
改进LeNet-5网络模型图像分类
2021-12-22 13:28:46谢沛松胡黄水张金栋
长春工业大学学报 2021年5期
谢沛松,胡黄水,张金栋
(长春工业大学 计算机科学与工程学院,吉林 长春 130012)
0 引 言
目前,图像分类广泛应用于医学图像、人脸识别[1]、交通车牌识别等领域[2]。因此,准确的图像分类方法成为图像处理方面的研究热点。传统机器学习如最小距离分类方法简单却适应性差,支持向量机分类法泛化能力好却只适合小数据量样本,K最优近邻算法无需参数估计和训练,但依然只应用于数据量小模型。随着信息技术的发展,深度学习逐渐用于海量数据时的图像分类[3]。
自2012年Krizhevsky A等[4]在ILSVRC大赛中提出AlexNet经典模型,人工神经网络(ANN)再次走进人们视野,深度学习开始广泛用于图像分类,并获得超越以往算法的成绩后,在AlexNet模型中大量使用卷积池化,增加了网络特征,并采用Relu[5]函数作为激活函数。文献[6]提出GoogLeNet网络模型,其中提出Inception V1结构模型用不同尺寸的卷积核提取特征,增加了特征提取宽度,提高了模型预测率。而后为了克服参数过大,提出了Inception V2[7]、Inception V3[8]结构。Lecun Y等[9]第一次用LeNet-5实现了手写数字的分类,近年来,LeNet-5被多次改进应用于多个领域,而且取得良好效果。文献[10]对LeNet-5网络的框架调整,增加了卷积层和池化层的个数,调整网络内部参数,在人脸表情识别上取得较好成绩。文献[11]提出把Inception V1模块嵌入LeNet-5网络中,加大提取图像的多尺度特征,引入跨连思想,充分利用低层次特征,在复杂纹理图像中具有良好的分类能力。文献[12]在识别形状类似物体时提出将LeNet-5卷积层改变为双层非对称卷积,降低提取特征的参数,采取全局平均池化替换Flatten层,能快速收敛且各项指标均优于原网络。LeNet-5存在网络训练参数大、准确率不够高、容易过拟合等问题,因此文中提出一种改进LeNet-5的图像分类方法ILIC(Improved LeNet-5 model for Images Classification),在降低参数与过拟合的同时提升分类准确率,比较不同batch_size大小模型准确率,调试出最佳模型。
1 LeNet-5网络模型
LeNet-5模型是Lecun Y等[9]提出的经典CNN模型,早期,美国大多数银行都采用LeNet-5模型识别支票上的手写数字,其准确性非常好。LeNet-5模型结合了特征提取和图像识别。这是一个自学习过程,包括集成学习、反向传播和选择优化,经典的LeNet-5卷积网络由一个输入层、两个卷积层、两个池化层、两个全连接层和一个输出层组成。
传统的LeNet-5网络中,卷积层C1输入图像尺寸32*32,经过一个步长为2的5*5卷积核,尺寸变为28*28,且featuer maps为6,卷积层计算过程
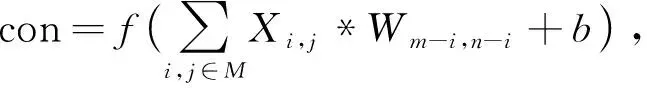
(1)
式中:X——输入需要卷积的M区域元素;
i,j——位置坐标;
W——卷积核元素;
m,n——卷积核尺寸;
b——偏移量;
f(*)——sigmod激活函数。
然后池化层S2的feature maps从6*28*28经过2*2尺寸最大池化层变为6*14*14,特征图大小减半,即得到最大池化,池化层计算过程为
pool=D(max(Yi,j)),i,j∈p,
(2)
式中:Y——池化区域p中的元素;
i,j——元素坐标;
D(*)——下采样。
卷积层C3、池化层S4重复上述操作,得到16*5*5的feature maps,再执行一次卷积核大小5*5,步长为1的卷积操作,得到1*120全连接层,最后连接1*84全连接层、1*10输出层。
2 ILIC的图像分类
针对LeNet-5网络参数过多、识别图像准确率低等缺点,提出在传统模型的基础上,添加Inception V1模块,增加网络特征提取宽度。为了降低模型参数,能在计算机资源占用量小的情况下实现网络训练,提出使用连续非对称卷积代替传统的大尺度卷积核,增加卷积核数量(fliter),并去掉最后的两层全连接层,卷积层激活函数改为Relu函数,使网络更加有效率地梯度下降以及反向传播,避免了梯度爆炸和梯度消失问题,文中改进网络的训练模型如图1所示。
对输入28*28图片分别进行卷积核大小为5*1、1*5的连续非对称卷积提取图像低维特征,其中步长(strides)为1,卷积核数量(fliters)为24,得到24*24*24的特征图;然后经过BN层批量标准化数据,特征图大小不改变;再通过最大池化层(Maxpool),poo_size为(2,2),strides设置为2,特征图大小减半为24*12*12;Inception V1模块设置每个通道卷积核数量为16,则输出特征图为64*12*12;再次经过5*1、1*5连续非对称卷积,其中步长(strides)为1,卷积核数量(fliters)为48,得到48*8*8的特征图;又经过BN层批量归一化数据;再经过最大池化层(Maxpool),参数设置同第一次,得到48*4*4的特征图;Flatten层将数据打平变成一维786*1,最后通过全连接层Softmax函数分类输出,选择交叉熵作分类器的损失函数改进网络参数[13-14],此次实验仿真里ILIC网络模型最终训练参数42 254,对比于原LeNet-5网络模型训练参数44 426,减少了训练参数,ILIC模型参数见表1。
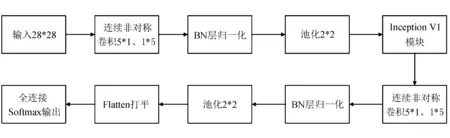
图1 改进的LeNet-5模型

表1 ILIC模型参数
2.1 改进后算法实现
整个网络训练分为前向传播与反向传播两个过程,其中,前向传播通过人工神经网络对特征进行提取,反向传播根据交叉损失熵大小不断调整参数,直到模型收敛。
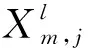

f(·)——Relu激活函数;

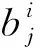
downσ,τ(·)——采样窗口大小为σ*τ的下采样;

O——输出层。
其中FilterConcat(·)连接Incepetion V1模块中的四个通道,在程序上使用tf.concat将其在第三维度上合并。
Softmax函数的本质是将一个K维的任意实数向量压缩(映射)成另一个K维的实数向量,其中向量中的每个元素取值都介于(0,1)之间,而且所有元素之和为1,计算公式为
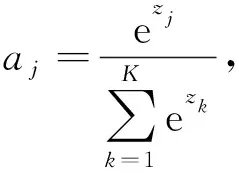
(4)
式中:j——输出类别,j=1,2,…,K。
再对Softmax函数求导
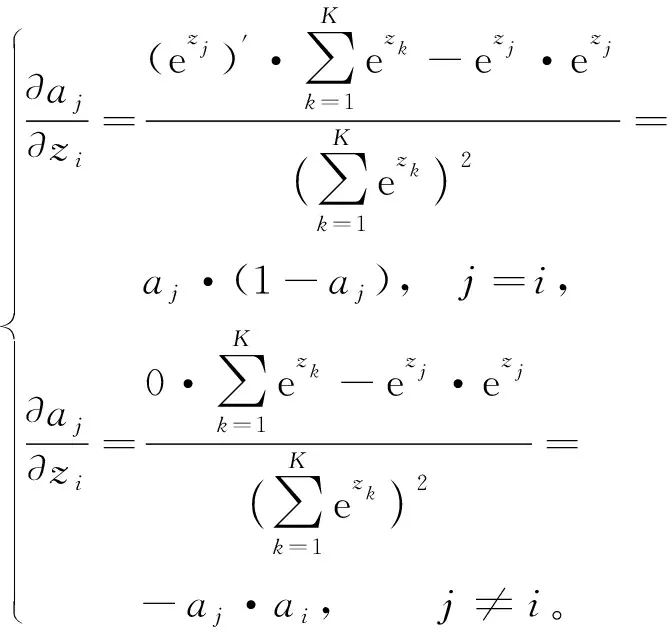
(5)
反向传播算法的参数更新采用随机梯度下降法(Stochastic Gradient Descent, SGD),文中利用多元交叉熵损失函数来评价模型的预测值与真实值的差距
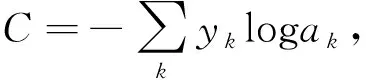
(6)
式中:y——实际标签;
a——预测输出。
计算参数wj,bj的梯度,设zj=xj·wj+bj表示某神经元的输入值,由下式分别对损失函数中权值与偏置值求偏导,
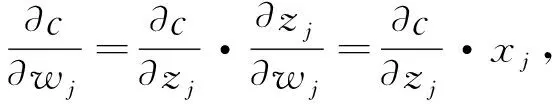
(7)

(8)
那么由式(5)可得
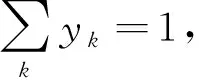

(10)

(11)
最后由如下公式对每一层wj,bj进行权值更新:

(12)
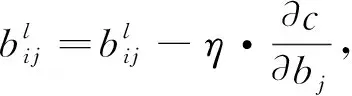
(13)
式中:η——学习率,一般取0.001,用来控制更新步长,通过不断更新wj,bj值,最后使模型收敛达到最优。
2.2 批量标准化
批量标准化(Batch Normalization)[6]是指在网络训练中对每个Batch_size里的数据归一化至均值为0、方差为1。不仅可加速网络收敛速度,还可使用较大的学习率来训练网络,改善梯度弥散,提高网络的泛化能力,BN层应加在卷积层后面和激活函数前面。设某Batch_size里数据为X={x1,x2,…,xm},那么数据的均值
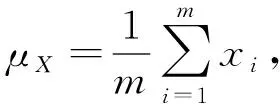
(14)
其中,xi表示X中第i个数据,计算X方差公式

(15)

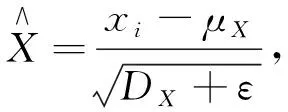
(16)
式中:ε——微小的常数,作用是防止分母为零。
再进行尺度缩放与偏移操作
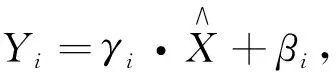
(17)
这样可以变换回原始分布,实现恒等变换,Yi就是网络的最终输出。
2.3 连续非对称卷积
对于传统的大卷积核,虽然可以获得更大的感受野、更多的特征提取,但是也会相应带来更多网络参数,在小分辨率图像中可以使用连续非对称的卷积核替换传统卷积核,能拥有更深层网络且有更多非线性变换降低过拟合,还能大量减少网络参数[11]。
连续非对称卷积原理如图2所示。
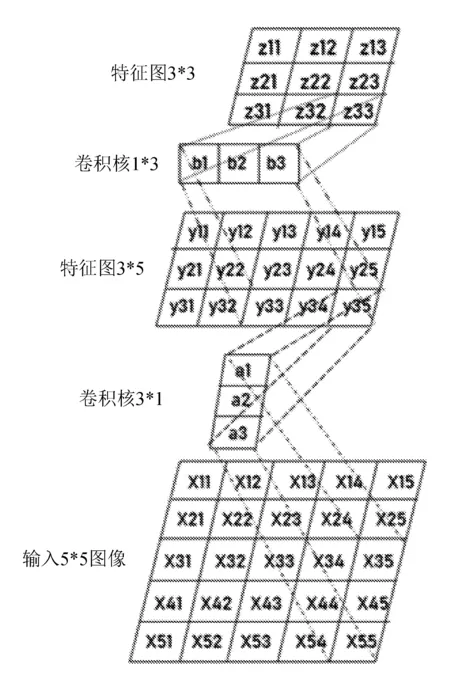
图2 连续非对称卷积原理图
对于输入5*5图像进行3*1卷积,如果padding参数选用vaild,那么卷积运算次数为45,得到特征图3*5。再对其进行卷积核1*3的卷积运算,运算次数为27,得到特征图3*3。总共运算次数为72,则连续非对称卷积相比原来3*3卷积核的运算次数81次减少了9次。当卷积核越大,减少的次数越多。如果以1*n、n*1卷积核来代替n*n卷积核,实现一组卷积,分别需要2*n、n*n次运算,那么连续非对称卷积运算次数为后者的2/n。
2.4 Inception模块
Inception V1模块由文献[5]首次提出,如图3所示。

图3 Inception V1模块
将1*1、3*3、5*5卷积层与3*3池化层堆叠在一起,增加了网络的宽度,也增加了网络对尺度的适应性,通过最后滤波连接获得非线性属性。但是因为5*5卷积核需要大量卷积运算,所以GoogLeNet借鉴了Network-in-Network的思想,使用1*1的卷积核实现降维操作,以此减小网络的参数量。在3*3、5*5卷积核前面、3*3池化后面加入1*1卷积核,降低了输入信道数量,能有效减小计算成本。
尽管Inception模块在后来有许多更好的变体[16],文中采用最传统的版本,原因是考虑到网络复杂度低,数据集小,在计算力充足范围内无需做出更多降维操作,以避免造成信息过多损失。
3 仿真测试
文中实验所用软件平台为Tensorflow2.0,python3.8,pycharm,硬件GPU为GTX3090,24 G。
Fashion MNIST数据集是代替MNIST手写数据集的图像数据集,其中共有10个类别,60 000张训练图,10 000张测试图,图像为28*28的灰度图像,主要图像内容为服饰、鞋子、包等,Fashion MNIST数据集图像如图4所示。
由于图片尺寸小、内容不清楚等给分类带来一定挑战,所以在每个batch_size里随机地对图像进行宽度偏移、高度偏移、水平翻转操作,增强数据特征提取多样性,并将输入除以数据集的标准差以完成标准化。

图4 Fashion MNIST数据集图像
首先对ILIC网络模型进行训练,优化器选择Adam函数,学习率设置为0.001,epoch设置100,选择交叉验证法更新网络参数,打开Tensorboard可视化,为防止过拟合,在Flatten层与输出层添加Dropout层,设置失活率为0.5。因为不同batch_size会有不同的训练速度以及训练效果,分别设置64、128、256三种批次数量,比较不同batch_size训练效果。当输入batch_size为64时,得到训练集与验证集准确率、交叉损失熵如图5所示。
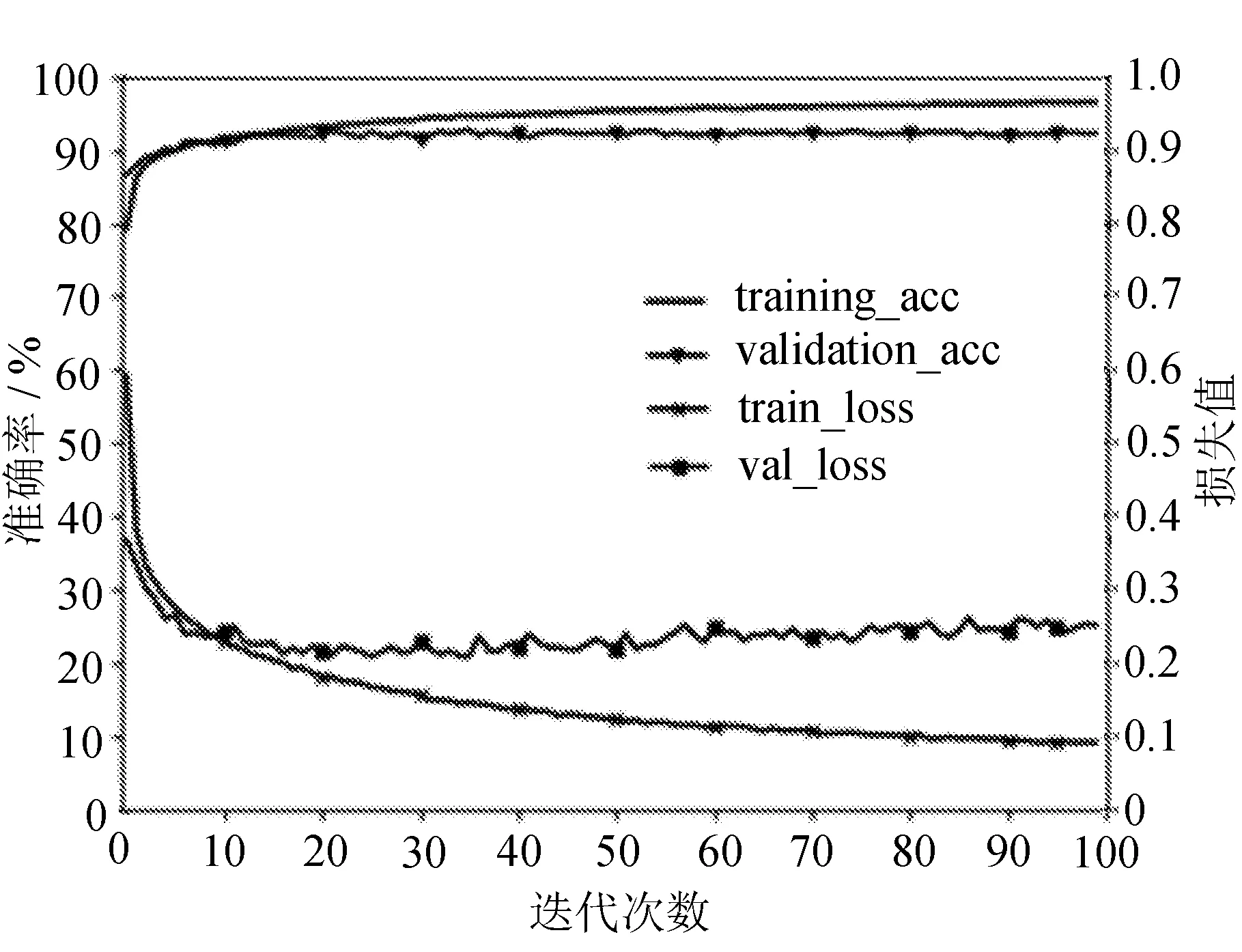
图5 ILIC网络模型准确率与损失函数
从图5可以发现,训练集准确率随迭代次数增加逐渐上升,迭代结束时达到96.2%。而验证集迭代30次以后准确率基本保持92%以上,不随训练集准确率上升而上升。观察loss曲线发现,迭代30次后,验证集loss稳定在0.23左右,最后改进后LeNet-5网络在测试集上得到准确率92.1%。
其次再对原LeNet-5网络模型进行训练以做比较,网络参数设置采用与上面相同的参数,且设置Dropout失活率0.5,当输入batch_size为64时,得到训练集与验证集准确率、交叉损失熵如图6所示。
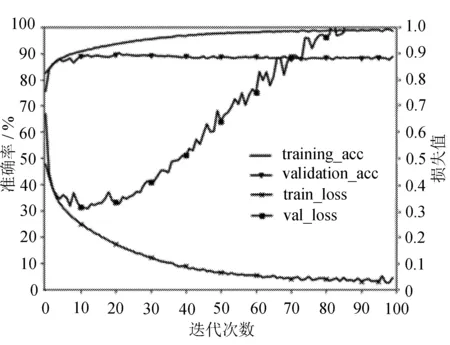
图6 LeNet-5网络模型准确率与损失函数
从图6可以发现,原LeNet-5网络训练集准确率大于98%,而验证集准确率仅达到90%,两者相差8%,出现轻微过拟合,最终在测试集上得到准确率为89.8%。随着迭代次数的增加,训练集与测试集loss值反而相差越来越大,验证集loss在不断增大,即出现了不收敛,与改进后的网络相比较,改进后网络收敛性明显优于原网络。
针对改进前后网络输入batch_size分别为64、128、256做对比实验,参数设置保持不变,仅改变batch_size大小,得到测试集准确率结果见表2。
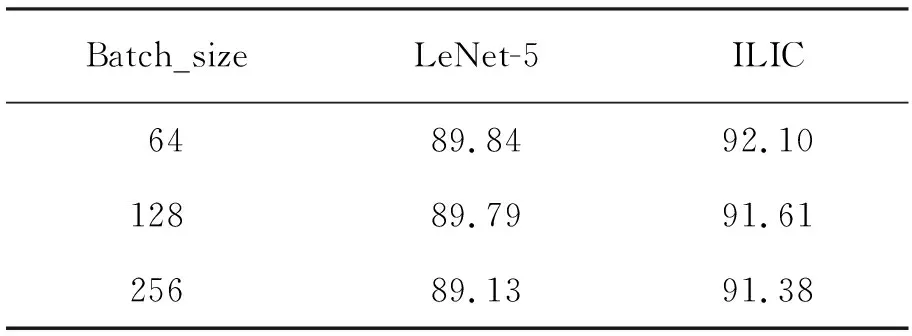
表2 不同batch_size网络模型准确率 %
实验发现,不同的batch_size对准确率有很大影响,同一网络下小量的batch_size输入可以得到更高的准确率,虽然小的batch_size能得到更高准确率,但需花费更长训练时间,所以针对不同的实验需要寻找合适的batch_size,在保证准确率的条件下快速完成实验。
4 结 语
提出一种改进LeNet-5的图像分类方法ILIC,增加了卷积核个数,引入了Inception V1模块增加特征提取能力,采用连续非对称卷积的方式降低卷积训练参数,并加入批量标准化Dorpout方式增加训练准确率,实验仿真表明,文中提出的ILIC方法提高了图像分类准确率,改进后的网络在Fashion MNIST数据集上分类准确率达92.10%,比原网络高2.26%,且改进后的网络收敛速度更快,产生过拟合的程度低。
猜你喜欢
科技创新与应用(2021年23期)2021-08-30 11:46:16
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
无线互联科技(2020年15期)2020-11-10 06:00:58
科技传播(2020年6期)2020-05-25 11:07:46
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:50
中国交通信息化(2018年5期)2018-08-21 03:37:40
雷达科学与技术(2018年3期)2018-07-18 00:59:32
数学理论与应用(2016年4期)2016-05-17 04:50:23
