
近二十年(2000—2020)国内语料库翻译研究文献计量分析
2021-11-08 07:44吴芳
乐山师范学院学报 2021年9期
吴 芳
(四川大学 外国语学院,四川 成都 610065)
英国翻译理论家Sara Laviosa[1]指出:“语料库翻译研究诞生于两个领域:语料库语言学和描写翻译研究。”20 世纪50 年代,语料库语言学的兴起对翻译研究产生了深远的影响。翻译学逐渐从关注翻译产品发展到探索翻译过程,从规定性研究到描写性研究,从认知研究模式发展为实证研究模式[2]。语料库为进一步解决翻译学的核心问题提供了新的研究工具和视角,并促进新的研究范式——语料库翻译学——的诞生。
我国语料库翻译研究始于21 世纪初。自2000 年以来,语料库翻译研究范式逐渐得到国内译学界的重视[3]。2008 年,王克非和黄立波[4]回顾了近十五年语料库翻译学的发展历程,指出该领域的研究课题有:翻译共性、翻译文体、翻译过程、应用研究(包括翻译教学)。三年后,两位学者[5]就语料库翻译学的课题及进展再次进行综述,发现语料库翻译学近年成果集中表现在两个方面:一是对翻译共性、译者风格等原有课题认识的深化;二是基于语料库对翻译语言变化的探索和多模态口译语料库建设等新课题的开拓。2019 年,庞双子[6]基于CiteSpace 对近十年国际语料库翻译研究文献进行了可视化分析,发现主要课题为翻译文本共性特征的验证、语言对比研究、受限语言的探索、研究的系统化整合、实证统计方法的革新以及研究范式和翻译研究情境的扩展等。然而,较少文献专门论述国内语料库翻译研究发展动态演进过程。经过二十年的研究发展,我国语料库翻译研究日渐成熟,不断呈现新的课题。把握语料库翻译研究在我国的整体发展脉络,厘清该领域研究关注的核心和热点课题是非常必要的。
科学图谱或引文空间(CiteSpace)分析是当前有效的文献计量工具,能对一个学科的内在构成和动态发展进行追踪和探析[7]。因此,本文运用CiteSpace5.6.R5 软件对中文社会科学引文索引(CSSCI)近二十年(2000—2020)有关语料库翻译研究的核心文献进行可视化分析,梳理该领域发展进程、现状和热点。主要回答以下问题:(1)我国语料库翻译研究的主要课题是什么?这些课题之间有何联系?(2)哪些是该领域的主要研究者及主要文献?(3)我国语料库翻译研究的历史发展中有哪些重要转折点?
一、研究方法
本文主要通过CSSCI 进行数据收集,并通过科学文献计量工具CiteSpace5.6.R5 对我国近二十年语料库翻译研究进行可视化分析。研究路径为作者和机构共现分析、关键词分析、共被引文献分析和聚类分析。
(一)数据来源
本研究数据源于中文社会科学引文索引(CSSCI)。CSSCI 收录了全国2 700 余种中文人文社会科学学术性核心期刊。入选的刊物经过同行专家评审,能反映我国语料库翻译研究各个阶段的最新研究成果。此外,通过CSSCI 获取的文献信息不仅包括标题、作者和关键词,还包括被引文献。这有助于进行共被引文献分析,为全面了解我国语料库翻译研究奠定了基础。
(二)元数据收集
首先,以“语料库”和“翻译”为检索词进行所有字段检索,得出2000—2020 年间(截至2020 年7 月18 日)相关文献258 篇。接着,以“语料库”和“口译”为检索词进行所有字段检索,得出2000—2020 年间(截至2020 年7 月18 日)相关文献39 篇。
最后,将两次检索的结果进行整理和核查。去除重复文献8 篇,书评16 篇,文献综述9 篇。最终,本文以从CSSCI 检索出的264 篇文献(涉及参考文献5 719 篇)为本次研究分析元数据。
(三)数据处理过程
将这264 篇文献的基本信息录入CiteSpace5.6.R5,时间跨度选择为2000—2020年,以1 年为切割分区。在选择标准(Selection Criteria)选定g-index(20)或Top 50,得到各个知识图谱。再制成可供科学分析的直观图表,并结合有关文献进行具体分析。
二、文献计量分析
本部分主要从研究力量、研究课题、研究发展历程和研究范式演进对上述264 篇文献进行可视化计量分析,以期全面梳理近二十年我国语料库翻译学研究。
(一)研究力量
本节从论文发表、学术机构分布、作者及合作群体三个方面分析我国近二十年语料库翻译学研究力量和学科发展。
1.论文发表
经分析,上述264 篇文献主要分布的领域有:语言学(234 篇),图书馆、情报与文献学(7 篇),中国文学(5 篇),教育学(3 篇)。近二十年中国语料库翻译研究文献发表趋势分布见图1。
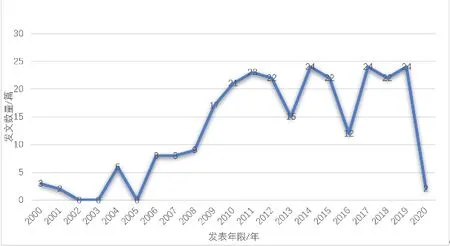
图1 文献发表趋势统计
由图1 可知,近二十年,我国语料库翻译研究发文量总体呈上升趋势。2011 年后,发文数量有所起伏,说明学者需要进一步发掘新的研究角度和增长点。发表上述文献的主要期刊为:《外语电化教学》(34 篇)、《中国翻译》(25 篇)、《外语与外语教学》(21 篇)、《外语教学》(21篇)、《外国语》(20 篇)。
2.学术机构分布
在CiteSpace 得到的合作共现网络中,节点的大小代表了作者、机构或者国家、地区的发文数量,各机构间的连线粗细表示合作关系的紧密程度,不同颜色代表不同的年份[8]。通过分析施引文献发表机构合作共现图谱(见图2),发现近二十年我国语料库翻译研究主要由以下机构进行:北京外国语大学、上海交通大学、上海外国语大学、曲阜师范大学和燕山大学。其中,北京外国语大学处于国内领先地位。上海交通大学、曲阜师范大学为后起之秀。
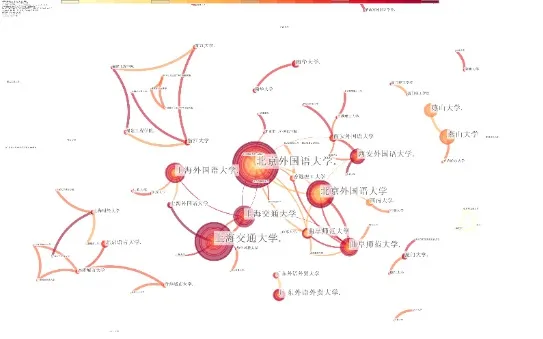
图2 施引文献机构共现图谱
3.作者及合作群体研究
将“作者”作为检索项,发现期刊发文最多的学者分别为:王克非(29 篇)、秦洪武(15 篇)、胡开宝(13 篇)、黄立波(13 篇)、刘泽权(10篇)、张威(7 篇)以及庞双子(7 篇)。其中,胡开宝、张威对口译研究贡献较大。
通过同时检索“机构”和“作者”两项,发现我国的机构和作者之间有着一定的联系和合作,但不紧密。北京外国语大学是该领域的领头羊,其最突出的学者是王克非。除北京外国语大学外,上海交通大学异军突起。2000—2010 年胡开宝促成上海交通大学同上海外国语大学的合作。2014 年后庞双子促成上海交通大学同北京外国语大学的合作。在2014 年后,各高校间的合作逐渐增加,但较少出现跨学科、跨领域合作。
通过梳理研究力量和学科发展,发现近二十年:(1)我国语料库翻译研究逐渐受到全国各高校的关注,北京外国语大学和上海交通大学是领头研究机构。代表学者有王克非、秦洪武、胡开宝等;(2)研究领域主要分布在语言学、翻译学、教育学和文学;(3)各高校间有一定合作,但不紧密,且较少出现跨学科、跨领域合作。
(二)研究课题
关键词(Keywords)代表了文章的核心内容。在特定时期,如果一个关键词在某一领域的文献中反复出现,则可以视为这个时期的研究热点[9]。本节通过分析关键词频次(Frequency)和中心性强度(Centrality),厘清我国近二十年语料库翻译研究的核心和热点课题。
1.关键词频次分析
通过CiteSpace 绘制出近二十年语料库翻译研究关键词共现图谱(见图3)。图中节点的大小与关键词的出现频次成正比,节点间连线代表共现关系[8]。
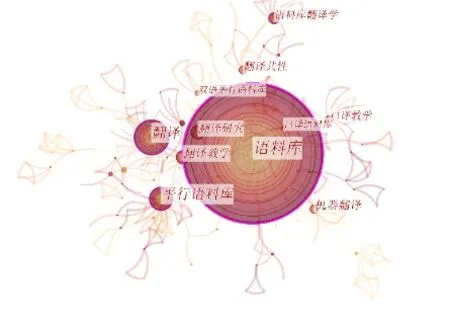
图3 关键词共现网络
图3 中最大的五个节点是:语料库(109 次)、翻译(29 次)、平行语料库(22 次)、翻译研究(14次)、翻译教学(13 次)。它们是语料库翻译研究的核心课题。其他课题有:机器翻译(10 次)、语料库翻译学(10 次)、翻译共性(8 次)、红楼梦(8 次)、口译教学(8 次)、口译语料库(6次)、显化(6 次)、译者风格(4 次)。
语言共性研究和译者风格研究是语料库翻译研究的重要课题[5]。通过图3 发现,相较于翻译共性和译者风格研究,我国学者对语料库建设和语料库同翻译的结合更加重视。此外,“红楼梦”的高频率表明在中国文化“走出去”的大背景下,汉语典籍英译是重要研究对象。
2.关键词中心性强度分析
分析关键词节点的中介中心强度的大小(强度有效取值为0.01)能对一个领域的变化程度进行探测[6]。在上述核心课题中,历年中心性强度最大的关键词如表1 所示。2002 年、2003 年以及2005 年因未有文献发表,所以无关键词。2019—2020 年因是最新年份,未能出现强中介中心关键词。
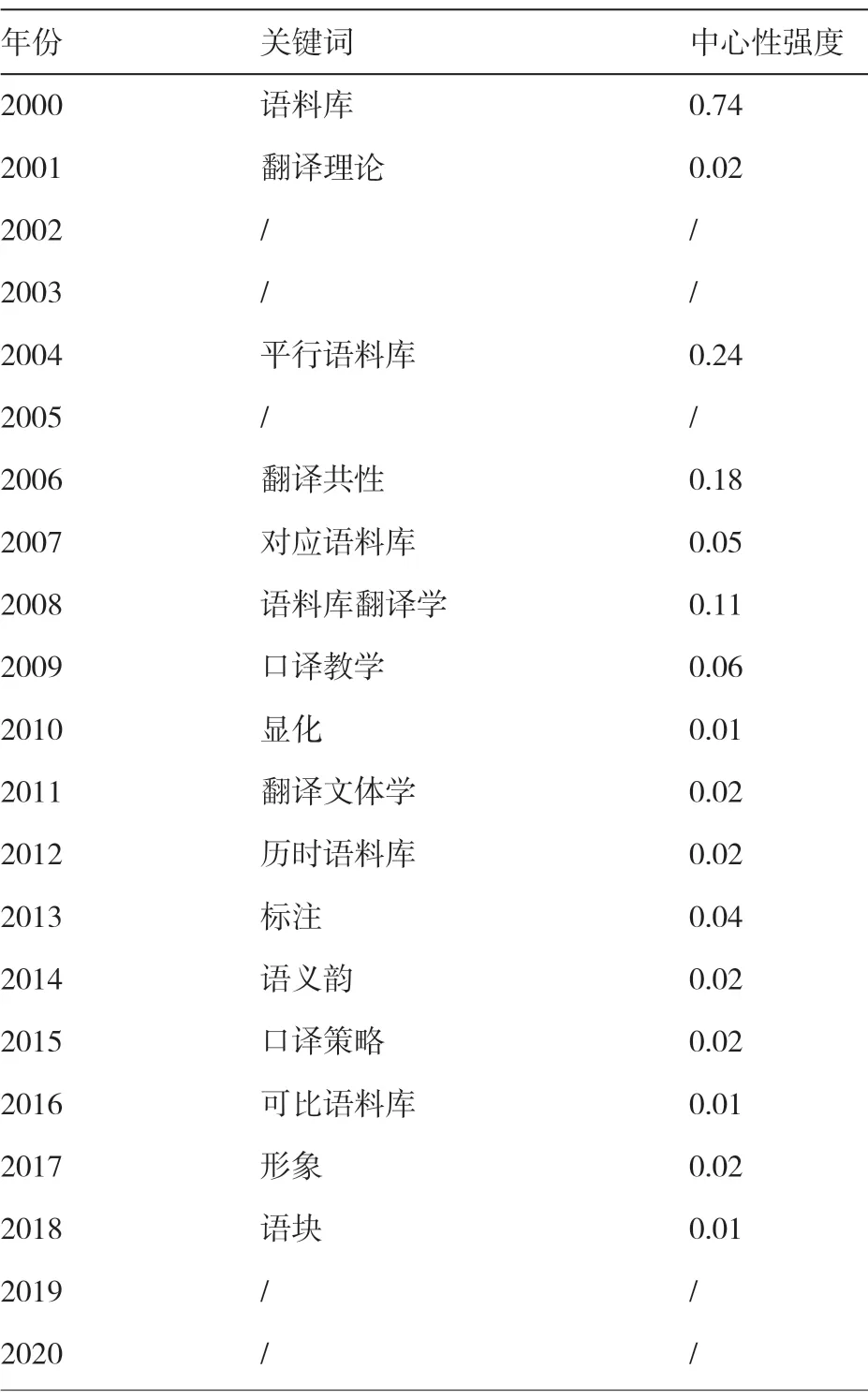
表1 历年关键词中心性强度统计
从历时角度看,我国语料库翻译研究非常重视语料库的建设。从平行语料库、对应语料库到历时语料库和可比语料库,表明运用语料库进行翻译研究的手段逐渐丰富。其次,研究对象逐渐多元,从关注翻译语言到翻译过程,再到转向文本之外的社会、文化和心理因素。研究切入点也不再局限于笔译和文学,口译研究逐渐得到重视,并发展为独立的研究领域。
通过上述对我国语料库翻译研究关键词的梳理和分析,发现:(1)我国语料库翻译学重视研究手段和工具的开发利用;(2)研究对象逐渐多元,既有该领域核心课题(如语言共性、译者风格等)的研究,又有具备中国特色的研究(如汉语典集外译等);(3)翻译语言普遍性依然是研究热点。同时,口译研究逐渐发展为新的热点课题。
(三)研究发展历程
文献共被引是指两篇或多篇论文同时被后来一篇或多篇论文所引证。通过引文网络向前可以追根溯源,向后可以追踪发展[10]。本节运用CiteSpace 绘制语料库翻译研究文献共被引知识图谱,阅读早期、转折点和里程碑文献,以期深入剖析该领域的演进。
1.早期文献
引文半衰期(Half Life)可以形容文献老化程度,显示引文的有效价值[6]。半衰期越大,引文的有效价值越大。通过对共被引文献进行半衰期数值排序(见表2),发现该领域引文半衰期最大且被引频次最高的文献是秦洪武[11]《对应语料库在翻译教学中的应用:理论依据和实施原则》。该文分析了对应语料库、翻译教学和自主学习之间的内在联系,并探讨了汉英对应语料库在翻译教学中应用的原则和方式。
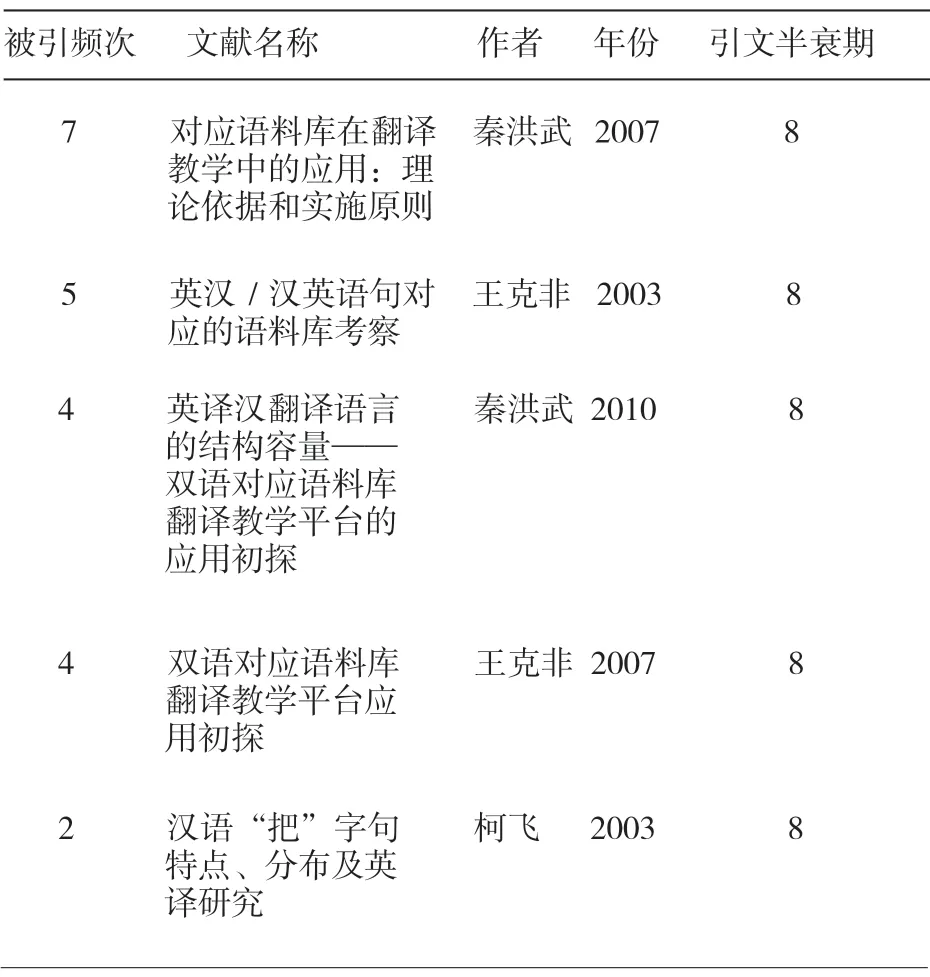
表2 引文半衰期统计
通过这些早期文献,发现我国语料库翻译研究的基础包括:英汉翻译语言特征对比研究、语料库建设和应用、翻译教学和翻译策略等。在早期阶段,语料库翻译研究手段单一,研究对象局限于翻译语言和翻译教学研究,且主要利用语料库进行数据统计并对翻译现象进行描述。
2.转折点文献
共被引文献中心性强度超过0.1 的称为关键节点[12]。近二十年语料库翻译研究按照中心性强度大小排列如表3 所示。
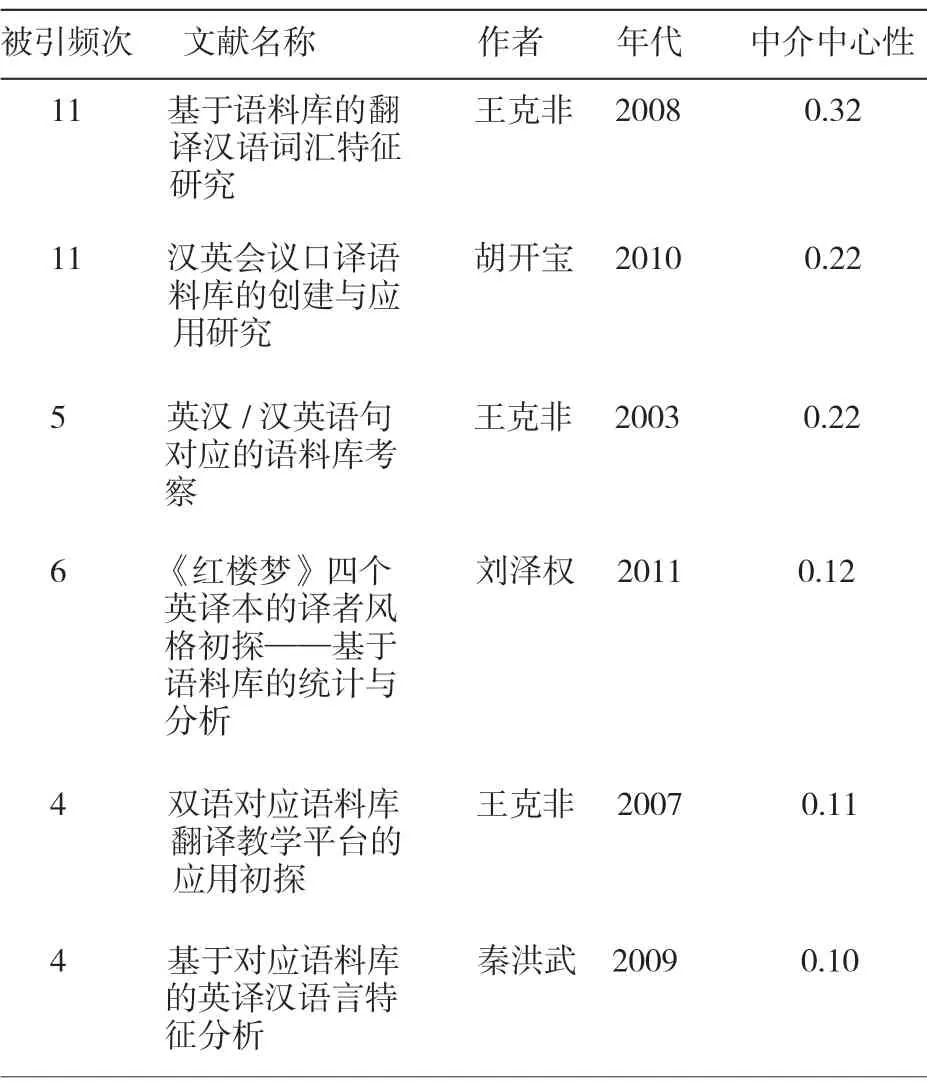
表3 转折点文献统计
其中被引频次最高且中心性最强的是王克非[13]《基于语料库的翻译汉语词汇特征研究》。该文不仅通过“通用汉英对应语料库”中翻译汉语与原创汉语语料进行词汇使用特征对比和分析,并对翻译特征和翻译共性进行了详细的定义和讨论。该文突破了单语类比语料库的研究模式,采用语际对比和语类对比相结合的模式,开辟了新的研究方式。另一转折点是胡开宝[14]讨论了“汉英会议口译语料库(CECIC)”的建设过程和应用,将口译研究和语料库相结合,拓宽了语料库翻译研究范围。
刘泽权[15]基于已建成的“《红楼梦》中英文平行语料库”,对《红楼梦》四个英译本在词汇和句子层面的基本特征进行数据统计和初步的量化分析,比较和探讨了四个英译本在译者风格上的异同,为中国古典文学外译和译者风格研究树立标杆。译者风格研究的实证性质愈发凸显。
通过将这些有代表性的转折点文献连接成时间线,发现从2000—2020 年,重要节点文献可以概括为以下三个阶段:(1)翻译文本共性特征的验证,尤以英语和汉语翻译文本为主;(2)语料库翻译研究运用,如教学、文学研究;(3)研究情境和研究范式的扩展。
3.里程碑文献
具备高强度的被引文献是科学图谱研究中十分重要的里程碑[16]。里程碑文献可以从出现突现(Bursts)的被引文献中获得。通过对全部被引文献进行突现检测,共出现15 篇文献(如图4)。
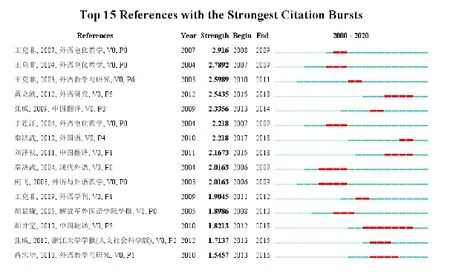
图4 被引文献突现统计
突现强度最高的是王克非[17]《双语对应语料库翻译教学平台的应用初探》。该文以实证研究的方式,通过语料呈现实验探讨双语对应语料库翻译教学平台的应用效果。此外,胡开宝[14]也是重要的里程碑。该文将口译同语料库相结合,拓宽了研究范围。在此基础上,张威[18]客观分析了口译语料库建设的有利条件与特殊困难,介绍了口译语料库建设的总体原则和相关注意事项,同时强调口译语料库与其他口译研究方法相结合的重要性。近五年(2015—2020年)保持较强影响力的文献是黄立波[19]和刘泽权[15],二者引领中国文学作品英译的译者风格实证研究。
通过梳理和阅读早期、转折点和里程碑文献,发现近二十年:(1)我国语料库翻译研究对象依然是语料库翻译研究核心课题,但研究方法逐渐多元;(2)研究切入点不再局限于笔译研究,口译研究也逐渐得到重视,口译研究也不再过分以笔译为标准,而是不断拓展多模态语料库的建设;(3)逐渐从对语言现象的描写发展到对语义、语用的解释。总的说来,我国语料库翻译研究紧跟国际趋势,在原有课题的基础上深化,形成适应汉语特征的相关研究。
(四)研究范式演进
一个领域的研究范式可以通过研究基础和前沿两个领域来判断[6]。通过聚类科学知识图谱,可以从历时的角度对研究领域进行梳理。本节对被引文献进行聚类分析,并绘制被引文献聚类知识图谱(图5),深入解析语料库翻译研究范式发展脉络。
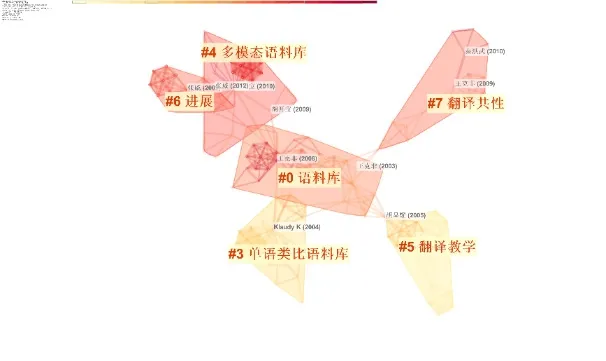
图5 被引文献聚类知识图谱
1.总体分析
一般来说,聚类值Moduality Q 值>0.3 表示划分出来的聚类结构是显著的,且聚类内部相似度指标Silouette S 值>0.7 表示聚类是高效率令人信服的[20]。图5 中 Q 值=0.9158 > 0.3,S 值=0.7329 > 0.7,说明聚类内节点的主题联系较强,具有参考价值。
CiteSpace 从施引文献的标题和摘要中提取高频名词短语作为其聚类名称[7]。在语料库翻译研究领域共生成了6个显著聚类,分别为“语料库(# 0)”“单语类比语料库(# 3)”“多模态语料库(# 4)”“翻译教学(# 5)”“进展(# 6)”和“翻译共性(# 7)”。其中,“语料库(# 0)”“单语类比语料库(# 3)”和“多模态语料库(# 4)”是最大的三个聚类。从颜色深浅可以看出:“单语类比语料库(# 3)”和“翻译教学(# 5)”研究板块颜色较浅,表明是早期研究领域 ;“语料库(# 0)”“多模态语料库(# 4)”“进展(# 6)”和“翻译共性(# 7)”聚类颜色较深,是前沿研究领域。因平均发表时间为2009 年,“多模态语料库(# 4)”代表了语料库翻译的最新研究领域。
2.重点聚类分析
限于篇幅限制,本节仅选取第一大聚类(# 0 语料库)和最新聚类(# 4 多模态语料库)进行重点分析。
(1)# 0 语料库
“# 0 语料库”是最大的聚类,包含36 篇文献。文献发表时间跨度从2003 年至2015 年。其中高频关键词有“汉英翻译”“翻译共性”“词义泛化”“历时类比语料库”和“语料库翻译学”。高被引文献包括王克非[13]、王克非[21]、肖忠华[22]和秦洪武[23]。
该聚类主要聚集了基于语料库对翻译语言共性的研究。描写翻译学的一个重要研究领域就是翻译共性假设及其子假设[22]。翻译共性最早由Baker[24]提出,具体包括显化、消歧、简化、合乎语法性、避免重复、凸显目标语语言特征及其分布六个方面。近年来又增加了独特项假设、干扰、非典型搭配、不对称假设等[5]。我国语料库翻译研究主要基于语料库验证翻译共性假说。其中,“显化”得到较多关注。
显化(Explicitation),即翻译文本的明确程度高于原创文本,或者说翻译过程倾向于在译文中增添信息或语言成分[25]。王克非[21]发现无论是英译汉还是汉译英都存在译本扩增现象,支持显化假说。而秦洪武[23]基于汉英双向对应语料库描写和分析英译汉语言的词汇特征对显化假说提出质疑。许家金[26]则通过对比中国英语学习者与英美人的英语口头叙事话语,发现在人物指称方面,中国英语学习者“过度显化”现象突出。通过对显化研究的梳理,发现我国翻译共性研究方法不再单一基于双语平行语料库,而是运用多种语料库的复合研究模式。同时,研究切入点也逐渐从描述翻译现象扩展到了解释导致现象的原因。
(2)# 4 多模态语料库
聚类“# 4 多模态语料库”共包含24 篇文献。其中,高频关键词有“研究范式”“标注模型”和“口译研究”等。该聚类文献平均发表年限为2009 年,是目前最新研究领域。高被引文献有胡开宝[14]、胡开宝[27]、张爱玲[28]、张威[29]和陶友兰[30]。
多模态语料库是指音频、视频和文字语料等多种信息集成,研究者可以通过多模态方式加工、检索和统计进行相关研究的语料库[31]。多模态语料库的提出和建立是基于口译研究的特殊性和研究需求的发展。口译研究最初借鉴笔译研究建立文字语料库,而胡开宝[14]记录了“汉英会议口译语料库(CECIC)”的建设过程,指出语料转写和语料的口语特征标注存在诸多困难。张威[29]也指出语料收集特别是转写与标注过程的巨大困难,导致口译语料库规模较小。同时,由于口译语料库的标注较为单一,难以充分反映口译操作的特殊性。因此,鉴于口译教学需求和口译研究的特殊性,多模态语料库逐渐走入研究视野。张爱玲[28]建设了包括中文在内的坡度性多语种视频演讲素材库,满足国际国内教学点在专业口译教学及测试中的迫切需求。然而,多模态语料库的建设在我国还处于起步阶段,相关研究欠缺,其相关理论和具体运用还有待进一步研究。
除上述聚类外,其他聚类也值得一提。“# 3单语类比语料库”是早期关注领域,然而随着技术和研究课题的发展,单语类比语料库逐渐不再受到关注。“# 5 翻译教学”聚类也是语料库翻译研究重点课题,教学是继翻译共性研究后最大的课题和应用领域。“# 6 进展”聚类表明语料库翻译学发展较快且十分关注自身的发展。“# 7 翻译共性”是语料库翻译研究核心课题。
上述聚类分析呈现了语料库翻译研究范式的动态演进过程,发现:(1)同国外语料库翻译研究相同,我国学者主要基于语料库对翻译共性,尤其是显性假设,进行验证;(2)研究对象逐渐多元,既有不同体裁的笔译研究,也有基于真实语料的口译研究;(3)基于口译研究的特殊性,多模态语料库是最新研究领域;(4)语料库翻译研究范式逐渐形成。
三、讨论与总结
基于CiteSpace,本文梳理回顾了语料库翻译学在我国近二十年的发展历程,研究现状以及热点话题,发现:
(1)就研究主体而言,以王克非、刘泽权、秦洪武、黄立波等为代表的学者最早介绍了国际语料库翻译研究的理论和前沿成果,推动了中国语料库翻译研究的开展。中后期以胡开宝、庞双子、张威等学者为代表,不断拓展该领域研究深度、手段和范围,实现了我国语料库翻译学研究范式的形成。经过二十年的发展,不断有新的研究者加入,研究力量得到了充实,研究成果丰硕。但该领域研究跨学科能力较弱,新课题开拓和高层次研究有待进一步提高。
(2)从研究课题看,我国语料库翻译研究借鉴国外最新成果,结合汉语特色开展。对该领域重点课题(如翻译语言共性)进行了大量、逐渐深化的研究。在汉语和英语翻译领域对国外提出的翻译语言共性假设进行了验证。然而,其他语种研究较少,且研究过于集中于显化,其他假设验证不够充分。另一重点课题“译者风格”研究得到关注,并结合中国特色。但国内研究起步较晚,大多模仿国外研究方式,研究层次有待提升。新课题在上述课题基础上发展,有机器翻译、翻译教学、口译语料库、第三语码的语言影响等。课题逐渐多元,具有跨学科趋势。但相对于国际研究,我国语料库翻译研究仍较局限。
(3)就研究模式和方法而言,我国语料库翻译研究逐渐从单语类比发展为语类对比和语际对比相结合的复合模式。且我国重视不同类型、不同用途的语料库建设,为该领域研究提供了充分的技术支持。借助工具,通过数据分析、描写、解释相结合的方法,我国语料库翻译研究从语言表面逐层深入。但是,大部分研究“基于语料库”,而“语料库驱动”研究较少。
(4)从研究视角与路径看,语料库翻译学赋予了翻译研究实证科学的性质。然而,国内语料库翻译学范式形成较国外滞后,且大部分借鉴国外研究范式。同时,国内语料库翻译理论研究不足,未能形成足以支撑汉语实证研究的理论基础。
本文仅借助作者和科研机构的共被引分析、关键词共现和文献共被引分析对我国语料库翻译学的演进发展进行了初步的梳理,仍有许多话题值得进一步探讨。例如,可以更进一步分析共被引文献,选择最具影响力或最前沿的研究领域进行深入的个案分析,以此来追踪该领域衍生和发展的重要环节。期待更多的学界同仁绘制出更多视角的语料库翻译学研究知识图谱。
猜你喜欢
现代企业(2022年5期)2022-05-31
外语学刊(2021年1期)2021-11-04
天津外国语大学学报(2021年3期)2021-08-13
天津外国语大学学报(2020年1期)2020-03-25
杂文月刊(2019年14期)2019-08-03
卷宗(2017年26期)2017-10-17
考试周刊(2016年82期)2016-11-01
英语学习(2016年2期)2016-09-10
外语教学理论与实践(2014年1期)2014-06-15
外语教学理论与实践(2014年4期)2014-06-13
