
基于SPSS的保险公司新投保数据的数据分析
2021-09-06 05:40:42邹玉兰杨杉
现代计算机 2021年22期
邹玉兰,杨杉
(四川大学锦城学院计算机与软件学院,成都611731)
0 引言
随着我国社会的飞速进步以及我国经济的快速发展,我国计算机信息技术也得到了迅速的进步,极大地影响着人们的生活水平[1]。保险最初建立时的意义是将个人现存的空闲资金对未来无法预期的风险损失做出保障的运行体制,作为个人防范风险的一种手段,大数据可以更有效地抓取用户需求、保险产品价格、保单风险防控等,但因为大数据在保险业的应用正处于初步的探索阶段,无法对信息进行完全有效抓取并分析[2]。保险行业是经营风险的行业,要利用风险模型或数理技术等对标的物的风险进行评定,风险评定的过程就是数字化的过程,数字化是保险行业的自然属性。保险公司的利润主要来源于收取的保费和未来的赔付支出的差额,保险公司先要对这些风险发生的概率进行预测,预测的过程就是数字化的过程[3]。本文就大数据对保险公司客户投保数据进行研究分析。
1 研究思路
以四川仁寿保险公司客户新投保数据为例,利用SPSS的分析方法挖掘保险客户的大数据信息价值。发现新投保数据列,险种、总保费、客户性别、客户年龄和客户过去三年平均年收入之间存在可以挖掘的关系和价值,本文主要针对这几列做出不同险种类别的频率分析,客户不同婚姻状况之间的总保费的单因素方差分析和客户过去三年平均年收入与性别探索分析。
2 数据说明
2.1 数据描述
该新投保数据集一共有900649行16列,包含机构、险种、投保时间、缴费方式、缴费期限、投保份数、总保费、保额、客户号、性别、年龄、婚姻状况、教育程度、过去三年平均年收入、职业、家庭人口字段。
2.2 数据清洗
删除投保时间、投保份数、教育程度、家庭人口无效列;筛选保额为0,过去三年平均年收入除无职业、无兼职离退休、无业家庭主妇、学生、婴幼儿等职业外在1000元以下的行并删除;筛选婚姻状况为X的行并删除;添加险种分类列,将险种第一个字符相同的划为同一类,以第一个字符作为共同的类型;添加婚姻状况代码列,并通过IF函数嵌套将M(已婚)设置为1、S(未婚)设置为2,D(离异)设置为3、W(丧偶)设置为4、R(再婚)设置为5。
原数据900649行16列,清洗数据417141行14列。
3 数据分析
3.1 不同险种类别的新投保客户频率分析
分析过程:选择分析工具栏下的描述统计的频率分析,将变量设置为险种分类(险种依据首字符划分类别),在图形中选择条形图,在格式中选择按计数升序排列,点击确定。
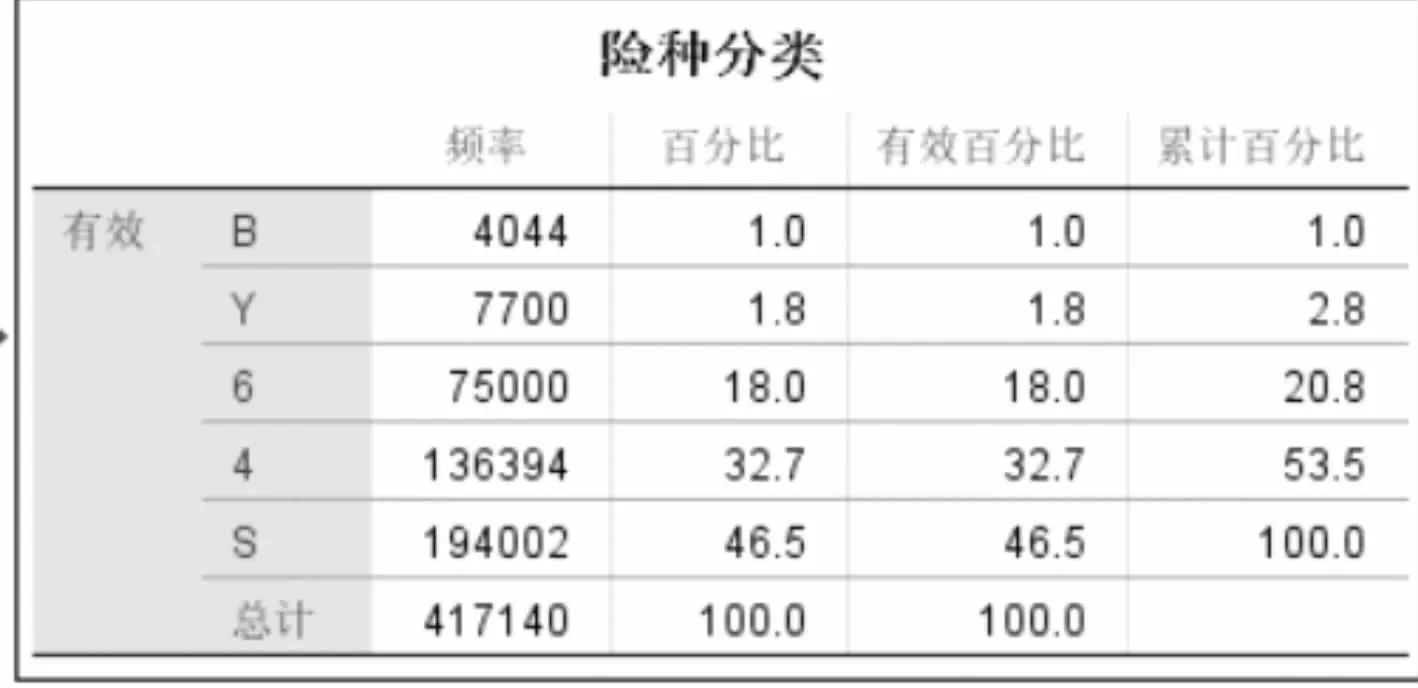
图1 以险种分类为分组的频率统计描述
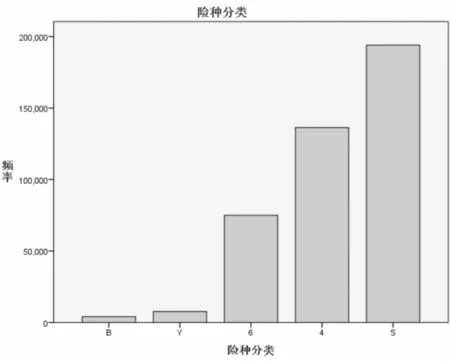
图2 各险种分类的个案数条形图
结论:观察以上两图可以得到,不同分类的险种的新增投保客户之间存在差异。其中B类保险的新投保客户最少,仅占总新投保客户数量的1%;S类保险的新投保客户最多,占比46.5%,接近一半的投保数量。因此,按照新投保数据的险种分类频率可以得出各险种受欢迎程度的顺序:S>4>6>Y>B。此结论说明,S类保险在新客户选择投保的时候占有绝对的优先选择权,这说明S类保险的设计比较符合大多数客户的需求,并且能够给机构带来大量的客户源;B类和Y类保险的投保率较低,这说明这两类保险的需求不高,4类保险和6类保险的投保率居中,其中4类保险比6类保险更受欢迎。
3.2 不同婚姻状况的客户与总保费的单因素方差分析
分析过程:先在变量视图中对婚姻状况代码设置值标签说明,再依次点击分析、比较平均值、单因素ANOVA检验打开单因素检验设置框,将总保费放入因变量列表中、婚姻状况代码放入因子中,点击选项并勾选方差齐性检验,点击继续,点击事后比较并在假定等方差中勾选LSD、在不假定等方差中勾选T2,点击继续,点击对比并设置系数依次为1.5、-1、-1、-1、1.5(即将已婚和再婚类别与未婚、离异和丧偶类别进行对比),点击继续。
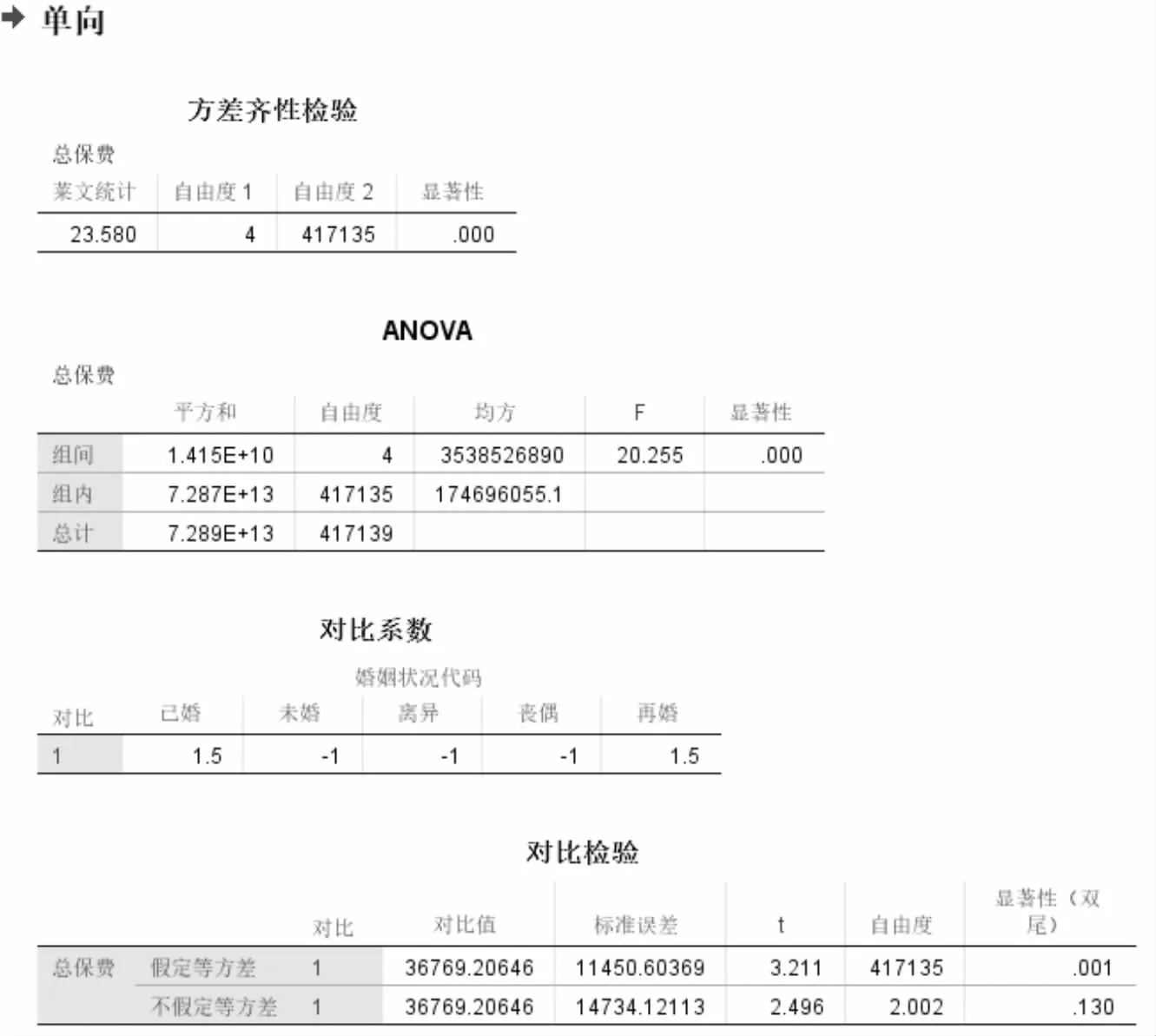
图3 方差齐次性检验
结论:根据对比检验表中假定等方差的显著性水平为0.001、不假定等方差的显著性水平为0.130可以得出应该拒绝假定等方差的原假设、接受不假定等方差的原假设,即已婚和再婚类别与未婚、离异和丧偶类别的方差不具有齐次性。从而选择查看塔姆黑尼多重比较表,根据此表可以得出各婚姻状况关于缴纳的总保费中已婚与未婚、丧偶之间有显著差异,与离异、再婚之间没有显著差异;未婚与离异、丧偶之间有显著差异,与再婚之间没有显著差异;离异与丧偶之间有显著差异,与再婚之间没有显著差异;丧偶与再婚之间没有显著差异;且再婚与其余4种婚姻状况都没有显著差异。

图4 各类别多重比较不假定等方差表
3.3 过去三年平均年收入与性别的探索分析
分析过程:点击分析工具栏中描述统计选项卡下的探索选项,将过去三年平均年收入放入因变量列表中、性别放入因子列表中,点击确定。
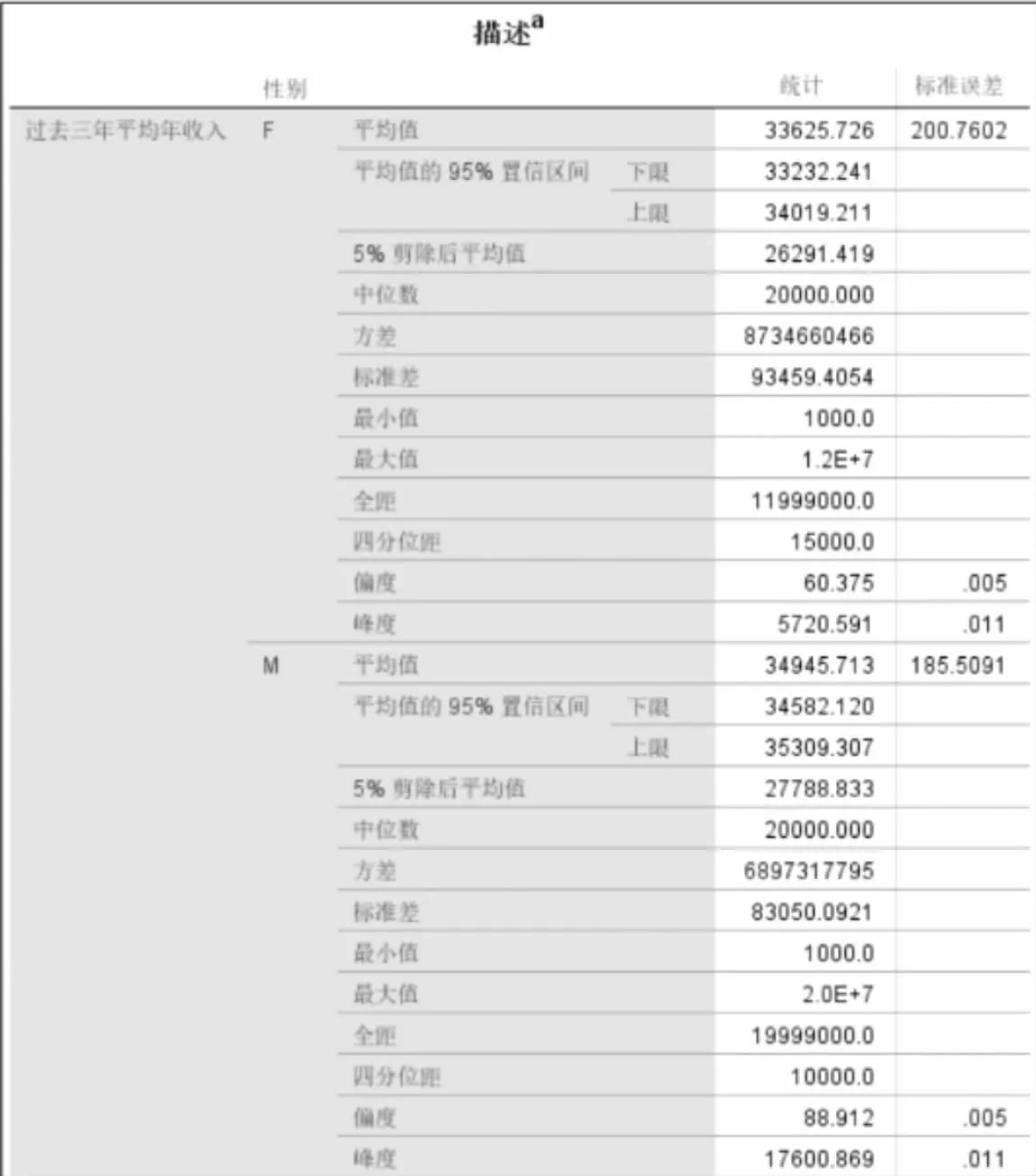
图5 以性别为分类的过去三年平均年收入统计描述
结论:由描述性统计结果可看出男性的平均收入高于女性,但两者的中位数都为2这个等级,即平均年收入为1w到3w这个区间,且男性、女性的峰度都大于零,表示该总体数据分布与正态分布相比较为陡峭,为尖顶峰。男性的峰度值更大,说明男性近三年年收入中,相较于女性收入波动更大,范围更广。男性、女性的偏度也都大于零,表示其数据分布形态与正态分布相比为右偏,数据右端有较多的极端值,数据均值右侧的离散程度强,即收入大于2w到3w这个区间值的极端值更多。男性偏度值大于女性说明男性近三年平均年收入中有更多的高收入人群。不难看出,男性女性总体的收入差异不大,但男性收入会稍多一些,高收入人群偏多。
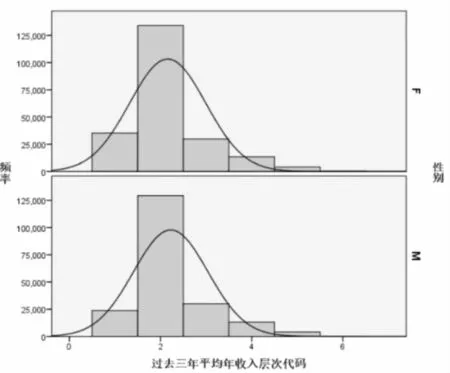
图6 以性别为分类的过去三年平均年收入直方图
4 结论及建议
4.1 结论
通过频率统计的结果、单因素方差分析结果、探索分析结果可得出以下结论:①不同险种的投保率存在明显的差异,S类保险的投保率最高占有46.5%,B类保险的投保率最低仅占1%,按照新投保数据的险种分类频率可以得出各险种受欢迎程度的顺序:S>4>6>Y>B。②各类婚姻状况关于缴纳的总保费中已婚与未婚、丧偶之间有显著差异,与离异、再婚之间没有显著差异;未婚与离异、丧偶之间有显著差异,与再婚之间没有显著差异;离异与丧偶之间有显著差异,与再婚之间没有显著差异;丧偶与再婚之间没有显著差异;且再婚与其余4种婚姻状况都没有显著差异。③近三年年收入中,男性收入相较于女性收入的波动更大,范围更广。男性近三年平均年收入中有更多的高收入人群。男性女性总体的近三年平均年收入差异不大,但男性收入会稍多一些。
根据本文的数据分析,可以得出目前保险行业的客户需求很大,本文研究的原始新投保数据约90万条,如此庞大的数字显示说明越来越多的人关注到了保险给人们带来的福利和保障,并且保险行业的发展是大势所趋,大数据在保险行业中的运用也会越来越成熟,越来越频繁。
4.2 建议
保险公司可以对客户需求量大的S类保险的新投保客户制定特殊的福利项,维持投保率在较高的水平;对需求量较小的B类保险进行优化提升,从客户的需求方面稍微优化保险套餐的内容,加大吸引客户的力度,优化这两类保险的套餐设计和投保推荐,争取能够让公司在相同需求的情况下争取更多的客户源,增加行业之间的竞争筹码;针对男性客户过去三年平均年收入比较高的客户,在客户有意愿的情况下可以推荐多个险种的保险,增加客户的受保几率和公司的保险订单;建议给已婚或者再婚的客户推荐一种家庭保险或者推荐家庭几个人一起买某种保险,送出福利或者打折或者提升保额等优惠操作;给未婚、离异或者丧偶的客户推荐保费较低的险种;建议客户可以在能力范围之内尽早地购买适合的保险为自己或者家人的未来做一个规划。
保险公司可以利用大数据技术对客户流动数据进行实时监控和挖掘,大数据技术可以帮助保险公司挖掘潜在有价值的客户和找出各类保险的需求量,用真实的客户数据反映市场动向和规划公司未来发展的方向。
猜你喜欢
中老年保健(2022年4期)2022-08-22 03:01:40
家庭医学(下半月)(2020年2期)2020-05-11 02:07:38
北方工业大学学报(2019年5期)2019-03-30 06:31:56
中国生殖健康(2019年9期)2019-01-07 01:19:06
中国生殖健康(2019年8期)2019-01-07 01:18:16
东北电力大学学报(2018年2期)2018-05-21 09:51:14
数学理论与应用(2017年2期)2017-06-27 07:39:00
卷宗(2017年1期)2017-03-17 11:48:59
环球时报(2017-02-10)2017-02-10 06:45:12
现代经济信息(2016年16期)2016-07-26 13:47:43
