
基于DPC聚类重采样结合ELM的不平衡数据分类算法 *
2021-10-26 02:12:02董宏成文志云万玉辉晏飞扬
计算机工程与科学 2021年10期
董宏成,文志云,3,万玉辉 ,晏飞扬
(1.重庆邮电大学通信与信息工程学院,重庆 400065;2.重庆邮电大学通信新技术应用研究中心,重庆 400065;3.重庆信科设计有限公司,重庆 401121)
1 引言
不平衡分类问题在医学诊断[1]、机器故障检测[2]、软件缺陷预测[3]和计算机视觉[4]等领域得到了广泛的应用。与类不平衡学习相关的问题是,标准方法通常将大多数正类样本错误地归类为负类样本。对于以上应用来说,少数类样本的检测更加重要,因此如何更加准确地检测出这类稀有样本已经成为当前机器学习研究者面临的挑战之一[5]。
近年来,针对类不平衡学习问题涌现出了大量的研究,研究人员也给出了很多解决方法,这些方法概括起来可以分为3类:(1)改进训练数据集的不平衡分布(数据层面上的方法),例如采用上采样方法、下釆样方法和混合采样等对原始数据集进行处理,目的是使类分布更加平衡;(2)改进经典算法(算法层面方法):对当前比较成熟的分类器算法,采用优化参数、对各类样本赋予不同的错分代价[6]、设计面向不平衡数据集的新算法等手段。例如,基于代价敏感的支持向量机[7]和极限学习机ELM(Extreme Learning Machine)[8 - 12];(3)结合数据层面和算法层面的方法:首先采用合适的采样方法对数据集进行平衡处理得到多个平衡数据集,然后再训练相应的分类器进行集成学习,例如DPBag(Density Peaks Bagging)算法[13]。
极限学习机ELM在分类问题上已经成为世界各国研究人员的研究热点。研究人员大量的实践表明,ELM对于不平衡数据分类问题具有较强的优越性,其改进思想主要包括与采样技术的结合和对自身算法的改进2方面。例如,Vong等人[14]将 ELM 与随机过采样技术ROS(Random Over Sampling)相结合提出了ROS-ELM算法,但是由于随机过采样是随机复制少数类样本使类分布达到平衡,容易导致过拟合。Sun 等人[15]则将SMOTE(Synthetic Minority Over-sampling TEchnique)算法[16]引入到 ELM 集成学习框架中,提出了SMOTE-ELM算法并用于企业生命周期预测。于化龙[17]将ELM与随机欠采样RUS(Random Under Sampling)相结合,和其它ELM算法对比虽然可提升少数类样本识别精度但提升效果并不明显。上述算法均采用了单一的采样技术,未考虑到样本的不平衡程度及样本内部的分布情况,无法解决样本噪声及类内不平衡问题,导致噪声被误分为少数类样本,并且适用场景过于局限,对不同平衡程度的数据集依然存在分类效果不明显甚至效率低下的问题。
针对上述算法存在的问题,本文提出了一种基于密度峰值聚类DPC(Clustering by fast search and find of Density Peaks)的重采样技术结合ELM的不平衡数据分类算法DPCR-ELM(imbalanced data classification algorithm based on DPC clustering Resampling combined with ELM)。
2 DPC聚类和ELM算法
2.1 DPC聚类
Alex等人[18]于2014年提出了一种新的聚类算法——密度峰值聚类DPC(Clustering by fast search and find of Density Peaks)算法。相比于其它聚类算法,该算法有以下优势:(1)可以发现任意形状的簇并且可高效处理高维数据;(2)算法简单,不需要迭代计算,耗时少;(3)能够高效进行样本分配和发现噪声点,适用于大规模数据的聚类分析。对于每个样本xi,由样本的局部密度ρi和该点到更大局部密度的样本的最小距离δi2个量来表示,相应的计算方法如式(1)~式(4)所示:
(1)
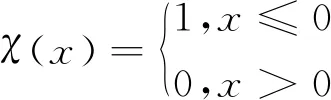
(2)
δi=minj:ρi<ρjdij
(3)
λi=ρiδi
(4)
其中,dij表示样本xi与样本xj之间的距离,dc为输入的截断距离,本文选取dij升序排序后的1%或2%的分位数作为dc的值,并且由式(1)和式(2)可以看出,样本点xi的局部密度ρi表示以dc为半径的圆内样本的个数。ρi越小表示该样本点周围越稀疏,越有可能成为边界点,ρi越大表示该样本点周围越密集,越靠近集群中心。λi为聚类中心选择的一个衡量标准,λi越大,表示样本xi的2个属性值都很大,xi越有可能成为聚类中心点。
根据DPC算法的原理,δi值和ρi值能很好地反映样本点在分布集群中所处的位置,其生成的决策图可方便用户去除噪声样本和选取聚类中心点,图1和图2分别展示了原始数据分布图及其生成的决策图。

Figure 1 Original data distribution图1 原始的数据分布

Figure 2 ρ_δ decision diagram based on DPC图2 基于DPC的ρ_δ决策图
根据图2所示决策图来分析图1可知,样本26~28被视为噪声点或离群点,因为它们都远离大部分样本,以dc为半径的圆内样本的个数只有一个。因此,本文定义样本局部密度ρ=1的点为噪声点或离群点,这样的点在采样之前会被去除。
2.2 极限学习机
ELM是一种广义的单隐层前馈神经网络,该网络中所有的隐层节点参数都是随机生成的,输出权值采用批量最小二乘学习技术进行训练。与传统的人工神经网络相比,ELM具有训练误差和输出权的范数最小的特点。其次ELM的学习算法简单有效,不需要在隐层中迭代调整,在学习速度极快的情况下也具有良好的泛化能力,已被广泛应用于各种分类问题中。ELM基本原理简述如下:
给定一组N个训练数据D(xi,ti),i=1,…,N,即输入和期望输出分别为xi=[xi1,xi2,…,xin]T∈Rn和ti=[ti1,ti2,…,tim]T∈Rm,其中n和m分别为特征维度和输出层的维数。因此,隐层输出矩阵为:
(5)
其中,wi和bi为隐层节点的输入权重和隐层偏置,G为隐层的激活函数,L为隐层的节点数。
输出权重β可通过求解式(6)所示的目标优化函数得到:
(6)
其中,ξi是第i个训练样本的训练误差向量,C是正则化因子,‖β‖2是分离超平面的参数,‖ξi‖2是误差平方和。H(xi)为输入样本xi的隐层输出函数,ti为训练xi的类别标记。求解以上目标函数可得隐层与输出层之间的输出权向量,β表示为:
(7)
其中,T为训练样本的目标矩阵。
进而得到ELM的决策输出如式(8)所示:

(8)
其中,signh(x)为隐层激活函数,也叫做特征映射函数。由该式可以得到对应样本xi的输出向量f(xi)=[f1(xi),…,fm(xi)],进一步可以得出xi的预测标号label(xi)=argmaxfk(xi),k=1,…,m。由于本文主要研究的是二分类问题,所以m取值为2,具体的分类模型如图3所示。

Figure 3 ELM classification model图3 ELM的分类模型
3 本文提出的分类算法
3.1 算法流程
根据采样技术与ELM分类算法相结合的思想,本文提出了基于DPC聚类采样结合ELM的不平衡数据DPCR-ELM分类算法,该算法考虑了分类模型的效率问题,根据数据集不平衡程度进行相应的处理。算法流程如图4所示。

Figure 4 Flow chart of DPCR-ELM algorithm图4 DPCR-ELM的算法流程图
该算法首先判断不平衡数据集的不平衡比率,即R=Nmax/Nmin,其中Nmax和Nmin分别为多数类样本和少数类样本的数量,本文设置不平衡阈值为9(实验所用公共数据集标准划分)来判断使用何种采样方法。若R>9,表明数据集十分不平衡,少数类样本相对于多数类样本来说是很稀少的,如果采用经典的SMOTE过采样方法生成(Nmax-Nmin)个少数类样本会加大数据集的训练量,增加分类器的时间复杂度,还会出现过度拟合现象。因此,本文通过采用DPC聚类算法对少数类样本进行过采样,并根据聚类后各个样本的ρ值和β值选取少数类边界(即稀疏域)样本集,对选取的少数类簇边界样本集采用经典的SMOTE过采样方法自适应地合成确定数目的少数类样本。对于R≤9的不平衡数据集,其少数类样本数量相对多数类样本不再那么稀少,ELM分类算法足以识别出大部分少数类样本,因此本文提出的算法只对多数类样本进行欠采样,去除一些冗余的样本,选取更具代表性的多数类样本。对于不平衡比率较大的数据集(R>9)来说,此类数据集因为减少了对少数类样本过采样的步骤,并且未对数据进行聚类,节省了算法的时间开销。
3.2 DPCR-ELM分类算法
DPCR-ELM分类算法主要包括样本平衡处理和ELM算法分类2部分。在样本平衡处理部分,本文受DPC聚类原理的启发,提出了一种能够有效平衡2类样本的重采样方法。
样本平衡处理部分主要包括多数类样本处理和少数类样本处理,处理过程分别如算法1和算法2所示,其中算法2借鉴了文献[19]的采样思想,并对其进行了改进,因为文献 [19]的算法需要对少数类样本进行聚类,复杂度会很高,还会破坏原始样本的类分布,因此本文根据DPC聚类的原理寻找少数类集群边界样本,不需要复杂的聚类;然后在边界样本周围合成更多的样本,解决类内不平衡问题,保持少数类样本原始分布的同时提高ELM分类对边界区域样本的识别度。
算法1多数类样本集的欠采样
输入:多数类样本集Smax,欠采样系数α。
输出:采用后的多数类样本集S′max。
步骤1应用DPC聚类的原理计算每个多数类样本的ρ、δ和λ值。
步骤2去除离群点和噪声点:
选取局部密度ρi=1的点为离群点或噪声点,因为ρi=1,表示该点与所有点之间的距离大于截断距离dc,远离了所有样本。
步骤3计算样本权重:根据式(4)计算剩余样本的λi值作为采样权重并进行降序排列。
步骤4根据权重进行采样系数为α的样本采样得到采样后的多数类样本集S′max。
算法2少数类样本集的过采样
输入:少数类样本集Smin,过采样系数β。
输出:少数类过采样样本集S′min。
步骤1根据式(1)~式(3)计算每个样本点xi的局部密度ρi以及xi到具有更大局部密度的点的最小距离δi。
步骤2去除ρi=1的样本,即噪声点或离群点。
步骤3根据式(9)计算每个样本点xi的采样权重wi:
(9)
其中,Nmin为去除噪声后少数类样本的数量,从式(9)中可以发现,若样本的ρi值越小,即周围越稀疏,越有可能为边界样本,其采样权重越大,样本的ρi值越大,即周围越密集,越靠近中心点,其采样权重越小。
步骤4计算要合成的样本数目:
N=(N′max-Nmin)×β
(10)
其中,N′max为算法1处理过后的多数类样本数量,β为取值在0~1的过采样系数。当β=1时,表示过采样后的正负类样本绝对平衡。
步骤5计算每个样本需要合成的样本数:
Ni=N×wi
(11)
步骤6对簇边界样本xi进行SMOTE采样合成对应的Ni个样本,合成样本的计算方式如式(12)所示:
x′i=xi+rand(0,1)×(xi-s)
(12)
其中,xi为进行采样的边界样本,s为xi的一个邻近样本,可根据xi的邻近距离δi来随机选择,x′i为合成的样本。合成的样本加入到样本集Snew中。
步骤7生成少数类过采样集S′min:S′min=Smin+Snew。
算法1可以有效去除噪声和异常值,其次利用样本的λi值作为抽样权值,方便了代表性样本的选择,因为样本类簇边界点的ρ值比簇中心周围点的ρ值小,δ值比簇中心周围点的δ值大,簇中心周围点的情况则刚好与之相反,通过对λ值降序采样可确保簇中心点被选取的情况下还可以随机选取到边界点以及簇中心周边点,保留了原始数据的分布特性。算法2考虑了类内样本不平衡及噪声的影响,使用式(9)计算过采样的权重不影响原始的类分布同时还保证了边界样本具有更大的过采样权重,因为边界样本更容易被错误分类。其次,采用SMOTE算法避免了合成重叠样本,保证了采样的合理性。
算法3DPCR-ELM分类算法
输入:不平衡数据集S,测试数据集V,欠采样率α,过采样率β。
输出:重新采样数据集S′,ELM分类器的预测目标。
步骤1将不平衡数据集S划分为少数类样本集Smin和多数类样本集Smax,确定样本不平衡比率R。
步骤2利用算法1对多数类样本集Smax进行处理,得到数据集S′max。
如果R> 9继续执行以下步骤,否则转到步骤4。
步骤3利用算法2对少数类样本集Smin进行处理,得到数据集S′min。
步骤4合成重采样平衡数据集S′:
(13)
步骤5训练ELM分类模型:
(1)将平衡数据集S′输入图3所示的ELM分类模型进行训练。
2)利用测试数据集V对ELM分类器进行测试,预测其分类准确率和少数类样本识别率。
4 实验与结果分析
4.1 实验评价指标
传统分类器采用的分类准则是整体分类准确率和错误率[20],但是这些分类准则不适用不平衡分类问题。二分类的分类性能评价标准通常建立在表1所示的混淆矩阵基础上,由表1中4个量可以表示几种常用的分类性能指标,计算方式如式(14)~式(17)所示:
(14)
(15)
(16)
(17)
其中,F-Measure是查准率Precision和查全率Recall的调和平均,当两者大小相当时F-Measure较大,G-mean指标为正精度和负精度的几何平均,用于评估感应偏差的程度,较大的G-mean值表明分类器对正负类的分类效果较好。为了更加全面评价本文算法的分类性能,本文选用F-Measure和G-mean作为实验结果的评价指标。

Table 1 Confusion matrix of binary classification problem
4.2 实验设置
本文实验的硬件环境:Intel(R) Core (TM) i5-6200U CPU@2.40 GHz,内存为8 GB,Windows 10 64位操作系统以及Matlab2018编译环境。
本文选用KEEL数据库中的8个二分类不平衡数据集来进行实验对比和性能测试,选取规则尽可能考虑了样本数量和不平衡样本比率的多样性,以验证本文算法在不同平衡程度数据集上的分类适用性。具体数据集信息如表2所示。

Table 2 Data sets details
为了有效评价本文所提DPCR-ELM分类算法的分类性能,实验将其与ELM、ROS-ELM、RUS-ELM和SMOTE-ELM分类算法进行比较。另外,本文将平衡处理后的数据集进行10倍交叉验证,实验结果取10次平均值以保证实验结果的公平性。对于实验参数的设定,ELM均使用Sigmoid 函数作为隐层节点激活函数,隐层节点数L取值为训练样本的个数。本文所采用的过采样率和欠采样率均设为0.8,以保证处理样本后的正负样本相对平衡,SMOTE算法的K近邻个数设为5,DPC聚类截断距离dc的选取至关重要,将其设置为最常用的前dij升序排序后的前1%或2%的分位数。
4.3 实验结果及分析
本文进行了大量的实验,得出了分类结果,表3和表4分别展示了5种算法在8个数据集上的F-Measure值和G-Mean值,表中的值越大表示算法的分类效果越好(最大值使用粗体字表示),能识别出更多的少数类样本。为了更加清楚地展示本文所提算法的分类效果,展示算法的综合性能,图5给出了5种算法在8个数据集上的F-Measure和G-Mean平均值的折线图。
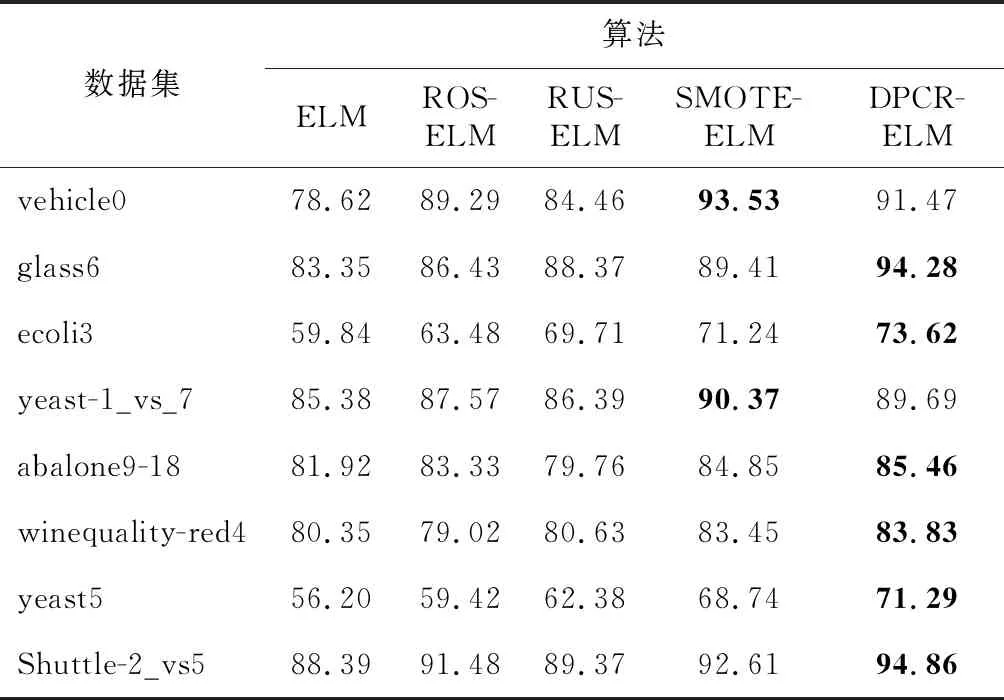
Table 3 F-Measure values of DPCR-ELM algorithm and other algorithms
由表3可以看出,对于大多数数据集,除数据集vehicle0和ecoli3之外,DPCR-ELM算法的F-Measure值均优于其他算法的,在数据集vehicle0和ecoli3上,SMOTE-ELM算法的性能优于本文算法的性能,这是由于样本的分布相对均衡,本文算法在对多数类样本处理时选择的欠采样率过低导致小部分代表性样本被丢弃所引起的。对于其他数据集,特别是对于不平衡程度较高的数据集,本文所提算法具有最高的F-Measure值,提升效果最为明显,其中,在数据集yeast5上提升最高,相比于ELM算法和次优的SMOTE-ELM算法,F-Measure值分别提升了15.09%和2.55%,充分说明了本文算法在采样过程中使用DPC聚类进行采样的合理性。

Table 4 G-Mean values of DPCR-ELM algorithm and other algorithms

Figure 5 Average G-Mean and F-Measure values of different algorithms on 8 data sets图5 不同算法在8个数据集上的平均G-Mean值和F-Measure值
由表4可以看出,除数据集abalone9-18之外,DPCR-ELM算法的G-mean值均优于其他算法的。其次,由图5可以看出,本文算法在8个数据集上的分类平均值(F-Measure和G-Mean)均大于其他算法的,这是因为其它算法在采样过程中未考虑到样本的类内不平衡以及多数类样本中噪声的影响,导致合成的少数类样本不合理以及噪声被ELM错误分类,本文提出的采样方法有效解决了这2个问题,所提算法确实可以提升少数类样本的分类精度以及具有较好的适用性。从图5还可以看出,未对数据集进行平衡处理的ELM算法的F-Measure平均值和G-Mean平均值均低于其他算法的,验证了ELM结合采样技术这一思想的合理性。
本文提出的采样方法涉及到欠采样率和过采样率2个参数,并且提出的DPCR-ELM算法也是根据不平衡比率来进行采样的,因此为了验证采样率对本文算法的影响,选取了数据量较大且不平衡比率小于9的vehicle0数据集和不平衡比率大于9的winequality-red4数据集进行实验。采样率的选取为[0.5,1]。对于不平衡比率大于9的winequality-red-4数据集,合成的少数类样本数量根据欠采样后的样本数量来确定,2个采样系数有着必然的联系。因此为了保证处理后的正负样本相对平衡,将2个值设为同样大小来讨论采样率对算法的影响。图6和图7分别给出了不同采样率在vehicle0数据集和winequality-red-4数据集上的F-Measure值和G-Mean值。
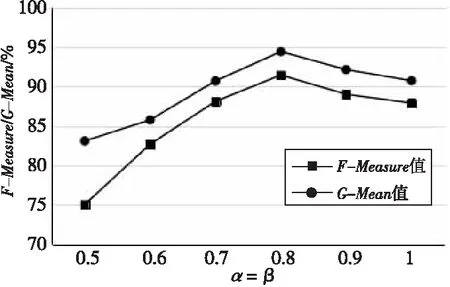
Figure 6 F-Measure and G-Mean values of different sampling rates on vehicle0 data set图6 不同采样率下在vehicle0数据集上的G-Mean值和F-Measure值
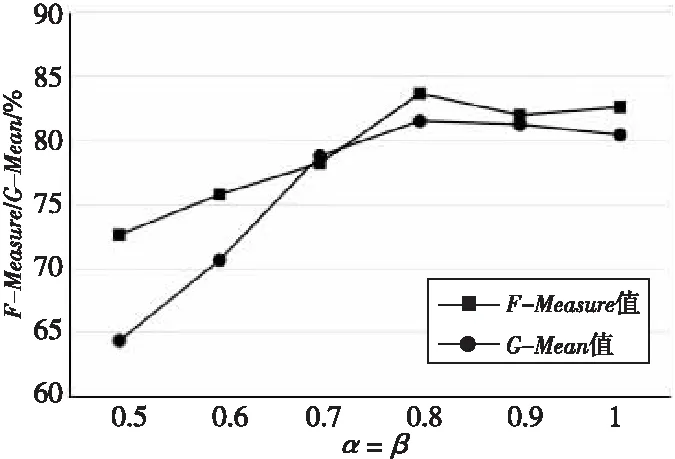
Figure 7 F-Measure and G-Mean values of different sampling rates on winequality-red4 data set图7 不同采样率下在winequality-red-4数据集上的G-Mean值和F-Measure值
从图6和图7可以看出,当采样率取0.8时,ELM的分类效果最好,其次,当采样率小于0.7或大于0.8时,F-Measure值和G-Mean值有所下降,其原因为当采样率较小时,会导致多数类样本的重要信息丢失和少数类合成样本不足,使ELM得不到充分的训练,当采样率过大时,会导致多数类噪声无法去除以及少数类样本出现过拟合的现象。因此,选择合适的采样率,DPCR-ELM分类算法的F-Measure值和G-Mean值才会有所提升。其次,由最佳采样率可知,本文改进的重采样方式确实能够有效去除多数类的冗余样本,并且合成的少数样本数量并非绝对的,减少了训练样本的数量,能够有效提升ELM分类算法的效率。因此,对于数据量较大场景,本文提出的DPCR-ELM算法分类效果会更佳。
5 结束语
类别不平衡是分类问题中最重要的数据挑战之一。为了解决少数类样本的分类精度不高的问题,本文提出并评估了一种基于DPC聚类的重采样结合ELM的不平衡数据分类算法。根据数据集不平衡程度来选择多数类代表性样本和创建属于少数类的合成样本,在对多数类样本选取时考虑了噪声的影响,有效解决了噪声误判的问题,在对少数类样本合成时考虑了类内不平衡的影响,根据聚类后找到每个集群的边界样本进行合成,解决了合成样本分布不均的问题。其次,利用ELM算法在平衡数据集上的分类优势,提升了分类效率。利用KEEL数据库中的不平衡数据集对算法进行了评估,实验结果表明了本文算法的有效性和适用性。由于本文算法只是针对二分类问题进行讨论,未来的工作将对多分类问题进一步展开研究,以便更加有效适应实际生活中的不平衡数据多分类问题。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
人民珠江(2019年4期)2019-04-20 02:32:00
电子测试(2017年15期)2017-12-18 07:19:27
数学物理学报(2017年5期)2017-11-23 07:51:31
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
计算机工程(2014年9期)2014-06-06 10:46:47
机械工程与自动化(2014年3期)2014-05-07 12:49:22
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
