
基于高光谱的黑色签字笔墨水种类鉴别方法研究
2021-11-03 09:21王书越杨玉柱何伟文李润康
分析测试学报 2021年10期
王书越,杨玉柱,何伟文,李润康
(中国人民公安大学 侦查学院,北京 100038)
近年来,签字笔以其书写流畅、供墨稳定、颜色持久等优势受到人们的青睐,逐渐取代了圆珠笔和钢笔在市场上的主导地位。签字笔可根据墨水成分分为水性笔、油性笔和中性笔,其中,中性笔使用最为广泛。签字笔墨迹是文件、证件、支票等造假案件中的重要证据。法庭科学家们通过分析可疑笔迹的墨水种类,可以了解一些书写行为并推断书写工具是否具有同一性[1-2]。因此,设计一种快速、准确的方法鉴别签字笔墨水种类对解决涉及笔迹检验的经济案件或民事纠纷具有重要的理论和实际意义。
墨水种类的鉴定方法可以分为有损检验和无损检验。薄层色谱法[3-4]、高效液相色谱法[5]等通过对墨水着色剂成分的分离实现墨水的种类鉴定,但此类方法破坏了样本的原始性,且耗费大量的时间。紫外-可见光谱法[6]、显微分光光度法[7]、傅里叶变换红外光谱法[8]、拉曼光谱法[9-10]和近红外光谱法[11]等可进行快速、灵敏、无损分析,使墨水的种类鉴定不仅基于着色剂的组成,而且基于添加剂和元素含量的差异。高光谱成像技术(Hyperspectral imaging,HSI)是一种较新的法庭科学分析工具,具有多波段、波长范围宽、非接触、图谱合一等特点,最大限度地减少了试剂消耗和样本制备过程。利用高光谱相机可以同时获得待测物的空间和光谱信息,形成一个图像数据立方体[12]。由于物体反射光谱的唯一性,因此可以区分化学成分相似的墨水之间光谱的细微差异。Reed 等[13]利用HSI鉴别了白色办公纸上不同品牌型号的蓝色、红色和黑色中性笔墨水,Devassy等[14]在中性笔墨水高光谱数据分析中比较了主成分分析和t-随机邻近嵌入算法降维的效果并进行了评价。
尽管高光谱成像技术在墨水种类鉴别方面具有优势,但黑色签字笔墨水成分基本相同,数据差异小,难以通过观察进行区分。因此本实验基于常见黑色签字笔墨水的高光谱数据,借助机器学习算法建立了线性判别分析模型(Linear discriminant analysis,LDA)和随机子空间-线性判别分析集成模型(Random subspace method-linear discriminant analysis,RSM-LDA),实现了高光谱数据的深度挖掘和黑色签字笔墨水种类的准确分类。
1 实验部分
1.1 仪器与实验材料
采用深圳中达瑞和科技有限公司SEC-E1100凝视型高光谱成像仪,光谱范围为450~950 nm,扫描精度为1 nm,采样间隔通道为10 nm,照明光源为4 盏50 W 卤素灯(左、右轴各2 盏),照明角度为45°,工作温度为32.9 ℃,曝光时间为标定光源参数。
实验材料为我国市场上常见的黑色签字笔,共15 个品牌36 个型号。将收集到的36 支黑色签字笔依次编号,在同一规格的白色A4 打印纸上依次书写“1 号”至“36 号”字样,每支笔重复书写3 次,制备过程中避免污染。
1.2 光谱采集与校正
采集时将书写材料放置于专用平台中央,调焦清晰后采集高光谱图像。为消除由光源强度分布不均带来的噪音,对高光谱设备记录的所有图像进行黑白校正。白板标定图像(W)是由制造商提供的标准聚四氟乙烯白瓷砖得到的图像,黑板标定图像(D)为关闭光源并合上镜头盖后采集的图像,每个样本的校正图像(I)通过方程(1)从原始光谱图像(Isample)中获得。

1.3 数据提取与预处理
使用ENVI 5.3 软件读取校正后的高光谱图像信息,为确保所选特征点均匀、不重复且具有代表性,对每支黑色签字笔的3 份平行高光谱图像分别手动选取6 个含50 个像元的感兴趣区域(Region of interest,ROI),即每支黑色签字笔高光谱图像可提取18个ROI,得到相应的平均光谱值。最终,从36支黑色签字笔笔迹的高光谱图像中共提取到648个原始平均光谱值,作为样本集。
在采集过程中,由于书写材料背景和杂散光等的影响,会产生其他无关信息和噪音,直接建模时将影响建模效果[15]。因此,光谱预处理采用Savitzky-Golay 平滑(S-G 平滑)、Z-Score 标准化和两者组合的预处理方法。S-G 平滑是最常用的去噪声方法,其实质是一种加权平均法。本实验采用7 点S-G平滑,以窗口内中心波长点k及前后w点处的测量值按照(2)式计算所得的平均值-xk代替波长点的测量值,自左至右依次移动k,完成对所有点的平滑。

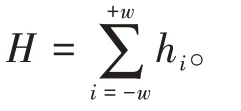
此外,不同样品在同一仪器参数下得到的高光谱相对强度差异较大,为使数据指标之间具有可比性,旨在消除数据量纲影响的标准化对模型的建立至关重要。Z-Score标准化为常用方法,其公式为:

式中,x~ 为标准化后的观测值,x为某一观测值,xˉ为所有观测值的平均值,σ为所有观测值的标准差。
数据预处理和建模分析软件使用Matlab 2019a。
1.4 模型建立
线性判别分析(LDA)是一种泛化性能良好且应用广泛的分类模型,其原理是将高维的样本投影到某个空间,使训练样本在新空间具有最大的类间距离和最小的类内距离[16],而在测试阶段,该模型可将新样本识别为新空间下最近类中心的一类[17-18]。在多分类问题中,为了得到新空间的投影向量,一般定义类间散度矩阵为:

式中,L为类别数,Pi为第i类别的先验概率,mi为第i类别的均值,m为整个样本集的均值。
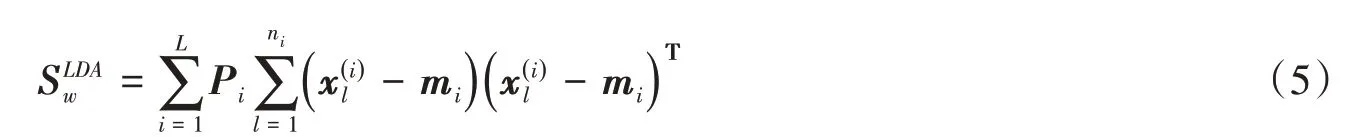
式中,ni为第i类别的样本个数,为第i类别的第l样本。线性判别函数即最佳投影向量e可以表示为:

这相当于找到下列广义特征值问题的最大特征值λ:

在找到最佳投影向量后,将投影后的新样本分配到距离最小的类别。本实验最终得到35个判别函数,其中方差贡献度最大的为第一判别函数,如下:y= 0.08x1-0.04x2+ 0.27x3+ 0.15x4-0.31x5-0.09x6+ 0.11x7+ 0.10x8+ 0.06x9-0.09x10-0.17x11-0.01x12+ 0.20x13-0.14x14+ 0.13x15+ 0.18x16-0.32x17+0.22x18-0.05x19-0.20x20-0.04x21+0.17x22+0.12x23+0.14x24-0.16x25-0.27x26-0.03x27+0.01x28-0.11x29+0.12x30-0.09x31+0.26x32-0.15x33+0.09x34+0.10x36-0.01x37+0.03x38+0.11x39+0.02x40+0.01x41+0.01x42-0.21x43+0.01x44+0.03x45+0.06x46+0.15x47-0.03x48-0.09x49-0.12x50+0.07x51。
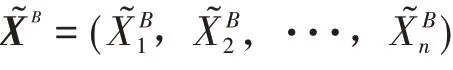
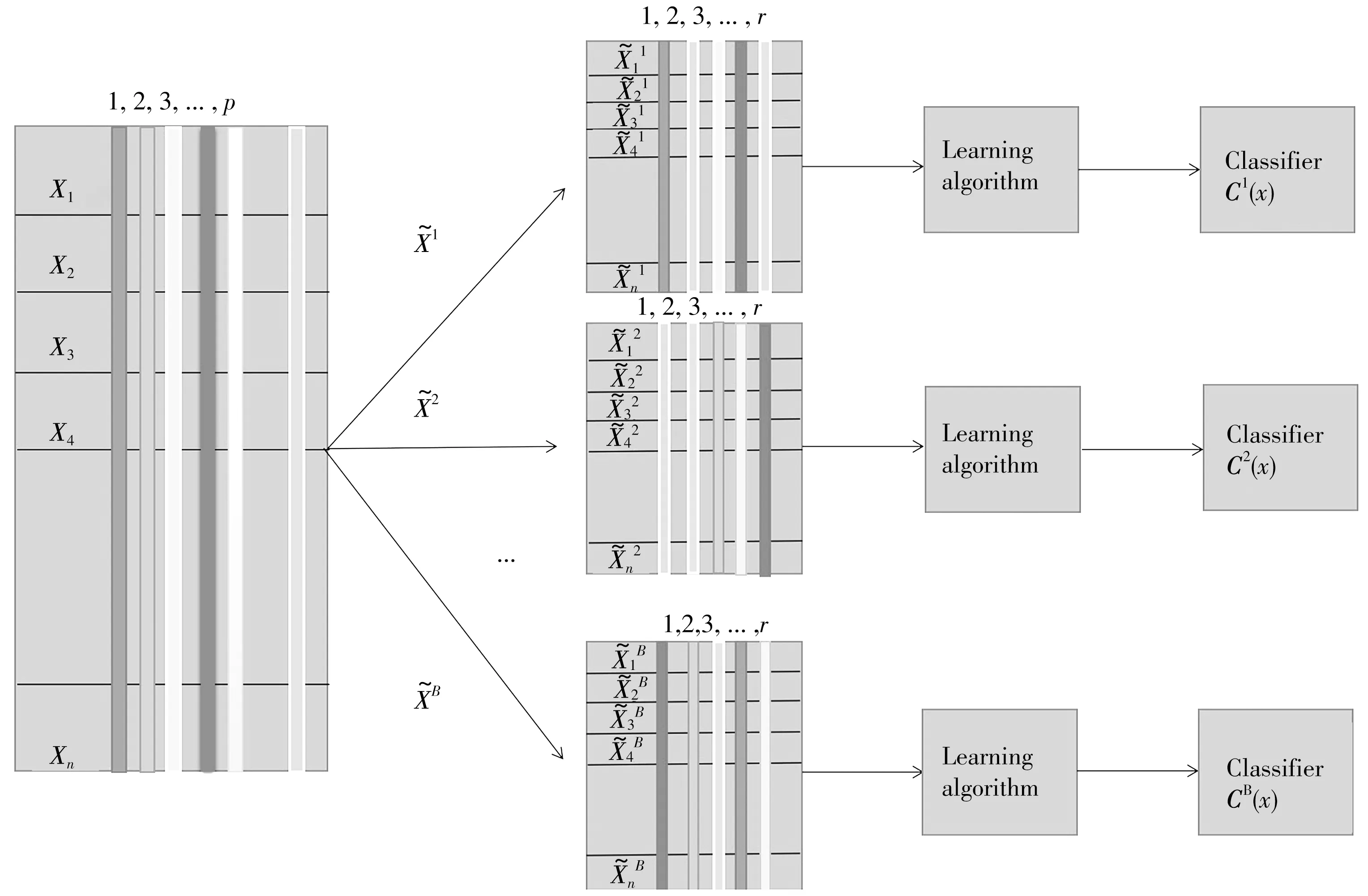
图1 RSM-LDA工作流程Fig.1 Workflow of RSM-LDA
2 结果与讨论
2.1 原始光谱分析
648 个样本的平均原始光谱见图2,其在470~550 nm 波段内呈缓慢下降趋势,550 nm 处有一个小的吸收峰;550~680 nm 波段内的变化幅度小,曲线较为平缓;当波长大于680 nm 之后,光谱反射率增强,光谱曲线总体呈上升趋势,其中一部分迅速上升,在890 nm 后较为平缓;其余大多数曲线缓慢上升,在740 nm 处有一个小的吸收峰。该结果表明有两类黑色签字笔的墨水成分差异很大。其余不同种类黑色签字笔墨水的高光谱图像形态高度一致,需要借助机器学习对高光谱数据进行分析。
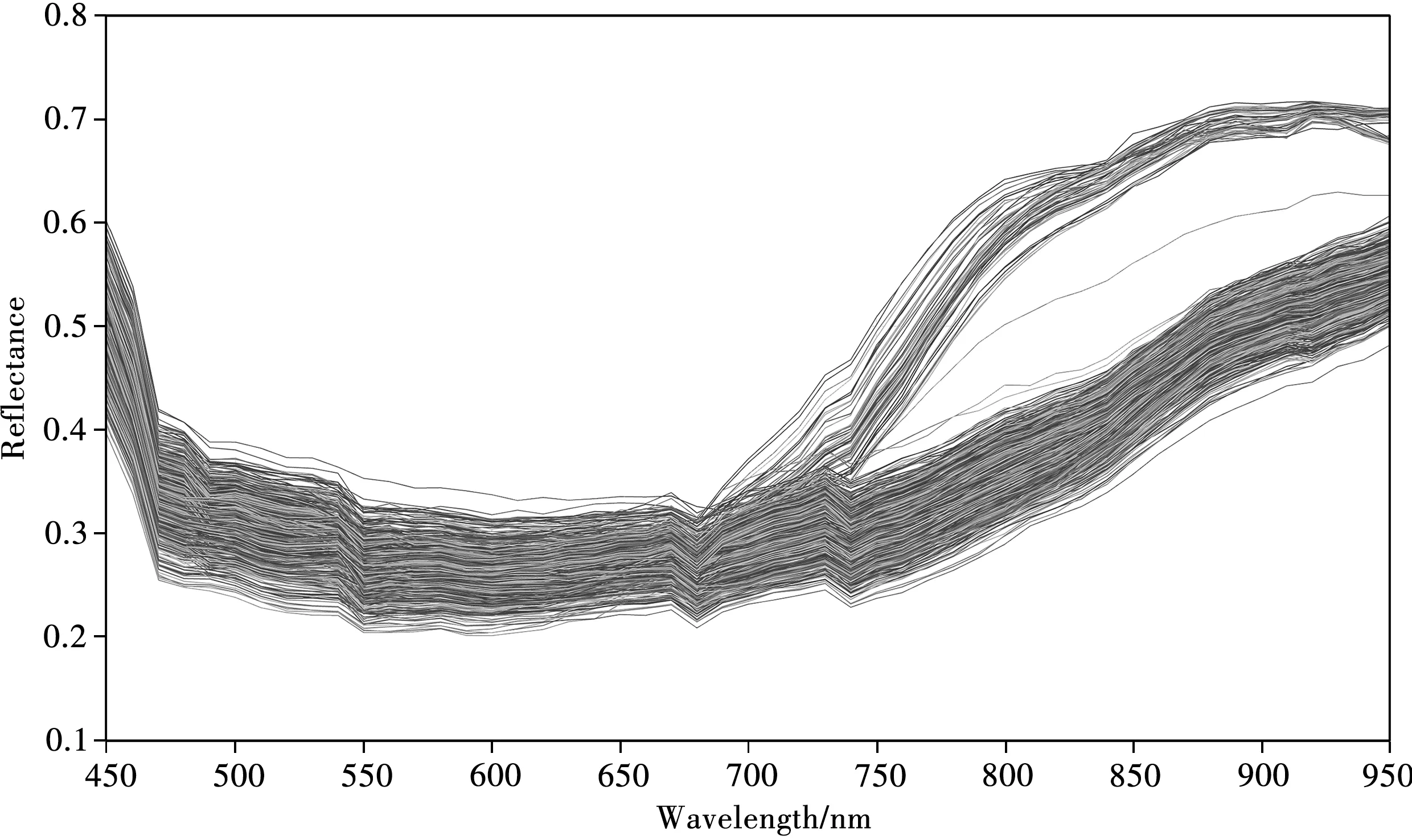
图2 648个样本的原始光谱图Fig.2 Raw spectra of 648 samples
2.2 数据预处理
对原始光谱进行Savitzky-Golay 平滑、Z-Score 标准化和两者组合的光谱预处理,以预处理后数据所建模型的交叉验证准确率(ACCCV)作为预处理方法的选择依据。图3A 展示了不同预处理方法下光谱的LDA 模型分类结果,未进行预处理的准确率达98.61%,单独使用S-G 平滑后,准确率上升到98.88%,表明S-G 平滑可以有效提高光谱的平滑性,降低噪音干扰;单独使用Z-Score 标准化,准确率无明显提升;两种预处理方法同时使用,准确率达99.07%。图3B 展示了不同预处理方法下光谱的RSM-LDA 模型分类结果,不难发现,预处理对模型的分类准确率无影响,表明该模型的学习能力和稳健性强。最终采用S-G 平滑和Z-Score 标准化组合方法对原始光谱进行预处理,结果如图4所示。
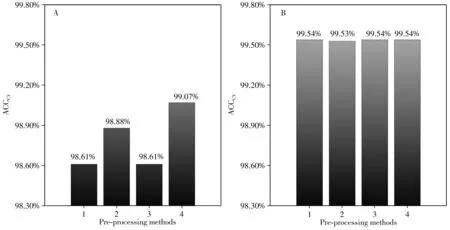
图3 不同预处理方法的分类结果Fig.3 Classification results of different pre-processing methods
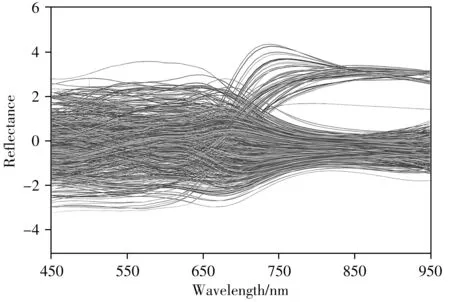
图4 预处理后的样本光谱曲线Fig.4 Spectral curves after combination of S-G smoothing and Z-Score pretreatment for sample
2.3 黑色签字笔的LDA及RSM-LDA分析
将数据集以均匀随机抽样的方式按4∶1 的比例分为训练集(Train set)和测试集(Test set),其中训练集用于训练模型的参数和评估模型的拟合能力,测试集用于评价模型的泛化能力。对每个模型进行五倍交叉验证,根据求得的误分类率的均值调整模型参数。由于黑色签字笔墨水大部分谱图规律高度一致,为了防止图像中的细微信息丢失,本实验选择直接对全谱图数据进行分析。
研究表明,LDA 和RSM-LDA 模型训练集的平均分类准确率分别为99.54%和100%,交叉验证平均分类准确率分别为98.16%和99.09%,两种模型测试集的分类结果如图5所示。对于测试集的129个样本,LDA模型有20个样本被误判,RSM-LDA模型有12个样本被误判。综上所述,LDA模型测试集平均分类准确率为84.50%,RSM-LDA 模型测试集平均分类准确率为90.70%,比LDA 模型提高了6.20%。两种分类模型均可有效区分不同品牌型号的黑色签字笔墨水,其中,RSM-LDA模型的分类效果更佳。
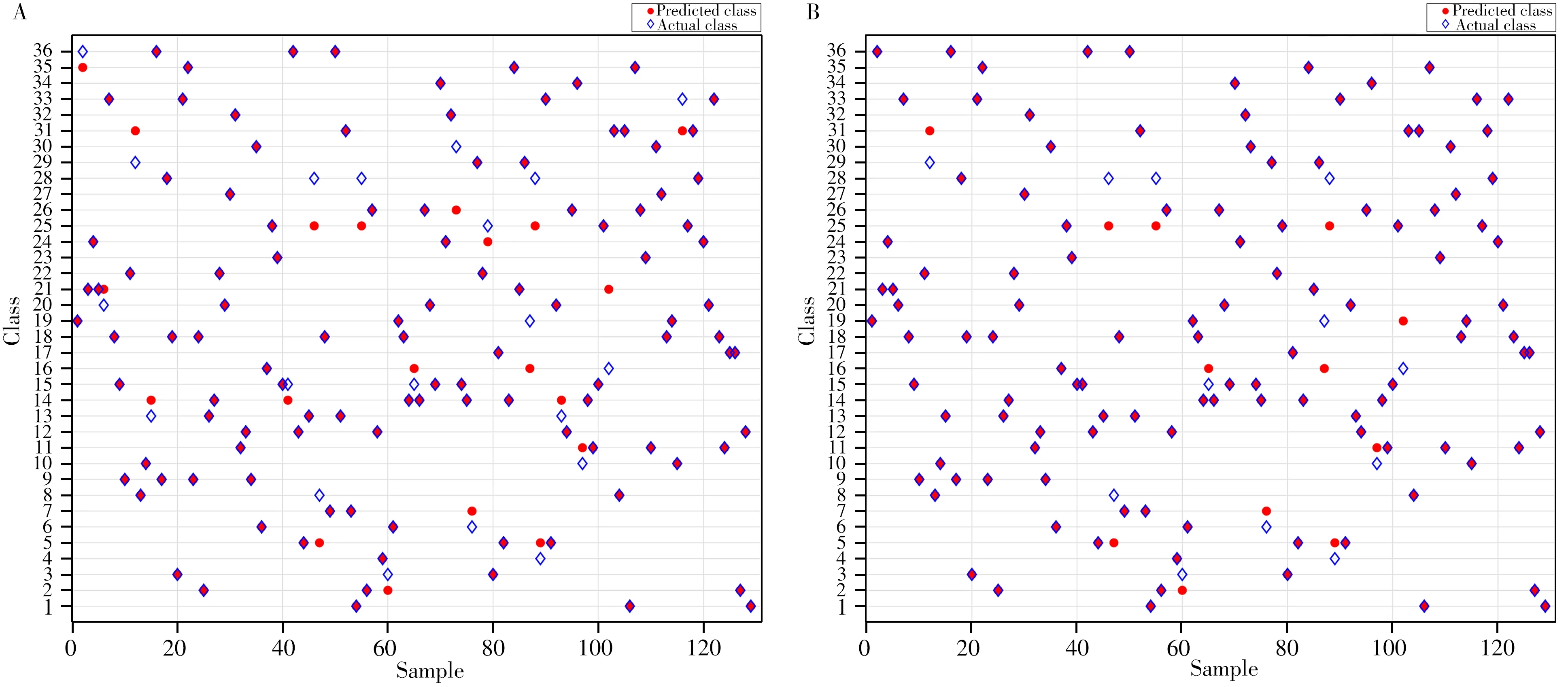
图5 LDA(A)和RSM-LDA(B)测试集分类结果Fig.5 Classification results of test set of LDA model(A)and RSM-LDA model(B)blue hollow diamonds represent the actual category,and red solid circles represent the predicted category
2.4 模型评估
2.4.1 准确率、精准率及召回率 为了解模型的泛化能力,考察了LDA 和RSM-LDA 分类模型每类样本的准确率、精准率和召回率,如表1 所示。准确率即预测正确的结果占总样本的百分比;精准率指所有被预测为正的样本中实际为正的样本的概率;召回率指实际为正的样本中被预测为正样本的概率。以上3 个指标越大,则说明模型分类能力越强。
从表1可以看出,36类黑色签字笔墨水样本的LDA模型和RSM-LDA模型准确率均不低于97.9%,可以有效区分样本。在LDA 模型中,1 号晨光牌(ARP50904)、12 号晨光牌(AGPA3903)和23 号得劲牌(17A)的样本准确率最高,达到100%;16号成田良品牌(80)和31号爱好牌(47920)的样本准确率最低,为97.9%。而在RSM-LDA 模型中,有11 类样本可100%准确分类,准确率最低为97.9%,为28 号样本。在精准率方面,LDA 模型有10 类样本可达100%,80%及以下的有11 类,最低的是31 号样本,为58.8%;而RSM-LDA 模型有15类样本精准率可达100%,80%以下的只有5类,最低的是3号和5号样本,为62.5%。其中,有19 类样本在使用了RSM-LDA 模型后精准率有所提升,只有5 类样本略有下降。就召回率而言,LDA模型有10类样本达100%,80%以下的有11类,最低的是28号真彩牌(0221B)和29号三菱牌(UB-150)的样本,为50.0%;而RSM-LDA 模型有15类样本召回率达100%,80%以下的有7类,最低为50.0%,同样是28号和29号样本。其中,有15类样本在使用了RSM-LDA模型后召回率有所提升,只有3 类样本略有下降。由此可见,RSM-LDA 模型可以更有效地区分黑色签字笔墨水种类且泛化能力良好。
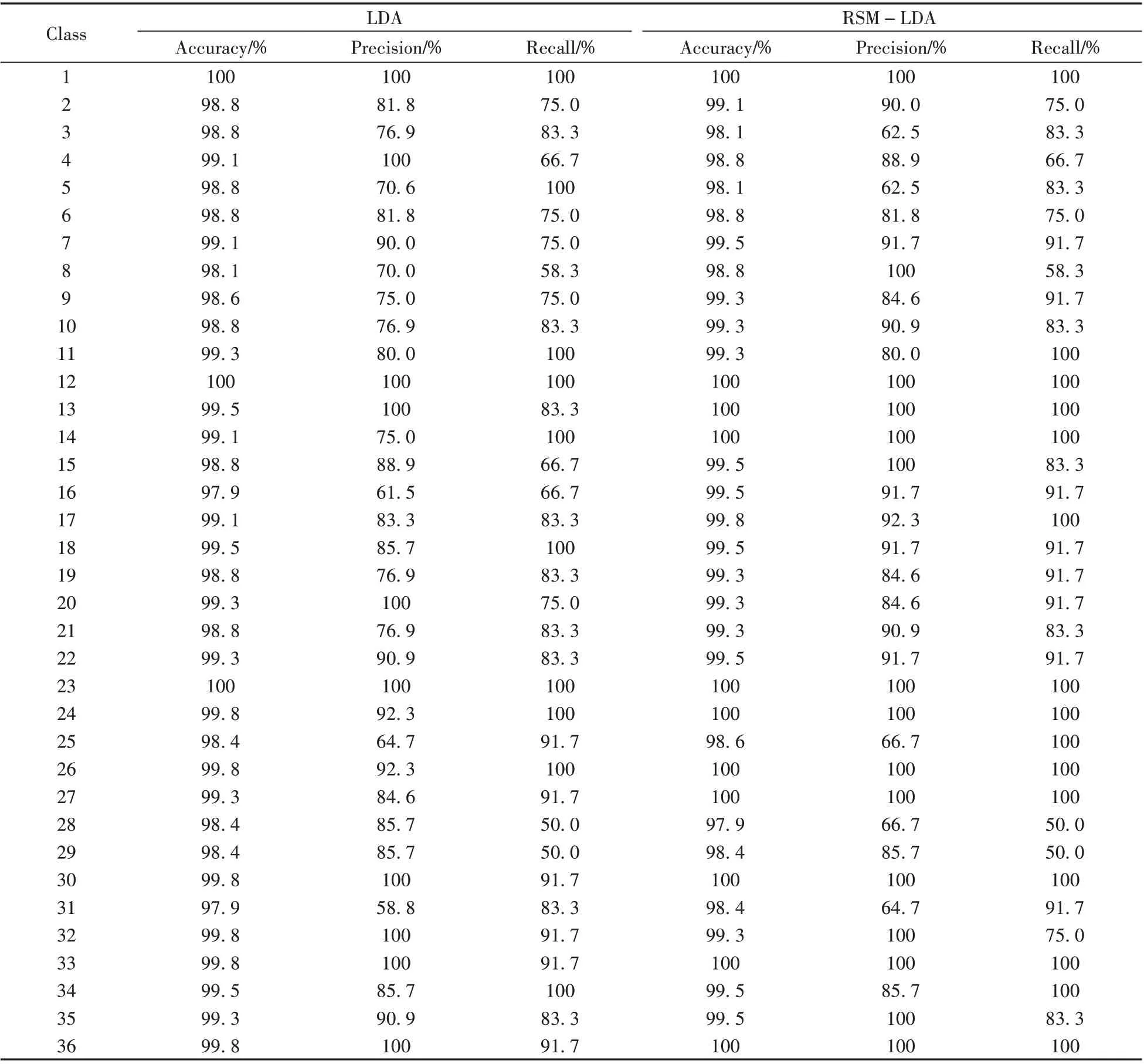
表1 36类样本的准确率、精准率和召回率Table 1 The accuracy,precision and recall of 36 classes samples
2.4.2 接受者操作特征曲线 为进行更全面的评估,本实验考察了两种模型的接受者操作特征曲线(Receiver operating characteristic curve,ROC),如图6 所示。ROC 曲线下方面积(Area under ROC curve,AUC)可用于评估模型的性能,AUC 越大,模型分类性能越强[22]。结果表明RSM-LDA 模型具有更大的AUC(0.998 3),这是因为随机特征选择产生多个分类器,RSM-LDA模型比LDA模型对噪声的抵抗力更强,对频谱的稳定性要求更低。
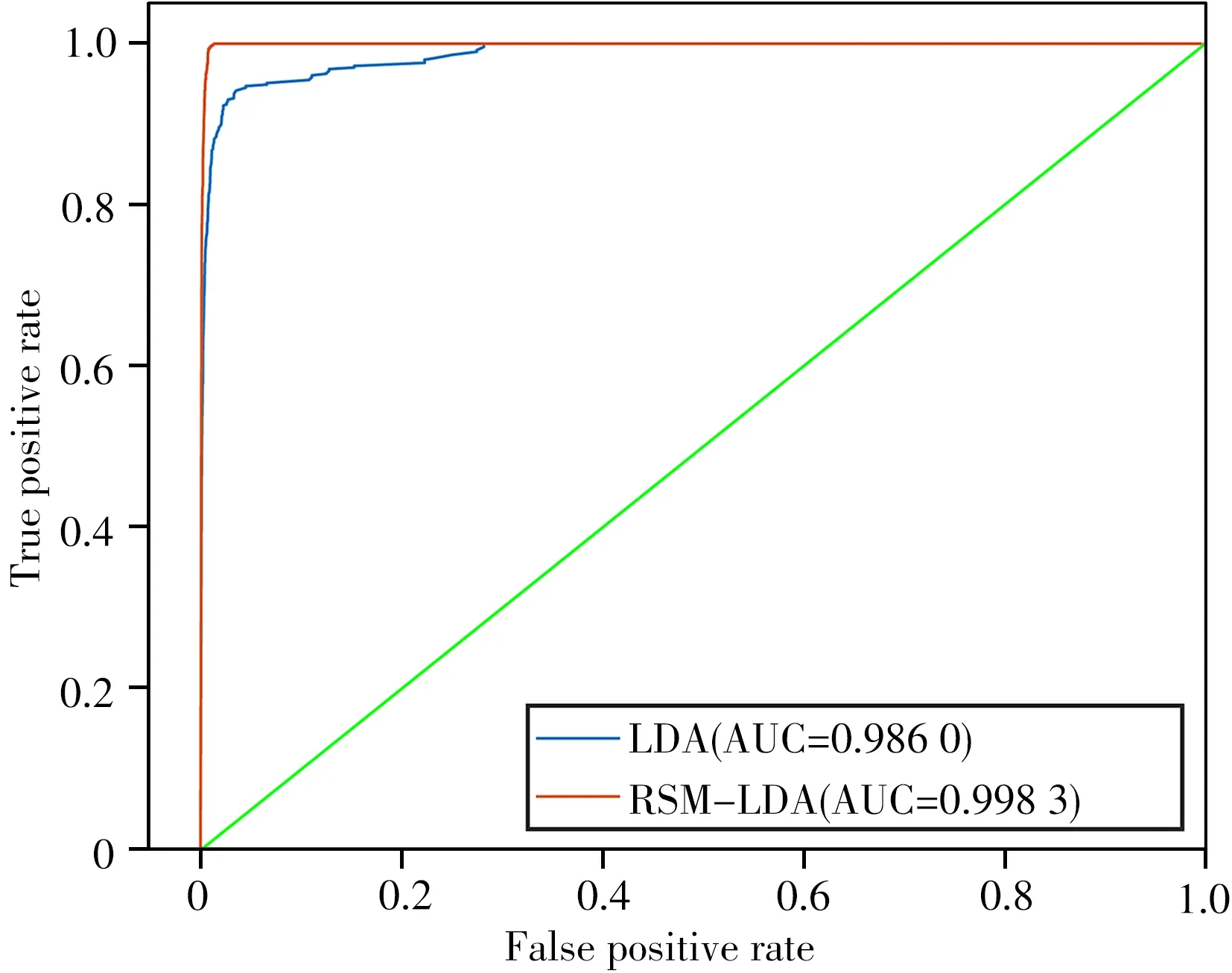
图6 ROC曲线Fig.6 ROC curve
3 结 论
高光谱成像技术结合RSM-LDA 模型可用于不同品牌、同品牌不同型号黑色签字笔的快速分类鉴别。本研究对36 支黑色签字笔墨水的原始光谱数据进行S-G 平滑和Z-Score 标准化组合预处理后,分别采用LDA 和RSM-LDA方法建立了黑色签字笔墨水种类的鉴别模型。两种方法分类结果均较好,且RSM-LDA 模型的分类效果和稳健性优于LDA 单一模型,其训练集的平均分类准确率为100%,交叉验证平均分类准确率为99.09%,测试集的平均分类准确率为90.70%,模型的AUC 值达0.998 3,模型性能良好,为笔迹检验提供了一种新的快速、无损方法。后续应扩大样本类型及数量,建立完备的样本库,以期为法庭科学墨水检验构建新平台。
猜你喜欢
材料与冶金学报(2022年2期)2022-08-10
温州大学学报(自然科学版)(2022年2期)2022-05-30
小学生优秀作文·时尚版·中年级(2022年2期)2022-02-18
粉末冶金技术(2021年3期)2021-07-28
建材发展导向(2021年23期)2021-03-08
恋爱婚姻家庭·养生版(2019年9期)2019-11-05
恋爱婚姻家庭(2019年27期)2019-09-27
数学大王·中高年级(2018年3期)2018-03-27
学苑创造·B版(2015年6期)2015-07-01
小学阅读指南·高年级版(2014年5期)2014-09-18
