
基于声纹识别技术的常见模型与发展应用
2021-08-19 08:24曾桂南吴恋何燕琴郭清粉
现代计算机 2021年21期
曾桂南,吴恋,何燕琴,郭清粉
(1.贵州师范学院,数学与大数据学院,贵阳550018;2.贵州师范学院,大数据科学与智能工程研究院,贵阳550018)
0 引言
从古至今,声音在人类信息传递中就有着非常关键的作用,是人类进行交流的主要手段之一。随着时代的变化,科学家们也开始尝试利用人声音特性展开一系列研究。因为不同说话人在发出一段声音时所使用的发声器官——舌头、牙齿、喉头、肺、鼻腔在尺寸和形态方面有所不同,以及受性格、年龄、语言习惯、地域差异等因素的影响,使得要想在现实生活中找到具有完全相同的声纹特征的两个人几乎是不可能。尽管声纹识别在目前的市场上不同于人脸识别、指纹识别具有大范围的应用,但手机、平板电脑等很多电子设备上内置的麦克风,带有录音功能,具有成本低廉,不需要高性能的硬件支持等优势。
1 声纹识别技术的发展历程
纵观声纹识别(说话人识别)技术的发展史,它大约可以被划分为四个时期。而早在上世纪三四十年代,人们就有了对“声纹”的一定认识和了解,在1945年,美国Bell实验室的劳伦斯·科斯塔(L.G.Kersta)等人结合肉眼观察语谱图并进行匹配,就此有了“声纹”的概念。
20世纪40年代到70年代,也就是声纹识别技术发展的第二阶段,在这个阶段,声纹识别的理论体系已经初步建立,而特征参数的提取以及选择成为人们关注之焦点,BS Atal提出了线性预测倒谱系数(LPCC),这种参数稳定性较好,也让该技术在准确率上有了大程度的提高。此后,随着数字信号处理技术的不断发展,研究人员又相继提出了线性预测编码系数(LPC),LSP谱系数等间接特征参数。
在第三阶段,也就是20世纪70年代到80年代末之间,在这个时期,研究人员将重心放在了特征参数的研究和寻找新的模式匹配方法上,在特征参数方面,Steven B.Davivs和Mermel Stein提出了特征参数——梅尔倒谱系数(MFCC),这种参数在不仅能在信号与噪声的比例较低时仍能拥有较好的性能,而且比起线性预测倒谱系数(LPCC)更加符合人的听觉特性,至今仍是应用范围较广,最有效的特征参数之一。同时,矢量量化技术,动态时间规整等新的模式匹配有也相继出现在人们的视野中。
从20世纪90年代到现在,基于最大似然概率统计的模型——高斯混合模型(Gaussian Mixture Model,GMM)的出现,因具有简单、可靠、性能稳定的优点,成为了声纹识别领域的重要技术。于1995年,由Cortes和Vapnik提出了支持向量机(Support Vector Machine,SVM),这种判决模型方法在处理小样本、非线性及高维模式识别中展示出许多独特的优点,使之迅速成为声纹识别的重要建模方式之一。
2 常用特征参数的介绍
2.1 线性预测倒谱系数(LPCC)
提取特征是在实际生活中我们最常见到的任一声纹识别系统中关键的过程。而LPCC是能够体现声道特性,表达说话人个性的重要特征参数,也是LPC在倒谱域中的表示。它具有计算量少,容易实现,元音描述好的优点,可以描述共振峰,去除激励信息,也因此在语音识别中拥有较好的性能,使用范围也较为广泛。

ai代表线性预测系数,cn由倒谱系数通过(1)式和(2)求导,整理可以得到:

再令Z-1的同幂项系数相等,就可以推出线性预测倒谱系数。
2.2 梅尔频率倒谱系数(MFCC)
Mel倒谱系数作为语音识别中被经常使用的特征参数,它的频带划分是基于梅尔刻度上的等距划分,相较于对数倒谱中的线性间隔频带,Mel标度的频率更适应于人类的听觉特性。f表示线性语的音频率,fmel表示转换到Mel域的梅尔频率,它与正常的线性频率有以下关系:

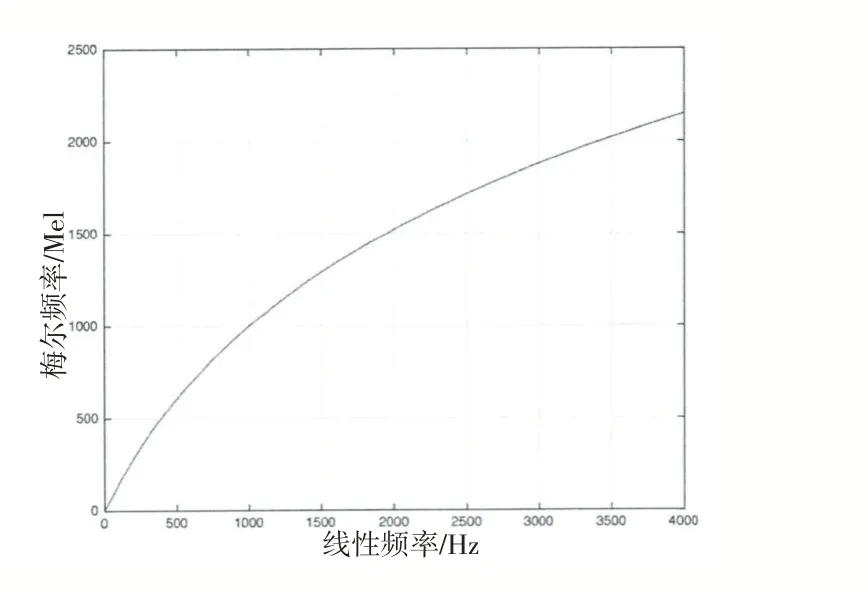
图1
求解MFCC的主要过程:
(1)先对语音信号进行预处理,S(n)用来表示得到的每一帧语音序列。
(2)对每一个短时分析窗,通过傅里叶变换得到对应的频谱。
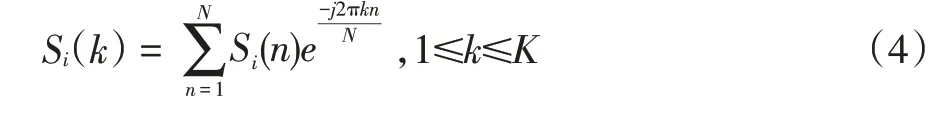
(3)将(2)所得到的频谱通过Mel滤波器组得到Mel频谱,记Pm为输出信号,Hm(k)为频率滤波器组
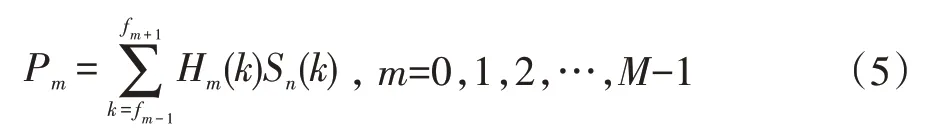
(4)在Mel频谱上取对数,再进行离散余弦变换。
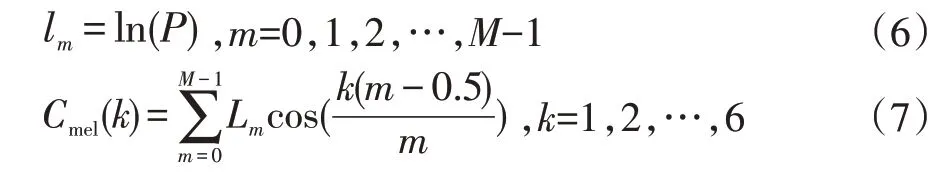
3 常用模型
3.1 GMM和UBM的联合使用
3.1.1 高斯混合模型(GMM)
高斯混合模型(GMM)同隐马尔可夫模型一样,为近年来在“声纹识别”中运用频率较高的一种概率统计模型。简单来说,GMM是由单一高斯密度函数叠加而成的模型,可以用来近似表示任意事物形状的密度分布。ak是系数,φ(y|θk)是高斯密度分布,它满足如下形式的概率分布模型:3.1.2 GMM-UBM
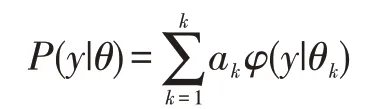
GMM-UBM是在GMM的基础上的一种改进,在实际生活中,每一个说话人能够提供的语音数据十分有限,而往往训练高斯混合模型又需要大量训练数据集,DA Reynolds的团队为了应对这种情况的出现,提出了通用背景模型(UBM),我们可以将不同音源来源人的声音收集起来,将这些背景数据混合起来进行训练,经过自适应算法即可建立目标人说话模型。
基于GMM-UBM模型的声纹确认实现流程如图2所示。

图2
3.1.3 基于GMM-UBM、GMM的声纹系统实验分析
在《基于“互联网+”的声纹识别技术在刑事案件侦破中的应用研究》文献中,实验选取女犯人和男犯人各50名,建立基于GMM-UBM和GMM两种声纹识别系统,在不同条件中选取GMM混合数两个系统的识别率,比较在不同的GMM混合度GMM与GMM-UBM的识别率。得到不相同混合度两个系统的识别率,如表1所示。

表1
经该实验结果可知,在GMM混合度相同的情形下,GMM-UBM系统的识别率要明显优于GMM系统。而GMM混合度增加时,GMM-UBM系统识别率也明显增大。
3.2 深度神经网络DNN
20世 纪 八 十 年 代Rumelhart、Williams、Hinton、LeCun等多人发明的多层感知机(Multi-Layer Percep⁃tron,MLP)改善了单层感知机的不足之处,摆脱了早期离散传输函数的束缚,解决了之前无法模拟异或逻辑的问题。DNN有时也可以被称作多层感知机,也可以将其理解成包含着很多隐藏层的神经网络,如果按照不同层位置的划分,可以将其分三层:输入层、隐藏层,以及输出层。其结构如图3所示。
3.3 CNN和LSTN的联合使用
3.3.1 卷积神经网络(CNN)
2014年,计算机科学家LeCun提出了一种新的深度学习模型——卷积神经网络(Convolutional Neural Network,CNN),它是现在被应用于生物特征识别最流行的网络之一。通过人们在人工智能领域的持续探索,CNN在语音识别、图像识别、图像分割等领域获得了巨大的成功。卷积神经网络通常包括卷积层、线性整流层、池化层和全连接层。
在卷积神经网络中,每层卷积层包含非常多的卷积单元,各个卷积单元的参数又是由向后传播算法得出的。线性整流层,这一层神经的活化性函数使用线性整流,池化下采样,是一种降采样操作。目的是为了减少特征图,把特征切分为几个小片。池化层池化方法众多,一般包含最大池化、均值池化、高斯池化、可训练池化。而全连接层(Fully Connected Layers),在整个卷积神经网络相当于“分类器”将所有的局部特征结合成为全局特征,用来计算最后每一类的得分。CNN网络结构如图4所示。

图4
(2)CNN-LSTM
长短时记忆网络被看作是一种特殊结构的RNN,而在处理中长时间的时序关系时,LSTM更具优势,因此往往会用到LSTM来解决,根据CNN网络、LSTM网络的特性,将两个网络串联结合,构建了以下系列模型如图5所示。
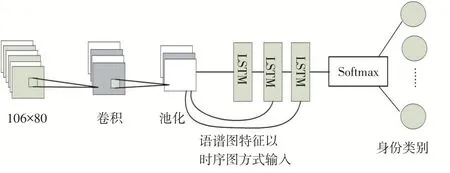
图5
在《基于CNN-LSTM网络的声纹识别研究》一文的实验中[7],对比CNN、DNN、LSTM、CNN-LSTM在不同迭代次数下的准确率结果如表2所示。

表2
不难看出,CNN-LSTM网络能够在较少次数的迭代中达到95.42%的准确率,从时间效率和准确率上看,CNN-LSTM网络更胜一筹。
4 声纹识别的应用分析
目前,声纹识别已在生活的多个方面有了应用,早在20世纪80年代,国外的Home Shopping Network就在基于语音订货的系统中就已经结合了声纹识别的相关技术,而同国外相比,尽管我国在这方面的技术研究起步较晚,但也不甘于落后,像国内的阿里、百度、腾讯等大型公司已经有了相应的产品和应用,在2014年支付宝App就推出了可以根据每个人声音特性的不同从而实现的非密码支付的功能,同年,在iOS上线的WeChat增加了“声音锁”的功能,用声音即可快速实现登录。
总体上说,声纹识别在生活中的应用,大致有以下几个方面。
军事情报方面:用于对电话的监听与追踪。
在社会保险领域:让身体欠佳、出行不便的老年人远程就可实现身份认证。
在进行网络交易时:例如手机网络支付、掌上银行等平台身份确认时,结合密码支付可以提供更高的安全保护机制。
刑侦方面:使用声纹识别,可通过现场遗留的少量的语音消息可以缩小侦查范围判断犯罪嫌疑人的身份特征从而实施追捕,大大提高办案效率。
由于声纹识别相关设备造价低廉,在保安、证件防伪方面也能起到相关作用,可以用于小区门禁系统,对进出小区住户进行记录,还可以用于银行自助取款机,快速识别取款人身份,既安全、便捷,还可以防止有些老年人因为记不住密码而无法取款的现象。
5 结语
如今,就准确率而言,声纹识别技术的识别的准确率在理论上已经高达百分之九十几,但在现实生活中,说话人自身具有的独有气质、身体状况、年龄增长、情感波动等其他干扰因素,导致实际与实验中的理想值还存在一定偏差,仍可能出现对说话人身份产生误判的情况,因此可以提高准确率的方法还需要人们更进一步的发现、探讨、研究。当然,过去的科学技术在不断地被更新,近些年深度学习技术在计算机视觉、自动驾驶等诸多领域都取得了惊人的成绩,在语音识别方面也有了新的突破,相信在不久的未来会有更多、更好的方法去解决我们现在所面临的困难和挑战。
猜你喜欢
计算机应用(2022年9期)2022-09-25
舰船科学技术(2022年10期)2022-06-17
软件导刊(2022年3期)2022-03-25
读与写·教育教学版(2019年9期)2019-10-30
卷宗(2018年14期)2018-06-29
智能计算机与应用(2018年2期)2018-05-23
小资CHIC!ELEGANCE(2018年8期)2018-04-03
电子技术与软件工程(2016年22期)2016-12-26
科技视界(2016年20期)2016-09-29
山海经(2015年18期)2015-04-19
