
基于改进蝙蝠算法优化LSTM网络的短时客流预测
2021-12-22 08:11段中兴温倩周孟宋婕菲王剑
铁道科学与工程学报 2021年11期
段中兴,温倩,周孟,宋婕菲,王剑
(1. 西安建筑科技大学信息与控制工程学院,陕西西安 710055;2. 西部绿色建筑国家重点实验室,陕西西安 710055)
随着社会经济的快速发展,我国城市轨道交通已进入快速发展期[1],地铁成为人们出行的主要方式之一。通风空调系统是地铁能够正常运行的必要设备,而每年通风空调系统的运营能耗占总能耗的1/3。客流预测是影响地铁通风空调系统能耗的一个重要因素,不准确的客流预测将使地铁产生大量不必要的能耗,因此对客流进行精确预测在降低地铁的运营能耗中具有极其重要的意义。目前,城市轨道交通短时客流量预测方法主要有:1) 概率估计,如马尔科夫链[2];2) 数理统计模型,如灰色模型[3]、卡尔曼滤波[4];3)机器学习,如支持向量机[5-6]、神经网络[7];4)组合模型,如深度信念网络(DBN)与极限学习机的组合[8]、自回归差分移动平均模型与广义自回归条件异方差模型的组合[9]、DBN 与多模式深度融合组合[10]。概率估计适用于随机现象的数学模型,不能准确有效地进行客流量预测;数理统计模型对中长期的客流变化有较好的刻画,但对特点明显的短时客流量局限性较强;机器学习的数据种类多样,对同一问题有不同的建模方式,可以从大量历史数据中找出隐含的规律,自动学习反应数据差别的特征,用于预测或分类,可以实现机器学习的深度学习算法,具有更深的层次。由于机器学习模型的优越性,越来越多的模型被应用在客流量预测中,长短期记忆网络(Long Short-term Memory, LSTM)即为其中之一。蒲悦逸等[11]将卷积神经网络和LSTM集成在一起,并通过在卷积神经网络中加入残差神经元的方式提高了预测准确性;李梅等[12]利用皮尔森相关分析提取客流的影响因子,建立LSTM预测模型,指出LSTM网络在短时客流量预测中具有更高的准确性。单一LSTM网络的参数对其训练结果有很大的影响,组合模型反而能结合单一模型的优势,进一步提高预测精度。由于LSTM在长期依赖性的信息中有良好的学习效果,因此,本文构建蝙蝠算法与长短期记忆结合的IBA-LSTM 模型对地铁站短时客流量进行预测,利用蝙蝠算法在寻优时的优势,对LSTM 网络的隐含层节点数、迭代次数、初始学习率、学习率下降因子4个参数进行优化,同时采用反向学习、动态自适应惯性权重与拉格朗日插值法对蝙蝠算法进行改进,平衡全局探索与局部搜索,提高搜索速度与精度,有效降低模型参数对预测精度的影响,减少预测误差。
1 LSTM网络
LSTM 是递归神经网络(Recursive Neural Network,RNN)的一种特殊实现,由于RNN 在反向传播期间容易产生梯度消失,因而对其隐含层进行改进,并在RNN 神经网络的基础上引入了时序的概念,使得上一刻的输出能对下一刻的输入产生直接影响,得到了在处理和预测具有较长间隔和延迟事件的时间序列方面应用效果显著[12]的LSTM网络。
LSTM 相较于RNN 增加了遗忘门ft,输入门it和输出门ot,通过门的控制对细胞状态ct添加或删除信息,让信息有选择性的通过,使相关信息在序列中传递下去,因而早期时间步长的信息也能携带到后期时间步长的细胞中去。原理图如图1所示。
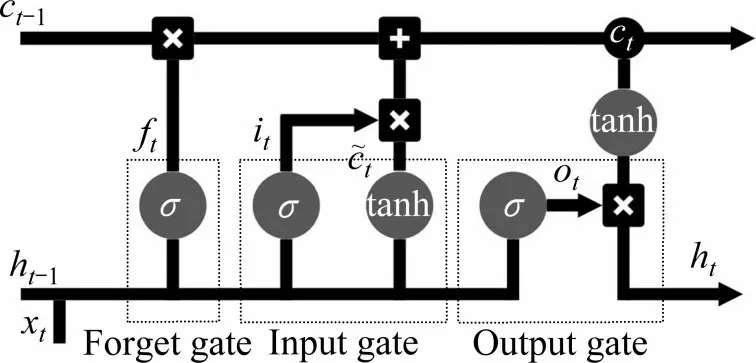
图1 LSTM原理Fig.1 LSTM schematic
遗忘门可以决定丢弃或保留哪些信息。通过读取前一个隐藏层状态ht-1与当前的输入xt,输出一个介于0-1之间的值给细胞状态ct-1中的信息,1表示“完全保留”,0表示“完全舍弃”。表示为:
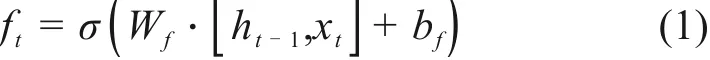
输入门的作用是更新细胞状态并创造新的候选值向量,确定保存哪些信息到新状态。将输入传递到sigmoid 层中来决定要更新哪些信息;其次将这2个信息传递到tanh层中,创造一个新的候选细胞信息,最终将2层的输出逐点相乘再与前一细胞状态与输出门输出逐点相乘后的向量逐点相加,得到更新后的细胞状态ct。

输出门确定下一个隐藏层状态的值。根据输入经过sigmoid 层判断细胞状态中哪些信息被输出,同时细胞状态经过tanh 层进行运算,最终将输出门的输出ot与运算后的细胞状态逐点相乘得到网络输出ht。表示为:

式(1)~(6)中:σ为sigmoid 激活函数,tanh 为双曲正切函数,Wf,Wi,We,Wo是遗忘门、输入门、细胞状态单元(CEC)与输出门的权重矩阵;bf,bi,be,bo是遗忘门、输入门、CEC 与输出门的偏差向量。
已有研究表明,LSTM 的隐含层节点数H,迭代次数N,初始学习率lr和学习率下降因子decay对预测结果影响较大,而蝙蝠算法相较于其他群体智能算法在寻优过程中有较好的表现。因此拟采用蝙蝠算法对LSTM 的H,N,lr和decay4 个参数进行优化。
2 蝙蝠算法的改进
2.1 蝙蝠算法
蝙蝠算法是YANG[13]于2010 年提出的一种新型智能群体算法,该算法是在理想状态下,通过改变蝙蝠在觅食时所发出的频率f,响度Ai,脉冲发射率ri对猎物或障碍物进行定位而成功猎取食物。即所有蝙蝠都用回声定位来感知距离并“知道”食物障碍之间的差异,每个蝙蝠在位置xi有随机的飞行速度vi,同时具有不同的频率、响度和脉冲发射率。蝙蝠狩猎和发现猎物时,它通过改变频率、响度和脉冲发射率,选择最佳解,直到目标停止或条件得到满足。
在蝙蝠算法的模拟过程中,频率根据目标猎物的大小而变化,从而影响波长λ的大小,波长的范围与猎物的大小范围一致。对于在位置xi以速度vi飞行的蝙蝠,在D维空间中,第i只蝙蝠在t时刻的位置xti与速度vti为:

式中:β∈[-1,1]是一个随机向量,x*是t时刻的全局最优解。在局部搜索时,一旦在当前最佳解中选择一个解,将采用随机游走的方式生成新的局部解:

式中:ε∈[-1,1]是一个随机数,At是同一代的整个群体的平均响度。

式中:α∈(0,1),为声波响度衰减系数;γ> 0,为脉冲频度增强系数;r0i为蝙蝠i的初始脉冲频率。当且仅当蝙蝠的位置被优化后,脉冲的响度和频度才会更新,表示蝙蝠正在朝最佳位置移动。
2.2 改进蝙蝠算法
蝙蝠算法有良好的优化能力,但由于其采用随机方法生成初始种群,种群多样性较差,存在易早熟、易陷入局部最优值的问题。因而提出新的改进蝙蝠算法IBA,增加种群多样性,平衡蝙蝠的全局搜索与局部探索能力,使其不易陷入局部最优值,增强算法性能。

图2 IBA-LSTM算法流程Fig.2 IBA-LSTM algorithm flow
2.2.1 反向学习
反向学习中提出反向解来对应原始解,从不同的方向进行探索,Tizhoosh 在文献[14]中给出了反向学习的定义:
若P(x1,x2,…,xn)是n维空间中的一点,x1,…,xn且xi∈[ai,bi],则xi的反向解为:

将反向学习运用在蝙蝠算法中,P(x1,…,xn)被看作蝙蝠位置,比较原蝙蝠位置与反向解的目标函数,若反向解的目标函数值优于原蝙蝠位置的目标函数值,则用反向解的位置代替原蝙蝠位置,反之,继续学习原蝙蝠位置。增加反向解,增加了种群的多样性,使种群不易陷入局部最优。
2.2.2 动态自适应惯性权重
由公式(8)可以看出,在探索过程中,基本算法的探索速度系数始终为1,大大降低了种群多样性与个体灵活性,极易导致算法在全局搜索与局部探索的不平衡。针对这一问题,引入定义的聚焦距离,通过聚焦距离变化率判断此次搜索蝙蝠应提高全局还是局部搜索能力,从而动态自适应地调整惯性权重。聚焦距离定义为:

其中:D为蝙蝠维数,n为种群个数,通过每次迭代时的聚焦距离变化率,由此判断本次粒子应提高全局搜索能力还是局部搜索能力,调整惯性权重。
惯性权重ω为:
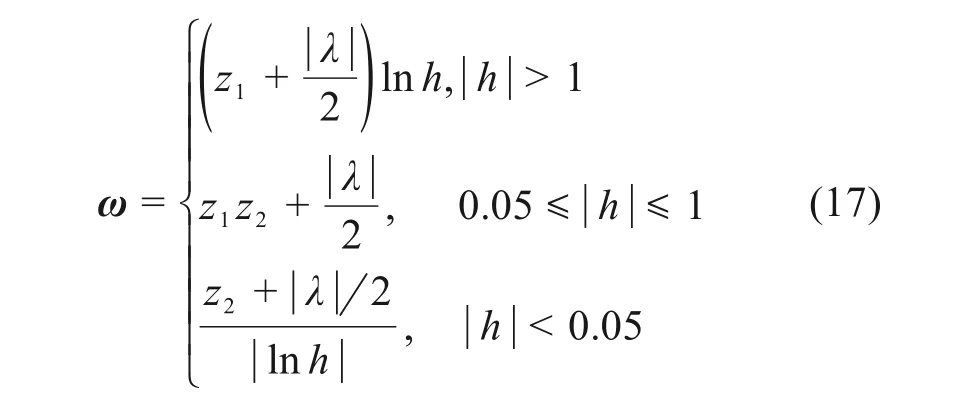
式中:z1= 0.3,z2= 0.2;λ为[0,1]间均匀分布的随机数。当聚焦距离变化率较大时,蝙蝠的全局搜索能力较差,因而增加惯性权重,蝙蝠可以以较大的飞行速度找到全局最优解的范围,提高蝙蝠在全局搜索阶段的能力;当聚焦距离变化率较小时,减小惯性权重,蝙蝠的飞行速度也随之减小,使蝙蝠在局部探索期间能够进行精确探索。动态自适应惯性权重的引入很好地平衡了蝙蝠的全局搜索和局部探索能力,有利于蝙蝠种群较好地适应环境,提高寻优效率。
2.2.3 拉格朗日插值法
为加快收敛速度、提高局部搜索的能力,采用拉格朗日插值法,模拟多项式,n阶拉格朗日插值公式为:
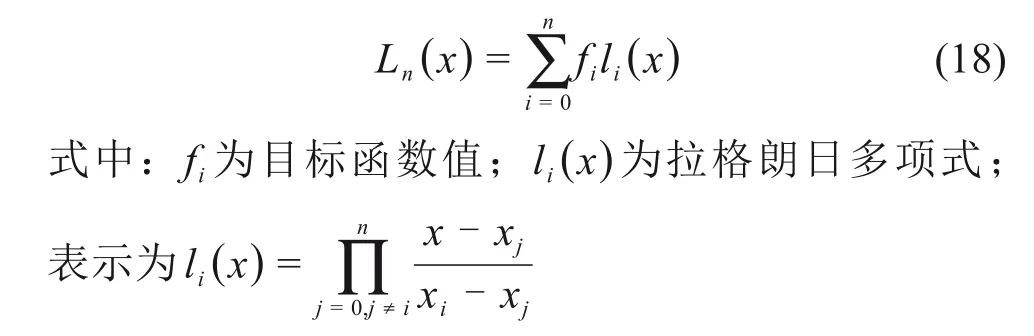
对于全局最优解gbest的第j维,选择3 个点来生成信息并执行拉格朗日插值,一个为现有的全局最优解,其余为最优解附近的扰动,其关系为:

式中:v(i,j)为每次迭代目标函数最优的蝙蝠速度,η= 0.5/n,n为种群数,在第j维空间中,x0,x1,x2可以通过拉格朗日插值方法生成抛物线,由此得到最小值,比较最小值处与当前最优解处的目标函数值,更新位置信息。拉格朗日插值计算公式为:

3 实验分析
3.1 实验数据
为验证算法与模型的有效性,本文选用西安某地铁站自动检票系统(Automatic ticket checking system,AFC)的刷卡数据作为样本进行客流量预测模型验证。实验采用具有完整工作日与非工作日的2 周作为实验时间,有效客流时间为6:00~23:00。同时,为体现客流量变化趋势及工作日与非工作日客流量差异,本文随机对1周的客流量分别采用5,10,20 和30 min 4 种不同时间粒度进行统计,结果如图3所示。
从图3中可以看出,不同时间粒度下的地铁站客流量数据特点较为明显,均呈现非线性变化趋势;且时间粒度越大,变化曲线趋于平缓,表明数据具有较强的随机性。工作日的一般高峰时间段出现在早上8:00~9:00 与下午17:30~18:30,而非工作日客流量无明显早晚高峰,客流量分布较为均匀,因而数据具有较强的周期性。此外,为进一步确定工作日与非工作日的相关性,对其数据进行Pearson相关性分析,结果如表1~2所示。

图3 地铁站不同时间粒度的客流量Fig.3 Passenger flow of subway station with different time granularity
Pearson系数超过0.85以上为高度相关,由表1与表2可知,工作日的数据间与非工作日的数据间相关性通过显著性检验,因此以5 min 为间隔对工作日与非工作日分别进行预测。
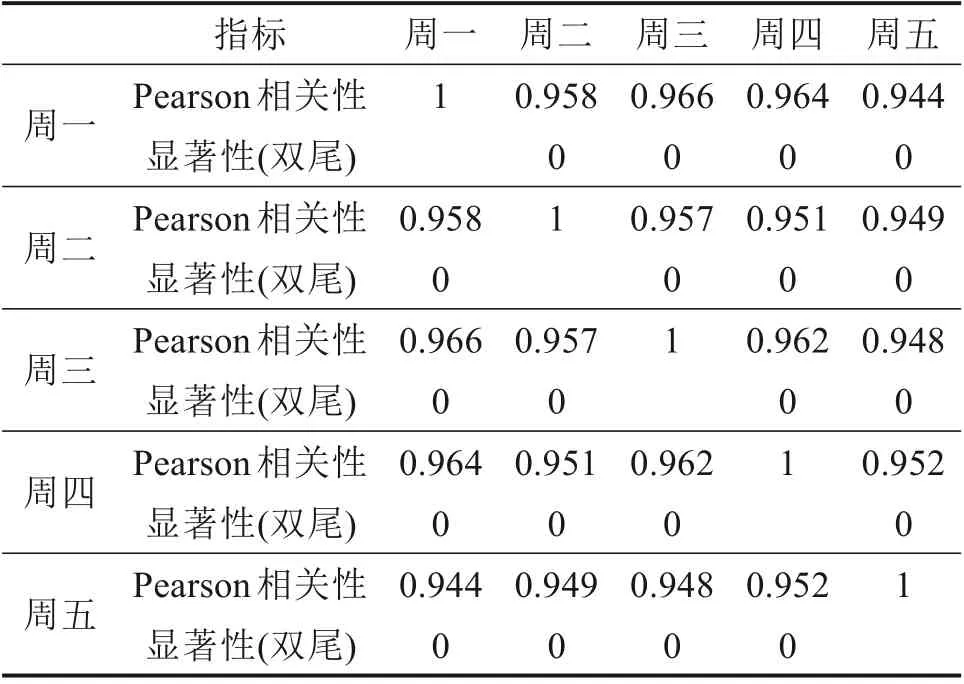
表1 工作日数据相关性统计Table 1 Working days data correlation statistics

表2 非工作日数据相关性统计Table 2 Non-working days data correlation statistics
3.2 数据预处理
对于2 类数据集,工作日选取1 938 组数据作为训练集,非工作日选取714 组数据作为训练集,均选取102 组数据作为测试集。由于数据相差较大,对预测结果有一定的影响,因此对客流数据进行预处理,采用Z-score方法对数据进行归一化:

式中:μ为所有样本数据的均值;σ为所有样本数据的标准差。
3.3 结果分析
IBA的编码结果会随着样本的大小而改变,对于时间粒度为5 min 时的样本,经重复实验,得到IBA 的最大迭代次数为100,种群数为20 时所得到的隐含层节点数、训练次数、初始学习率、学习率下降系数在LSTM模型中预测精度最高,最终选取算法的最大迭代次数为100,种群数为20,编码下限为[10,10,0.000 1,0.1],编码上限为[100,200,0.01,0.4]。对客流量进行训练预测后,得到不同模型的预测结果如图4~5所示。

图4 工作日预测结果对比Fig.4 Comparison of predicted results in working days
同时,为了更好地对比不同模型的预测效果,选取均方根误差(RMSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)作为模型的评价指标,反映预测值与真实值之间的误差大小。
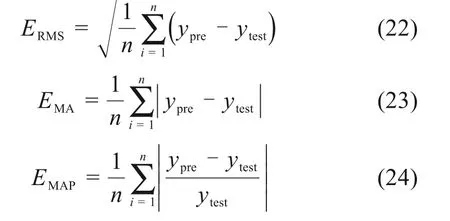
式中:ypre,ytest分别为预测值与真值。评价结果如表3所示。
由表3 可以看出,IBA-LSTM 在RMSE,MAE与MAPE 上均优于其他4 个模型。在5 种模型中,由于BP 模型与其组合模型在进行预测时可能会出现梯度消失的问题导致模型的性能变差,难以获得最优模型;文章提出的LSTM模型对时间序列问题的预测有很好的效果,而短时客流量预测正是一种时间序列预测,同时考虑到LSTM在其中的广泛使用,因此加入了带有反向学习、动态自适应惯性权重与拉格朗日插值法的蝙蝠算法对其进行寻优,提高了LSTM预测模型的精度。

图5 非工作日预测结果对比Fig.5 Comparison of predicted results in non-working days

表3 预测模型性能评价Table 3 Predictive model performance evaluation
4 结论
1) 针对地铁站客流数据非线性、随机性的特点,提出了基于改进蝙蝠算法优化长短期记忆神经网络的短时客流量预测模型(IBA-LSTM),克服了传统预测模型对非线性、随机性的客流数据处理效果不佳的问题。
2) 利用反向学习、动态自适应惯性权重与拉格朗日插值法改进BA,增加了种群多样性,改进了蝙蝠全局与局部搜索能力,加快收敛速度。
3) 利用IBA 对LSTM 的隐含层节点数、训练次数、初始学习率、学习率下降系数进行优化使模型对短时客流量预测有更好的预测效果,对比BA-LSTM,LSTM,BP及BP-Adaboost精度更高。
4) 在以后的研究中,可深入探究节假日、天气等因素对客流量的影响,并建立多因素约束的模型进行预测,以提高模型在多因素影响下的预测精度和泛化能力。
猜你喜欢
环球时报(2022-12-12)2022-12-12
现代电子技术(2021年15期)2021-08-06
科学家(2021年24期)2021-04-25
大连交通大学学报(2020年5期)2020-10-17
数学大王·中高年级(2019年5期)2019-06-09
智富时代(2018年7期)2018-09-03
智富时代(2018年7期)2018-09-03
湖北函授大学学报(2018年6期)2018-05-23
理论观察(2018年1期)2018-03-24
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
