
导盲犬行走机构运动仿真及其视觉识别算法研究
2021-09-02 00:23迟蒙蒙
电子科技 2021年9期
赵 崇,迟蒙蒙,储 聪,张 鹏
(1.昆明理工大学 机电工程学院,云南 昆明 650500;2.大连工业大学 机械工程与自动化学院,辽宁 大连 116034;3.大连工业大学 信息科学与工程学院,辽宁 大连 116034)
相比于生物导盲犬训练难度大、耗时长、成本高等缺点,仿生机械导盲犬的开发与应用有着更为广泛的前景。经过简单行走、低智能化和高智能化[1]3个阶段的仿生机械的研发,研究人员已取得了一定的理论基础和实践应用成果。同济大学的研究人员利用能力风暴机器人的红外传感器、碰撞传感器、直流电机以及喇叭的测控功能设计的导盲机器人为商业化生产提供了参考依据[2]。与之相对应的导盲犬控制系统以及设计开发流程也更加高智能化[3-4],但设计成本与生产成本也大幅度增加。导盲犬的行走机构由履带设计演变为多足机构[5-8],可以更加灵活地适应多种路况的行进,其爬坡能力也优于履带设计的结构。基于契贝谢夫连杆机构的六足军用机器人将曲柄摇杆机构改为曲柄双摇杆机构,可有效增加机构的刚度和强度,也将行走机构改为二自由度,但是可实现路程差,使得机器人实现转弯,因此这种方式仍有待在实践中应用[9]。基于Jansen-leg机构标准型研制的小型八足仿生机器人机构控制简单,运动协调性好,仿生度高,且可以实现零半径转弯。该机器人的爬坡能力和非结构环境的适应性得到了试验样机的验证,具有良好的优化价值[10]。本文基于Jansen机构的行走机构设计,采用单一的步进电机实现动力驱动与行走控制,加上红外线传感器和视觉图像识别系统的控制,不仅具有一定的智能化功能,也降低了设计和制造成本。
1 导盲犬的Jansen行走机构
导盲犬的行走机构采用标准型Jansen机构。本文设置了一个步进电机驱动四足行走机构,并对其机构复杂程度进行简化,使其更加接近于导盲犬的真实行走姿态。Jansen行走机构如图1所示。

图1 Jansen行走机构Figure 1. Jansen walking mechanism
如图2所示,件号1为机体前面的右脚;件号2为红外线传感器,用于探知行走前方的障碍物,其功能为回避或者绕行传感器;件号3为摄像头,用于视觉识别系统的图像采集;件号4为机体,内置驱动电动机以及齿轮机构的传动,实现单电机驱动,导盲犬机体两侧驱动同步,摇臂方向相反,从而实现四肢按照行走的步伐运行;件号5为行走机构摇臂,左右各一个,与驱动电机的输出轴联结,用于输出电机转速,驱动行走机构运动;件号6为机体后面右脚;件号7为机体前面左脚;件号8为机体后面左脚,四足末端均为仿真数据采集点。基于Jansen机构的行走机构也可以使导盲犬在更加复杂的路况下行走。
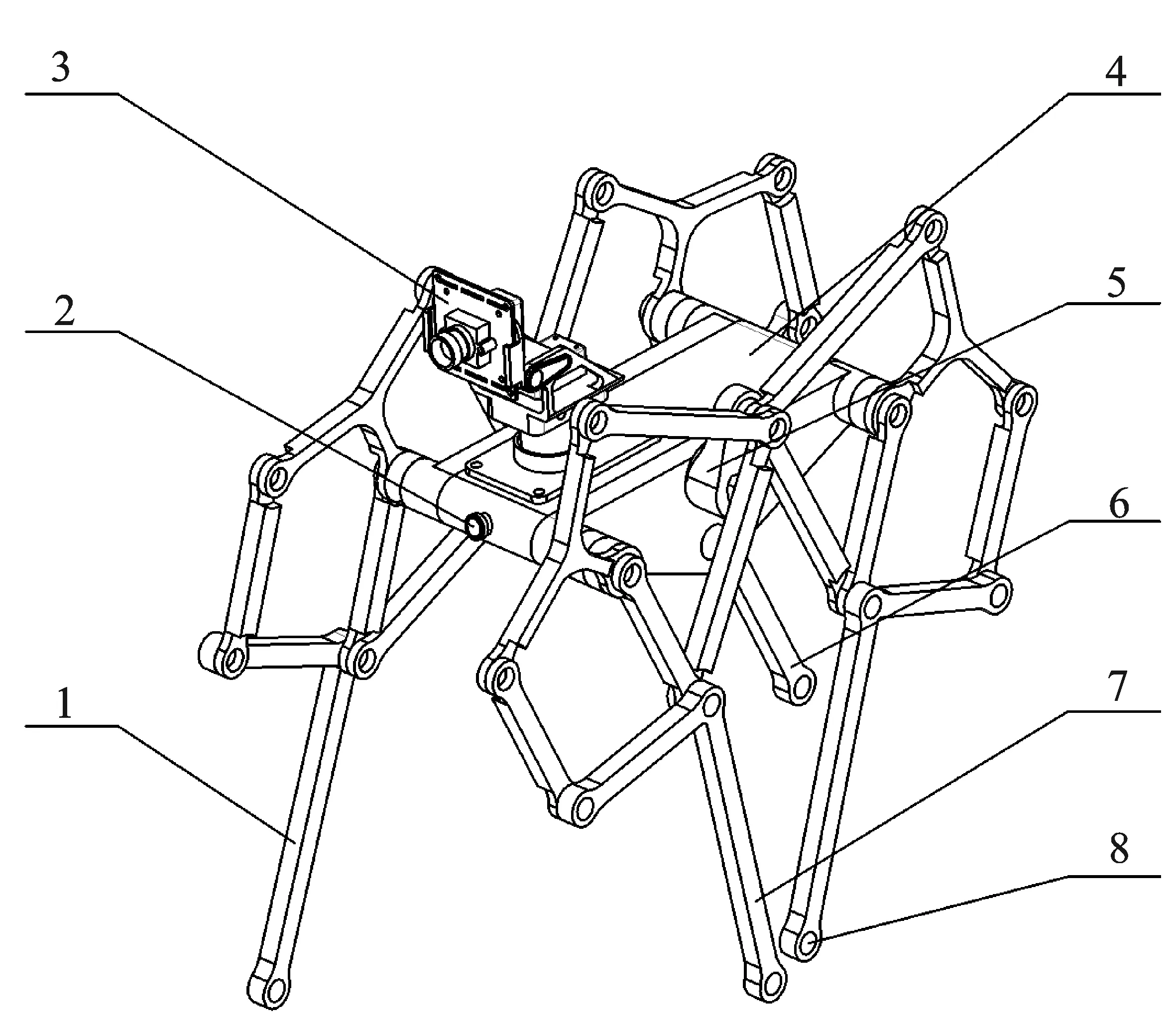
图2 导盲犬机体Figure 2. Guide dog body
2 行走机构的运动仿真
为了验证行走机构的非结构环境适应性,对导盲犬行走机构四肢末端的位移进行运动仿真。将三维实体模型导入到Admas软件中,固定导盲犬机体,将电机输出点的转速参数设置为0.1 rad·s-1,运行时间为10 s,计算出4个仿真数据采集点相对于基准地面法向方向上的位移。参数设置如表1所示,运行计算得到的数据结果如图3所示。

表1 行走机构运动仿真参数设置
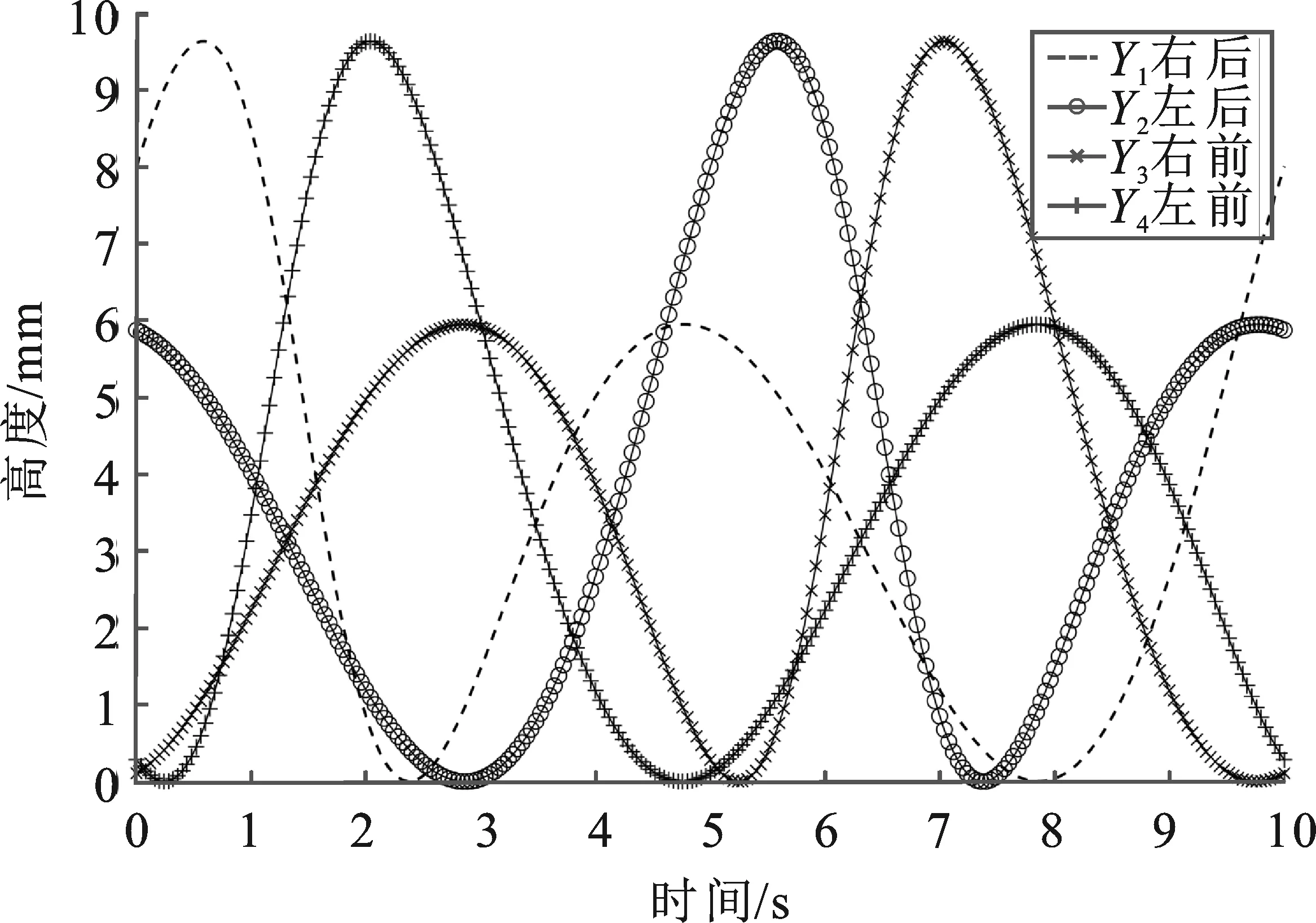
图3 导盲犬四肢末端相对于地面法向位移仿真数据曲线Figure 3. Simulation data curve of the normal displacement of the limbs of the guide dog relative to the ground
从以上分析数据可以得出,导盲犬四肢末端(即行走机构的四足)相对地面的法向方向位移具有相似的位移运动曲线,4个仿真数据采集点有规律地交替上升、交替落地,使其整机在较为复杂的非结构环境下能够平稳运行。
3 导盲犬视觉识别算法
目前,仿生机械导盲犬对周围环境的感知主要通过红外传感器[11]、避障传感器和超声波测距仪[12]等实现,对导盲犬视觉系统的研究较少。随着科技的发展和深度学习日益广泛的应用[13],促进了机械导盲犬向工业化和智能化发展。本文提出了一种基于YOLO(You Only Look Once)的仿生导盲犬视觉识别算法,以人行横道的交通信号灯为例,判断当前信号灯状态是否可通行,为盲人过马路提供指导。实验具体流程为:(1)采集实验数据,标注图像,建立红绿灯的目标检测数据集;(2)将数据集输入到网络,对网络模型进行训练,评价模型性能;(3)验证模型的性能,输出红绿灯的类别信息和位置信息。
3.1 数据集的建立
选择适用于本研究场景的数据集是红绿灯识别和定位的关键[14]。目前,该领域有很多公开的数据集。巴黎高等矿业学校机器人中心TLR(Traffic Lights Recognition)数据集在人口稠密的城市环境中采集图像,包含红灯、黄灯、绿灯3种交通信号灯。伍斯特理工学院嵌入式计算实验室公开的WPI (Worcester Polytechnic Institute)交通信号灯数据集是在美国马萨诸塞州伍斯特市收集训练数据。上述数据集适合无人驾驶汽车领域交通信号灯的识别,不适用于盲人出行场景交通信号灯的识别。本实验使用自建数据集,在辽宁省北镇市城市道路采集。为了减少光照对实验结果的影响,选择早中晚3个时间段采集图像共计300张。为了增加数据集数量,模拟真实场景录制视频,通过取帧得到图像193张。该数据集共计493张图像,图像格式为jpg,图片分辨率为416×416像素。该实验部分数据集如图4所示。

图4 本实验部分数据集Figure 4. Part of the dataset
采用YOLO_Mark标注工具,使用矩形框标注图像中的红灯、绿灯,为后续训练提供真实值。该数据集需要Green lighted light两个标签,标注后可自动生成包含目标类别、目标中心点坐标(x,y)、矩形框宽度w、高度h的文本文件。
在训练有监督的机器学习模型时,为了能够得到识别效果好、泛化能力强的模型,需要将数据集分为训练集、验证集和测试集。训练集拟合模型,通过设置分类器的参数训练分类模型。验证集用于调整模型的超参数并初步评估模型性能。测试集用于评估模型的泛化能力。本实验数据集参数如表2所示。

表2 数据集参数表
3.2 红绿灯识别模型的训练
3.2.1 YOLO网络
YOLO[15]是一种2016年提出的目标检测算法。该算法将物体检测任务作为回归问题来解决,其核心思想是将整张图像输入到神经网络中,然后在输出层预测物体边界框(Bounding Box)的位置、物体的类别和置信度分数。
YOLO网络结构由24个卷积层与两个全连接层构成。首先将图像缩放到固定尺寸,将输入图像划分成7×7的网格,每个网格预测两个边框。将图片划分为7×7网格的方法较为粗糙,会影响边界框的回归,从而影响定位误差,导致YOLO v1物体检测精度较低。YOLO v1每个网格只能识别一个物体,对密集的小物体检测效果不佳。
YOLO v2[16]是对YOLO v1网络的改进,增加批归一化,提高模型的收敛速度,减少过拟合提高平均检测精度(mAP)。通过引入锚点框(Anchor Boxes)机制预测,提升了召回率。在网络结构中添加跨层连接,将高分辨率特征和低分辨率特征结合,提高了小物体的检测性能。YOLO v2在提高精度的同时也提升了检测速度,但是仍无法解决重叠分类等问题。
YOLO v3[17]网络使用了darknet-53的前52层。该网络主要由一系列1×1和3×3的卷积层组成,每个卷积层后面会有一个BN(Batch Normalization)层和LeakyReLU层。YOLO v3网络将Softmax层换成逻辑回归层实现目标的多标签分类。相较于YOLO v1和YOLO v2网络,YOLO v3采用了多尺度融合的方法,通过上采样和特征融合的方式,将3个尺度进行融合,提高了小目标的检测性能。当盲人站立在人行横道一侧准备过马路时,相对盲人的位置红绿灯属于远目标,在图像中成像较小,所以选择YOLO v3作为本研究的目标检测方法。
3.2.2 锚框优化
本文在YOLO v3的基础上优化锚框的尺寸和数量,对数据集中的目标边界框进行K-means聚类分析,获得适用于本模型的先验框。锚框数量与平均交并比关系如图5所示。综合考虑模型的复杂度和平均交并比(Intersection Over Union,IOU),选择锚框数量为4,平均交并比为79.06%进行后续实验。
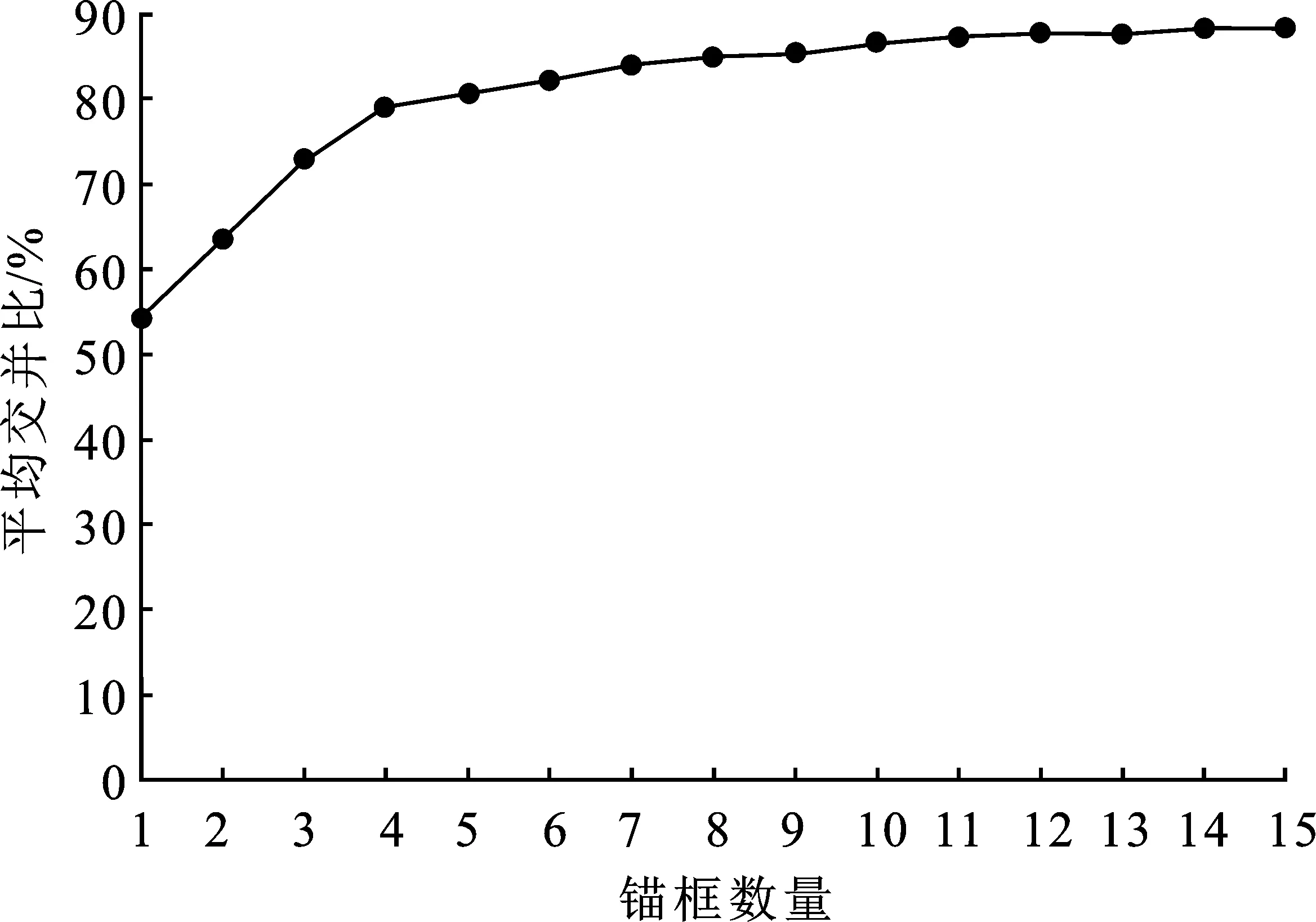
图5 锚框数量与平均交并比的关系Figure 5. Relationship between the number of anchor boxes and average IOU
根据目标对象边界框的宽高比优化锚框尺寸,图6(a)为YOLO v3根据VOC和COCO数据集聚类得到的先验框。为了减少模型的计算量,加快模型的计算速度,本文分别采用anchors=7,14,10,20,16,34,57,98的锚框进行后续实验。该尺寸的锚框在宽高比和尺度上与数据集中目标对象匹配程度高,其尺寸如图6(b)所示。

(a) (b)图6 优化前后锚框尺寸对比(a)先验框 (b)优化后锚框尺寸Figure 6. Anchor box size comparison(a)Prior box size (b)Anchor box size after optimization
3.2.3 YOLO参数选择
本文使用Windows 版本的darknet框架进行YOLO v3版本的训练和测试。为了使网络达到所需性能,需要合理地设置YOLO v3网络模型的训练参数[14]。YOLO v3模型参数主要包括学习率、动量和权值衰减系数。在选择参数的时候,需要考虑硬件的GPU性能。本实验在笔记本电脑上进行,电脑型号为神州战神Z7-KP7EC,内存为16 GB,处理器为Intel Core i7-8750H,显卡为 NVIDIA GTX 1060。为了充分利用实验设备并且达到相对高的性能,本次实验设置batch=64,subdivision=32。该参数说明网络在训练时,训练迭代包含了32组,每组包含了2张图片,减少了内存的占用,减轻了GPU的运行压力。为了提高收敛速率,避免过拟合现象,将动量设置为0.9,学习率设置为0.001。模型的参数选择如表3所示。

表3 YOLO v3训练参数
3.3 实验
本实验共对 YOLO v3 模型进行了 7 500 次迭代,网络的损失函数[18]图像如图7所示。从图中可以看出,在前240次的迭代中平均损失迅速下降;在240~800次迭代中平均损失下降速度减慢;在800~2 000次迭代中,平均损失缓慢下降;2 000 次后损失函数达到收敛;到达7 500次时,平均损失保持平稳不再减少,所以停止训练。
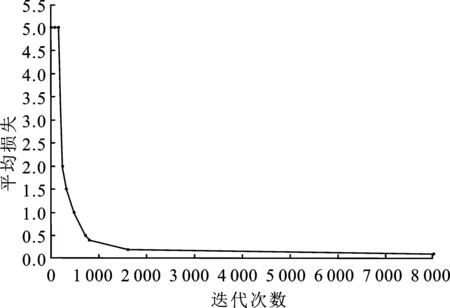
图7 模型的损失函数图Figure 7. Loss function of the model
在训练中,模型会因为迭代次数的增加而出现过拟合的现象,即模型能在训练集上达到良好的效果,但无法检测其他图像的目标[19-20]。对比多个模型的权重,选择最优模型。设置每迭代 100次输出一个模型,记录模型的交并比(IOU)、绿灯、红灯准确度(Average Precision,AP)、模型召回率(Recall)和平均准确率(Mean Average Precision,mAP)等模型评价指标。不同迭代次数的模型性能指标如图8所示。

图8 不同迭代次数的模型性能对比Figure 8. Performance comparison of models with different iterations
本算法的目的是区分红灯和绿灯,并减小漏检率。为分析算法的性能,定义TP(True Positives)为被正确识别的正样本,TN(True Negatives)为被正确识别的负样本,FP(False Positives)为被错误识别的正样本实际为负样本,FN(False Negatives)为被错误识别的负样本实际为正样本。
交并比IOU的计算方式是模型的预测框和手动标注的真实框交集部分与并集部分的比值,反映了预测框是否更加接近物体的真实位置。
召回率Recall是被正确识别出来的红、绿灯个数与测试集中所有真实红、绿灯的个数的比值。
(1)
查准率Precision是模型在识别的所有对象中,正确识别的比率,衡量了模型在单一类别上的性能。mAP则衡量了模型在所有类别上的性能。
(2)
根据实际情况分析,针对盲人出行场景红绿灯的识别,正确识别出红绿灯的类别比识别红绿灯位置准确性重要,所以选择准确率高的优化模型。
经对比发现,迭代次数为5 000时,模型达到最优性能。实验表明,该模型平均精度为88.67%,绿灯准确率为87.96%,红灯准确率为89.38%,召回率为88%。网络模型的检测速度为23.5 frame·s-1,本文方法能实时检测并区分人行横道红绿灯。
3.4 结果分析
为了检验模型对人行横道上红绿灯的识别效果,本文选择部分拍摄图片和网络图片来对模型进行验证。图9展示了部分红绿灯图像的预测结果。图9(a)和图9(b)来源于自建数据集中的验证集,网络对该图像红绿灯的识别概率为100%。图9(c)和图9(d)来源于网络。图9(c)没有在人行横道上拍摄,但是网络识别红绿灯的概率分别为51%和81%,图中两个绿灯均被正确识别,说明模型具有一定的泛化能力。由于图像拍摄角度的原因,图9(d)预测的实际位置与真实位置有一定的偏差,识别概率为40%。图9(e)为原图,图9(f)为预测图,网络对该图像中目标存在误检,图中的绿灯被重复检测,图像下方公交车的质检标志被识别为红灯。

(a) (b)
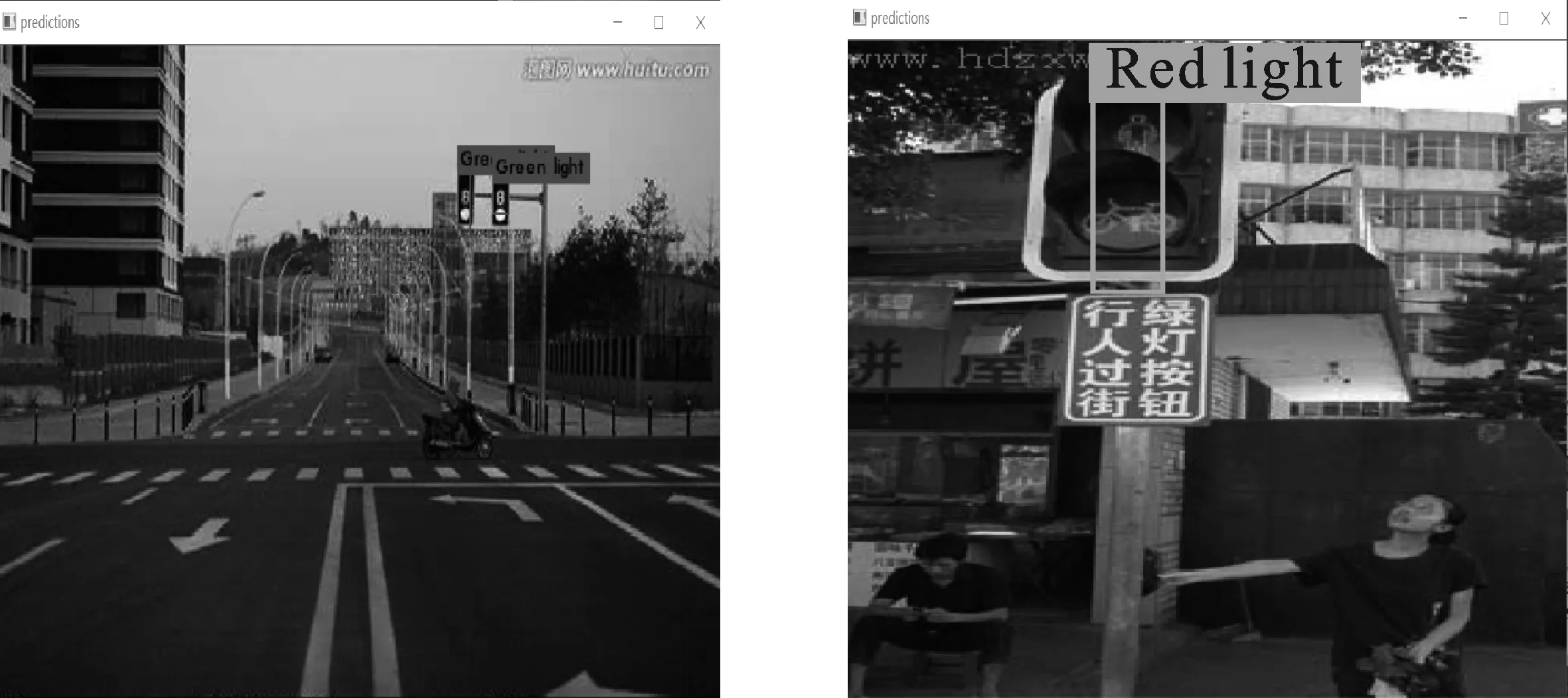
(c) (d)

(e) (f)图9 训练后模型检测效果(a)自建数据集红灯预测结果 (b)自建数据集绿灯预测结果(c)其它场景图像绿灯预测结果 (d)其它场景图像红灯预测结果(e)自建数据集待检图像 (f)自建数据集错误预测示例Figure 9. Model detection effects after training(a) Red light prediction result of self-built data set(b) Green light prediction result of self-built data set(c) Green light prediction results of images of other scenes (d) Red light prediction results of images of other scenes(e) Image of self-built data set to be checked(f) Examples of self-built data sets with false predictions
4 结束语
Jansen行走机构的导盲犬机械装置具有紧凑的结构。机构运动仿真的结果表明,相对于地面的法相位移,其四足可以有规律地进行交替的上升下降,与自然界生物运动机理有着较高的仿生度。因此,可以较好地适应复杂非结构环境下的行走。基于YOLO的视觉识别系统能够判断当前信号灯状态是否可以通行,识别红绿灯的平均精度为88.67%,绿灯准确率为87.96%,红灯准确率为89.38%,网络模型的检测速度为23.5 frame·s-1。未来将进一步改进算法,提高模型的准确性和泛化能力,并针对盲道和台阶等标识物进行识别,提高机械导盲犬的智能化和实用性。
猜你喜欢
农业装备与车辆工程(2021年8期)2021-08-28
故事作文·高年级(2021年8期)2021-07-27
新少年(2021年3期)2021-03-28
南方农机(2021年1期)2021-01-20
港口装卸(2020年3期)2020-06-30
现代营销·理论(2019年10期)2019-09-10
小学科学(学生版)(2019年6期)2019-07-10
快乐语文(2018年25期)2018-10-24
小学生导刊(2018年13期)2018-06-29
小天使·一年级语数英综合(2018年6期)2018-06-22
