
融合词向量和点互信息的领域情感词典构建
2021-11-10 08:13范庆春匡皓松
阜阳师范大学学报(自然科学版) 2021年3期
范庆春,匡皓松,谢 飞
(合肥师范学院 计算机学院,安徽 合肥 230601)
在线评论是体现消费者情感的最直接的方式之一,当今各种网络平台的快速成长和消费者线上消费习惯的养成都加速了在线评论数量呈指数级增长,而如何从大量的评论中提取有价值的信息已成为越来越多企业关注的焦点,因此很有必要针对这些评论数据进行情感分析,这对于企业优化产品或辅助用户进行消费决策都有着很重要的实际意义。
一般情感分析技术分为基于词典的技术和基于机器学习的技术[1]。情感词典是带有情感倾向的词或者词组的集合,一般由正向情感词和负向情感词组成[2]。尽管目前已经有很多的情感词典构建方面的研究,但是对于特定的领域情感词典研究工作较少,尤其是对于餐饮领域的情感词典鲜有研究。在实际应用中,因为社交网络在线平台上诸如口语化、不规范的词语表达等特点,造成了情感词的提取面临着众多难题。尤其是有些情感词在不同领域中会有不同的情感极性,有些词在许多领域甚至都不是情感词,而在餐饮领域却是情感倾向很明显的情感词,比如说“必点”、“还来”和“地道”等词在餐饮领域就属于正向情感词,表达了消费者十分正面的情感意愿;而“太硬”、“油腻”和“脸色”等词却反映出了消费者满满的负面情绪。为了解决这些问题,本文提出融合词向量和SO-PMI(Semantic Orientation Pointwise Mutual Information,情感倾向点互信息)方法来构建领域情感词典。
本文的主要贡献有以下几点:1)提出一种融合词向量和SO-PMI算法的领域情感词典构建方法,克服了词向量方法中情感词虽然上下文相似但是情感极性相反的问题。2)将构建的领域情感词典和基础情感词典融合,进一步提高了情感分析的准确率。3)在情感分析任务中,验证了该领域情感词典的有效性,分析了多种分类方法对情感分析任务性能的影响。
本文第1 节介绍了情感词典、词向量和SOPMI算法等相关工作;第2 节重点阐述了如何利用数据集来领域情感词典构建过程;第3 节介绍了实验内容,详细描述了在多个数据集上的领域情感词典实验结果并作出对比分析;最后进行了总结和展望。
1 相关工作
1.1 情感词典
情感词典是情感分析工作很重要的因素,大多数的情感分析的研究工作都会涉及情感词典。基于情感词典的情感分析方法是一种典型的研究方法,该方法结合情感词典获取文本特征,然后使用机器学习方法对文本情感倾向进行分类[3]。目前英文情感词典主要有SentiWordNet、General Inquirer、Opinion Lexicon[4]和HowNet(英文)[5]等词典,而比较有代表性的中文情感词典是台湾大学NTUSD 正负面情感词典[6](台大情感词典)、清华大学李军中文褒贬义词典[7](清华情感词典)和知网HowNet 情感词典(中文)等,但这些都是基础的情感词典,对于具体的应用领域、特定的评价对象情感分析评价的效果不是很好,无法囊括所有领域,在不同领域下,即便同一词汇也会存在一词多义的现象,因此,构建特定领域的领域情感词典是很有必要的。
赵妍妍等[8]构建了面向微博的情感词典,阳爱民等[9]使用正向、负向各40 个种子词和PMI 来计算情感词的情感权值,林江豪等[10]根据TF-IDF 值筛选出种子词与候选词集,加入训练的word2vec模型计算相似度,并与TF-IDF 值乘积得出情感倾向构建领域情感词典。杨小平等[11]在情感分析对比阶段使用特征融合的支持向量机分类模型进行二元分类,得出情感词汇的情感极性。何炎祥等[12]将词向量技术应用到基于表情符号的微博情感分析中。王侨云[13]等采用词间距和点互信息的方法来构建影评情感词库,杨晨等[14]使用情感词典来改进BERT的预训练任务。这些工作都对情感词典的构建做了很多深入的研究。
经调研发现,餐饮领域几乎没有完善的领域情感词典。Lukasz 等[15]对从Automotive 到Video Games 等十个领域的情感词典作了对比分析,虽然比较全面,但是尚未涉猎餐饮领域。餐饮领域在线评论有其独特性,例如,“香脆”、“地道”等较为平常的词汇在该领域具有较为明显的情感倾向;消费者人群的大众性使大量口语化的词语频繁出现,如“没得说”、“要不是”,等等。本文的工作是收集整理大量的餐饮领域评论数据形成语料库,根据计算得到的TF-IDF 值作为参考生成种子词集,训练word2vec 模型,挑选出与种子词集相似度Top50的词汇构成候选情感词集,再用SOPMI 计算候选情感词集中各个情感词汇的情感倾向,过滤无效词,然后构建了餐饮领域情感词典,最后对比不同的分类方法,达到较满意的情感分析效果。
1.2 词向量
word2vec的本质上是一个神经网络语言模型,本文利用CBOW 模型[16,17](Continuous Bag-of-Word Model,连续词袋模型)进行分布式词向量的训练,该模型如图1 所示。
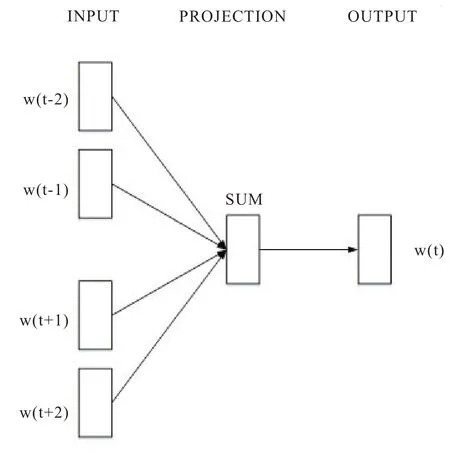
图1 CBOW 模型
该模型能依据给定中心词的一定邻域半径预测出某一单词为该中心词的概率,因此需要大规模语料进行训练,以找到语料中潜藏的词与词之间的联系。
1.3 SO-PMI
在计算情感倾向方面,Turney 等[18]利用PMI分辨未知词汇的情感极性,YANG 等[19]利用SOPMI算法构建了中文情感词典,CHENG 等[20]利用SO-PMI算法计算投资者的情绪指数。SO-PMI算法是在PMI算法的基础上,引入词语的情感倾向计算,从选取的种子词词典内以一组正向情感词posword 和一组负向情感词negword 作为基准,将候选情感词集中的某一词汇word 在经预处理后的评论数据集中分别计算出与posword 和negword的PMI 值,PMI 计算见公式(1),经过计算与所有组种子词的PMI 值后进行总和平均得出word的正向PMI 值和负向PMI 值,作为PMI+(word)和PMI-(word),将两者的差值来判断出该词的情感倾向,见公式(2)。SO-PMI(word)的值大于0、等于0 和小于0 分别对应正向、中性和负向情感词。
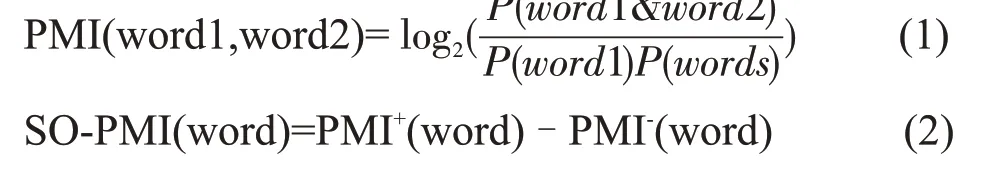
2 领域情感词典构建
2.1 领域情感词典构建过程
在对餐饮领域的评论数据集预处理后,利用TF-IDF 值计算各个词条的重要程度,按倒序挑选出该领域正、负向种子词集,再用评论语料集训练词向量模型,挑选出与种子词集相似度靠前的词汇构成候选情感词集,使用SO-PMI 计算其情感倾向,设置词频阈值过滤无效词,最后构建餐饮领域情感词典。领域情感词典构建流程如图2 所示。
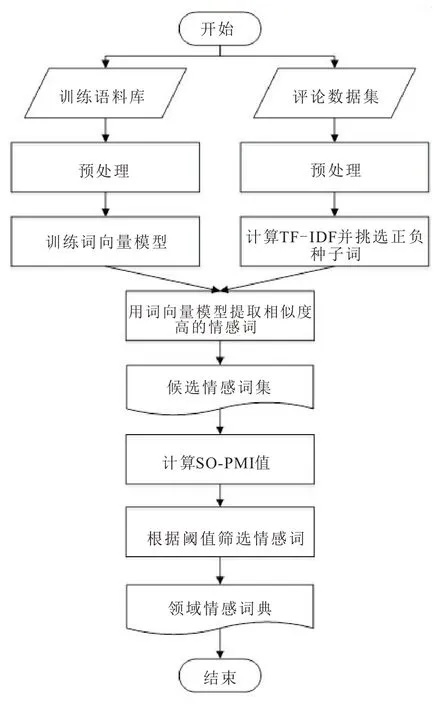
图2 领域情感词典构建流程
算法主要步骤如下:
1)数据预处理(删除无效评论;加入餐饮领域新词用户词典进行分词,删除停用词)。
2)训练词向量模型。
3)在评论数据集中计算训练集TF-IDF 值,选择正负向情感种子词,构建种子词词典。
4)分别利用词向量模型提取出与种子词集相似度高的词汇作为候选词集。
5)采用SO-PMI算法,计算候选词集与种子词典的PMI 值并作差,得出每个词情感值(SO-PMI(word)),根据阈值筛选并去重后得到领域情感词典。
2.2 种子词选择
餐饮在线评论还具有口语化和其领域特殊性的特点,存在着大量新词以及其特殊的包含强烈情感倾向的情感词汇,而基础情感词典无法做到识别这些情感词汇;领域情感词典的构建关键在于种子词的选取,各领域的种子词天差地别,因此需要选取贴合该领域的种子词词典。
本文根据餐饮领域在线评论数据集,利用TFIDF算法,计算出所有词汇的tfidf(word),构成词集(word,tfidf(word)),在词集中按照tfidf(word)的从高到低排序,然后请三位项目组成员人工挑选出具有明显情感倾向的情感词,为了减少不确定性因素,只有当三位成员意见一致的候选情感词才加入到种子词词集。表1 是部分种子词实例。

表1 部分种子词
2.3 训练词向量模型
将在线评论语料集经过数据预处理后,输入到word2vec 中,设置词向量维度,去除低频词,训练词向量模型并保存。
训练分为两组实验:第一组仅使用领域语料集作为语料训练词向量模型,得到w2v 模型;第二组在领域语料集中加入中文维基百科语料预训练的模型,更新模型词库并再次训练模型,得到w2v+wiki 模型,然后分别利用w2v 模型和w2v+wiki 模型提取出与种子词集相似度高的词汇作为候选情感词集。
2.4 获取领域情感词典
利用SO-PMI算法计算候选情感词集中各个词条与正负向种子词典的情感分值,设置词频阈值并去重后提取出有效的情感词来构建领域情感词典。SO-PMI算法流程如图3 所示。
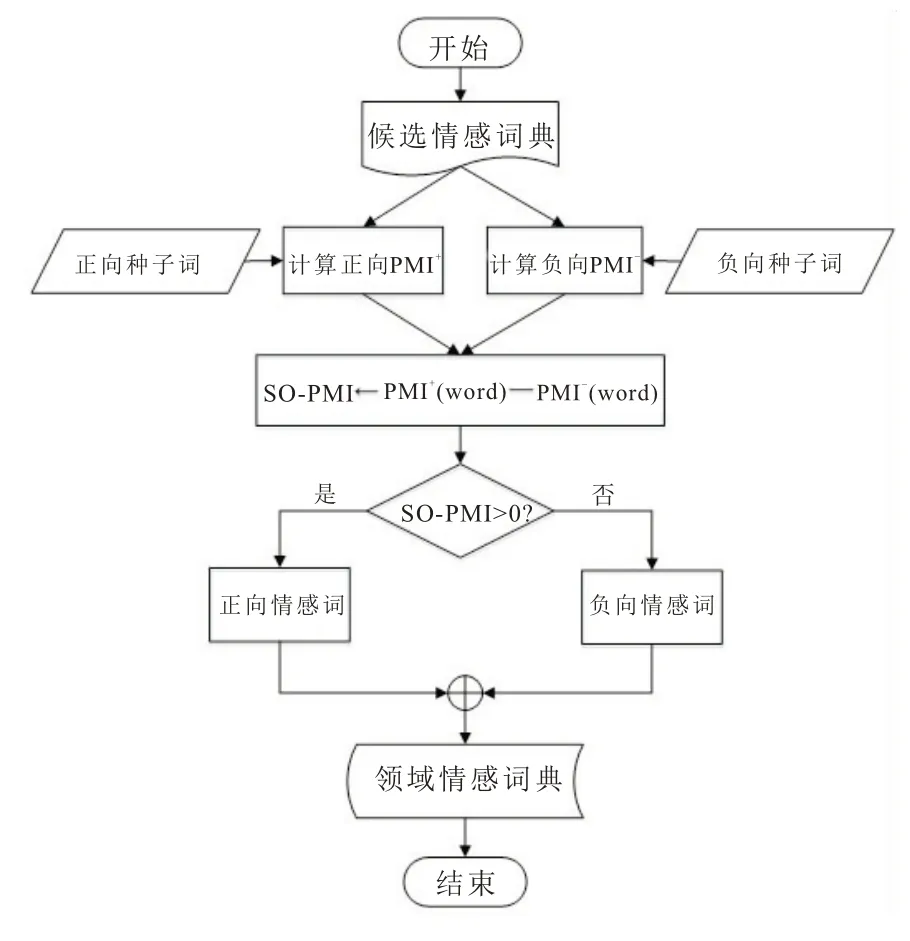
图3 SO-PMI 值计算流程
3 实验结果与分析
3.1 实验设置
本数据为公开数据集,是点评网的评论数据。由于网络平台上对评论无法做到很好的限制和约束,经过数据预处理后,将评分1 分和5 分的评论随机抽取各5000 条构成数据集1,评分1 分、2 分、4 分和5 分随机抽取各2500 条构成数据集2。去除数据集中词频为5 以下的生僻低频词,设置词向量维度为100,采用CBOW 模型,窗口为5,得到词向量模型。应用2.3 节的方法得到正负向各200 组的种子词。然后输入到词向量模型中,获取其相似度前50的词汇。利用SO-PMI算法计算候选情感词集中各个词汇与正负向种子词典的情感分值,设置阈值为10,即计算出候选词集中词频高于10的有效情感词,经去重后得到领域情感词典。
实验主要依据F1 值作为性能评价指标,比较各情感词典的在餐饮领域数据集的情感评判情况。其中F1 值计算公式如公式(3)所示。

3.2 实验结果与分析
实验提出利用word2vec 模型构建领域候选词集,结合维基百科语料预训练模型进行对比实验,故设置两组实验,第一组为仅使用数据集中的评论语料训练得到w2v 模型,根据种子词典寻找相似度前50的候选词共20000 个构成候选词集,第二组为使用数据集输入维基百科语料预训练模型更新其词汇并再次训练模型,得到w2v+wiki 模型,仍根据种子词典寻找相似度前50的候选词共20000 个构成候选词集。第一组实验经上述过程后构建了总计正面787 个词、负面463 个词,共计1250 个词汇的领域情感词典(Word Embedding and PMI Domain Sentiment Lexicon,简写为WPDSL);第二组实验经上述过程后构建了总计正面767 个词、负面440 个词共计1207 个词汇的领域情感词典(WPDSL+wiki),将这两个领域情感词典分别与清华大学李军中文褒贬义词典融合并去重后得到扩充的领域情感词典WPDSL+TsingHua和WPDSL+wiki+TsingHua,如表2 所示。
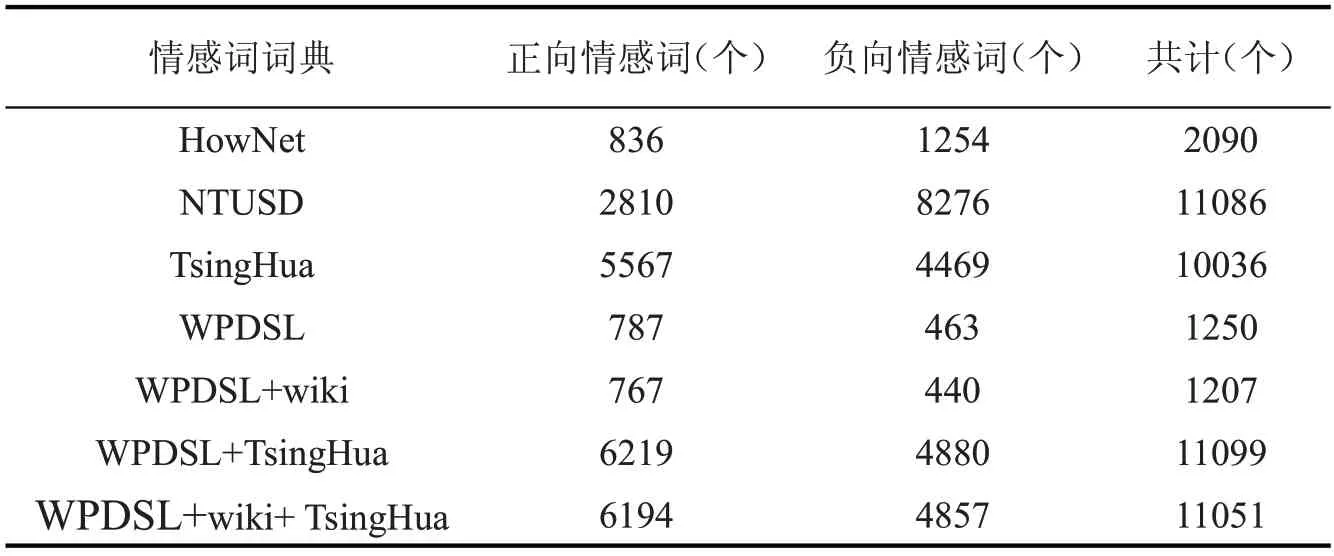
表2 各情感词典正负向情感词个数对比
实验将候选词集作为输入,设置阈值为10,即经过2.1 节所述算法使用SO-PMI算法计算出词频大于10的情感倾向词构建领域情感词典。通过分别使用多个基础情感词典和上述构建完成的领域情感词典进行实验,使用各情感词典来提取训练集的特征向量,使用TF-IDF 计算出特征向量的权重,并预测出测试集的情感倾向,最后计算出在数据集1 和数据集2 上各自的准确率、精确度、召回率和F1 值进行对比,得到实验结果(见表3和表4),其中在数据集2 上只采用了贝叶斯分类方法。
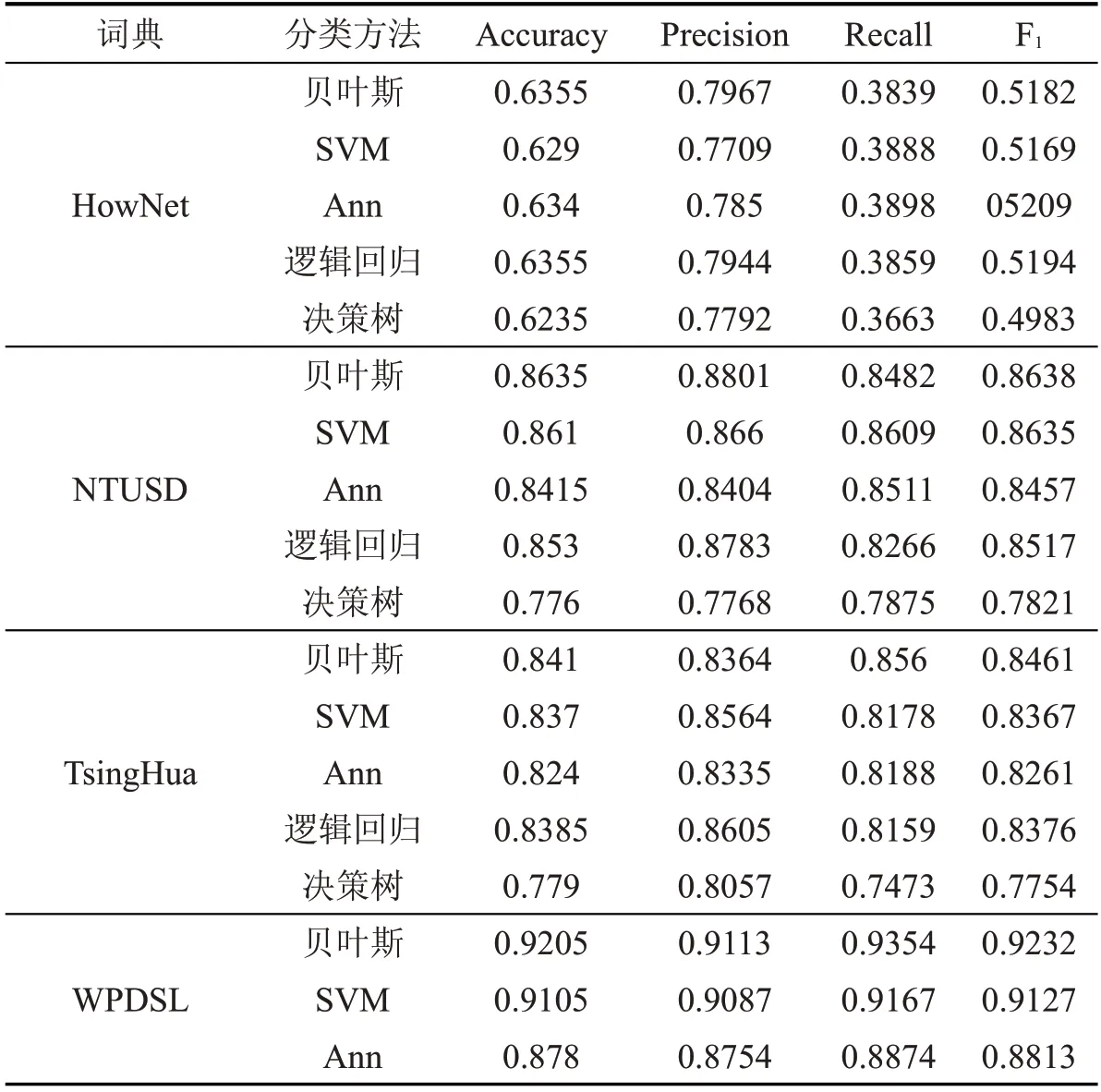
表3 各情感词典在数据集1 上的对比

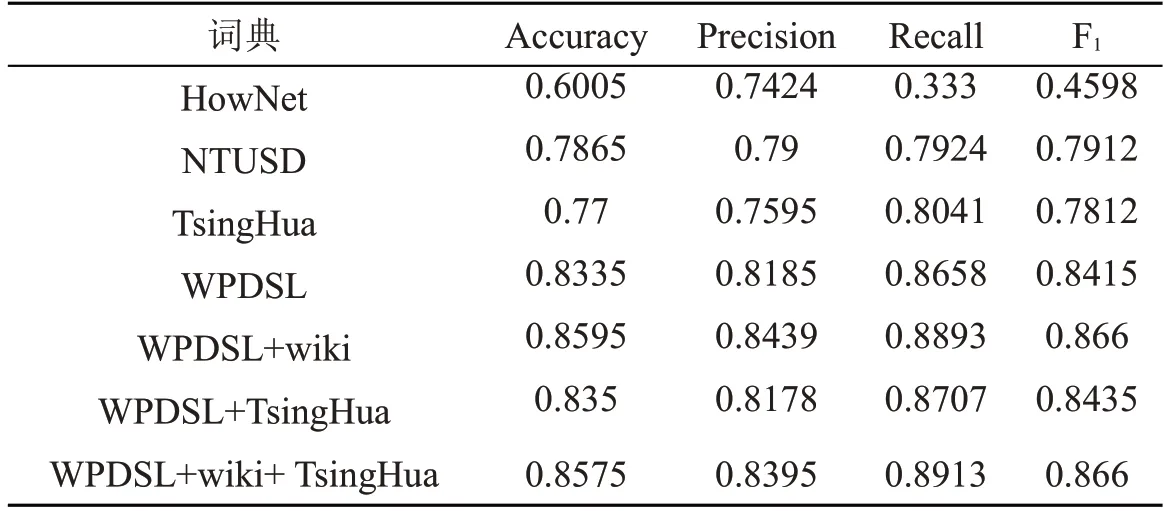
表4 各情感词典在数据集2 上的对比
从实验结果中可以看出,使用知网情感词典的效果最不理想,可能是因为相对其他的情感词典,情感词汇较少,涉及餐饮领域的更加稀少;使用台大情感词典的效果要好很多,其包含的情感词数量最多,因此涉及的餐饮领域词汇会比较宽泛;清华情感词典的表现稍差于台大情感词典,相较而言台大情感词典包含了更多的口语化情感词,更贴近于餐饮领域在线评论的特点。在表3中可以看出使用了领域情感词典(WPDSL),贝叶斯和SVM 分类的F1 值都是在0.9 以上。对比每一种情感词典用5 种分类方法的分类效果来看,贝叶斯和SVM 更适合做情感分类的工作,尤其是贝叶斯分类在每一种情感词典上都能取得最佳的分类效果。
表4 是在数据集2 上只采用了贝叶斯分类方法,对比表4 中各种情感词典在情感分析任务上的表现来看,使用了领域情感词典WPDSL的分类结果明显超过其他的几种情感词典,这充分说明了本文构造的情感词典的有效性。表4 中的分类效果比表3 中F1 值少了0.06 到0.09,说明了本文的领域情感词典在对于由评分1 分和5 分构成的数据集1的分类效果要比由评分1 分、2 分、4分和5 分构成的数据集2的效果好,这是由于数据集1 中的评论情感倾向更加明显所致。
考虑到不同的种子词个数可能会对情感分析的结果会有不同的影响,故设计了在其他条件完全相同的情况下,分别选择150 组、200 组、250组、300 组和350 组正负向种子词,实验结果如图4 所示。从实验结果可以得出正负向各200 组种子词能取得较好的结果。正负向种子词组从250组到350 组比较平稳,并且比150 组和200 组的效果差,这说明了种子词并非是越多越好,随着种子词数量的增加会引入许多噪音情感词,从而影响最终的情感分析效果。
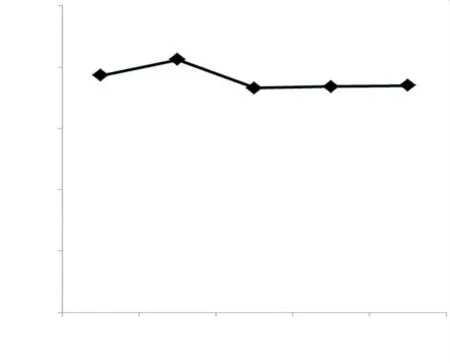
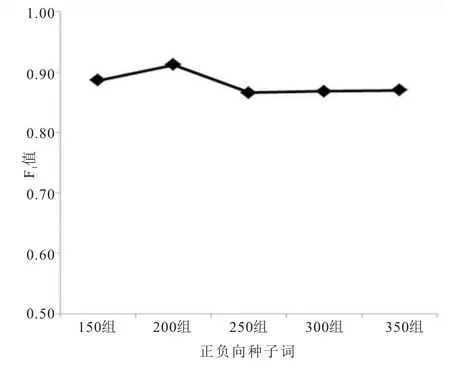
图4 不同的种子词个数情感分析结果对比
综上所述,本文构建的领域情感词典效果更优,F1 值也超出其他的基础情感词典不少,而两组实验的对比中,也能清晰地看出仅使用餐饮领域评论语料集训练出的word2vec 模型比加入维基百科语料预训练模型略胜一筹,能凸显出模型的领域适应性,提取的相似度高的候选词集更加精确,更加贴合该领域。由于使用了TF-IDF算法挑选后的餐饮领域的种子词,并训练词向量模型提取候选词集后,计算SO-PMI 值构建出的餐饮领域情感词典,将构建的领域情感词典与清华情感词典相融合得到扩充的领域情感词典,进一步提升了领域情感词典的效果。从而证实了本文提出的融合词向量和点互信息的领域情感词典算法,确实能更好预测出餐饮领域在线评论的情感倾向。
3.3 案例分析
例如“好吃”和“难吃”这两个种子词分别作为正向、负向情感词的例子,将其输入w2v 模型中提取出相似度前50的词构建候选情感词集word 各50 个(其中前10 个相似词在表5 中列出)。再将这100 个候选词逐个分别计算与所有正负种子词的PMI 值总和平均得到PMI+(好吃)和PMI-(好吃),然后由公式(2)计算出SO-PMI(好吃)的值为816.999,大于0 则为正向情感词;同样也会得到SO-PMI(难吃)的值为-847.093,小于0 则为负向情感词。
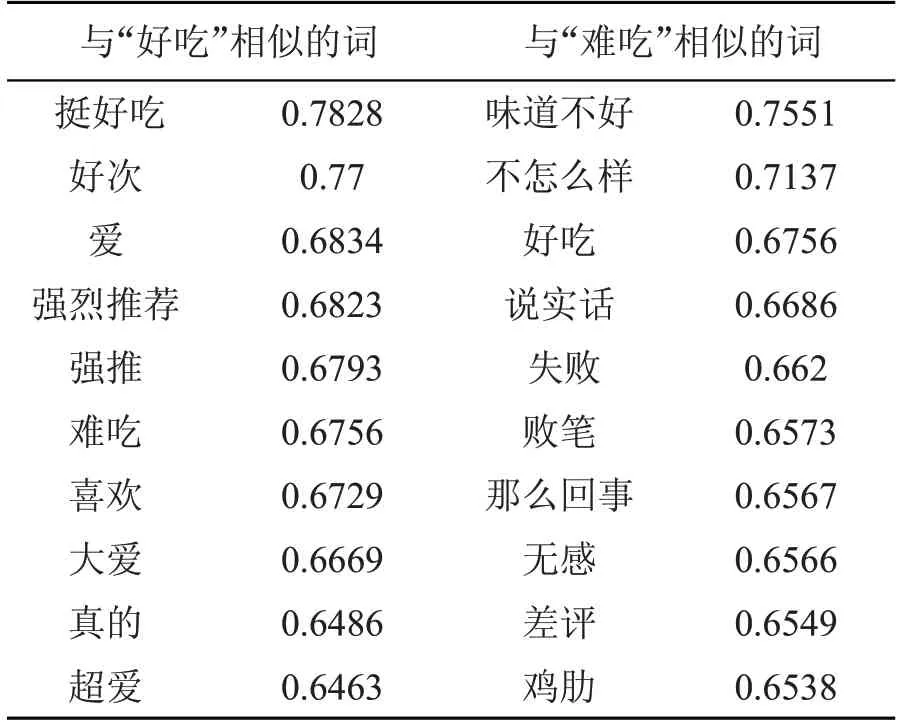
表5 部分候选情感词
从表5 中可以看到与“难吃”相似的词中排在第三名的就是“好吃”,而与“好吃”相似的词中排在第六名的是“难吃”,显然仅用词向量模型的相似度计算这两个词是很相近的,但是其情感倾向却刚好相反,这显然不合理,需要将“难吃”和“好吃”这两个候选词分别从正、负向情感词中排除,实验也证实了融合词向量和点互信息的领域情感词典算法能很好地做到这一点。
4 结束语
为了提高特定领域情感分析的效果,本文提出了融合词向量和点互信息的领域情感词典构建算法。先结合IF-IDF算法来挑选该领域种子情感词,再用词向量来获取语义相似的词作为候选情感词集,然后用SO-PMI算法来获取领域情感词典,最后在餐饮领域的实验中证实了该领域情感词典构建算法的有效性。该算法虽然达到了一定的效果,但仍存在很大的上升潜力,下一步将已经构建的领域情感词典与深度学习算法相结合,以期取得更好的成绩。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
厦门大学学报(自然科学版)(2021年4期)2021-06-22
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
电脑知识与技术(2019年23期)2019-11-03
英语文摘(2019年5期)2019-07-13
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
外语教学理论与实践(2014年2期)2014-06-21
