
卷积神经网络图像识别算法的FPGA加速优化研究
2021-11-06 01:00:28马晓光蒋占军
兰州交通大学学报 2021年5期
马晓光,蒋占军
(兰州交通大学 电子与信息工程学院,兰州 730070)
随着人工智能技术的飞速发展,深度学习技术已日渐普及,卷积神经网络(convolutional neural network,CNN)作为深度学习中的一个重要算法,已广泛地应用于计算机图像处理、自然语言识别和文档分析等领域[1-3].
早期的卷积神经网络多是由CPU执行的,但随着应用需求越来越复杂,CPU计算显得缓慢低效.目前实现CNN加速的平台主要有图形处理器(graphics processing unit,GPU)、专用集成电路(application-specific integrated circuit,ASIC)、现场可编程逻辑门阵列(field-programmable gate array,FPGA)三类,其中FPGA平台因为体积小、功耗低、灵活性高等特点,已逐渐成为卷积神经网络硬件加速常用的研究平台[4].
卷积神经网络的FPGA加速研究主要集中在并行计算和内存带宽优化两方面,其中并行计算主要通过设计卷积层间并行、卷积内计算并行和输出通道并行3种方式来实现加速.例如文献[5]提出了一种全并行乘法-加法树模块加速卷积运算等,此类单纯的硬件并行加速方法资源占用较多、带宽需求较大,实际应用中仍需做相应的改进.内存带宽优化通常采用一些优化算法定量分析计算吞吐量和所需内存的带宽,确定最佳性能进而解决资源占用量大的问题,例如基于天花板模型(roofline model)的设计方案等[6].但是此类方案在不同层间需要重新配置,灵活性稍显不足.在加速算法设计方面,一般采用通用矩阵乘法算法(general matrix multiplication,GEMM)将矩阵转换为向量,并对每个向量一对一计算,最后将向量计算结果用in2col函数输出并转换为矩阵[7].但并未减少计算量,同时又产生大量的读写需求和内存需求.为此,本文采用软硬件协同并行优化的机制,在CNN参数定点量化的基础上设计全并行的加法-乘法模块和高效的流水线操作,进一步优化CNN在FPGA上计算的效率.
1 CNN模型参数分析
1.1 CNN加速优化网络模型
卷积神经网络是一种多层的监督学习神经网络,一般包含输入层、卷积层、激活层、池化层和全连接层[8].而每一层的参数更新都会使上一层的输入参数分布逐步偏移,导致网络收敛速度缓慢.为了解决这一问题,Google在2015年提出了一种批量规范化(batch normalization,BN)算法,通过对偏移参数做规范化处理使其达到标准分布,避免梯度消失,从而可加快网络收敛,防止过拟合[9].
本文将识别图形作为输入,经过卷积层、批量规范化层、激活函数层和池化层处理后得到识别结果.其中,卷积层通常是大量数据的乘加运算来实现,假设卷积层共有L个,则第l层的第n个特征图为x(l,n),其表达式为
(1)
其中:M为输入特征图的总数;N为经过卷积运算后得到的特征图的总数;ωl,n为第l层的第n卷积核;*表示卷积运算.
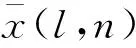
(2)
式中:n=1,2,…,N;μ为卷积参数均值;σ2为卷积参数方差;ε是一个很小的常数,用来排除分母为零的情况;β为偏置;γ为缩放因子.
激活层本文采用ReLU函数,其收敛速度比sigmoid和tanh函数快[10].激活函数主要是为此网络提供非线性建模能力,有效提高网络对于复杂问题的表达能力.池化层本文采用全局平均池化层,有效减少CNN参数规模以及计算量[11].
1.2 卷积参数权值预处理
BN层在网络训练中有很大的优势,在每层卷积后加上BN层代替原来的局部归一化(local response normalization,LRN).由于直接加入BN层会导致网络模型增大,所以将BN层计算和卷积层计算合并,用于提高前向推理的运算速度,同时压缩网络模型[12].由公式(1)和(2)可得
(3)
将公式展开得
(4)
(5)
从而将BN层规范化和卷积计算合并,在每次计算中减少一层运算,能够在一定程度上减少资源占用,并且提高计算速度.
2 CNN模型参数定点化处理
卷积参数预处理是将训练网络简化为卷积层、激活层和池化层.其方式是将卷积层和BN层合并为一层,计算量主要集中在卷积层.文献[13]提出了定点量化与网络准确率平衡的方式,但是在图像识别应用场景中未做分析研究,针对此问题本文提出对卷积层的特征参数动态定点化处理,将浮点计算转换为高效的定点计算.
2.1 浮点数动态定点量化
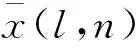
(6)
(7)
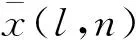
(8)
根据式(8)可得出一个量化误差.在数学概念中,只要误差小于最小精度误差的一半,可视为无损.所以将量化误差与误差精度比较,以查找表的形式选择一个合适的量化范围使用Q格式表示.Q格式是二进制的定点数格式,相对于浮点数,Q格式指定了相应的小数位数和整数位数,在FPGA硬件运算的平台上,可以更快地对数据进行处理,定点数的Q值表示精度见表1.量化的精度决定了卷积运算数据的准确性,对于浮点数使用Q15格式转换定点数,可以保留最高精度,但保留精度越高其精度范围非常小,若超出精度范围会损失全部的有效数据[15].通过这种动态的Q值数据设置,可调整量化后的定点数据精度达到最优,以此来减少定点量化所带来的误差损失.
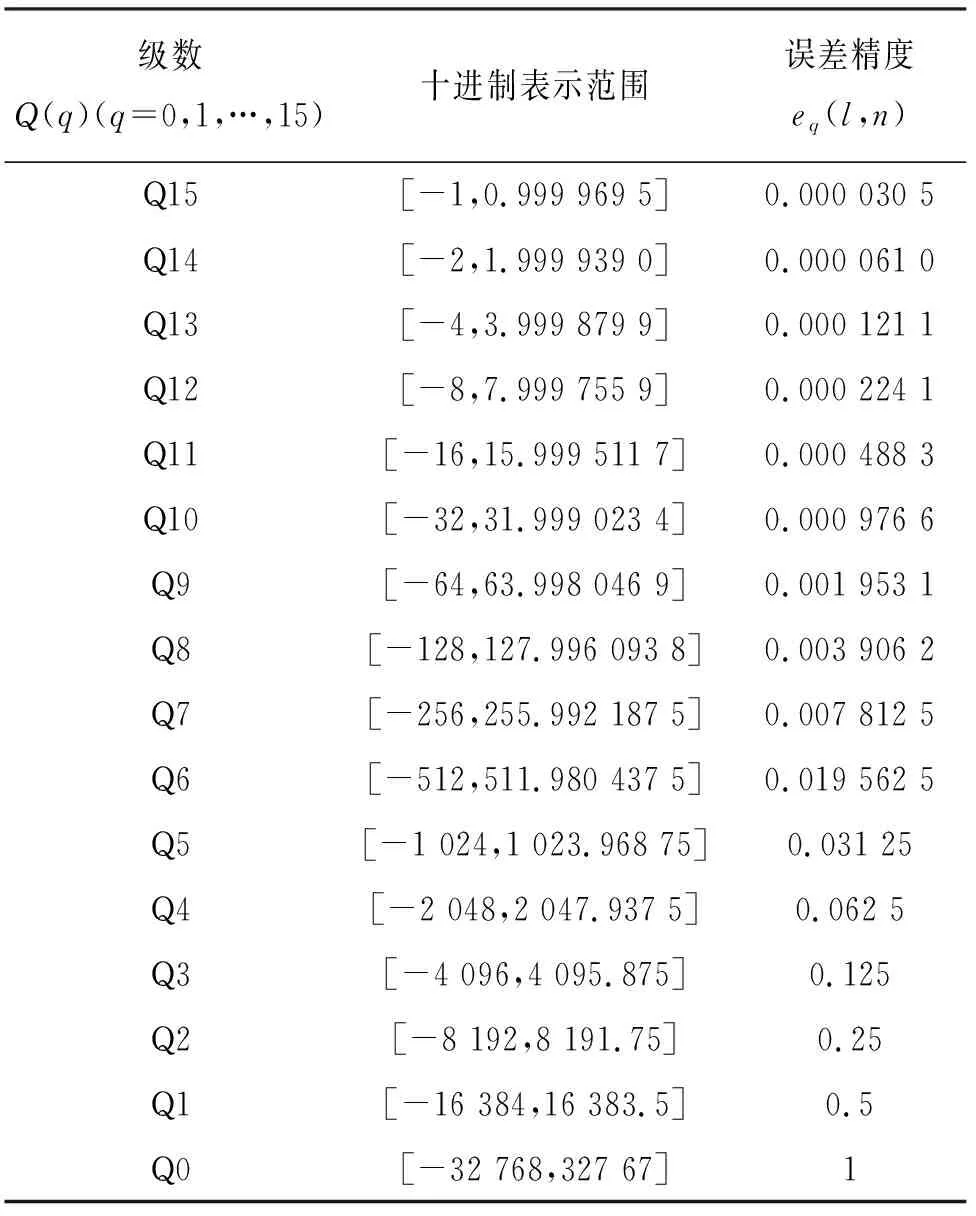
表1 16位定点数Q格式十进制数值范围及精度误差Tab.1 Decimal value range and precision error in 16-bit fixed-point number Q format
2.2 定点量化的取舍
在数据量化过程中,为了进一步提高定点数计算效率,本文采用就近取舍.假设2.1节定点量化后得到一个定点数X,在⎣X」和「X⎤之间的数据取值是一个概率问题,将X舍入到⎣X」的概率与X到「X⎤的接近度成正比:
(9)
3 面向CNN并行优化方式
面向CNN软硬件协同设计是针对开发软件HLS工具和C/C++ 语言相结合的方式所提出的[16].由于FPGA资源受限,不能移植庞大的卷积神经网络实现卷积加速.针对此问题本文提出一种FPGA的并行优化方式.
3.1 软硬件协同设计
软硬件协同是目前卷积神经网络加速研究的一个重要方向,是将整个系统设计集成在一个片上系统(system on chip,SoC)中,片上系统是由可编程逻辑(PL)和ARM处理器(PS)组成,如图1硬件结构设计.ARM处理器通过IP网络接口从PC端获得特征参数和权值并存入DDR存储模块中,然后驱动AXI_DMA控制模块将参数传输到片上存储器(random access memory,RAM)中.ARM会控制CNN硬件加速计算单元将特征参数和权值依次从片上存储系统中传输到CNN加速模块中进行计算.整个运算结束后,ARM驱动AXI_DMA模块,将运算结果返回到DDR,通过IP网络接口传输到PC.
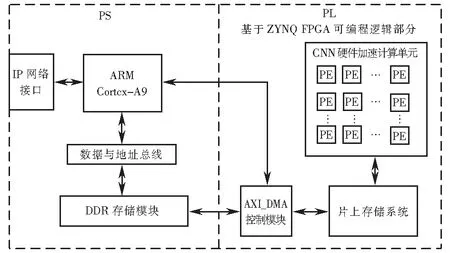
图1 FPGA硬件结构图Fig.1 FPGA hardware structure
3.2 FPGA实现动态定点量化
针对3.1节提出的浮点数动态定点量化方法,设计了基于FPGA的动态定点量化模型.文中提出的定点计算主要分为两个模块:参数量化模块和误差优化模块,如图2所示.参数量化模块主要是对特征图参数和卷积核权值进行定点量化,如图2中左部分,量化器的主要功能是使用3.1节中的方法,对参数和权值做量化和反量化的计算过程.经过定点量化后计算出特征参数误差eq_x和权值误差eq_w.第二部分是误差优化,如图2中右部分,将误差精度数据存储在硬件内部,利用查找表的形式对特征参数误差和权值误差比较,若误差小于最小误差精度的一半,可视为无损量化,然后将量化后的参数存储进行下一步的卷积计算,反之,返回到量化器中重新量化比较,直到参数达到最优为止.
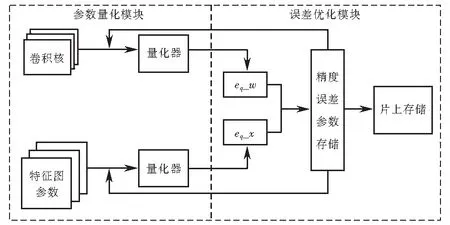
图2 定点量化计算模型Fig.2 Fixed-point quantization calculation model
3.3 卷积层硬件加速设计
为了提高计算效率和减少访问存储器延时,本文提出了并行交错的计算方式,如图3所示,其中FIFO为存储器,buffer为缓冲器,这两部分称为数据通道,后面的卷积运算实质上是乘法运算.为了实现运算加速效果,将特征图中数据和卷积核的矩阵形式转换为数据流形式.提取特征图中的每行数据存储到存储器(FIFO_1),并且提取卷积核每行权重值存储到下一个存储器(FIFO_2),以此方式提取每组数据存储到后面的存储器,将每个存储器中的权值和卷积参数串行输入到寄存器Ai_buffer和Bi_buffer中依次做乘法运算,最后做累加运算.如此方式在有限的设计单元中实现了卷积并行运算.并且在FPGA中每个阶段的计算都是由寄存器来完成,所以不需要等待当前计算执行完成后再将数据提取到Ai_buffer和Bi_buffer中,而是在每个时钟周期内同时进行输入、输出和计算操作,有效地提高了运算效率.
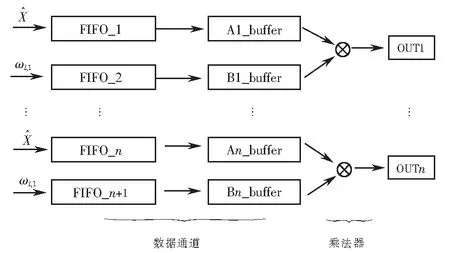
图3 FPGA矩阵乘法原理Fig.3 FPGA matrix multiplication schematic diagram
根据FPGA矩阵乘法原理,本文设计了如图4所示的卷积计算单元,实现卷积层运算在硬件内部的并行加速计算.图4中,I(z,s)表示输入特征图第z行第s列的参数,Wzs表示卷积核内第z行第s列权值参数.在每个时钟周期内每行依次输入一个特征参数与卷积核的权值运算,经过3个时钟周期后可得到一个卷积窗口的运算值.例如,第一个时钟周期输入第z行第一个参数I(z,0),并与卷积核中W00计算得到I(z,0)W00,结果传输到下一级加法器中;第二个时钟周期累加I(z,1)W01的结果,并且得到I(z,1)W00的结果;第三个时钟周期得到I(z,0)W00+I(z,1)W01+I(z,2)W02,同时得到I(z,1)W00+I(z,2)W01的结果,相当于卷积窗口的滑动操作.同时,第z+1行和z+2分别得出结果,累加后得到一个卷积窗口的和.当计算完所有输入特征图后可得出最终的卷积结果.

图4 卷积运算硬件结构设计Fig.4 Design of hardware structure of convolution operation
3.4 数据传输优化
由于卷积网络中数据庞大,考虑到将特征图参数全部存储到FPGA内部存储器中计算是不现实的,而在FPGA数据传输过程中,外部访问数据时延较大.针对这一问题,本文将PL端与PS端使用HLS工具中流数据传输减少传输时延.数据传输的相关伪代码如下:
#pragma SDS data access_pattern(
in_A:SEQUENTIAL,
in_B:SEQUENTIAL,
out_C:SEQUENTIAL
);
int i,j,x,y;
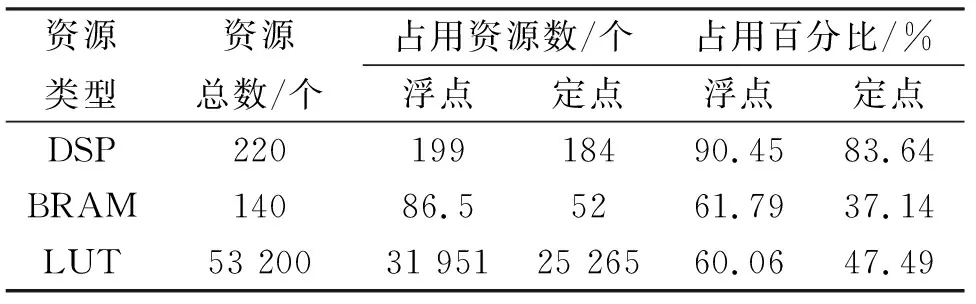
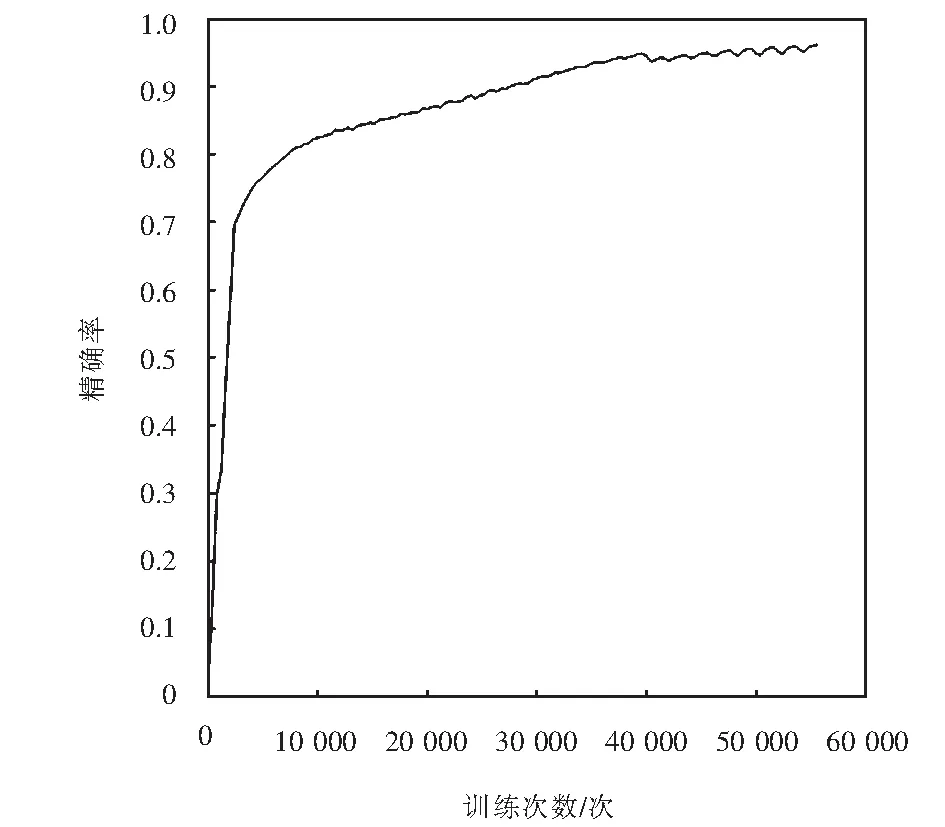
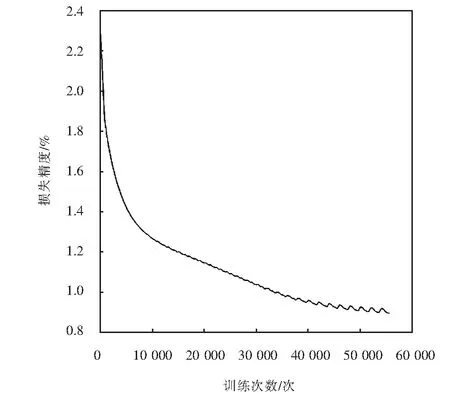
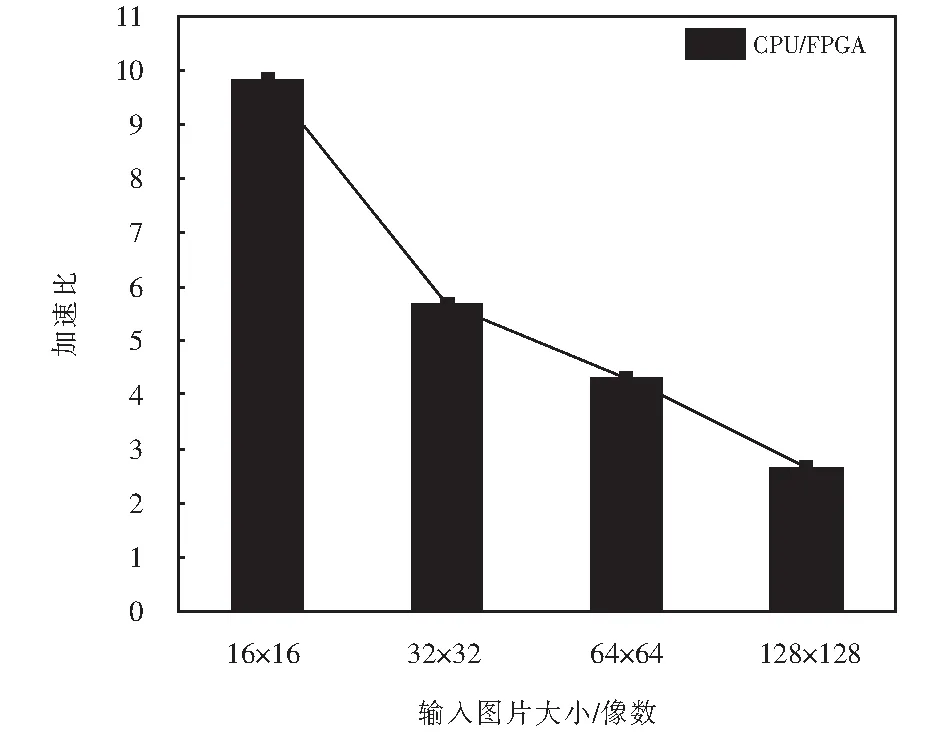
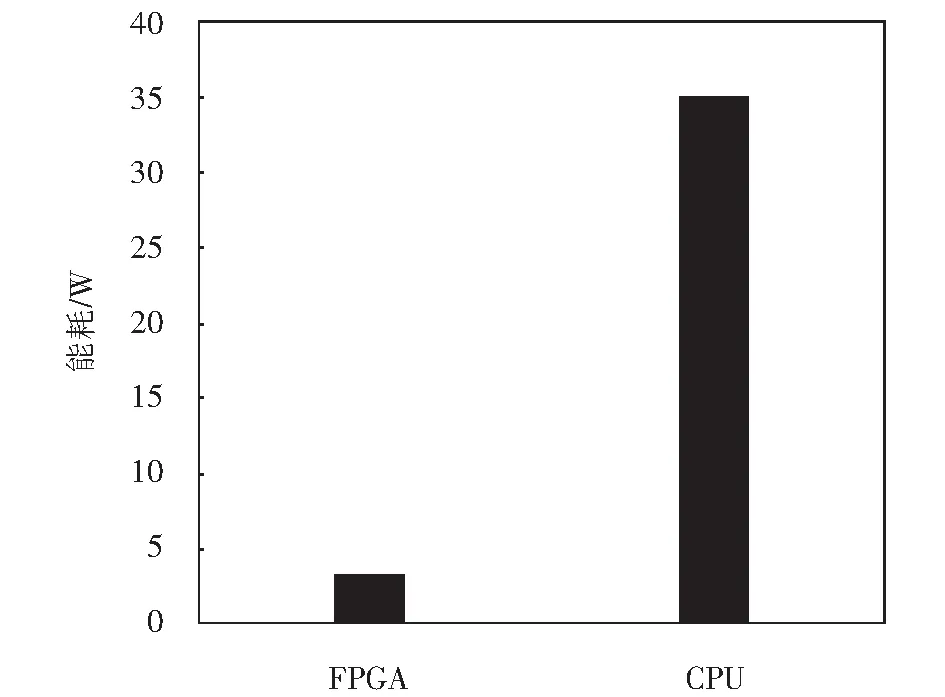
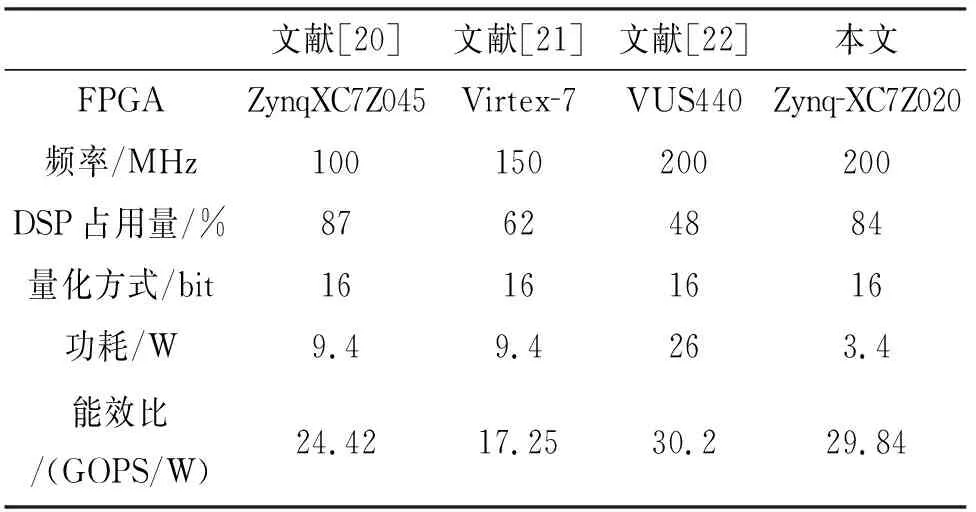
for(i=0;i for(j=0;j #pragma HLS PIPELINE result=0; for(x=0;x #pragma HLS UNROLL for(y=0;y product_term=in_A[x][y]*in_B[x+i][y+j]; result+=product_term; }} out_C[i*N+j]=result; }}} 伪代码中,SDS data access_pattern指令用于规定SDSoC编译器中数据访问的模式,由于在卷积神经网络计算中,数据访问的模式必须是流式访问而不是随机访问,所以将访问模式设置为SEQUENTIAL,则会被综合成流接口(如ap_fifo);否则,将综合为RANDOM,系统可随机访问数组.考虑到卷积计算的流水线操作,卷积计算采用PIPELINE,将卷积特征图矩阵循环展开并使用流水线计算. 实验采用Xilinx XC7Z020嵌入式平台,实验将卷积神经网络已训练的权值移植到FPGA中实现硬件加速,并对数据结果进行分析.首先对比数据定点量化前后FPGA资源占用情况,资源占用见表2.由于本文采用定点数据格式,所以计算资源DSP和内存占用资源BRAM分别减少约6%和24%.查找表(look-up-table,LUT)使用量减少是因为定点数乘加不消耗LUT资源,但本文在Q格式定点量化中以查找表方式确定无损量化需要大量的LUT资源,所以无明显减少. 表2 浮点数及定点数卷积层资源消耗对比Tab.2 Comparison of resource consumption between floating points and fixed points convolutional layer 将硬件资源占用率情况与文献[17-18]中的结果进行对比,见表3.DSP利用率达到83%,相较于文献[17]和文献[18],本文对FPGA内部计算资源高效利用,BRAM占用率相较于其他两种方案都有所减少,LUT相较于文献[17]有所增加,是因为本文采用Q格式动态定点量化,使用FPGA内部查找表资源. 表3 资源利用对比Tab.3 Comparison of resource consumption % 实验以图像种类识别作为具体实验的应用背景,采用caffe深度学习框架,利用cifar-10数据集做为测试,其中包含50 000个样本的训练集和10 000个样本的测试集.对浮点数定点量化后对网络重新训练,当训练次数达到40 000次后,由图5中可看出,识别率达到90%以上且趋于稳定,说明定点优化后网络精度没有明显的降低;同时损失曲线收敛,拟合度较好,说明网络不存在过拟合问题,见图6. 图5 训练识别率结果Fig.5 Training recognition rate result 图6 训练损失收敛曲线Fig.6 Training loss convergence curve 针对不同平台卷积计算速度对比如图7所示.FPGA的工作频率为200 MHz,CPU采用Inter Core i5-3337U处理器,主频为1.8 GHz.图7中加速比η=tc/tf,tc为CPU处理图片时间,tf为FPGA处理图片时间.随着输入图片大小的增加,FPGA处理速度明显高于CPU处理速度,且功耗很低,见图8.但当图片大小增加时,加速比明显下降,因为数据的增多会使FPGA内部数据传输速度有时延,导致处理速度有明显的下降. 图7 FPGA与CPU加速性能对比Fig.7 Comparison of FPGA and CPU acceleration 图8 FPGA与CPU功耗对比Fig.8 FPGA and CPU power comparison performance 本文以AlexNet[19]网络模型为基础,FPGA底层运算代码采用C++ ,设计卷积前向推理加速器.表4是与其他FPGA加速方案结果进行对比,由于各方案选用的FPGA硬件平台不同,为了进行有效对比增加了能效比参数.从表4中结果可看出,本文DSP利用率相对较高,说明本设计充分利用FPGA内部计算资源且功耗相较于其他三种方案最低.能效比达到了29.84 GOPS/W,但相较于文献[22]还有一些差距. 表4 FPGA硬件加速对比Tab.4 FPGA hardware acceleration comparison 本文针对卷积神经网络可并行提出了基于FPGA的卷积神经网络图像识别算法加速优化研究,将卷积层与BN层合并计算,压缩网络模型,在此基础上针对卷积运算中的浮点数设计了Q格式动态定点量化,有效地提升了前行推理的计算速度,并且在有限资源的FPGA中减少了资源的占用.在硬件方面针对CNN可并行性设计了全并行乘法-加法结构,利用高效的流水线传输方式对卷积窗口进行缓存和计算,相比于CPU串行计算有大幅的提升.而本文只是针对卷积层进行优化,未考虑到其他网络层的优化,后续工作为了提高FPGA加速性能,将深入研究网络结构,改进其他层的网络结构,并且在FPGA并行计算的基础上优化硬件结构.4 实验结果与分析

5 结论
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04中学生数理化(高中版.高考数学)(2022年4期)2022-05-25 13:07:02中学生数理化(高中版.高考数学)(2022年1期)2022-04-26 14:09:30今日农业(2021年21期)2021-11-26 05:07:00新世纪智能(教师)(2021年2期)2021-11-05 08:43:20教育周报·教育论坛(2021年21期)2021-04-14 00:09:18沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46数学小灵通(1-2年级)(2020年6期)2020-06-24 05:57:54自动化学报(2017年7期)2017-04-18 13:41:02中学生数理化·八年级数学人教版(2017年2期)2017-03-25 16:12:51
