
基于随机矩阵理论和改进粒子群优化-深度置信网络的无功优化
2021-12-02 09:34王群京
科学技术与工程 2021年33期
夏 芃,张 倩,王群京,王 璨
(1.安徽大学电气工程及自动化学院,合肥 230601;2.安徽大学工业节电与电能质量控制协同创新中心,合肥 230601;3.教育部电能质量工程研究中心(安徽大学),合肥 230601;4.工业节电与用电安全安徽省重点实验室(安徽大学),合肥 230601;5.国网安徽省电力有限公司,合肥 230601)
分布式电源并网导致配电网结构趋于复杂,配电网电压波动过大[1]、网损较大[2]等问题日趋严重。因此,如何保障电力系统稳定且安全运行,并减小配电网电压波动和网损是国内外学者研究的热点。配电网无功优化是指在电力系统能稳定且安全运行的前提情况下通过针对配电网发电机端电压的调节[3]、变压器分接头次数[4]以及增加无功补偿装置[5-6]等方式来减少电压波动并降低网损。
为解决大规模分布式电源并网所引发的相关问题,目前中外学者主要从改变无功优化模型以及无功优化算法等方面进行研究。文献[7]通过建立系统运行成本和用户满意度为目标的配电网无功优化模型,提高了计算精度和速度。文献[8]建立了混合整数半定规划模型,先将传统无功优化模型转化成半定规划模型,在此基础上增加离散变量使其变成混合整数半定规划模型,使配电网无功优化模型的求解更加方便。上述改进虽然和配电网原始模型相比计算速度得到提高,但改进的方法过于依赖配电网的模型,当配电网的模型过于复杂时,该方法存在局限性。文献[9]将禁忌搜索算法和粒子群算法相融合,对传统的粒子群算法进行改进,并运用到配电网无功优化策略当中。文献[10]通过构造初始信息矩阵和蚁群算法相结合,提高了蚁群算法的计算效率,上述算法改进虽然和传统算法相比寻优精度和计算精度有所提高,但仍未摆脱算法计算时间长、步骤较为复杂的特点。
近些年来,大数据技术在电力系统中的应用越来越广泛,从而给配电网无功优化的方法带来了一种新的途径。目前大数据技术大多用于电力系统负荷预测以及故障诊断领域[11-13],但是部分学者也将大数据技术和配电网无功优化应用领域相结合。文献[14]运用大数据技术对风力发电厂并入光伏后的电压进行无功控制。文献[15]将支持向量机的方法运用到遗传算法当中并加以改进,得出了基于数据挖掘技术的无功优化策略。文献[16]将负荷分布匹配与熵权理论相结合,运用熵权法从历史优化方案中选择最优无功优化控制方案。文献[17]将粒子群算法对极限学习机进行优化,并运用到配电网的调压策略中。上述基于数据挖掘技术的无功优化控制策略对配电网具体模型依赖程度低,均取得了较好的无功优化控制效果。
配电网无功优化是典型的高维非线性函数问题,而深度学习理论可直接确定输入和输出之间的隐含关系。其中,深度置信网络(deep belief networks,DBN)的网络模型结构较为简单且训练难度较低,常用于求解高维非线性函数问题。现利用配电网运行的光伏、负荷、温度、光照强度以及风速5个数据构造随机矩阵构成样本集,运用粒子群优化 (particle swarm optimization,PSO)对DBN的初始权重进行优化,通过建立PSO-DBN模型得出配电网运行特征与无功优化策略的函数关系,将本文方法用于改进后的IEEE33节点,并和粒子群优化方法、改进的粒子群优化方法以及DBN对比,以验证本文方法对电压波动和网损的调节效果。
1 随机矩阵理论
随机矩阵理论[18]是一种常用的大数据分析方法,其主要应用于故障诊断以及变电站二次评估。当随机矩阵的行数和列数的比值保持恒定时,其经验分布函数满足单环定律、半圆律等。主要以单环定律进行研究。
1.1 单环定理


i=1,2,…,N,j=1,2,…,T
(1)

(2)
式(2)中:U为酉矩阵。

(3)

根据式(4)将矩阵积标准化得
(4)

(5)
式(5)中:λ为矩阵的特征值。
1.2 线性特征值统计量
线性特征值统计量是对随机矩阵特征值分布的特点具体形式的表现,而线性特征值统计量定义为

(6)
式(6)中:s为统计函数对应的映射值;λi(i=1,2,…,n)为随机矩阵的特征值;φ(·)为一个线性特征统计函数,不同的线性统计函数的选择即可得到不同的线性特征统计量。
1.3 特征指标的提取
采用光伏、负荷、温度、环境以及风速共5种数据,每种数据用单环定理算出随机矩阵的特征值,然后通过特征值计算每种随机矩阵的平均谱半径、最大/最小谱半径、圆环外/上/内特征根的分布概况。随机矩阵的模以及协方差共8个统计特征,因而5种数据共构成40种统计特征。每个统计特征的具体公式为

(7)

(8)

(9)

(10)

(11)

(12)
式中:N为矩阵特征值的个数;rMSR、Rmax、Rmin分别为平均谱半径、最大以及最小谱半径;P1、P2、P3分别为圆环外/上/内的特征值占总特征值比例;S1、S2、S3分别为分布在圆环外、上、内的特征值个数。

(13)

(14)
2 DBN理论
DBN由多层受限玻尔兹曼机(restricted Boltzmann machine,RBM)和最外层的BP网络构造而成[19],具体结构如图1所示。

图1 DBN结构Fig.1 DBN structure
DBN的训练步骤主要有RBM的预训练以及DBN参数反向微调。预训练即通过输入自下而上逐层训练RBM,如此进行反复训练,不断优化网络中的模型参数,使网络达到局部最优。而参数的反向微调即以DBN模型的最后一层为输入,运用BP神经网络自下而上地微调整个DBN的网络模型参数,从而实现全局参数最优。
2.1 RBM预训练
RBM作为概率神经网络的分支,主要由可视层以及隐藏层所构成的。可视层v=(v1,v2,…,vm)以及隐含层h=(h1,h2,…,hn)的联合概率能量函数为


(15)
式(15)中:θ={ω,a,b}为RBM网络模型相关参数;vi和ai分别为可视层神经元的当前状态以及该层网络的偏置;hj和bj分别为隐含层神经元的当前状态以及偏置;ωij为每层之间所需连接的权值。
在RBM中定义任意一组关于v和h的联合概率分布为

(16)
而由联合概率分布可得v和h的条件分布为
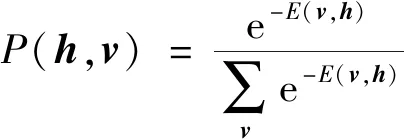
(17)
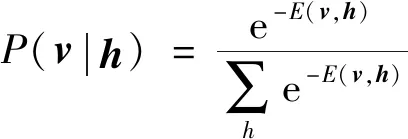
(18)
RBM的训练的最终目的即找到合适的参数θ={ω,a,b},进而使RBM的能量误差函数达到最小值。
2.2 DBN的反向微调
当每层的RBM参数调整完成之后,却很难保证整体DBN的参数达到最佳。因此,需要运用BP算法针对整个DBN网络参数进行微调,具体微调过程是利用反向误差将权值进行更新,因而获得了整体DBN的最佳网络参数。
在参数调整过程当中,将RBM训练的最后一层作为输入,利用BP算法对RBM预训练过程中产生的训练误差自下而上传到RBM层中,进而调节整个DBN网络,大大减少了训练时间。反向微调过程中参数更新公式为
(19)
式(19)中:ωn为每层网络之间的权值;n为RBM更新迭代次数;η为学习率;m为动量系数。
3 基于PSO-DBN无功优化策略
3.1 粒子群优化算法及其改进
在建立DBN模型之初,DBN网络初始权重是通过随机赋值所得出,若赋值不恰当会使得DBN模型在训练中会出现局部收敛现象,因而采用粒子群算法对DBN网络初始权重进行优化。
粒子群优化算法作为一种启发式算法,其算法本身是通过对每个粒子的速度Vi和位置Xi进行更新,当满足结束条件时,即可获得最优解,粒子的速度以及位置更新公式为

(20)
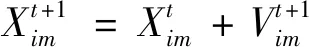
(21)
式中:m=1,2,…,M;ω为粒子的权值;c1和c2为学习因子;r1和r2为在0~1所取的随机数;t为迭代次数;Pim和Gim为个体以及群体极值。
因为传统的粒子群算法易陷入局部最优解的状况。因此,对其改进的方法也有很多。目前大多数学者主要采用调整权重、限制学习因子等方法对粒子群算法进行改进。
主要使用对惯性权重的改进,通过线性权重递减法,具体公式为

(22)
式(22)中:ωmax、ωmin分别为粒子群算法初始权重的最大值以及最小值;T为最高迭代次数;k为当前迭代次数。
3.2 PSO优化DBN网络的无功优化策略
基于PSO-DBN网络的无功优化流程图如图2所示,其具体优化步骤如下。

图2 PSO-DBN无功优化流程图Fig.2 PSO-DBN reactive power optimization flowchart
步骤1对配电网历史时刻的负荷、光伏、环境、温度以及风速分别构建各时刻的5种随机矩阵。
步骤2根据前文所述的特征指标提取方法,提取出40个历史特征指标集,进行归一化处理并得到样本训练集和测试集。
步骤3确定DBN网络中隐含层层数及隐含层中神经元的个数,以便对粒子维度进行确定。
步骤4对粒子群各参数进行设置,即粒子的群体规模、学习因子、惯性权重以及最大迭代次数。并将DBN网络中各层之间的连接权值作为PSO的向量。
步骤5计算粒子的适应度函数值f。其函数为

(23)
式(23)中:N为样本数目;m为粒子维数;pij和tij分别为第i个样本中第j维粒子的重构值和实际值。f和个体极值Pbest进行比较,若f>Pbest,则将当前适应度值替换掉,否则将个体极值保留。
步骤6将每个粒子的适应度值大小f和群体极值gbest相比较,若f>gbest,则将当前适应度值替换掉,否则将群体极值保留。
步骤7根据式(20)和式(21)将粒子的速度以及位置进行更新。
步骤8利用PSO优化后获得的群体极值的各维数值作为DBN网络的初始权重。再进行DBN模型的训练和参数微调,直至DBN训练结束,DBN的网络模型建立,从而得到无功优化策略。
4 算例分析
4.1 算例介绍及样本数据集的构造
以IEEE33节点系统作为研究对象,对系统的22节点和33节点增加无功补偿,在16-17支路、19-20支路、24-25支路、26-27支路进行变压器分接头变比的调节,TA1~TA4分别为4个载调压器,SVC代表无功补偿,其改进后的节点拓扑图如图3所示。

图3 改进IEEE33节点拓扑结构图Fig.3 Improved IEEE33 node topology diagram
配电网运行状态数据源于安徽省安庆市电网公司数据集。利用配电网两个月的负荷、光伏、环境、温度以及风速构造5种随机矩阵。研究每小时配电网的无功优化策略,构造5种不同的高维随机矩阵,提取特征统计量作为历史输入,从当地电网数据库中得到两个月中每小时的无功优化控制策略作为历史输出,构成1 440个历史样本的输入和输出标签,放入PSO-DBN模型中进行训练,训练过程中设置DBN网络共有4层结构,两层隐含层神经元的数量可分别设为20和10。粒子群优化算法参数设置如下:ωmax=0.9,ωmin=0.5,学习因子c1=c2=2,T=1 000。接着,选取前文所述两个月之外的某日作为待优化时刻,利用随机矩阵理论获取该天每小时共24个特征统计量作为样本输入,再将输入运用到训练好的DBN模型中得到当前时刻的无功优化策略。图4和图5表明了该日通过本文方法得出改进后IEEE33节点系统的变压器调节挡位和无功补偿量。再将所得策略进行仿真计算。

图4 IEEE33节点各支路变压器档位调节图Fig.4 IEEE33 node branch transformer tap adjustment diagram

图5 22节点和33节点无功补偿Fig.5 Reactive compensation of22 and 33 node
4.2 无功优化结果分析
为更好地验证本文方法在无功优化方面的有效性,将本文方法与PSO算法、改进PSO算法、DBN这3种优化方法调压所得的电压波动和网损进行对比,以系统降损率和系统电压偏差波动率为指标,可更直观地看出本文方法调压策略的有效性。其中定义某时刻系统降损率为

(24)
式(24)中:eL为系统降损率;f0为系统该时刻未使用任何调压方法所得的网损;f为系统该时刻使用调压方法所得的网损。
定义某时刻的系统电压偏差波动率为

(25)
式(25)中:eu为系统电压偏差波动率;ΔUR为系统该时刻运用调压算法调压所得的电压值;ΔUc为系统该时刻未使用任何调压方法所得的电压值。
运用式(24)和式(25)对无功优化结果分析,对于待优化的24个时刻,4种优化方法的系统降损率如图6和表1所示,系统电压偏差波动率如图7和表2所示。

图6 降损率比较Fig.6 Comparison of loss reduction rate curve

表1 降损率分析Table 1 Analysis of loss reduction rate

图7 电压偏差波动率比较Fig.7 Comparison of voltage deviation volatility rate curve

表2 电压偏差波动率分析Table 2 Analysis of voltage deviation volatility
由图6及表1可知,在减少网损方面,本文方法在当天的降损率曲线幅度要大于其他3种方法的曲线,而降损率均值和方差分别为7.94%和1.67%,均高于其他2种方法。由图7及表2可知,在减小电压波动方面,该方法的整体电压偏差波动率曲线幅度要小于其他3种方法的曲线,而电压偏差波动率均值和方差分别为0.94%和0.29%,均小于其他2种方法。
5 结论
针对配电网的无功优化问题,提出了基于PSO-DBN的配电网无功优化方法,并在IEEE33节点系统进行仿真实验,得出以下结论。
(1)利用随机矩阵理论对配电网运行状态数据进行特征提取,大大提高了数据利用率,可有效地体现出配电网的运行状态,为后续配电网无功优化策略的分析提供了重要数据来源。
(2)所建立的改进PSO-DBN模型可搭建配电网运行状态与配电网无功优化策略之间的关系,使得无功优化效果得以提高。
(3)本文方法对配电网模型参数依赖程度较低,并不需要配电网的网架结构的具体参数,仅需将配电网运行状态合无功优化策略之间建立深度学习模型,相较于传统优化方法无功优化效果有所提高。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
昆明医科大学学报(2022年1期)2022-02-28
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
烟台大学学报(自然科学与工程版)(2020年1期)2020-02-08
电子制作(2019年16期)2019-09-27
活力(2019年22期)2019-03-16
电子制作(2018年8期)2018-06-26
课程教育研究·新教师教学(2016年18期)2017-04-12
