
基于高光谱的茄子外部缺陷检测
2021-10-09 05:19:46池江涛张淑娟任锐廉孟茹孙双双穆炳宇
现代食品科技 2021年9期
池江涛,张淑娟,任锐,廉孟茹,孙双双,穆炳宇
(山西农业大学农业工程学院,山西太谷 030801)
茄子(Solanum melongenaL.)又称昆仑瓜、矮瓜、落苏和酪酥等,属于非呼吸跃变型果实,起源于亚洲东南热带地区,西汉时传入我国[1]。茄子富含膳食纤维、维生素、多酚、蛋白质和矿物质等多种营养物质,具有降血脂、防治高血压和糖尿病、保肝以及抗氧化等保健功效[2]。茄子的生产和开发利用市场前景广阔,然而茄子存在木栓化和烂果等缺陷问题,严重影响了茄子的产量和品质,进而降低了其商品性。木栓化可能是高温或者气候变化异常导致茄子钙硼缺失引起;烂果则可能由虫害、菌害、雨水和光照等因素造成。在实际生产过程中,将茄子木栓化和烂果样本剔除仍然靠人工来完成,不仅耗时耗力、效率低下,还易造成漏选,因此实现一种能够快速、准确识别木栓化和烂果茄子的方法则尤为重要。
高光谱成像技术将光谱分析技术和数字成像技术相结合,可以同时获得样本大量波段的空间图像信息和每一像素点的光谱信息,具有灵敏度高、测量速度快和抗干扰能力强等优点,广泛应用于农产品无损检测、病害检测等领域中[3]。刘立新等[4]利用高光谱技术结合机器学习算法,基于CARS 提取的特征波段建立LDA、KNN 和SVM 模型来鉴别红枣品种,总准确率分别达到85.53%、98.68%和98.25%;A.Del Fiore 等[5]利用高光谱成像技术,在光谱范围为400~1000 nm内对玉米产毒真菌进行研究,实现了玉米早期病害的检测;Folch-Fortuny 等[6]利用高光谱成像技术,采用排列测试法提取特征波长并建立多路PLS 判别模型,实现了柑橘腐烂病的检测;Sun 等[7]利用高光谱成像技术对无损、轻度腐烂、中度腐烂和重度腐烂的桃子进行病害检测,进一步提高了其病害识别率;李宏强等[8]采用高光谱分析技术结合模式识别,通多分层、分步骤建立了8 种马铃薯微型种薯的分类模型,其平均正确识别率达到89.75%,表明高光谱分析技术可用于马铃薯微型种薯的分类检测;YEH 等[9]基于高光谱成像技术,对草莓叶状炭疽病进行研究,利用光谱角度映射器实现了对病害的3 个不同感染阶段的有效检测;LAN 等[10]运用多种机器学习算法,分别对健康和黄龙病感染的柑橘多光谱样本建模,实现了很强的分类效果。上述研究均为利用高光谱成像技术对各种农产品进行识别分类,就目前研究状况来看,尚未有学者利用高光谱对茄子外部缺陷类型进行鉴别研究。
本研究采用高光谱技术对茄子完好、木栓化和烂果进行检测,通过多种预处理方法对原始光谱数据进行预处理,并建立PLS 判别模型比较分析,选择最佳预处理方法进行后续研究。采用SPA、RC 和CARS对预处理后的光谱数据提取特征波长,基于特征波长分别建立PLS 和MLR 判别模型进行比较分析,以实现对茄子缺陷的定性判别,为进一步开发茄子在线分选装备提供了理论依据。
1 材料与方法
1.1 试验材料
所有用于试验的茄子样本均采摘于山西省晋中市太谷区明星乡武家堡村(茄子于2020 年5 月23 日移栽,7 月20 日采摘),品种为“紫光”茄子。为保证研究的可靠性,采摘时选择大小(单果质量450 g~680 g)均匀,形状为近圆球形以及缺陷类型(完好、木栓化和烂果)齐全得茄子作为试验样本,图1 所示为3 类样本图。运回实验室后,对其表面泥土进行清理以避免误判。共挑选252 个样本,包含完好样本170 个,木栓化样本60 个和烂果样本22 个。采集各样本的高光谱图像,然后从中提取252 个光谱数据,运用Kennard-Stone 算法将3 类样本按近似3:1 的比例随机划分为校正集样本189 个和预测集样本63 个。

图1 采集的茄子样本 Fig.1 Sample of eggplant collected
1.2 高光谱信息采集
本试验采集样本信息的仪器为北京卓立公司开发的“盖亚”高光谱分选仪,仪器部件包括:计算机、Image-λ-N17E 光谱相机、4 个溴钨灯、暗箱以及电控移动平台,采集到的光谱波长范围为900~1700 nm。采集的信息过度饱和会出现失真现象,因此在信息采集前需调试曝光时间和平台的移动速度。根据实验经验,设置曝光时间为20 ms,平台移动速度为2 cm/s,样本与镜头的距离为22 cm 时,采集效果最佳。
为消除光强的变化和镜头中暗流对成像产生影响,以及计算扫描物体的相对反射光谱值,因此要在光谱采集前进行黑白板校正[11]。计算公式如式(1):
式中,R 是校正后的高光谱图像,I 是原始高光谱图像,B 是黑板校正后的高光谱图像,W是白板校正后的高光谱图像。
1.3 光谱分析和数据处理软件
研究中的数据处理和分析基于ENVI 4.7、Matlab R2012a、The Unscrambler X 10.1、Origin 8.5 和Microsoft Excel 2010 等软件完成。
2 基于高光谱数据的茄子外观品质定性判别分析
2.1 茄子完好、木栓化和烂果3 种区域的平均光谱曲线图
使用ENVI 4.7 软件的提取感兴趣区域(ROI)函数分别提取茄子的木栓化、烂果和完好3 种区域的光谱数据,然后计算并求取各类样本的平均光谱,如图2 所示。“紫瓜”茄子呈类球状,且表皮光滑发亮,导致采集到的高光谱图像中间区域漫反射强度大、信噪比高,影响建模精度以及试验可靠性。因此,在利用ENVI4.7 提取感兴趣区域时应避开中间反光区域。
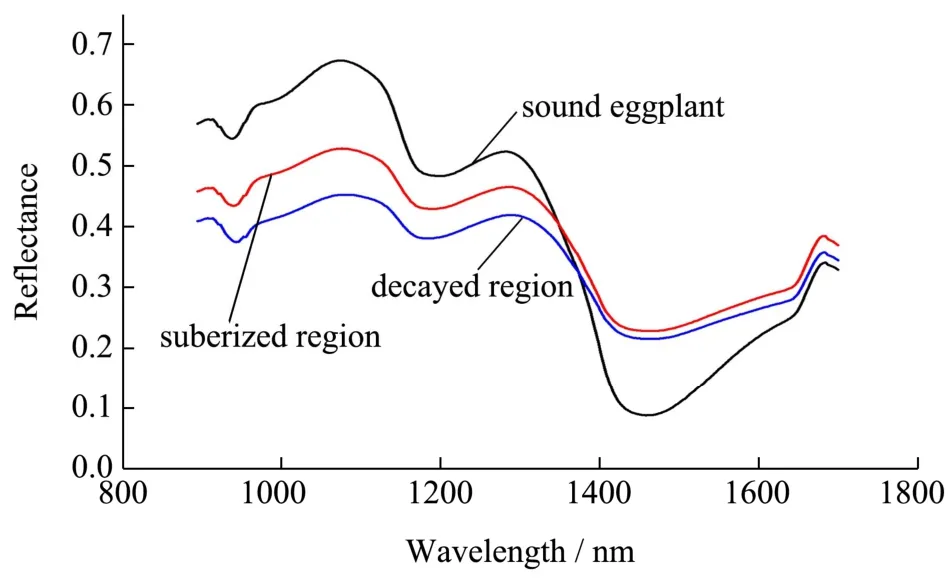
图2 完好、木栓化和烂果区域平均光谱图 Fig.2 Average spectral image of sound,suberized and decayed regions
由图2 可知,完好茄子、木栓化区域和烂果区域的平均光谱曲线具有很大差别,在900~1300 nm 范围内,完好区域的反射率最高,原因可能是完好茄子表皮光滑,对光的反射最强;在1200 nm 附近的3 种曲线均为波谷,这是由于茄子表皮叶绿素的C-H 基团二级倍频吸收作用[12];大于1350 nm 的波段范围,完好区域的反射率低于木栓化和烂果区域的反射率。
2.2 光谱数据预处理
对采集到的原始光谱数据预处理,可以有效降低或消除因采集背景、噪声干扰和暗电流等产生的大量与样本固有性质无关的冗余信息,起到提高模型精度和预测能力的作用[13]。本研究采用标准归一化(standard normalized variate,SNV)、多元散射校正(multiplicative scatter correction,MSC)、中值滤波(median filter,MF)、卷积平滑(savitzkygolay,SG)和归一化(normalize)等方法对原始光谱数据进行预处理,通过建立PLS 模型,比较模型参数决定系数(Rc2、Rp2)和标准偏差(RMSEC、RMSEP)(决定系数越大,标准偏差越小,其建模精度越高)以确定最佳光谱预处理方法。
由表1 可以看出,经Normalize 预处理后所建立的PLS 模型精度最高,其校正集决定系数Rc2最大,为0.74;均方根误差RMSEC 最小,为0.33。其预测集决定系数Rp2为0.85,均方根误差RMSEP 为0.26,同样均为最优。因此,最终选择Normalize 作为预处理方法进行后续研究。
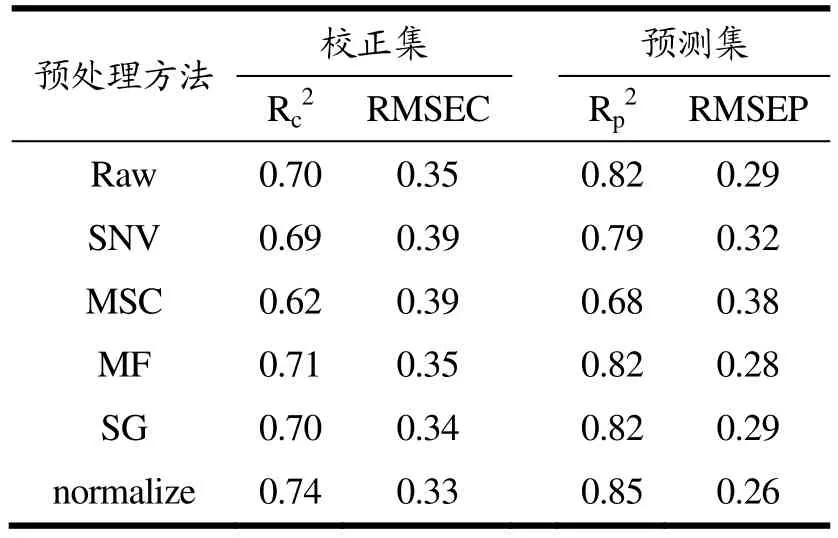
表1 不同预处理方法对3 类茄子PLS 分类模型精度的影响 Table 1 Effects of different pretreatment methods on the accuracy of PLS classification model of eggplant
2.3 特征波段提取
特征波段来源于全光谱波段,携带其最重要的光谱判别信息。其作用主要有:消除原始数据的线性相关性、奇异性和不稳定性;降低数据维数,减少变量数,排除多余的干扰信息等。特征波段的提取直接影响模型建立的效率以及建模后预测结果的可靠性和准确性。
2.3.1 连续投影法(SPA)
连续投影算法(successive projection salgorithm,SPA)是一种使矢量空间共线性最小化的前向变量选择算法。作为一种新兴的特征波长筛选方法,它能够有效消除波长变量之间共线性的影响,进而有效提取出特征波长变量[14]。对normalize 预处理后的样本光谱数据进行SPA 特征波长提取,如图3 所示。当特征波长数为14 时,RMSE 值为0.3274,且值达到最小;所提取的特征波长分别为:931.02、924.64、1399.29、1093.68、950.17、902.3、1380.21、1147.86、895.91、1345.23、1265.68、1332.5、1173.34、982.08 nm,其重要程度依次递减。

图3 特征波长分布图 Fig.3 Characteristic wavelength distribution map
2.3.2 回归系数法(RC)
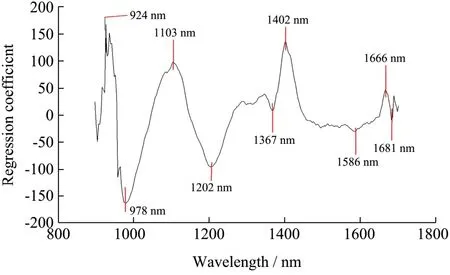
图4 RC 提取的特征波长 Fig.4 Key variables selection results of RC
回归系数法[15](RC):通过对预处理后的样本光谱数据建立PLS 判别模型,并从模型中提取回归系数。本研究选取了9 个特征波长值,分别为924、978、1103、1202、1367、1402、1586、1666、1681 nm,所依据的原则为:将局部极值作为特征波长值,如图5 所示。
2.3.3 竞争性自适应重加权算法(CARS)
竞争性自适应重加权算法基于达尔文生物进化论“适者生存”的法则,将蒙特卡罗采样与偏最小二乘回归系数相结合,以实现变量优选。在变量优选过程中,指数衰减函数决定变量剔除数量。变量剔除后,将保留的变量数据利用自适应重加权采样建立PLS 模型,比较模型的交叉验证均方根误差RMSECV 值,算出RMSECV 值最小时对应的PLS 模型,其对应的子集变量即CARS 方法优选出的特征变量[16],如图5 所示。由图5 可以看出,第32 次采样所得RESECV 最小,因此第32 次采样保留的变量为所提取的特征波长,分别为:18、20、65、67、78、79、81、157、158、159、163、230 nm。
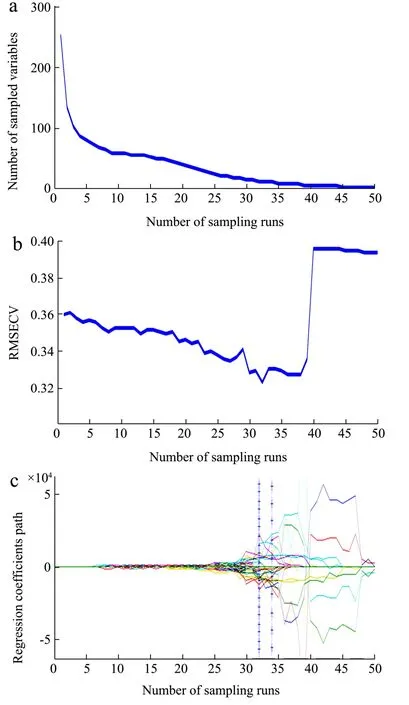
图5 CARS 关键变量选择 Fig.5 Key variables selection results of CARS
2.4 基于特征波长的判别模型建立及性能比较
对3 类样本各假定一个值作为判别缺陷类型的依据,将完好样本赋值为1,木栓化样本赋值为2,烂果样本赋值为3。基于上述3 种特征波长优选方法,分别以SPA 算法提取的14 个特征波长、RC 提取的9 个特征波长以及CARS 提取的12 个最优变量和类别值作为输入,建立偏最小二乘法(PLS)和多元线性回归(MLR)模型对预测集进行识别分类,如图6 和图7。由图可以知道,模型预测结果数值非整数,因此将最大偏离值设定为0.5,即预测值与假定值之差的绝对值在0~0.5 范围内时,则将其认定为此类样本,否则为误判。

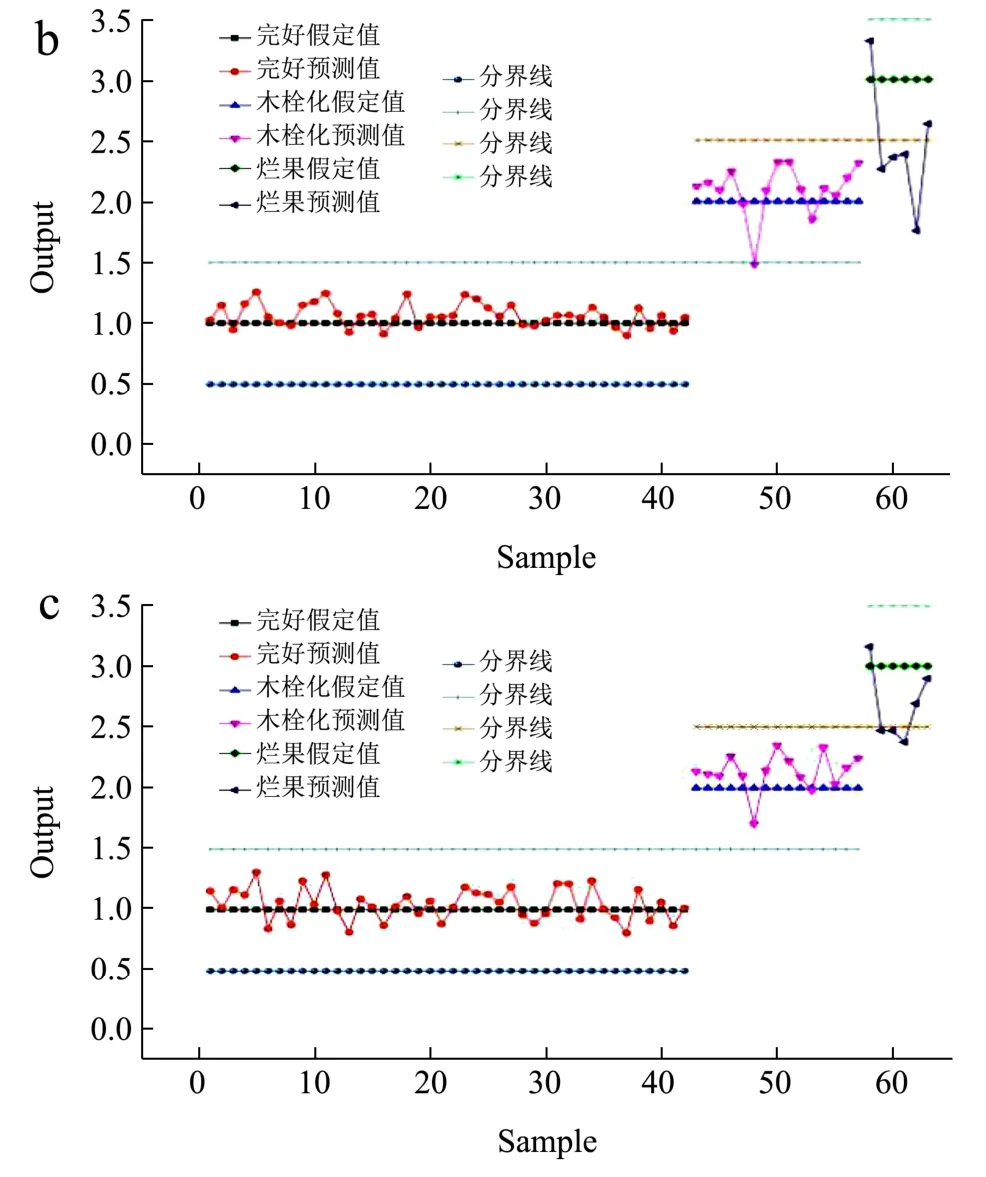
图6 PLS 模型预测集鉴别结果 Fig.6 Prediction set of discrimination results of PLS model
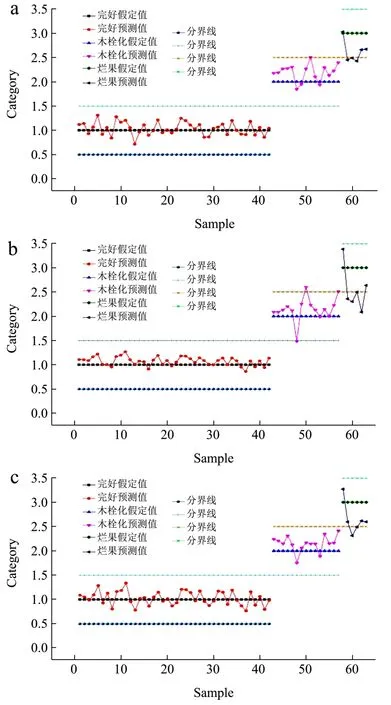
图7 MLR 模型预测集判别结果 Fig.7 Prediction set of discrimination results of MLR model
表2 列出了以3 种特征波长提取方法所优选的变量和类别值作为输入时,PLS 模型和MLR 模型对茄子完好、木栓化和烂果的判别结果。由表2 可得,CARS提取的12 个最优变量能更好地代替原始光谱信息,原因是SPA 算法和RC 在提取特征变量时,虽然降低了原始波长的冗余度,但是同时也剔除了部分有用的信息。因此,基于CARS 提取的特征波长所建立的预测模型效果最好。比较模型对样本的预测性能及参数可得,CARS-MLR 模型的预测精度最高,其Rc2值为0.94,Rp2值为0.90,相比于其他模型,Rc2和Rp2值较优,同时RMSEC 和RMSEP 值都相对较小,分别为0.19 和0.21;比较模型对预测集样本判别的准确率,CARS-MLR 模型的准确率最高,为96.82%,其次为CARS-PLS(95.24%),RC-MLR 模型判别准确率最低,为88.89%。综合判别模型的决定系数R2、均方根误差RMSE 以及预测集判别准确率三大指标,认为CARS-MLR 模型对茄子外部缺陷的鉴别分类效果最优。

表2 PLS 预测模型与MLR 预测模型性能比较 Table 2 Performance comparison of PLS and MLR models
3 结论
3.1 基于高光谱技术采集茄子样本的高光谱数据。比较原始光谱数据和经过多种预处理方法预处理后建立PLS 模型,结果表明,经Normalize 预处理后的PLS判别模型效果最佳,其校正集决定系数Rc2为0.74,均方根误差RMSEC 为0.33;其预测集决定系数Rp2为0.85,均方根误差RMSEP 为0.26。
3.2 采用SPA、RC 和CARS 分别对Normalize 预处理后的光谱数据提取特征波长,基于特征波长分别建立PLS 和MLR 模型。比较多种模型可知,CARS-MLR模型效果最优,其校正集决定系数Rc2为0.94,预测集决定系数Rp2为0.90,RMSEC和RMSEP分别为0.19和0.21,预测集判别准确率达到96.82%,较好地实现了茄子外部缺陷的检测。
猜你喜欢
特产研究(2022年6期)2023-01-17 05:06:16
今日农业(2021年20期)2021-11-26 01:23:56
今日农业(2021年13期)2021-08-14 01:38:14
阅读与作文(小学高年级版)(2019年9期)2019-11-06 07:12:05
幸福家庭(2019年14期)2019-01-14 05:14:57
大灰狼(2018年9期)2018-10-25 20:56:42
实用口腔医学杂志(2017年6期)2017-09-19 02:51:28
小天使·一年级语数英综合(2017年4期)2017-04-18 17:42:28
中国照明(2016年4期)2016-05-17 06:16:15
物理实验(2015年9期)2015-02-28 17:36:46
