
基于LightGBM算法的航空发动机基线多参数建模方法
2021-11-23 13:02王腾飞曹惠玲曲春刚
科学技术与工程 2021年31期
王腾飞, 曹惠玲, 曲春刚
(中国民航大学航空工程学院, 天津 300300)
基线方程是指在标准大气状态下同一类型的处于性能最佳状态的航空发动机(或新发动机)的性能参数与控制量、其他飞行参数之间的函数关系。发动机性能参数换算值与基线值之间的偏差反映了发动机健康状态,所以航空发动机基线模型直接影响了对航空发动机健康状态的判断[1],因此航空发动机基线模型是发动机状态监控、故障诊断和预测的基础[2],有必要对其进行研究。
龙江等[3]根据现有基线模型,建立单参数的二次模型,进行相关回归分析。李书明等[4]利用最小二乘法对数据拟合从而实现发动机基线方程的挖掘。钟诗胜等[5]采用数学统计的多元非线性回归分析方法对发动机基线进行了挖掘工作。莫李平等[6]提出了考虑数据选择的航空发动机基线建模方法,该方法 基于多元线性回归建立基线模型,并通过网格搜索确定最优的建模数据选取方案,最终在一定程度上缩小了基线建模误差。这些方法虽然可行,但都存在一个精度不高、鲁棒性不强等问题。随着机器学习和人工智能的发展,利用机器学习和人工智能进行基线建模也层出不穷。王聃[7]对现有的支持向量回归机(support vector regression,SVR)和BP(back propagation)神经网络算法改进后应用到航空发动机的基线挖掘上,并且获得了较好的结果。闫峰等[8]利用以高斯函数为隐含层激励函数、以线性函数为输出层激励函数的多参数 RBF(radial basis function) 神经网络对航空发动机进行了数据挖掘也获得了不错的结果。刘渊等[9]利用堆叠降噪自编码器和支持向量回归相结合的方法进行了基线建模,并且得到了预期的预测精度和鲁棒性。这些方法在精度上有了很大的提高,但当样本量少时,训练时间和收敛速度方面却表现不佳。
以上建模所用数据都是来源于稳态报文数据,曹惠玲等[10]利用快速存储记录器(quick access recorder,QAR) 数据通过支持向量回归机进行了基线挖掘,有效提高了发动机基线建模的准确性,为基线建模提供了一种新的数据选择。王奕首等[11]利用大量QAR数据作为数据源,提出一种基于核主成分分析和深度置信网络相结合的航空发动机排气温度基线模型构建方法,建立了CFM56-7B发动机排气温度( exhaust gas temperature,EGT)基线模型。曹惠玲等[12]针对稳态报文数据和QAR数据的基线建模方法分别进行了总结分析,并对两种数据源进行了实例建模,并验证了基于QAR数据建立基线建模的可行性与便利性。稳态报文数据较为难获取且需取得许可后购买,而QAR数据直接从航空公司下载获得,故利用QAR数据比稳态报文数据更加便利。
以上研究中,基于拟合方程的显性建模所得的方程虽然直观,但精确度不高,而SVR、BP神经网络等算法虽然能够很好地挖掘出发动机基线模型,但是由于神经网络自身的原因,在训练样本相对比较少的情况下,训练时间长并且难以收敛是最常见的问题。以上都是中国对于航空发动机的研究现状,目前国外研究发动机基线的相对较少。而在这些已有的基线建模方法中,无论是基于稳态报文数据的建模还是基于QAR数据的基线建模,均没有考虑引气和滑油温度因素的影响。而从厂家资料[13]中明确说明了挖掘发动机基线时,应考虑引气因素的影响。针对上述传统算法难以收敛,精度不高且选择数据时考虑因素不全面等问题,提出基于QAR数据考虑引气和滑油温度影响下的LightGBM航空发动机基线建模方法,来解决发动机考虑引气等因素影响和缩短训练时间的问题。
1 QAR数据处理
发动机基线模型是发动机厂家通过台架试验再经数据处理所得,由于客观原因,航空公司用户只能使用却无法获得基线模型。为了自主监控的需要,大多数学者均是通过稳态巡航报文——飞机通信寻址与报告系统(aircraft communications addressing and reporting system,ACARS)报文获取数据进行相似修正,并且通过发动机监控软件得到相应的小偏差值,将两者做差最终得到基线数据,再用这些基线数据训练得出基线模型。虽然这样得到的基线点数据最为真实有效,但稳态巡航报文数据需要结合趋势图来提取特征数据,而趋势图数据种类有限,并没有厂家规定的引气数据,其次由于每次航班只下发两份报文数据,所以导致可提取数据量少,利于训练出精度高的基线模型;而作为与稳态巡航报文数据同源的QAR数据,其种类繁多(包括航空发动机油路、气路和引气等参数),可以满足基线建模的数据特征要求,故而可采用新发与之同源的、数据量大且易获取的快速存取记录器中所记录的QAR数据作为替代[14]。
1.1 基线点数据的提取
依据稳态巡航报文触发逻辑规定,一个航班一般会产生和下发2个发动机稳态报文,在首次满足所有判定条件之后立即下发第一个报文,巡航阶段内最后一个满足判定提取条件的报文将作为第2个下发报文[14]。但为了能够尽可能地达到与稳态巡航报文数据同样的基线建模效果,可以按照稳态巡航报文触发逻辑从QAR数据中筛选并提取出多组满足提取条件的稳态数据作为基线点数据,以便为后期的基线建模打好基础。
在QAR数据中,包含许多可能影响航空发动机基线模型的参数[15],包括马赫数、飞行高度、温度、大气压力以及发动机很多其他气路参数,如低压转子速度、高压转子速度和推力杆角度。本文中在参考飞机性能手册的基础上,初步选择了13个参数作为影响基线建模的参数,分别为飞行高度(ALT)、马赫数(MA)、排气温度(EGT)、低压转子转速(N1L)、高压转子转速(N2L)、大气静温(AST)、大气总温(TAT)、计算空速(CAS)、燃油流量(FF)、高压压气机入口温度(TAP)、引气(BLEED)、空气流量(AIR)、滑油温度(TEMP)。
本次所用的QAR数据为GE90-115B发动机的刚服役半年时间内的数据,即为新发动机的数据,可用于本次基线挖掘,按照稳态巡航报文触发逻辑从QAR数据中共提取1 160条数据,整理出EGT、N2L和FF及N1L、引气等影响其基线建模的共13种数据,如图1所示为EGT、N2L和FF以低压转子转速N1L为自变量的散点图。可见,数据点总的趋势明显,但聚集性并不好,说明N1L是影响这些因变量的主要因素,同时这些因变量还受到其他参数的影响。因此需要通过相关性分析,从以上13种数据中确定基线建模所需数据。
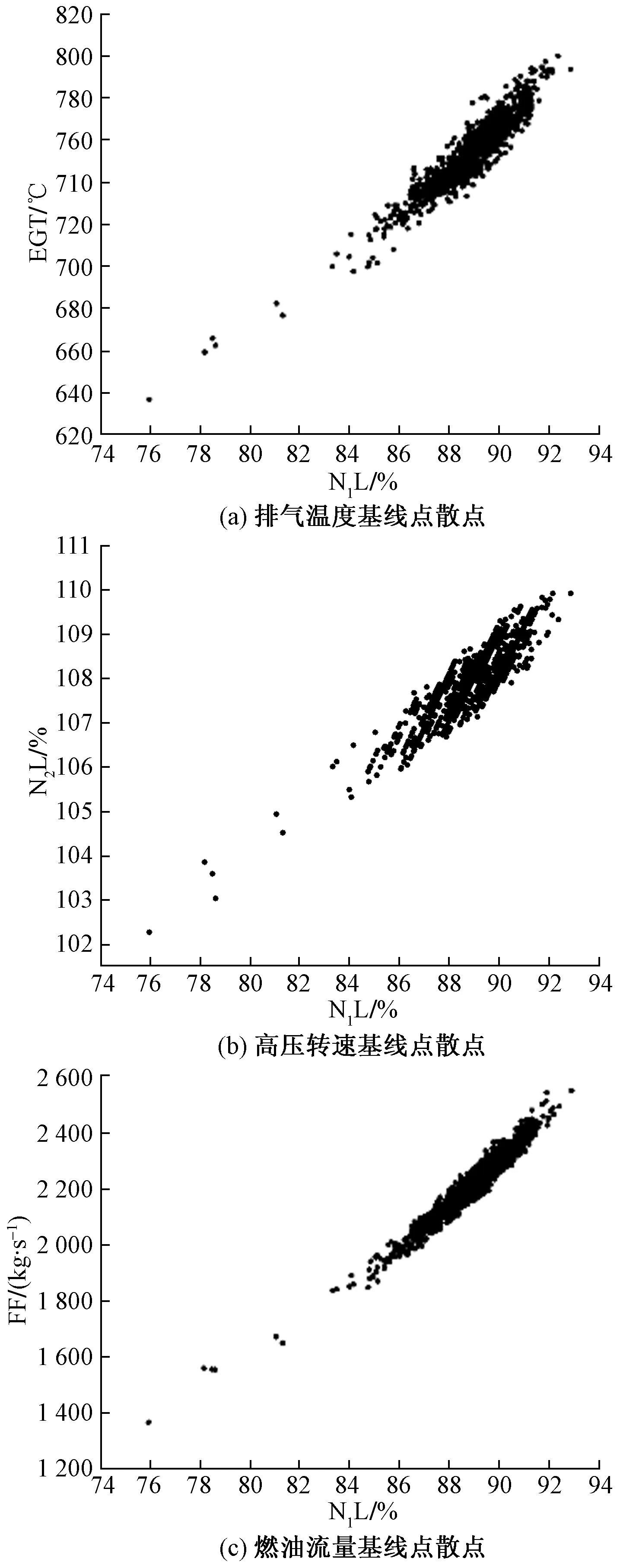
图1 基线点数据散点图
1.2 相关性分析
在相关性分析中,一般认为相关性系数低于0.3则被认为是弱相关,0.3~0.6被认为是中度相关,超过0.6则被认为是高度相关。对1.1节所选用的13种数据做相关性分析结果如图2所示。
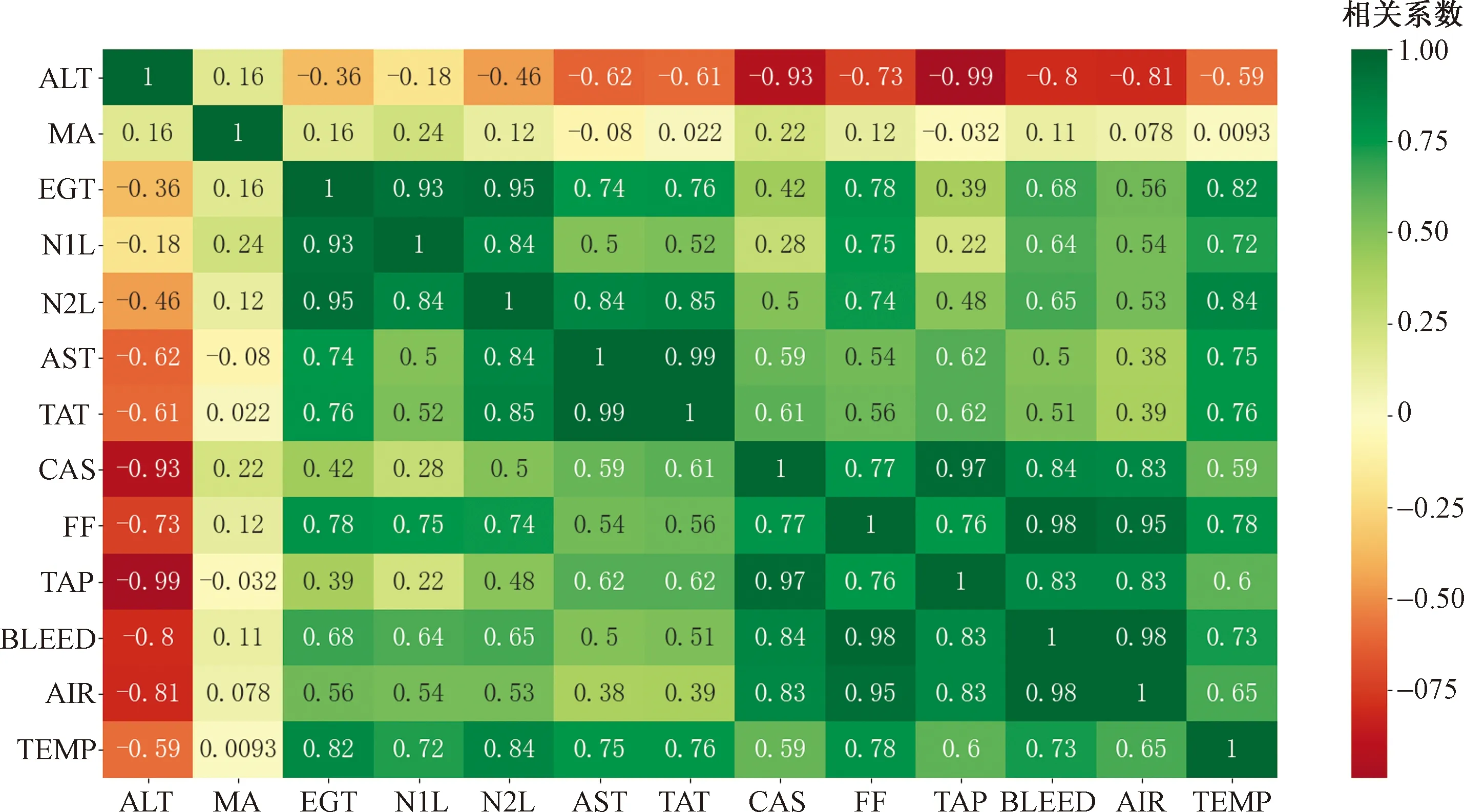
图2 相关系数图谱
以EGT基线模型为例,通过相关性图谱可以看出,与EGT高度相关的数据参数有低压转子转速、大气总温、大气静温。然而通过相关性图谱可以看出大气总温和静温有着高度相关性也可称为共线性,所以这里舍弃大气静温,选择相关性更高的大气总温。而以往的基线模型也基本考虑了这两个因素的影响。通过相关性图谱也可以明显看出引气和滑油温度对排气温度、高压转子转速和燃油流量也具有较高的相关性,所以不能忽视其对基线模型的影响,所以本文中亦引入了发动机引气量和滑油温度作为排气温度、高压转子转速和燃油流量基线模型的重要输入参数。
通过以上相关性分析,同时结合厂家给出的基线模型建议,确定了EGT、N2L和FF基线模型的重要输入参数有:低压转子转速大气总温、飞行高度、马赫数、引气量和滑油温度。并且通过下文的实例建模效果来看,在加入引气量和滑油温度之后建立的排气温度、高压转子转速和燃油流量基线模型具有更高的模型精度和泛化能力。
1.3 基线点数据预处理
根据航空发动机原理可知,同一台发动机在不同的环境条件下,其主要性能参数差别很大,所以建立基线模型的参数必须转化到标准大气条件下(P0=101 325 Pa,T0= 288.15 K)才能用于建立基线模型。根据相似原理,各性能参数相似换算公式为
EGTcor=EGTraw/(Tt2/T0)
(1)
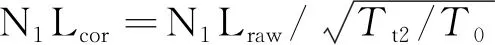
(2)

(3)
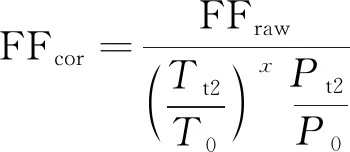
(4)
式中: N1L为低压转子转速;N2L为高压转子转速;Tt2为压气机进口总温;T0为标准状态大气温度;Pt2为压气机进口总压;P0为标准状态大气压力;x为与实际发动机有关的参数,一般由发动机制造厂商提供,这里x选取理论值0.5。
由于各种数据在量纲和单位上存在差别,所以需要对数据进行归一化处理以保证各参数对回归分析的影响程度一致,归一化公式为
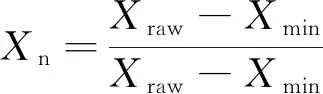
(5)
式(5)中:Xn为归一化后的数据;Xraw为原始数据;Xmin是数据中的最小值;Xmax是数据中的最大值。
至此,挖掘基线模型的数据预处理工作已经完成,下面将采用带交叉验证的网格搜索LightGBM算法对以上数据进行训练,来获取基线模型。
2 带交叉验证的网格搜索LightGBM算法
2.1 LightGBM算法
LightGBM算法是微软2017年提出的属于梯度提升决策树 (gradient boosting decision tree,GBDT)的一种基于直方图的分割算法,可用于做分类和拟合。相比于传统的XGBoost算法而言,在不降低准确率的前提下,不仅训练速度提升了10倍左右,而且内存的占用也下降到原有的1/3,还能有效防止训练的过拟合,由于速度的提升更适用于训练大量的高维数据[16-17]。
它是将弱学习器组合成强大的学习器的集成学习算法,算法采用基于Histogram的决策树算法把连续特征离散化,同时通过构造直方图来遍历数据并进行统计,以此寻找最优的分割点[18]。使用带有深度限制的Leaf-wise的叶子生长策略,每次迭代从当前所有叶子节点中,找到分裂增益最大的叶子节点进行分裂,降低误差来得到更好的精度[19]。LightGBM训练过程如图3所示。

图3 LightGBM训练过程
2.2 带多折交叉验证的网格搜索算法
2.2.1 网格搜索
在机器学习过程中,模型参数的设置非常重要,直接影响着训练结果,而在LightGBM的训练过程中需要设置很多参数,比如树的最大深度,每个决策树的最大叶子数量,学习率,特征选择,数据的随机采样,迭代次数,执行切分的最小增益,一个子叶上数据的最小数量等,都需要进行人工设置,然而由于参数较多,导致其参数可能的组合太多(LightGBM参数范围如表1所示),所以人工设置会导致其训练次数变多,费时费力。故而为了提高学习器学习的性能和效果,需要对其进行网格搜索,从而给学习机选择一组最优参数组合。
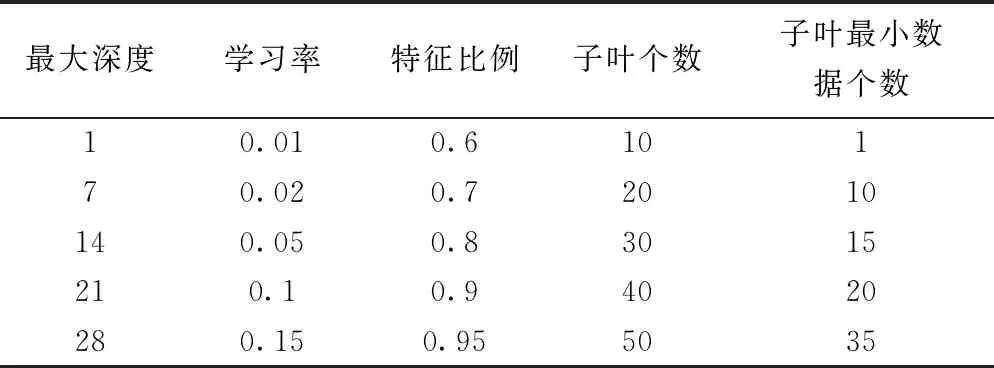
表1 LightGBM参数范围设置
对于需要设置的参数,网格搜索是将每个参数的所有可能的组合通过循环遍历,最终找到一个最佳参数组合,从而实现对所有可能的参数组合的运算。
2.2.2 多折交叉验证
目前评估机器学习模型的最好标准就是交叉验证,而传统的较为简单的交叉验证是将数据划分为训练集和验证集,然后使用验证集调整训练集训练出来的模型参数,并且还能对模型的泛化能力进行初步评估。这种简单的交叉验证方法就是随机将原始数据分为两组(训练集和验证集),虽然这种交叉验证方法操作简单并且容易实现,但是它并没有达到交叉的目的,因为它只是随机的将数据分组,然后进行训练验证,故而不太具备可信度,不能证明其模型的泛化能力强弱,所以文中采用多折交叉验证。
多折交叉验证基本原理如下:首先将原始训练集平分为N组,使其每一个子集都作为一次验证集,而其他的N-1个子集便作为训练集,这样就会得到N个模型,最终取每个模型参数的平均值作为其模型参数。基本原理如图4所示。
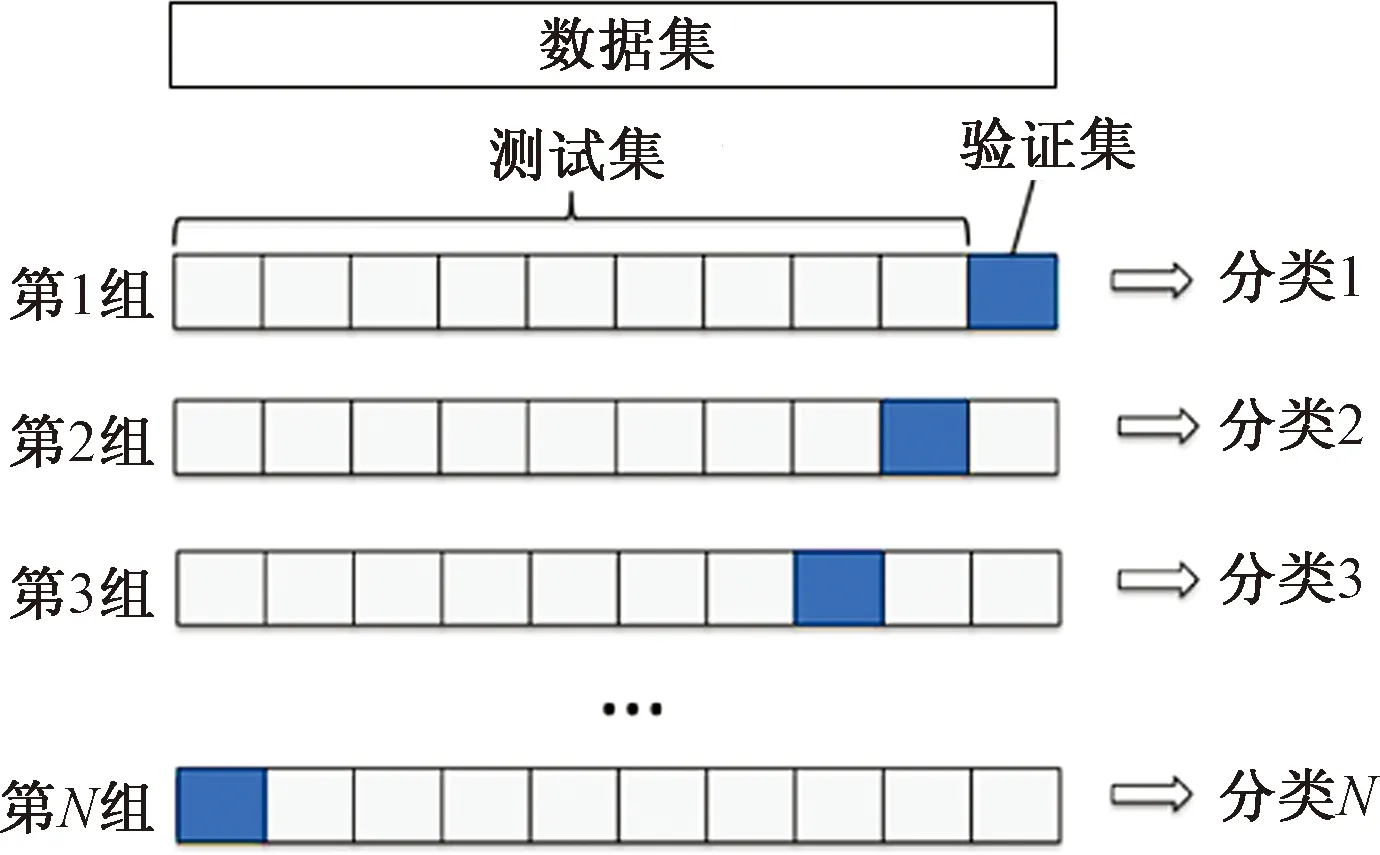
图4 多折交叉验证基本原理
2.3 基线建模步骤
利用带交叉验证的网格搜索LightGBM算法训练基线模型步骤如下。
(1)将筛选好的基础数据划分为训练集和验证集:训练集数据用来训练基线模型,验证集数据用来验证模型精度。
(2)对经过预处理的上述数据做归一化处理,目的在于避免各特征数据由于数量级的差别而影响基线模型精度。
(3)利用带多折交叉验证的网格搜索算法对LightGBM算法参数进行选择。
(4)将数据导入到优化好的LightGBM算法进行训练,得到最终的基线模型。
(5)利用验证集数据对训练好的基线模型进行验证。
3 实例建模及验证
以GE90-115B发动机为例,根据上文提取出来的基线数据进行建模,为了充分对比在输入参数中加入引气量和滑油温度对基线拟合效果的影响,首先将修正后的低压转子转速、大气总温、飞行高度和飞行马赫数作为输入参数,以排气温度为输出参数进行建模;后面再在这4个输入参数(修正后的低压转子转速、大气总温、飞行高度和飞行马赫数)的基础之上引入滑油温度、引气量作为输入参数进行建模。
选用平均绝对误差(mean absolute error,MAE)和对称平均绝对百分比误差(symmetric mean absolute percentage error,SMAPE)作为模型精度的评价标准,其定义式为
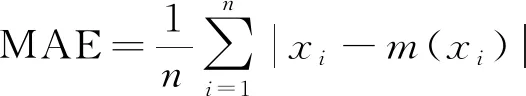
(6)

(7)
式中:xi是数据样本值;m(xi)是其对应的标准值;n表示样本容量。MAE和SMAPE的数值大小直接反映了基线模型的误差大小,MAE和SMAPE数值越小,则表示基线模型的整体误差越小。
3.1 基线建模实例
3.1.1 基线点数据样本获取
本次按发动机ACARS报文触发逻辑提取的QAR基线点数据共1 160组,提取的部分结果如表2所示。

表2 QAR提取数据的部分结果
3.1.2 基线建模
在上述的1 160组数据中随机选取1 118组数据作为训练集,用来训练基线模型,剩下的48组数据作为验证集。
通过相似修正,将提取的基线点数据修正到标准大气状态下的性能参数EGTcor、N1Lcor、N2Lcor和FFcor,并对数据进行归一化处理,修正公式和归一化公式见1.3节。
确定输入参数和输出参数,构造训练集和验证集。这里输入参数和输出参数的确立共分为3组,以便对比引气和滑油温度对基线模型的影响。3组输入方式下EGTcor的基线关系分别为
EGTcor=(ALT,MACH,TAT,N1L)
(8)
EGTcor=(ALT,MACH,TAT,N1L,TEMP)
(9)
EGTcor=(ALT,MACH,TAT,N1L,TEMP,BLEED)
(10)
对于高压转子转速和燃油流量的基线建模,只需将这3组中的因变量更改为N2Lcor和FFcor即可。
通过带交叉验证的网格搜索算法确定最佳的LightGBM参数,最终确定上述3种基线模型的LightGBM参数如表3所示。
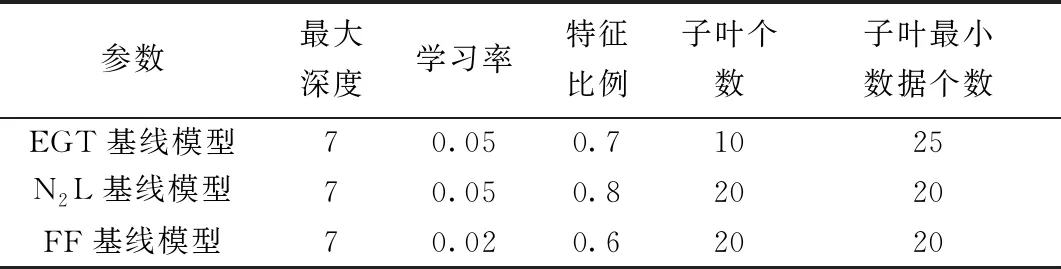
表3 Light GBM参数寻优结果
使用优化后的LightGBM对1 118组训练集数据进行训练,最终得到3种不同输入参数下的EGT基线模型,并用剩余的42组数据验证其模型的精度。
3.2 结果分析
分别以3组不同输入数据为基础的多参数EGT基线挖掘训练结果如图5~图7所示。
由图5~图7可以看出,在考虑滑油温度的影响后,模型精度略有提高,但效果并不是特别明显,但在综合考虑滑油温度和引气的影响后,EGT基线模型精度有了很大的提升,绝对误差保证在4以内。

图5 第一组输入方式在EGT验证集上的预测结果及误差

图6 第二组输入方式在EGT验证集上的预测结果及误差

图7 第三组输入方式在EGT验证集上的预测结果及误差
在考虑了引气和滑油温度的影响下对N2L、FF基线模型进行挖掘,其结果如图8、图9所示。

图8 N2L基线模型预测结果及绝对误差
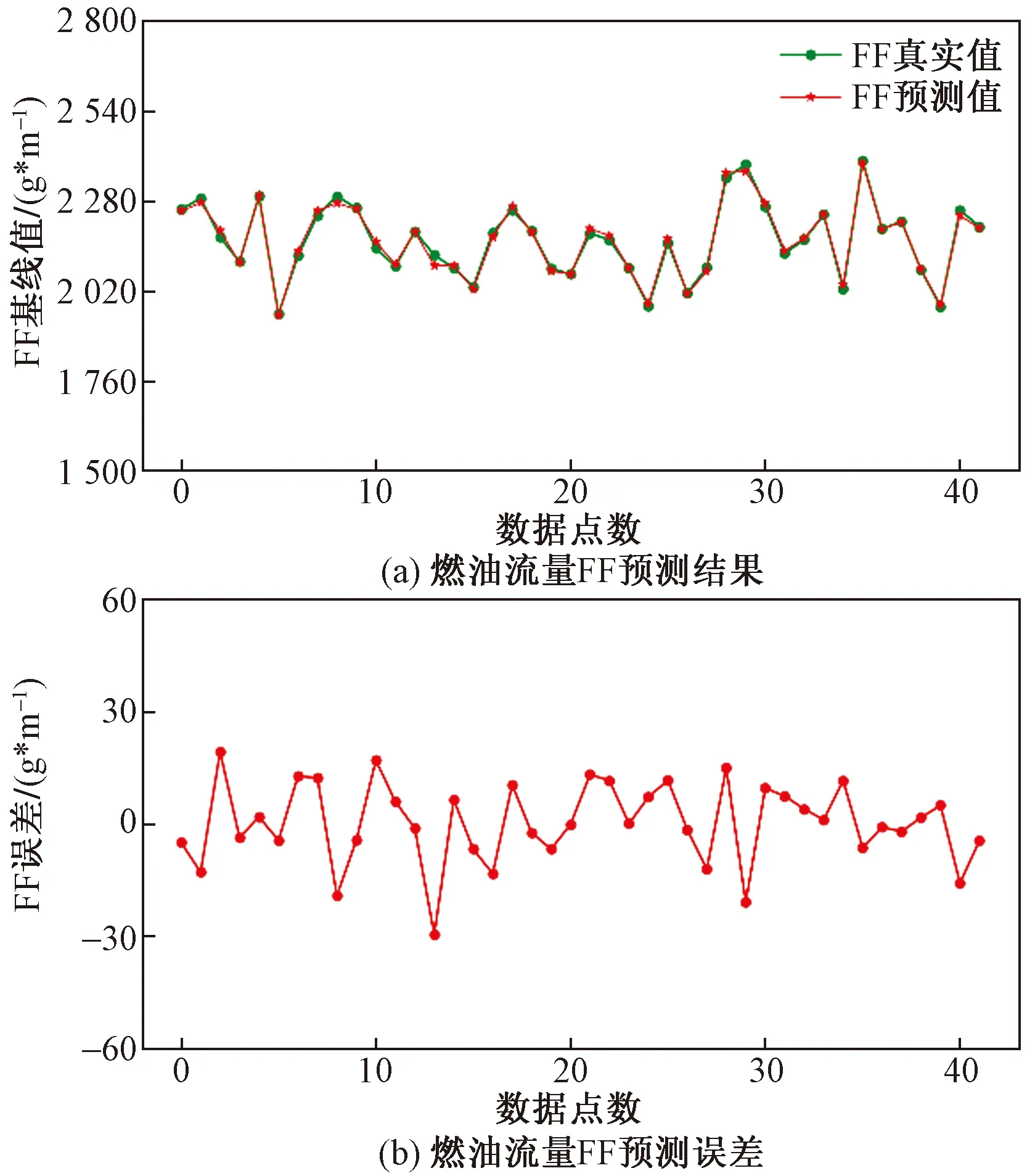
图9 FF基线模型预测结果及绝对误差
通过训练结果显示,当加入滑油温度和引气这两个影响因素时,预测精度有了很大的提高。训练所得的基线模型MAE和SMAPE如表4所示。
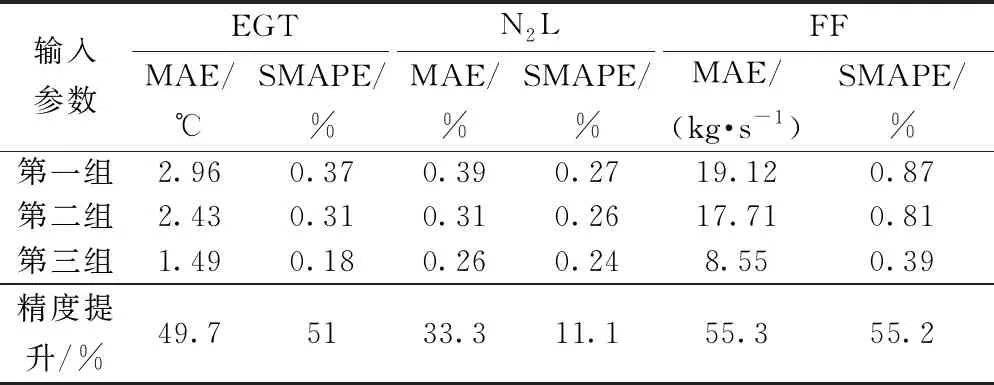
表4 3组输入方式所得MAE和SMAPE
以上采用LightGBM算法对3种不同输入变量的模型进行了拟合,在对误差结果进行分析后,可以发现绝对误差均在允许的误差范围之内,尤其在输入变量中考虑了滑油温度和引气的共同影响之后,训练出的基线模型精度有了大幅度的提高。通过图7~图9可以看出,EGT、N2L和FF最大绝对误差分别保持在了4、0.5、20之内,平均绝对误差MAE分别提升了49.7%、33.3%和55.3%,可见在输入参数中考虑到引气和滑油温度的影响之后使基线模型精度有了很大的提高。
4 结论
首先从QAR中提取数据,通过相关性分析确定了模型输入参数,并对其做了相似修正。之后通过带多折交叉验证的网格搜索LightGBM算法对3种不同输入变量组合进行基线挖掘,发现在考虑引气和滑油温度影响之后所得的EGT、N2L和FF的基线模型精度更高,EGT基线模型的平均绝对误差为1.49,N2L基线模型的平均绝对误差为0.26,FF基线模型的平均绝对误差为8.55,相比之前没有考虑引气和滑油温度时,EGT、N2L和FF的基线模型精度分别提升了51%、11.1%、55.2%,拥有很好的基线模型精度,为以后的航空发动机基线建模提供了新的方法和思路。
猜你喜欢
汽车电器(2022年9期)2022-11-07
导航定位学报(2021年5期)2021-10-13
空间科学学报(2021年6期)2021-03-09
科学导报·科学工程与电力(2019年41期)2019-10-21
中国外汇(2019年11期)2019-08-27
导航定位学报(2019年2期)2019-06-06
舰船电子对抗(2019年6期)2019-04-27
山东工业技术(2014年8期)2014-12-25
中国信息化·学术版(2013年4期)2014-01-03
中国科技术语(2012年5期)2012-12-28
