
基于模式识别的分布式存储信息一致性控制
2021-11-17 08:37卫朝霞
计算机仿真 2021年6期
卫朝霞,徐 艳
(四川大学锦城学院,四川 成都 611731)
1 引言
大型的分布式存储系统中,通常将同一数据的不同副本存储在多个异地数据库上,由于部分副本数据库是可移动的,很难保证可以实时更新最新数据信息,如何保证异地数据库中不同副本的数据一致性已成为开发高效分布式信息存储机制必不可少的关键技术。
针对这一问题,相关科研人员提出了几种分布式存储信息一致性控制方法:文献[1]运用值计算的方法控制分布式存储机制传输数据一致性,通过构建大规模异地数据传输架构,对数据包中的数据进行分块处理和值计算,得到值和序列号,对数据包是否连续进行判断。文献[2]重新定义了条件函数依赖和微函数依赖,应用依赖控制数据一致性,确定了依赖集合,发现违反依赖的错误数据和修复错误,并对其中两个步骤展开了深入的研究。
但是以上两种方法还存在一些问题,主要有两个方面:问题1:数据存储:传统的数据存储方式,需要设立1个或者多个字段用于记录数据的更新记录,大大增加了存储的开销;问题2:数据传输:传统的数据一致性控制方法对网络通信开销的需求比较大,一般的互联网环境很难满足。
基于此,本文提出了一种基于模式识别的分布式存储信息一致性控制方法。模式识别相对于其它控制方法特征分类更精准,安全性更高,开销成本更低,同时结合数据全相关的一致性更新技术,可以有效并且在节约存储开销的前提下完成对分布式信息存储机制的一致性控制。
2 模式识别下分布式存储信息一致性控制
2.1 分布式信息存储机制组建
分布式信息存储机制由主副本两部分组成:
1)副本移动端
如PDA、手机、笔记本电脑等是可进行移动的便携电子设备,其数据库为副本数据库[3-4]。
2)主本固定端
有固定的数据存储设备,安全性、可靠性极高。具有可用来传输数据的通信接口,可以和副本数据库进行数据传输,其数据库为主本数据库。
分布式信息存储机制如图1所示。
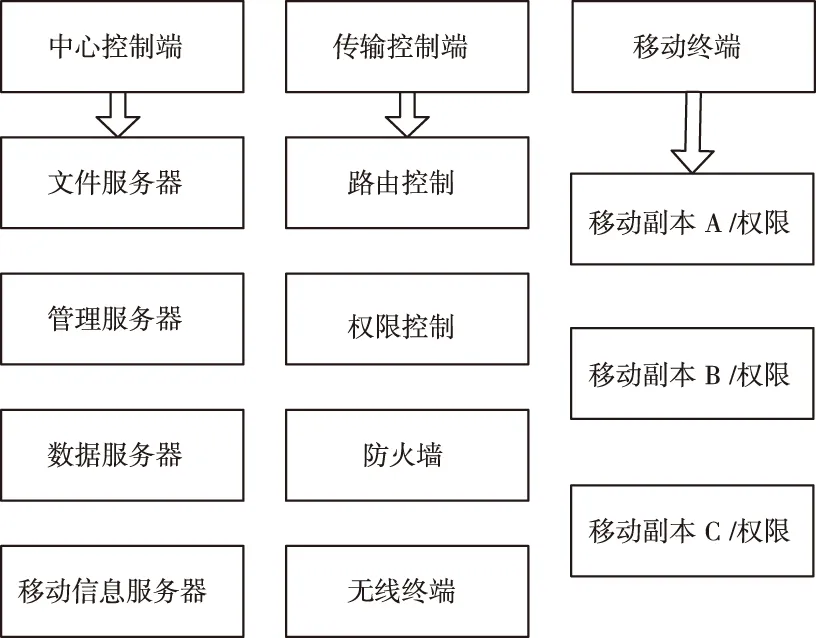
图1 分布式信息存储机制
该分布式信息存储机制分为3层结构:
结构1:中心控制端
中心控制端是主本数据库所在的固定端。采集分布式信息存储机制所有的数据集,可以操控整个系统,以及对副本的权限进行设置。
结构2:传输控制端
传输控制端对主副本各节点之间的数据信息进行传输,并判断其使用的广域网还是企业内部的局域网或者企业网。
结构3:移动端
移动端中的各个副本由于是可移动的,工作环境复杂多变,而且是不可预测的,很难具备实时更新数据的条件,但分布式信息存储机制中的主本数据处在动态变化之中,而且每个数据的副本数量多。
2.2 主副本数据更新过程分析
为了提高分布式信息存储机制的存储效率、时效性、可用性以及可靠性,需要采用主副本的方式来存储信息。建立副本存储机制不但可以提高数据的可靠性、安全性,而且还可以大大提高整个系统的存储效率。但是副本也需要占用一部分的存储空间,增加了整个分布式信息存储机制的复杂性。对副本的实时更新成为控制分布式信息存储机制一致性的重要研究内容。图2为产品数据规划图,以某企业B为例,达到分布式存储产品数据一致性更新的目的。

图2 产品数据规划图
在图2产品数据规划图中,企业B拥有零件Pi的生产权限,下属部门有B1和B2,B2部门拥有零件Pi的数据主本数据以及研发设计权限。有关零件Pi的主本信息如结构化数据、有关零件Pi的全部文档信息存储在企业B的数据库中;一些副本信息如非结构化数据存储在企业B与其它企业A、C、F的分布式存储系统中。为了更好的实现信息一致性控制,可以借助文件指针功能把企业B数据库中的主副本信息联系在一起,实时更新主副本数据以达到主副本信息一致性控制的目的。为了防止数据丢失或损坏,将数据分布式存储在企业A的数据库中,当做零件Pi的备份数据。则企业B对零件Pi的数据进行更新的同时也要对企业A的数据库中有关零件Pi的数据进行一致性更新。企业C和企业F是零件Pi的相关配件企业,如子装配件、套用件、装配基准件等可能来自企业C或者企业F。所以当企业B有关零件Pi的数据发生变化时,相应的也要及时更新企业C和企业F的次级库的产品数据。
由于零件Pi由企业B生产研发,那么企业B所拥有的有关零件Pi的所有产品数据都是主本数据,而企业A是该数据的备份存储部门,企业C和企业F是相关配件企业,所以企业A、C、F中有关零件Pi的数据是零件Pi数据的副本。
如图2中的部门B2是零件Pi的设计研发部门,B1是零件Pi数据备份部门,对于企业B内部的多个设计或者制造部门,由于这些部门使用的是企业内部的局域网或者是企业网,使用的是同一个网络地址,所以企业B的所有部门都拥有零件Pi的主本数据信息,并且各部门之间不存在数据一致性要求。
在企业B有关零件Pi的主副本数据存储方式中,对于零件Pi的数据需要在中心库、次级库和数据相关性的其它次级库重复更新设置,这种分布式存储信息的方法较为复杂,但是安全性极高。每个企业节点都有零件Pi的副本数据,当其中某一个节点出现故障时,不会影响其它企业继续使用这些数据,而且每个节点使用的都是企业内部的局域网或者企业网,不使用广域网,相对成本也较低。因此采用数据全相关的一致性更新技术,可以满足异地企业之间动态联盟的数据管理要求。
在这种分布式信息存储机制中,拥有产品数据主本的企业对数据进行更新和维护,以保证实时更新其它相关企业的数据。当数据主本发生改变时,数据全相关的一致性更新机制将所有有关产品数据的企业节点库中的数据副本进行更新。
2.3 模式识别下最优特征子集选取
模式识别技术在数据的处理、特征的提取等方面有一定的优越性,且在各行业中应用广泛,因此本文利用该方法提取数据特征信息。
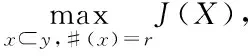
特征选择方法一般有筛选和复选两种。筛选与复选的方式有所不同,筛选中判别函数J(X)所得到的最优特征子集只依赖于训练样本,而复选主要是依据分类器的学习算法在不同特征子集上的正确识别率,来判断所选子集是否为最优特征子集。那么可知训练样本的统计特性同时影响筛选和复选的结果,并且测试样本的学习算法复选的结果也有一定的影响,复选在实际的应用中会比筛选难的多,所以应用的也比筛选少。
无论用筛选或者复选哪一种方法,在d中选取r的最优特征子集最简单也是最常用的方法就是衡量每一个特征子集,从中找出使J(X)可以达到最大值的那个特征子集。
为了解决这个问题,通过模式识别法来获取最优特征子集,找出可以构成最优特征子集所需的单个特征。虽然这种方法不能保证找出的就是最优特征子集,或者说找到的就是次优特征子集,但是由于这种方法计算量非常的小,在实际应用中也是比较常见的。本文通过大量分析得出,在所有d没有任何关系时,单个最优特征所构成的子集未必是最优特征子集,但是自动文本分类的诸多实验数据说明,由单个最优特征构成最优特征子集依然是应用最多的一种方法。在大量提取单个最优特征的算法中,模式识别最为有效。
在从d中选取r个特征的计算如下:
d中的每个特征f与类别标号的互信息用式(1)表示为

(1)
其中,f的观测值用x表示,x的类别标号用ϖ表示。
将互信息最大的r个特征选取出来,构成所需的最优特征子集,以便接下来对分布式存储信息进行一致性控制。
3 分布式存储信息一致性控制体系
3.1 数据操作模型和定义
将数据模型定义比较常见的二元组(ID,DataSet)。ID可以表示其中某一个数据项,也可以表示多个数据项结合起来所构建的,是数据库中每组数据独有的标识;DataSet表示与ID相对应的某一个数据集合。
对数据库中的数据进行操作主要有添加、修改、删除三种。对数据进行这三种操作所产生的数据集就是结构序列,为了实现计算机编程计算,将这三种操作用形式化表达为:
1)ADD(ID,DataSet),对ID所对应的数据项中增加一个DataSet
2)DELETE(ID,DataSet),对ID所对应的数据项中删除DataSet;
3)MODIFY(ID,DataSet),修改ID所对应的数据项DataSet。
对同一个DataSet执行多次重复的添加、删除和修改,只有第一次操作对数据产生实际改变。
3.2 数据操作构成的结构序列
当对系统中的数据进行添加、删除或者修改时,操作记录会被记录在分布式信息存储机制的结构序列[5]中。结构序列由以下三种格式构成:
1)(“+”,ID,DataSet):对ID添加了一个DataSet;
2)(“-”,ID,DataSet):对ID删除了一个DataSet;
3)(“`”,ID,DataSet):对ID修改了数据DataSet。
结构序列仅记录对数据产生实际改变的操作,并且只有提交对数据的操作,使数据发生改变,操作记录[6]才会被记录在结构序列中。如果对一个数据项添加或者删除一个已经存在的数据时,数据项不会发生任何的改变,也不会有操作记录,更不会被记录在结构序列中。这样不仅减少了存储机制的存储开销,而且减少了对系统数据的误操作,保证了系统数据的安全性。如果要修改其中某一个数据项,可以通过先在系统中删除这个数据项,再添加新的数据项来实现。
在对系统中数据进行一致性控制时,整个结构序列会被分为n个序列域。在同一数据库中,一个序列域可以包含数据一致性控制间隔中对数据操作产生的所有结构序列条目[7]。序列域只有在本地节点中创建,如果要与其它节点进行数据一致性控制,一定要在发送到其它节点数据库之前关闭。在数据一致性控制完成后,会有新的序列域产生,因此,结构序列也可以说是本地节点的序列域与其它节点的序列域的集合。
在整个分布式存储机制中,已知所有主副本数据库,也就是所有节点数据库的版本状态,所有的版本状态可以通过状态向量[8]体现并记录,记录格式如表1。
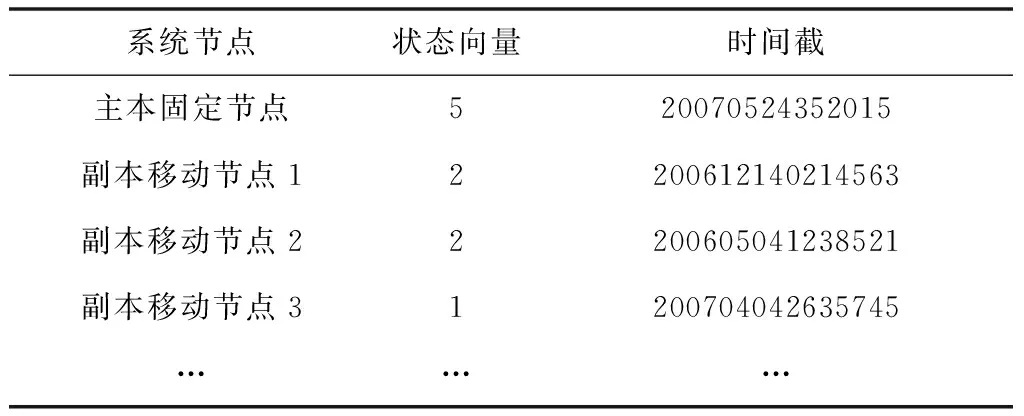
表1 状态向量的记录
状态向量可以用来表示和记录整个分布式信息存储机制中所有的主副本数据库,也就是已知节点数据库所处的版本集合,在分布式存储信息一致性控制中是数据库状态的主要参考,有着不可或缺的作用。
3.3 分布式存储信息一致性控制实现
在对分布式信息存储系统的两个节点进行数据一致性控制时,可以通过对比分析两个节点数据库的状态向量,尽可能选择少的信息进行传输,以减少系统的工作量。
企业B的状态向量中包含了其副本数据企业A、C、F的状态,并同时体现在企业B的数据集中。在完整的分布式信息存储机制中,每个节点数据库的状态向量是递增的,如果企业A的状态向量值大于企业B的状态向量值,说明企业A拥有的数据信息要比企业B的新,所以,要把相应的数据集发送给企业B,例如企业A的状态向量是3,企业B是2,那么企业B会接收到来自企业A状态向量为3所对应的所有数据集。当企业A、B中所有数据集的状态向量完成对比后,企业A就可以得到所有状态向量值大于企业B的数据集清单[9],并通过网络传输给企业B。
企业A利用模式识别技术扫描整个数据库,将所有需要发送的数据集按r分类,否则可能导致数据无法被正确同步,然后将完成分类的数据集发送给企业B,企业B在接收到这些数据集后,后台程序对整个数据库进行扫描对照,并将相应的数据操作对企业B的主本数据库进行更新,同时把数据集添加到本地数据库中,使接收到的数据集只有对本地数据产生实际的改变才会被写入,否则将不会被写入。
不同企业之间数据集顺序[10]的不同不会影响到分布式信息存储机制中主副本数据之间的一致性控制。因为对于每一个数据项来说,在本地数据集进行更新时,与该数据项有关的信息是否可以被添加到本地数据库中,与其它数据项无关,即使该数据项的内容在两个数据库中的顺序是完全不同的,最终也能实现一致性控制的目的。
4 仿真研究
为了验证本文方法对分布式存储信息一致性控制的综合有效性,进行仿真。将本文方法与文献[1]方法和文献[2]方法对比,以分布式存储信息一致性控制的准确性和耗时为实验指标进行测试。
首先对准确度进行测试,依次向系统写入300M、500M、1G、2G、3G、5G的数据,结果如表1所示,其中,J代表数据文件大小,D表示主本数据,R表示副本数据,A表示实际一致情况,Z表示本文方法测试结果,F表示文献[1]测试结果,X表示文献[2]测试结果,而表中的Y代表测试结果一致,N代表测试结果不一致。
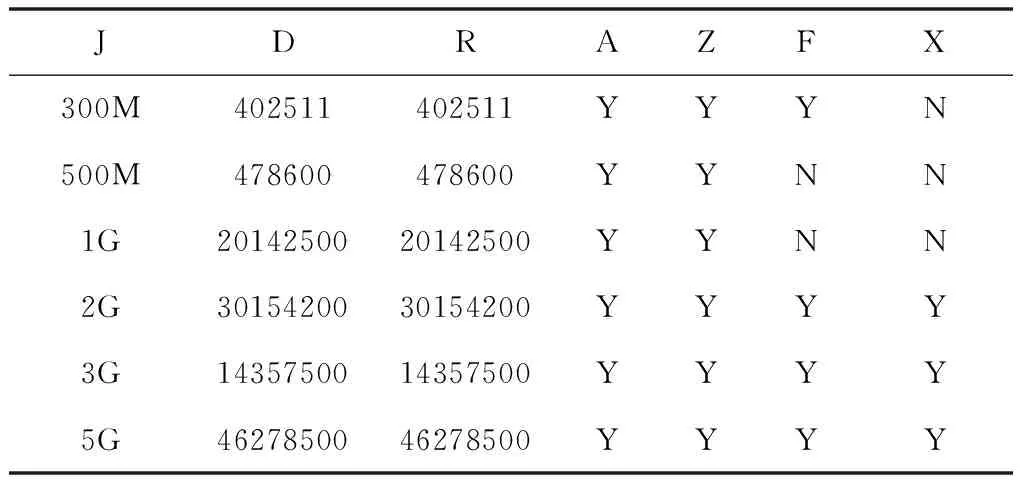
表2 三种方法对分布式存储信息一致性控制测试结果
分析表1可知,本文方法测试结果与实际结果一致,而文献[1]和文献[2]方法都存在数据错误的情况,说明本文方法在控制分布式存储信息上准确度更高。
其次,使用三种方法对综合数据库和企业数据库再次进行一致性控制准确度测试。综合数据库通过信息检索和机器学习所得,二者均为大规模数据库。结果如图3所示。

图3 综合数据库和企业数据库准确度测试结果
分析图3可知,不管是综合数据库还是企业数据库,本文方法在控制分布式存储信息一致性上准确度一直最高,而文献[1]方法和文献[2]方法对综合数据库的一致性控制准确度相对较低,对企业数据库的一致性控制准确度明显降低,这是因为本文使用了模式识别提取出最优特征子集,使得一致性控制结果更优,同时适用性更强。
在上述实验的基础上,给出本文方法、文献[1]方法和文献[2]方法对不同数据库进行一致性控制的耗时,结果如图4所述。
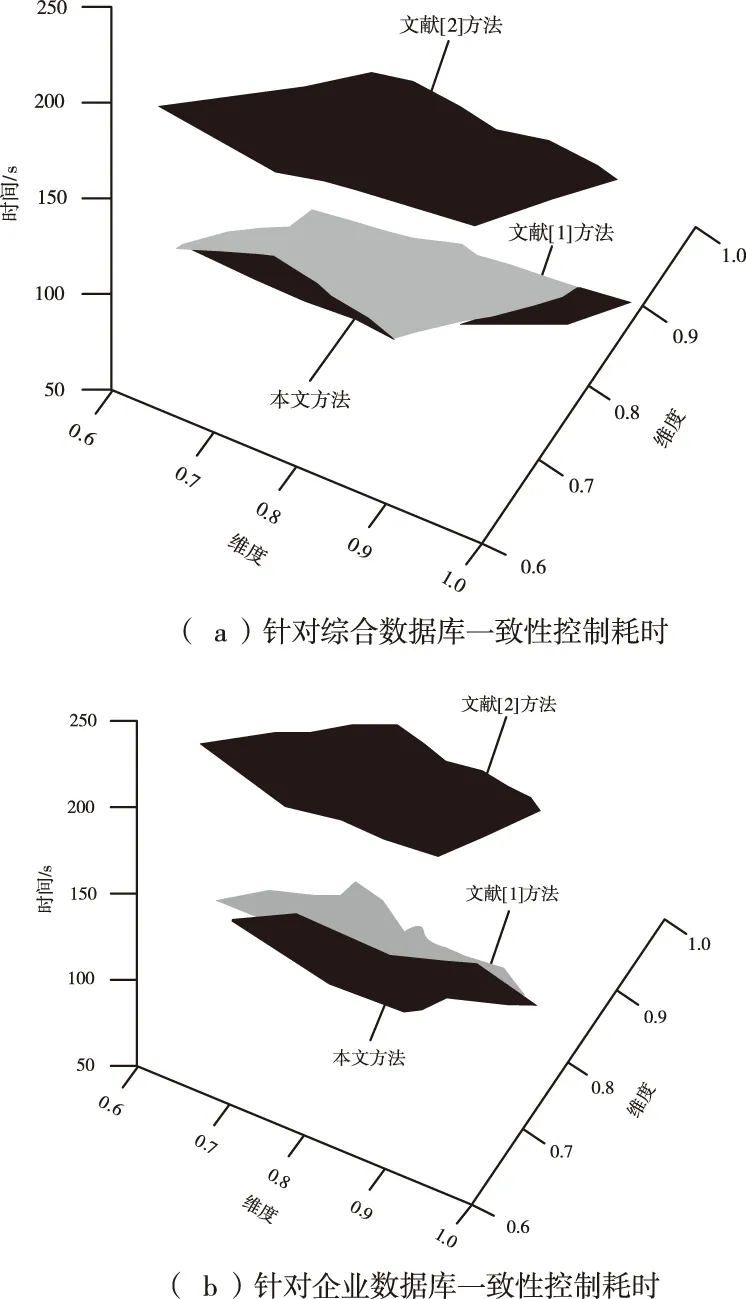
图4 对综合数据库和企业数据库一致性控制耗时
分析图4可知,不管是综合数据库还是企业数据库,本文方法耗时明显比其它两种方法少,说明本文将模式识别与数据全相关的一致性更新技术相结合的方法不仅对控制分布式存储信息一致性的准确度高,而且可有效解决分布式存储信息实时更新的问题。
5 结论
本文采用的基于模式识别的分布式存储信息一致性控制方法,与现有的数据一致性控制方法相比具有计算简单、数据更新及时、节省存储开销等优势。采用模式识别技术对数据集进行甄别和预处理,筛选出某些特征相似的信息与数据全相关的一致性更新技术相结合,二者协同对分布式存储信息一致性控制有很大的帮助,可以在一定程度上节省系统存储开销,更有效的支持移动设备在移动条件下的数据一致性控制,为继续研究分布式信息存储一致性控制提供了参考依据。
猜你喜欢
汽车实用技术(2022年19期)2022-10-19
计算技术与自动化(2022年2期)2022-07-04
汽车实用技术(2022年9期)2022-05-20
中学生数理化·高一版(2022年1期)2022-04-05
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
中国知识产权(2018年3期)2018-04-13
数学教学通讯·初中版(2015年5期)2015-06-17
都市丽人(2015年4期)2015-03-20
电子竞技(2009年13期)2009-09-28
电子竞技(2009年14期)2009-09-07
