
基于特征加权的分布式大数据相关性挖掘方法
2021-11-17 08:37戴惠丽王敬宇
计算机仿真 2021年6期
戴惠丽,王敬宇
(1. 闽南科技学院,福建泉州362332;2. 北京邮电大学,北京 100876)
1 引言
数据挖掘是一种通过数据计算来发现数据内部潜在规律和特征的过程,是目前人工智能和数据库建设领域的研究热点[1,2]。数据挖掘技术的发展也带来了很多新的问题和挑战,在海量数据背景下,对于数据挖掘技术的要求已经不仅仅满足于数据相关性挖掘的准确性,还需要保证数据相关性挖掘的效率与实际效果。为此,相关学者对数据相关性挖掘方法进行深入研究。
米捷和刘道华[3]提出基于语义关联性特征融合的大数据挖掘方法,对高位相空间进行重构,在重构空间中提取数据语义关联特征,并进行其进行自适应训练,得到训练后的测试集。运用模糊C均值算法融合处理数据的关联特征,实现数据挖掘的目的。实验结果表明,该方法具有数据挖掘准确率较高的优势,但是在面向海量数据源时,不能对任务进行快速分配,存在数据相关性挖掘时间较长的问题。毛晓菊[4]提出基于模糊关联规则的海量数据挖掘方法,依据模糊理论对海量数据进行模糊化处理,组建数据库,对其中的数据进行聚类与离散化处理,根据关联规则实现海量数据挖掘。实验结果表明,该方法能够有效降低数据挖掘所占内存,并且数据挖掘的支持度较高,但是由于各个节点之间的任务是随机分配的,使得不同节点之间的计算时间差别较大,进而导致整体挖掘时间较长,挖掘效率不高。孙红和李存进[5]提出融合遗传算法和关联规则的数据挖掘改进方法,将改进的遗传算法融入到关联规则中,基于遗传算法的全局搜索能力,实现数据挖掘效率的提升,同时,融入亲密度原理提高数据挖掘的可靠性。实验结果表明,该方法具有较高的鲁棒性,但是任务分配均匀程度较差,在一定程度上影响了挖掘方法的整体性能。
针对传统方法存在的问题,设计一种基于特征加权的分布式大数据相关性挖掘方法。该方法通过软子空间聚类,获取加权聚类中心与权值。在此基础上,通过MapReduce编程模型,对每个数据簇的聚类中心进行反复扫描,确定对应的子集,计算样本到聚类中心的距离,并在此过程中去除孤立点,解决了传统挖掘方法总体收敛速度较低的问题,从而提高了数据相关性的挖掘效率。
2 基于特征加权的分布式大数据相关性挖掘
2.1 软子空间聚类
为了提升数据处理的高效性,将批量处理聚类算法与同增量学习策略相结合,提出子空间聚类算法。子空间聚类算法主要是依据数据的原始特征空间,将其进行分割从而得到不同特征子集。子空间的聚类实际上是在线学习的一种策略,为人们提供了很好的大规模数据处理方式。在线学习具体可以分为“硬”竞争学习和“软”竞争学习,学习的过程中,WTA(Winner Take All)竞争学习理论规则针对数据集中新输入样本的获胜节点只有一个,其聚类的中心递归方程可以表示为
vi*(t)=vi*(t-1)-η(t)×D(vi*(t-1),xNt)
(1)
其中
i*=arg mind(vi(t-1),xNt)
(2)
式中,vi(t-1)表示聚类中心;xNt表示数据样本;d(vi(t-1),xNt)表示聚类中心和数据样本之间的距离;D(vi*(t-1),xNt)表示度量间距;η表示学习速率,该速率会随着时间的延长而逐渐减少,引入该参数的主要目的是为了防止目标接触出现震荡,并保证算法的收敛。由于目前的软子空间聚类都是基于单个目标函数对聚类评价准则进行优化,而聚类算法的真正目的是寻找数据内部的潜在结构或规律,按照这种潜在的相似性程度对数据样本进行聚类划分,使经过划分后得到的数据簇类内部更加紧致,而类间更加分离[6]。从某种意义上说,所提出的在线软子空间聚类算法是基于“软”竞争学习理论,将软子空间内高维度、大规模的数据进行分割,得到若干个数据子块,子块的大小是由内存和数据流速度所决定的,将子块的相关统计信息进行处理,形成加权聚类中心,并利用隶属度函数求解出聚类中心的权值。
2.2 选择特征加权
根据软子空间内数据的聚类结果,进行特征加权选择。特征加权选择是机器学习与数据相关性挖掘研究中的经典问题,随着高维特征和大规模数据的出现,对于特征加权选择来说,精度已经不能满足实际的需求,因此,需要对其进行综合化和多样化的改进[7]。通过对大量的特征加权选择方法进行分析后,得到特征加权选择技术框架,如下图1所示。

图1 特征选择技术框架
根据图1可知,在特征选择的过程中,从原始特征集合中,依据一定的规律或规则生成的某些特征子集,可以称之为生成策略;通过评价准则对特征子集的相关性进行评价,从而判断生成的特征子集是否合理[8];停止条件主要判断特征子集是否符合起始定义的要求,在结论验证中需要验证相关特征子集的有效性。
在特征选择方法中存在很多选择性,随着特征选择技术向机器学习方面的扩展,可以选择不同的学习算法对数据库的样本进行特征挑选,以便选出比较合理的特征子集。再根据数据库中训练数据集的标记使用情况,将特征加权选择算法进行进一步划分[9]。一般情况下,其可以划分为有监督、无监督和半监督三种算法,这三种不同类型的算法区别在于使用数据时,对于数据的处理侧重点不相同。考虑到本文研究的实际情况,选择了过滤型方法,这是因为其评价标准并不会过分依赖于分类器,而是更加依赖于数据特征本身携带的信息和规则。
在特征选择过程中,将信息和规则视为互相独立的存在,并通过某种搜索策略,将合理的特征子集选择出来,将训练集与全部特征进行输入,根据数据集本身各个特征的评价标准来构建相应的特征子集[10]。通过特征空间搜索机制得到特征子集与特征评价标准,并将特征评价结果输入到特征空间搜索机制中,由此得到训练集、特征子集和测试集,共同构成数据特征。
2.3 设计分布式大数据相关性挖掘方案
由于数据的复杂性不断提高,大数据相关性挖掘的难度也在不断加大,传统相关性挖掘算法在有效的时间内无法提供准确的计算结果[11]。目前,云计算的飞速发展为数据相关性挖掘提供了一定的优势,对于分布式大数据来说,云计算平台的分布式存储、分布式计算和数据的融合处理,在相关性挖掘的过程中会将计算任务进行分配,保证海量数据在较短的时间内完成计算,并保证其计算过程的扩展性。
在传统的分布式大数据相关性挖掘过程中,任务的分配机制为随机分配,没有考虑不同任务的计算量差异。在初始化阶段,对整个数据集进行随机抽样,在迭代阶段选择合适的聚类中心,并替代当前几何中表现不好的样本点。这样一来就会导致各个节点之间的计算时间相差较大,降低挖掘方法的总体收敛速度。因此,本文在设计分布式大数据相关性挖掘方案时,主要依托MapReduce编程模型,对每个数据簇的聚类中心进行反复扫描,确定对应子集,并在子集上计算样本到聚类中心的距离,在去除孤立点的同时进行重新划分,并对算法的并行化进行设计[12]。
由于设计的相关性挖掘算法是针对分布式大数据而言的,首先数据是分布式存储的,数据经过预处理之后执行后续的分布式算法,经过频繁项集计算后,MapReduce任务会通过某数据集扫描实现所有项,并执行并行化的数据统计,数据重新排列并分割,通过后缀模式的转换将原始的数据分割节点独立计算,形成子事务几何。主要作用是独立进行数据的相关性挖掘,并保证结果的准确性,得到计算量的估值与分组,再次经过局部计算,最后得到汇聚结果。算法的示意图如图2所示。

图2 分布式大数据相关性挖掘步骤
图2中,当分布式计算中的数据成为子数据集后,HDFS文件系统在Hadoop平台中以64M为单位给节点分配数据,并通过合并较小的数据提高存储效率。确定Map的任务量之后将其输出,输出内容是后续程序的数据输入值。所提相关性挖掘方案的改进重点就是分配机制的改进,受Hadoop的Shuffle均衡分组机制的影响,数据挖中的各个节点都会收到不同的事务分组,在这种均衡机制下,多个分组将依次有序输入。当新输入事务的key发生变化时,对已建立的FP树进行条件FP树挖掘,计算完成后获得其频繁项集,并清空FP树,开始新项的FP树建立及频繁项集挖掘,直至完成所有频繁项集的挖掘。至此完成基于特征加权的分布式大数据相关性挖掘方法设计。
3 实验分析
为了验证设计的基于特征加权的分布式大数据相关性挖掘方法在大数据挖掘中的性能表现,需要将设计的挖掘方法与传统基于语义关联性特征融合的大数据挖掘方法(文献[3]方法)、基于模糊关联规则的海量数据挖掘方法(文献[4]方法)以及融合遗传算法和关联规则的数据挖掘改进方法(文献[5]方法)进行比较。
3.1 实验环境与参数设置
首先对实验环境参数进行设置,参数与变量定义如下表1所示:

表1 实验环境参数
实验集群选择的是9台高性能的计算机,其中包含1台管理节点,8台计算子节点,以上实验集群的相关节点中,其配置均为4GB内存,Intel CoreTM i7-3770 CPU@3.40GHz型号CPU,主板为Intel Q77,操作系统为Ubuntu 14.04,Hadoop发行版本为0.23。在本次实验中,采用的是公共数据源,并将此数据源扩展至事物数为105,2×105,4×105,8×105四个级别的测试数据集中,将这四个数据集记作D1、D2、D3、D4,选择四个数据集的D1数据集进行详细数据频次分析,分布情况如下图3所示:

图3 数据集D1中事物项的频次分布情况
对以上四个数据集进行特征统计,得到事务数据集特征统计结果如下表2所示:
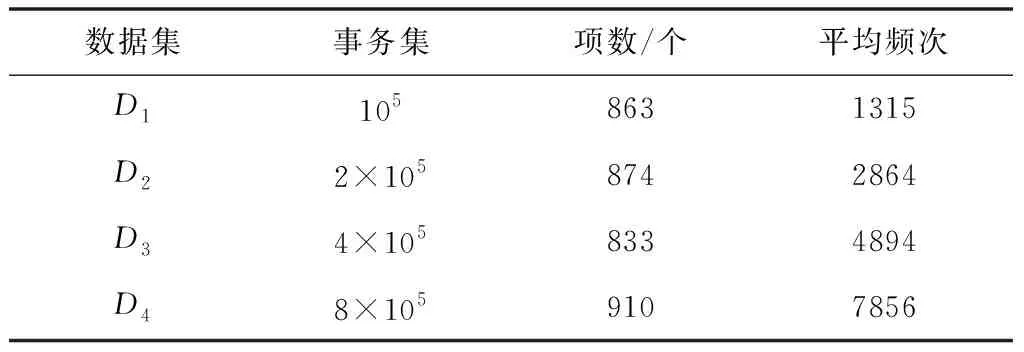
表2 事务数据集的特征统计信息
在上述实验环境设置条件下,对设计的数据挖掘方法和传统数据挖掘方法进行实验,并对实验结果进行分析和研究。
3.2 实验结果与分析
1)数据挖掘计算时间对比
为了直观看出不同挖掘方法的性能,统计了在同等配置下不同数据挖掘算法对不同节点的计算时间,结果如下图4所示:

图4 不同方法对不同节点的计算时间差异
图4中,横轴表示的是不同的计算节点,纵轴表示的是计算时间。从图中能够明显看出不同挖掘方法在相同配置下对不同计算节点计算时间的差异。由于传统数据挖掘方法采用的随机任务分配机制使得不同节点之间的计算时间差别较大,而并行任务的完成时间是由节点中的最大完成时间决定的,这在一定程度上使挖掘方法的效率有所降低。而设计的基于特征加权的分布式大数据相关性挖掘方法,能够利用各个分组的任务计算量对信息进行预估,从而完成任务均衡分配,使得各个节点的任务计算时间基本稳定在5-10s之间。并且所设计方法的计算时间明显低于传统方法,说明该方法的数据相关性挖掘效率更高。
2)任务分配均匀度对比
为了明确分布式数据各个节点的任务分配均匀程度,可以通过下式进行计算
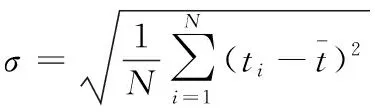
(3)

利用式(3)计算不同方法的节点任务分配均匀程度,结果如图5所示。

图5 不同方法节点任务分配均匀程度对比
分析图5可知,当测试时间低于10s时,不同方法的节点任务分配均匀程度呈现出持续增长的趋势,随后变化趋势趋于平缓。对比传统方法与所设计方法可知,所设计方法的任务分配均衡系数明显高于传统方法,其均衡系数最高值接近1.0,说明该方法能够实现对节点任务的均匀分配。
综上实验结果可知,由于传统方法中任务为随机分配,并不存在任务量的计算,因此在支持度阈值较小的情况下,计算任务量比较大,时间标准差也比较大;当支持度的阈值增大后,标准差逐渐降低,
说明传统方法的效率受支持度的阈值影响较大。根据最终的对比结果显示,所设计方法在分布式大数据相关性挖掘过程中的计算时间与任务分配均衡性均优于传统方法,说明该方法具有一定的优势性,更适合应用于数据挖掘领域。
4 结束语
为了解决传统方法计算时间较长,任务分配均匀程度较差的问题,研究了基于特征加权的相关性挖掘方法,针对传统方法在挖掘过程中存在的弊端,进行了一系列的改进优化,重新设计了相关性挖掘的方案,优化了任务分配机制,提高了相关性挖掘方法的效率。通过实验验证,所设计方法在挖掘效率与任务分配方面均具有明显的优势,说明该方法具有可行性。
大数据相关性挖掘是一个新兴的研究领域,互联网时代的数据快速膨胀,使数据挖掘的意义逐渐凸显出来,在数据挖掘方法中对各个节点的负载进行均衡分配,能够实现挖掘效率的最优化。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中学生数理化·高一版(2022年1期)2022-04-05
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
科学与财富(2021年35期)2021-05-10
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
数学教学通讯·初中版(2015年5期)2015-06-17
都市丽人(2015年4期)2015-03-20
