
面向机器人路径规划的改进粒子群算法
2021-09-23 10:52:46封建湖张婷宇郑宝娟
机械设计与制造 2021年9期
封建湖,张婷宇,封 硕,郑宝娟
(1.长安大学理学院,陕西 西安710064;2.长安大学工程机械学院,陕西 西安710064)
1 引言
路径规划问题是在有复杂障碍物环境中搜索从初始点到目标点的无碰撞路径[1]。机器人的路径规划即对机器人行驶路径进行合理的决策。对于已知地图环境的情况,粒子群优化(PSO)算法是一种模拟鸟类飞行的优化算法,具有收敛速度快、算法易于实现等优点;遗传算法(GA)是基于生物种群进化的算法,具有全局收敛性的优势。然而这两种算法都有各自的局限性:粒子群算法容易陷入早熟、遗传算法收敛速度较慢等问题。针对这种情况,文献[2]提出了一种PSO和GA的混合算法,混合算法的初始种群由PSO生成,文献[3]人提出了一种只与GA突变算子结合的PSO算法,避免了粒子陷入局部最优。文献[4]在为旅客提供最佳路径选择的旅行商问题中提出PSO-GA算法,得到了很好的效果,但是会造成收敛代数大幅度增加。
针对算法中的不足,引入基于划分的聚类方法中的Kmeans算法,对粒子进行聚类,把粒子划分为若干个子群,使相当数量的具有较优适应度值的粒子位置信息传递到下一代粒子中。对每个子群采用一定规则的交叉和变异算子,从而提高粒子群算法的种群多样性。在每个子区内更新粒子速度和位置时,随着代数的增加改变惯性权重和加速系数。最后通过计算机仿真实验验证了该算法的有效性。
2 传统粒子群算法
粒子群算法是用位置、速度、适应度来描述粒子的运动特征,每次迭代通过跟踪粒子的个体极值Pbest和群体极值Gbest动态更新[5]。个体极值Pbest是粒子在迭代过程中得到的适应度值最优的个体所在位置,群体极值Gbest是搜索到所有粒子的适应度值最优个体所在位置。
传统粒子群算法通过以下公式在每次迭代过程中更新速度和位置:

式中:ω—惯性系数,j=1,2,…,n—维数,c1、c2—加速度因子,r1、r2—[0,1]区间的随机数。为了使粒子更好地搜索,通常将粒子的位置和速度限制在一定范围内[ -xmax,xmax]、[ -vmax,vmax]。
传统粒子群算法的劣势在路径规划问题中体现为:粒子群算法是全局随机搜索算法,但是如果缺少逃逸策略容易陷入局部最优解[6]。对于智能机器人,不仅需要尽可能缩短路径长度,更加需要在复杂环境中减少路径的起伏,使其平滑地走到终止点,避免局部最优的出现。
3 聚类融合交叉粒子群算法
3.1 环境建模
针对已知地图情况下的机器人路径规划问题,栅格法是由文献[7]于1968年提出。该方法将智能机器人实际运动环境分解成具有二值信息的网格单元,并通过判断障碍物是否占用此网格单元进行分类,处理后的路径规划问题就转化成在带有序号表示的栅格网中寻找两个网络节点的最优路径问题。
将已知地图栅格化,在栅格化的空间中分布着若干障碍物,0表示自由栅格,在图中用白色表示;1表示障碍栅格,在图中用黑色表示。
3.2 适应度函数的选择
在寻找最优路径时,要综合考虑路径的长短和是否成功避开障碍物。在实际的三维地图转换为二维栅格表示中,障碍物点可能是机器不能穿过的点,也可能是坡度较大、易损失能量的点。综合各种因素,改进的算法选择的适应度函数如下所示:

式中:N-路径段数,n-不可行的路径段数目,D-已走的路径总长度,通过公式(4)进行计算。


式中:(xs,ys),(xf,yf)—路径的起点坐标与终点坐标。
3.3 K均值聚类
为了保持目标粒子种群的多样性,引入K均值聚类算法。K均值聚类算法[8]是一种基于原型的目标函数聚类方法,将一批现实或抽象的数据对象分组成为多个类或簇的过程,是根据目标粒子的编码设计,定义目标粒子i与粒子j之间的距离的度量函数,改进后的算法采用基于初始聚类质心产生法。
在聚类融合交叉粒子群算法中,将初始种群N中的粒子根据K-means算法分为若干个子种群Ci,由每个子种群的最优粒子以及个体最优粒子的速度和位置信息指导下一代粒子更新进行速度和位置值:

式中,(i=1,2,…,N)—粒子i目前搜索到的最优个体位置,qi(i=1,2,…,K)—每个聚类区Ci(i=1,2,…,m)中的粒子搜索到的最优位置。
3.4 交叉操作
交叉算子是指以某种方式对两个染色体交换某部分基因,得到两个新的个体[9]。改进的具体思想是:
(1)交叉概率初始化。为了加快收敛速度,交叉概率初始化时采用在迭代过程中随代数线性递增的方式,记为Cross=(cross1,cross2,…,crossN),其中N为粒子数。算法中迭代次数t越大,粒子进行交叉操作的概率crosst也随之增大。
(2)判断是否交叉。对具有交叉可能性的粒子(i),随机产生一个数字randi与之对应,当随机数比交叉概率小时,即randi<crosst,则对粒子i进行交叉操作,进入步骤3;反之,则粒子i跳过交叉操作(步骤3),执行算法的下一步。
(3)交叉操作。若粒子i需要进行交叉操作时,在粒子路径点范围内,随机产生一个位置区间[xa,xb],把分区极值qi位置区间内的路径点覆盖在被粒子i相应位置区间内,执行算法的下一步。
假设粒子路径交叉区间是[3,4],则交叉过程,如表1所示。

表1 粒子交叉操作示例Tab.1 The Example of Crossover
3.5 变异操作
变异算子是指对染色体中的一部分进行突变,使其转化为一个新的个体[9]。相应的改进思路为:
(1)变异概率初始化。采用迭代过程中线性递减的方式定义变异概率,记为Var′=(var1′,var2′,…,varN′),算法中迭代次数t越大,粒子进行变异操作的概率vart′也随之减小。
(2)判断是否变异。对具有变异可能性的粒子i,随机产生一个数字randi与之对应,当随机数比交叉概率小时,即randi<vart′,则对粒子i进行变异操作,进入步骤3;反之,则粒子i跳过步骤3,执行算法的下一步。
(3)变异操作。当粒子i达到变异概率vart′时,随机选择粒子i的一个路径点(xc,yc),使新生成的路径点代替旧的路径点,继续算法的下一步。假设随机产生的变异路径点位置为3,则变异后的粒子,如表2所示。

表2 粒子变异操作示例Tab.2 The Example of Mutation.
3.6 自适应调整加速系数和惯性权重
在机器人路径规划过程中,早期希望机器人能有更多探索的能力,这样保持路径的多样性;在后期希望机器人根据走过的路径信息,有较多的自我学习能力,这样使路径能较快地收敛于全局最优解。为此,对传统的粒子群加速系数进行改进,具体为:
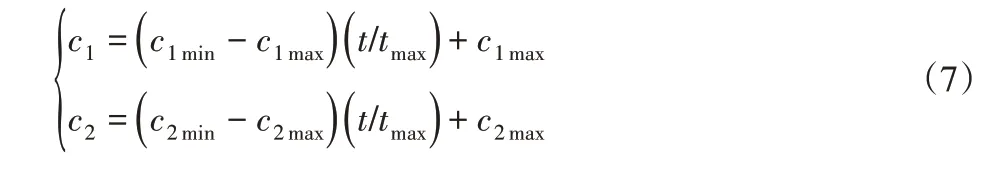
式中:c1max和c1min—加速系数c1的上下限。c2max和c2min—加速系数c2的上下限。tmax—迭代的最大次数,t—当前迭代次数。
3.7 聚类融合交叉粒子群算法流程图
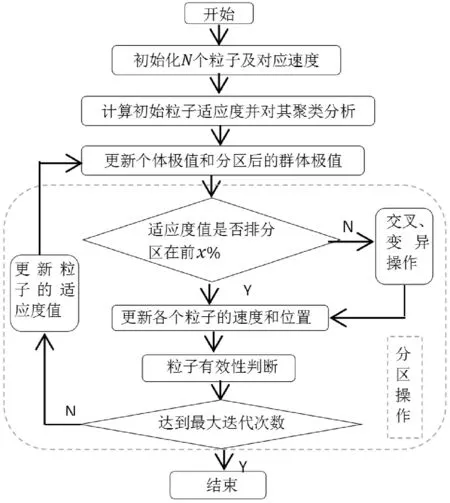
图1 聚类融合交叉粒子群算法流程图Fig.1 Process of Clustering Combined with Crossed PSO Algorithm
4 仿真及结果分析
在MATLAB上分别用传统粒子群算法、具有交叉、变异算子的粒子群算法和聚类融合交叉粒子群算法对虚拟轮式机器人进行了对比仿真实验。
首先对复杂地图初始栅格化,仿真过程中地图大小从10×10逐步扩充到40×40,起始点定为(1,1),终止点为相应矩阵的对角点,并随机生成一定比例的障碍物。
随着栅格地图的规模扩大,收敛代数和粒子数量都需要以一定比例增长才可以得到较为理想的路线。为了更好展示不同粒子群算法的应用效果,以40×40的路径规划效果为例说明。实验中参数设置,如表3所示。

表3 路径规划参数表Tab.3 Parameter Setting for Path Planning
为了更加直观看出算法的优势,将算法运行50次效果,比较,如表4所示。
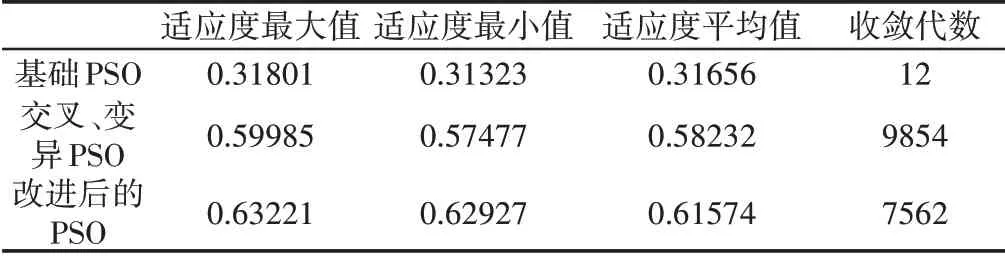
表4 算法运行50次仿真结果Tab.4 The Simulation Result for Three Algorithms Run Fifty Times
根据适应度公式(3)可以得到,适应度值越大,路径长度越小,路径表现越优秀。在栅格地图较大、环境较为复杂的情况下,当总的迭代次数和粒子数目一定时,交叉粒子群算法比传统粒子群算法的最优路径长度缩短约16.3%,其中传统粒子群算法收敛过快,容易陷入早熟;交叉粒子群则有效避免了早熟现象,从而减少了产生局部最优路径的可能性,但是交叉粒子群算法比基础粒子群的每一代迭代时间多了约64.8%,收敛代数增加了约90.8%,计算成本较高。聚类融合交叉粒子群是在交叉粒子群的基础上,加了K-means聚类分析算法,比交叉粒子群算法收敛代数减少约23.8%。在保证相对最短路径的情况下,跳出局部最优有很好的效果,同时程序运行过程中,聚类融合交叉粒子群中的分区操作,虽然使存储空间有少许增加,却大大减小了收敛代数,加快了收敛速度,且每一代的运行时间与交叉粒子群相差细微,最终得到最优路径的总时间减少约45.9%,可以看出改进后的算法对点到点的机器人路径规划具有较好的应用价值。
从上述比较效果来看,本文改进后的算法搜索结果在精度上有明显的提高。算法在迭代的开始对初始群体按照K-means聚类法分成若干个子群体,从而在迭代过程中每个粒子根据其个体极值和所在子种群中的最好个体更新自己的位置和速度,增加粒子的信息交换,有助于引导算法向可行路径方向搜索。为了克服传统算法在后期易于陷入局部最优的缺陷,引入交叉、变异算子,帮助算法摆脱局部极值点的束缚,极大地提高了算法的搜索效率,有效地实现了全局搜索能力及收敛速度方面的平衡。
下面将更加直观地给出采用传统粒子群算法、带有交叉、变异算子的粒子群算法和聚类融合交叉粒子群算法的最优路径图,从起始点到目标点单独执行10000代得到的路径中,长度最短即适应度值最大的一次规划路径图,如图2所示。

图2 三种算法的路径图Fig.2 Path Map of Three Algorithms
从上图中容易看出,图2(a)传统粒子群优化算法在相同迭代次数下走出的路径效果最差,虽然找出一条不和障碍物重叠的路线,但是粒子路线跳跃起伏较大,使机器人耗能随之增大,明显是一条局部最优路径。图2(b)是在传统粒子群中加入交叉、变异算子后的结果,可以看出减少了一些冗余路线,效果虽然有所改进,但是耗费时间长,一些区域还存在可以优化的可能性。而在交叉粒子群的基础上加入K-means聚类分析的改进算法,图2(c)得到的最优路径精度相对较高,在相同运行代数下,路径长度明显最短,路线较为顺滑,相对而言降低了拐点数和无效路径段,实际过程中可以达到减少能量消耗、机器损耗的效果。
为了更直观看出加入聚类算法的优势,对交叉粒子群算法和聚类融合交叉粒子群算法收敛情况进行比较(参数设置:粒子数为3000,迭代次数为10000,聚类数为10),如图3所示。

图3 两种算法收敛情况对比图Fig.3 Comparison of the Convergence Curve
对比结果可以看出,加入K-means聚类分析算法,能够使收敛代数稳定下降,加快收敛速度,使得获得最优路径的总计算时间也大大缩短,对于智能路径寻优有很好的效果。
虽然加入聚类的思想可以明显达到加速收敛速度的效果,但是聚类的数目不同,产生的效果也不完全相同。选取5000粒子,10000代,在相同环境下对以下聚类数目进行对比实验,对比结果,如表5所示。

表5 聚类效果对比Tab.5 Clustering’s Comparison of Effects
如果初始化参数时选择的聚类数目过多,会导致这些群体极值中保留很多适应度值适中甚至偏差的粒子信息,将直接影响下一代的优化结果,最终导致形成的最优路径趋于局部最优的结果。在仿真实验中,我们可以根据栅格地图的复杂度,选择适中的分区数目,在加快收敛速度的同时选择相对运算成本较小、路径长度较优的参数设置。
5 结论
在机器人路径规划虚拟仿真过程中,通过引入聚类分析的思想和遗传算法中的交叉、变异算子到传统粒子群算法中,避免了粒子群算法在复杂环境下容易出现停滞现象,最终出现局部最优的结果,有效的帮助机器人找到最优路径。通过对比仿真实验可以看出,改进后的算法有以下三个优点:
(1)加入交叉、变异算子,增加了粒子多样性。
(2)引入复杂环境下适合的聚类数目,可以加快算法收敛速度。
(3)在路径规划的应用中,改进后的算法搜索出的路径明显优于传统粒子群算法和交叉粒子群算法。
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
科技创新与应用(2021年31期)2021-11-09 13:11:18
数学物理学报(2021年2期)2021-06-09 08:54:26
应用数学(2020年2期)2020-06-24 06:02:44
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:54
数学物理学报(2016年3期)2016-12-01 05:36:27
中国塑料(2016年11期)2016-04-16 05:26:02
弹箭与制导学报(2015年1期)2015-03-11 15:32:23
雷达学报(2014年4期)2014-04-23 07:43:13
教育与职业(2014年16期)2014-01-19 01:24:36
