
基于改进用户相似度的协同过滤算法
2021-08-19 08:21潘锦丰叶东东谭北海余荣
现代计算机 2021年21期
潘锦丰,叶东东,谭北海,余荣
(广东工业大学自动化学院,广州510006)
0 引言
现今,信息过载问题使用户无法高效、准确地找到有用的信息[1]。为了解决上述问题,个性化推荐算法受到学术界广泛研究应用[2]。其中,作为个性化推荐算法中较为经典的协同过滤推荐算法[3],凭借其原理简单和可解释性等优点,广泛应用于社交网络和电子商务等方面。目前,协同过滤推荐算法主要分为基于用户和基于项目两种[4]。本文主要研究的是基于用户的协同过滤推荐算法,本算法主要通过以下四个步骤实现个性化推荐。第一,建立用户-项目评分矩阵;第二,计算用户间的相似度并找到最近邻用户集;第三,根据最近邻集合预测用户没有评分的项目;第四,对评分结果排序将N个评分最高的项目推荐给用户[5]。但是传统的用户相似度计算,如皮尔逊相似度[6]、余弦相似度[7]、杰卡德相似度[8]以及修正余弦相似度[9]等还是无法有效地同时解决用户共同评分项目数、评分数值和项目热门度差异问题,导致评分预测不准确,进而使推荐质量下降[10-11]。
为了解决上述问题,大量学者提出了许多创新和改进,以此对用户进行准确推荐。郑翠翠等人[12]提出融合杰拉德相似度和皮尔逊相似度的乘积作为新的算法,降低了共同评分项目数对计算结果的影响。肖宇航等人[13]在皮尔逊相似度计算的基础上考虑了共同评价的项目数和项目热门度两个因素,来降低平均绝对误差。李德新等人[14]将用户相似度计算细分为共同评分项目数、评分数值、评分倾向和项目热门度四个方面并提出改进方法,提高评分预测准确度。上述研究工作虽然在一定程度上降低了评分预测误差,但是不能很好解决高度依赖共同评分项目数量这一问题,当共同评分项目数量较少时容易进一步加剧评分预测误差。因此,本文提出一种融合了权重余弦相似度和修正余弦相似度的改进用户相似度计算算法。该算法不仅能够缓解用户共同评分项目数差异问题,而且通过引入两个修正因子分别改善评分数值差异和项目热门度差异问题。通过MovieLens数据集进行实验验证提出的改进算法在平均绝对误差(Mean Absolute Error,MAE)方面优于现有的基准相似度算法。另外,提出的改进算法在预测用户评分的准确性和推荐质量两个方面具有良好的鲁棒性。
1 传统的相似度计算方法
1.1 余弦相似度
余弦相似度是计算出两个向量之间的夹角对应的余弦值,并作为衡量两者差异的标准[15]。在计算过程中,忽略具体的评分数值,将用户有过评分记录的记为1,没有评分记录的为0,这样就可以得到用户的n维评分向量。用户u和v两组评分向量分别用u和v,计算出的余弦值越大,则说明用户之间越相似。

1.2 皮尔逊相似度
皮尔逊相似度计算的取值范围为[-1,1],数值不同代表不同的相关性,正数表示正相关,负数表示负相关[16]。计算公式如下。

其中,Iuv为用户u和用户v的公共评分集合,也就是两者都有的评分的项目的集合;Ru,c和Rv,c分别是用户u、用户v对项目c的评分分别为用户u和用户v在公共评分集合Iuv中的评分均值。
1.3 修正余弦相似度
修正余弦相似度也是一种传统的度量方式,它是在皮尔逊相似度的基础上改进,因其在相似度计算过程中考虑了评分尺度[17],避免评分倾向造成的评分偏差,使得度量相似度更加合理,因此被广泛应用。修正余弦相似度和皮尔逊相似度两者的主要区别在于分母上。

其中,Iuv为用户u和用户v的公共评分集合;Ru,c和Rv,c分别是用户u、用户v对项目c的评分;Iu和Iv分别是被用户u和v评价了的项目集合;分别为用户u和v在各自评分集合上的评分均值。
2 改进的相似度计算方法
随着建立的用户数和项目数量日益扩大[18],使得所建立的用户-项目评分矩阵越来越稀疏。上述相似度计算虽然已经得到了广泛应用,但是计算过程中仍然难以找到真实最近邻居集。下面介绍了传统的相似计算方法中存在的缺点和改进之处。
2.1 用户共同评分项目数量差异
使用传统相似度(公式1-3)计算用户相似度时,需要先找出用户之间的共同评分集合,对于稀疏的评分矩阵,共同评分集合数量的多少直接影响着相似度度量的准确性。表1分别列出用户1-3对项目1-5的评分,评分尺度为5分制,空白表示用户未对该项目评分。

表1 用户-项目评分(1)
对于表1,采用上述三种传统的相似度计算公式分别计算出用户1与用户2、用户1与用户3之间的相似度,结果如表2所示。
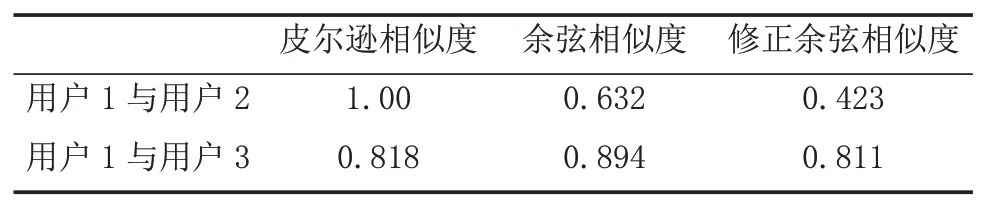
表2 不同相似度公式计算结果(1)
由表2可见,皮尔逊相似度计算出用户1与用户2之间的相似度为1,而用户1与用户3共同评分数量明显比前者高,计算出来的相似度却是较低的0.818,这明显不和理。另外,由于在计算用户相似度过程中,余弦相似度考虑的是用户所有评分过的项目,修正余弦相似度考虑了用户所有评分的均值,所以它们计算出来的相似度是考虑了共同评分数量差异这一缺陷的。因此,为了更好地解决这一差异,本文提出采用权重因子α,综合考虑余弦相似度和修正余弦相似度来缓解这一问题,公式如下。

其中,simcos(u,v)与simacos(u,v)分别代表余弦相似度(公式1)和修正余弦相似度(公式3)。
2.2 评分数值差异
传统的相似度计算的是两个用户评分向量的趋势相关性,忽略了用户对同一项目具体评分数值的差异,这导致了每个项目计算时都存在这一问题。同样地,表3分别列出用户1和2对项目1-5的评分。

表3 用户-项目评分(2)
对表3采用余弦和修正余弦相似度计算公式分别计算出用户1与用户2之间的相似度,结果如表4所示。

表4 不同相似度公式计算结果(2)
如表3、表4,用户1与用户2对每个项目的评分数值差距很大,换句话说,他们彼此之间的兴趣点并不相同,而计算出来的用户相似度却为1。余弦相似度在计算过程中考虑的是用户的评分记录,不关注具体评分数值,修正余弦相似度计算的是两个评分向量的趋势性,可见,它们在计算过程中忽略用户具体评分数值差异,所以本文提出评分数值修正因子,公式如下所示。

pun1(u,v)是衡量用户之间评分数值差异的修正因子。其中,Iuv为用户u和用户v的公共评分集合;Ru,c和Rv,c分别是用户u、用户v对项目c的评分;n为用户u和v的共同评分集合的个数。当两个用户之间的评分数值均值差距越大,计算出的修正因子越小。
2.3 项目热门度差异
传统的相似度计算中,每一个项目都是一视同仁,即权重值一样。但是在实际评分矩阵中,每个项目受到用户评分的记录数是不一样的,对于几乎人人都评价过的项目,可以说它很受欢迎,很热门的项目。但是,对于一个热度高的项目,往往并不能代表用户的兴趣,比如说,生活必需品是每个人都必备的,但是却不能以它来区分人群,所以应该降低热门项目在相似度计算过程中的影响;反而,冷门的项目更能反映出用户的兴趣,应该增大冷门项目的影响。本文提出了项目热门度修正因子,如下所示。

公式(7)中pun2(i)代表衡量项目i的热门程度修正因子。其中,counti是对项目i有过评分记录的用户数,all是评分矩阵中所有的用户数。
2.4 最终改进的相似度算法
综合考虑2.2-2.3小节所述,将评分数值修正因子和项目热门度修正因子分别引入公式(4)中的余弦相似度和修正余弦相似度,以减少评分数值差异和热门项目对相似度的影响,最终本文提出的新的用户相似度计算方法如公式(7)所示。

其中:
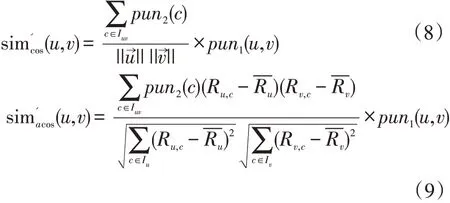
3 实验结果及分析
3.1 实验数据集
本文使用GroupLens提供的MovieLens电影推荐数据集进行计算实验。该数据集包括943个用户在1682部电影的100000个评分记录,评分值为1-5分,每条评分包含用户id、影片id、评分数值和评分时间。本文对全集100000条评分记录随机分成了80%和20%的训练集和测试集。
3.2 实验步骤
3.2.1 建立评分矩阵
根据训练集建立用户-项目评分矩阵,其中每一行代表一个用户,每一列代表一个项目,矩阵中具体数值代表用户对该项目的评分数值。
3.2.2 最近邻用户集K
采用相似度计算公式计算用户之间的相似度,根据相似度的计算结果从高到低进行排序,最后根据实验设定的K值取出前K最相近的用户作为最近邻用户集。实验中的K取值范围为5-80。
3.2.3评分预测
根据最近邻用户集和用户的历史评分信息,通过下面的公式对用户未评分过的项目进行评分预测。

其中,Pu,c代表预测用户u对项目c的评分数值;N(u)是指步骤2中用户u的最近邻用户集合指用户u和v的平均评分。
3.3 评价指标
本文使用平均绝对误差MAE作为计算指标,MAE反映了用户对该项目实际的评分和预测得出的绝对误差,计算的MAE越小表示预测更准确,具体公式如下。

对于测试集T中的一个用户u和物品c,ru,c是用户u对物品c的实际评分,pu,c是推荐算法预测出来的评分,n表示测试集中的所有用户对项目的评分记录数量。
3.4 实验结果分析
3.4.1 引入修正因子的有效性验证
首先,由于本算法在余弦相似度和修正余弦相似度上考虑了用户评分数值差异和项目热门度差异,并加入相应的修正因子,因此,需要验证引入这一步骤的有效性。表5是实验得出的结果。最近邻用户集数量K选取为5、10、20、30、40、50、60、70、80,以MAE计算值作为评价指标。其中的COS、ACOS、COS-P、ACOSP分别是采用相似度计算公式(1)、(3)、(8)和(9)的计算结果。
根据表5的计算,对比结果如图1所示。

表5 引入修正因子后的MAE
依图1,余弦相似度、修正余弦相似度在引入修正因子后MAE都有所降低,前者降低的幅度较大,后者在K≥50时逐渐与未加入修正因子的效果几乎保持一致,证明本文对余弦相似度和修正余弦相似度引入修正因子是有效的。

图1 引入修正因子后的MAE对比
3.4.2 确定权重因子α
由图1可知,当K=30和40时,COS-P和ACOS-P在此数据集中计算出的MAE取得较小值,即在这一范围两者效果较好。因此,改变公式(7)中权重因子α在0.1-0.9的取值(步长为0.1),对比不同α计算出来的MAE结果,如表6所示。
根据表6的计算,对比效果如图2所示。

表6 K=30和40时不同α对应的MAE
如图2所示,改变α的取值,当α=[0.1,0.7],K=30时计算出的MAE明显比K=40时低。同时,在K=30下,当α等于[0.1,0.3]之间时,MAE值逐渐降低,之后,随着α的增高,MAE值不断上升,所以当α为0.3时,MAE取得最小值。

图2 K=30和40时不同α对应的MAE对比
根据表5和表7的相关数据,作出对比图如图3。

图3 权重COS-P和ACOS-P的MAE对比(α=0.3)

表7 权重COS-P和ACOS-P的MAE(α=0.3)
如图3所示,融入权重因子(α=0.3)之后的新的用户相似度计算方法可以进一步降低MAE,更有效地计算相似度,使预测用户评分更准确。
3.4.3 不同相似度计算方法的MAE比较
为了检验本文所提出的新的用户相似度算法(α=0.3),在协同过滤中使用传统的余弦相似度(COS)、修正余弦相似度(ACOS)、文献[14]提出的类似计算方法进行比较实验,对比使用不同用户相似度计算方法下的MAE值如表8所示。
根据表8的计算结果作图对比效果。

表8 不同相似度计算方法的MAE
根据图4的实验结果,在基于用户的协同过滤算法中,本文提出的新的相似度改进算法能得到更低的MAE,当邻居数K为5时,比修正余弦相似度计算出的结果大约低1.0%,比余弦相似度大约低1.7%,随着K的增大,MAE取值整体趋向稳定,在K=30时MAE取得最小值,评分预测误差得到降低。

图4 不同相似度计算方法的MAE对比
3.4.4 多次实验验证
为了验证本文算法的稳定性和有效性(α=0.3),对MovieLens全集数据随机分成80%训练集和20%测试集进行实验计算平均MAE,实验次数共5次(记为T1-T5)。实验结果如表9所示。
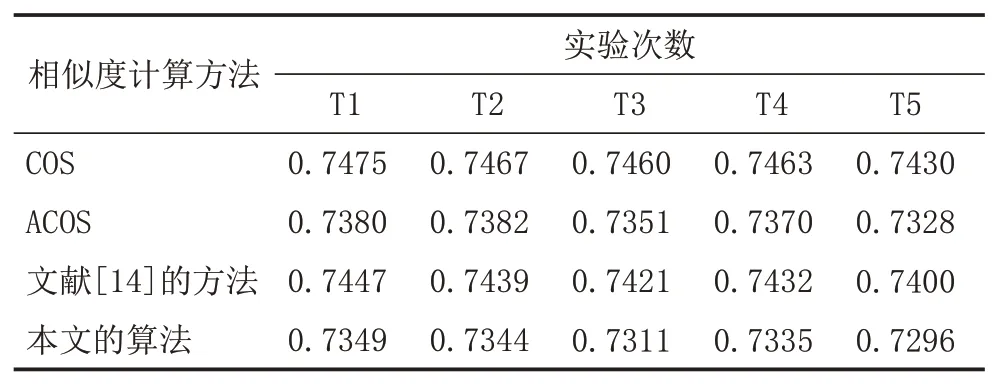
表9 多次实验的平均MAE
根据表9进行作图对比效果,如图5所示。

图5 多次实验的平均MAE对比
如图5所示,使用本文提出的改进用户相似度计算方法求得的平均MAE值都低于使用其他相似度计算方法的求得的MAE值,多次对比实验结果表明,本文改进的算法效果稳定有效,提高了用户评分预测的准确度,具有良好的鲁棒性。
4 结语
本文对基于用户的协同过滤推荐算法中用户相似度计算进行改进优化,提出一种融合权重余弦相似度和修正余弦相似度的新的用户相似度计算公式,并引入评分数值和项目热门度两个修正因子。实验结果显示,引入修正因子是有效的,同时,融合权重后的算法能更进一步降低评分预测误差。多组实验数据验证,本文方法能更好地提升推荐效果,具有良好的鲁棒性。
接下来将会考虑在对不同数据集进行实验测试,继续提高本算法的鲁棒性和运行效率。
猜你喜欢
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
计算机辅助工程(2018年2期)2018-06-03
中学数学杂志(高中版)(2016年6期)2017-03-01
福建中学数学(2016年7期)2016-12-03
智能制造(2015年7期)2015-11-20
旅游纵览(2015年8期)2015-09-25
大众创业(2009年10期)2009-10-08
现代计算机(2009年1期)2009-03-03
