特征保持不变,从而约束了图像除光照以外的特征信息.
EnhenceGAN弱光增强的具体步骤为:
步骤1取输入RGB图像的亮度分量I,将其标准化至[0,1].
步骤2对编码器中的特征图用1-I进行加权,得到attention map.
步骤3将attention map大小调整到对应的特征图大小.
步骤4将attention map与解码器中的特征图进行加权.
步骤5将attention与U-Net转换中各部分的特征进行逐元素相乘.
步骤6网络输出的部分和attention map相乘得到一个残差.
步骤7残差和原图相加,得到最终的增强后图像.
1.2 实验及结果
建立一个非配对的含2 500张低光图像和1 000张正常图像的数据集,最开始从0训练100次迭代,学习率为1×10-4,再训练100次迭代,学习率线性衰减为0.
对实验结果采用自然图像质量评估器(NIQE)进行定量比较,通过五种方法在五个公共数据集上的NIQE进行比较,结果见表1.
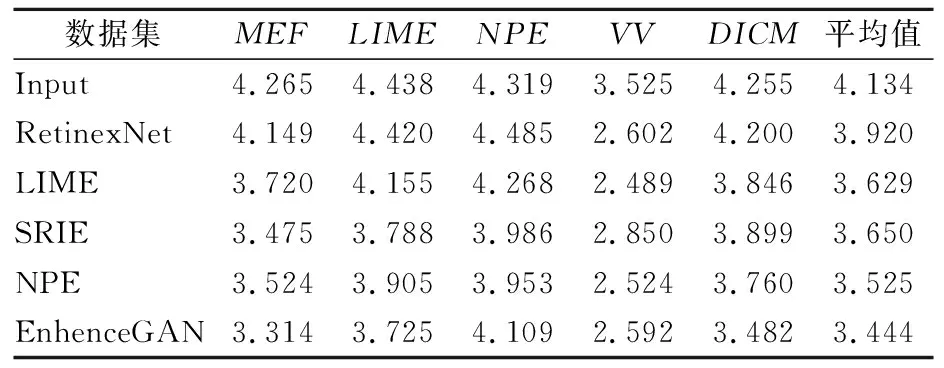
表1 五种方法在五个数据集上的NIQE值
由表1可知:EnhenceGAN在弱光图像增强方面总体上优于其他方法.
2 基于改进的多任务级联卷积神经网络的面部检测
2.1 基本网络架构改进
改进后的MTCNN网络结构图见图2.P-Net以大小为12×12×3的图像为输入,可以有效地从输入图像中获取粗糙的面部窗口.P-net中的C1、C2和C3是卷积层,内核大小为3×3.

图2 IMP-MTCNN网络结构
Relu、池化和归一化在每个卷积阶段的输出之后进行. O-Net的详细参数见表2,由8层组成.O-Net以大小为48×48×3的图像为输入,可以有效预测相应的面部地标定位和边界盒回归.
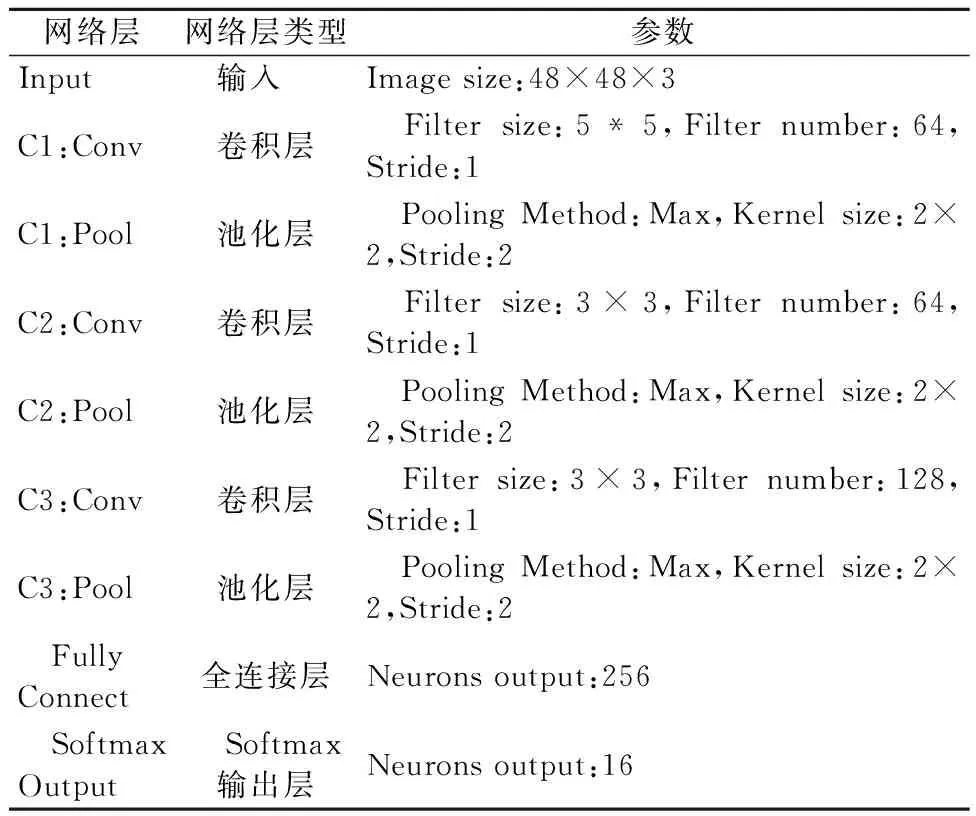
表2 IMP-MTCNN网络层参数
前六层是卷积层,后两层是内积层.该方法中卷积和全连接层的非线性激活函数采用ReLU函数.通过对比实验,选择了固定核尺寸和滤波器尺寸三种卷积层的参数,全连接层和softmax输出层分别将输出卷积特征映射为256-d和16-d特征向量.最后softmax输出层有16个神经元,预测相应的面部地标定位和边界盒回归.与O-Net相同,P-Net和R-Net中的参数是根据P-Net中相同策略下的可比实验设置的,目的是得到相应的精确输出.
该层网络的输入特征更为丰富,在网络结构的最后是一个更大的256的全连接层,保留了更多的图像特征,同时再进行面部判别、面部区域边框回归和面部特征定位,最终输出面部区域的左上角坐标和右下角坐标与面部区域的五个特征点.O-Net拥有特征更多的输入和更复杂的网络结构,具有更好的性能,这一层的输出作为最终的网络模型输出.
2.2 损失函数
IMP-MTCNN的联合训练是一个多任务的训练过程,包含:人脸非人脸分类、边界框回归以及面部关键点定位.IMP-MTCNN中有一个指标值,通过该值确定是否需要计算其中某一项的损失,最终的IMP-MTCNN损失函数为
(2)
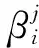
2.3 在线困难样本挖掘
为了使学习到的网络模型有更强的泛化能力,在网络训练过程中,采用的是在线困难样本挖掘(online hard example mining,OHEM)算法.选取前70%作为困难样本,计算出相应的梯度用于反向传播过程,OHEM算法为:
输入 ground truth标签序列gt_label,预测标签列pred_label
步骤1初始化 ratio←0.0, break point←0
步骤2loss←CrossEntropyLoss
步骤3sorted←loss/sum
步骤4For i, v in sorted[0] do
步骤5If ratio≥0.7
步骤6break
步骤7Ratio+=v
步骤8End for
步骤9bp←sorted[1][:break point]
步骤10topK←loss[bp]
步骤11End
输出 前70%困难样本的梯度针对在线困难样本挖掘方法的效果评估,在O-Net中训练了另一个不使用该策略的模型,并比较了相应的损失曲线.这两个模型的结构和参数是相同的,结果见图3.
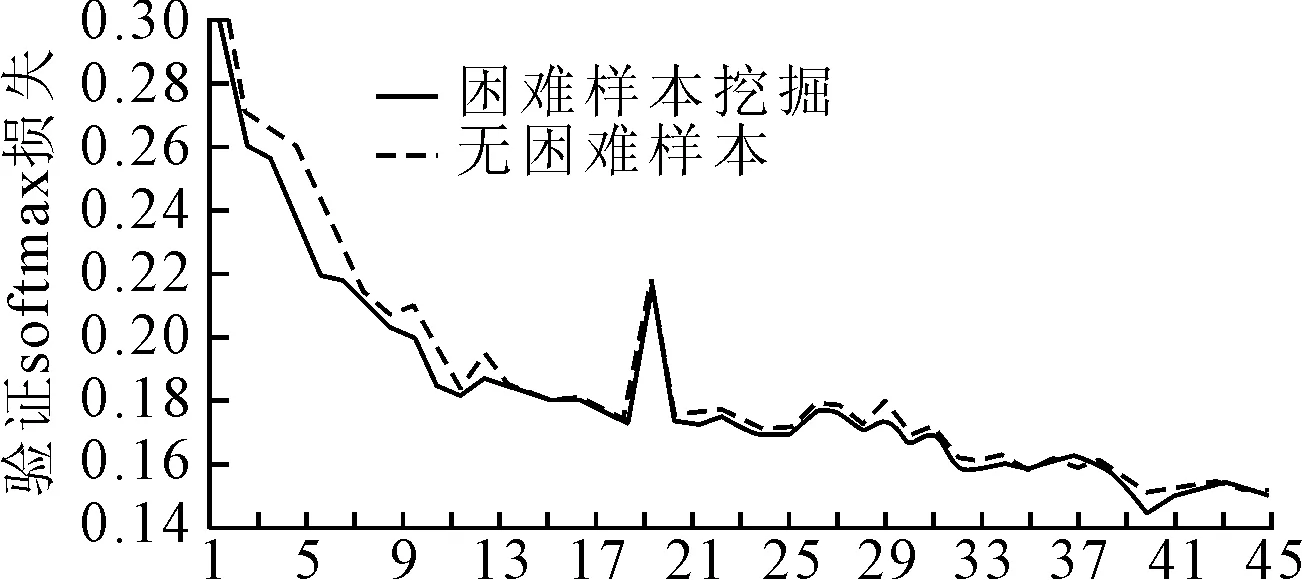
图3 损失曲线
由图3可知,OHEM损失曲线低于不使用该策略的模型,即验证了困难样本挖掘有助于提高方法的性能.
2.4 实验结果与分析
实验中所使用数据的是江苏省公安厅构建的PSD-HIGHROAD数据库作为数据集,包含了不同交通车辆在不同光照条件下大约15 000张驾驶员的图像.该数据集涵盖了江苏省大部分高速公路上的车辆图像,随机选取10 000张图像训练IMP-MTCNN模型.
不同车辆行驶过程中IMP-MTCNN与级联CNN的测试效果对比见图4.

图4 不同环境下的测试实例
由图4可知,第一列为PSD-HIGHROAD数据集中的原图,第二列为级联CNN的面部检测结果,第三列为级联CNN面部检测结果放大图,第四列为IMP-MTCNN面部检测结果,最后一列为IMP-MTCNN面部检测结果放大图.IMP-MTCNN不管是在白天还是黑夜都能很准确地检测到驾驶员的脸部并且精确定位出面部关键点,相比于级联CNN,本文的IMP-MTCNN有着更高的精确度以及更低的误检率,在复杂的驾驶环境中能够保持良好的性能.
IMP-MTCNN与原始MTCNN、YOLOv3、级联CNN和联合级联的检测性能见表3.
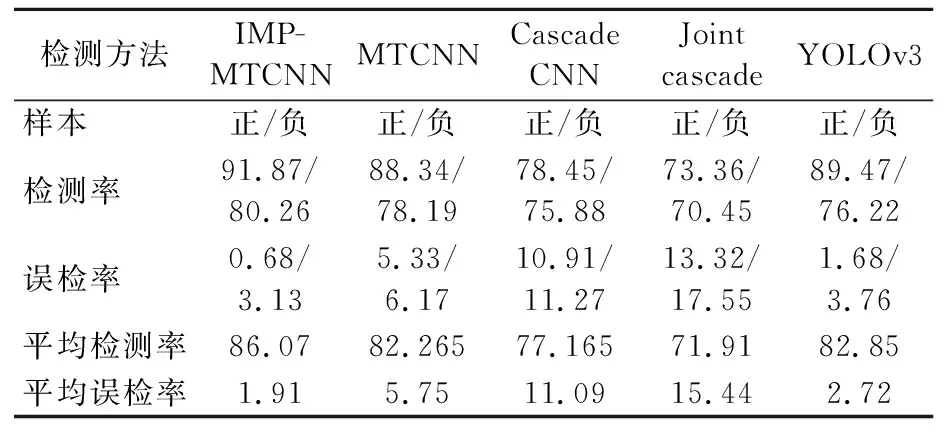
表3 检测性能比较 单位:%
由表3可知:IMP-MTCNN模型在正样本上的检测精确度达到了91.87%,负样本上为80.26%,均比原始MTCNN、YOLOv3 等方法的检测精确度高.并且 IMP-MTCNN平均误检率仅为1.91%,与其他几种方法相比,误检率明显降低.
3 基于FSR-Net的多任务疲劳状态检测
3.1 VGG网络
VGG网络是由牛津大学计算机视觉组(visual geometry group)与Google DeepMind公司共同研发出来的一种新的深度卷积神经网络.VGG网络是一个16~19层深的卷积神经网络,深层的结构使得网络性能大幅提高,同时拓展性、泛化性也非常好,适合用来提取图像特征.
VGG结构简单,由五个卷积层和池化层的组合、三层全连接层、一个Softmax输出层构成,所有隐层都采用非线性修正ReLU激活函数.输入为224×224的RGB图像,唯一做的预处理是归一化处理,再经过5层卷积层,卷积层中卷积核的大小为3×3,部分卷积核为1×1,卷积层步长设为一个像素.每个卷积层后都有一个池化层,池化窗口大小为2×2,步长为2.接着是三个全连接层,通道数分别为4 096,4 096,1 000.最后一层是用来分类的softmax层.
VGG网络具有小卷积和深网络的特点,这样使用参数的减少了,同时还产生更丰富的非线性映射.训练时,先训练级别简单,层数较少的VGG的A级网络,再初始化后面的复杂模型,加快了训练的收敛速度,同时采用多尺度的方法,增加了训练数据,提高了准确率.
3.2 改进的多任务疲劳状态检测网络FSR-Net
为了更准确地判断驾驶员是否疲劳驾驶,通过对VGG的网络结构进行改进,设计了一种多任务卷积神经网络结构FSR-Net,见图5.

图5 FSR-Net网络结构示意图
构造的FSR-Net网络模型是一个9层的大型总面积神经网络,由三个SE_module模块、一个卷积层、一个最大池化层、一个全局平均池化层、两个全连接层、一个多任务输出层组成.在卷积层结构中连续插入了三个SE模块,从空间维度上简化网络学习,对特征通道之间的内在联系进行建模,自适应地重新校准通道方向的相应特征,从而提升了网络性能.
FSR-Net网络模型中,相关参数见表4~5.
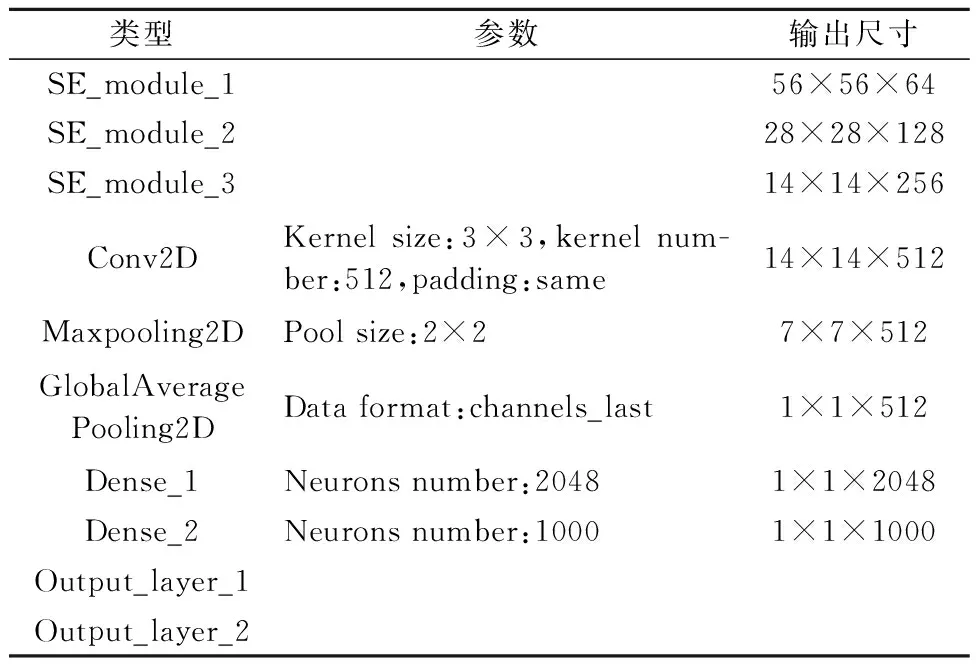
表4 FSR-Net网络层参数
在实际驾驶环境中,采集到的面部图像尺寸大小不一,先统一调尺寸为112×112,再送入到FSR-Net网络中进行检测.其中三个SE_module模块输入特征通道数分别为32、64、128,输出图像尺寸分别为56×56×64、28×28×128、14×14×256.
卷积层的卷积核为3*3,步长为1,填充方式

表5 SE_module_1网络层参数
为“SAME”,用0填充边界,输出图像尺寸为14×14×512,并将图像送入到最大池化层,pool_size为(2,2),对邻域内特征点取最大.在全局平均池化则直接把整幅特征图进行平均池化,整合全局特征,防止过拟合.经过最大池化层和全局平均池化层,输出特征图尺寸为1×1×512.两个全连接层dense_1、dense_2的节点个数分别为2 048、1 000.通过全连接,把卷积提取的局部特征重新通过权值矩阵组装成完整的图像.
3.3 多指标整合的疲劳驾驶判断
当驾驶员出现疲劳时,会出现打哈欠、眼睛长时间闭合等现象,如果单一地对眼部或嘴部进行检测出现误判的可能性较大.在检测模型中同时对眼睛和嘴巴进行多指标检测,将大大提高检测的精度.
3.3.1眼部疲劳状态判断
目前权威的疲劳驾驶判断指标为美国联邦公路管理局和美国国家公路交通安全管理局提出的PERCLOS(眼睑闭合度).
当人出现疲劳时,眨眼频率会增加,通过驾驶员眼睛闭合帧数占总帧数的比例来近似计算PERCLOS,为
(3)
正常状态下,Ep值在(0~0.15),当Ep>0.4时,表示该驾驶员当前已经是疲劳状态.
人在疲劳状态时,除了眨眼频率增加,闭眼时间也会延长,持续闭眼时间也可以作为疲劳驾驶的判断指标.对连续帧图像中眼部状态进行识别分类,当识别结果为闭合时,记录此时帧图像的序列号为F0,统计眼睛持续闭合帧数,直到眼睛睁开,T0表示采集每一帧图像所占的时间间隔.持续闭眼时间定义为
ET=(Fn-F0)×T0
(4)
正常人平均每次眨眼时间为0.2~0.4 s,若闭眼时间超过1 s,无论是否疲劳都属于危险驾驶.本研究将Ep阈值设为1 s.
将眨眼频率和持续闭眼时间同时作为判断指标,能有效减少误判.
3.3.2嘴部疲劳状态判断
人处在疲劳状态时,还会伴随着打哈欠,因此对嘴部状态的检查也是判断疲劳驾驶的有效补充.
驾驶员在说话时,嘴巴的状态也是不断变化的,但是张合的时间不像打哈欠那样持续较长,有关研究表明,一次打哈欠的时间大约为3 s.通过选取嘴部持续张开时间能很好地与说话状态分开.嘴部的持续张开时间的定义为
MT=(MN-M0)×T0
(5)
式中:M0为嘴部持续张开帧的首位图像帧序列号;MN为持续帧数;T0为每一帧图像的时间间隔.若持续时间超过3 s则此时为打哈欠状态.当人疲劳时,会持续打哈欠,根据某段时间内打哈欠的次数可以判断疲劳状态.研究中,选取2 min作为检测时长,在某时间段内打哈欠次数Nyawn大于3,则判断驾驶员为疲劳状态.
3.4 FSR-Net实验及结果
实验数据集来自公开的YawDD[13]视频,包含不同性别、不同种族的驾驶员在不同光照环境下拍摄的驾驶视频.通过将选取的视频数据集转换成帧图像,利用IMP-MTCNN算法检测出人脸,并截取驾驶员的面部图像,制成包含46 652张面部图像的数据集.在训练过程中,将数据集按比例分成包含40 909张图像的训练集,包含4 730张图像的测试集,以及包含1 013张图像的验证集.训练采用小批量梯度下降的方式,以keras的ReduceLROnPlateau学习率适应方法,初始学习率设置为0.01,若数据无进步,自动减少学习率,学习率的下边界设置为0.000 01.训练结果见图6~7.
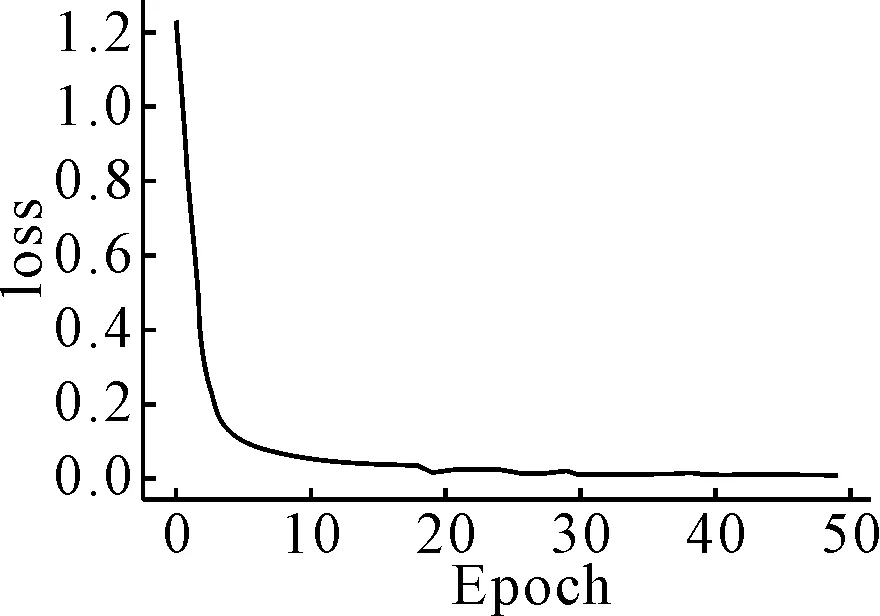
图6 训练损失曲线
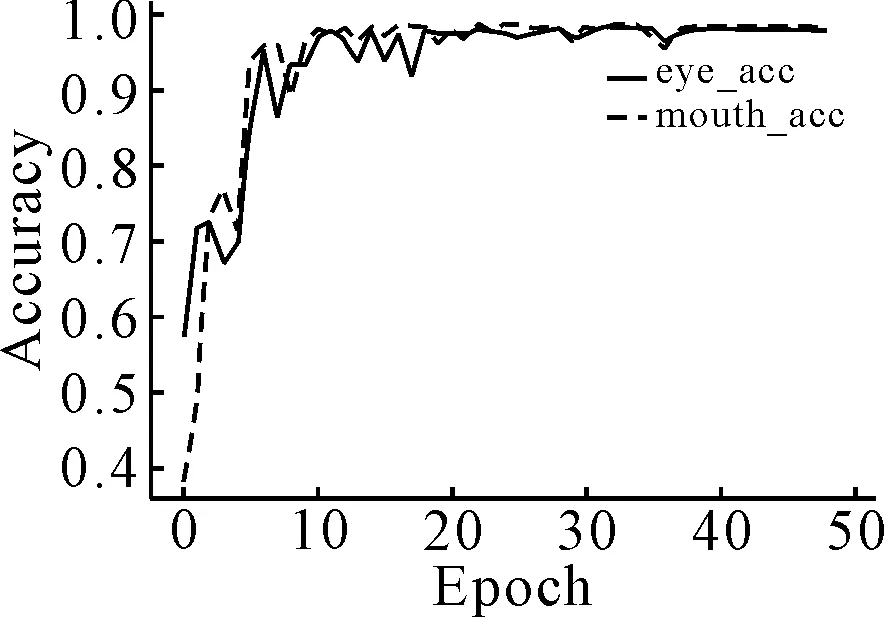
图7 准确率曲线
由图5可知,在训练开始阶段损失值下降幅度很大,说明学习率合适且进行梯度下降过程,在学习到一定阶段后,损失曲线趋于平稳.由图6可知,随着时间推移,眼睛和嘴巴的识别准确度在上升,达到一定程度后,两者准确度相差不大,说明模型状况良好.
利用设计的FSR-Net网络及疲劳驾驶判断指标,对YawDD中六段视频进行了测试,测试结果见表6.
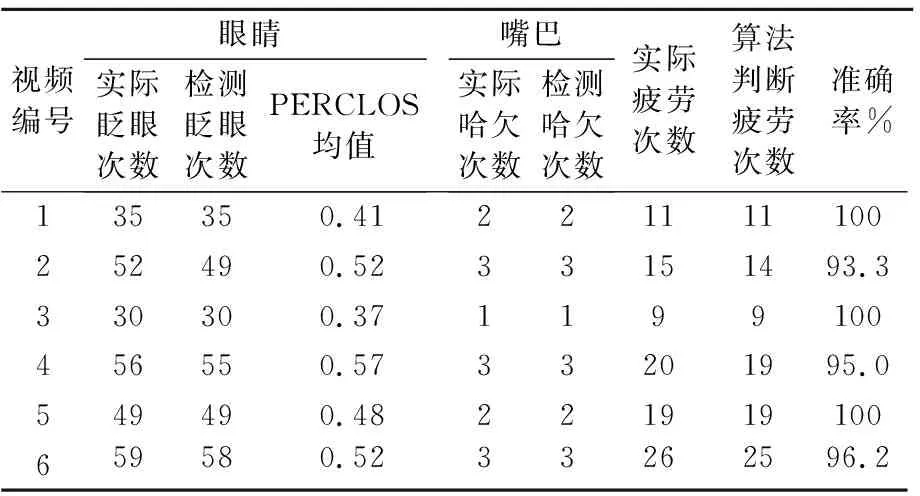
表6 疲劳驾驶判断算法测试结果
测试结果最终的判断准确率达到了97.4%,实验结果表明,基于FSR-Net网络以及疲劳驾驶判断指标,针对复杂多变的实际驾驶环境也有着较高的疲劳检出率.
4 结 束 语
针对在光照不好的条件下面部图像对比度低、ISO噪声高的问题,采用生成对抗网络EnhenceGAN对图像进行弱光增强,从而获取到较清晰的面部图像.提出了一个改进的正则化算法的多任务级联卷积神经网络IMP-MTCNN,解决了面部检测速度慢以及关键点定位不准确的问题.提出一种基于VGG网络改进的多任务疲劳状态识别网络FSR-Net,同时对眼部和嘴部状态进行检测,实现多任务分类,解决了单特征检测率低以及多个神经网络检测多个面部特征效率低的问题.提高了检测的精确度,但是由于实际驾驶场景复杂多变,存在着驾驶员戴口罩及墨镜等面部遮挡、IMP-MTCNN定位关键点耗时较长、公开的疲劳驾驶数据集样本较少以及缺少头部姿态和眼睛视线等更多的疲劳指标等实际情况,以及对疲劳驾驶检测算法的优化,是后续研究的重点.
猜你喜欢
核安全(2022年3期)2022-06-29
北京大学学报(自然科学版)(2022年1期)2022-02-21
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
中国生物医学工程学报(2019年6期)2019-07-16
电子制作(2019年11期)2019-07-04
—— “T”级联
同位素(2019年1期)2019-03-14
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2016年3期)2016-08-23
系统工程与电子技术(2016年2期)2016-04-16
