
基于深度学习的杂乱场景下零件实例分割*
2021-08-31 04:50:26李东年陈成军赵正旭
组合机床与自动化加工技术 2021年8期
王 杨,李东年,陈成军,赵正旭
(青岛理工大学机械与汽车工程学院,山东 青岛 266520)
0 引言
工业机器人应用于分拣、搬运和装配等工业环境中,极大提升了生产的效率。其中分拣作业是一个十分重要的环节,在分拣作业中,零件分割的结果直接影响着零件分拣能否顺利地进行。
对于零件识别分割,目前研究已经取得了一些进展。刘学平等[1]为了准确识别出图像中的目标零件,提出一种自适应边缘优化的改进YOLOv3目标识别算法。李庆利等[2]通过计算颜色间的灰色关联度来确定像素点间隶属关系,求得特征颜色,完成零件图像分割。这些方法依赖于零件的轮廓和纹理等特征,在工业环境下,存在油渍污染,导致零件的纹理信息缺失。
在深度学习方面,陈廷炯等[3]为完成机器人抓取零件的任务,利用语义分割模型对彩色图进行分割。黄海松等[4]利用卷积神经网络对零件图像提取特征,通过Mask RCNN对零件进行实例分割。卷积神经网络需要大量的图片进行训练,但这些方法采用的数据集大多是通过人工完成,人工采集、标注图像浪费了大量的时间和精力,且人工标注存在主观因素,使得标签图标注不准确,影响网络的训练结果。
本文利用三维仿真技术,通过三维渲染引擎OSG和物理引擎Bullet建立了杂乱场景零件训练集合成系统,该系统可以自动完成图像的采集、标注工作。本文首先利用杂乱场景零件训练集合成系统,构建了三种合成训练集,然后通过迁移学习中的微调(fine tune)方法,对Mask RCNN网络模型进行训练,最后通过Kinect视觉传感器采集不同零件数目的真实图像,对训练好的模型进行测试,分析模型对零件的分割结果。
1 训练集的制备
1.1 合成训练集的制备
OpenSceneGraph(OSG)是一个开源的场景图形开发库,主要是为图形应用程序提供场景管理和渲染优化功能,OSG采用OpenGL作为底层渲染的API,广泛应用于虚拟现实、视景仿真、科学计算可视化等领域[5]。Bullet是一个跨平台的物理模拟计算引擎,通过Bullet可以赋予虚拟场景中的模型以物理属性,如碰撞检测、力学等属性。OSG和Bullet间的数据类型有所区别,需要通过插件osgBullet(OSG的扩展模块)解决两个引擎之间数据传递的问题[6]。
图1a所示为杂乱场景零件训练集合成系统框架,本文基于Bullet和OSG,利用osgBullet建立了系统开发环境,通过C++编程建立了零件的杂乱堆叠场景,在场景中加载零件模型,并赋予模型碰撞检测和重力属性,通过OSG中自带的观察器去观测虚拟场景。如图1b所示,将零件模型的位置预设在距箱盒模型一定高度的位置,零件模型在重力的作用下落于箱盒当中,零件与箱盒之间的碰撞,使得零件杂乱地摆放于箱盒中,待零件碰撞一段时间静止后,虚拟相机拍摄出杂乱摆放的零件图像,不断重复上述过程直至训练集生成完毕。
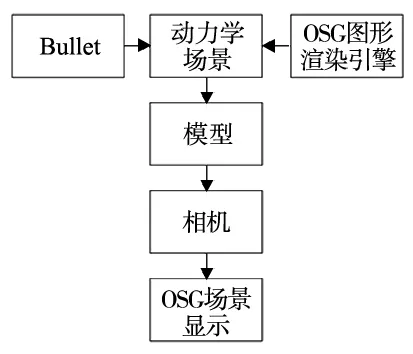
(a) 系统框架

(b) 杂乱场景生成演示
图2所示为杂乱场景零件训练集合成系统生成的深度图和标签图,但是这些图片并不能直接输入到网络当中进行训练,需要对图片进一步处理。Mask RCNN图像分割的掩码是由全卷积层生成,对应的损失函数为二元交叉熵函数,所需标签是像素为0,1,…,n的灰度图,其中n为零件的个数,标签图为24位的图像,因此需要对标签图重新编码,利用公式:
Gray=0.299×R+0.587×G+0.114×B
(1)
将三通道图像转化为单通道灰度图,最后将灰度图中的灰度值修改为0,1,…,n的形式。

(a) 深度图 (b)标签图图2 合成训练集
1.2 合成训练集的增强
真实场景下采集的零件图像与虚拟训练集相比,包含大量的噪音,使得模型对真实图像分割的效果较差。本文对合成训练集进行数据增强,采用向合成训练集中加入高斯噪音的方式,来模拟真实图像中的噪音,提高模型的鲁棒性。
依据Box-Muller算法[7],通过式(2)、式(3)产生服从高斯分布的随机数Z0,Z1。
(2)
(3)
其中,U1,U2服从(0, 1)之间随机分布,然后通过式(4)、式(5)生成噪音点。
(Z0×σ+μ)×k
(4)
(Z1×σ+μ)×k
(5)
其中,σ为高斯噪音的方差,μ为高斯噪音的均值,k为高斯噪音的系数。将生成的噪音点均匀加在虚拟图像的像素上,如图3所示。

(a) 原图 (b)加噪后的图像图3 合成深度图像高斯加噪
本文将少量的真实图像添加到训练集当中,利用其对网络中的权重参数进行优化,确保模型对真实图像有更好的分割效果。本文采集10张真实图像并利用labelme工具进行标注,通过图像仿射变换的旋转操作,将图像扩充到100张,如图4所示。

(a) 原图 (b)旋转30° (c)旋转60°图4 图像旋转
2 Mask RCNN网络的构建
Mask RCNN是He K等[8]于2017年提出的一种对物体实例分割的方法,与传统卷积神经网络相比,不仅可以对不同种类物体进行分割,还可以对同种类物体进行分割。本文构建的Mask RCNN如图5所示,其主要分为以下几部分:主干网络(Backbone)、区域候选网络[9](Region Proposal Network, RPN)以及网络输出模块(Output)。
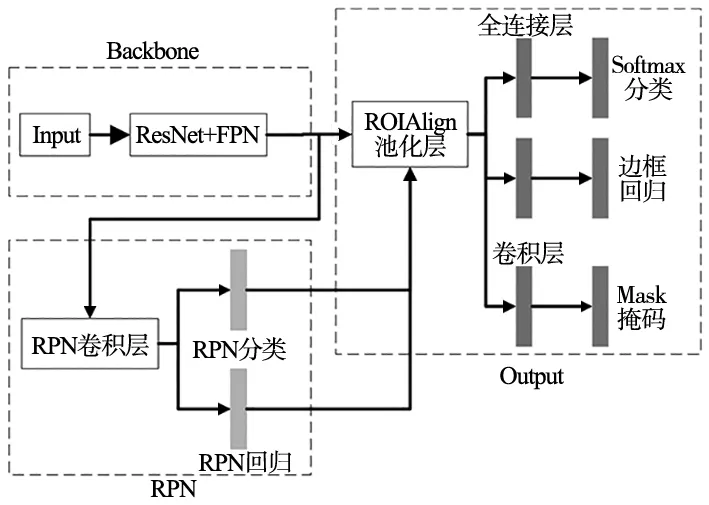
图5 Mask RCNN网络结构
本文采用残差网络[10](Residual Network, ResNet)和特征金字塔网络[11](Feature Pyramid Networks, FPN)作为主干网络用于图像特征提取。ResNet是一种深度卷积网络,该网络很好的解决了网络深度增加造成的性能退化的问题,具有很好的学习和表达能力。FPN是传统CNN网络(如:VGGNet、AlexNet、ResNet)对图像信息特征提取的一种增强方法,基本流程包括:自下至上,自上至下,横向连接,使图像具有深层次和浅层次的信息。ResNet-FPN架构与传统CNN网络相比,通过增加网络深度和特征融合的方法,提高了网络的性能。
RPN用来产生可能的目标候选区域,解决了传统方法生成目标检测框耗时较多的问题。ResNet-FPN结构提取的每张特征图,通过滑动窗口生成产生候选框然后对生成的候选框进行分类和回归,分类任务中筛选出包含目标物体的候选框,回归任务中调整候选框的位置。
Output模块是网络的输出部分,主要包括:边框的生成、mask掩码的生成,图6所示为Mask RCNN的预测图像,每个实例被边框所包围,且被附上了不同颜色的mask掩码。边框的生成首先通过RPN生成带有多个候选框的特征图,经过ROIAlign池化层处理后转化为统一大小,然后通过全连接层对候选框进行分类和回归,生成边框。mask掩码的生成是通过ROIAlign池化层将ResNet-FPN架构提取的特征图转化为统一大小,通过全卷积层生成mask掩码。

图6 Mask RCNN预测图
本文将Mask RCNN划分为三个模块:Backbone、RPN、Output,由于三个模块包含大量的参数,并且ResNet-FPN结构提取的特征图质量,直接影响着RPN和Output模块的输出结果。因此本文采用迁移学习的微调(fine tune)方法[12],利用ResNet-FPN结构在COCO数据集进行特征提取。COCO数据集包含20万张80多类标注好的图片,是一个高质量的数据集,提取到的特征图也包含足够的语义特征[13]。在COCO数据集训练好的模型基础上,利用合成数据集训练RPN和Output模块,在保证了分割精度的同时,减少了训练时需要调整的参数个数,降低训练的时间成本。
3 实验
本文为探究不同训练集对模型检测和分割效果的影响,将训练集分为三种进行对比实验。训练集1:虚拟零件图像训练集,即只包含未经处理的虚拟图像。训练集2:虚拟图像和加噪图像构成的训练集,即包含未经处理的虚拟图像和对其加噪后的图像。训练集3:虚拟图像、加噪图像以及少量真实图像构成的训练集,即包含未处理的虚拟图像、加噪后的图像以及少量的真实图像。利用三种不同的训练集分别对模型训练,搭建真实的实验台采集深度图像,利用双边滤波对图像进行处理,使用labelme软件对图像进行标注,并测试模型在不同零件数目下的结果。
3.1 实验数据集的构建
在win10操作系统下,通过visual studio2013编译器开发了杂乱场景零件训练集合成系统,系统运行在一台CPU为i7-8750H,GPU为NVIDIA GTX1050Ti,内存为8G的PC机上。通过零件训练集合成系统和数据增强的方法构建了三种训练集,构成如表1所示。
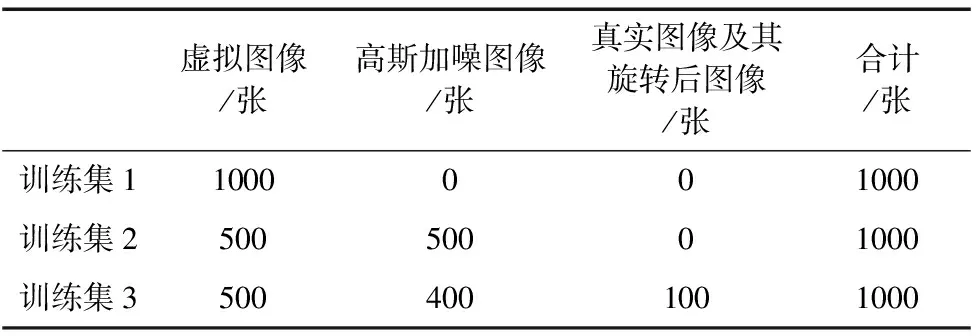
表1 训练集的构成
通过Kinect视觉传感器分别采集了零件数量为5个和10个的深度图像各50张,由于深度图中含有较多的噪音,因此需要对深度图进行降噪处理。本文采用了双边滤波器降低深度图像中的噪音,降噪前后的图像如图7所示,将采集到的100张深度图进行降噪后,利用labelme软件进行标注,完成测试集的制备。

(a) 原图 (b)降噪后的图像图7 深度图像双边滤波效果
3.2 Mask RCNN模型训练
机械零件的表面大都呈现银白色,具有较强的反光性,在工业环境下,存在油渍污染,使得机械零件表面纹理不清晰,导致RGB图像训练的模型在实际环境下的效果较差。采用深度图对Mask RCNN进行训练,可以降低反光性和纹理不清对模型的干扰。
本文在一台CPU为Xeon E5-2650V4,GPU为NVIDIA GTX TITAN xp,内存为128G的PC机上对Mask RCNN模型进行训练。分别采用三种不同训练集进行训练,训练过程中的总损失曲线如图8所示。Mask RCNN的损失函数由分类误差、检测误差和分割误差组成:
L=Lmask+Lclass+Lbbox
(6)
训练过程分为三个阶段:预训练阶段,利用ResNet-FPN结构在COCO数据集上进行特征提取;第二阶段在预训练权重的基础上,利用三种不同的训练集进行训练,学习率为0.01;第三阶段为了使模型充分拟合,将学习率调整为0.001。其中第二阶段进行了50轮(epoch)训练,第三阶段进行了30轮训练,模型经过80轮20 000次迭代(每轮迭代250次)训练后损失趋于稳定。
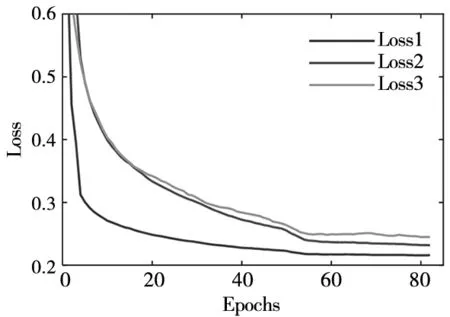
图8 训练过程中的损失变化
3.3 Mask RCNN模型测试
当图像中零件只有少量零件时,遮挡现象并不明显,且零件的轮廓清晰,便于识别;当图像中零件数目较多时,遮挡现象严重,不利于模型在边缘处的分割。为探究不同数量的零件对模型效果的影响,本文采集了不同数量零件的图像,进行模型测试。
对三种不同训练集训练出的模型进行测试,其中训练集1对应的模型为模型1,训练集2对应的模型为模型2,训练集3对应的模型为模型3,随机挑选2张真实采集的图像进行预测,可视化结果如图9所示。由于真实的深度图存在着噪音的干扰,只用虚拟图像训练的模型1存在框位置和掩码分割不精准等问题;虚拟图像加入高斯噪声后,模型2相比模型1有所改善;模型3在模型1和模型2的基础上添加了由旋转变换扩展的100张真实图像进行训练,可以看到模型3的效果有了明显的提升,框的位置和掩码分割相对精准,并且在边缘分割效果较好。

(a) 原图

(b) 模型1预测结果

(c) 模型2预测结果

(d)模型3预测结果图9 模型预测效果
对模型检测分割进行评价,需要同时考虑准确率(Precision)和召回率(Recall),准确率和召回率的计算如下:
P=TP/(TP+FP)R=TP/(TP+FN)
(7)
其中,TP是正样本被检测为正样本的个数,FP是负样本被检测为正样本的个数,FN是正样本未被检测出的个数。选取AP50(IoU=0.50)作为评价实验结果的指标,选取0.5作为阈值,图10所示为Precision-Recall曲线,AP值为Precision-Recall曲线与坐标轴所围成的面积。
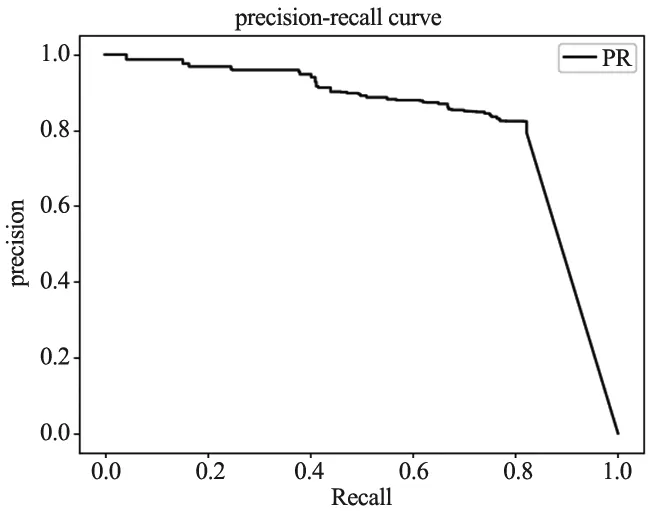
图10 Precision-Recall曲线
为了防止测试结果的偶然性,采集不同数量零件的图片各50张,分别对AP50指标进行3次测试,测试结果如表2所示。可以看出,当场景内包含少量零件时,零件与零件之间遮挡情况较少,纹理和轮廓清晰,与场景中包含较多零件时相比,三种模型的AP值较高;模型2的训练集中包含了加噪的图像,测试结果表明,加噪后训练集训练的模型2与模型1相比检测和分割的精度有了明显的提升;模型3在三种模型中效果最好,训练集中既包含了虚拟图像及其加噪后图像,又包含了由10张真实图像旋转扩展后的100张图像,能够很好的检测和分割杂乱场景下的零件。
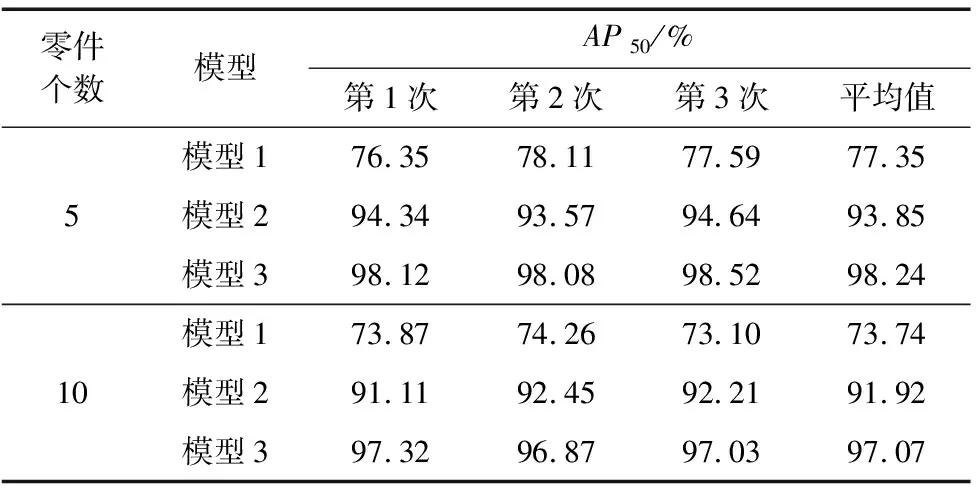
表2 三种模型在不同数量零件下的测试结果
4 结束语
本文提出一种基于零件合成训练集对Mask RCNN进行训练的方法。通过杂乱场景零件训练集合成系统生成了合成训练集,建立了三种不同的训练集分别进行训练,采集了不同零件数目的深度图像对三种训练集训练出的三个模型分别进行测试。对于零件数目为10个的真实图像,虚拟图像训练的模型准确率达到了73.74%,虚拟图像和加噪图像训练的模型准确率达到了91.92%,虚拟图像、加噪图像以及少量真实图像训练的模型准确率达到了97.07%。测试结果表明,利用合成数据集训练的模型,可以有效地对杂乱场景下的零件进行检测和分割。
猜你喜欢
初中生学习指导·提升版(2022年11期)2022-12-09 18:32:16
小学科学(学生版)(2020年10期)2020-10-28 07:52:12
疯狂英语·新悦读(2019年10期)2019-12-13 09:02:32
通信学报(2019年5期)2019-06-11 03:05:56
意林(绘英语)(2018年2期)2018-11-29 03:23:16
通信技术(2018年3期)2018-03-21 00:56:37
小火炬·阅读作文(2017年8期)2017-09-26 06:30:48
Coco薇(2017年9期)2017-09-07 22:09:28
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
浙江大学学报(工学版)(2015年4期)2015-03-01 01:17:53
