
基于语义挖掘的快递运输货品风险评价研究
2021-08-28 07:06:24奇格奇张子贤卫振林李宝文
交通运输系统工程与信息 2021年4期
奇格奇,张子贤,卫振林,李宝文*
(北京交通大学,a.交通运输学院;b.综合交通运输大数据应用技术交通运输行业重点实验室;c.北京市城市交通信息智能感知与服务工程技术研究中心,北京100044)
0 引言
互联网电商平台的普及为人们提供了更加多样性和更富便利性的线上服务,与之相匹配的快递运输作为线下货品的主要流动方式也得到了快速发展。根据国家统计局年度数据显示,2010—2020年间快递量由23.4 亿件上升至833.6 亿件,快递业务收入由574.6 亿元增加至8795.0 亿元,十年间快递量增长近36 倍,快递业务收入增长近15 倍。然而,与快递业务迅猛增长相对应的是相对滞后的快递风险监管与评价方法[1]。在快递运输过程中,营运货车运行风险通常是多因素耦合的结果[2],而快递所运输的货品本身也呈现高风险态势。由于快递运输所具有的成本低、隐蔽性强、地域广的特点,部分不法分子通过快递等物流方式运送犯罪工具,寄递过程中出现快递货品涉恐、涉暴、涉毒、涉枪等危害城市交通与城市运行安全的问题,成为社会治安管理中的不稳定因素,间接地增大了城市安全风险。
目前,国内外关于快递运输货品风险识别方式主要分为两类,一类是通过人工检查核对《禁止寄递物品指导目录》(简称《指导目录》)来发现违禁品,郭小伟[3]指出相关规定通过概括和列举方法对违禁品进行界定,并围绕《指导目录》分析了利用快递运输进行违禁品犯罪的现状、原因及对策;贾健等[4]分析了利用快递寄递违禁品的相关案件,提出快递实名、收寄验视、过机安检的实施和改进有助于快递犯罪的治理。另一类则是通过图像处理和识别技术作为辅助手段,判别货品类别是否为违禁品,Mery等[5]回顾和比较了10种计算机视觉检测算法,并应用于检测行李中的手枪、手里剑、刀片等3 种危险对象,最高达到95%的目标识别准确率;王宇石等[6]利用X 射线安检形成的伪彩色图像,基于卷积神经网络设计和部署了违禁品自动识别系统;张友康等[7]提出一种多尺度违禁品检测网络,基于X光安检图像进行违禁品检测,改进了小尺度违禁品、重叠遮挡、背景干扰条件下的检测效果;Hong等[8]针对快递包裹的X 光图片,提出基于深度卷积神经网络的违禁品识别方法,相较于传统方法识别准确率提高了20%。然而,上述研究大多针对某一类违禁品进行“非黑即白”的二元判断,而未能进一步量化评价快递货品隐含的风险,且相关检测识别方法仍受限于《指导目录》所列举的货品,面对种类繁多的快递运输货品,缺乏一定的自适应调节与扩展特性。
自然语言处理技术的不断进步为从快递货品文本描述中挖掘风险信息提供了新途径。快递货品的文本描述可来自快递员的验视描述、寄件人的货品描述,以及基于图像识别的自动化描述。前两项通常合并为快递订单货品描述,主要在快递订单生成时产生,而自动化图像识别描述主要发生在安检过程。由于后者需要海量图像数据的标定与长时间的模型训练过程,本文中的货品描述主要来自快递订单货品描述。在传统方法中,人工查验和评价快递货品风险仍是当前最主要的风险识别和预警方法,安检人员需要长时间无重点观看扫描图像,容易发生漏检、错检情况,即使利用图像识别技术提高对货品的识别准确率,相应货品的风险程度仍难以评价,需要依赖检验人员的主观判断。
为此,本文针对繁杂的货品描述,利用网络大数据资源提供的法院判决书文本信息,尝试将相关犯罪工具(往往亦为快递运输敏感货物)与处罚轻重程度相关联,结合隐狄利克雷分布与模糊均值聚类方法,以期通过语义分析、文本挖掘方法实现相关货品风险模式的挖掘,进而有效识别和量化快递货品语义风险。一方面能够协助安检工作人员合理分配注意力,另一方面为风险预警及应对方案提供可量化的客观指标依据,有助于提高快递货品风险监测管控能力,降低快递运输货品风险所导致的城市安全事件发生的可能性。
1 网络文本数据
1.1 数据描述
《指导目录》能够为快递货品风险的甄别提供0或1的是非判断,但并不足以提供可量化的快递货品风险值,从而进行针对性的预警和应对。为此,本文由网络文本库中获取约10万份法院公开刑事判决书作为基础数据,尝试从物流领域外部迁移学习货品风险知识。
法院判决书数据来自2018—2019年全国34个省级行政区,以尽可能保证数据不受地域差异影响。法院判决书数据主体字段包含标题、案号、法院、判决日期、原告、被告、庭审过程、判决结果、审判员、书记员、当事人等部分。其中,判决书“庭审过程”“判决结果”字段中与作案工具和判决年限相关的内容涉及到相关物品及其风险的度量,是支撑本文后续研究的关键信息。
1.2 数据预处理
从法院判决书数据中的文本内容截取“作案工具”“判处”等提示语前后的信息,并通过数据搜索防止遗漏。提取完毕后,进行无效信息剔除,除去不含作案工具的特殊案件、维持原判因而无判决结果的案件和重复案件,最后得到35135条可用于后续研究的有效数据。截取信息内容如表1所示。

表1 有效数据截取内容示例Table 1 Examples of extracted content of valid data
2 物品风险词集构建
2.1 物品风险权重
为剥离出更加准确的物品名称,去除作案工具前后的修饰词和其他无关信息,采用Python中文分词组件“Jieba”,对作案工具词条进行分词及词性判定,如表2所示。将作案工具视为词性为名词,即后缀带有“/n”,根据分词及词性标注结果,对其他词性的词(以“/△”表示,△为其他字母)进行去除。此外,名词中仍有大量无用词与之后的语义分析无关,多为判决书中的常见高频词以及日常低风险物品。针对这些词建立停用词表,将这些与风险关联度较低的词剔除后,得到较为简洁准确的风险物品词条,如表3所示。

表2 分词及词性判定示例Table 2 Examples of word segmentation and Chinese part-of-speech
法院判决书中的“作案工具”提供物品词条,而“判决结果”则能够揭示相应物品可能造成的危害,且通常可用判决年限量化处罚程度。为刻画物品风险权重,将判决结果文字描述转化成数字形式,例如“有期徒刑一年六个月”转化成“1.5”,其中“无期徒刑”转化成“30”,“死刑”转化成“50”。若有多个犯罪者则认为主犯判刑即最重刑罚具有代表性,最终判决结果,即转化成最长刑罚年限的数字形式。由此,可量化物品风险权重如表3所示。

表3 物品风险权重示例Table 3 Examples of goods risk weights
2.2 风险词集
由法院判决书文本挖掘获得的风险物品涉及到《指导目录》中18个违禁品类别,图2给出文本挖掘结果中补充《指导目录》的比例情况。可见,针对“管制器具”“吸毒工具”“毒性物质”“枪支弹药”“爆炸物品”“毒品、麻醉药品和精神药品”等类别的补充最为显著,而对“放射性物质”“易制毒化学品”“濒危野生动物及其制品”“生化制品、传染性”“感染性物质”“遇水易燃物质”保留原有集合未予以补充。同时,本文方法中也没有包含“非法出版物、印刷品、音像制品等宣传品”“非法伪造物品”“侵犯知识产权和假冒伪劣物品”“禁止进出境物品”等较难从名称上识别风险的物品类别。

图2 风险词云Fig.2 Risk words cloud
一个词条中物品的风险与物品的风险权重及其发生频率密切相关。通过风险权重值,给定物品词条的重复次数,应用于所有词条生成物品风险词集。在此过程中,更具危害的案件中词条将根据判决结果被多次重复,而在多个案件中的相同词条也将在词集中反复出现,从而综合考虑案件发生频次及其危害程度。图3 为利用本文中判决书数据所获得的风险词云,其中“毒品”的风险最大,这表明其发生频率与可能造成的危害都较大。物品风险词集是后续语义风险分析的输入文本集合。

图1 文本挖掘结果对《指导目录》的补充比例Fig.1 Supplemental proportion of text mining results to guide catalogue
3 语义风险评价
基于语义挖掘的快递运输货品风险评价过程如图3所示,主要由隐含狄利克雷分布与模糊均值聚类作为其核心方法。

图3 基于语义挖掘的快递运输货品风险评价过程Fig.3 Risk evaluation process of express delivery goods based on semantic mining
3.1 隐含狄利克雷分布
隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)[9]是一种常见的文档主题生成模型,它以非监督学习的方式对文本集的隐含语义结构进行学习,多被用于自然语言处理中的语义分析和文本挖掘问题。LDA 主题模型为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。主题是以文档中所有词为支撑集的概率分布,文档中某主题出现的频繁程度越高,表明与该主题关联性高的词有更大概率出现。
本文以法院判决书提取的简洁词条作为主题模型中的“文档”,每个词条中的物品名称作为主题模型中的“单词”,物品风险词集即为“文档”集。每一个词条所属的物品风险主题概率分布θdk与每一个物品风险主题中的物品名称概率分布φkt为

式中:nd,k,nd,j为词条d中归属于主题k与j的物品数量统计;nk,t,nk,l为词集中归属于主题k的物品名称t与l的数量统计;αk,αj为文档中主题k与j的超参数;βt,βl为主题中物品名称t与l的超参数;K为风险主题数量;T为物品名称数量;j和l分别为主题和单词编号。
模型具体学习步骤如下:
Step 1 依据历史数据或经验设定主题数K,并选取狄利克雷分布超参数α和β。
Step 2 初始化主题编号,随机给每一篇文档的每一个单词分配主题编号,将第d条词条中的第q个物品名称定义为wi,其中i=(d,q)是一个二维下标,wi对应生成所述物品名称的主题编号为Zi,。
Step 3 统计物品名称在词集中出现次数以及各个风险主题在词集中的出现次数,并根据式(3),重新计算wi分配到主题Zi=K的概率,从而更新主题编号,表示在集合中去除下标为i的元素,W为风险词集。

Step 4 循环Step 3,并判断循环次数是否达到阈值或满足判断条件。若满足条件,则停止计算,输出θdk与φkt。判断条件为
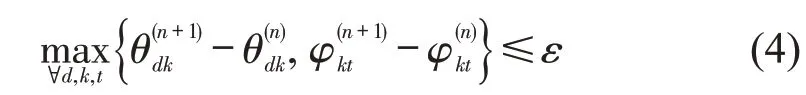
式中:n为迭代次数;ε为迭代停止阈值。
计算不同主题数下模型的困惑度MPerplexity,即

选择最小困惑度所对应的K,即为最佳主题数,式中D为文档数量,即风险词条数量。至此,LDA 主题模型将每个词条用其对应的风险主题分布量化表征。
3.2 模糊均值聚类
模糊均值聚类算法(Fuzzy C-Means,FCM)[10]作为K-means的软聚类版本,被广泛应用于无监督学习工程应用中。本文根据词条的风险主题分布θdk(k=1,2,…,K)及其对应的风险权重换算值δd组成风险词条向量,其中风险权重换算值与风险权重值范围间的设置关系如表4所示。根据上文,风险权重值由案件判决结果获得,数值越高代表刑期越长风险越大,风险权重换算值则是对应地将风险权重值换算为一定区间的标准化数值,设置最低风险值为0.5,最高风险值为1,中间风险值根据不同刑期区间进行设定。在未来研究中,可尝试结合刑法中相关规定进一步标定风险换算值。将风险词条向量代入FCM聚类算法中,根据式(6)与式(7)循环迭代计算,直至收敛。设置不同聚类数C,采用模糊划分系数(Fuzzy Partition Coefficient,FPC)评估聚类效果,获得最佳聚类数,并在此条件下,计算获得最终聚类中心。

表4 物品风险权重换算值Table 4 Conversion value of goods risk weights
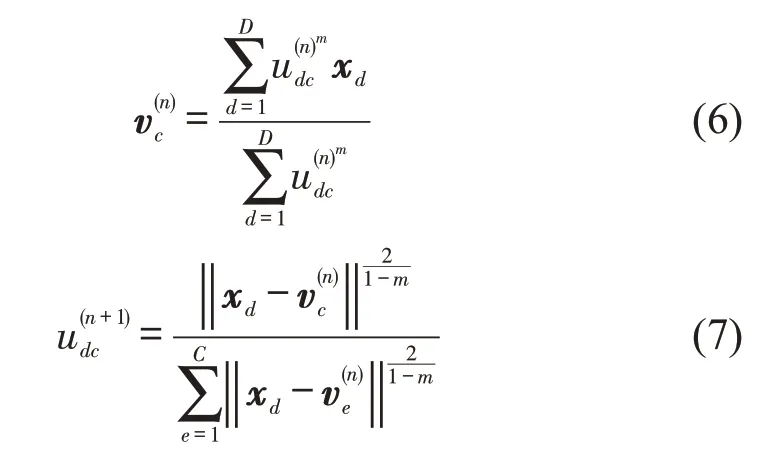
式中:xd为第d个风险词条向量;vc,ve为类别c,类别e的聚类中心;udc为风险词条向量对聚类中心的隶属度;m为模糊因子,其最优取值范围在[1.5,2.5],根据以往研究经验,本文中取m=2.0;C为聚类中心个数;D为词条数量。
提取聚类中心的前K个维度作为快递货品风险评价依据,即快递货品的风险主题分布,并计算风险评价值,从而量化表征快递货品yg的语义风险Rg。

式中:yg为目标快递货品的风险主题分布;hs,he为类别s,类别e的风险主题聚类中心;ugs为目标快递货品g对类别s的隶属度;δs为类别s的风险权重换算值;Rg为快递货品g的语义风险值。
4 结果分析
基于数据预处理后的35135 条法院判决书数据构建出58777个词条组成的风险词集,通过LDA主题模型训练,主题模型困惑度如图4所示,选择困惑度最小的主题数量为4,获得不同风险主题的特征词分布,表5 为各主题中排序前5 的特征词及其概率。其中,所涉及的物品不仅包含“毒品”“海洛因”“砍刀”“枪支”等违禁品,也存在一些如“钳子”“剪刀”“扳手”等不在违禁品清单,但同样在历史案件中多次充当作案工具的风险物品,应根据不同风险评价值采取对应的检视措施。

图4 主题模型困惑度Fig.4 Perplexity of topic model

表5 物品风险主题特征词分布概率Table 5 Keywords probability of goods risk topics
根据LDA 主题模型结果,获得各物品词条的风险主题分布,如图5所示。例如,物品词条“枪支、弹药、毒品”被量化表示为[0.062,0.063,0.321,0.554]的主题分布,即该词条主要由主题4与主题3构成。

图5 物品词条风险主题分布示例Fig.5 Examples of risk topic distributions of goods descriptions
在此基础上,加入风险权重换算值,组成风险词条向量,如“枪支、弹药、毒品”的风险词条向量可被量化表征为[0.062,0.063,0.321,0.554,1.000]。随后利用FCM 聚类算法进行聚类,不同聚类数条件下的模糊划分系数如图6所示,选择模糊划分系数最大的713 类作为最优聚类数。存储模糊聚类类别中心点数据,供式(8)与式(9)计算风险评价值。

图6 模糊划分系数Fig.6 Fuzzy partition coefficient
以物流企业实际订单中的快递运输货品描述,结合模拟风险信息作为异常输入,测试风险评价效果。快递运输货品语义风险评价值超过0.5则被识别为需要进一步预警和应对的风险。设定模拟风险货品总数为1000,正常货品总数为9000。经测试,本文提出方法的识别准确率可达99.63%,误报率为0.37%。表6为部分快递运输货品的语义风险评价结果。可以发现,本文方法获得的语义风险评价值不再是0 或1 的是非判断,能够实现风险的柔性划分,有利于针对性地设置多样化的应对预案,而且所涉及的词条也不再依赖《指导目录》中的固定化表述,使得该方法对于快递运输货品种类繁多的非固定描述具有更好的灵活性与适应性。在物流安检过程中,对于给出语义风险评价值的快递货品,可根据其风险评价值设定不同的管控策略,包括登记备案、开箱检视、规劝取消寄递、予以拒收拒运扣押、通报邮政管理部门、通报公安部门等响应处置。

表6 快递货品语义风险评价值Table 6 Semantic risk evaluation value of express goods
5 结论
本文运用隐狄利克雷分布模型与模糊均值聚类方法,由法院判决书中的“作案工具”与“判决结果”文本数据发现了物品与风险的对应关系,实现了快递运输货品的风险评价。研究表明,该语义挖掘方法不受限于既定的违禁品清单,可在更大范围内实现快递运输货品的语义风险识别与评价。风险主题分析结果说明,快递运输风险货品不仅包含了“毒品”“海洛因”“砍刀”“枪支”等违禁品,也存在一些如“钳子”“剪刀”“扳手”等不在违禁品清单,但同样在历史案件中多次充当作案工具的风险物品。通过对快递运输货品的实例分析,本文所提出方法获得了较好的准确率与较低的误报率,且风险的柔性划分有利于指导更具针对性的预警及应对措施。
猜你喜欢
法制博览(2023年9期)2023-10-05 15:09:06
科学技术与工程(2022年26期)2022-11-01 05:40:14
中国船检(2021年11期)2021-12-04 14:02:26
时代人物(2020年15期)2020-10-09 19:27:25
哈尔滨学院学报(2020年7期)2020-01-19 08:33:08
儿童时代·快乐苗苗(2017年8期)2018-01-24 18:25:42
职工法律天地·上半月(2016年20期)2016-01-31 04:48:00
法制博览(2015年10期)2015-11-06 12:37:22
系统工程学报(2015年5期)2015-02-28 19:54:16
山东纺织科技(2014年4期)2014-04-06 03:37:42
