
基于自注意力和Lattice-LSTM的军事命名实体识别 *
2021-10-26 02:11:54李鸿飞刘盼雨
计算机工程与科学 2021年10期
李鸿飞,刘盼雨,魏 勇
(1.战略支援部队信息工程大学地理空间信息学院,河南 郑州 450052;2.31008部队,北京 100091;3.国防科技大学计算机学院,湖南 长沙 410073)
1 引言
命名实体识别NER(Named Entity Recognition)[1]是自然语言处理的基础任务,研究成果广泛用于语义提取、关键词检索、计算机翻译和智能问答QA(Question Answering)系统[2]。当前,军事领域已进入到信息化联合作战阶段,基于传统非格式化文本的指挥方式已不能适应现代作战指挥需要,数据化、甚至代码化支撑驱动的指挥控制功能成为指挥信息系统不可或缺的组成部分,大量由数据驱动的、满足精确作战需要的难点问题成为打赢未来战争的重要研究内容。在上述问题中,通过加强军事命名实体识别研究,采用人工智能算法可以以较高精度和速度抽取文本中的重要实体信息,例如军衔职务、军事机构、武器装备和时空区域等,进而把非格式化、半格式化数据转变为可度量、可计算、可分析的格式化数据,使军事数据的精算、深算、细算成为现实。
通常NER的研究方法分为3大类:(1) 基于词典和规则的方法[3]。在缺少数据的小样本情况下,这种方法精度较高且执行效率高,但是该方法对词典规模及词典覆盖率的依赖性较大,并且规则的生成代价是大量时间和精力消耗[4]。当前常用的方法是将通用规则和机器学习融合使用。(2) 利用机器学习算法。其常用算法和模型包括:条件随机场CRF(Conditional Random Field)和支持向量机SVM(Support Vector Machine)等。(3) 利用深度学习策略。深度神经网络是一种提取潜在信息的多层神经网络结构,每一层的提取结果都是该字句的一种计算机表示,而文本字句的最大特点就是对于计算机来说是非量化的数据。因此,在大量数据的支撑下,利用神经网络训练生成基于向量嵌入的特征表示,进而进行NER是当前学术界正在探索的一种方法。
目前在英文数据NER中,通过双向长短时记忆BiLSTM(Bidirectional Long Short-Term Memory)网络可以较为准确地识别出字句中的局部信息,而CRF层将标签的依赖关系信息提取出来,使得标注的工作不再是对每个词进行分类,取得了较好的识别效果[5,6]。与英文不同,对中文命名实体识别结果影响贡献度最大的是中文分词的准确性[3],从对文本分词到命名实体识别的过程中可能会存在误差累积的潜在风险,并且分词不准确的词语边界会造成命名实体识别的不准确[7],因此需要提取的重要特征包括分词中未登录词[8]。军事文本属于特定领域的文本信息,与普通的文本在很多方面存在差距[9]。军事语言信息中通常有较多的军事命名实体,而这些实体的语法结构区别于传统的语言文本,构成都比常见的文本特殊[9]。对中文军事文本进行分词时,字所包含的语义信息在很大程度上没有词包含的信息多,所以字级别的分词容易导致语义信息缺失。利用某种单一的机器学习训练好的模型进行命名实体识别是多数研究者采用的方法。在获取字词融合信息的过程中,首先是将属于字词层次的数据输入到设置好的模型网络结构中,然后通过参数的迭代更新获取到隐层嵌入向量信息,最后将隐层嵌入向量组装在对应的词向量后面,从而在词层次的命名实体识别准确率得到提高。另一方面,为了快速记录信息,在军事文本中还存在着在形成文本时只需要展示主要信息数据的现象,其中快速记录数据的规则和记录格式是一成不变的[9]。在NER提取特征过程中,基于卷积神经网络的方法一般只提取全文字词的全局特征,忽视文本的局部特征,这可能会最终限制模型的总体表现。
为了解决上述问题,本文提出了Lattice长短时记忆(Lattice-LSTM)神经网络与自注意力机制(self-attention)相结合的神经网络模型。Lattice-LSTM[10]结构可以对句中专有名词进行有效提取,并将隐含的字词特征融合到基于字符的LSTM-CRF模型中[3]。本文通过自行标注的小规模样本集进行实验,结果表明,本文提出的模型相较于几种基线模型取得了最优结果。
2 军事命名实体识别框架
2.1 预训练模型
近年来,自然语言处理在预训练语言模型方面取得了巨大的进展,极大地促进了文本问答、自然语言推论和文本分类等下游任务的发展。预训练语言模型的核心思想是在大规模无监督语料库上预训练一个语言模型,并在下游目标任务中利用该模型的编码嵌入表示进行训练。这类工作是预训练词嵌入工作的延续,主要解决了传统词嵌入模型在以下2方面的问题:(1) 传统词嵌入模型无法有效处理复杂的词汇变形;(2) 传统词嵌入模型很难获取到基于上下文的信息表示。预训练语言模型可以根据模型结构、训练方法和使用方法等方面进行分类。从模型结构角度来看,预训练语言模型主要分为基于LSTM的模型和基于Transformer[10]的模型。具体来说,Peters等人[11]提出的ELMo嵌入,其实质是一个深度双向LSTM语言模型。McCann等人[12]提出的CoVe嵌入,利用机器翻译中的编码器和解码器架构来学习嵌入表示,而编码器和解码器这2个组件都是用深度LSTM模型实现的。但是,基于LSTM的模型无法有效捕捉长程依赖关系,且由于梯度爆炸/消失问题无法通过增加网络深度来增强模型的容量。为了解决这一问题,Vaswani等人[10]提出Transformer模型,该模型不包含任何循环单元和卷积单元,完全是通过自注意力和前馈连接构建。与LSTM类模型相比,Transformer模型具有捕捉长程依赖关系、并行编码速度快以及模型容量大等优点。基于Transformer结构,Radford等人[13]提出了单向Transformer结构的GPT模型。在此基础上,Devlin等人[14]提出了BERT模型,该模型是一个深度双向Transformer模型。而Yang等人[15]更进一步地提出了XLNet,在BERT模型中融入了双流自注意力机制、相对位置编码和段循环机制等技术。Liu等人[16]提出了RoBERTa,其网络结构和BERT一致。从使用方法角度来看,预训练语言模型又可分为固定参数和微调参数2类。固定参数类方法是在预训练过程结束以后,用预训练模型编码输入以获得编码嵌入表示,而模型本身参数固定,不参与后续训练。该类方法的好处是可以针对不同任务设计更加有针对性的模型结构,并且由于参数固定的原因训练计算量更低。而微调参数类方法是指在预训练结束后,还追加了一个微调阶段,以便在目标任务上进一步地训练模型参数。这类方法的好处是预训练模型本身充当了编码器,而研究人员只需引入极少的额外参数和网络结构,但缺点是训练计算量更大。
按照上述分类,固定参数类方法包括ELMo和CoVe,微调参数类方法包括GPT、BERT、XLNet和RoBERTa等。对于一个指定的文本,模型的输入一般由3个标识的特征向量相加得到:第1个是特征标识,通常加在文本头部,用于表示文本整体的特征信息并用于模型的最终分类;第2个是分隔标识,当输入文本包含2个句子时添加在2句之间;第3个是位置标识,通常用于表示指定文本在全文中的位置信息。
本文采用BERT作为字向量嵌入层,字典使用腾讯训练好的词向量,腾讯词向量包含了800多万中国字词,其中每个词用200维的向量表示。
2.2 BiLSTM 结构
循环神经网络以一列n维向量X=[x1,…,xn]作为输入,返回另一列与输入层中每一步的输入信息相对应的n维向量h=[h1,…,hn]。网络的隐藏层可以处理不限长度的语言序列信息,达到对文本特征的长时间记忆的效果,学习长时间信息的关联关系。训练过程中一个最重要的过程是反向传播,而反向传播由于采用幂乘方式进行计算,极其容易出现梯度消失和梯度爆炸现象。不同的神经网络会采用不同的策略避免和解决这种问题,而其中一种重要的网络是长短时记忆LSTM网络,对于反向传播过程中梯度消失等问题,LSTM是采用引入门的策略解决的。这种方法常见于很多的自然语言处理任务中。LSTM在结构组成上和卷积神经网络类似,这两者的区别在于LSTM的每次循环计算过程中设计和使用了复杂的网络图,LSTM的网络结构主要由4个以特殊方式互相影响的门控单元组成。其计算过程如式(1)~式(6)所示:
(1)
(2)
(3)
(4)
(5)
(6)
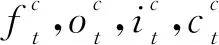
2.3 Lattice-LSTM结构
本文采用Lattice-LSTM来表示句子中的字典单词(lexicon word)。基于字符的NER的一个不足是表征的字词和字词位置信息未被有效使用,在实体识别任务中这些信息是非常重要的,因此需要借助外部信息源进行NER任务处理,通常利用Lattice-LSTM来表示句子中的字典单词,将隐含的单词特征融合到基于字符的LSTM中。本文采用一个自动获取到的词典来与句子进行匹配,进而构建基于词的Lattice,如图1所示,通过组合输入文本和词典构造单词-字符的Lattice结构[3]。基于词的Lattice是由大规模经过分词后的中文文本使用BERT训练后自动得到的,例如“集团”“集团军”“指挥”等。训练输出的词典可用于解决上下文中深层的命名实体问题。模型中的潜在词序列与主干LSTM模型中相应的字符连接,例如 “指” 字的潜在词汇有 “指挥” 和 “指挥所”,因此当计算 “指” 的向量时除了考虑“指” 字以外还应考虑 “指挥” 和 “指挥所”。
(7)
(8)
(9)
(10)
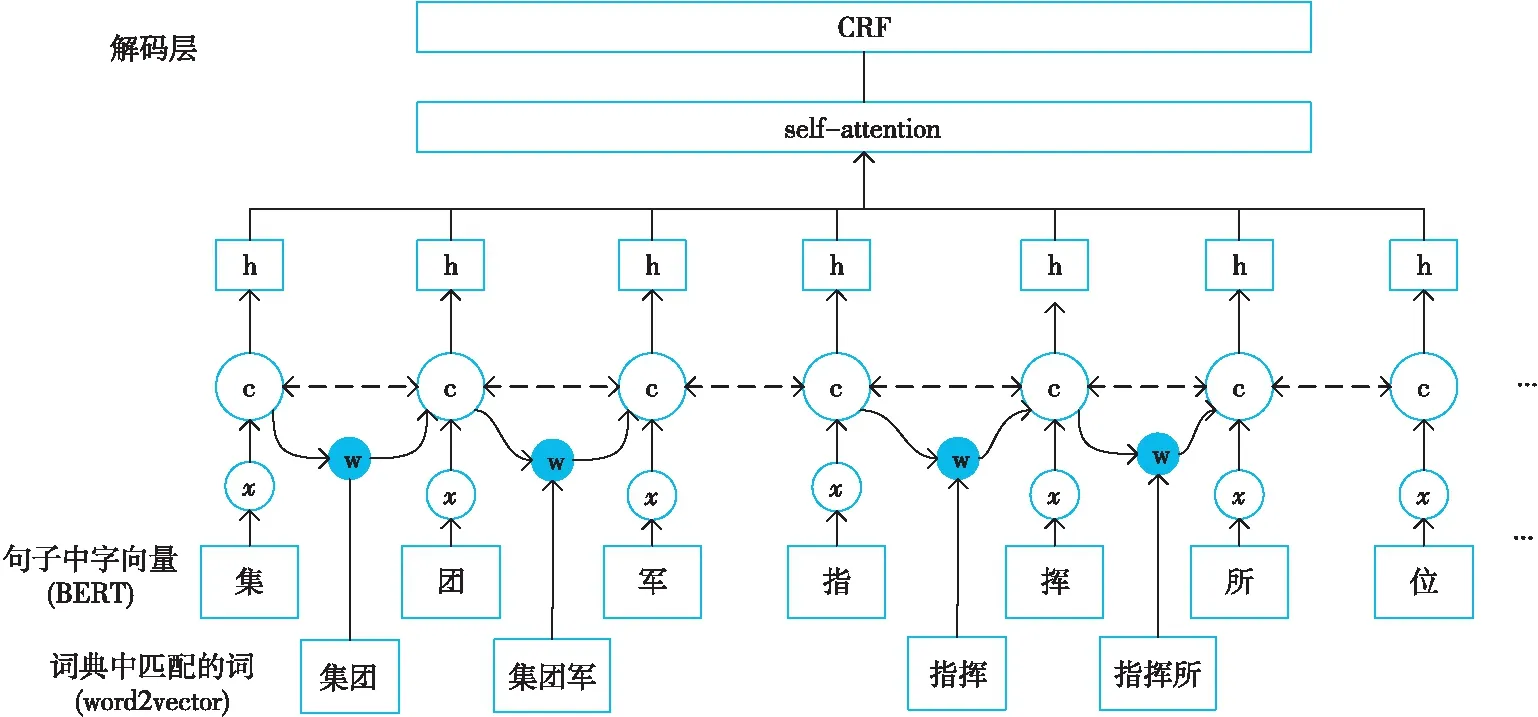
Figure 1 Lattice-LSTM structure图1 Lattice-LSTM 结构图
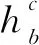
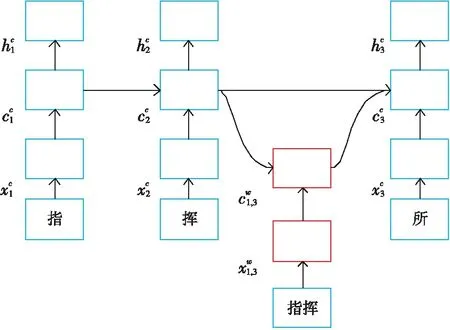
Figure 2 Lattice model图2 Lattice 模型
Lattice-LSTM 对字信息的提取同原始结构一样,但对于词主要是通过重新设计循环网络单元结构,在原网络的基础上加入外部词典来增强模型对于词信息的获取。该模型集成了词序列信息和用于控制信息流的附加门,如图2所示。
(11)
再将当前字计算出的输入门和所有词的输入门进行归一计算出权重:
(12)
其中,D表示之前构建的字典。
最后和通常计算注意力特征向量的方式一样,利用计算出的权重进行向量加权融合:
(13)
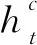
2.4 Self-attention结构
正如“注意”一词所表达的意思,self-attention结构的重点是给予上下文的局部信息,使模型加强对重要信息的捕捉,减少非必要信息的噪声影响。简单来说,将重点放在序列的特定部分,而不是整个序列来预测该单词,不会丢弃编码器状态的中间值,而是利用它从所有状态生成上下文向量,以便解码器给出输出结果。作为适用于顺序数据建模的代表性深度学习结构,LSTM网络结构被视为建立关注机制的基础网络。 LSTM的作用是对每个输出层在其之前的层上施加的影响权重的时间历史进行建模,并且注意力机制会自适应地确定每个输出层对最终特征性能的影响。
自注意力(self-attention)机制是注意力机制的一个特例,也被称为内部注意力机制(Intra Attention)。Self-attention 的奖励策略是点乘注意力(Scaled Dot-Product Attention)函数[10],如图3所示。先通过词向量Q和K的点乘运算来得到每2个词之间的相关性,再利用softmax进行归一化处理,最后对V进行加权求和,如式(14)所示:
(14)
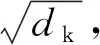
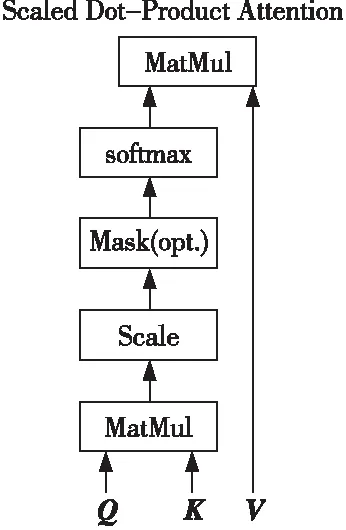
Figure 3 Scaled dot-product attention function图3 点乘注意力函数
使用单个注意力策略并一不定可以达到理想效果,本文使用多头注意力(Multi-head Attention)策略[10]从多个方向对文本隐含信息进行提取,以增加文本表达信息的力度和强度,如图4所示。
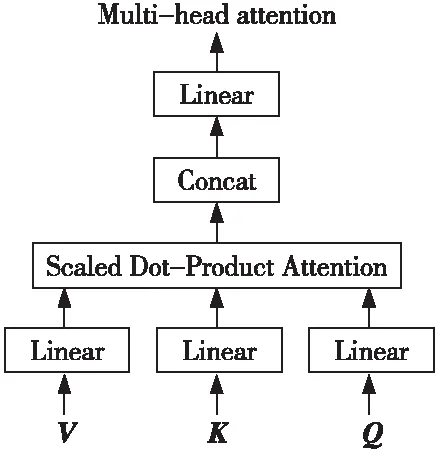
Figure 4 Multi-head attention mechanism图4 多头注意力机制
多头注意力机制是将Q、K、V分别通过参数矩阵进行转换,再对转换后的参数矩阵进行点乘。将该过程重复h次后的结果进行拼接,得到最终的特征信息,其计算公式如式(15)和式(16)所示:
(15)
M(Q,K,V)=Concat(head1,…,headi)Wo
(16)
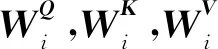
2.5 CRF 结构
对于命名实体识别模型,给出最终标签预测结果的通常是其组成结构中的网络输出层,其功能是对隐含层输出的非标准化计算值进行归一化处理。通俗来讲就是将模型对于不同文本属于各个标签的得分转化为概率,最终给出分类预测结果。但是,每个标签结果的概率值计算是相互独立的,局部的标签和上下文信息不会被归一化函数计算进去,所以使用归一化函数并不是最准确的策略。为了解决上述问题,CRF避免了没有考虑附近标签的相关性的缺点,通过融合相关标签数据实现对句子级信息较为准确的标注。CRF的核心模块是标签的转移奖励矩阵,该矩阵的作用是利用计算全局的序列最优解对结果进行优化,计算出全局最优的序列预测结果,在一定程度上弥补了独立计算概率方法的不足。
对于输入文本向量,LSTM 输出的结果是维度为n*k的矩阵P,其中n是输入序列的长度,k是定义标签的数目,p(i,j)表示模型将输入xi分配给标签yj的得分。对于一个待预测的文本序列Y=[y1,…,yn], 其得分定义为:
(17)
其中,A(yi,yj)表示第i个标签到第j个标签的转移奖励矩阵,y0和yn是句子起始和结束字符,所以在输入句子为X产生序列标记为y的概率为:
(18)
其中,y′代表真实的标签值。
在模型权重更新过程中,使用式(19)和式(20)所示的最大化对数似然函数:
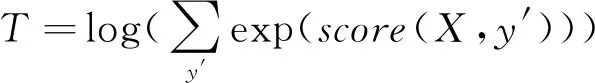
(19)
logP(yx|X)=S(X,yx)-T
(20)
3 实验与结果分析
3.1 数据集
针对中文命名实体识别和实体关系的分析研究,本文使用的数据集来源于联合作战公共数据集的军事数据集,该数据集为人工新标注的特殊军事领域数据集。本文根据该数据集中文本的特殊性,并结合经典ACE 2005[20]中文数据集的实体类型和实体关系类型,定义军事领域文本数据集中的命名实体和实体关系,然后使用人工完成标注。军事特定领域文本标注数据集中命名实体的类型共有4种:人名PER(Person)、地名LOC(Location)、机构名ORG(Organization)和装备EQU(Equipment)。为了更全面地验证本文所提方法的效果,本文也在开放数据集 Chinese Resume[6]上进行了结果校验。
3.2 评价方法
为了对命名实体识别模型的准确率有客观和全面的评价,本文使用以下3个指标对人名、地名、机构名和装备的识别结果进行计算:准确率P(Precision)、召回率R(Recall)、F1 值(F1-Score)。对于二分类情况,将测试数据集的真实分类和模型计算得出的分类进行比较,4种指标如图5所示,样本总数为TP+FP+FN+TN。对比结果用混淆矩阵表示。
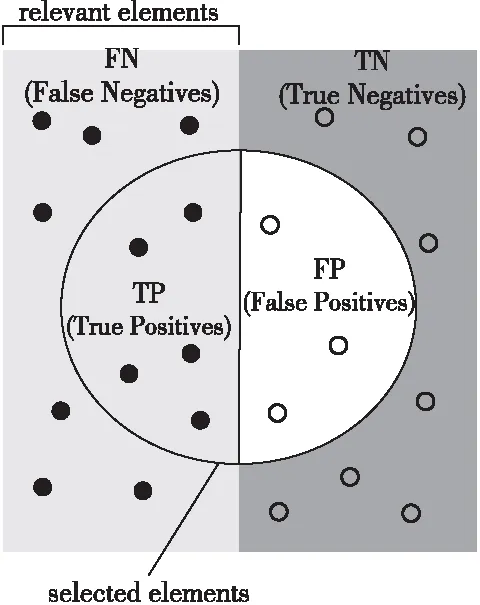
Figure 5 Comparison of four prediction types图5 4种预测类型对比
(1)准确率:正确识别的命名实体数占全部识别出来的命名实体数的比例:
P=TP/(TP+FP)×100%
(21)
(2)召回率:正确识别的命名实体数占数据集中命名实体总数的比例:
R=TP/(TP+FN)×100%
(22)
(3)F1 值:准确率和召回率相互影响,很多情况下单一指标无法准确衡量,需要将几个指标综合计算,最常见的就是F1值:
F1=2×P×R/(P+R)
(23)
可见F1值综合了精确率和召回率的结果,F1值较高时说明模型的整体性能较好。
3.3 实验设置
本文在TensorFlow1.11框架基础上进行实验,该深度学习框架被研究人员广泛应用于各类机器学习算法的实现。使用Python实现模型的构建和训练。本文实验中字向量和词向量的维度都是768。采用ADMA 作为优化器,训练时的学习率(Learning Rate)为0.01。为了预防训练过程中发生梯度爆炸,使用梯度裁剪(Gradient Clipping)技术并设置参数为5。使用随机丢弃(dropout)技术来防止过拟合,值设为0.5。
3.4 结果与分析
在上述军事领域实验样本集和参数设置基础上,本文选择 4个模型进行对比实验,表1所示为不同模型的对比实验结果。
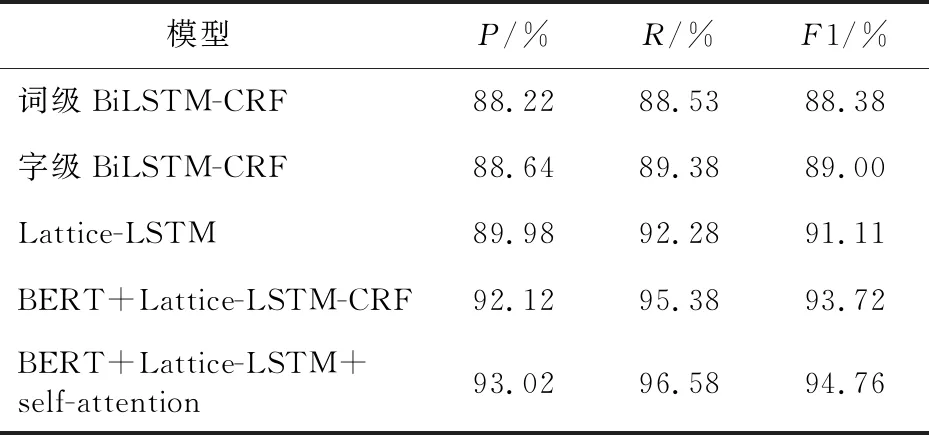
Table 1 Comparative experimental results of various models in the military field
为了将词级、字级的BiLSTM-CRF 模型性能进行比较和分析,第1步是对字级BiLSTM-CRF与词级BiLSTM-CRF进行对照实验,实验数据显示,字级BiLSTM-CRF模型的准确率、召回率和F1值分别为88.64%,89.38% 和89.00%,对比词级BiLSTM-CRF模型分别高出了0.42%,0.88% 和0.62%。可以得出结论,字级BiLSTM-CRF模型由于能够更好地利用上下文信息,效果要优于词级BiLSTM-CRF模型。此外还可以发现,Lattice-LSTM 模型相比于字级BiLSTM-CRF与词级BiLSTM-CRF模型的性能都有不小的提升,说明Lattice-LSTM可以捕获词级信息融入模型。为了验证使用预训练模型BERT提取特征的有效性,设置了BERT-BiLSTM-CRF 模型。BERT-BiLSTM-CRF 模型与BiLSTM-CRF 模型相比,有不低于2%的准确度的提升,从这里可以看出 BERT 模型对文本数据中字符间的关联提取较为精准,对提升模型的精度发挥了重要作用。本文在模型 5 中加入了自注意力机制,即表 1中BERT+Lattice-LSTM+self-attention 模型,其准确率、召回率、F1值分别达到了 93.02%,96.58% 和94.76%。相较模型4 中未包含 self-attention 层的模型3项指标分别提高了0.9%,1.20% 和1.04%。可以看到,自注意力机制的引入提升了模型性能,表明了多头注意力机制能在多个不同子空间捕获上下文信息,从而获取更丰富的文本内部特征信息。
表2为各模型在Chinese Resume数据集上的表现。为了比较的公平性,本文没有采用BERT训练文本的向量表示,而是采用词嵌入表示[6]。从表2中可以发现,本文所提模型相较于基准模型,其准确率、召回率、F1值都达到最好的结果,分别为95.60%,94.88% 和95.23%,说明本文模型识别相关实体的有效性。对比 Lattice-LSTM模型[11],本文所提模型准确率、召回率、F1值分别提高了0.79%,0.77% 和0.77%,同样表明了Lattice-LSTM结构结合self-attention的有效性。
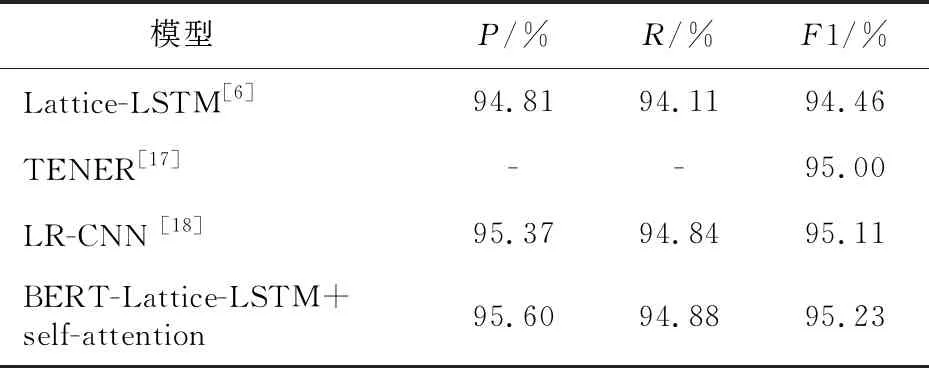
Table 2 Comparative experimental results of each model on Chinese Resume dataset
4 结束语
本文针对军事命名实体识别任务的特点,提出了一种基于Lattice-LSTM结合自注意力机制的军事命名实体识别方法,以BiLSTM-CRF为基线模型,分别对字级BiLSTM-CRF、词级BiLSTM-CRF、BERT+BiLSTM-CRF、BERT+Lattice-LSTM和BERT+Lattice-LSTM+self-attention 在自建数据集上进行了对比实验。实验结果表明了引入Lattice-LSTM 和自注意力机制的有效性,此外预训练模型BERT在模型的总体性能提高方面也有重要作用。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
中国外汇(2019年18期)2019-11-25 01:41:54
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
哲学评论(2017年1期)2017-07-31 18:04:00
传媒评论(2017年3期)2017-06-13 09:18:10
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
