
基于卷积神经网络的颅内出血检测
2021-12-22 13:29:00周长才
长春工业大学学报 2021年5期
周长才,刘 爽,王 昕
(长春工业大学 计算机科学与工程学院,吉林 长春 130012)
0 引 言
颅内出血,即颅骨内发生的出血。它是临床常见的急重症,具有极高的致死率或致残率,对病人的生命健康有极其严重的威胁。快速确定病人出血的位置和类型是治疗的关键。导致颅内出血的病因有多种,常见的有脑部遭受外伤、中风和高血压等。根据脑中不同的出血部位,颅内出血分为脑实质内出血、脑室内出血、蛛网膜下腔出血、硬膜下出血和硬膜外出血5种亚型[1]。
近几年,人工智能(Artificial Intelligence)中深度学习算法的火热给各行各业带来了福音,作为一种处理大数据的手段,在医学图像处理中也得到了广泛应用。目前只有部分学者尝试将深度学习应用于颅内出血的研究,Ye H等[2]在3家医院收集2 836套CT扫描数据用于训练和测试模型,结合卷积神经网络VGG-16和双向GRU作为一个端到端可训练网络,用于预测颅内出血和出血亚型种类。Chilamkurthy S等[3]在印度多家医院收集脑CT图像数据用于训练深度学习模型,并验证其有效性。Tomasz Lewicki等[4]用RSNA提供的数据集对颅内出血的亚型进行分类,每张图像的准确率是93.3%。Arbabshirani M R等[5]采集约4万张数据用于训练,约1万张数据用于测试,验证了三维卷积神经网络在检测是否颅内出血任务上的有效性。综上所述,目前多数算法的训练样本集数目有限,且只做单一的颅内出血检测。文中在大样本数据集上构建深度学习模型,对颅内出血及其亚型进行检测。
1 网络模型构建
1.1 卷积神经网络
卷积神经网络(CNN)作为深度学习的一种典型算法,目前已在医学影像处理中得到了广泛应用,在肺结节的良恶性识别,皮肤及宫颈癌的探查,视网膜病变检测,脑肿瘤检测,以及目前的新冠肺炎筛查等方面表现出良好的计算机辅助诊断性能。它的基本结构包括输入层、卷积层、池化层、全连接层及输出层。输入层即整个神经网络结构的输入,卷积层和池化层采取多轮交替设置,接下来是若干个全连接层,输出层也称为 Softmax 层,主要用于各种分类问题[6]。
文中选择的卷积神经网络是ResNet(Residual Neural Network),即残差网络。原因在于ResNet在几个脑图像分析项目中得到应用,如用于诊断阿尔茨海默病[7],并具有近乎完美的多类预测的准确性。另一项研究[8]将各种深度学习模型用于大脑异常检测,发现ResNet具有最佳分类精度。
1.2 网络结构
ResNet是2015年提出的一种神经网络,按照层数的不同可以分为ResNet18、ResNet34、ResNet50、ResNet101、ResNet152这5种类型,不同深度ResNet的具体结构见表1。

表1 ResNet的结构
ResNet的结构单元如图1所示。
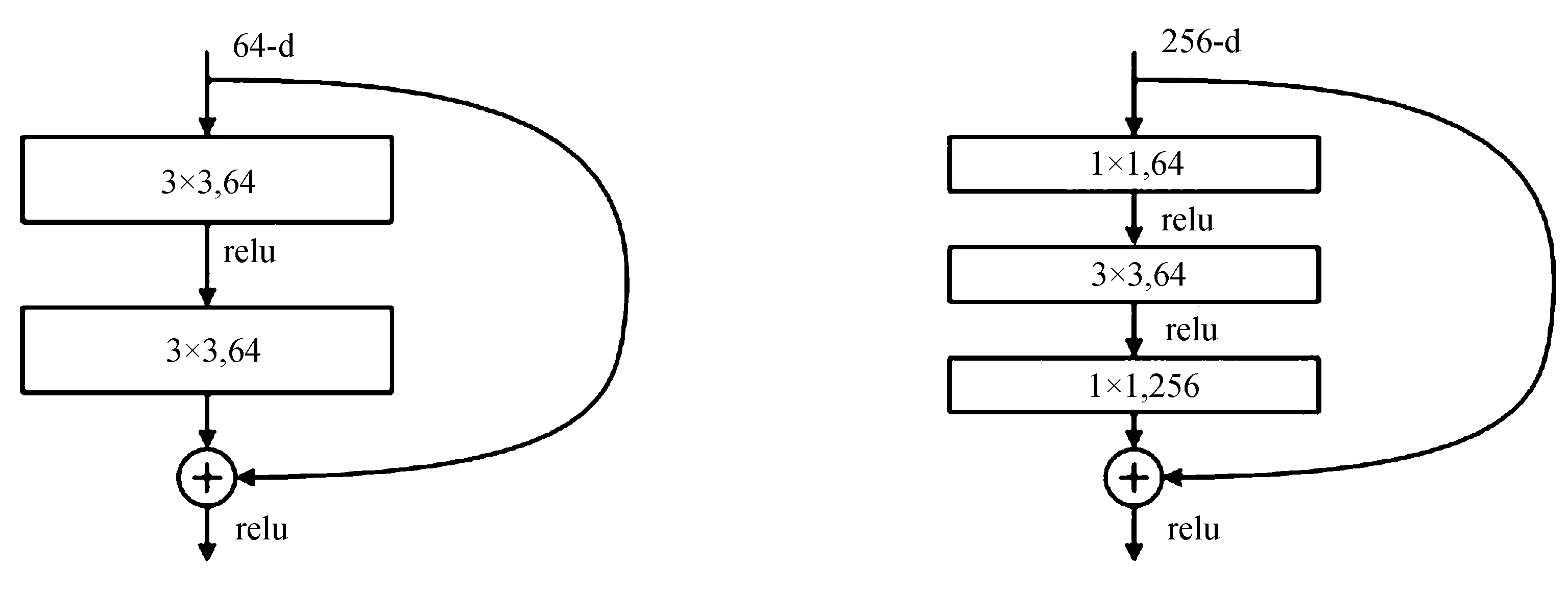
(a) BasicBlock (b) Bottleneck
根据Block类型,可以将这5种ResNet分为两类:
1)基于BasicBlock(见图1(a)),浅层网络ResNet18、34都由BasicBlock搭成;
2)基于Bottleneck(见图1(b)),深层网络ResNet50、101、152乃至更深的网络都由Bottleneck搭成。Block相当于积木,每个layer都由若干Block搭建而成,再由layer组成整个网络[9]。
使用ResNet-101中的卷积基作为特征提取器,网络模型的数据流向如图2所示。
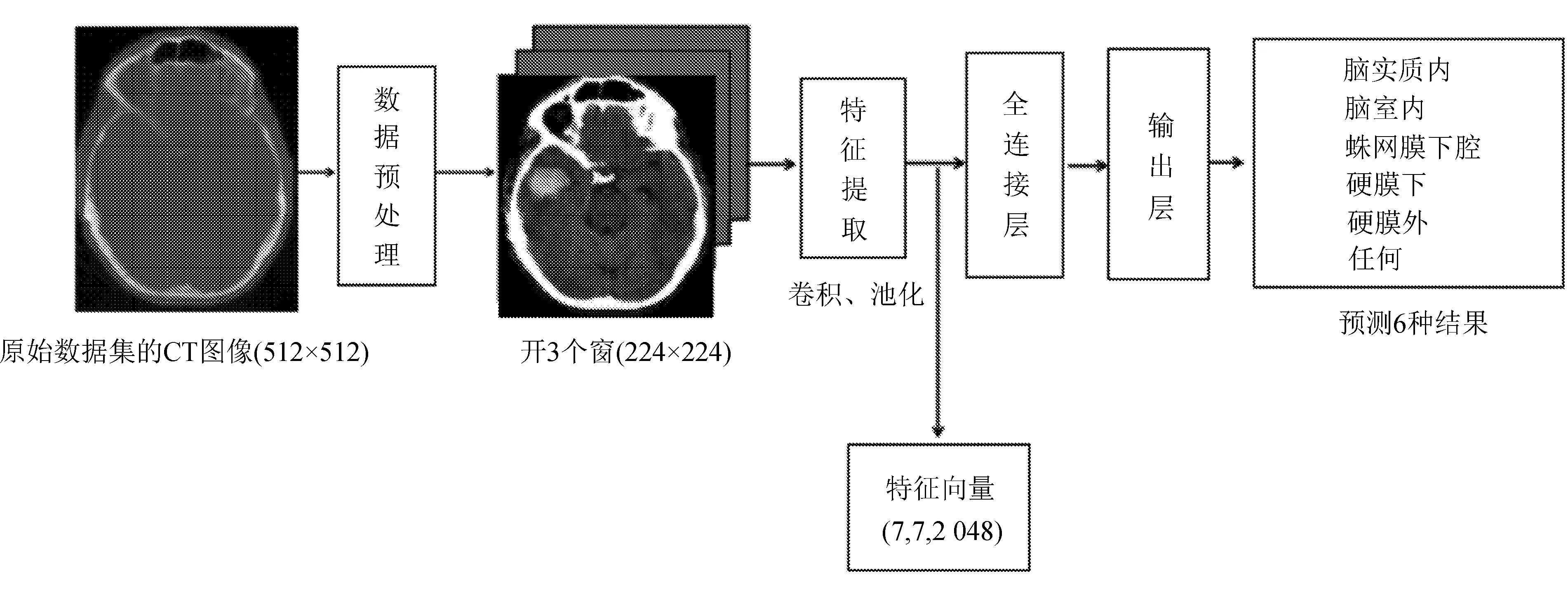
图2 网络模型的数据流向图
全连接层设计成两层,包括512个神经元的隐藏层(relu激活)和6个神经元的输出层(Sigmoid激活)。模型的输出向量是一个6维向量,有5个值对应诊断每种出血类型的可能性,第6个值对应属于“任何”类别的可能性,即指出血类型不止一种。在训练中,使用Adam优化器,学习率为1e-5,通过超参数优化确定,批量大小设置为16。
2 实验分析与结果
2.1 实验环境
模型训练是在处理器为Intel(R) Xeon(R) Gold 6130CPU、显卡为NVIDIA Tesla P100的硬件平台上完成的,在Windows 10操作系统下进行环境配置,Cuda版本为11.0,Keras版本为2.4.3。整个实验的深度学习框架用Keras搭建,一些残差网络的结构参数可以直接从Keras导入。
2.2 实验数据集
文中数据集来自2019年Kaggle平台推出的RSNA急性颅内出血检测竞赛(RSNA Intracranial Hemorrhage Detection),该数据集由北美放射学会(RSNA)提供,共包含752 803个标记DCM文件,都是512×512的大脑横断面图像[10]。我们留出20%随机选择的样本作为测试集来测试模型的准确率,其中每个文件都标有一种或多种出血类型,或者根本没有出血。数据集中可能出现的5种出血类型如图3所示。
(a) 脑实质内 (b) 脑室内 (c) 蛛网膜下腔 (d) 硬膜下 (e) 硬膜外
标签以CSV文件的形式给出,每个患者ID包含6行,每行对应一种出血类型,后跟一个布尔值表示该图像中是否存在该类型的出血。
2.3 数据预处理
CT扫描是使用X射线生成的,组织密度越大,X射线衰减越多,从而产生的像素强度越高。文献[3]指出,对于特征提取,加窗口后可以最大化特征之间的细微差异。因此在预处理阶段,原始CT中HU值被3个影像科医生常用的视窗截断,即脑窗(窗位40,窗宽80)、骨窗(窗位600,窗宽2 800)和硬膜下窗(窗位80,窗宽200),然后归一化到[0,1]范围内,再拼接成输入图像的3个通道中,所有输入图像将会通过双线性插值缩小到 224×224,预处理之后的CT图像如图4所示。

(a) 无对比扫描 (b) 脑窗 (c) 硬膜下窗 (d) 骨窗
2.4 评价指标及实验结果
对于模型评估,在训练完整个网络后,随机抽取整个数据集的20%(大约150 000个示例)作为测试集来测试模型的有效性。文中采用分类任务中最常见的一个性能指标——准确率(Accuracy)对颅内脑出血类型进行评价,其定义式如下

(1)
式中:TP、TN、FP、FN——分别表示真阳率、真阴率、假阳率和假阴率。
实验结果表明,基于ResNet-101构建的深度网络模型每幅图像的识别准确率为94.6%。为了进一步证明文中算法的有效性,还与其他两种颅脑出血分类方法[3-4]及文献[2]中提到的VGG-16网络进行了对比实验,结果见表2。
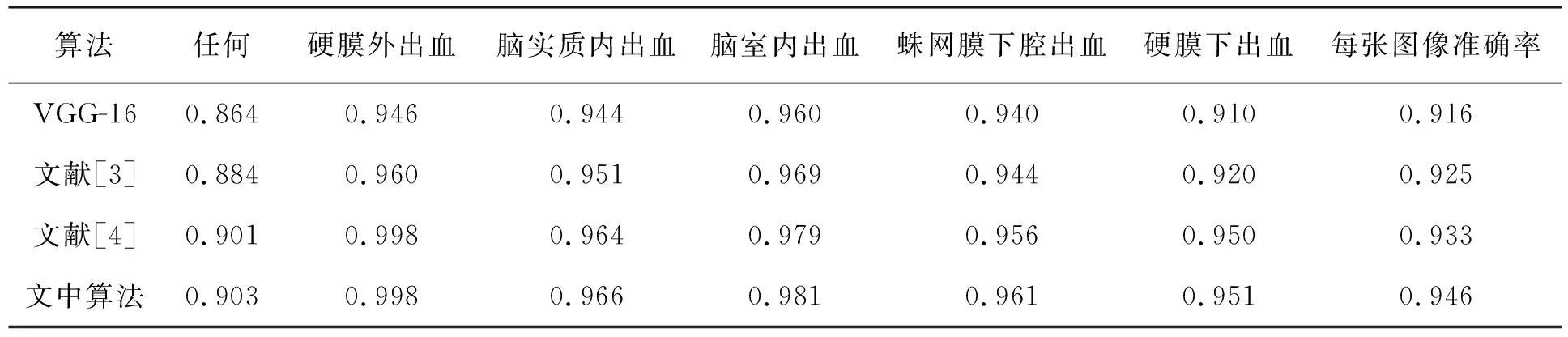
表2 不同算法的识别准确率对比
从4种不同网络模型的识别准确率结果可以看出,文中算法的识别准确率更高,相比于VGG-16网络,在每张图像准确率上高出2~3个百分点。
3 结 语
研究一种用于颅内出血及其亚类型分类的深度学习方法,该方法基于当前在图像分类任务上取得优异成果的ResNet网络,并将该分类模型进行调整,应用于颅内出血检测任务中。该方法在RSNA颅内出血数据集上进行了大量实验,使用加窗方法进行预处理,将CT扫描转换为16位dicom图像,并转换为3个通道,浮点数矩阵归一化处理在[0,1]。最终实验结果表明,该方法在颅内出血分类上取得了优异性能,模型的分类平均准确率为98.1%,每幅图像的平均准确率为94.6%,对颅内出血的计算机辅助诊断具有参考价值。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
