
一种政府公文智能辅助写作系统
2021-11-10 12:28施运梅
北京信息科技大学学报(自然科学版) 2021年5期
柏 峰,李 宁,施运梅
(北京信息科技大学 计算机学院,北京 100101)
0 引言
随着人工智能领域的发展,面向各个领域的计算机辅助写作成为人们研究的热点。如今国内外开发出了各种计算机辅助写作系统,如Style Writer、方正公文写作、易改等商业软件,这些软件极大地提高了用户的书写效率和写作质量。
万强[1]设计了一个在线摘要辅助写作系统Write Ahead。该系统利用学术领域文件进行抽取式摘要生成,构造了一个摘要语料库,可以将用户选择的学术领域或输入的关键词作为查询条件,与摘要语料库中相应的关键字进行匹配推荐,还可以通过线上检索,扩充摘要的检索范围,增加了系统的多样性。Liu等[2]设计了一个情书辅助写作系统,该系统利用文本生成技术,将用户输入的关键词和句子生成情书。同时使用同义词替换和比喻表达技术来构建并扩充情书语料库。Liu等[3]设计了一个博客辅助写作系统,该系统使用文本生成技术生成各种博客模版,同时利用知网词典将用户输入的关键词进行概念扩展,使其能提供更多的语义信息,最后通过百度搜索引擎进行网页检索,为用户提供相关的内容。Chen等[4]设计了一个英文作文辅助写作系统FLOW,该系统基于机器翻译将各种语言翻译成英语,并且当用户需要修改内容时,根据其上下文内容进行提示,提供复述候选。Dai等[5]设计了一个面向写作辅助的中文智能输入法系统WINGS,该系统使用Word2Vec[6]词向量相似度计算和词性搭配规则相结合的方法,准确地推荐和用户输入相关的单词,最后,采用自动分类算法[7]对句子进行质量评价,同时使用 LDA 模型对句子进行主题建模,为用户准确推荐与上下文相似的语句。
这些辅助写作系统基本上都提供了关键词检索、纠错改错等功能,辅助用户更快地撰写文档。然而,大多数辅助写作系统的研究重点都放在研究单词短语,对于文档级别的内容研究甚少,不能有效地为用户推荐相关的长文本。
公文是政府机关单位传达政令的工具,随着无纸化办公的推进,电子公文在政府机关单位中扮演着越来越重要的角色。本文在研究基于私有云环境的文档智能分类和信息抽取技术基础上,调研分析了目前市场上辅助写作系统的关键技术,并结合对机关单位人员撰写需求的调查,设计实现了面向政府公文的辅助写作系统。
1 智能辅助写作系统构建
政府公文辅助写作系统是为政府机关单位人员开发的写作平台,该系统包括关键词检索模块和公文智能推荐模块,其中关键词检索模块根据用户输入的多个关键词进行全文检索,公文智能推荐模块根据用户输入的公文内容进行相似度计算,从而实现相似公文推荐。系统的架构如图1所示。

图1 系统架构
1.1 关键词检索功能
关键词检索功能是辅助写作系统的基本功能。由于政府公文一般是围绕特定主题展开,当用户明确公文主题时,参考相同主题的政府公文,能从中获得写作思路,极大地提升写作效率。政府公文辅助写作系统针对这一需求,基于Lucene[8]设计开发了关键词检索功能。Lucene关键词检索有两个部分:构建索引和查询索引。构建索引就是将从政府网站爬取的非结构化公文数据结构化,构建索引库。查询索引就是获取用户的查询请求,在索引库中进行搜索并返回结果。Lucene关键词检索原理如图2所示。

图2 Lucene关键词检索原理
本文首先使用爬虫从政府网站爬取公文,将公文集合进行分词、去停用词等预处理操作后,构建索引从而建立字符串到文件的映射。假设有100篇公文,将公文从1~100进行编号,公文集合进行预处理操作后得到“农业”、“林业”、“税收”等单词,将这些词保存成词典,将每个单词指向的公文文档构建成倒排表,得到图3所示索引库结构。Lucene的索引结构中,既保存了正向信息,也保存了反向信息,正向信息是指按层次保存了从索引到词的包含关系,反向信息是指保存了从词典到倒排表的映射,索引库的结构如图3所示。
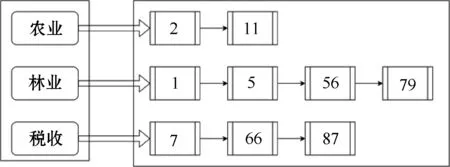
图3 索引库
用户在进行索引查询时,可能会查询多个关键词,最基本的查询语句包含AND、OR、NOT等。Lucene根据查询语句的语法规则来形成一棵语法树,接着搜索索引,得到符合语法树的文档。当用户输入“农业 AND 林业 NOT 税收”时,Lucene在索引库中分别找出包含“农业”、“林业”、“税收”的公文链表,接着合并包含“农业”、“林业”的公文链表,得到包含“农业 AND 林业”的公文链表,最后将该链表与“税收”链表进行差操作,删除该链表中包含“税收”的公文,从而得到“农业 AND 林业 NOT 税收”的公文链表。
当Lucene获得和查询语句相关的公文链表后,需要将查询语句和相关的公文链表进行相关性对比,将公文链表进行排序并展示给用户。Lucene使用TF-IDF[9]计算单词的权重:
(1)
式中:tfi,j为单词i在公文j中的词频;N为索引库中的公文总数;dfi为包含单词i的文档数。
在获得单词的权重后,利用向量空间模型的算法(VSM),将查询语句和公文表示成向量,放到一个N维空间中,每一维对应着一个单词,词的权重为向量位置上的值,最后计算向量之间的夹角,向量之间的夹角越小则相关性越大,按相关性将查询结果返回给用户,从而实现关键词检索功能。
1.2 公文智能推荐功能
政府公文的智能推荐是指在用户撰写公文的过程中,系统计算出和用户当前撰写内容相似的政府公文并推荐给用户。目前大部分的辅助写作系统将研究重点都放在单词短语级别,为了实现政府公文特点的智能推荐功能,本文结合公文标题和文本内容,设计出符合政府公文特点的智能推荐算法。本文使用编辑距离计算公文标题之间的相似度,随后使用TextRank算法提取公文文本的关键词,消除大量的冗余信息,采用ELMo(embedding from language models)词向量将公文向量化,计算公文文本之间的相似度,最后将公文的标题相似度和文本相似度加权融合。智能推荐算法如图4所示。
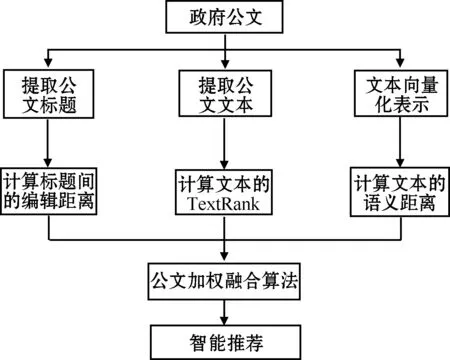
图4 政府公文智能推荐算法
1.2.1 编辑距离
政府公文的标题可以视为政府公文的主旨,它包含了政府公文的文种、主题、发文单位等重要信息。最小编辑距离[10](minimum edit distance,MED)又称Levenshtein距离,它是指一个字符串转化成另一个字符串所需要的最少编辑操作次数,其中编辑操作包括替换、插入、删除。本文使用编辑距离来计算政府公文标题之间的相似度。编辑距离算法的具体过程如表1所示。

表1 编辑距离算法步骤
1.2.2 TextRank关键词提取
TextRank算法[11]是由谷歌的PageRank算法改进而来,它是一种基于图论的文本排序算法,可以基于单篇公文构建图模型,从而提取关键词。首先根据窗口内单词的共现关系,构造图模型,其模型由一个无向有权图G=(V,E)来表示,V代表单词在图中的节点,E代表图中节点的边。图中任意点Vi的得分:
W(Vi)=(1-d)+d×
(2)
式中:d为阻尼系数,一般取0.85,表示当前节点向其他节点跳转的概率;Lni代表指向Vi的点;Oj代表Vj指向的点;Wij代表点i和点j在窗口内的共现次数。
在使用TextRank提取公文关键词时,模型图中的边是由单词的共现关系决定的,而共现关系由共现窗口决定。本文设定共现窗口大小为5,这样可以同时考虑任意1个词和周围10个词的共现关系,最后选取得分最高的10个关键词来代表公文。
1.2.3 ELMo词向量
ELMo[12]是一种新型深度语境化词向量,与Word2Vec和GloVe的一个词对应一个词向量,无法处理一词多义的情况不同,ELMo使用双层BiLSTM获得词的上下文信息,根据语境生成相对应的生成词向量,ELMo的模型结构如图5所示。

图5 ELMo模型结构
ELMo模型采用Char-CNN模型[13]生成的字向量作为输入,这样做使得ELMo模型能适配各种语言。首先将政府公文数据集处理成候选词词典,使用Char-CNN对候选词词典进行训练,生成字级别的上下文无关的词向量;接着使用双层BiLSTM来训练语言模型,第一层LSTM用来提取公文的句法特征,第二层LSTM用来提取公文的语法特征,然后线性组合两个LSTM层的词向量。ELMo模型结合双向语言模型表示层,对于每个词En都会计算出3个词表示:
(3)

(4)

接着使用ELMo模型将TextRank中提取的公文关键词进行向量化表示,生成公文词向量,利用余弦距离计算公文词向量的相似度:
(5)
由于余弦距离的取值范围为[-1,1],因此需要进行归一化操作:
d1=0.5+0.5×cos(X,Y)
(6)
最终实现公文的智能推荐。
2 实验分析与对比
多因素加权融合的相似度计算算法是将公文标题的编辑距离和文本的语义距离加权融合得到公文的相似度计算评分:
d=α×dMED+β×d1
(7)
式中:dMED为标题的编辑距离;d1为文本的语义距离;α、β分别为标题编辑距离和文本语义距离的加权因子。
为了确定α、β为何值时算法性能最好,本文使用THUCNews数据集的新闻短文本进行测试。该数据集是新浪新闻根据2005-2011年的历史新闻过滤筛选生成的,共计74万篇新闻文档,本文选取10 000篇新闻文本作为测试集,使用召回率、准确率、F1值来评估算法的性能,实验结果如表2所示。

表2 算法性能评估
从表2可以看出,在一定范围内,随着α的增加,算法的准确率有所提升,这是因为标题是公文的重要组成部分,标题之间的相似度能从侧面反映出公文之间的差异;随着β的增加,算法的准确率有所提升,这是因为公文高频词越相似,公文的内容越接近。通过实验对比,最终确定当α=0.4、β=0.6时,多因素加权融合相似度计算方法的准确率最高。此时将其与传统相似度计算算法的性能进行对比,结果如表3所示。
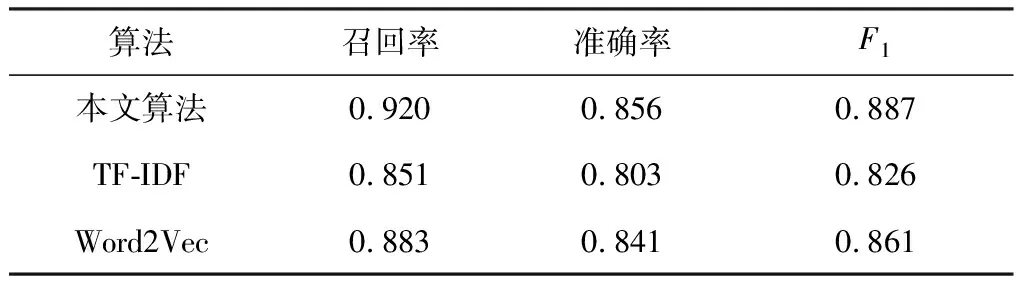
表3 相似度计算算法性能对比
实验结果表明,本文算法的效果优于单一的相似度计算方法。TF-IDF方法从词频的角度计算文本相似度,这种方法简单易行,但是无法包含公文文本的语义关系。WordNet方法依靠人工构建词库,但是对于词库中未收录的新词,就无法计算出这一部分词的相似度。Word2Vec方法可以解决文本稀疏的问题,但是不能解决一词多义的问题。而本文算法结合了公文的结构特征和语义特征,分别计算公文的标题和文本,更适用于公文领域的相似度计算。
3 结束语
本文构建了一个政府公文智能辅助写作系统,该系统目前部署在国家重点研发计划项目私有云环境下服务化智能办公系统平台,为广大政府机关人员提供了便捷高效的写作工具。本文将北京市政府网站的公文进行处理,利用Lucene设计开发了公文的关键词检索功能,并针对政府公文提出了一种多因素加权融合的相似度计算算法,可以在用户撰写公文的过程中,时刻提供智能推荐。本文提出的相似度计算方法已应用于方正智能办公系统。在后续的研究工作中,该系统将不断扩充公文数据,研究词向量的动态更新,使得ELMo模型生成的词向量能包含更多的语义信息,进一步提升多因素加权融合相似度计算算法的性能。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小学生学习指导(低年级)(2021年12期)2021-12-31
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
技术与创新管理(2020年5期)2020-10-09
科学与财富(2019年27期)2019-10-25
阅读与作文(英语初中版)(2019年8期)2019-08-27
意林(图解作文)(2019年6期)2019-07-16
科学与财富(2017年28期)2017-10-14
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
