
距离感知和方向感知的Transformer Encoder用于司法领域实体识别
2021-08-19 08:21曹重阳杨品莉
现代计算机 2021年21期
曹重阳,杨品莉
(四川大学计算机学院,成都610065)
0 引言
由于司法领域中各种司法文件种类繁多、数量巨大、案件复杂等特点,司法信息自动化已经迫在眉睫。司法信息自动化有助于实现司法信息共享[1],完善司法业务流程,优化司法系统,极大地提高相关从业人员工作效率。
近年来,深度学习加持下的自然语言处理技术得到了迅猛发展,其中越来越多的相关技术,例如实体识别[2]、知识图谱[3]等被运用到司法领域,这极大促进了司法信息自动化,提高了司法领域的发展。法律案例文本中存在大量司法领域实体,例如“张三”、“安徽省人民法院”、案卷编号、犯罪类型等,这些司法领域实体的准确识别是后续实现司法事件抽取,构建司法领域知识图谱等技术的前提。
命名实体识别(NER)的任务是在句子中找到一个实体的开始和结束,并为这个实体指定一个类。由于命名实体识别在问题生成[4]、关系提取[5]和参考文献分辨率[6]方面的潜在帮助,命名实体识别在自然语言处理领域得到了广泛研究。命名实体识别通常被看作是一个序列标注任务,神经模型通常包含三个部分:词嵌入层、上下文编码器层和解码器层[10-12],不同命名实体识别模型之间的差异主要体现在这三层。命名实体识别的方法大致可以分为有监督、半监督、无监督和混合方法几种。有监督的实体识别方法:数量巨大的已标注语料库作为模型的输入,比较流行的方法有隐马尔可夫模型、最大熵模型、支持向量机、决策树和条件随机场(Conditional Random Field,CRF)等,其中,基于CRFs的模型在实体识别任务上获得了比较好了效果。半监督的实体识别方法:数据规模小的已标注的小数据集(种子数据)作为模型的输入,让模型自举学习数据的内在结构,大体思路是使用大量的无标注语料库训练了一个双向神经网络语言模型,然后使用这个训练好的语言模型来获取当前要标注词的语言模型向量,然后将该向量作为特征加入到原始的双向循环神经网络(Recurrent Neural Network,RNN)模型中。无监督的实体识别方法:利用词汇资源(如WordNet)等进行上下文聚类。近年来,算力得到不断提升,各种神经模型被引入命名实体识别以避免手工制作的特征[7-9],基于深度学习的命名实体识别方法也展现出很高的识别准确率,此类方法无需大量人工特征,只需词向量和字符向量便可以产生很不错的识别性能,若再加入高质量的词典特征可以是性能更强。此类方法主要思路是把实体识别等价为一个序列标注任务,比较经典的是GRUCRF(Gated Recurrent Unit,GRU)和BiLSTM-CRF[13]等RNN模型。
最近,Transformer[14]开始在各种NLP任务中盛行,如机器翻译[14]、语言建模[15]和预训练模型[16]。Transform⁃er Encoder采用全连接的自我注意结构对远程上下文进行建模,这是RNNs的缺点。此外,Transformer比RNNs具有更充分利用GPUs并行计算的能力。然而,在命名实体识别任务中,Transformer Encoder已经被报告表现不佳[17],因为它既不感知距离,又不感知方向。这个问题在司法裁定书的实体识别任务中更为严重。如图1所示,观察裁定书发现:“审判长、审判员”的后面一般是姓名,“罪犯”的后面一般是姓名,“犯”的后面一般是犯罪类型等;此外词与词之间的距离也很重要,因为只有连续的文字才能形成一个实体,每个实体之间是有间隔的。总之,实体方向和实体距离对司法实体识别任务十分重要。

图1 裁定书标记文本
基于此,本文提出一种距离感知和方向感知的Transformer Encoder模型(DDATE)用于司法领域实体识别系统,实验表明这种距离感知和方向感知是十分有效的。此外本文不仅使用DDATE建模词级上下文,还使用它建模字符级特征。字符编码器不但能够有效捕获字符级特征,而且减缓了OOV问题[8-9,18]。在命名实体识别中,卷积神经网络(CNN)被广泛作为字符编码器[11,19],其有限的感受野限制了字符编码能力[17],而DDATE作为字符编码器能够感知长程上下文且更高效的利用GPUs的并行计算。本文的总体流程图如图2所示,首先对司法案例文本进行规范格式和去除空格等操作,把已标记文本作为实验数据集并输入模型,不同的模型在合理的实验配置下分别进行训练后,对比各个模型的实体识别效果。综上所述,本文利用DDATE对字符级特征和字级特征进行建模,在合理的实验配置下,与基于BiLSTM-CRF模型和普通Transformer模型相比,DDATE大大提升了司法实体识别的性能。
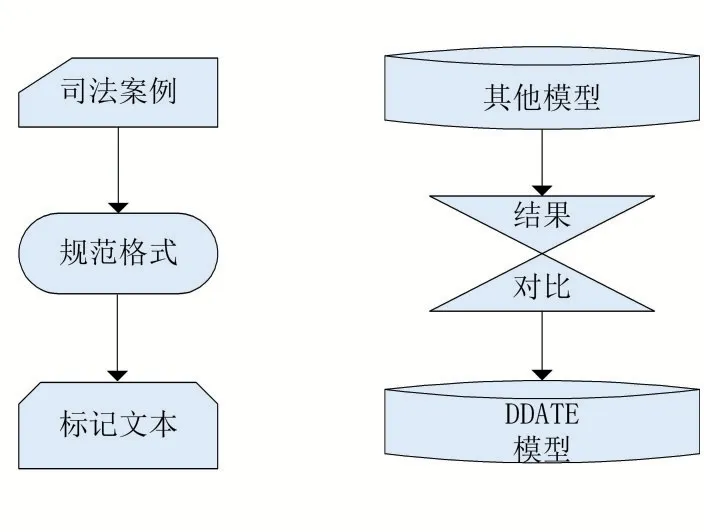
图2 司法领域实体识别流程
1 方法
本文利用DDATE进行裁定书的实体识别,整个网络结构如图3所示。

图3 DDAFE模型
1.1 Embedding Layer
为了缓解数据稀疏性和OOV的问题,大多数NER模型采用了CNN字符编码器。由于Transformer能充分利用GPU的并行性,且具有不同感受野和提取不连续字符的特征的能力,因此将Transformer作为字符编码器是一项很有意义的工作。最终的词嵌入是前训练的词嵌入和字符编码器提取的特征的合并。
1.2 Encoding Layer with DDATE
Transformer在2017年被Vaswani提出[14],它在各种NLP任务中取得了巨大的成功。Transformer Encoder首先接受一个矩阵H∈Rl×d,其中l是序列长度,d是输入维度。然后三个大小为Rl×dk的可学习矩阵Wq,Wk,Wv与H相乘分别得到Q,K,V,其中dk是超参数,公式如下:

其中Qt是第t个token的query向量,j是上下文token的下标。Kj是第j个token的key向量,当使用多组Wq,Wk,Wv时,称为多头自注意力,其计算公式为:

其中n是head个数,h是head索引,通常dk×n=d,所以的大小为WO的大小为Rd×d。多头注意力的输出被前馈网络进一步处理,可以表示为:
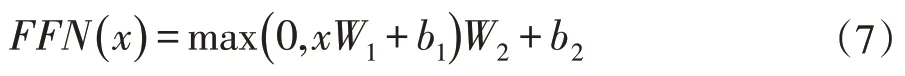
其中W1∈Rd×dff,W2∈Rdff×d,b1∈Rdff,b2∈Rd是可学习参数,dff是超参数。Transformer Encoder的其他组件还有层归一化和残差连接。
由于Transformer中使用的自注意力机制不感知距离,为了避免这一不足,文献[14]使用了正弦位置嵌入,第t个token的位置嵌入可以用如下公式表示:

因此,为了使Transformer具有距离感知和方向感知的属性,提升司法实体识别的准确率,本文基于文献[17,20-21],改进的注意力的公式如下:

其中t是目标token的索引,j是上下文token的索引。为了得到Hdk∈Rl×dk,首先在第二维分割H为d/dk个部分,然后每个head使用一部分。u∈Rdk,v∈Rdk是可学习参数。Rt-j∈Rdk是相关位置编码,是两个token的注意力分数,是第t个token在某一相对位置上的偏置,是第j个token的偏置是某一距离和方向上的偏置。
本文为了减少参数量,没有使用Wk,避免了两个可学习参数的直接相乘,因为它们可以用一个可学习参数表示。多头注意力仍然利用公式(6)。如图3所示,上述改进的能够感知距离和方向的Transformer En⁃coder既被作为字符编码器,又被作为词编码器。
1.3 CRF Layer
为了利用不同标签之间的依赖关系,所提出的模型和所有对比实验的模型均使用了条件随机场。给定序列,金标准标签,所有的有效标签序列的可能性计算公式如下:

2 实验
2.1 数据集准备
把裁判文书网下载的1000份裁定书作为本文的数据集,主要包括减刑案件、假释案件以及暂予监外案件三种案件的裁判文书,随机将其分为6:2:2,分别作为训练集、验证集和测试集。首先进行文本处理,将1000份裁判文书规范格式,去掉空格;然后标记标签,利用语料标注工具YDEEA将裁定书标记为BIO字标签形式,标记好文本后让法学专家进行修改和完善。如表1所示,本实验定义了5类实体类别:姓名、地点、司法单位、案卷编号、犯罪类型,即11类字标签。
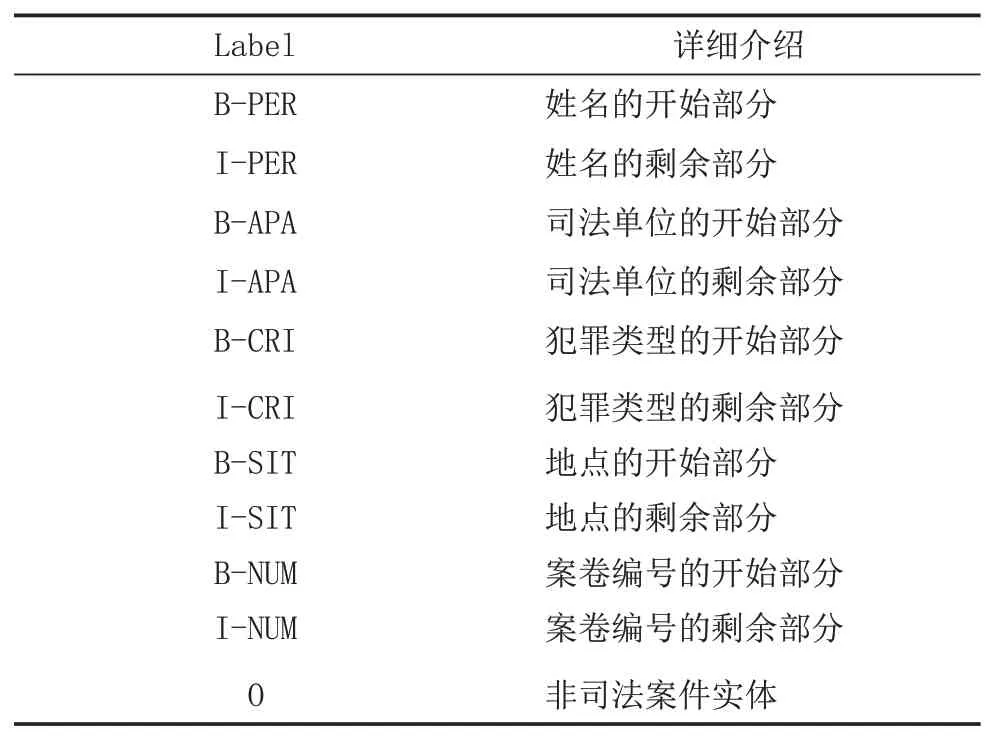
表1 BIO字标签类别
2.2 评价指标
在实体识别任务上,最常用的指标为F1值(F-measure),为了和对比实验进行充分评估,本文还采用准确率(precision)、召回率(recall)作为评价指标。三个评价指标的计算公式如下所示:


2.3 实验设置
所有实验环境由存储空间为8GB的NVIDIA RTX 2070 GPU和PyTorch 1.3框架实现。实验中使用的超参数的设置如表2所示。

表2 训练BiLSTM-CRF模型参数设置
2.4 对比实验及分析
2.4.1 BiLSTM-CRF
长短期记忆模型(LSTM)改进了RNN的长度依赖问题,能够获取任意长度的上下文特征信息。BiLSTM[18]模型由前向LSTM模型和后向LSTM模型组成,可以得到双向的语义信息。本文实现了BiLSTM-CRF模型,其实验结果如图4和表3所示。

表3 不同模型的评价指标比较
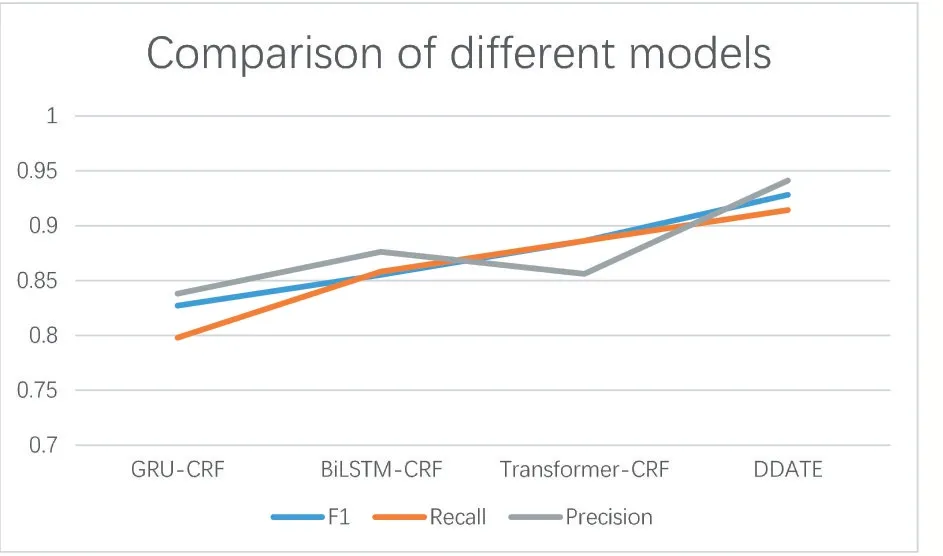
图4 不同模型的评价指标比较
2.4.2 GRU-CRF
门控循环单元(GRU)是LSTM的变体,它较LSTM网络的结构更加简单,只留下能够分别获取序列中长距离依赖关系和断距离依赖关系的更新门和重置门,文也实现了GRU-CRF模型。如表3和图4所示,在三个评价指标上,所提出的模型DDATE与BiLSTMCRF和GRU-CRF模型相比,实体识别性能提升明显。在F1值、召回率和准确率上,DDATE比BiLSTMCRF模型大约分别提升0.6、0.5、0.6。
2.4.3 Transformer-CRF
所提出的模型DDATE是在Transformer Encoder的基础上进行改进的,本文在合理的实验配置下,让普通的Transformer也用于字符编码器和词编码器。如表3和图4所示,在F1值和召回率评价指标上,Trans⁃former-CRF模型高于基于RNNs的模型。但却与所提出的模型DDATE有较大差距。
根据表3,DDATE模型的F1值为0.928,召回率为0.914,准确率为0.941,表明本文所提出的方法具有很好的司法实体识别性能。
图5 是减刑、假释以及暂予监外的裁判文书中的姓名、地点、司法单位、案卷编号、犯罪类型等5类实体进行识别的F1值。可见在裁判文书中不同实体类型的识别中,DDATE模型的实体识别性能均优于Trans⁃former-CRF模型。此外发现司法单位这类实体的评价指标比较低,这可能是由于司法单位实体在裁判文书的位置比较复杂,其前后文字变化较大,这影响了基于Transformers模型的实体识别性能。

图5 所提出的模型对不同实体识别的性能比较
3 结语
本文所提出的DDATE模型用于司法领域实体识别系统,使该系统能在法学专家的容忍下,准确的识别出减刑案件,假释案件及暂予监外案件的裁判文书中的姓名、司法单位、地点、案卷编号、犯罪类型等实体,优化司法业务系统,极大地提高相关从业人员的工作效率,为实现司法信息自动化,研究司法事件抽取,构建司法领域知识图谱打下了基础。
该实体识别系统也存在一些待改进的地方,例如可以通过增加语料,实现更多司法实体类别如法条的识别;还可以通过细分实体类别,如姓名类进一步分出被告人,来获得更准确的实体识别结果。接下来将融合公共数据集与司法领域的数据集来训练模型,这在一定程度上,能有助于模型识别更多的重要实体和提升司法领域实体识别的性能。此外,可以发现图5中的司法单位这类实体识别指标低于其他实体,这是由于如果某类实体在裁判文书中的前后文字的改变幅度大,基于Transformers的模型受长程上下文的影响,使该类实体识别性能下降,这是基于Transformers的模型与生俱来的瓶颈。DDATE虽然能够感知到裁判文书中文字的距离和方向,大大提高了司法实体识别的性能,却逃脱不了这种瓶颈属性。因此,下一步将继续改进Transformers结构,使其能对实体周围的文字进行权重优化,进一步提升司法领域实体识别系统的性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
今日农业(2022年2期)2022-06-01
电脑报(2021年41期)2021-11-04
数字技术与应用(2021年1期)2021-03-24
民主与法制(2020年19期)2020-08-24
民主与法制(2020年16期)2020-08-24
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
科技与创新(2017年5期)2017-03-28
农机使用与维修(2014年10期)2014-10-23
