
基于生成对抗网络的无监督图像风格迁移 *
2021-10-26 02:11:26辛月兰殷小芳刘卫铭姜星宇
计算机工程与科学 2021年10期
兰 天,辛月兰,殷小芳,刘卫铭,姜星宇
(青海师范大学物理与电子信息工程学院,青海 西宁 810001)
1 引言
近年来,机器学习与深度学习的发展取得了重大的突破,尤其是深度学习的发展使计算机具备了非常强大的感知能力,计算机可以感知物体、识别内容,甚至理解人们说的话。生成式对抗网络GAN(Generative Adversarial Network) 是Goodfellow[1]在2014年提出的一种生成模型。目前GAN在图像处理领域和计算机视觉领域得到了广泛的研究和应用,例如图像复原[2]、图像识别[3]、超分辨率合成[4]和语义分割[5]等,并且相比传统的卷积神经网络取得了更优异的效果。无监督的图像风格迁移是一种图像到图像的转换问题[6],在没有配对示例的情况下将图像从源域X转换到目标域Y的方法。图像到图像的转换可以追溯到Hertzman[7]的图像类比,他们在单个输入输出训练图像对上采用了非参数纹理模型,在传统的图像风格迁移模型中,一种算法同时只能进行一种图像风格的迁移,因此它有着极大的限制。而Gatys等[8]首次使用卷积神经网络进行图像风格的迁移,可以同时获得多种图像风格,首先输入原图像,对深层卷积神经网络中的卷积层所获得的图像特征进行图像内容的约束,然后通过不同阶段的卷积特征学习得到图像纹理,进行纹理约束,从而优化得到最终结果。Isola等[6]提出的“pix2pix”框架借助条件生成对抗网络[9]来学习从输入图像到输出图像的映射,这是真正意义上利用GAN进行图像风格迁移的方法,但需要成对匹配的数据。无论以上哪种方法都是在有监督的条件(即具有先验知识)下进行的,这些模型都需要预先对源域和目标域的数据进行匹配,但如果想改变一幅图像的风格,例如校园夏天的图像变成秋天的图像,几乎不可能找到和此图像内容完全一致的秋景让神经网络学习,因此以上方法均不是理想的方法。
研究人员最近广泛研究在没有监督的情况下进行图像转换。这个问题看似是一个不合理的问题,因为它需要另外附加约束。然而无监督的图像风格迁移目前有了几种解决方案,Resales等[10]提出了一种包含先验知识的贝叶斯框架,该框架基于马尔可夫随机场计算由多个源图像和一个似然项而得到的风格图像。耦合生成对抗网络[11]和跨场景模式网络使用权重共享策略来实现跨域的通用表示。Liu等[12]将变分自动编码器[13]与耦合生成对抗网络结合在一起,利用GAN框架,将不同图像域的图像特征映射到同一空间中,其中2个生成器共享权重以学习跨域图像的联合分布。与上述方法不同的是,循环一致性网络不依赖于输入和输出之间任何特定于任务的预定义的相似性函数,也不假定输入和输出必须位于相同的低维空间中,因此循环一致性网络是图像到图像转换的通用解决方案。卷积神经网络被广泛应用于图像处理中,并且在图像处理任务中取得了最佳的性能。在各类经典的神经网络网络结构中,效果最好的结构是DenseNet[14],在该结构中,每一层均采用密集连接的方式将该层之前的每一层输出引入到该层中,极大增强了网络的建模能力。相比ResNet[15],DenseNet网络的不同之处在于它提出了特征共享的思想,因此其参数量会大幅减少,并且避免了传统神经网络梯度消失的缺陷。因此,本文在生成器网络部分引入DenseNet,组成了密集连接的残差网络,网络训练速度得到提升。同时,将attention机制引入网络,使生成器不再只关注局部特征,生成的图像效果更佳。而在网络结构方面,在每一个卷积层都增加谱归一化,这样可以降低模型的结构风险。
2 循环一致性对抗网络结构
循环一致性对抗网络的核心结构是2组生成式对抗网络,这2组生成式对抗网络是合作关系。X与Y分别代表2组不同的图像数据域,第1组生成对抗网络是生成器G(从X到Y的生成)与判别器DY,用于判断生成的图像是否属于域Y;第2组生成对抗网络是生成器F(从Y到X的生成)与判别器DX,用于判断图像是否属于域X。2个生成器的目标是尽可能生成对方域的图像来“骗过”对方的鉴别器。
2.1 生成式对抗网络
生成式对抗网络GAN由生成器G和判别器D组成,2个网络并非合作关系,而是对抗与博弈的关系。在对抗与博弈的过程中,生成网络G就好比赝品制作者,而判别网络就好比一个鉴别师,赝品制作者仿制能力会越来越强,鉴别师的鉴别能力也会越来越强,二者通过不断地对抗最终达到一个平衡。G和D的对抗损失函数如式(1)所示:
minGmaxDV(D,G)=Ex~Pdata(x)[logD(x)]+
Ez~Pz(x)[log(1-D(G(x)))]
(1)
其中,x为输入的图像数据,Pdata(x)为输入图像的数据分布,Pz(x)为输入到生成网络的噪声分布,E表示数学期望。
2.2 循环一致性网络
从理论上来看通过2组生成对抗网络独立的训练就能达成目标,但是这之间存在一个问题是生成器G可以不从域X中提取任何信息而直接从域Y生成数据,独立训练会失去各自的意义,因此需要引入循环一致性网络。

Figure 1 Principle diagram of two groups of generative adversarial network图1 2组生成式对抗网络原理图
图1的2个过程可以用式(2)和式(3)表达:
x→G(x)→F(G(x))≈x
(2)
y→F(y)→G(F(y))≈y
(3)
其中,式(2)表示前向循环一致性,式(3)表示反向循环一致性,前向循环一致性和反向循环一致性组成了一个完整的循环一致性网络。
为了将生成图像的数据分布与目标域图像数据的分布进行匹配,需要引入对抗损失,而传统的对抗损失通常会出现训练不稳定的情况,生成图像会出现模式崩溃的问题。因此,为了稳定训练过程并生成更高质量的图像,本文采用最新的研究成果来稳定训练过程,即采用如(4)式所示的Wasserstein GAN(衡量真实数据分布和生成数据分布之间距离)[16]的改进模型WGAN-GP替换式(1):
LGAN=Ex[D(x)]-Ex[D(G(x))]-
(4)

为了防止学习到的映射G和F相互矛盾,需要引入循环一致性损失。循环一致性损失函数如式(5)所示:
Lcyc(G,F)=Ex~Pdata(x)[‖F(G(x))-x‖1]+
Ey~Pdata(y)[‖G(F(y))-y‖1]
(5)
式(5)使用L1范数计算损失,因此完整的损失函数如式(6)所示:
L=LGAN+Lcyc(G,F)
(6)
2.3 长距离依赖关系
人类在看东西时首先会进行定位,即最先关注到感兴趣的区域,而这种该关注哪里就看哪里的机制就是注意力机制(attention)。注意力机制旨在捕获长距离依赖关系,而捕获这种依赖关系是深度神经网络的核心问题,对于序列数据(语音),周期性操作是长距离依赖关系建模的主要解决方案,而对于图像数据,长距离依赖关系是由卷积操作形成的大的感受野。使用非局部操作捕获长距离依赖关系可以对远端图像细节进行协调,从而输出优异的结果。最近的研究表明,注意力机制已经成为必须捕获全局依赖性的模型的组成部分,大多数基于GAN的图像生成模型是使用卷积层构建的,卷积在局部邻域中处理信息,因此仅使用卷积层在建模图像中的长距离依赖关系时计算效率低下。本文在生成器部分引入注意力机制,注意力机制通过关注同一序列中的所有位置来计算序列中某个位置的响应,首先将来自先前隐藏层的图像特征转换到2个特征空间以计算注意力,然后注意力层的输出乘以比例参数,最后加回到输入的图像数据,这使网络可以首先依靠邻域中的线索,然后逐步学会为非邻域特征分配更多的权重。该机制不仅可以更好地对结构性强的图像进行建模,并且还可以保留更多图像细节。注意力机制结构如图2所示。

Figure 2 Structure of attention mechanism图2 注意力机制结构
图2中,Q,K,V分别表示来自隐藏层的3个特征向量空间,Q为查询向量,K为键向量,二者执行Softmax操作后与值向量V相乘得到注意力特征图。
2.4 谱归一化
最近有关网络参数调节与GAN相关的最新见解表明,生成器的条件几乎决定了训练的成败,因为GAN的训练总是不稳定的,而归一化技术有助于加速训练,提高准确性,提高学习速率。Miyato等[17]通过将谱归一化应用于判别器网络来稳定GAN的训练,但这样做会限制网络每层的谱范数,从而限制了鉴别器的Lipschitz条件(函数的导数始终小于某个固定的常数K)。与其他归一化技术相比,谱归一化不需要额外的超参数调整,并且计算成本也相对较小。因此,本文将谱归一化应用于生成器中,以防止参数幅度的提升并避免异常的梯度。从实验中可以发现,生成器和鉴别器的谱归一化可以显着降低训练的计算成本,也能使训练更稳定。
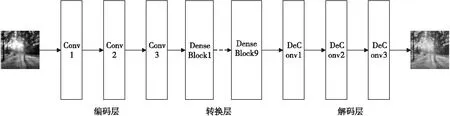
Figure 3 Generator network图3 生成器网络
3 实验与结果分析
3.1 实验平台与数据集
本文所采用的实验平台为Intel i5 8300H 2.3 GHz 4核处理器,图形处理器NVIDA GTX1060(6 GB),内存8 GB,深度学习框架采用基于GPU版本的PyTorch 0.4.1。数据集使用facades数据集以及由cycleGAN提供的monet2photo数据集和vangogh2photo数据集。其中,facades数据集包含226幅语义图像和226幅真实图像,这些图像均作为训练集和测试集。monet2photo数据集包括2种风格的图像,训练集由莫奈油画风格图像和相机拍摄的风景风格图像组成,其中莫奈油画风格训练集由1 337幅256×256大小的图像组成,风景风格训练集由3 671幅256×256大小的图像组成,同样测试集也由2种风格的图像组成,莫奈油画风格的测试集由271幅256×256大小的图像组成,风景风格测试集由751幅256×256大小的图像组成。vangogh2photo数据集包含梵高画作风格图像和风景风格图像,梵高画作训练集由755幅256×256大小的图像组成,风景风格训练集由6 287幅256×256大小的图像组成,测试集由400幅256×256大小的梵高画作风格图像和751幅256×256大小的风景风格图像组成。
3.2 网络模型
生成器网络由编码层、转换层和解码层构成,传统循环一致性网络转换层由6个ResNet模块组成,本文改进的网络采用9个Dense Block模块。在ResNet中,第k层的输入Xk-1经过函数Hk后得到的输出Hk(Xk-1)再加上输入就组成了下一层的输入Xk,如式(7)所示:
xk=Hk(Xk-1)+xk-1
(7)
而DenseNet由Dense Block模块组成,第k-1层的输入与之前所有层的输入按照通道组合在一起作为真正的输入,经过一个BN层、ReLU和卷积层后得到对应的隐层输出,该输出即是下一层的输入Xk,如式(8)所示:
xk=Hk([X0,X1,…,Xk-2,Xk-1])
(8)
尽管DenseNet采用密集连接的方式,但实际参数量比ResNet少得多。本文生成器网络模型如图3所示,其中,编码层的作用是将输入图像的特征向量进行编码,转换层的作用是将输入的特征向量转换为目标域的特征向量,解码层的作用是对目标域的特征向量解码,生成目标域的图像。在转换层的开始和结束都增加一个注意力机制,除了解码层第3个反卷积,其余每一个卷积层都增加谱归一化。
判别器网络采用Isola等[6]提出的PatchGAN判别模型,PatchGAN的思想是将图像划分为若干个70×70的图像块,然后对这些图像块是真实的还是生成的进行分类,计算这些图像块分类的结果平均值,从而判断图像是真实的还是生成的。判别器网络模型如图4所示。

Figure 4 Discriminator network图4 判别器网络
训练时同时训练2个域的图像,即莫奈油画风格图像和风景风格图像、梵高画作风格图像和风景风格图像、建筑物语义图像和真实图像,这些图像并没有进行配对。传统的循环一致性网络训练时每一次迭代需要40 min,而本文改进的网络每次迭代减少到34 min左右。
3.3 实验结果
为了体现模型的泛化能力,本文在facades和vangogh2photo数据集上分别进行了莫奈油画风格转风景风格和风景风格转莫奈油画风格的实验,并将实验效果和DiscoGAN[18]、传统的循环一致性网络CycleGAN进行了对比。
3.3.1 monet2photo数据集上实验结果
莫奈油画风格转风景风格的对比结果如图5所示,第1列为输入图像,第2列为CycleGAN的结果,第3列为DiscoGAN的结果,第4列为本文方法的结果。

Figure 5 Contrast experiment of Monet style transferred to landscape photos图5 莫奈风格转风景风格对比实验
输入为莫奈油画风格图像,实验目标是将莫奈油画风格图像转换为风景风格图像,实验结果越接近真实生活场景则效果越好。从图5可以看出,传统的CycleGAN在稻草堆转换过程中保留了油画当中的红色,DiscoGAN结果出现变形,而本文方法更接近真实生活中的土黄色并且形状未发生改变;而第2行中CycleGAN和DiscoGAN生成的结果中海水出现了绿色;第3行本文方法生成的结果中无论天空颜色还是草地细节都优于前2种方法。
风景风格转莫奈油画风格的实验结果如图6所示,第1列为输入图像,第2列为CycleGAN生成的图像,第3列为DiscoGAN结果,第4列为本文方法结果。

Figure 6 Contrast experiment of landscape photos transferred to Monet style图6 风景照转莫奈画风对比实验
输入风景风格图像,学习莫奈油画风格图像,希望将风景风格图像转换为莫奈油画风格图像。从图6可以看出,传统的CycleGAN生成的图像更像是将风景风格换了颜色,第1行的绿树也没有生成很好的细节;第2行背景颜色没有得到很好的生成;第3行路边小花没有得到保留;而本文方法的结果更接近真实的油画风格,并且细节得到更多保留。因此,实验结果表明,本文引入的attention机制有助于提升图像的生成效果。
3.3.2 facades和vangogh2photo数据集上实验结果
facades数据集上的实验结果如图7所示,输入为语义图,目标是将语义图还原为真实图像,第1列为输入,第2列为CycleGAN实验结果,第3列为DiscoGAN实验结果,第4列为本文方法实验结果。

Figure 7 Experimental results on facades data set图7 facades数据集上的实验结果
从实验结果可以看出,DiscoGAN实验结果比CycleGAN实验结果涂抹感更严重一些,而本文方法在细节恢复上更胜一筹,尤其是第2行最后一幅图像楼下的护栏。
vangogh2photo数据集上的实验结果如图8所示,第1列为输入,第2列为CycleGAN结果图像,第3列为DisacoGAN结果图像,第4列为本文方法实验结果。输入为梵高画作风格图像,目的是将其转换为风景风格图像。

Figure 8 Contrast experiment of Van Gogh style transferred to landscape photos图8 梵高画作风格图像转风景风格图像对比实验
从实验结果来看,尽管CycleGAN和DiscoGAN取得了相似的结果,且 CycleGAN的实验结果细节更丰富,例如第2行远处的房子,但是色彩还原上不尽人意。而本文方法无论是颜色上还是细节上都获得了良好的效果。
3.3.3 消融实验
为了验证attention机制(AT)在生成效果上的有效性,本文进行了消融对比实验,实验结果如图9所示。经过大量实验表明,使用DenseNet网络和谱归一化技术仅起到加快网络收敛速度和提高稳定性的作用,对图像生成效果并没有本质的提升;而attention机制善于捕获全局细节,对于颜色的捕获也非常敏感,对于图像生成效果起到至关重要的作用。例如第1行图像立体结构发生较大改变,引入attention机制有明显的效果提升,而对风景风格图像在颜色上的还原也起到良好的作用。

Figure 9 Ablation comparison test图9 消融对比实验
3.4 性能评估
IS(Inception Score)分数是衡量图像质量的常用指标,IS分数通过计算目标域的概率分布和生成图像的概率分布之间的KL散度(概率分布之间的相似程度)来衡量生成图像和目标域图像之间的差异。本文采用IS分数进行评估,IS分数通过谷歌提供的Inception V3网络计算得到,该网络主要从图像清晰度和图像多样性来衡量图像生成的质量,因此IS分数越高则代表生成图像的质量越好。IS平均分数对比如表1所示。

Table 1 IS comparison
FID(Fréchet Inception Distance)是更权威和更全面的一种评价指标,在评估所生成样本的真实性和变化方面与人类主观感受更加一致。FID分数同样通过谷歌提供的Inception V3网络计算得到,衡量特征空间中生成图像和实际图像之间的距离。因此,FID分数越低,意味着生成数据分布与实际数据分布之间的距离越接近,图像生成效果越好。FID平均分数对比如表2所示。

Table 2 FID comparison
4 结束语
传统的循环一致性网络采用的ResNet在实验过程中表现并不稳定,有时会出现梯度消失的现象,导致生成器无法继续学习,而本文集成了DensNet网络,在减少参数量的同时也避免了梯度消失现象,训练过程更稳定。通过对生成器引入注意力机制提高了图像的生成效果,可以更好地进行图像风格迁移。
猜你喜欢
小猕猴学习画刊·下半月(2022年9期)2022-11-03 12:08:12
公民与法治(2022年5期)2022-07-29 00:47:28
教学考试(高考物理)(2021年5期)2021-11-08 10:31:22
中医眼耳鼻喉杂志(2021年1期)2021-07-22 07:38:14
天水师范学院学报(2020年6期)2020-06-05 02:05:34
小学科学(学生版)(2020年5期)2020-05-25 07:11:38
现代妇女(2018年6期)2018-06-10 15:38:26
新东方英语·中学版(2017年9期)2017-09-25 07:06:52
海燕(2017年4期)2017-04-11 13:52:18
爆笑show(2016年3期)2016-06-17 18:24:33
