
基于ALBERT的改进实体关系分类模型
2021-11-10 12:28朱瑞天王兴芬
北京信息科技大学学报(自然科学版) 2021年5期
朱瑞天,王兴芬
(1.北京信息科技大学 计算机学院,北京 100101;2.北京信息科技大学 信息管理学院,北京 100192)
0 引言
知识图谱作为知识的结构化表达方法,可以刻画自然世界中知识的组成和构成系统[1]。在知识图谱建立的过程中,常利用实体关系抽取方法来挖掘文本信息的语义关系。面对互联网上海量非结构化文本数据,如何利用计算机进行实体关系结构化抽取是我们目前正面临的挑战[2]。
信息抽取任务的主要内容是从给定文本中识别给定实体间的语义关系。从信息抽取技术的发展现状看,其主要由命名实体识别和实体关系抽取两个子任务组成[3]。命名实体识别任务负责从语句中识别实体,实体关系抽取任务负责针对被识别出的实体给出其实体间关系分类。
近年来伴随着计算机性能的不断提高,机器学习和深度学习技术逐步代替了传统的基于语言学特征的实体关系抽取方法,成为实体关系抽取的主要方法[4]。传统的实体关系分类方法大都利用手工构建模板或特征工程[5-8],过于依赖领域特性以及构建人的知识,并且较少利用文本上下文信息。而深度学习方法不需要手工构建模板或特征,大大减少了特征工程的工作量。常见的基于深度学习的实体关系分类方法主要是基于卷积神经网络(convolutional neural network,CNN)和循环神经网络(recurrent neural network,RNN)。近年来,预训练语言模型的出现,极大地提高了关系分类任务的效果,但这些模型还是没有充分利用实体间语义信息。
为了解决以上问题,本文设计了一种基于预训练ALBERT模型的实体关系分类方法,以实体位置信息为特征作为输入的一部分,提高了模型对文本上下文信息的利用率,并提出了基于依存句法分析的实体间关系指示代词提取方法,利用实体关系描述词提高了关系分类模型的准确率。
1 相关研究
1.1 预训练模型
随着深度学习技术的发展,预训练语言模型成为目前解决自然语言处理任务的基准方案。基于Transformer[9]结构的预训练语言模型BERT(bidirectional encoder representations from transformers)[10]是目前使用规模最大的动态预训练语言模型。与其他语言模型不同的是,Transformer结构不依赖于RNN或CNN结构作为特征抽取器,而是利用Attention机制在上下文中双向提取特征表征,并堆叠Transformer模块以提取更深层次的特征。为了训练BERT模型,预训练过程包括掩码语言模型(masked language modeling,MLM)和下一句预测(next-sentence prediction,NSP)两个任务。BERT模型在诸多自然语言处理任务中表现优异,但其模型参数过大,训练所需参数空间较高。
Lan等[11]提出了ALBERT(a lite BERT)模型,其将词嵌入矩阵分解为两个更小的矩阵来取代One-Hot矩阵,有效降低了词嵌入矩阵大小和参数量。使用跨层参数共享(cross-layer parameter sharing)机制,将前向传播网络(feed-forward network)和Attention层参数进行共享,增强了模型稳定性。此外,ALBERT提出了句子顺序预测(sentence-order prediction,SOP)任务,即判断两个句子的顺序是否正确,这项任务使得模型可以学到更多的句间信息,有助于理解上下文语义关系,提高了模型的性能。
1.2 关系分类模型
Zeng等[12]首先将CNN网络融入关系分类模型中,模型将字级别特征与词级别特征相结合,包括了实体词、实体词的左右位置词以及实体词的上位词信息,并将其拼接后送入Softmax层进行关系预测。Santos等[13]提出了CR-CNN 模型,使用对偶损失函数评估模型损失,增强了对负样本的正确率。Shen等[14]使用了基于Attention机制的CNN模型,在句级别表征时,使用Attention机制使各单词学习到相对于实体词的权重,并将表征用于关系分类。但是CNN模型的卷积核数量有限,对长文本序列的数据有一定局限性。为了捕获更长文本序列下的实体关系,Zhang等[15]将BILSTM网络引入关系分类模型中,使用BILSTM结构学习实体间依存关系。Zhou等[16]将Attention机制引入了BILSTM网络中,提高了关系分类的效果。Zhang等[17]提出结合CNN和RNN的RCNN模型,此模型使用RNN解决了长序列文本问题,使用CNN在文本中学习到了更多信息。Lee等[18]使用基于Attention机制的端到端LSTM网络,学习了更多的语义信息。Jin等[19]提出使用基于LSTM网络的MALNET模型,并使用实体过滤器机制学习关键词。张东东等[20]将BERT与Attention机制结合,提出了ENT-BERT模型。其使用Attention机制捕获各实体间信息,使得不同特征向量对分类结果有不同的权重,加强了模型的性能。Wu等[21]提出了R-BERT模型,使用BERT模型作为向量化层,并使用实体定位信息作为额外输入,取得了更好的效果。
2 改进关系分类模型
2.1 模型架构
本文提出的改进实体关系分类模型架构如图1所示。该模型主要包括以下3个部分:

图1 模型架构
1)ALBERT向量化层。对于给定输入序列S={s1,s2,…,sn},以及实体对E={e1,e2},首先将实体对进行定位,作为ALBERT模型的首部输入I1;接着逐一计算s1、s2、…、sn到实体对E的指示相对距离D={d1,d2,…,dn},并从中选取关系指示词作为I2;I1和I2拼接后作为ALBERT模型输入部分,将ALBERT模型的输出作为下层网络输入。
2)Attention定位层。根据实体定位信息对ALBERT模型输出的隐状态集合H={h1,h2,…,hn}进行提取操作,并对提取信息进行Attention加权学习,对影响分类结果的信息给予更大的权重,将权重信息与整句表征拼接后作为下层网络输入。
3)全连接分类层。将上层网络输出经全连接网后送入Softmax分类器,计算权重得分后分类出相应实体关系。
2.2 ALBERT向量化层
实体作为序列中语句的组成部分,其关系信息隐含在语句以及实体本身中。为了最大程度利用语义信息与实体定位信息,ALBERT向量化层的输入部分I由文本序列部分I1和实体关系描述词I2两部分拼接而成。拼接完成后的输入I将被送入预训练ALBERT模型进行向量化。
2.2.1 文本序列输入
为了使ALBERT模型尽可能地同时识别更多的实体位置信息,对于序列S以及实体词E,首先使用e1S、e1E、e2S、e2E分别表示e1起始位置、e1结束位置、e2起始位置、e2结束位置。然后使用定位符号$插入至e1S、e1E位置,使用定位符号#插入至e2S、e2E位置。将插入定位符号后的文本I1作为文本序列输入的第一部分。
2.2.2 实体关系描述词提取
实体关系描述词定义为对实体关系构成表意的关键性指示词语,是决定实体关系的重要特征,一般为名词、动词、形容词、副词和介词。利用关系描述词的指示作用可以帮助模型更准确地识别关系类型。依存句法分析是自然语言处理技术中的重要组成部分,其基本任务是分析句子中各个组成成分间的依存关系从而理解语法结构。本文使用基于依存句法分析的实体关系描述词提取方法来构建模型的第二部分输入I2。
首先使用Stanford Core NLP工具对文本序列S进行依存分析,得到依存图G。对于给定的句法依存图,忽略其中弧的方向,将其转换成无向图G′={V,Y}。其中V={v1,v2,…,vn}为句子中单词序列集合;Y={y1,y2,…,yn}为各单词间依存关系的集合。定义相对距离为D={d1,d2,…,dn}。其中:
i=1,2,…,n
(1)
式中:die1为vi到实体1的最短路径;die2为vi到实体2的最短路径。
本文根据相对距离选择实体关系描述词,选择相对距离最小且词性为名词、形容词、动词、介词的两个词作为实体关系描述词,将其作为模型第二部分的输入I2,并与I1拼接后增加token,送入ALBERT模型。
例如,对于输入:S= {As a result,pollution from cars is causing serious health problems for Americans.},E= {pollution,cars},其中无向图G′及对应的相对距离D如图2所示。则转换后的输入I为:

图2 无向图G′及相对距离D
I= {[CLS] As a result,$ pollution$ from #cars# is causing serious health problems for Americans.[SEP] result# problems}
其中[CLS]、[SEP]为ALBERT规定token,#为关系描述词分隔符。
2.2.3 ALBERT向量化
ALBERT模型作为预训练模型BERT的变种,同样基于堆叠Transformer结构,其每层输出向量与输入文本序列一一对应,在堆叠计算Transformer过程中,上一层的输出向量作为下一层的输入向量,如式(2)所示。
El=Transformer(El-1)
(2)
式中:l为层数;El为该层所对应的特征表示。本文使用最后一层Transformer的编码信息作为下层模型的输入信息。
2.3 Attention定位层
为了最终得到实体间关系,在得到ALBERT模型的表征信息后,将进入Attention定位层。本层的目的是对ALBERT模型的输出信息进行处理,最终得到适合下一层输入的信息。本文利用Attention机制将实体信息与实体关系描述词进行定位。
2.3.1 整句向量
由于Attention定位层的输入信息为El,其对应位置信息与输入I一一对应,相对应位置为该输入token的向量化表征。

(3)
式中:W0为训练参数权重矩阵;tanh为非线性激活函数;b0为偏置项。
2.3.2 实体与关系指示词向量
对于ALBERT模型输出El,其中a、b、c、d分别表示实体e1与实体e2的起始与结束位置。i、j、k、l分别表示关系指示词i1与关系指示词i2的起始与结束位置。其中ha和hb间的向量为实体e1的表征,hc和hd间的向量为实体e2的表征,hi和hj中间的向量为关系指示词i1的表征,hk和hl间的向量为关系指示词i2的表征。
对于每个向量表征段,本文使用实体—平均操作将其转换为单一向量,如式(4)~(7)所示。
(4)
(5)
(6)
(7)
2.3.3 Attention机制
对于实体e1和实体e2以及关系指示词i1和i2,根据依存分析的结果,关系指示词对实体关系的类型识别有着指导作用。利用Attention机制可以编码字符上下文间关系,自动学习各字符间权重,将实体关系与关系指示词对应。为了尽可能捕获关系,本文使用了Multi-head Attention,该方法允许模型在不同位置共同关注来自不同表示子空间的信息,具体计算如式(8)~(11)所示。
(8)
(9)
Z=WM(head1⊕…⊕headr)
(10)
X=he1⊕he2⊕hi1⊕hi2
(11)
在本文中Q、K、V均为X;⊕为拼接操作。
(12)
2.4 全连接分类层
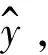
p(y|x,θ)=softmax(W1·ao+b1)
(13)

(14)
式中:y为目标关系类别;θ为可训练参数;W1为训练参数权重矩阵;b1为偏置项。此任务的目标是学习到清晰明确的实体关系分类结果,所以本文采用交叉熵损失函数作为优化目标函数。为了避免模型过拟合,在全连接层前引入dropout策略,并且在目标函数后加入正则化系数:
(15)
3 实验与结果分析
3.1 实验数据
本文在Semeval-2010-task8以及KBP37数据集上进行实验。下面分别介绍两个数据集:
1)Semeval-2010-task8。该数据集是常用的实体关系分类数据集,包含9种关系以及“other”关系类别,共有10 717个数据样本,其中训练集包含8 000个实例,测试集包含2 717个实例。其数据分布如图3所示。
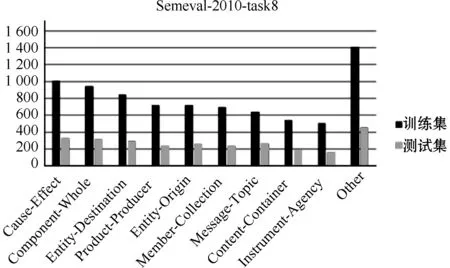
图3 Semeval-2010-task8 数据分布
2)KBP37数据集。该数据集是基于Wikipedia注释以及KBP文档构建的实体关系分类数据集,包含18种关系以及“no_relation”关系类别,共有21 046个数据样本,其中训练集包含17 641个实例,测试集包含3 405个实例。与Semeval-2010-task8不同的是,KBP37的实体名词由更多的单词组成,且平均句子长度大于Semeval-2010-task8数据集。其数据分布如图4所示。

图4 KBP-37数据分布
3.2 评价指标
为了衡量模型的预测效果,本文针对每个类别i分别计算了准确率P(Precision)、召回率R(Recall)以及F1值(F1-Score),在两个数据集上均使用其官方评价指标Marco-F1(Fmarco)[21]来衡量模型水平,如式(16)~(19)所示。
(16)
(17)
(18)
(19)
其中:nTP为实体关系预测正确的关系个数;nFP为将其他分类样本预测为本类别样本的数量;nFN为将本类别样本预测为其他分类样本的数量。
3.3 参数设置
为确保模型在不同数据集上的公平性,本文对两个数据集使用相同的超参数,如表1所示。

表1 模型参数表
3.4 实验结果与分析
本文使用以上超参数分别在Semeval-2010-task 8和KBP37数据集上进行训练,并在其测试集上进行验证。对于每种关系类别,由于有实体指向性的存在,实际关系类别数量为关系数量的两倍。为了更好地衡量模型性能,在两个测试集中“other”类别都不计入。本文对比了目前多种深度学习模型在此数据集下的结果,其Marco-F1值如表2所示。
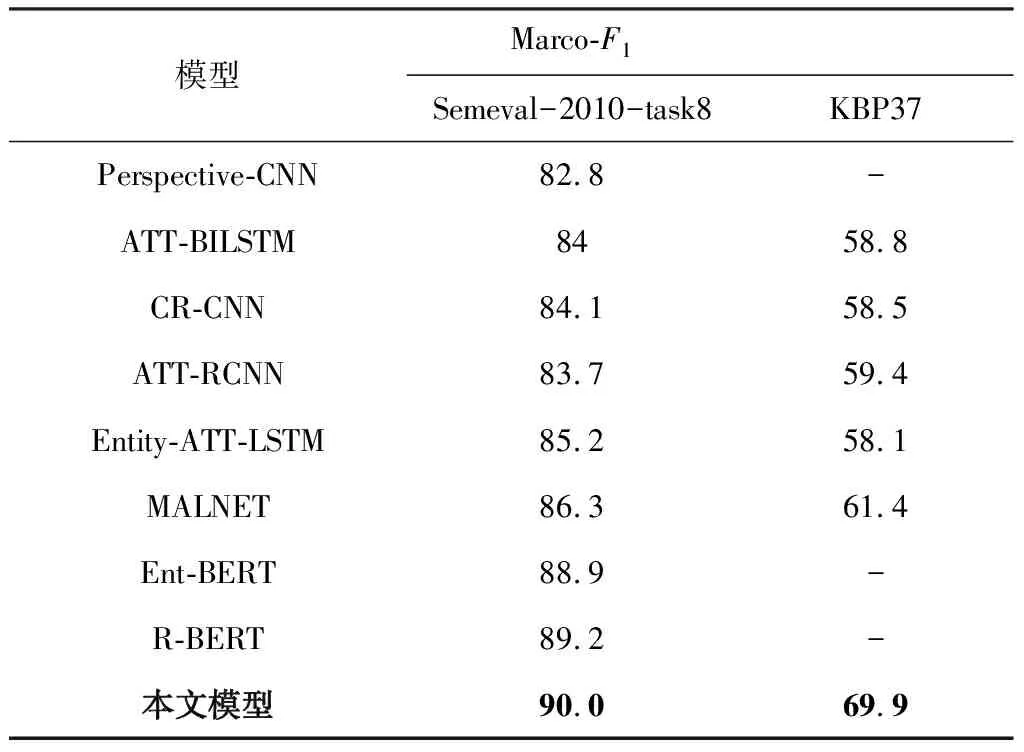
表2 实验结果 %
其中,Perspective-CNN采用了将实体位置引入句子编码的方法,并尝试使用多种卷积核进行卷积操作,在Semeval-2010-task8上取得了82.8%的F1值,这也证明了实体相对位置对于实体关系分类的有效性。同时由于卷积操作在信息提取上的局限性,ATT-BILSTM模型采用LSTM代替CNN作为特征抽取器,并采用Attention机制学习权重特征,最终在Semeval-2010-task8和KBP37上分别得到了84%和58.8%的F1值。这也说明本任务具有长距离依赖的特点,需要分类的关系信息包含在更长的句子中。通过改进损失函数,CR-CNN的结果得到了一定程度的提高,这说明此类任务的分类结果与数据集分布有相关性。由于RNN网络相对于CNN网络在长距离依赖问题上有着更好的效果,结合CNN模型的跨距离信息,ATT-RCNN和Entity-ATT-LSTM性能相较之前的模型有了提高。但以上模型并未充分利用实体词与语句本身的关系。MALNET使用了BILSTM及Attention机制,在定位层引入了句子级特征,使用句法分析方法使得模型获得了更多额外信息,加强了模型对实体词语义的应用能力,得到了目前非BERT模型里的最好成绩,这说明实体词与语句本身在语义层面有着关系信息,对最终的关系分类结果有着指导作用。
伴随着预训练语言模型的发展,预训练语言模型的表征能力大大超过了上述模型。Ent-BERT模型使用基于Transformer结构的预训练BERT模型,提高了模型效果,使用Attention机制捕获了更多的实体间信息关系。R-BERT模型采用预训练BERT模型,结合了实体定位特征,并使用了共享参数的全连接网络,在实体关系分类任务中取得了目前最好的成绩。
本文模型结合了以上模型的优点,使用基于预训练ALBERT模型作为向量化层,并加入实体位置定位信息和实体关系描述词信息的深度学习模型,相比R-BERT模型有着更高的F1值,在Semeval-2010-task8和KBP37数据集上均取得了较大幅度提升。
另外,为了验证实体关系描述词对模型的有效程度,本文分别选用0、1、2、3、4、5个实体关系描述词进行了对比试验。其在两种数据集上的Marco-F1值分别如图5和图6所示。从图可以看出,当实体关系描述词数量为2时模型取得了最好的结果。

图5 Semeval-2010-task8不同实体关系描述词效果

图6 KBP37不同实体关系描述词效果
为了验证使用实体关系描述词对各项分类类别的影响,对Semeval-2010-task8的各类别F1值分布进行分析,结果如表3所示。从表中可以看出,除 Message-Topic和Entity-Origin外,其余各类别的F1值均有提升,以Cause-Effect的提升最为显著。这是由于Cause-Effect关系大都有着明确的关系描述词,如“cause”、“result”、“produce”等,所以利用提取实体关系描述词方法可以有效提升模型效果。相反地,Message-Topic和Entity-Origin类别语言描述更为抽象,较少有词语能明确指代该关系,所以使用实体关系描述词方法增加了模型的混淆程度,反而降低了该类别的效果。总体而言,在大多数的关系类别下,使用提取实体关系描述词方法可以有效提高模型效果。

表3 Semeval-2010-task8各类别F1值分布 %
4 结束语
本文提出了一种基于ALBERT预训练语言模型的实体关系分类模型。针对传统方法对实体位置信息和语义信息利用较少的问题,提出了一种结合实体词定位及实体关系关键词的关系分类方法。在语句的实体位置前后加入实体定位符号,为模型提供实体定位信息;使用基于依存关系分析的关系指示词提取方法,提取实体关系指示词,为模型提供实体关系指示语义信息。本方法既利用了预训练语言模型的整句表征能力,同时也有效利用了实体在语句中的语义信息。实验证明了本文模型相对于其他方法效果更好,在实体关系分类任务上有着良好表现。
本文目前只在英文数据集上进行了训练与测试,在未来的研究中将考虑继续研究将模型迁移到中文语料中,并考虑尝试使用层数更少的Transformer结构构建模型。
猜你喜欢
当代陕西(2019年5期)2019-03-21
海峡姐妹(2018年2期)2018-04-12
人大建设(2018年12期)2018-03-21
21世纪商业评论(2018年3期)2018-03-02
杂文选刊(2018年1期)2018-01-09
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
