
一种基于日志相似度的轨迹聚类评估方法
2021-09-23 01:13:26
山东科技大学学报(自然科学版) 2021年5期
(山东理工大学 计算机科学与技术学院,山东 淄博 255000)
过程挖掘[1-3]旨在从事件日志中提取关于业务过程的有效信息,从而发现、监控和改进实际过程。事件日志对应于业务过程的一系列过程实例,过程实例表现为轨迹(轨迹被定义为过程实例从开始执行到结束所调用的活动有序列表)。现实生活中的过程往往更灵活、非结构化,传统的过程挖掘算法在处理这种非结构化过程时存在生成难以理解的过程模型(即意大利面模型)等问题,解决这一问题的有效方法之一是对事件日志中的轨迹进行聚类,使得聚类后的子日志对应的过程模型组合能够清晰完整地表达原始事件日志中的行为,减少类似意大利面过程模型出现的概率,进而更直观地理解过程模型。
轨迹聚类的基本原则是根据定义的轨迹之间相似或相异概念,将事件日志划分为K个(一般K≥2)聚类子日志,使得子日志中的所有轨迹的行为(如活动、直接跟随活动关系等)是相似的,属于不同子日志的轨迹是不相似的。有不同的评价指标来评价轨迹聚类的效果,文献[4]从传统数据挖掘的角度使用聚类熵和分离率等指标评价聚类质量;文献[5]使用加权拟合度值评价聚类的好坏,采用XOR、Joins/Splits等控制流的数量评估过程模型的复杂性;文献[6]通过计算过程模型的总体精度以及单个过程实例的拟合度进行实验评估。从过程挖掘的角度来看,最常用的聚类评估指标是基于拟合度[7]和准确度[8]的综合指标F-Measure[9]。不同的轨迹聚类方法所用的评价指标不尽相同,目前尚未有一个明确统一的标准。本研究提出一种新的基于日志相似度轨迹聚类评估方法,并与使用已有的轨迹聚类方法在真实事件日志上与传统评估指标F-Measure进行对比实验,来验证新的聚类评估指标的可行性和高效性。
1 相关工作
本节首先介绍已有的轨迹聚类方法,如基于向量空间方法的聚类、基于上下文感知的聚类、基于模型的序列聚类等,然后从传统数据挖掘角度和过程挖掘角度概述轨迹聚类质量评估指标,最后指出已有指标存在的问题并提出一种新的轨迹聚类评估方法。
1.1 轨迹聚类方法
目前已有多种轨迹聚类方法,大多数是在数据挖掘等领域中相关聚类方法的基础上,将事件日志进行一系列的转换处理,然后利用现有的聚类算法进行聚类。例如,将事件日志转换成向量空间模型,在每对轨迹之间定义距离度量,应用传统聚类算法进行轨迹聚类;也有考虑了上下文感知方式对轨迹聚类技术进行扩展的方法;而基于模型的序列聚类技术也适用于轨迹聚类。
1) 向量空间方法。Greco等[10]是过程挖掘领域中研究事件日志轨迹聚类的先驱,使用包含活动的向量空间方法聚类事件日志中的轨迹,在聚类后的子日志中使用分离工作流模式来发现更简单的过程模型。Song等[11]提出了为事件日志中的轨迹构建向量空间模型的方法,该方法基于一组配置文件,每个配置文件从一个特定的角度测量每个轨迹的多个特征,比如活动、直接跟随活动关系、活动组织者等,这些特征组成相应的特征矩阵;基于特征矩阵,应用多个距离度量(欧式距离、汉明距离等)计算事件日志中任意两个轨迹之间的距离;应用数据挖掘中传统的聚类算法,如K-Means聚类、凝聚层次聚类等,将事件日志中的轨迹分组成子日志,这些子日志可以独立地进行分析,从而使环境更灵活,显著提高过程挖掘的质量。
2) 上下文感知的轨迹聚类。文献[5,12]中描述这一轨迹聚类技术,通过改进考虑控制流上下文感知的方式扩展了之前的轨迹聚类方法。此处的上下文感知指的是事件日志中轨迹的控制流属性,而不是上下文信息,如组织者、案例数据等。文献[5]提出了一种通用编辑距离技术,其中的编辑操作包括插入、删除或替换。文献[12]进一步发展了上下文感知轨迹聚类的思想,重新考虑了为事件日志中的轨迹生成向量空间模型这一思想,使用保守模式或子序列代替之前的活动作为向量空间模型的基础。以这种方式,定义了极大、超极大和接近超极大重复的概念来创建确定某一轨迹向量的特征集。本研究中对应的轨迹聚类方法是Guide Miner Tree。
3) 基于模型的序列聚类。受到Cadez等[14]在Web使用挖掘领域的工作启发,Ferreira等[13]提出一种完全不同的轨迹聚类方法,通过使用期望最大化(expectation maximization,EM)算法学习混合一阶马尔可夫模型聚类轨迹。文献[15]将这种基于模型的轨迹聚类技术应用到服务器日志中,证明了其在现实生活中的可用性。文献[6]提出在给定数量的集群上执行轨迹寻找最优分布的问题,从而最大化关联过程模型的组合精度;改变了传统轨迹聚类的目标,即通过将相似轨迹分在一组来寻找最优轨迹分布,提出一种自上而下的贪婪算法,通过对轨迹进行分组来计算,轨迹选择的标准不是基于相似的行为,而是因其很好地适合特定的过程模型。在本研究中对应的轨迹聚类方法是ActiTrac。
1.2 轨迹聚类质量评估指标
1) 数据挖掘角度。文献[4]从数据挖掘的角度使用聚类熵和分离率作为评价聚类效果的指标。但此轨迹聚类质量度量有一个缺点,即如果事先不了解一些预先信息,如划分几个类以及哪些轨迹属于哪个类等,那么此质量评估指标是不可行的。如果有预先的信息可用,则可以使用纯度、聚类熵等传统聚类评估指标量化某项技术区分不同类别行为的能力。
2) 过程挖掘角度。从过程挖掘角度的量化轨迹聚类质量有很多的评估指标。文献[5]中使用了加权拟合度值作为轨迹聚类评估指标,使用XOR、Joins/Splits等控制流结构数量描述过程模型的复杂性;文献[6]通过计算过程模型的总体精度以及单个过程实例的拟合度对聚类后的过程模型进行评估。
1.3 现存挑战
在传统的数据挖掘领域,通常使用纯度、聚类熵等聚类指标衡量一个轨迹聚类方法的质量,在过程挖掘领域则使用基于拟合度、精确度的综合指标F-Measure衡量轨迹聚类效果。然而,这些方法在进行实验评估时往往需要花费大量的时间,评估效率低下,而且评估过程复杂繁琐,不具有简洁性和高效性。因此,本研究提出一种基于日志相似度的轨迹聚类评估方法,能确保评估实验结果正确的前提下,极大地提高评估效率,为量化轨迹聚类方法的质量提供一种新的评估标准。
2 基于日志相似度的轨迹聚类评估方法
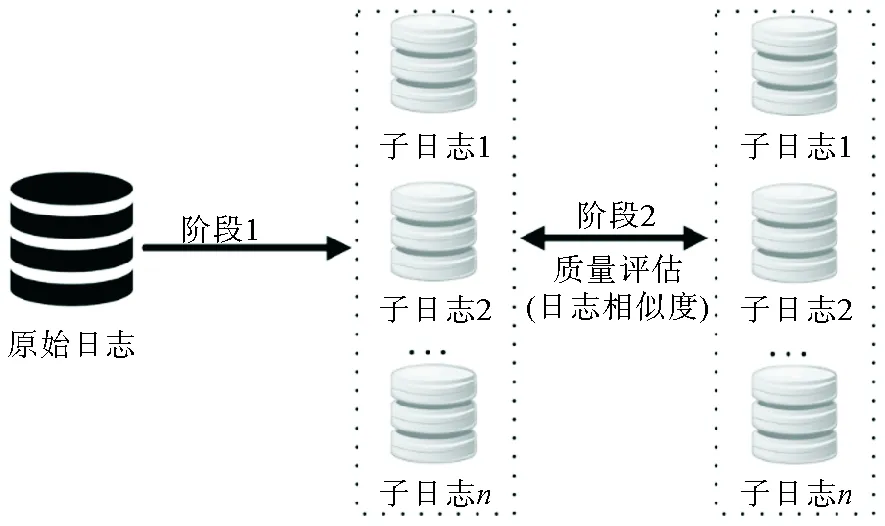
图2 基于日志相似度的轨迹聚类评估框架
传统的轨迹聚类评估技术框架分为两个阶段,如图1所示。第1阶段通过已有的轨迹聚类技术将原始日志进行聚类,生成几个子日志;第2阶段将这几个子日志分别通过同一过程挖掘算法得到的过程模型与原始日志做质量评估,由F-Measure指标进行量化。
本研究提出一种基于日志相似度的轨迹聚类评估方法,相应的评估框架见图2,包含两个阶段:①轨迹聚类。首先采用已有的轨迹聚类方法如K-Means聚类、凝聚层次聚类等,对原始日志进行聚类处理后得到几个子日志,使得属于同一子日志中的轨迹是相似的,属于不同子日志的轨迹是相异的。该阶段需要预先设定参数比如聚类的个数等,而参数设置不同会影响最终的评估质量;②质量评估。一般来说,好的聚类效果是日志内相似、日志间相异。根据这一思想,两两比较子日志的相似度来说明轨迹聚类的效果,将平均相似度值作为评估轨迹聚类的结果。两个子日志之间的相似度越高,说明两个日志中的行为(如活动,直接跟随活动关系等)重合度越高,表明此轨迹聚类方法得到的结果越差;两个日志之间的相似度越小,说明两个日志中存在较大差异性,表明此轨迹聚类方法的效果就越好。
本节介绍两种测量日志相似度的方法:余弦相似度和EMD相似度,通过这两种日志相似度的度量来评价轨迹聚类方法得到的日志质量。
2.1 余弦相似度
余弦相似度[16]通过计算事件日志对应矩阵展开行向量的夹角余弦值来计算相似度。在此过程中,将两个事件日志对应的矩阵表示为行向量的形式,通过一一比较对应行向量的余弦相似度,再对其求平均值,得到的最终相似度即为两日志的相似度。余弦相似度表示为
(1)
其中,X、Y分别为两日志生成矩阵对应的行向量。两个日志对应的生成矩阵的余弦相似度越小,说明两个日志的相似程度越接近,得到的样本日志的质量就越好。余弦相似度的取值在0到1之间。
2.2 EMD相似度
EMD(earth movers′ distance)[17]是一种在特定区域两个概率分布距离的度量。通俗来讲,如果两个分布被看作是在特定区域上两种不同方式堆积一定数量的土堆,那么EMD就是把一堆变成另一堆所需要移动单位的最小距离之和。
首先引入重新分配函数的概念来说明一种随机语言如何转化为另一种随机语言,再引入一个距离函数来表达将一个轨迹转换成另一个轨迹的代价,然后引入一个代价函数来表达一个特定的再分配函数的代价,最后定义EMD的随机一致性度量。
重新分配函数表示概率质量在两种随机语言之间的运动。设L和M是随机语言,一个重新分配函数r:L×M→[0,1]描述了L如何转化为M,即r(t,t′)描述了t∈L转移到t′∈M的概率。
为了确保重新分配函数正确地将L转换为M,应该考虑每个t∈L的概率质量。因此,t的行之和等于L(t),即有
(2)
同样,轨迹t′∈M的质量也要保留:
(3)
将符合式(2)和(3)的所有重新分配函数的集合称为R(注意,R取决于L和M)。
例如,考虑随机语言Le=[〈a〉0.25,〈a,a〉0.75]和Me=[〈a〉0.5,〈a,a〉0.25,〈a,a,a〉0.125,〈a,a,a,a〉0.0625,…]。重新分配函数re的一个例子如表1所示。

表1 重新分配函数reTab. 1 Reallocation function re
表1中,式(2)规定每行的总和应该等于随机语言Le中的相应值(例如,第1行的总和等于1/4,即Le(〈a〉)=1/4)。类似地,式(3)表示每一列应该加起来是Me中对应的概率质量。
距离函数d表示轨迹之间的距离,这里使用的是编辑距离[5]。
例如,考虑上述随机语言Le和Me,标准化编辑距离函数dl如表2所示。
代价函数。给定两种随机语言,可能存在多种重新分配函数,EMD为两种随机语言之间的最短距离,即在轨迹之间的最小距离上以最小概率质量运动。使用重新分配函数r将随机语言L转换为随机语言M的代价是重新分配函数和距离函数的内积,代价函数的计算公式为:
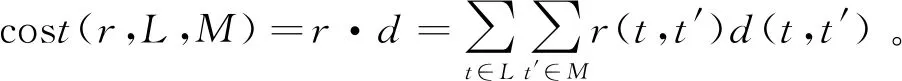
(4)

表2 标准化编辑距离函数dlTab. 2 The normalised Levenshtein distance function dl
例如,考虑上述随机语言Le和Me,成本函数为
(5)
EMD的随机一致性即EMSC。给定L和M,EMSC被定义为任何重新分配函数r的最低代价,即:

(6)
EMSC的值为1表示完美一致性,0表示最差一致性。
在例子中,re是最优的重新分配函数,因此EMSC(Le,Me) ≈0.761 294。
值得注意的是,重新分配函数可能存在多种,要确定一个最优的重新分配函数可以通过线性规划来实现。为了找到具有最低代价的最优分配函数,选择式(4)作为目标函数,约束通过式(2)和式(3)来确定。比如,考虑上述随机语言Le和Me,线性规划的问题构造如下:
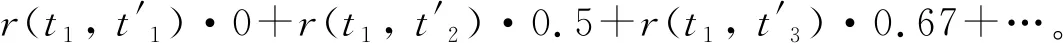
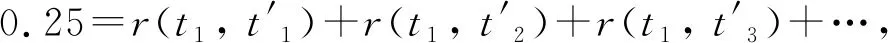
…
…
可以用上述EMD相似度的方法量化两个事件日志的相似程度,EMD越大,说明两日志的相似程度越高。
3 实验分析
首先介绍实验环境和实验日志的基本信息,然后对不同的聚类方法在不同的聚类个数下得到的聚类子日志进行质量评估,对比传统指标F-Measure和日志相似度指标的趋势,说明本研究提出指标的可行性;对比两个指标的评估时间说明日志相似度指标的高效性。
3.1 实验设置及数据集
实验均基于PC Intel Core i5-4210M 2.60GHz CPU,12GB RAM环境,使用Java语言实现,详细代码见https://svn.win.tue.nl/repos/prom/Packages/ShandongPM。使用4个真实事件日志对所提出的日志相似度的轨迹聚类评估方法进行实验评估,表4说明了这些事件日志的部分主要统计数据,所用的实验数据集链接见https://data.4tu.nl。
1) Sepsis数据集:来自医院的脓毒症病例事件,每1条轨迹代表1个脓毒症患者的治疗过程;
2) Helpdesk数据集:来自意大利软件公司服务台票务管理过程,每1条轨迹代表1个票证的处理过程;
3) BPI2012_O数据集:源自荷兰1家金融机构的个人贷款申请过程,每1条轨迹描述了不同客户申请个人贷款的过程;
4) BPI2015_3数据集:由荷兰城市市政当局提供的所有建筑许可证申请,期限约为4年,选取了其中一部分数据进行处理。
3.2 实验结果分析
从评估指标结果和评估效率两方面出发,在实验数据集上将传统指标F-Measure与本研究提出的日志相似度指标(余弦相似度和EMD相似度)进行对比,说明基于日志相似度评估指标的可行性和高效性。
测量传统评估指标F-Measure的具体做法如下:先通过轨迹聚类方法(选择的是ActiTrac聚类和Guide

表3 实验日志概述
Miner Tree聚类)将原始实验日志在不同的聚类个数(此处用K表示,取值为3,4,5,6)下进行聚类得到几个子日志,然后将每个子日志通过过程挖掘算法(选择的是Inductive Miner[18]算法)生成过程模型,再将每个过程模型与原始实验日志做合规性检查,得到基于拟合度、准确度的综合指标F-Measure,最后将得到的各个F-Measure平均后的结果作为此轨迹聚类方法在选定K值上的传统评估指标量化值。
F-measure值被定义为拟合度和精确度的调和平均值,具体计算公式为:
(7)
其中:fitness(L,M)为从样本日志中发现的过程模型相对于原始日志的拟合度,表示量化过程模型再现事件日志中记录轨迹的准确程度和记录轨迹的能力,值为1表示过程模型可以重新生成事件日志中的所有轨迹,低拟合度表明事件日志中的大部分行为不能被过程模型重演;precision(L,M)为从样本日志中发现的过程模型相对于原始日志的精确度,量化在过程模型中能够重演但在事件日志中看不到的部分行为和生成事件日志中记录轨迹的能力,值为1表示过程模型生成的所有轨迹都包含在事件日志中,低精确度意味着过程模型允许事件日志外更多的行为。
基于日志相似度的评估方法过程如下:先通过轨迹聚类算法(同上)将原始实验日志在不同的聚类个数(同上)下进行轨迹聚类得到聚类后的子日志,然后将子日志通过基于日志相似度评估方法(本次实验选择为余弦相似度和EMD相似度)两两计算相似度,最后将各个相似度平均后结果作为此聚类算法在选定K值上的日志相似度评估指标量化值。
3.2.1 评估指标对比
好的聚类结果标准是日志内相似,日志间相异,故两两日志之间的相似程度越低,说明聚类的效果越好;F-Measure越高,说明聚类的效果越好。由此可见,日志相似度指标与传统指标F-Measure呈负相关。在4个数据集上的实验结果如图3所示。
由图3可见,传统指标F-Measure值与基于日志相似度的两个指标(余弦相似度和EMD相似度)呈负相关关系。以Sepsis日志(聚类方法为ActiTrac)为例,在不同的聚类个数设置下,随着聚类个数的增大,F-Measure值逐渐降低,而基于日志相似度的指标(余弦相似度和EMD相似度)逐渐升高,两者呈现出相反的趋势,这与之前分析的结论是一致的。因此,本研究提出的日志相似度评估指标适用于轨迹聚类方法评估,完全可以代替传统评估指标进行评估测量。
值得注意的是,本研究的余弦相似度、EMD相似度这两个指标在不同的日志中有所差异,比如在BPI2015_3日志、ActiTrac聚类中,随着聚类个数的增加,余弦相似度值的范围在0.1~0.2,EMD相似度值的范围在0.25~0.4;而在Guide Miner Tree聚类中,余弦相似度值与EMD相似度值的范围在0.15~0.3,相差不大。由此可以看出,两个相似度指标之间可能存在差异,这是由于不同指标间的计算方式不同引起的,但两者总是表现出与传统指标F-Measure相反的趋势。
3.2.2 时间性能对比
图4为本文传统评估指标与基于日志相似度评估指标的时间对比图。对于传统的F-Measure指标,测量时间包括样本日志通过挖掘算法生成过程模型的时间及过程模型与原始事件日志的拟合度、精确度的综合指标F-Measure的评估时间;对于基于日志相似度的评估方法,计算聚类子日志之间日志相似度度量时间。
由图4可以看出,在真实事件日志上,基于日志相似度的评估指标所用时间远远小于传统评估指标F-Measure,说明基于日志相似度的评估指标具有高效性。以Helpdesk日志(聚类方法为ActiTrac,聚类个数为6)为例,传统评估指标F-Measure值所用时间为4 179 ms,而余弦相似度评估指标仅花费了56 ms,在时间性能上提升了80倍,EMD相似度用时127 ms,相比于F-Measure指标提升了33倍。由此可见,基于日志相似度的评估方法能有效地缩短日志评估所用的时间,提高了评估效率。

图3 评估指标对比

图4 评估时间对比
4 结论
本研究提供了一种基于日志相似度的轨迹聚类评估方法,为衡量轨迹聚类方法提供了一种新的评估指标,相比于传统的聚类评估指标,该评估指标在保证聚类评估结果正确性的同时,可以更高效地对聚类子日志进行实验评估。
未来可以从如下3方面继续深入研究:将基于日志相似度的轨迹聚类评估方法应用到专门领域(如医疗、物流、制造业等)的事件日志;尝试更多的轨迹聚类方法与评估指标对比基于日志相似度轨迹聚类评估方法的鲁棒性;除余弦相似度和EMD相似度等日志相似度指标外,探究更多的日志相似度评估指标。
猜你喜欢
华人时刊(2021年13期)2021-11-27 09:19:02
心声歌刊(2020年4期)2020-09-07 06:37:14
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
现代装饰(2018年5期)2018-05-26 09:09:39
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
中国三峡(2017年2期)2017-06-09 08:15:29
中学数学杂志(高中版)(2016年6期)2017-03-01 18:53:58
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:40
职业技术(2015年8期)2016-01-05 12:16:46
