
一种新闻文本标注方法
2021-12-22 13:29:00王红梅郭真俊张丽杰
长春工业大学学报 2021年5期
王红梅, 郭 放, 郭真俊, 张丽杰
(长春工业大学 计算机科学与工程学院,吉林 长春 130012)
0 引 言
随着互联网、机器学习、大数据等技术的飞速发展,各种信息数据以指数级的速度持续增长,目前人工智能所依托的机器学习和深度学习算法多数是依赖数据的,需要大量的数据采用有监督或半监督的方式训练算法进行定制化部署。由于中国大数据体量庞大,尤其是新闻文本没有固定格式,且种类多样,更新速度快,给数据标注任务提出了巨大挑战。最常见的新闻类别标注是通过人工方式对全部数据进行标注,人工成本很高,数据质量难以保证,不可避免地存在标注人员主观疲劳,数据审核环节质量难以把控等问题。
而深度学习是这个时代人工智能领域内最热门的研究之一,因其优秀的特征提取能力,对包括自然语言处理在内的诸多任务有着十分重要的影响。越来越多的任务选择采用深度学习来进行研究。自然语言处理(Natural Language Processing,NLP)是其中热门的研究领域,自然语言是高度抽象的符号化系统,文本间存在数据离散、稀疏、一词多义等问题。而深度学习具有强大的特征提取和学习能力,在NLP诸多任务中都取得了很好的发展。文本分类是NLP中最基本的一项任务,是根据文本所蕴含的信息将其映射到预先定义带主题标签的两个或几个类的过程[1]。文本分类被广泛应用到内容审核、广告标注、情感分析、邮件过滤、新闻主题划分、问题甄别、意图识别等场景[2]。2010年之前,基于浅层学习的文本分类模型是主流。浅层学习方法是机器学习的一种,基于从原始文本中提取的各种文本特征来训练初始分类器。浅层学习模型意味着基于统计的模型,如朴素贝叶斯(Naive Bayes, NB)[3]、K近邻(K-Nearest Neighbors, KNN)[4]和支持向量机(Support Vector Machines, SVM)[5]。其中,朴素贝叶斯模型是最早应用于文本分类任务的模型。之后,陆续提出了通用分类模型,如KNN、SVM等,它们被称为分类器,广泛应用于文本分类任务中。浅层学习模型加快了文本分类的速度,提高了准确性。与早期基于规则的方法相比,在准确性和稳定性上都更具有优势,但仍然存在成本高昂、耗时等问题。此外,这些方法通常会忽略文本数据中的上下文信息或顺序结构。近年来,深度学习在NLP领域被广泛应用,它避免了人工设计规则和功能,且自动为文本提供语义上有意义的表现形式。深度学习的核心是通过数据驱动的方式,采取一系列的非线性变换,从原始数据中提取由低层到高层、由具体到抽象的特征。与浅层学习相比,深度学习强调模型结构深度,通过模型深度的增加来获取深层次的含义。近年来,越来越多的研究人员对CNN(Convolutional Neural Networks)、RNN(Recurrent Neural Network)等进行改进,或进行模型融合,提高不同任务的文本分类性能,BERT(Bidirectional Encoder Representation from Transformers)[6]、ERNIE(Enhanced Language Representation with Informative Entities)[7]的出现给文本分类发展带来了重大转折,许多研究者在新闻分类上投入大量工作,如短文本分类[8]、基于BERT的中文文本分类[9]、基于改进ERNIE的中文文本分类等[10]。此外,研究人员将GNN(Graph Neural Network)[11]引入到文本分类任务中,也带来了前所未有的优秀性能。
文本标注是一种监督学习的问题,它可以认为是文本分类的一个扩展。标注问题又是结构预测问题的简单形式。将包含特征和标签信息的训练样本输入到模型中,从而得到一个最优模型。再通过最优模型对没有标签的测试样本进行测试,输出分类标签,并将其注释到相应位置。由于中文语法和字的差异,相对于英文,中文文本分类需要进行大量的处理和分析工作,中文长文本标注效果并不是特别理想。在数据方面,无论是浅层学习还是深度学习,长文本、短文本、跨语言、多标签等不同数据对于模型的性能都具有很重要的影响。为了更全面捕捉字的语义以及上下文之间的理解,针对长文本新闻自动标注问题,提出一种基于改进语言表示学习(Improved Enhanced Language Representation with Informative Entities,IERNIE)的新闻文本标注方法。
1)将ERNIE模型与LCNN(Bi-directional Long Short-Term Memory with Convolutional Neural Network)模型融合,提出一种新的IERNIE模型,该模型能够更好地捕获字的语义,以及上下文的特征;
2)首次将IERNIE模型用于长文本新闻类别标注任务上;
3)IERNIE模型与经典模型相比,在长文本新闻数据集上,准确率、精确率、召回率、F1值这4个评价指标上的表现均优于对比模型。
1 相关工作
1.1 FastText
FastText[12]是Facebook于2016年开源的一个词向量计算和文本分类工具,FastText模型有3层:输入层、隐藏层和输出层。FastText的输入是多个单词及其n-gram特征,然后输入到隐藏层中,将词向量进行叠加平均;最后通过输出层输出特定的标签。值得注意的是,在输入时,单词的字符级别的n-gram向量作为额外特征,输出时FastText采用了分层Softmax,从而降低模型的训练时间。在应用方面,Dai L L等[13]使用FastText模型进行中文文本分类,大幅降低分类时间。Tahsin R等[14]使用FastText模型对电子邮件进行自动分类,节省大量人工和时间。
1.2 Transformer
Transformer[15]结构分为Eencoder和Decoder两部分。Encoder由6个相同的块构成,每块由两个子层组成,分别为多头自注意力机制和全连接前馈网络,每个子层都添加了残差连接和归一化;Decoder结构与Encoder结构相似,但是增加一个注意力子层,目的是为了和Encoder的输出做操作。因其具有提取超长距离特征、高效并行和较快的收敛速度的优越性,Wang C C等[16]使用基于Transformer的方法,对5种不同语言进行分类,与只能处理一种语言的模型相比,有更高的性能。
1.3 BiLSTM
LSTM (Long Short Term Memory)网络是RNN的特殊类型,可以学习长期依赖模型。通过对单元状态中信息遗忘和记忆新的信息,使后续时刻计算有用信息得以传递,而无用信息则被丢弃,并在每个时间步都会输出隐层状态,这便是LSTM的计算过程。而BiLSTM则是将前向的LSTM和后向的LSTM结合起来。杨妥等[17]采用LSTM方法对新闻内容信息进行情感分析,再将分析得到的情感分类结果与股票的技术指标相结合,用以对股票指数进行预测;于佳楠等[18]通过LSTM对上下文信息进行独立语义编码,同时引入注意力机制,改善了情感特征信息;和志强等[19]利用BiLSTM从前、后两个方向全面捕捉短文本语义特征进行短文本分类。
1.4 CNN
CNN模型可以分为输入层、卷积层、最大池化层和全连接层4部分。输入层接受输入句子的单词向量矩阵,将其传输到卷积层中;在卷积层输入矩阵进行卷积操作,其中需要注意卷积核的列数是固定的,与词向量维度相同。卷积核不断向下移动,得到卷积后的值。多个不同的卷积核会生成多列向量,在最大池化层中,最大池化会取出每一列中的最大值,最终形成一个一位向量。而全连接层则使用Dropout防止过拟合,再通过归一化进行分类,这便是CNN文本分类模型。韩栋等[20]基于CNN进行改进,融合CNN和句子级监督学习构建了短文本分类模型。
1.5 BERT
BERT模型是建立在Transformer的基础上,采用双向的Transformer,以此建立一个通用的NLP模型,对于特定任务只需要加一个额外的神经网络层即可,相当于把下游任务的工作转移到预训练阶段,使用BERT进行文本分类,实际上就是将BERT得到的字符嵌入连接到全连接层进行多分类。段丹丹等[21]使用BERT模型研究中文短文本分类;李铁飞等[22]使用预训练BERT模型作为词向量模型,将得到的词向量输入到其他模型中进行分类工作。
2 IERNIE模型
IERNIE融合了ERNIE模型对语义信息的捕获和对RCNN进行改进的LCNN对上下文信息的捕获,IERNIE模型包括ERNIE层、BiLSTM层、最大池化层以及全连接层。模型算法中提到的符号描述以及算法步骤分别见表1和表2。
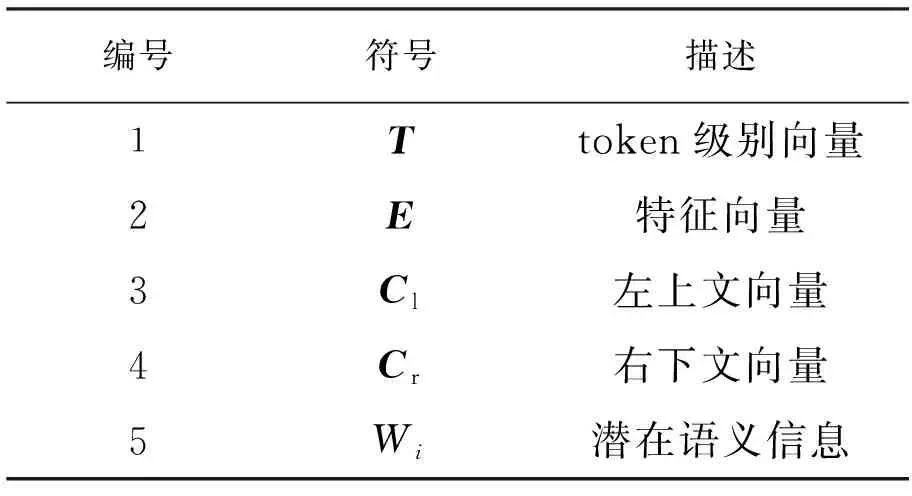
表1 符号描述

表2 算法步骤
首先将待标注的长文本新闻数据集转化token级别向量,并进行mask遮盖,然后将其通过ERNIE模型进行编码以及知识整合,得到特征向量E。接下来将E输入到BiLSTM模型,获得左上文向量Cl和右下文向量Cr。最后将E,Cl,Cr进行拼接,通过最大池化层保留最重要的潜在语义,并通过全连接层获得预测结果进行新闻类别标注。
2.1 ERNIE模型
ERNIE[7]是一种新的知识增强语言表示模型,ERNIE受BERT掩蔽策略的启发,目的是学习通过知识掩蔽策略增强的语言表示,包括实体级掩蔽和短语级掩蔽。ERNIE模型包括Transformer[15]编码和知识整合两部分,Transformer可以通过自注意捕获句子中每个标记的上下文信息,并生成上下文嵌入序列,使用先验知识可以增强预先训练好的语言模型,是一种多阶段知识屏蔽策略。第1段是基本遮蔽,第2段是短语级遮蔽,第3段是实体级遮蔽,经过3个阶段的处理,可以将短语和实体级知识集成到语言表示中。
文中使用ERNIE模型可以获得更多的语义和语法信息,首先捕获输入数据集的语义信息,并进行语义表征嵌入,得到包括[CLS]标记的特征向量E∈Rde,其中de表示词向量维度,然后将E通过全连接层得到输出xt,最后将其输入到BiLSTM层,公式为
xt=Wa*E+ba,
Wa∈Rde*da,
(1)
式中:da——编制ba的维度。
2.2 LCNN模型
LCNN是一种基于RCNN(Recurrent Convolutional Neural Networks)[23]模型的改进,将RCNN模型中的BiRNN用BiLSTM来代替,达到一个更好的效果。LCNN引入了BiLSTM的结构来捕获上下文信息,并且使用最大池化层模仿CNN用于判断文本分类中起到关键作用的词。
模型的第1部分是BiLSTM层,使用双向循环神经网络来学习字的上下文表示,第2部分是最大池化层,第3部分是全连接层,这两部分用来学习语义表示。
2.2.1 学习字的上下文信息
cl(wi)=f(W(l)cl(wi-1)+W(sl)e(wi-1)),
(2)
cr(wi)=f(W(r)cr(wi+1)+W(sr)e(wi+1)),
(3)
式中:cl(wi)——wi左上文;
el(wi)——单词wi的嵌入向量;
W(l)——用于将上一个字的左上文传递到下一个字的左上文;
W(sl)——结合当前词的语义到下一个词的左上文。
其余同理。
2.2.2 计算单词潜在语义信息
每个字wi的潜在语义表示是将左上文cl(wi),嵌入向量el(wi)和右下文cr(wi)连接起来表示为字Xi,
Xi=[cl(wi);e(wi);cr(wi)]。
(4)
将潜在语义Xi通过激活函数relu计算wi的隐藏语义向量y(2),y(2)的每个语义因素将被分析,以确定表示文本最有用的因素。
y(2)=relu(W2xi+b(2))。
(5)
2.3 最大池化层
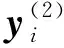
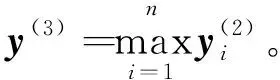
(6)
2.4 全连接层
全连接层(Fully Connected Layers, FC)在整个网络中起到了分类器的作用。它将学到的“分布式特征表示”映射到样本标记空间,做到将数据进行降维,从而得到预测结果。全连接层对模型的影响参数有3个,分别是全连接层的总层数、单个全连接层的神经元个数和激活函数。另外,全连接层在一定程度上保留了模型的复杂度。卷积神经网络中的全连接层设计属于传统特征提取和分类思维下的一种“迁移学习”思想,将y(3)通过全连接层得到预测结果y(4),全连接层计算公式为
y(4)=W(4)y(3)+b(4)。
(7)
3 实 验
3.1 数据集
实验采用的数据集由9万条长文本新闻所构成,每条新闻长度均大于200,是用于中文新闻分类的数据集,数据来源于各个新闻网站近期的新闻,包括财经、房产、教育、科技、军事、汽车、体育、游戏、娱乐9类数据,每类新闻数量为1万条。
为了确保实验结果可以复现,使用numpy和torch设置随机种子,并按照文献[24]的方式采用留出法[25]划分成70%和30%的两个互斥的集合。两个集合内训练集、测试集、验证集尽可能保持数据分布的一致性,这样可以避免额外误差带来的影响,使用分层采样的方式划分数据集。但单次留出法产生的结果可能会不够准确,因此进行5次实验,最终结果取5次实验的平均值。
3.2 评价指标
文中实验评价主要有4种,分别为准确率(Accuracy,ACC)、精确率(Precision)、召回率(Recall)、F1值[7],具体计算公式如下:

(8)

(9)

(10)
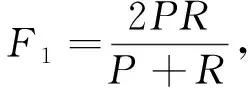
(11)
式中:TP——当实际值与预测值均为正时的数据数量;
TN——当实际值与预测值均为负时的数据数量;
FP——当实际值为负、预测值为正时的数据数量;
FN——当实际值为正、预测值为负时的数据数量;
P——精确率;
R——召回率。
3.3 实验结果
为验证模型的标注效果,选择一些经典算法CNN、FastText[12]、BERT[6]、BiLSTM[26]、Transformer[15]与文中IERNIE进行对比。将数据应用在IERNIE以及其他几类模型上,比较各模型在训练过程中随着训练批次的增加,在验证集上的训练效果,如图1所示。
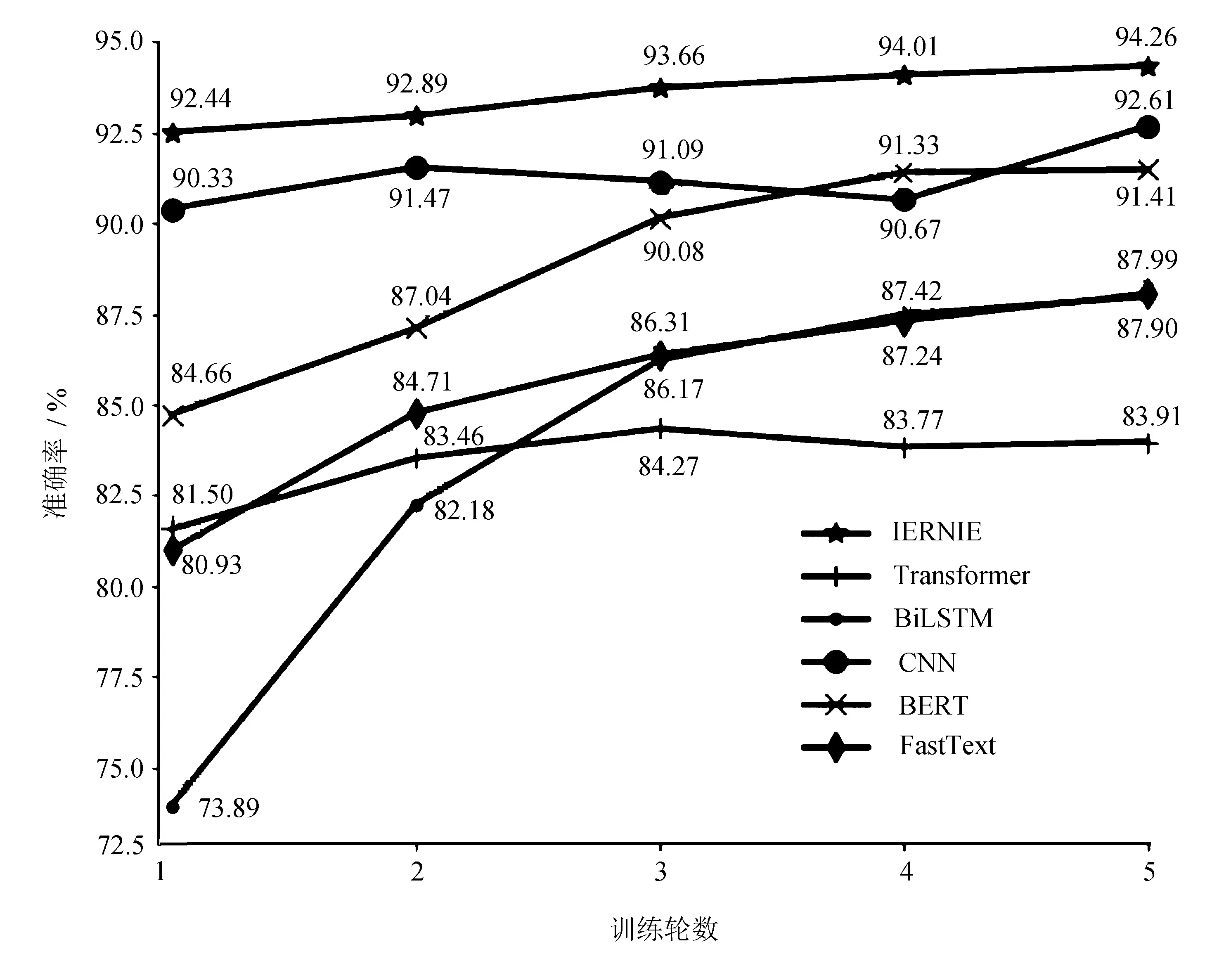
图1 模型训练中的准确率
训练了5轮之后,在验证集的准确率为94.26%,明显优于其他算法的准确率(CNN的准确率为92.61%,BERT的准确率为91.41%,FastText的准确率为87.99%,BiLSTM的准确率为87.99%,Transformer的准确率为83.91%)。
为了更好地评估IERNIE在长文本新闻标注的效果,在测试集上与CNN、FastText、BERT、BiLSTM、Transformer进行对比。在对比实验过程中,训练和测试的各项参数都保持统一,评价指标为准确率、精确率、召回率和F1值,得到模型的评估结果见表3。

表3 模型性能对比 %
从表3可以看出,IERNIE在准确率、精确率、召回率、F1值这4个评价指标上的表现均优于其他模型。BERT在处理中文语言时,通过预测汉字进行建模,很难学习更大语义单元的完整语义表示;ERNIE模型通过对词、实体等语义单元的掩码,使得模型学习完整概念的语义表示,相较于BERT学习原始语言信号,ERNIE直接对先验语义知识单元进行建模,增强了模型语义表示能力;经典的CNN算法使用固定词窗口捕获上下文信息,实验结果受窗口大小的影响,LCNN使用循环结构捕获更加广泛的上下文信息。通过实验结果对比可以发现,模型具有更好的效果,验证了文中融合思想的有效性。
4 结 语
针对长新闻文本类别标注问题,结合上下文信息提出一种基于改进语言表示学习的新闻文本标注方法IERNIE。该方法首先使用预训练ERNIE模型,获取新闻数据的向量表示,其次使用LCNN模型处理该向量表示,更好地提取上下文信息。在长文本新闻数据集上的实验结果表明,IERNIE方法的准确率、精确率、召回率、F1值评价指标均高于对比方法。实验结果验证了IERNIE在长文本新闻标注的可行性和有效性。接下来,将会继续在其他文本数据集上进行测试,验证方法的有效性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
开放教育研究(2020年2期)2020-03-31 01:54:14
电子制作(2019年11期)2019-07-04 00:34:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
