
基于GPU的并行置信传播算法优化加速研究
2021-09-06 05:39:58孙诗慧侯骏腾王海平
现代计算机 2021年22期
孙诗慧,侯骏腾,王海平
(1.中国电子科技集团第十五研究所,北京100083;2.中国科学院信息工程研究所,北京100093)
0 引言
置信传播(Belief Propagation,BP)算法是一种在概率图模型上完成推断的信息传递算法,其广泛应用于数据为图结构的应用领域,例如:图神经网络、知识图谱、5G编码中的极化码[1]与低密度奇偶校验编码[2]等。随着数据获取与存储技术的不断发展,需要处理的数据规模越来越大,单纯使用CPU处理相应的算法已经无法满足快速实时的计算需求。具有几千甚至几万个线程的GPU设备为算法的优化加速提供了重要的条件,GPU的单指令多线程(Single Instruction Multiple Threads,SIMT)执行模式可以对大量数据同时执行相同的操作,从而提升了算法的计算效率。但是研究表明,在置信传播算法的计算中,对全部未收敛信息同时进行更新不能保证算法达到最高的计算效率[3]。因为置信传播算法通过周围边上的信息计算当前顶点的信息,如果周围的信息均没有达到收敛状态,则当前信息的计算也是不准确的,从而造成大量的冗余计算。并且这些未收敛信息的相互影响导致算法最终的收敛度也不高。
本文针对以上问题,提出了一种结合分区提取与随机减少的GPU环境下的置信传播算法。首先通过快速分区的方式将整个图数据分成若干个分区;然后选取每个分区中残差最大的信息进行更新,这样可以保证每次迭代计算使用较少的时间对全局残差较大的信息进行更新;最后,通过逐渐降低所选分区的数目保证算法的收敛度逐步上升。
1 相关工作
在早期的研究中,主要在CPU上进行串行的置信传播算法的计算。串行算法每次只能更新一条信息,对于大量未收敛的信息,每次迭代计算对残差最大的信息进行更新可有效提升算法的计算效率[4]。随着并行计算设备计算能力的提升,并行置信传播算法的性能优势逐渐突显出来。Loopy BP(LBP)是一种最简单的并行置信传播算法,其直接对所有的未收敛的信息进行更新[5]。Joseph等人指出所有未收敛信息的同时更新无法保证算法性能达到最优[3],并提出了Residual Splash(RS)算法,其通过选取多个全局信息残差最大的顶点,并以此顶点为中心进行确定顺序的置信传播计算,显著提升了算法的计算性能。但是这一算法只适用于多核CPU,其中的排序操作在GPU设备上的计算非常耗时。Mark等人通过两次过滤操作随机筛选中部分未收敛的信息进行更新,提出了专门针对GPU的随机置信传播算法(Random Belief Propagation,RnBP)。虽然排序操作不适用于GPU,但是侯骏腾等人提出了ColorWave算法[6],与Residual Splash(RS)算法具有同样的信息更新顺序。该算法通过着色操作检测出多个分区,将每个分区中着色操作的中心点作为置信传播计算的中心点,并以此为中心在每个分区中进行固定顺序的信息更新操作,使图数据中的大多数信息在短时间内快速收敛。另外,为了提升置信传播算法每次迭代的计算效率和算法最终的收敛度,侯骏腾等人还提出了ColorExtract算法与RandomDrop算法。
在基于GPU的各类并行置信传播算法中,虽然相比于直接对所有未收敛信息进行更新的LBP算法,后来的算法在收敛度与收敛速度上有了很大的提升,但是算法中仍然存在很多的冗余计算,并且各类算法在置信传播算法的不同计算阶段中计算效率差异较大。本文算法充分考虑了不同计算阶段中置信传播算法的计算特征。在算法的最初阶段,图数据中大多数信息处于未收敛的状态,通过分区提取的方式更新每个分区中残差最大的信息;随着迭代的进行,越来越多的信息达到收敛状态,并且未收敛的信息相互影响,导致算法整体的收敛度不高。我们通过逐渐降低所选分区数目的形式提升算法最终的收敛度。
2 算法实现
2.1 置信传播计算
置信传播计算在概率图上进行推断从而完成信息更新,马尔科夫随机场是一种典型的概率图,我们以马尔科夫随机场为例介绍置信传播计算。图1(a)是一个由5个顶点组成的马尔科夫随机场。以G(V,E)表示马尔科夫随机场对应的图结构,其中,V为顶点集,E为边集。每个顶点vi在标签集Xi中取一个标签xi。如图1(a)所示,对于某个确定的xi,其对应于一元势函数Ψi,变量之间的可能关系对于二元势函数Ψi,j,则马尔科夫随机场上X的联合分布如式(1)所示。
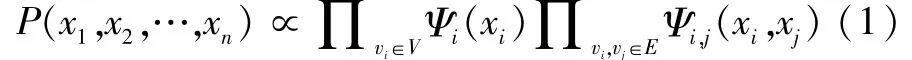
置信传播算法通过顶点间的信息更新来更新概率图模型的标记状态。如图1(b)所示,mi→j表示从顶点vi到顶点vj的信息。置信传播算法的最终目标是计算得到每个顶点的“置信度”。可以根据顶点vi取值的概率分布P(xi)得到当前顶点的“置信度”,计算公式如式(2)所示,其中信息值mi→j的计算如式(3)所示。在多个文献中[3-4,6-7],通常将前后两次信息残差的值小于一个预设的阈值作为判断算法信息收敛的条件。假设信息mi→j经过t次迭代计算后变为信息则其信息残差的计算如式(4)所示。本文中,我们采用相同的方式判断置信传播是否收敛。
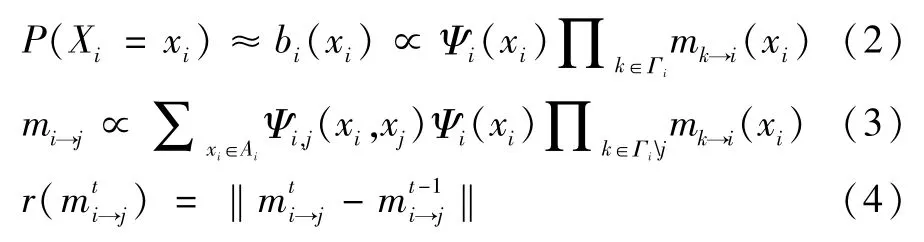
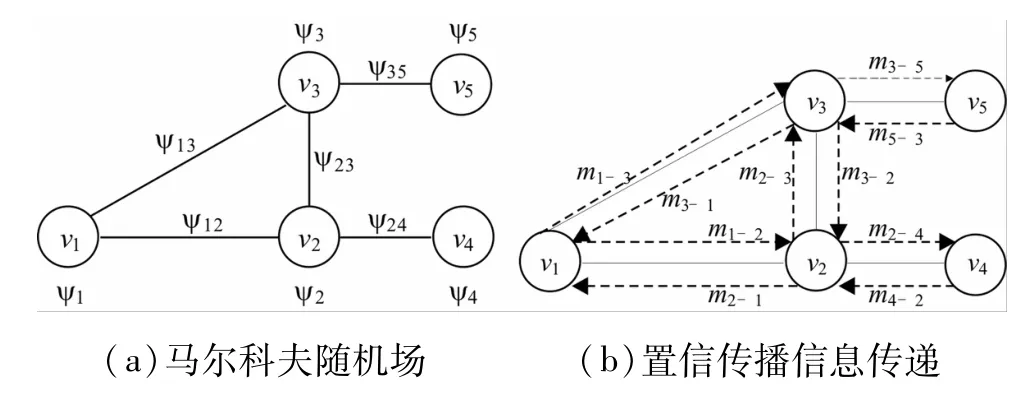
图1 置信传播计算示意图
2.2 算法整体过程
算法根据用户预设的参数对用户提供的概率图模型进行置信传播计算,具体流程如图2所示。首先加载需要处理的概率图数据与用户预设的参数,包括需要在多少次分区提取后再进行随机减少操作及每次迭代计算随机减少操作的比例。其次,进行信息残差的计算,由于是首次计算信息值,无法将前后两次信息的差作为作为信息残差,因此直接将当前计算所得的信息值作为信息残差。分区提取操作通过当前信息与周围信息残差的大小关系判断需要提取出需要更新的信息。随机减少操作根据当前迭代计算所处的计算阶段对需要更新的信息进一步过滤。通过以上的公式(3)对两次过滤后剩余的信息进行更新,然后通过公式(4)计算所有信息的残差。根据信息残差的变化情况判断算法是否已达到收敛状态;如果未达到收敛状态,则从分区提取操作开始继续进行迭代计算,如果已达到收敛状态,则停止迭代计算并通过公式(2)计算每个顶点的置信度。该算法中的分区提取策略可以使得算法在计算的开始阶段有较高的收敛速度,分区提取策略与随机减少策略的结合可以使用算法的收敛度逐步提升,并且使得算法在达到稳定状态时有较高的收敛度。

图2 置信传播算法流程
2.3 分区提取策略
依据文献[4]中的结论,在每次迭代计算中,相比于随机更新任意一个未收敛的信息,对残差最大的信息进行更新可以使算法具有更高的收敛速度。但是,在GPU设备中,对信息的残差进行排序的算法非常耗时,并且考虑到具有大规模并行处理架构的GPU设备可以同时对多个信息进行更新处理。本文提出了一种分区提取策略,该策略可以快速提取出当前信息及其邻接的所有信息中残差最大的信息,并且只对该信息进行更新处理。相比于对整个图数据中所有未收敛的信息同时进行更新处理的传统并行置信传播算法及每次只能更新一条信息的串行置信传播算法,信息分区提取策略具有以下两个优势:其一,可以对整个图数据中所有残差较大的信息进行更新,其中包含整个图数据中残差最大的信息,保证算法具有较快的收敛速度,并且减少了并行置信传播算法中的冗余计算;其二,如果当前信息及其邻接信息中存在未收敛的信息,则必然会在这几条信息中选择一条信息进行更新,这样在每次迭代计算时,有大量的信息参与更新操作,充分利用了GPU的大规模并行处理能力,提升了算法整体的计算量。
分区提取策略的并行处理操作过程为:①为每条信息分配一个线程,假设某个信息mi所在的边为<va,vb>;②将以下所有信息视为处于同一个分区中,并对比各信息的残差大小情况:信息mi、以顶点va为终点的边上的信息mx、以顶点vb为终点的边上的信息my;③将以上分区中残差最大的信息标记为“需要更新”,其余所有信息标记为“不需要更新”,如果所有信息均达到收敛状态,则均标记为“不需要更新”。
2.4 随机减少策略
在经过分区提取策略处理后,即能保证算法的收敛速度,又能对保证每次迭代中更新大量的信息。但是,随着迭代计算的进行,达到收敛状态的信息数目越来越多,算法的收敛速度逐渐下降,并且当算法中未达到收敛状态的信息数目稳定时,仍然有很多信息没有达到收敛状态。在文献[6]中,侯骏腾等人提出,通过逐渐降低信息更新比例的方式,可以进一步提高算法的收敛度。因此,本文在分区提取策略的基础上增加了随机减少策略,通过逐渐减少所选取的分区的数目的方式降低整个图数据中未达到收敛状态的信息的更新比例,使得达到稳定状态的置信传播算法有较高的收敛度。
随机减少策略的操作流程及操作目的为:①由用户预设三个阈值:分区提取策略操作步数n、随机减少策略减少率pr及信息最小更新率pl;②在算法的前n次处理中,只采用分区提取策略,不采用随机减少策略。在算法的初始阶段,大多数的信息均未达到收敛状态,因此每个分区中都会提取出一条信息进行更新操作,并且此时算法的收敛速度较高。所以,此时对所有未达到收敛状态的信息进行更新处理;然后根据随机减少策略减少率pr逐渐减少所选分区数目,即:在第i次迭代计算时,只对所提取信息中占比为pi的信息进行更新,则在第i+1次迭代计算时,需要更新的信息的占比为pi+1=pi-pr。随着迭代的进行,算法的收敛速度降低,通过随机减少策略可以提升算法收敛速度;最后,当信息更新比例pi降低为pl时,使pi=pl保持不变,这样做是为了在每次迭代计算时均有一定数量的信息进行更新。
3 实验结果
实验环境为:Intel Core i5-8300H CPU,8G运行内存与NVIDIA GeForce 1050Ti GPU,4G显卡内存。在CentOS 7.1操作系统下运行。编译器与优化设置为:CUDA Driver Version 10.0,NVCC version 7.5 with-O3 and-arch=sm_37,GCC 4.8.5-03。实验所用的概率图模型为Ising生成图数据,这是一个由二进制变量组成的1500×1500格式的网格图数据。图3为100秒时间内,采用本文算法、LBP(Loopy Belief Propagation)算法[5]及CE(Color Extract)算法[6]对实验数据进行处理时,未收敛信息数随迭代次数的变化情况,其中OUR1的参数为:n=30,pr=0.005,pl=0.2,OUR2的参数为:n=20,pr=0.01,pl=0.2。从图中可以看出,相比于对所有未收敛信息进行更新的传统并行算法,本文算法与CE算法均有较高的收敛速度,并且在算法达到稳定状态时,有较高的收敛度。与CE算法相比,本文算法前期的分区提取策略与CE算法达到相近的收敛速度,在采用随机减少策略后,本文算法的收敛速度有所下降,但是当算法达到稳定状态时,本文算法具有更高的收敛度。
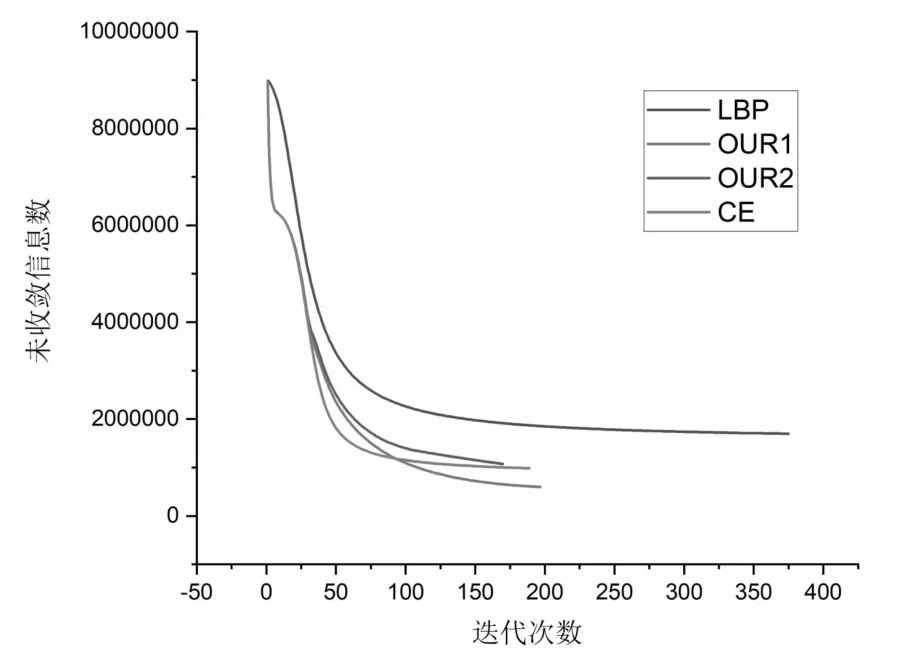
图3 实验结果
4 结语
本文针对于在GPU上进行并行置信传播算法计算时,大量冗余计算降低了算法的计算效率的问题,提出了一种基于分区提取与随机减少的并行置信传播算法。该算法考虑到并行置信传播算法在不同计算阶段的算法特征。在算法初始阶段,通过对图数据的快速分区并选取分区中残差最大的信息进行更新提升了算法的收敛速度。随着达到收敛状态的信息数目的不断增加,算法的收敛速度下降,通过逐渐减少选取的分区数目的方式提升算法的收敛度与收敛速度,保证算法达到稳定时具有较高的收敛度。但是目前仍采用预设参数的方式减少选取的分区数目,通过自适应的方式减少选取的分区数目是未来的研究重点。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
中国毕业后医学教育(2021年3期)2021-12-02 02:24:20
中国毕业后医学教育(2021年3期)2021-12-02 02:24:18
中等数学(2021年9期)2021-11-22 08:06:58
陶瓷学报(2021年2期)2021-07-21 08:34:58
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
山东科学(2018年6期)2018-12-20 11:08:58
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:29
河南科技(2015年8期)2015-03-11 16:23:52
