
基于灰色关联分析与遗传神经网络的襄阳市物流货运量预测
2021-08-12 08:57齐兴敏徐海段晨樊锐
物流技术 2021年7期
齐兴敏,徐海,段晨,樊锐
(1.湖北物资流通技术研究所,湖北 襄阳 441002;2.襄阳市交通物流发展服务中心,湖北 襄阳 441099)
0 引言
现代物流业是支撑国民经济发展的基础性、战略性、先导性产业。襄阳市作为湖北省的第二大城市和省域副中心城市,近年来现代物流业得到了快速发展,物流业增加值和社会物流总额不断增长,物流总费用占GDP比重逐年下降,物流产业降本增效效果显著。近几年襄阳市又先后被确定为国家流通领域现代供应链体系建设试点城市、绿色货运配送示范城市和生产服务型国家物流枢纽承载城市,物流业在推动襄阳市经济、社会全面发展方面的作用越发突出。
襄阳市物流货运量稳步提升,据不完全统计,襄阳市2010-2019年十年间货运量增长近3倍。据襄阳市社会物流统计分析发现,货运量不仅受地方经济发展指标GDP的影响较大,而且还与其他经济指标密切相关。为此,本文做两个方面的研究:第一,利用灰色关联分析法,找出与货运量变化关联度比较大的经济指标;第二,采用遗传BP神经网络,将这些指标作为神经网络的输入值,建立襄阳市物流货运量的预测模型。期望通过模型预测襄阳市未来的货运量,为襄阳市交通基础设施建设、襄阳市中长期物流发展规划等提供决策依据。
1 货运量的灰色关联因子分析
灰色关联分析法是根据各因素之间发展趋势的相似或相异程度(即灰色关联度)来衡量因素之间关联程度的一种方法,适合数据动态历程的量化分析。而物流货运量及其相关影响因素的研究刚好是对动态数据的变化历程进行量化研究与分析,并找出这些动态数据变化之间的关联性,所以本文选取灰色关联分析法分析襄阳市物流货运量变化的影响因素。灰色关联分析步骤如下:
1.1 基准序列和比较序列的选择
选取襄阳市物流货运量(万t)作为基准序列X0,选取经济指标地区生产总值GDP(亿元)(x1)、第一产业产值(亿元)(x2)、第二产业产值(亿元)(x3)、第三产业产值(亿元)(x4)、全社会交通运输行业固定资产投资(x5)、公路线路里程(km)(x6)、进出口总值(万美元)(x7)、社会消费品零售总额(亿元)(x8)、人均GDP(元)(x9)共九个因素作为比较因素序列。样本数据见表1。
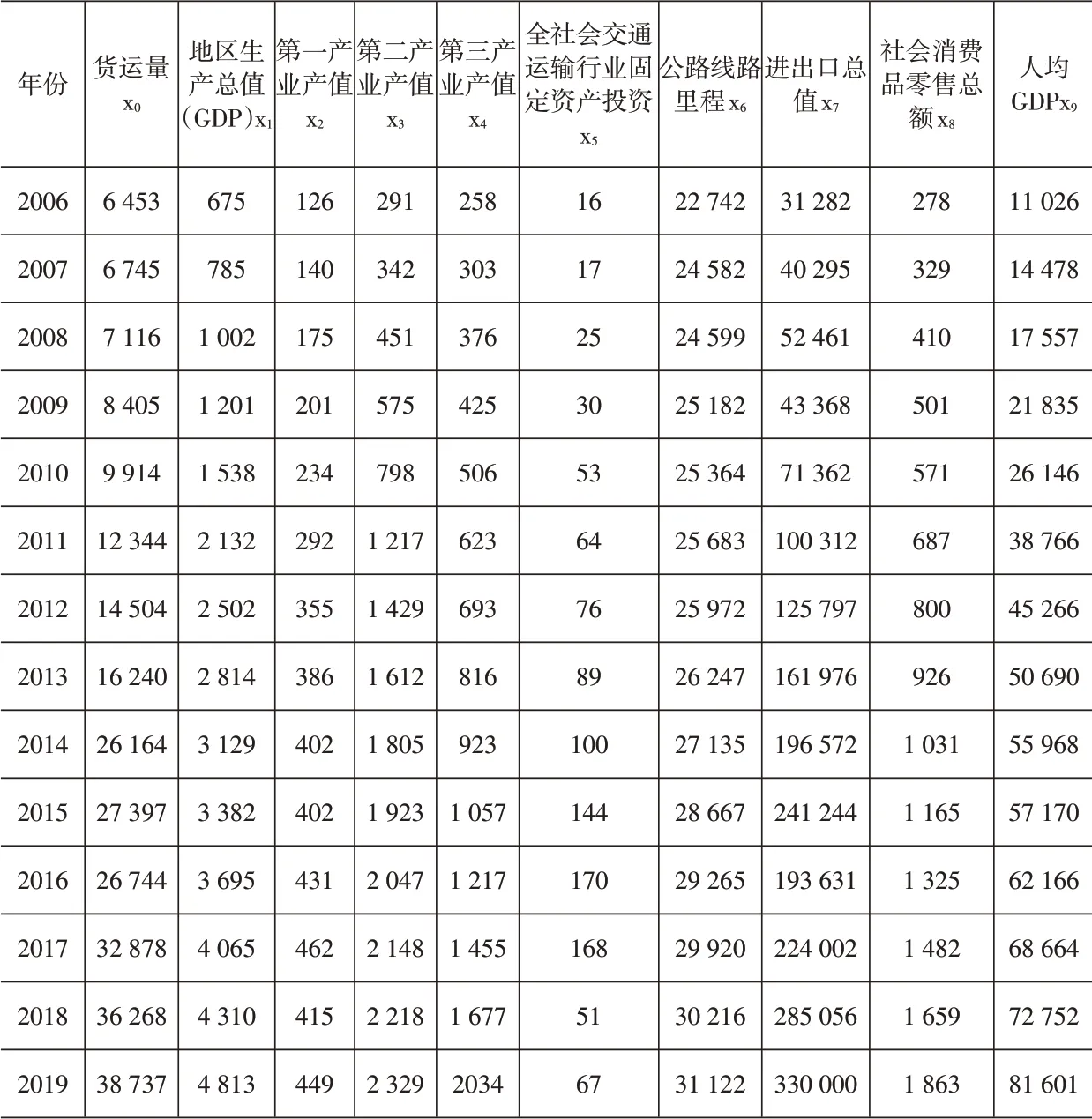
表1 样本数据
1.2 原始数据的无量纲化处理
选取常用的标准化处理方法、最大最小差值化处理方法、最大值处理方法、最小值处理方法、平均值处理方法、初值化处理方法六种无量纲化处理方法对步骤一中数据进行处理,以保证关联度的可靠性。
(1)标准化处理方法
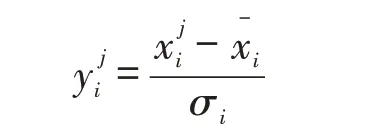
其中,i=0,1,2,...,n,j=1,2,...,m。n为比较序列中因素数目,本文中n=9;m为样本数,本文中取襄阳市2006-2019年的样本数据进行研究,所以m=9,下同。为样本数据的平均值,σi为样本数据的均方差。
(2)最大最小差值化处理方法
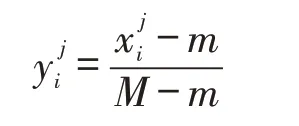
其中M和m分别为样本值的最大值和最小值,下同。
(3)最大值处理方法

(4)最小值处理方法
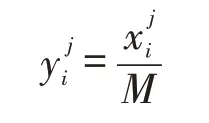
(5)平均值处理方法
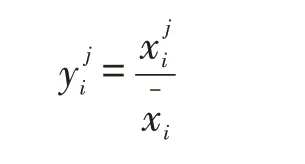
(6)初值化处理方法
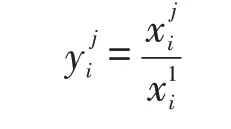
由于篇幅有限,本文只给出了最小值无量纲化处理方法处理表1样本数据后的结果,见表2。

表2 原始数据采用最小值无量纲化处理方法得到的结果
1.3 关联度计算
计算物流货运量和地区生产总值GDP、第一产业产值、第二产业产值、第三产业产值、全社会交通运输行业固定资产投资、公路线路里程、进出口总值、社会消费品零售总额和人均GDP九个关联因素之间的关联系数和关联度。
关联系数计算公式[1]如下:
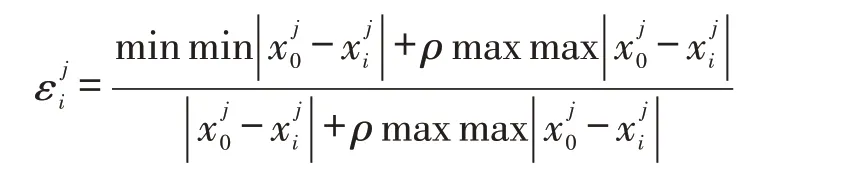
其中ρ为分辨率,范围在(0,1],本文取0.5[2]。
关联度的计算公式如下:
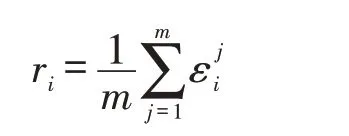
利用关联度计算公式计算出采用每一种无量纲化处理方法下得到的物流货运量和九个关联因素之间的关联度,见表3。表中R1-R9依次表示物流货运量与地区生产总值GDP、第一产业产值、第二产业产值、第三产业产值、全社会交通运输行业固定资产投资、公路线路里程、进出口总值、社会消费品零售总额和人均GDP九个关联因素之间的关联度。表中的数值分别表示某一个影响因素采用某种无量纲化处理方法得到的与物流货运量的关联度,如第一个数字0.847 3,表示采用标准化无量纲化处理方法得到的货运量与关联因素地区生产总值的关联度为0.847 3,依此类推。
将表3中各种无量纲化处理方法计算得到的关联度进行排序,排序结果见表4。
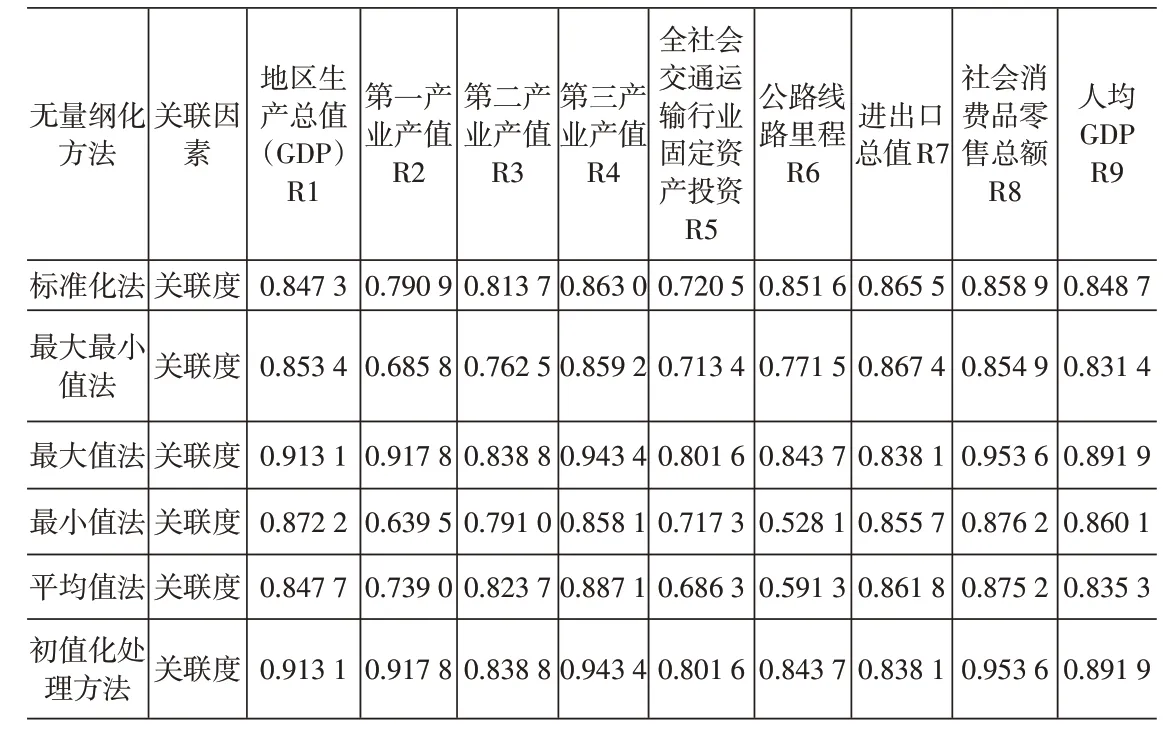
表3 采用六种无量纲化处理方法计算得到的关联度[3]
从表4可以看出,采用不同的数据无量纲化方法会导致关联序的排序各不一样。所以要找出一个最优关联序。
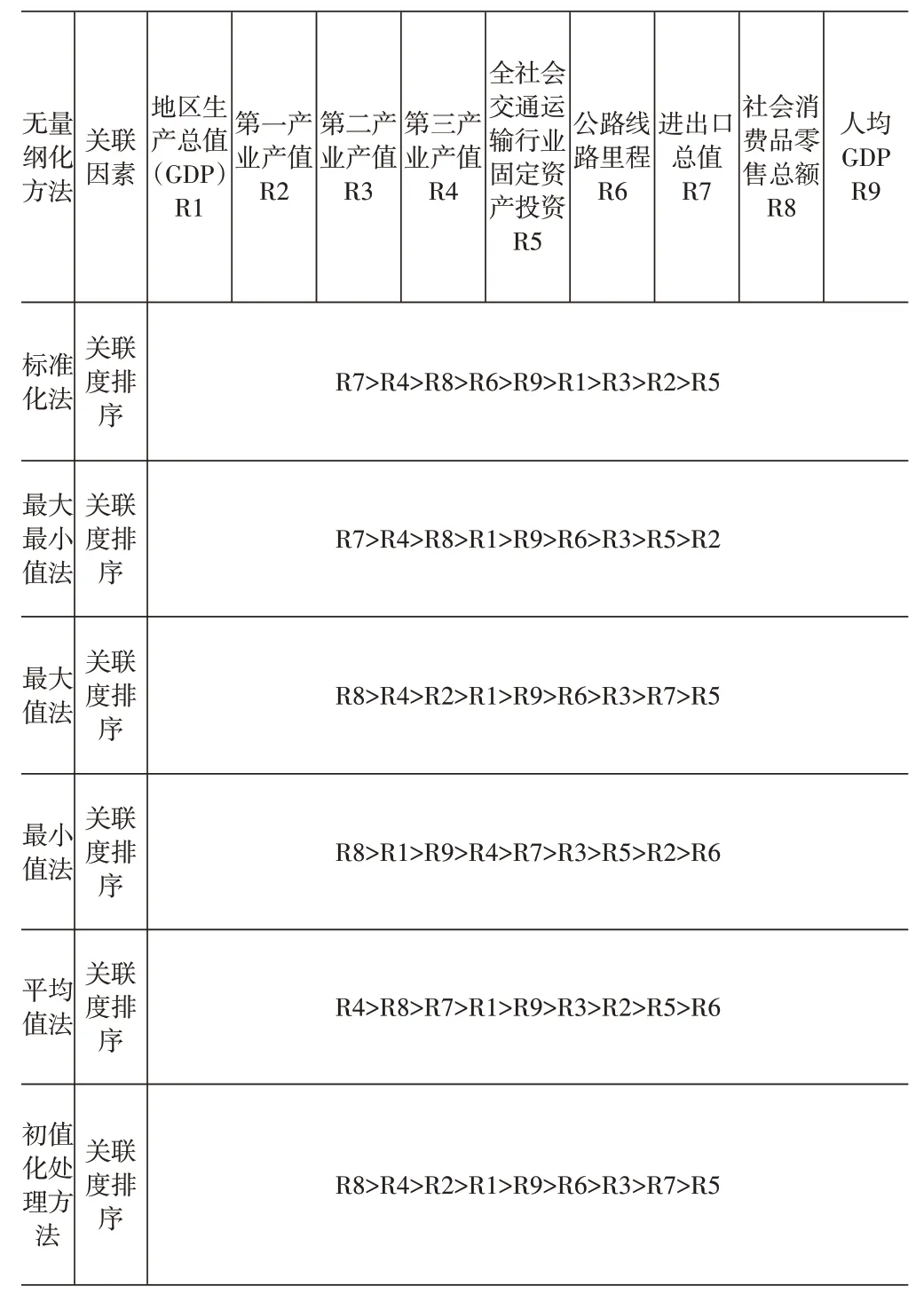
表4 六种无量纲化处理方法计算得到的关联序
1.4 确定最佳关联序的确定
六种无量纲化处理方法的Δk和σk见表5。
依据满足Δk和σk同时最大的原则,从表5可知最小值处理方法得到的关联序满足Δk和σk同时最大,故为最佳关联序。至此得到襄阳市物流货运量的最佳影响因素关联序为:R8>R1>R9>R4>R7>R3>R5>R2>R6,具体关联度值见表6。
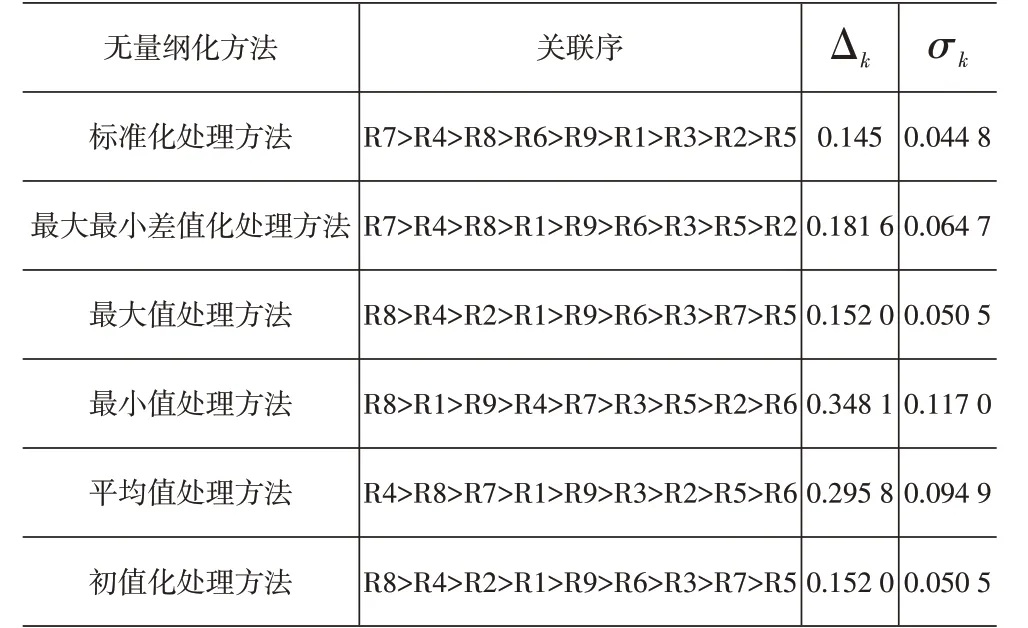
表5 六种无量纲化处理方法的Δk和σk
从表6可以看出,地区生产总值、第三产业产值、进出口总额、社会消费品零售总额、人均GDP的关联度均大于0.8,与物流货运量的关联度很好;第二产业产值和全社会交通运输行业固定资产投资的关联度在0.7-0.8之间,与物流货运量的关联度较好;第一产业产值和公路线路里程两个因素与物流货运量的关联度<0.7,与物流货运量的关联度相对较差。所以去除第一产业产值和公路线路里程两个关联度较差的影响因素,将剩下的七个影响因素选做遗传神经网络模型的输入神经元。
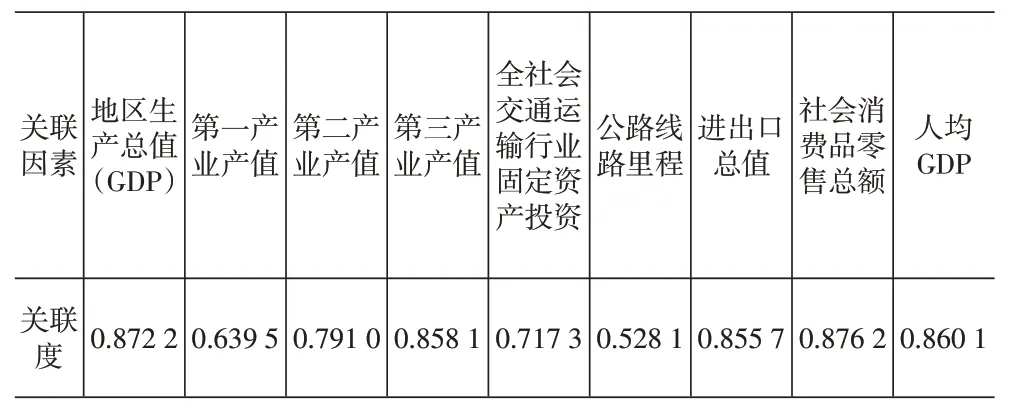
表6 襄阳市物流货运量影响因素最佳关联度
2 遗传神经网络预测模型的建立
2.1 BP神经网络及遗传算法[5]
考虑到货运量的影响因素复杂多样,且具有不确定和非线性的特点,单一的BP神经网络模型预测精度不高,所以本文选取BP神经网络和遗传算法两种组合模型进行建模。BP神经网络的一次学习过程由正向传播和反向传播两个子过程组成。正向传播时由输入单元输入学习样本,经隐层单元处理、输出单元处理后得到样本的输出值;误差反向传播时将样本的输出值与期望输出值做比较,若输出值达到期望的结果,则学习过程结束;否则进入反向传播过程,把输出值与期望输出值的误差由输出单元向输入单元反向传播,在传播过程中修改各层神经元的连接权值。
遗传算法(GA)是模拟达尔文的遗传选择和自然淘汰的生物进化过程的计算模型。其思想源于生物遗传学和适者生存的自然规律,是具有“生存+检测”的迭代过程的搜索算法。遗传算法首先对数据进行编码,将它们转换成遗传的基因型表示,然后随机挑选一组编码作为进化的第一代群体,经过选择、交叉和变异操作生成新一代种群,最后通过新老个体产生下一代群体,算法不断重复,直到满足结束条件后终止。相对BP算法而言,遗传算法具有全局优化搜索功能,能够克服BP算法容易陷入局部最优的缺点,所以两算法结合,各取所长,在很多领域中广泛应用。
2.2 遗传神经网络预测模型的建立
遗传神经网络预测模型采用GA算法对BP神经网络的初始化权值和阈值进行快速优化,定出一个较好的解空间,然后将此空间作为神经网络初始化权值和阈值,再利用BP神经网络局部搜索能力强的优点进行精确寻优,找出神经网络权值和阈值的最优解。
根据前述灰色关联度计算结果,选取货运量关联度比较大的七个影响因素地区生产总值(GDP)、第二产业产值、第三产业产值、全社会交通运输行业固定资产投资、进出口总值、社会消费品零售总额和人均GDP作为神经网络的输入层,输出层为货运量。
2.2.1 模型初始化参数的设定。本文基于MATLAB2014建立神经网络。根据前面灰色关联度的分析结果,选取关联度较大的货运量影响因素作为BP神经网络的输入层神经元,输出层为货运量。神经网络的输入层神经元个数为7,隐含层神经元个数通过试算法确定,最大为9个,输出层神经元的个数为1。神经网络训练模型设置的最大迭代次数为5 000次,学习率为0.01,训练精度为0.000 01。
2.2.2 遗传神经网络的实现步骤
(1)编码与初始化种群的建立。编码串由控制基因串和参数基因串两部分组成。控制基因串由0和1组成,0表示无连接,1表示有连接。参数基因串表示神经网络的权值和阈值。设置迭代次数为100次,种群规模为50,编码规则为:s=in*hide+hide*0ut+hide+0ut,in为输入层节点数,hide为隐含层节点数,0ut为输出层节点数。
输入层到隐含层的权值矩阵为:
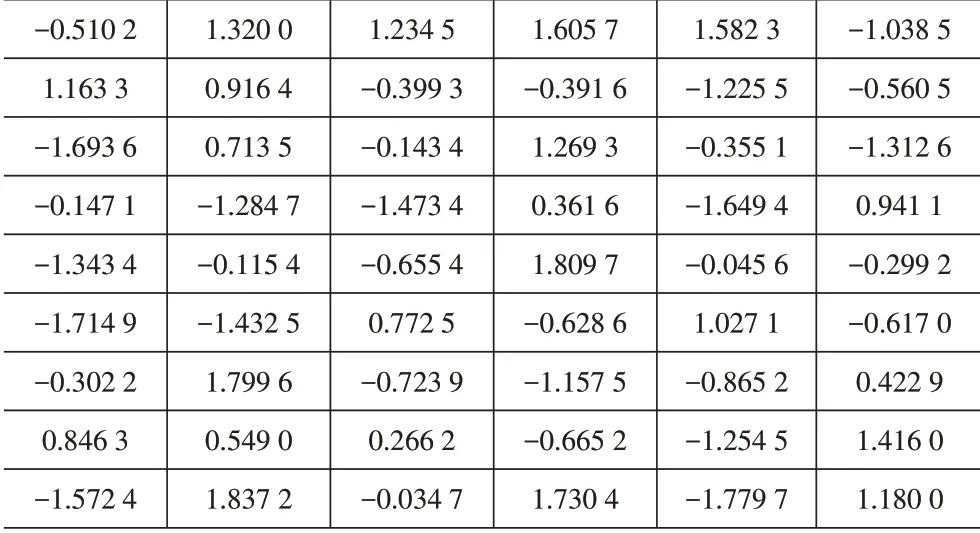
-0.510 2 1.163 3-1.693 6-0.147 1-1.343 4-1.714 9-0.302 2 0.846 3-1.572 4 1.320 0 0.916 4 0.713 5-1.284 7-0.115 4-1.432 5 1.799 6 0.549 0 1.837 2 1.234 5-0.399 3-0.143 4-1.473 4-0.655 4 0.772 5-0.723 9 0.266 2-0.034 7 1.605 7-0.391 6 1.269 3 0.361 6 1.809 7-0.628 6-1.157 5-0.665 2 1.730 4 1.582 3-1.225 5-0.355 1-1.649 4-0.045 6 1.027 1-0.865 2-1.254 5-1.779 7-1.038 5-0.560 5-1.312 6 0.941 1-0.299 2-0.617 0 0.422 9 1.416 0 1.180 0
隐含层神经元阈值为:

?
隐含层到输出层权值矩阵为:

?
输出层神经元阈值:-0.403 8。
(3)选择复制。保留适应度最高的个体复制下一代,其他个体采取轮盘赌选择法进行选择,参与交叉和变异。
(4)交叉和变异操作。交叉操作是产生新个体的主要操作过程,变异操作是对个体的基因值按某一较小的概率进行改变,从而产生新个体。
具体交叉过程是随机选择配对个体xi,xj,i,j=1,2,...,N。
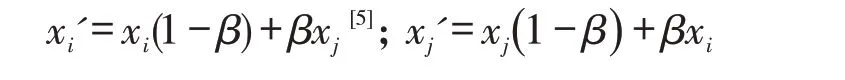
其中x'i,x'j分别为xi,xj交叉生成的后代,β为[0,1]内的随机交叉参数。
变异是在[0,1]区间内产生N个随机数,若任一随机数n<变异概率p,则对应的个体进行变异,构成新群体。本文选取交叉概率0.7,变异概率0.01。
(5)遗传神经网络运行流程如图1所示。
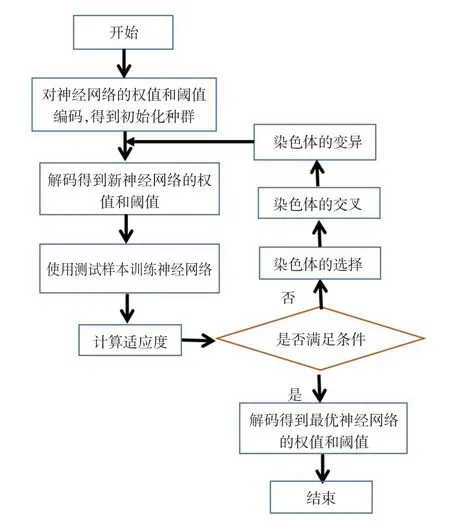
图1 遗传神经网络运行流程图
2.3 实验结果分析
选取襄阳市2006-2016年货运量及其影响因素的历史数据作为模型的训练样本对模型进行训练,将2017-2019年的历史数据作为模型的测试样本,对模型进行检验。训练到18次时,模型的精度达到最小。当训练到接近100次时,训练精度小于0.000 01,模型结构稳定,训练结束。此时模型的网络结构如图2所示,输入层7个神经元,输出层1个神经元,隐含层两个,神经元个数分别是9和1。
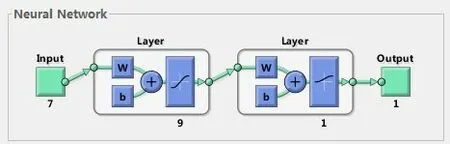
图2 基于灰色关联分析与遗传神经网络的模型网络结构
从表7可以看出,训练样本的输出值和实际值点位基本吻合,相关性非常好,反映输出值与真实值之间的差异非常小,该模型的预测精度比较高。运用模型预测2017-2019年的物流货运量,效果见表8。
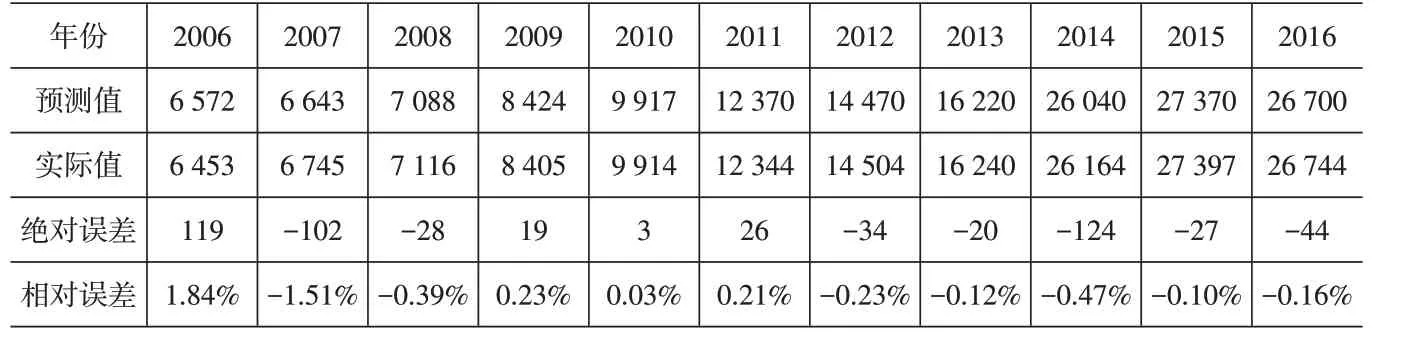
表7 2006-2016年训练样本输出值和实际值的比较
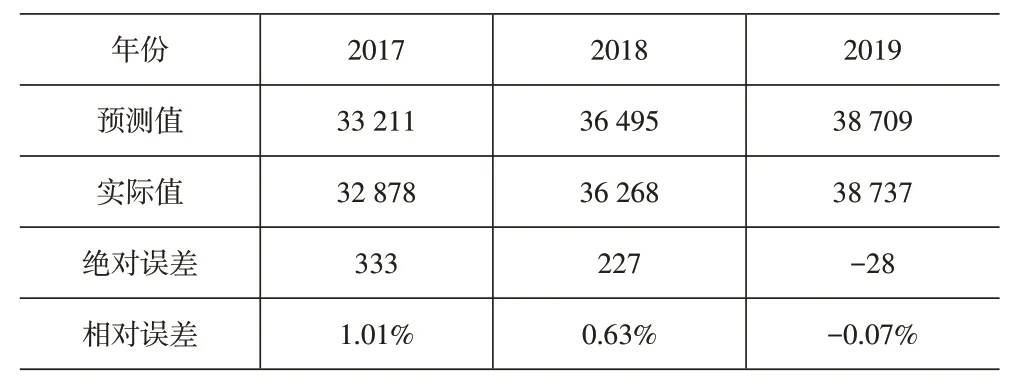
表8 模型对2017-2019年样本预测结果比较
从表8可以看出,预测模型的预测精度比较高,而且比较稳定。
3 结语
本文利用襄阳市2006-2019年的历史数据,通过灰色关联分析法针对地区生产总值GDP、第一产业产值、第二产业产值、第三产业产值、全社会交通运输行业固定资产投资、公路线路里程、进出口总值、社会消费品零售总额、人均GDP九个经济指标与物流货运量进行关联度分析,得到影响物流货运量的最佳关联度排序,最后确定选取地区生产总值(GDP)、第二产业产值、第三产业产值、全社会交通运输行业固定资产投资、进出口总值、社会消费品零售总额和人均GDP七个与物流货运量关联度比较大的经济指标作为遗传神经网络预测物流货运量的输入值,输出值为物流货运量。
通过实验发现,先利用灰色关联分析优化样本结构,提高样本质量,再利用遗传算法优化BP神经网络的权值和阈值,最后用BP神经网络进行问题求解,克服了BP神经网络容易陷入局部极小值的缺点,提高了遗传算法在寻找最优权值和阈值的收敛速度和搜索精度。预测结果分析可以看出本文建立的基于灰色关联分析与遗传神经网络的物流货运量预测模型预测准确度比较高,具有一定的实践意义。由于数据收集有难度,本文未将此次模型应用到其他城市货运量的预测中去检验,这是本文有待完善的地方。
猜你喜欢
当代水产(2021年8期)2021-11-04
中小学实验与装备(2021年3期)2021-06-28
今日农业(2020年22期)2020-12-14
今日农业(2020年14期)2020-08-14
创新作文(1-2年级)(2019年4期)2019-10-15
意林·全彩Color(2019年4期)2019-05-11
科学中国人(2018年8期)2018-07-23
大陆桥视野(2017年13期)2017-12-23
中国资源综合利用(2016年6期)2016-01-22
