
融合作者合作强度与研究兴趣的合作者推荐 *
2021-10-26 01:17马慧芳胡东林刘宇航李志欣
计算机工程与科学 2021年10期
马慧芳,胡东林,刘宇航,李志欣
(1.西北师范大学计算机科学与工程学院,甘肃 兰州 730070;2.桂林电子科技大学广西可信软件重点实验室,广西 桂林 541004;3.广西师范大学广西多源信息挖掘与安全重点实验室,广西 桂林 541004)
1 引言
科研社交网站旨在为研究人员提供在线的以科学研究为导向的活动[1]、作者署名识别[2]、学术文本功能识别[3]、发布自己的研究成果(如论文、基金项目)[4,5]以及发现相同研究领域的学者或团体以快速挖掘出“合作关系紧密”“潜在的”合作者。在学术资源非常宝贵的前提下,研究人员数量的不断增长给彼此带来了更多的合作机会。在学术界,作者之间的频繁合作对科研发展有一定的促进作用。然而,如何为研究人员快速选择最有价值的合作者并非易事,合作者推荐也显得尤为必要。
近年来,研究人员已从不同的角度提出了合作者推荐方法。如Tang等人[6]提出了解决跨领域中存在的稀疏连接和主题偏离的CTL (Cross- domain Topic Learning)方法。Sun等人[7]提出了一种基于元路径的关系预测模型来解决异构网络中存在多种类型的对象(例如作者、主题和论文)以及这些对象之间存在多种类型的链接预测问题。Li等人[8]提出了ACRec (Academic Collaboration Recommendation)方法,其使用3个学术指标的随机游走方法推荐新合作者,通过计算的链接重要性,使随机游走者更有可能访问有价值的节点。Rêgo等人[9]研究了合作网络的形成模型,认为作者的贡献与合作者的数量以及作者与其他作者合作的相对努力大小有关。Makarov等人[10]使用node2vec网络嵌入和新的边缘嵌入运算符嵌入方法研究合作网络中合作量的预测问题。此外,合作者推荐也可被看作是社区搜索,一般地,可将科研社交网络建模为由节点和边组成的图,节点表示研究者关注的实体,边表示实体与实体之间的关系,如作者合作关系。行之有效的向科研人员推荐适合的合作者的方法本质上就是在图中找到包含特定节点的最合适社区,该过程也称为社区搜索[11]。现有的社区搜索方法包括2类:(1)网络拓扑相关的社区搜索,指寻找包含给定节点集且满足k-clique[12]、k-core[13]或k-truss[14]等特定拓扑结构的社区;(2)综合考虑了网络拓扑结构和节点属性的社区搜索[15]。Sourabh等人[16]已将社区搜索方法成功地运用到了推荐系统中。上述工作中,Rêgo等人[9]和Sourabh等人[16]提出的方法与本文方法最相关,但前者没有采用社区搜索方法并对合作网络进行双加权;后者虽然将社区搜索方法运用到了合作者推荐方法中,但没有同时考虑合作网络的结构信息与属性信息,并且忽略了推荐的作者质量高低以及一篇论文具有多个合作者等特殊情况。
针对以上问题,本文提出了一种融合作者合作强度与研究兴趣的合作者推荐CRISI(Collaborator Recommendation via Integrating author’s cooperation Strength and research Interest)方法。首先,利用合作网络的结构信息(合作强度大小)与属性信息(研究兴趣相似程度)构建双加权网络;其次,设计种子替换方法寻找种子节点,即影响力大的作者;再次,基于分数k-core社区搜索方法搜索合适的目标社区,使用这种方式可以推荐与其他研究人员合作强度较高的合作者;最后,在DBLP(Digital Bibliography and Library Project)数据集上进行实验,验证本文方法的有效性。
2 准备知识
2.1 二分图
二分图又称为二部图,是图论中的一种特殊模型,在复杂网络研究中具有重要的意义,它可以模拟2类实体之间的关系,同类实体之间无边,不同类实体之间可能有边。例如作者和论文,查询和网页等。以本文使用的DBLP数据集为例,构建作者和论文形成的二分图。DBLP作为计算机领域内计算机类英文文献的集成数据库,以作者为核心,按年代列出了作者的科研成果,其中涵盖了国际期刊和会议等公开发表的论文。
形式化地,设G=(A∪P,D)是一个作者-论文二分图,如图1所示。其中,A={a1,a2,…,an}表示作者集合,P={p1,p2,…,pm}表示论文集合,D表示边集合,同类节点(作者与作者、论文与论文)之间无边,不同类节点(作者与论文)之间可能有边。

Figure 1 Example of author-paper bipartite graph图1 作者-论文二分图示例
2.2 问题定义
由作者-论文二分图G构建作者合作关系图T=(A,E,B),其中A表示作者集合,E表示边集合,(ai,aj)∈E表示作者ai与作者aj有过合作关系,即存在边;B=[b1,b2,…,bn]∈Rk×n是一个属性矩阵,其属性向量bi是每一个节点ai∈A对应的k维向量;使用一个对称权重矩阵W=[wij]n×n存储作者ai和作者aj之间边上的权重,其权重大小由作者间合作强度和作者研究兴趣相似度决定。仅仅单方面通过作者间的合作强度(结构)或研究兴趣相似性(属性)来计算边的权重,这不足以有效地捕获作者间的合作紧密性。所以,同时对结构和属性加权可以有效地提升推荐效果。
3 融合作者合作强度与研究兴趣的推荐方法
3.1 融合作者合作强度与研究兴趣的基本框架
本节详细描述融合作者合作强度与研究兴趣推荐方法的基本过程。首先同时考虑结构和属性构建双加权网络,其次利用提出的种子替换方法挖掘种子节点,最后使用分数k-core社区搜索方法给待推荐作者搜索合适的目标社区,如图2所示。
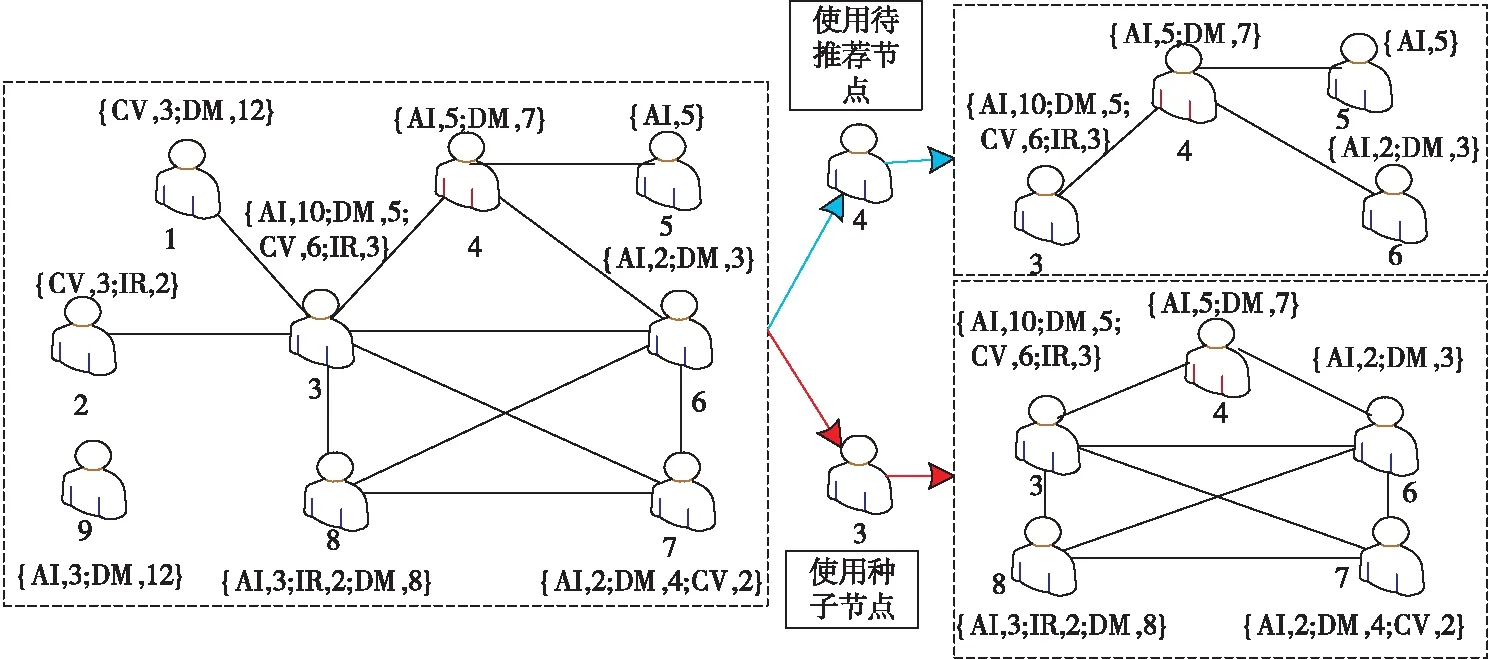
Figure 2 Example of integrating author cooperation strength and research interest图2 融合作者合作强度与研究兴趣的示例图
图2描述了融合作者合作强度与研究兴趣的基本过程。节点表示作者,每个节点都有一个与之关联的属性列表,用于定义作者的属性。以作者4作为待推荐节点为例,考虑以下2种情况:(1)直接将作者4作为种子节点,利用传统的k-core方法搜索社区,得到与作者4有直接合作关系的社区,如图2的右上方框所示,此社区由作者3、作者4、作者5和作者6构成;(2)图2右下方框使用本文的种子替换方法和分数k-core方法则可以找到一个由作者3、作者4、作者6、作者7和作者8构成的目标社区,如图2的右下方框所示。通过比较图2右上方和右下方的2个图,可以看出,本文方法找到的社区具有合作关系强度大、兴趣类似的特点。
3.2 构建双加权网络
(1)合作关系强度计算。在作者合作关系网络中,作者间的合作次数在一定程度上反映了网络的紧密性。如果作者间的合作次数越多,作者间的合作关系强度越大,网络连接就越紧密。作者间的合作强度定义如式(1)所示:
(1)
其中,cij表示作者ai与作者aj之间的合作强度,xij表示作者ai和作者aj之间的合作次数。
(2)作者研究兴趣相似度计算。以DBLP数据集上作者在6个研究领域[17]以及在每个领域已发表的论文篇数为依据,构建每个作者ai的属性向量bi=[b1,b2,…,b6]T,其中每个维度的属性值为作者ai在对应领域发表的论文数量,则可利用余弦相似度度量作者研究兴趣相似度,定义如式(2)所示:
(2)
其中,sij表示作者ai与作者aj之间的研究兴趣相似度值。
最后,定义作者ai与作者aj之间的边上的双加权重如式(3)所示:
wij=r×cij+(1-r)×sij
(3)
其中,r∈(0,1),用来调整作者间合作强度与研究兴趣相似度所占比例的大小。经实验发现,将r设置为0.6时实验效果最佳,具体分析见4.2.2节。
3.3 挖掘种子(作者)节点方法
在作者合作关系网络中,社区搜索中的查询节点对查询结果有很大的影响。考虑到直接使用待推荐节点搜索社区,找到的社区中成员很有可能质量不高,于是本文设计了一种挖掘高质量的种子节点替换方法,从而搜索合作关系强度较大的目标社区。以下给出挖掘种子节点方法的相关定义及具体描述。
定义1(节点的邻居社区)A中任意节点a的邻居社区如式(4)所示:
N(a)={ai|(a,ai)∈E}∪{a}
(4)
其中,(a,ai)∈E表示有边,E是作者合作关系图中的边集合。
定义2(节点质量) 节点a的质量如式(5)所示:
(5)
其中,|E|表示图中的总边数,Q(a)表示节点a的邻居边数与总边数的比值,即表示节点a的中心性。由于节点质量的计算涉及到节点邻居社区中边的数量,引入节点质量作为局部节点中心度指标,较大的节点质量值意味着节点的中心性越高,节点的影响力就越大。
定义3(节点影响区域) 2个相邻节点ai,aj之间的影响区域如式(6)所示:
IA(ai,aj)={a|a∈N(ai)∩N(aj)}
(6)
定义4(节点影响区域密度) 影响区域中的节点密度[18]如式(7)所示:
dIA(ai,aj)=
(7)
定义5(节点关系强度) 2个相邻节点ai,aj之间的关系强度如式(8)所示:
(8)
从式(8)中可看出,节点属性越相似,影响区域密度越大,节点关系强度值就越大,意味着相邻节点之间合作越紧密。
在很多情况下,由于待推荐节点往往带有主观特性且包含的信息量有限,直接将其作为种子节点,会使得搜索的目标社区中作者之间链接稀疏。算法1将用户给定的待推荐节点替换为目标社区中的种子节点。
算法1挖掘种子(作者)节点的方法
输入:图T=(A,E,B),节点ar。
输出:目标社区的种子节点ass。
1:ass=ar;
2:MaxNRS=0;
3:使用式(4)计算N(ar);
4:使用式(5)计算Q(ar);
5:do
6:forallai∈N(ar)do
7: 使用式(5)计算Q(ai);
8:ifQ(ai)>Q(ar)then
9: 使用式(8)计算NRS(ar,ai);
10:ifNRS(ar,ai) >MaxNRSthen
11:MaxNRS=NRS(ar,ai);
12:endif
13:endif
14:endfor
15:while(节点ass的质量小于图T中所有节点的质量)
16:输出ass。
在算法1中,第1行将节点ar赋值给种子节点ass,第2行将最大节点关系强度MaxNRS的初始值设置为0;第8行确保候选邻居节点的质量大于节点ar的质量;第10~12行确保候选邻居节点与节点ar有最强的关系;第15行重复使用候选邻居节点迭代地替换当前节点,直到找不到比当前节点质量大的节点停止;第16行最终输出与节点ar合作强度高且质量最大的节点作为种子节点ass。
3.4 分数k-core社区搜索方法
社区搜索中一个非常重要的问题就是定义目标社区的联系紧密程度,研究人员常利用k-core定义局部社区链接的紧密程度,其具体定义[19]如下所示:
定义6(k-core) 给定一个整数k(k≥0),图T的k-core是该图的一个最大子图H,其中图H中的每一个节点的度degH(ai)都大于或等于k,即∀ai∈H,degH(ai)≥k。
然而,在现实世界中存在某些论文的作者数量很庞大,甚至有的有一百多位作者,而这些作者之间虽然存在互相合作关系,但也仅合作一次,使得搜索到的社区并不是某个作者想要的。如以本文采用的DBLP数据集为例,有114位作者共同参与了同一篇论文的合作,而其中多数作者从未参与过其他论文的合作,若使用传统的k-core社区搜索方法,当k=113时,发现最终得到的目标社区中这些作者之间的合作强度较低。所以,本文方法可以有效地基于分数k-core方法来应对合作次数少且作者人数多的情况。
定义7(节点分数度) 图T中节点ai的分数度定义如式(9)所示:
(9)
其中,E(ai)表示节点ai的边集,wij是作者ai和作者aj构建的边上的权重。
定义8(分数k-core) 给定一个有理数f,图T的分数k-core是该图的一个最大子图F,图F中的每一个节点的分数度都不小于f,即∀ai∈F,FDegF(ai)≥f[20]。
从定义8看出,尽管分数k-core与k-core定义类似,但分数k-core中的节点引入了分数度的约束,更为严格,对应的子图满足权重的约束,即体现了作者间合作强度与研究兴趣相似度,使得搜索得到的子图更有意义。特别地,在作者合作关系图中,分数k-core会将仅仅合作过一次的大量作者形成的子图过滤掉,具体过程如算法2所示。
算法2分数k-core社区搜索方法
输入:有理数f,图T=(A,E,B)。
输出:子图F。
1:F=T;
2:forallai∈Ado
3: 使用式(9)计算每个节点的FDegF(ai);
4:endfor;
5:whileFDegF(ai)>f
6: 删除节点ai;
7:endwhile
8:return子图F;
算法2描述对于给定一个合适的f值,可以找到包含种子节点在内的最大分数k-core子社区作为可推荐目标社区。第2~4行计算每个节点的分数度;第5~7行删除节点分数度小于给定f值的节点;第8行输出包含种子节点ass在内的具有最大f值的分数k-core的一个子图(子社区)F。
3.5 合作者推荐
合适的合作者推荐有助于提高作者的研究质量,加快其研究进程。考虑到作者之间存在合作关系或某些作者与其他作者之间不存在合作关系(冷启动用户)的2种情况,在作者合作关系网络中,对于冷启动用户,通过待推荐作者的主页查找他感兴趣的论文,寻找论文中与他有过合作关系的作者。然后,使用算法1挖掘质量高且合作关系强的作者作为种子节点。最后,利用算法2搜索合适的目标社区。
对于一个给定的作者a,先使用上述搜索方法得到目标社区,然后利用式(9)计算该目标社区中每位作者的节点分数度并降序排序形成推荐列表。
4 实验与结果分析
4.1 实验设置
数据集:本文选取了DBLP数据集中2013年1月之前,53 872位作者主要在“人工智能”(AI)、“计算机视觉”(CV)、“数据库”(DB)、“数据挖掘”(DM)、“信息检索”(IR)和“机器学习”(ML)领域发表的65 006篇论文[17],如表1所示。

Table 1 DBLP experimental data statistics
本文利用以下社区搜索评价指标:加权模块度Q(F)(Modularity)[21]和加权电导率C(F) (Conductance)[22]来评估推荐社区的质量,其中,F表示特定社区。
模块度也称模块化度量值,是一种常用的衡量网络社区内部紧密程度的指标。具体来说,模块度的大小定义为实际情况下社区内部2个节点连接强度与将网络随机连接情况下社区内2个节点连接强度的差异,定义如式(10)所示:
(10)
其中,w表示社区F中边的权值总和,wij表示社区F中节点ai与aj边上的权值,wi表示社区F中节点ai的所有连边的权值之和。Q(F)值越大表明社区紧密性越强。
电导率是一种衡量社区内一组节点的组织紧密度的指标,定义为平行割与社区容积的比值。平行割指的是社区内节点与社区外节点的连边数与社区内部节点之间的连边数比值;社区容积指的是社区中所有节点度的和。具体定义如式(11)~式(13)所示:
(11)
(12)
(13)
其中,Vol(F)表示社区F的容积;deg(ai)表示节点ai的度;P_Cut(F)表示社区F的平行割;C(F)表示社区F的电导率,电导率越小,表示社区内节点之间的连接越紧密,C(F)取值为0~1。
对比方法:选取本文方法的3种变体和4种经典的合作者推荐方法与本文方法进行比较。具体包括:(1) CRISI-1方法,其利用本文设计的种子替换方法和传统k-core方法进行社区搜索;(2)CRISI-2方法,其直接利用待推荐用户和本文的分数k-core方法进行社区搜索;(3)CRISI-3方法,直接利用待推荐用户和传统的k-core方法进行社区搜索;(4) ACRec[8]方法利用3个学术指标计算链接的重要性,以使随机游走者更有可能访问有价值的节点,但此方法只考虑了结构信息并未考虑节点的属性信息;(5) CAMLS(Co-Authorship Model with Link Strength)[9]方法研究合作网络的形成模型,其中作者的利益不仅取决于合作者的数量,还取决于作者与其他作者合作的相对努力大小;(6)PEER(PEER recommendation in dynamic attributed graphs)[16]在属性图上使用动态社区搜索,以进行同行推荐;(7)ARBCI(co-Author Recommendations Betweenness Centrality and Interest similarity)[23]方法基于节点的中介中心性和兴趣相似性为作者产生推荐,虽然考虑了节点的结构和属性信息,但没有使用高质量的种子节点搜索社区和过滤掉合作次数很少的作者形成的社区。
4.2 实验结果与分析
4.2.1 种子节点替换的分析
为了验证种子节点替换对社区搜索结果的影响,将本文方法与对比方法进行对比实验,结果如表2所示。
由表2可以看出,本文提出的CRISI方法的性能优于其他7种方法,同时其变体CRISI-1方法的性能与CRISI的接近,原因是这2种方法都使用了种子替换方法找出高质量的种子节点来搜索社区,而其他6种方法都没有使用此方法,所以它们在种子节点替换分析结果中表现的性能较差。

Table 2 Influence of seed node replacement on results
同时发现变体CRISI-2、PEER和变体CRISI-3这3种方法虽然没有考虑种子替换方法,但3者都使用了不同的社区搜索方法来搜索社区,其最终挖掘的社区紧密性高于ARBCI、CAMLS和ACRec 3种都没有使用种子替换方法和社区搜索方法找到的社区的紧密性。
4.2.2 参数r的影响
本节将探索调节合作强度与研究兴趣的参数r对推荐结果的影响。本文通过控制质量法来得到参数对推荐结果的影响。为了能够有效地得到参数r对实验结果的影响,将参数f取0.5,实验结果如图3a和图3b所示。

Figure 3 Influence of r on Q(F) and C(F) of CRISI图3 r对CRISI的Q(F)和C(F)的影响
从图3a和图3b中可以看出,参数r会影响推荐效果。进一步通过在2个评价指标上的实验结果表明,在合作强度占比较小(小于0.5)时,CRISI方法的性能相对较差,而在合作强度占比超过一半时,CRISI方法的性能有所提升。特别地,当合作强度占比达到0.6时,CRISI方法的性能达到最佳。这说明合作强度的重要性略大于研究兴趣的相似性。
4.2.3 参数f的影响
由于CRISI和CRISI-2方法都使用了分数k-core方法来搜索社区,所以本节使用这2种方法来分析参数f对实验结果的影响,实验结果如图4a和4b所示。

Figure 4 Influence of f on Q(F) and C(F) of CRISI and CRISI-2图4 f对CRISI和CRISI-2的Q(F)和C(F)的影响
图4a和图4b分别展示了参数f变化时CRISI与CRISI-2方法得到的Q(F)和C(F)。随着参数f值的增大,CRISI方法始终优于CRISI-2方法。特别地,CRISI方法的社区紧密性的影响最好,而由于CRISI-2方法没有使用种子替换方法找出质量最大的节点来搜索社区,导致搜索的社区中作者之间的合作强度很小,与本文方法的差距相对较大。当f取值为0.5时,CRISI方法的评价指标Q(F)和C(F)达到了最佳,CRISI-2方法在f取值为0.4时搜索的社区紧密性达到了最好。当CRISI方法和CRISI-2方法的f取值分别超过0.5和0.4后,这2种方法在评价指标Q(F)和C(F)上的性能都有所降低,由于f值越大,更多的作者会被过滤掉,使得搜索得到的社区中作者人数减少。可以看出,将参数f取值设为0.5时,本文方法的推荐效果最好。
4.2.4 离群点(冷启动用户)的分析
合作者关系网络中可能存在某些作者与其他作者之间没有合作关系,给这些没有参与合作的作者推荐合作者就显得比较困难,本文方法在3.4节给出了解决办法。表3展示了8种方法在离群点上的实验结果,粗体字表示8种方法中的最佳性能。
从表3看出,CRISI方法在解决离群点问题上表现的性能最好,CRISI方法的模块度Q(F)为0.41,电导率C(F)为0.009。特别地,虽然本文方法的3种变体和CAMLS方法都没有同时使用种子替换方法和社区搜索方法来搜索社区,但它们都考虑了离群点这一因素,因此它们最终得到的目标社区中各成员之间的连接紧密性高于没有考虑离群点的PEER、ARBCI和ACRec 3种方法。可见,本文方法可以更好地应对离群点问题。

Table 3 Experimental results of outliers testing 表3 测试离群点的实验结果
4.2.5 双加权对实验结果的影响
在本节,为了分析边上的权重对推荐结果的准确性的影响,统计了权重在不同合作者数量下的推荐精度,如图5a和图5b所示。

Figure 5 Influence of weigh on results of different recommendation methods图5 权重对不同推荐方法结果的影响
具体来说,依据作者社交关联作者的数量和本文方法得到的权重将作者划分成5组,如图5a和图5b所示。从柱状图可以看出:不同推荐方法在不同权重范围下具有很大的差异,而本文CRISI方法始终表现最优。从图5中也发现,同时对结构和属性加权的5种方法的性能都比较好,而CAMLS、PEER、ACRec 3种方法没有同时对结构和属性加权,所以在2个评价指标上表现相对较差,这表明双加权在合作者推荐方法中是很有必要考虑的。
4.3 案例研究

Figure 6 Example of a fractional k-core community search on the author’s partnership graph图6 作者合作关系图上的分数k-core社区搜索示例
图6a是一个完整的作者合作关系图,图6b是图6a中阴影部分所示的子图。其中,节点表示作者,边上数字表示权重,其由作者合作强度与研究兴趣相似度计算得到。图6c是采用式(9)计算分数度得到的推荐列表。现以灰色节点Beng Chin Ooi作为待推荐节点为例,使用算法1挖掘种子节点,则整个替换过程为图6b中的黑粗实线路线,最终找到的种子节点为黑色节点Jiawei Han。如果不使用本文方法,直接使用待推荐作者Beng Chin Ooi搜索社区,则搜索的社区为图6b中右边虚线构成的椭圆部分,社区紧密性明显较差。若以作者Jiawei Han作为种子节点,将f设为0.5并使用分数k-core社区搜索方法搜索社区,就会过滤掉仅仅参与一次合作的作者,如Sung Young Lee、Takahiro Hara和Christian S.Jensen,最终将推荐列表中分数度大于0.5的作者推荐给作者Beng Chin Ooi,即图6b中黑粗虚线构成的社区。可见,使用本文方法搜索得到的社区紧密性高。
5 结束语
为了给作者推荐一个合作关系更紧密的社区,本文提出了一种融合作者合作强度与研究兴趣的合作者推荐方法。首先,本文从合作者强度(结构)和研究兴趣(属性)2方面构建双加权网络;然后,利用种子替换方法找到高质量的种子节点;最后,利用分数k-core社区搜索方法搜索合适的目标社区,即给待推荐作者推荐合作关系紧密的群体。通过在DBLP数据集上进行验证,实验结果表明所提出的方法具有很好的推荐性能。在今后的工作中考虑给定作者和作者的研究主题来搜索合适的合作者群体。
猜你喜欢
领导文萃(2021年19期)2021-11-05
文萃报·周五版(2021年10期)2021-09-13
小学生学习指导(高年级)(2021年4期)2021-04-29
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
趣味(数学)(2019年12期)2019-04-13
意林(2018年20期)2018-10-31
小学生导刊(2017年16期)2017-06-15
山东青年(2016年1期)2016-02-28
当代修辞学(2014年3期)2014-01-21
公务员文萃(2013年5期)2013-03-11
